数据可视化基础与应用-04-seaborn库人口普查分析--如何做人口年龄层结构金字塔
总结
本系列是数据可视化基础与应用的第04篇seaborn,是seaborn从入门到精通系列第3篇。本系列主要介绍基于seaborn实现数据可视化。
参考
参考:我分享了一个项目给你《seaborn篇人口普查分析–如何做人口年龄层结构金字塔》,快来看看吧
数据集地址
https://www.kesci.com/mw/project/5fde03b883e4460030a8dc3d/dataset
数据集介绍
2010年各地区分年龄,性别人口数据
背景描述
数据为中国2010年人口普查资料,包含2010年各地区分年龄、性别的人口,各地区分性别的户籍人口, 2010年(城市,乡村,镇)各地区分年龄、性别的人口
数据说明
1-7c 各地区分年龄、性别的人口(乡村).csv
1-7b 各地区分年龄、性别的人口(镇).csv
1-7a 各地区分年龄、性别的人口(城市).csv
1-3 各地区分性别的户籍人口.csv
各地区分年龄、性别的人口.csv
数据来源
中国2010年人口普查资料
问题描述
20年来出生男女比例变化?
男女找对象的合适年龄假设?初婚和再婚?
基于以上假设,哪个省份的男生以后找女朋友会越来越难?
结合结婚率、离婚率、民族、地域等信息,进一步猜测00后找女朋友的趋势变化
案例
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use('fivethirtyeight')from warnings import filterwarnings
filterwarnings('ignore')
#读取各地区分年龄、性别的人口
pcount = pd.read_csv('/home/kesci/input/GENDER8810/各地区分年龄、性别的人口.csv',skiprows=2)
"""
2010年各地区分年龄,性别人口数据
背景描述数据为中国2010年人口普查资料,包含2010年各地区分年龄、性别的人口,各地区分性别的户籍人口, 2010年(城市,乡村,镇)各地区分年龄、性别的人口
数据说明1-7c 各地区分年龄、性别的人口(乡村).csv
1-7b 各地区分年龄、性别的人口(镇).csv
1-7a 各地区分年龄、性别的人口(城市).csv
1-3 各地区分性别的户籍人口.csv
各地区分年龄、性别的人口.csv
"""
1. 探索性分析并处理数据
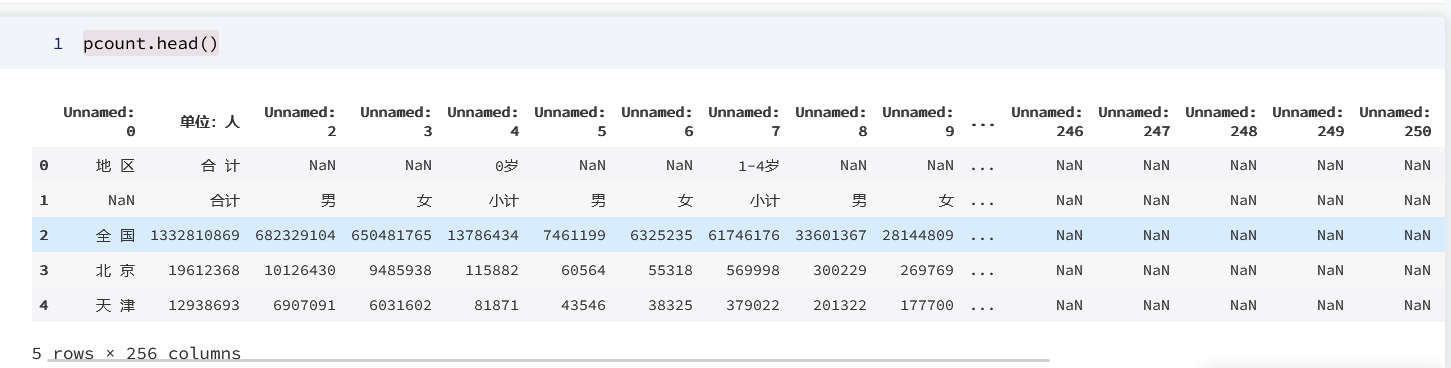
pcount.head()
输出为:
pcount.info()
输出为:

1.1 删除多余的列
#删除所有值为na的列
pcount=pcount.dropna(axis=1,how='all')
1.2 处理表头
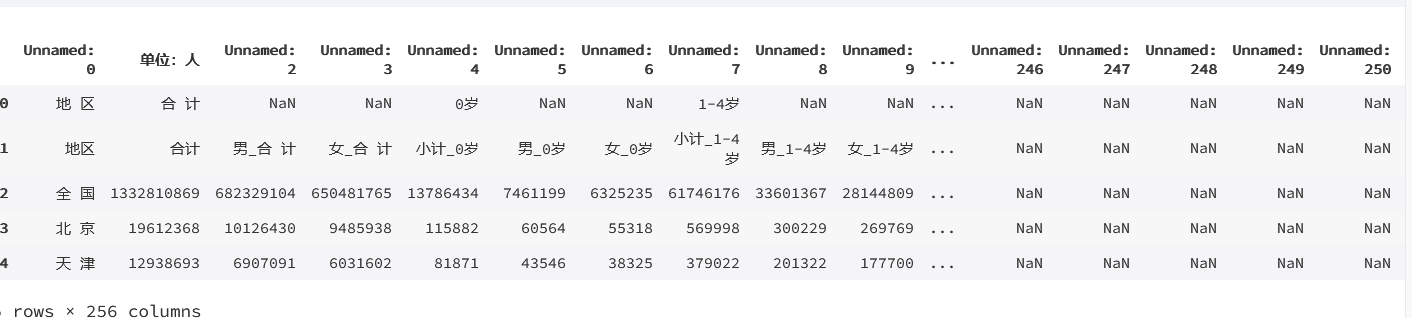
def rename(frame):for i in range(frame.shape[1]):frame.iloc[1,0]='地区'if frame.iloc[1,i]=='小计':frame.iloc[1,i]='小计'+ '_'+str(frame.iloc[0,i])elif frame.iloc[1,i]=='男':frame.iloc[1,i]='男' + '_' + str(frame.iloc[0,i-1])elif frame.iloc[1,i]=='女':frame.iloc[1,i]='女' + '_' + str(frame.iloc[0,i-2])rename(pcount)
pcount.head()
输出为:
1.3 透视数据
pcount.columns = pcount.iloc[1,]
pcount.columns
输出为:

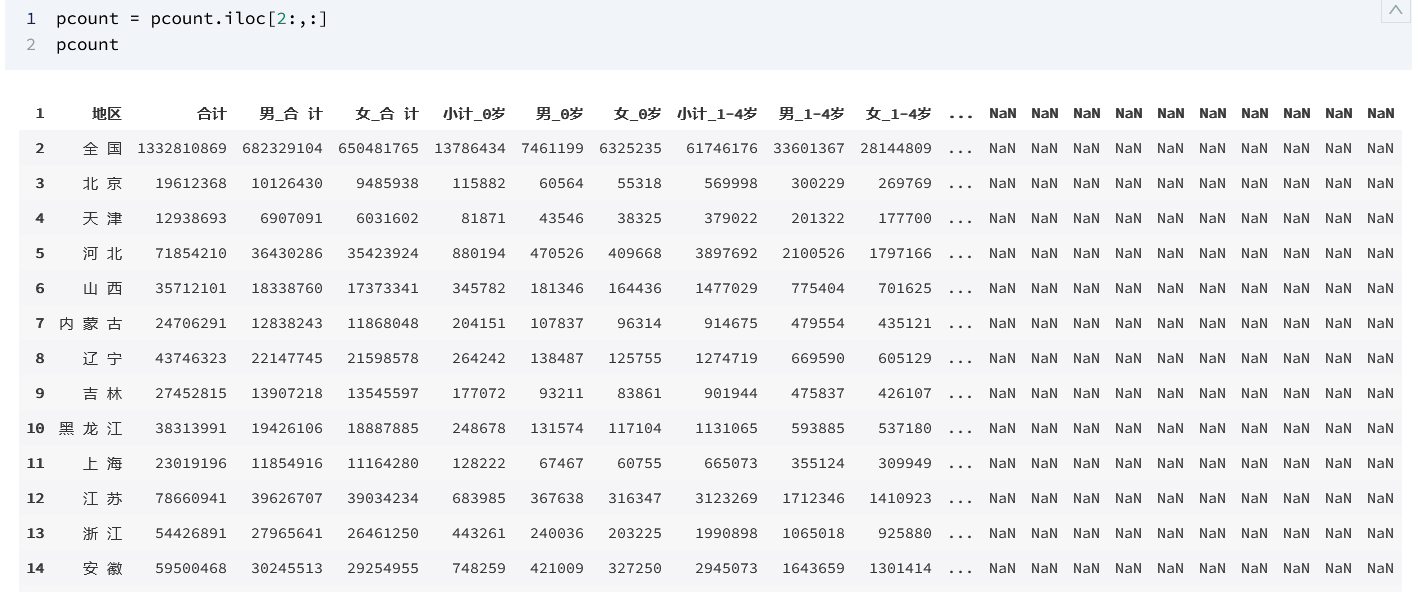
pcount = pcount.iloc[2:,:]
pcount
输出为:
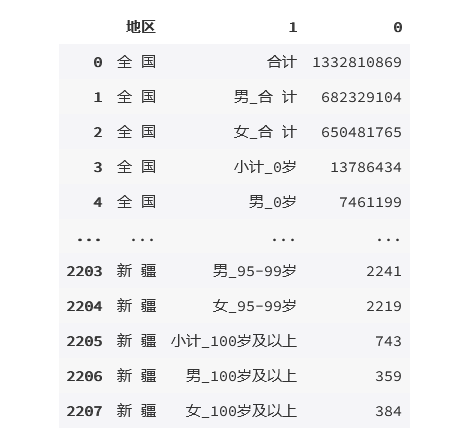
pcounts = pcount.set_index("地区").stack().reset_index()
pcounts
输出为:
pcounts.columns = ['地区','类别','统计人数']
pcounts
输出为:
1.4 处理空格(数据量大的话不建议这么做)
def replace_r(frame):for i in range(frame.shape[0]):frame.iloc[i,0] = frame.iloc[i,0].replace(" ",'')frame.iloc[i,1] = frame.iloc[i,1].replace(" ",'')replace_r(pcounts)
pcounts
输出为:

1.5 增加统计列
pcounts['年龄段'] = pcounts['类别'].str.split('_').str[-1]
pcounts['性别'] = pcounts['类别'].str.split('_').str[0]
#将统计人数转换为数值
pcounts['统计人数']=pcounts['统计人数'].astype('int')
2. 可视化部分
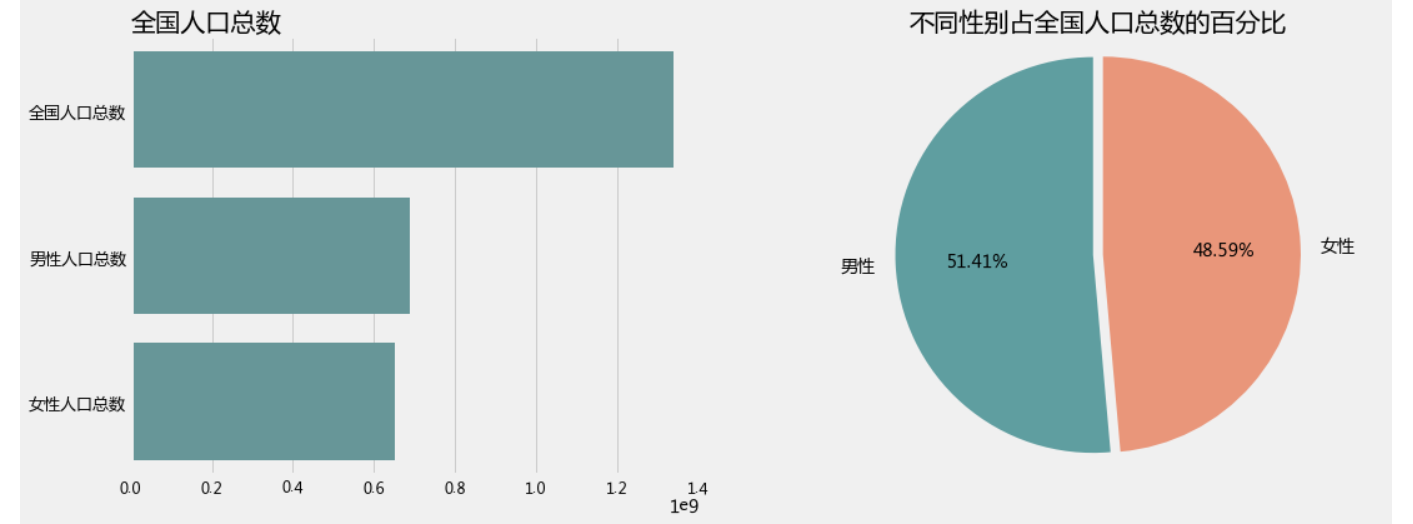
2.1 我国人口总数
plt.figure(1,figsize=(16,6))
plt.subplot(1,2,1)
sns.barplot(y=['全国人口总数','男性人口总数','女性人口总数'],x=[1337376754,687562046,649814708],color='CadetBlue')
plt.title("全国人口总数",loc='left')
plt.xticks(fontsize=12)
plt.yticks(fontsize=13)plt.subplot(1,2,2)
patches,l_text,p_text=plt.pie([687562046,649814708],labels=['男性','女性'],autopct='%.2f%%',colors=['CadetBlue','DarkSalmon'],explode=[0,0.05],startangle=90)
plt.title('不同性别占全国人口总数的百分比')
plt.axis('equal')
plt.show()
输出为:
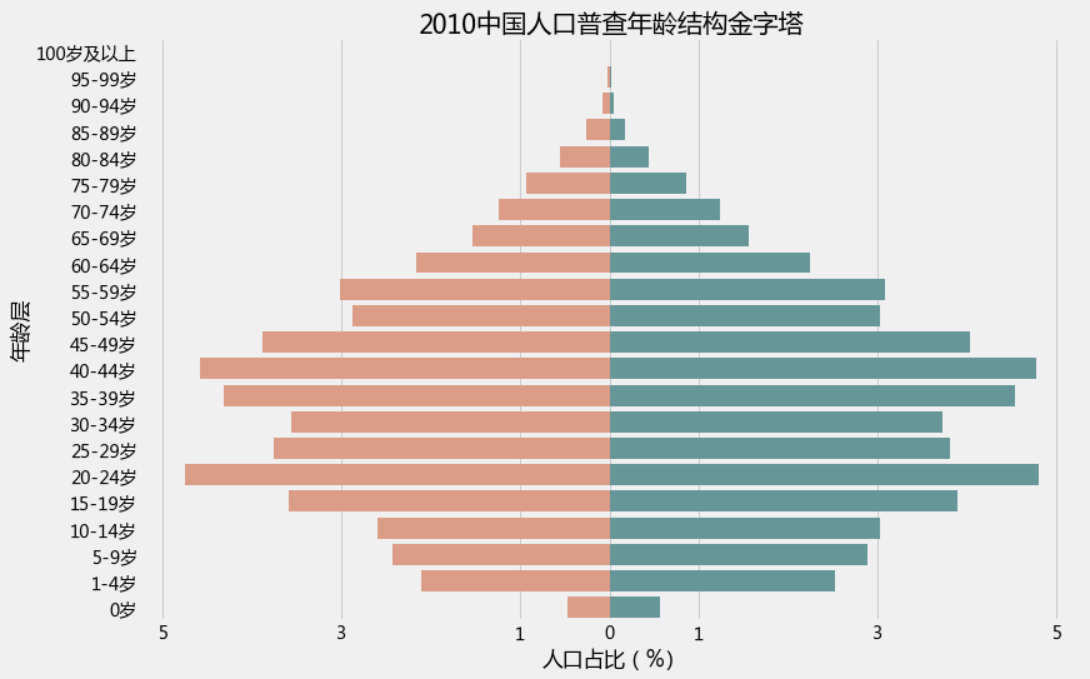
2.1 人口年龄结构金字塔(左边女右边男)
result = pcounts[(pcounts['性别'].isin(['男','女']))&(pcounts['地区']=='全国')&(pcounts['年龄段']!='合计')]
result输出为:
result['人口占比'] =( result['统计人数']/result['统计人数'].sum()*100).round(2)
result
输出为:
# 女性占比
-result[result['性别']=='女']['人口占比'].values
输出为:

plt.figure(figsize=(12,8))bar_plot = sns.barplot(y = result['年龄段'].unique(), x = -result[result['性别']=='女']['人口占比'].values, color = "DarkSalmon", data = result,order = result['年龄段'].unique()[::-1],)
bar_plot = sns.barplot(y = result['年龄段'].unique(), x = result[result['性别']=='男']['人口占比'].values, color = "CadetBlue",data = result,order = result['年龄段'].unique()[::-1],)plt.xticks([-5,-3,-1,0,1,3,5])
# plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = True
bar_plot.set(xlabel="人口占比(%)", ylabel="年龄层", title = "2010中国人口普查年龄结构金字塔")
plt.show()
输出为:
2.2 差异
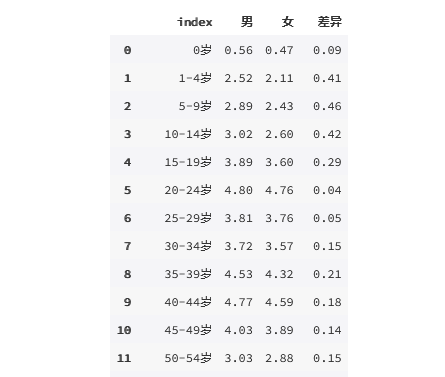
data = {'index': result['年龄段'].unique(),'男': result[result['性别']=='男']['人口占比'].values,'女': result[result['性别']=='女']['人口占比'].values,}
Data = pd.DataFrame(data)
Data['差异']=Data['男']-Data['女']
Data
输出为:
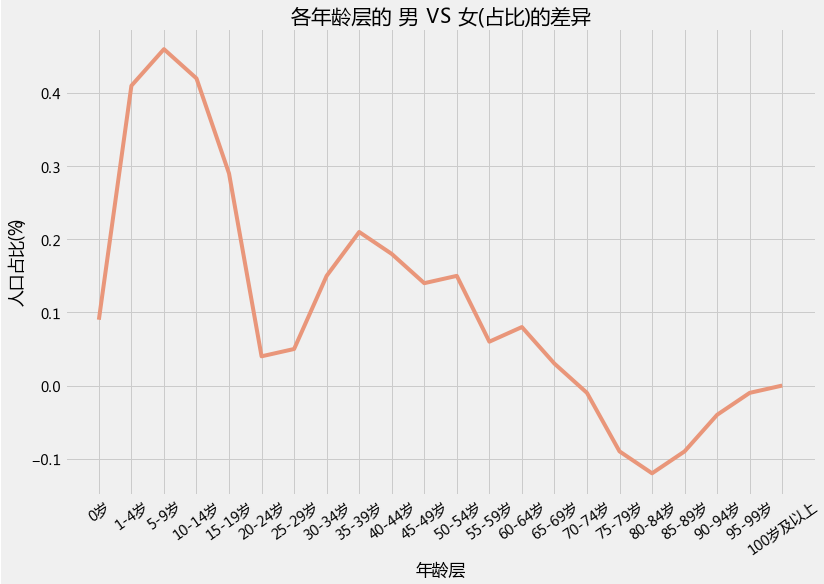
plt.figure(1,figsize=(12,8))
sns.lineplot(x=Data['index'],y=Data['差异'],color='DarkSalmon',sort=False)
plt.xlabel("年龄层")
plt.ylabel("人口占比(%)")
plt.title("各年龄层的 男 VS 女(占比)的差异")
plt.xticks(rotation=35)
plt.show()
输出为:
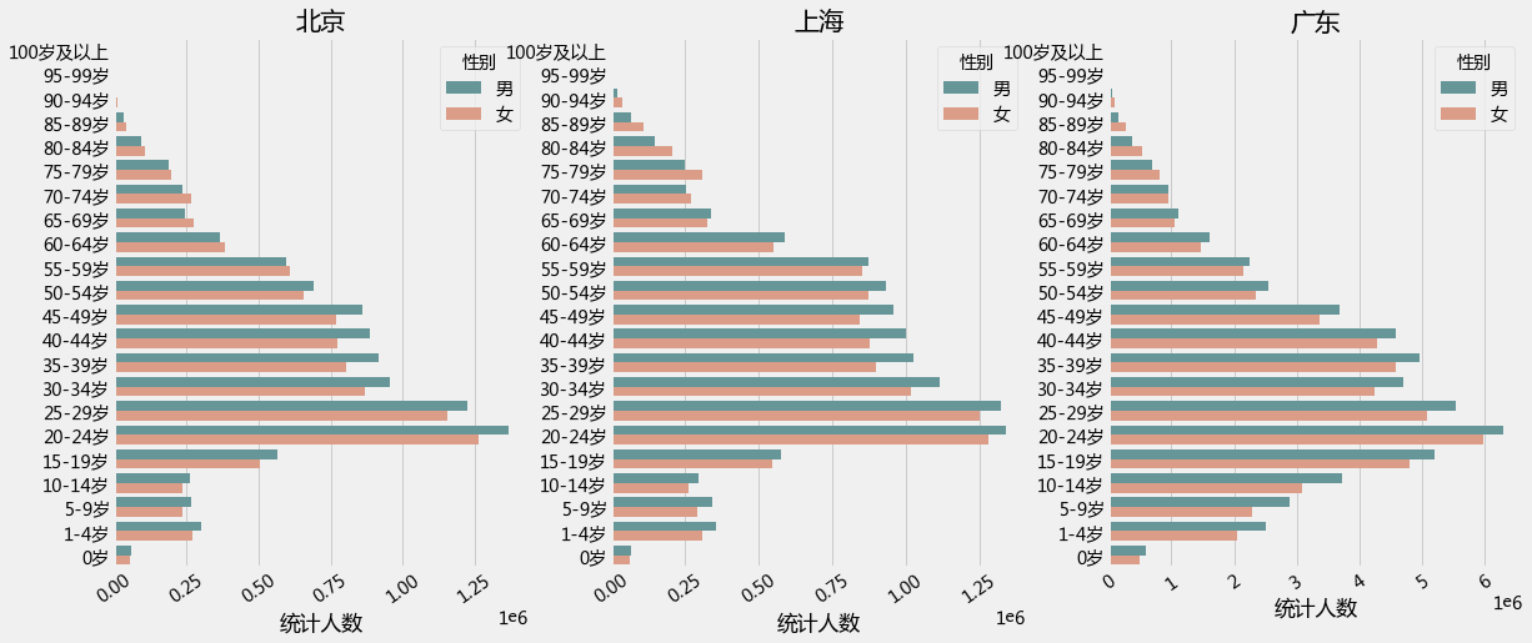
2.3 北京、上海、广东地区的人口年龄结构金字塔(左边女右边男)
plt.figure(1,figsize=(18,16))
n = 0
for x in ['北京','上海','广东']:result = pcounts[(pcounts['性别'].isin(['男','女']))&(pcounts['地区'] == x )&(pcounts['年龄段']!='合计')]result['人口占比'] =( result['统计人数']/result['统计人数'].sum()*100).round(2)n +=1plt.subplot(2,3,n)bar_plot = sns.barplot(y = result['年龄段'].unique(), x = -result[result['性别']=='女']['人口占比'].values, color = "DarkSalmon", data = result,order = result['年龄段'].unique()[::-1],)bar_plot = sns.barplot(y = result['年龄段'].unique(), x = result[result['性别']=='男']['人口占比'].values, color = "CadetBlue",data = result,order = result['年龄段'].unique()[::-1],)plt.xticks([-7,-5,-3,-1,0,1,3,5,7],[7,5,3,1,0,1,3,5,7])plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Truebar_plot.set(xlabel="人口占比(%)", ylabel="年龄层", title = x )plt.ylabel('')
plt.show()
输出为:
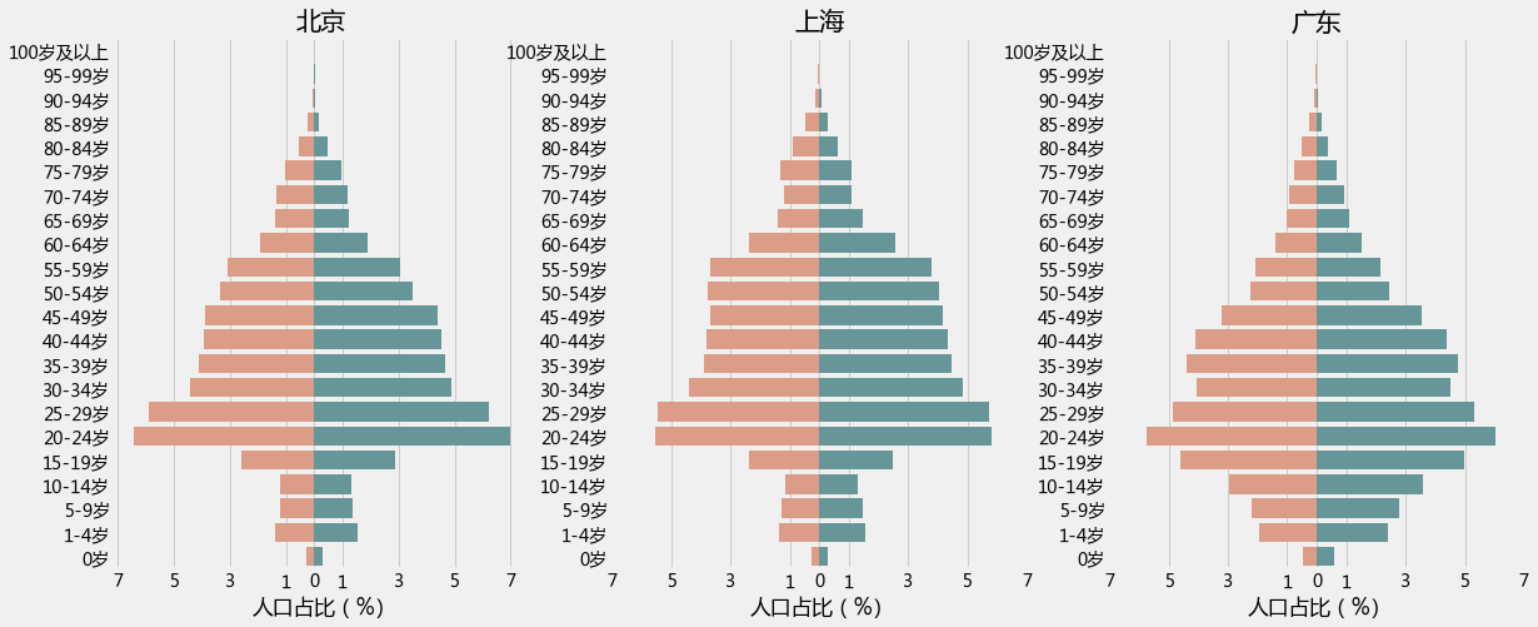
上图这三个地区还是比较突出的但不容易看出男女差异,我们再来一个性别的对比图
plt.figure(1,figsize=(18,16))
n = 0
for x in ['北京','上海','广东']:result = pcounts[(pcounts['性别'].isin(['男','女']))&(pcounts['地区'] == x )&(pcounts['年龄段']!='合计')]n +=1plt.subplot(2,3,n)sns.barplot(x='统计人数',y='年龄段',hue='性别',data=result,palette=['CadetBlue','DarkSalmon'],order=result['年龄段'].unique()[::-1])plt.title(x)plt.xticks(rotation=35)plt.ylabel('')
plt.show()
输出为:
不难发现这三个地区的男女比例失衡,在中青年这个年龄段较为严重
2.4 人口分布地图
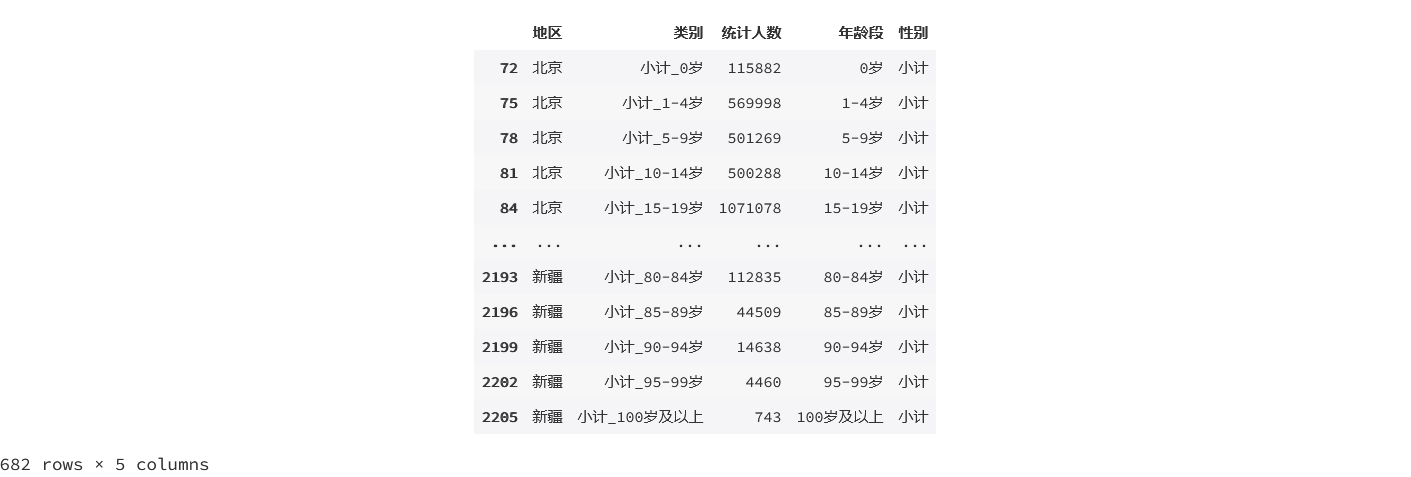
result1 = pcounts[(pcounts['性别']=='小计')&(pcounts['地区']!='全国')&(pcounts['年龄段']!='合计')]
result1
输出为:
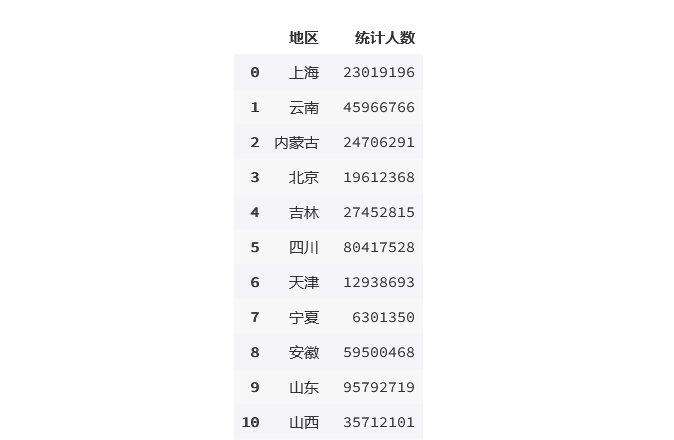
result2 = result1.groupby('地区')['统计人数'].sum().reset_index(name='统计人数')
result2
输出为:
# pip install pyecharts
# from pyecharts.globals import CurrentConfig,OnlineHostType
# CurrentConfig.ONLINE_HOST = OnlineHostType.NOTEBOOK_HOST
from pyecharts.charts import Map
from pyecharts import options as opts
x_data = result2['地区'].tolist()
y_data = result2['统计人数'].tolist()
x_data
输出为:

name_translate = {"宁夏回族自治区":"宁夏","河南省":"河南","北京市":"北京","河北省":"河北","辽宁省":"辽宁","江西省":"江西",
"上海市":"上海","安徽省": "安徽","江苏省":"江苏","湖南省":"湖南","浙江省":"浙江","海南省":"海南",
"广东省":"广东","湖北省":"湖北", "黑龙江省": "黑龙江","陕西省":"陕西","四川省":"四川","内蒙古自治区":"内蒙古",
"重庆市":"重庆","广西壮族自治区":"广西","云南省":"云南","贵州省":"贵州","吉林省":"吉林","山西省":"山西",
"山东省":"山东","福建省":"福建","青海省":"青海","天津市":"天津","新疆维吾尔自治区":"新疆","西藏自治区":"西藏",
"甘肃省":"甘肃","大连市":"大连", "东莞市":"东莞","宁波市":"宁波","青岛市":"青岛","厦门市":"厦门","台湾省":" ","澳门特别行政区":" ",
"香港特别行政区":" ","南海诸岛":" "}
# 地图
map1 = Map()
map1.add("", [list(z) for z in zip(x_data, y_data)],"china",name_map=name_translate)
map1.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
map1.set_global_opts(title_opts=opts.TitleOpts(title='全国各地区人口分布'),
visualmap_opts=opts.VisualMapOpts( max_=result2['统计人数'].max(),
min_ =result2['统计人数'].min(),is_piecewise=False))
map1.render_notebook()
输出为:
2010年的人口普查数据显示:广东省、山东省、河南省、四川省、江苏省 是总人口数前 5 的地区
相关文章:
数据可视化基础与应用-04-seaborn库人口普查分析--如何做人口年龄层结构金字塔
总结 本系列是数据可视化基础与应用的第04篇seaborn,是seaborn从入门到精通系列第3篇。本系列主要介绍基于seaborn实现数据可视化。 参考 参考:我分享了一个项目给你《seaborn篇人口普查分析–如何做人口年龄层结构金字塔》,快来看看吧 数据集地址 h…...

软考之【系统架构设计师】
系统架构设计师 根据原人事部、原信息产业部文件(国人部发[2003]39号)文件规定,计算机软件资格考试纳入全国专业技术人员职业资格证书制度的统一规划,实行统一大纲、统一试题、统一标准、统一证书的考试办法,每年举行…...

LigaAI x 极狐GitLab,共探 AI 时代研发提效新范式
近日,LigaAI 和极狐GitLab 宣布合作,双方将一起探索 AI 时代的研发效能新范式,提供 AI 赋能的一站式研发效能解决方案,让 AI 成为中国程序员和企业发展的新质生产力。 软件研发是一个涉及人员多、流程多、系统多的复杂工程&#…...

如何看待2023年图灵奖
目录 1.概述 2.计算复杂性理论 3.随机性和伪随机性 4.学术生涯和领导力 1.概述 图灵奖(Turing Award),全称A.M.图灵奖(ACM A.M Turing Award),是由计算机领域的最高学术机构——美国计算机协会…...
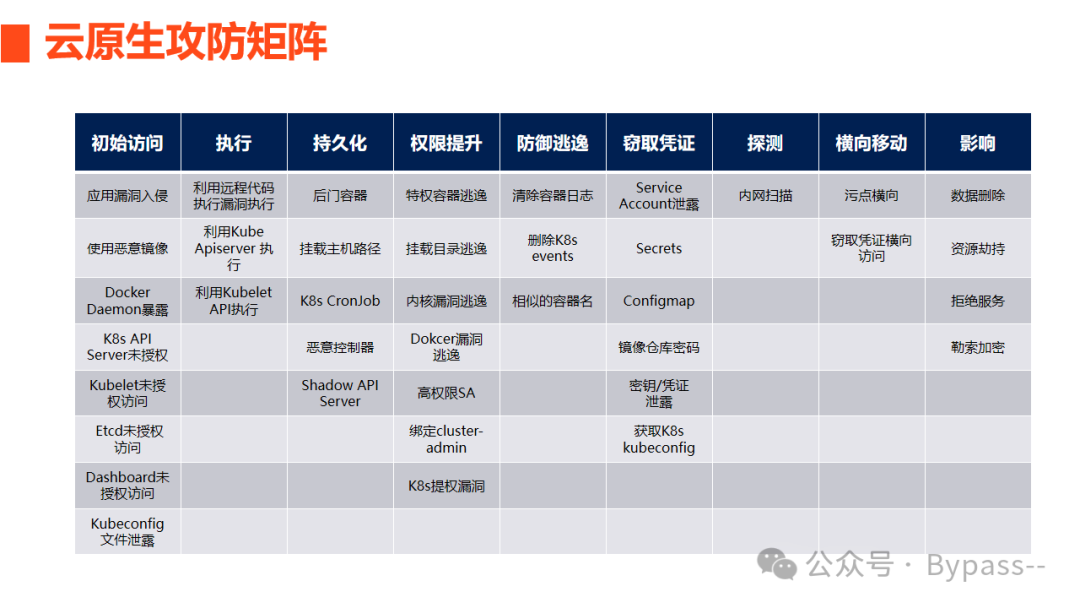
《云原生安全攻防》-- 云原生攻防矩阵
在本节课程中,我们将开始学习如何从攻击者的角度思考,一起探讨常见的容器和K8s攻击手法,包含以下两个主要内容: 云原生环境的攻击路径: 了解云原生环境的整体攻击流程。 云原生攻防矩阵: 云原生环境攻击路径的全景视图࿰…...
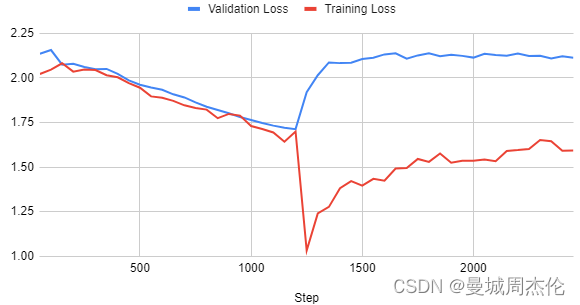
自然语言处理: 第二十七章LLM训练超参数
前言: LLM微调的超参大致有如下内容,在本文中,我们针对这些参数进行解释 training_arguments TrainingArguments(output_dir"./results",per_device_train_batch_size4,per_device_eval_batch_size4,gradient_accumulation_steps2,optim"adamw_8bi…...
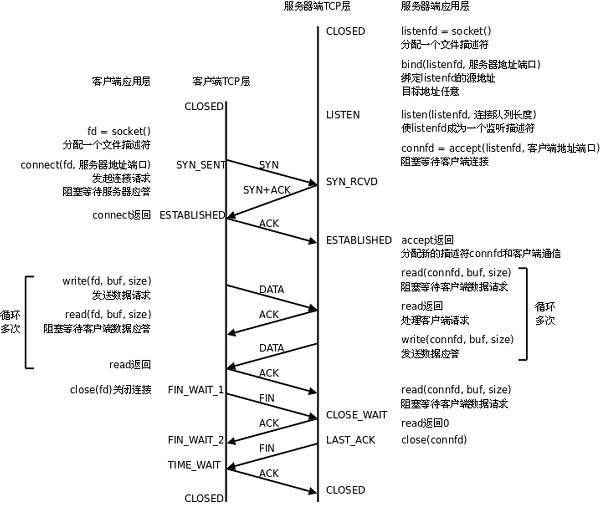
Linux使用C语言实现Socket编程
Socket编程 这一个课程的笔记 相关文章 协议 Socket编程 高并发服务器实现 线程池 网络套接字 socket: (电源)插座(电器上的)插口,插孔,管座 在通信过程中, 套接字是成对存在的, 一个客户端的套接字, 一个…...
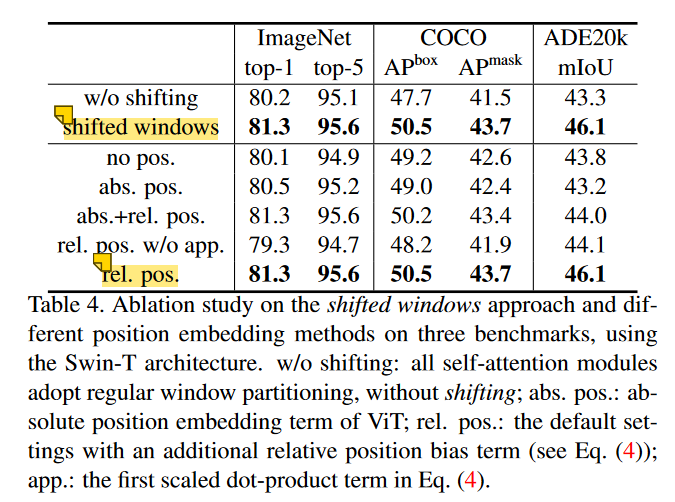
Swin Transformer——披着CNN外皮的transformer,解决多尺度序列长问题
题目:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》作为2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet…...
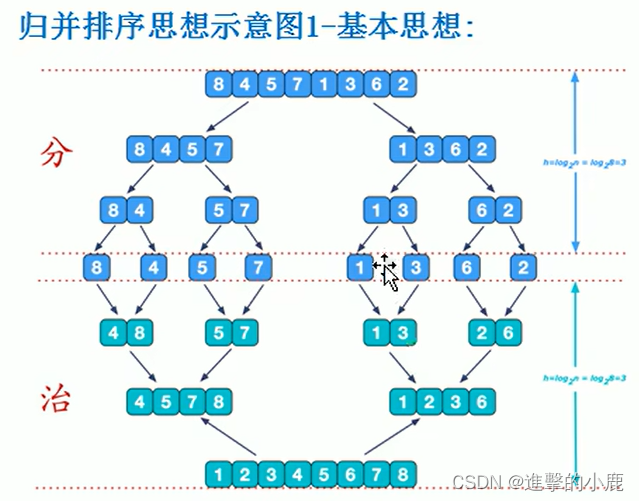
数据结构排序算法
排序也称排序算法(SortAlgorithm),排序是将一组数据,依指定的顺序进行排列的过程。 分类 内部排序【使用内存】 指将需要处理的所有数据都加载到内部存储器中进行排序插入排序 直接插入排序希尔排序 选择排序 简单选择排序堆排序 交换排序 冒泡排序快速…...

【深度剖析】曾经让人无法理解的事件循环,前端学习路线
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7 深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞…...
Spring 事务失效总结
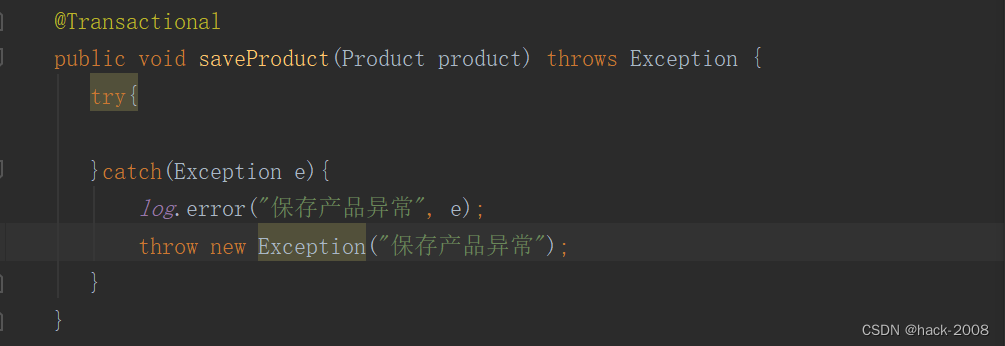
前言 在使用spring过程中事务是被经常用的,如果不小心或者认识不做,事务可能会失效。下面列举几条 业务代码没有被Spring 容器管理 看下面图片类没有Componet 或者Service 注解。 方法不是public的 Transactional 注解只能用户public上,…...

K8S节点kubectl命令报错x509: certificate signed by unknown authority
K8S节点上执行kubectl get node命令报错证书问题,查看kubelet日志如下 [localhost10 ~]$ journalctl -xeu kubelet --since "2024-04-09" --no-pager 4月 09 00:06:22 10.10.44.23-v7-prod-cams-08 kubelet[2142]: I0409 00:06:22.150535 2142 csi_pl…...

【HTML】制作一个简单的实时字体时钟
目录 前言 HTML部分 CSS部分 JS部分 效果图 总结 前言 无需多言,本文将详细介绍一段HTML代码,具体内容如下: 开始 首先新建文件夹,创建一个文本文档,两个文件夹,其中HTML的文件名改为[index.html]&am…...
servlet的三个重要的类(httpServlet 、httpServletRequst、 httpServletResponse)
一、httpServlet 写一个servlet代码一般都是要继承httpServlet 这个类,然后重写里面的方法 但是它有一个特点,根据之前写的代码,我们发现好像没有写main方法也能正常执行。 原因是:这个代码不是直接运行的,而是放到…...
【软考】设计模式之命令模式
目录 1. 说明2. 应用场景3. 结构图4. 构成5. 优缺点5.1 优点5.2 缺点 6. 适用性7.java示例 1. 说明 1.命令模式(Command Pattern)是一种数据驱动的设计模式。2.属于行为型模式。3.请求以命令的形式被封装在对象中,并传递给调用对象。4.调用对…...

波奇学Linux:ip协议
ip报头是c语言的结构体 报头和有效载荷如何分离? 固定长度四位首部长度 4位版本号就是IPV4 8位服务类型:4位TOS位段和位保留字段 4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本 给路由器提…...
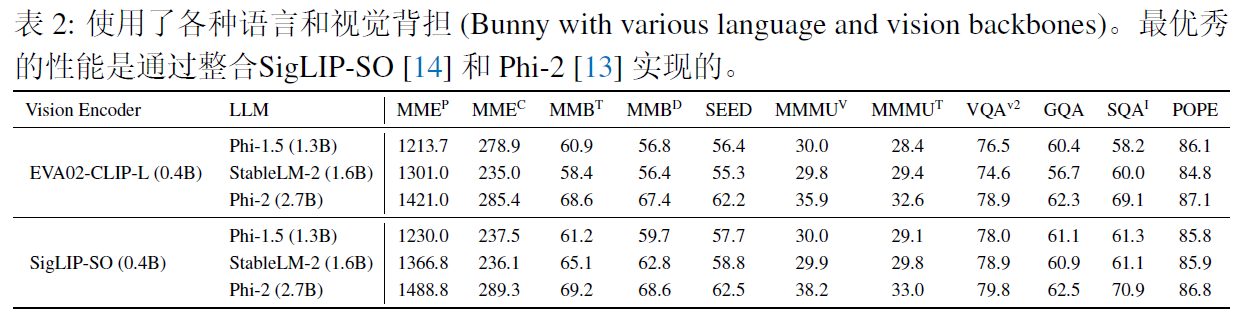
Efficient Multimodal learning from data-centric perspective
[MLLM-小模型推荐-2024.3.18] Bunny 以数据的眼光看问题 - 知乎近期几天会梳理下多模态小模型相关的论文,做个汇总。为了能够每天更新点啥,先穿插一些小模型算法。等到全部算法都梳理完成后,再发布一篇最终汇总版本的。 3.15 号 BAAI 发布了 …...

ubuntu下交叉编译ffmpeg到目标架构为aarch架构的系统
Ubuntu下FFmpeg的aarch64-linux-gnu架构交叉编译教程 一、前言 有时候真的很想报警的,嵌入式算法部署花了好多时间了,RKNN 1808真是问题不少;甲方那边也是老是提新要求,真是受不了。 由于做目标检测,在C代码中有对视…...

【Linux C | 多线程编程】线程同步 | 条件变量(万字详解)
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 ⏰发布时间⏰:2024-04-15 0…...

【高阶数据结构】哈希表 {哈希函数和哈希冲突;哈希冲突的解决方案:开放地址法,拉链法;红黑树结构 VS 哈希结构}
一、哈希表的概念 顺序结构以及平衡树 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系。因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N);平衡树中为树的高度,即O(log_2 N)…...
)
告别导入报错!手把手教你用Navicat把Excel数据完美搬进MySQL(含字段超限处理)
从Excel到MySQL:Navicat数据迁移全流程实战指南 数据迁移是开发者和数据分析师日常工作中的高频需求。想象一下这样的场景:市场部门发来一份包含3000条客户信息的Excel表格,需要快速导入到测试环境的MySQL数据库中进行功能验证;或…...

靠谱的工程防火门公司推荐
在工程行业摸爬滚打十几年,我见过太多因防火门翻车的项目:验收反复返工、产品用了两三年就变形卡死、超大门洞找不到厂家定制…… 这些看似鸡毛蒜皮的小事,一旦卡到消防验收节点上,轻则赔钱延期,重则被责令停工整改。今…...

音乐解锁终极指南:打破平台限制,释放你的音乐收藏
音乐解锁终极指南:打破平台限制,释放你的音乐收藏 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址…...

【DeepSeek API接入实战指南】:20年架构师亲授5大避坑法则与3小时极速接入方案
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API接入开发教程 DeepSeek 提供了稳定、高性能的大模型 API 接口,支持文本生成、对话补全与函数调用等多种能力。开发者需通过 RESTful 方式调用其 OpenAPI v1 接口,所…...

告别混乱!用Cadence Allegro SPB17.4从DXF文件创建PCB封装的完整清洁流程
告别混乱!用Cadence Allegro SPB17.4从DXF文件创建PCB封装的完整清洁流程 在PCB设计领域,从机械图纸(DXF)快速创建精确的封装是工程师常面临的挑战。许多设计师都经历过这样的困扰:导入DXF后,封装在3D预览中…...

手把手复现文献案例:用Design-Expert做阿维菌素发酵培养基的响应面优化
手把手复现文献案例:用Design-Expert做阿维菌素发酵培养基的响应面优化 在生物工程和发酵工艺优化领域,响应面法(Response Surface Methodology, RSM)已成为提升产物产量的黄金标准。本文将以胡栋等学者2018年发表在《中国抗生素杂…...

AMD锐龙处理器深度调优终极指南:5种专业级配置策略
AMD锐龙处理器深度调优终极指南:5种专业级配置策略 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitco…...
)
手把手教你用FPGA+CORDIC算法实现任意角度图像旋转(告别浮点运算)
FPGACORDIC算法实现高精度图像旋转的硬件优化实践 在数字图像处理领域,实时图像旋转是一项基础而关键的技术需求。传统基于浮点运算的旋转方案虽然直观,但在FPGA等硬件平台上往往面临资源占用高、时序难以满足的挑战。本文将深入探讨如何利用CORDIC&…...

不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制
不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制 在汽车工程仿真领域,AVL Cruise与Matlab Simulink的联合仿真已成为动力系统开发的标准工具链。大多数教程停留在环境配置层面,而真正影响仿真效率与可靠性的,往…...

不删除属性的情况下简化对象属性的方法探讨
是否还有其他方法可以简化从对象中删除特定属性的操作。舍友提出了一个对象属性简化的问题,询问在不删除属性的情况下,如何简化从对象中删除特定属性的操作。02解决方案最初,我曾考虑过不直接删除属性,而是仅保留业务所需的那些。…...