【高阶数据结构】哈希表 {哈希函数和哈希冲突;哈希冲突的解决方案:开放地址法,拉链法;红黑树结构 VS 哈希结构}
一、哈希表的概念
-
顺序结构以及平衡树
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系。因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N);平衡树中为树的高度,即O(log_2 N),搜索的效率取决于搜索过程中元素的比较次数。
-
哈希表
如果构造一种存储结构,通过某种转换函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系。那么在查找时可以不经过任何比较,通过该函数一次直接从表中得到要搜索的元素:
-
当向该结构中插入元素时:根据待插入元素的关键码,通过转换函数计算出该元素的存储位置并按此位置进行存放。
-
当从该结构中搜索元素时:对元素的关键码进行同样的计算,获得元素的存储位置。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table或者称散列表)
-
二、哈希函数和哈希冲突
-
哈希函数
哈希函数的设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见的哈希函数:
-
直接定址法
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀、不存在哈希冲突
缺点:需要事先知道关键字的分布情况,只适合查找分布相对集中的情况。
举例:1.编程题:字符串中第一个只出现一次字符 2.排序算法:计数排序 -
除留余数法
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数;
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
例如:数据集合{1,7,6,4,5,9};
哈希函数采用除留余数法:hash(key) = key % capacity; capacity为存储元素底层空间的总大小。

问:按照上述哈希方式,向集合中插入元素44,会出现什么问题?
-
哈希冲突
-
对于两个数据元素的关键字
k_i和k_j,有k_i != k_j,但有:Hash(k_i) ==Hash(k_j);-
即:不同关键字通过哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
-
把关键码不同而具有相同哈希地址的数据元素称为“同义词”。
-
问:发生哈希冲突该如何处理呢?
-
三、哈希冲突的解决方案
解决哈希冲突两种常见的方法是:开放地址法和链地址法
3.1 开放地址法
开放地址法:当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的下一个空位置中去。那如何寻找下一个空位置呢?
3.1.1 线性探测
-
线性探测
比如2.2中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。- 插入
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素

-
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。
比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
哈希表每个空间给个标记:EMPTY此位置为空, EXIST此位置已经有元素, DELETE元素已经删除插入时:对于EMPTY和DELETE标记的位置可以进行插入,EXIST不能插入。
搜索时:遇到EXIST和DELETE标记的位置继续向后搜索,遇到EMPTY结束。
-
扩容
思考:哈希表什么情况下进行扩容?如何扩容?

载荷因子(空间占用率)达到基准值(0.7~0.8)就扩容。
基准值越大,哈希冲突的概率越大,查找效率越低,但空间利用率越高。
基准值越小,哈希冲突的概率越小,查找效率越高,但空间利用率越低。
-
Hash算法
-
对于类型不匹配或者复杂类型的key值,不能直接求余计算哈希地址。这时我们需要一种算法,将不匹配或复杂类型的key转化为无符号整型,然后才能通过除留余数法计算哈希地址。我们将这样的算法称为Hash算法。
-
Hash算法的设计原则是:尽量避免出现key值不同但转换后的无符号整型相同的情况。使不同的key值转换成唯一、独特的无符号整型数据。降低哈希冲突的概率。
-
以字符串Hash算法为例:
-
问:为什么不选字符串首字母的assic码做key?
答:字符的assic码共有128个,而字符串有无数种组合方式。单靠首字母的assic码区分字符串,违背了Hash算法的设计原则。会使哈希冲突的概率变大,所以我们取字符串所有字符的assic码和做key。
-
仍然无法解决的问题:abcd acbd aadd
最终方案:BKDR算法,在每次加和时累乘131,能使哈希冲突的概率大大降低。也是Java目前采用的字符串Hash算法。
-
-
-
线性探测的实现
enum State{EMPTY,DELETE,EXIST};template <class K, class V>struct HashData{pair<K,V> _kv;State _state = EMPTY;};//HashKey用于将不匹配或复杂的key值转化为size_t类型,然后才能通过除留余数法计算哈希地址。//对于不匹配的内置类型做强转:template <class K>struct HashKey{size_t operator()(const K& k){return (size_t)k;}};//对于常见复杂类型提供模版的特化:template <>struct HashKey<string>{size_t operator()(const string& str){size_t ret = 0;for(auto ch : str){ret += ch;ret *= 131; //BKDR算法}return ret;}};template <class K, class V, class Hash = HashKey<K>>class HashTable{vector<HashData<K,V>> _table;size_t _size= 0; //哈希表中的实际有效数据public:bool insert(const pair<K,V>& kv){//不允许键值冗余if(find(kv.first) != nullptr)return false;//检查载荷因子,进行扩容,复用下面的插入逻辑if(_table.size() == 0 || _size*10/_table.size() >= 7){int newsize = _table.size()==0? 10 : _table.size()*2;HashTable newHT; //创建新的哈希表对象newHT._table.resize(newsize);for(auto &e : _table){if(e._state == EXIST)newHT.insert(e._kv); //调用成员函数insert重新计算元素的映射位置}//交换两个哈希表的vector//函数返回前newHT包含扩容前的vector会被析构_table.swap(newHT._table); }Hash hash; //hash算法会将不匹配或复杂的key值转化为size_t类型int hashi = hash(kv.first)%_table.size(); //线性探测//遇到EMPTY或DELETE位置停下while(_table[hashi]._state == EXIST){++hashi;hashi %= _table.size(); //如果超出范围需折返到开头继续探测}_table[hashi]._kv = kv;_table[hashi]._state = EXIST;++_size;return true;}HashData<K,V>* find(const K& k){if(_table.size() == 0)return nullptr; //空表返回nullptrHash hash;int hashi = hash(k)%_table.size(); int start = hashi;//线性探测//遍历到EMPTY位置表示对应key值的元素不存在。//注意:遇到DELETE位置不能停,要继续向后查找。while(_table[hashi]._state != EMPTY){if(_table[hashi]._state == EXIST && _table[hashi]._kv.first == k){return &_table[hashi]; //找到返回数据地址}++hashi;hashi%=_table.size();//处理极端情况:表中元素的状态全是DELETEif(hashi == start) break;}return nullptr; //找不到返回nullptr}bool erase(const K& k){HashData<K,V>* ret = find(k);if(ret == nullptr)return false;else{//线性探测采用标记的伪删除法来删除一个元素ret->_state = DELETE; //所谓删除就是将对应key值的元素状态改为DELETE--_size; //记得修改大小哦return true;}}void printHT(){ //打印哈希表for(int i=0; i<_table.size(); ++i){if(_table[i]._state == EXIST){printf("[%d]:%d ", i, _table[i]._kv.first);//cout << _table[i]._kv.first << ":" << _table[i]._kv.second << endl; }else{printf("[%d]:* ", i);}}}}; - 插入
3.1.2 二次探测
- 二次探测
线性探测的优点是实现非常简单,但其缺陷是元素之间相互占用位置导致产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找:H_i = (H_0 + i )% m 或 H_i = (H_0 - i )% m
因此二次探测为了避免该问题,找下一个空位置的方法为:H_i = (H_0 + i^2 )% m, 或者 H_i = (H_0 - i^2 )% m。
其中:i =1,2,3…。 H_0是通过散列函数Hashfunc(key)对元素的关键码 key 进行计算得到的位置。m是表的大小。
-
将线性探测改为二次探测
bool insert(const pair<K,V>& kv){if(find(kv.first) != nullptr) return false; //检查载荷因子,进行扩容 //......Hash hash; int i = 1; int hashi = hash(kv.first)%_table.size(); //二次探测while(_table[hashi]._state == EXIST){hashi += i*i; //加i的平方hashi %= _table.size();++i;}_table[hashi]._kv = kv;_table[hashi]._state = EXIST;++_size;return true;}提示:对应的find函数也应该改为二次探测才能正确运行!
二次探测只能在一定程度上缓解线性探测带来的“洪水效应”,但其终归是占用式的,没有从根源上解决因占用而导致的冲突问题。
3.2 链地址法
-
概念
链地址法又叫拉链法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
仍以2.2中的场景为例:

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
-
对比哈希表和红黑树
-
查找
哈希表的查找更快:O(1);红黑树的查找:O(log_2N)
如果某个哈希桶过长(一般不会),可以考虑挂红黑树,以提高该哈希桶的搜索速度。
-
插入
红黑树的插入:消耗主要在查找空位置O(log_2N)+变色O(log_2N)+旋转O(1) ==> O(log_2N)。
哈希表的插入:消耗主要在扩容,不仅要开空间拷贝数据,还要重新计算每个元素的哈希地址。扩容的时间复杂度O(N)
使用rehash/reserve提前开空间,提高哈希表的插入效率。
-
unordered_map和unordered_set底层的哈希结构采用的就是开散列法。
相关文章:
【高阶数据结构】哈希表 {哈希函数和哈希冲突;哈希冲突的解决方案:开放地址法,拉链法;红黑树结构 VS 哈希结构}
一、哈希表的概念 顺序结构以及平衡树 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系。因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N);平衡树中为树的高度,即O(log_2 N)…...
)
嵌入式之计算机网络篇(七)
七、计算机网络 1.说说计算机网络五层体系结构 计算机网络的五层架构包括应用层、传输层、网络层、数据链路层和物理层。 应用层:是网络结构中的最高层,负责向用户提供网络服务,如文件传输、电子邮件、远程登录等。常见的应用层协议有HTTP…...
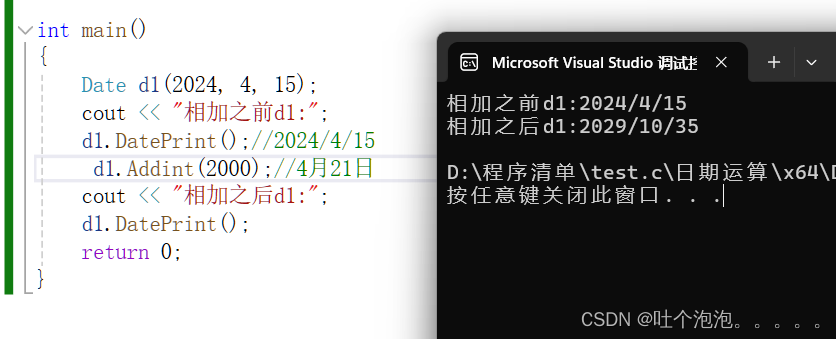
C++|运算符重载(1)|为什么要进行运算符重载
写在前面 本篇里面的日期类型加法,先不考虑闰年,平年的天数,每月的天数统一按30天算,那么每一年也就是360天 目录 写在前面 定义 基本数据类型 自定义数据类型 成员函数解决相加问题 Date类+整形 下一篇----运…...
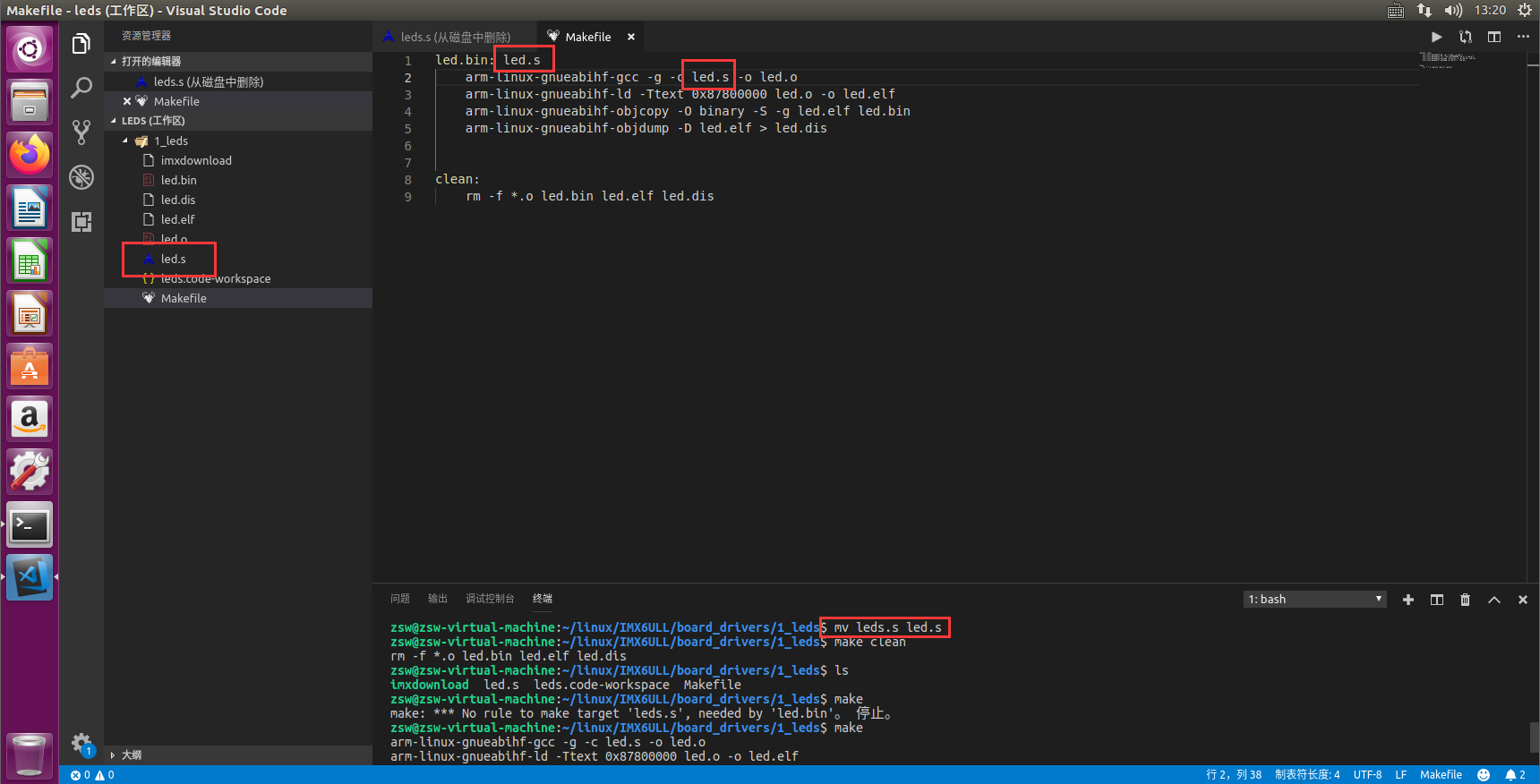
【ARM 裸机】汇编 led 驱动之烧写 bin 文件
1、烧写概念 bin 文件烧写到哪里呢?使用 STM32 的时候烧写到内部 FLASH,6ULL 没有内部 FLASH,是不是就不能烧写呢?不,6ULL 支持 SD卡、EMMC、NAND FLASH、NOR FLASH 等方式启动,在裸机学习的工程中&#x…...

计算机网络之CIDR
快速了解CIDR CIDR 表示的是什么? 单个IP地址:当你看到一个CIDR表示法,如192.168.1.1/32,它表示一个单独的具体IP地址。/32表示所有32位都是网络部分,没有主机部分,因此它指的是单一的IP地址。 一个IP地址…...
【无标题】系统思考—智慧共赢座谈会
第432期JSTO—“智慧共赢座谈会”精彩回顾 我们身处一个快速变化的世界,其中培训和咨询行业也不断面临新的挑战和机遇。为了紧跟这些变革,我们邀请了行业专家与合作伙伴深入探讨在培训、交付和销售过程中遇到的难题。 本次座谈会的亮点之一是我们科学上…...

【Linux C | 多线程编程】线程同步 | 互斥量(互斥锁)介绍和使用
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 ⏰发布时间⏰: 本文未经允许…...

mid_360建图和定位
录制数据 roslaunch livox_ros_driver2 msg_MID360.launch使用fast-lio 建图 https://github.com/hku-mars/FAST_LIO.git 建图效果 使用python做显示 https://gitee.com/linjiey11/mid360/blob/master/show_pcd.py 使用 point_lio建图 https://github.com/hku-mars/Point…...

ThreadX在STM32上的移植:通用启动文件tx_initialize_low_level.s
在嵌入式系统开发中,实时操作系统(RTOS)的选择对于系统性能和稳定性至关重要。ThreadX是一种广泛使用的RTOS,它以其小巧、快速和可靠而闻名。在本文中,我们将探讨如何将ThreadX移植到STM32微控制器上,特别是…...

【python实战】游戏开发——恐龙跳跃小游戏
目录 背景开发环境步骤初步搭建主窗口的实现地平线滑动场景小恐龙跳跃障碍物出现碰撞检测和积分功能优化改为随时可以跳跃源码参考背景 小恐龙沿着地平线前进,遇到障碍物跳跃,躲避障碍物。根据躲避的障碍物进行积分统计。 开发环境 开发环境:Windows10 软件:pycharm 开发…...

成都百洲文化传媒有限公司电商领域的新锐力量
在电商服务领域,成都百洲文化传媒有限公司凭借其专业的服务理念和创新的策略,正逐渐成为行业内的翘楚。这家公司不仅拥有资深的电商团队,还以其精准的市场定位和高效的服务模式,赢得了众多客户的信赖和好评。 一、专业团队&#…...
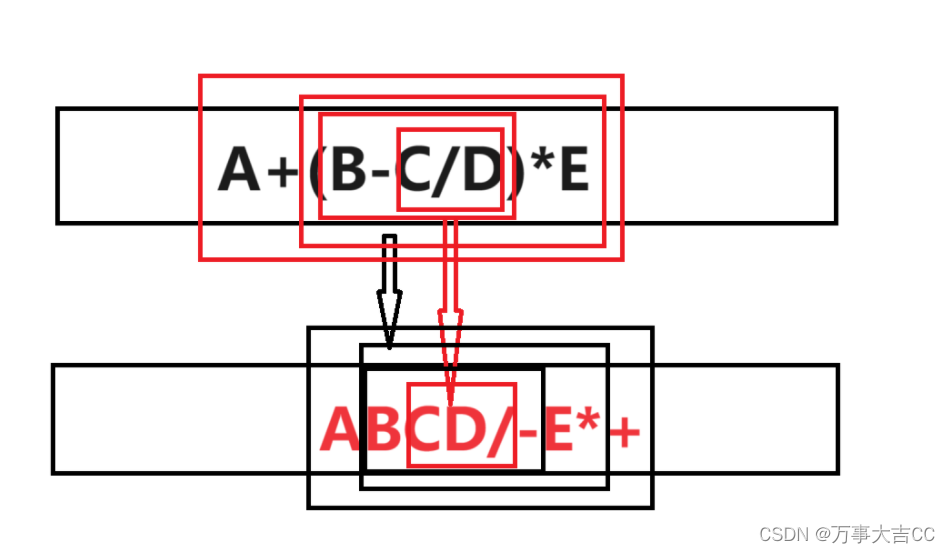
1042: 中缀表达式转换为后缀表达式
解法:直接给算法 创建一个栈和一个空的后缀表达式字符串。 遍历中缀表达式中的每个字符。 如果当前字符是操作数,直接将其添加到后缀表达式字符串中。 如果当前字符是操作符,需要将其与栈顶的操作符进行比较: 如果栈为空&#…...

避免上下文切换--Linux原子函数
在现代操作系统中,原子函数是一类特殊的函数,它们能够保证在并发环境中执行的操作是不可分割的。这意味着一旦一个原子函数开始执行,它的操作会在任何其他线程或进程可以介入之前完全完成。这是通过多种机制实现的,包括硬件支持的…...

塔面板php7.37.4版本不支持ZipArchive手工安装扩展方法
centos 7 宝塔面板安装的PHP7.3和7.4默认已经不带zip扩展,要手工安装zip扩展首先需要安装libzip, yum -y install libzip 方法如下: 宝塔面板php7.3版本在SSH命令行界面执行以下语句: cd /www/server/php/73/src/ext/zip/ /ww…...
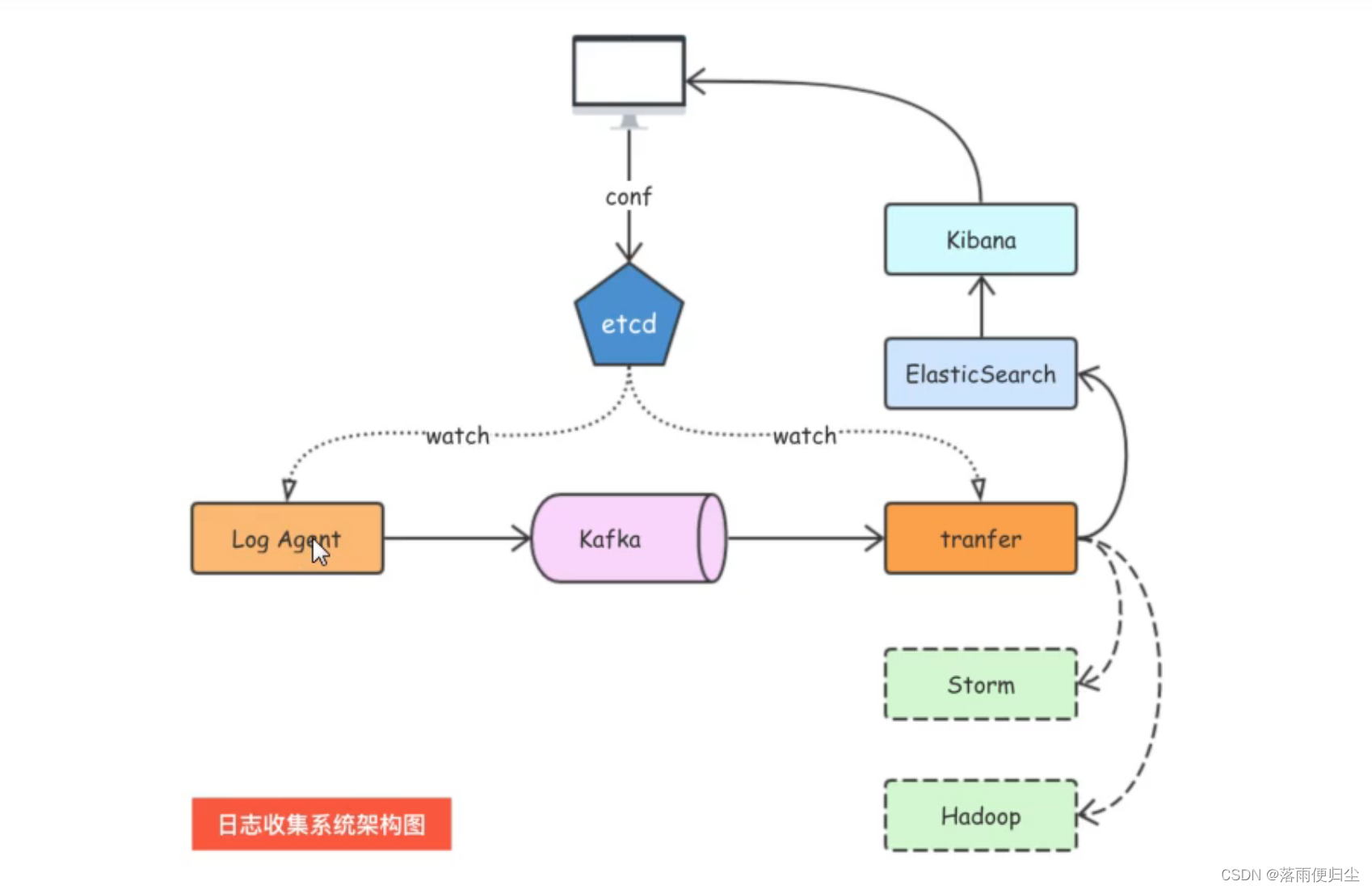
go语言并发实战——日志收集系统(一) 项目前言
-goroutine- 简介 go并发编程的练手项目 项目背景 一般来说业务系统都有自己的日志,当系统出现问题时,我们一般需要通过日志信息来定位与解决问题,当系统机器较少时我们可以登录服务器来查看,但是当系统机器较多时,我们通过服务器来查看日志的成本就会变得很大,…...

Android Studio 之 Intent及其参数传递
一、Intent 显式Intent:通过组件名指定启动的目标组件,比如startActivity(new Intent(A.this,B.class)); 每次启动的组件只有一个~隐式Intent:不指定组件名,而指定Intent的Action,Data,或Category,当我们启动组件时, 会去匹配AndroidManifest.xml相关组件的Intent-…...
【黑马头条】-day06自媒体文章上下架-Kafka
文章目录 今日内容1 Kafka1.1 消息中间件对比1.2 kafka介绍1.3 kafka安装及配置1.4 kafka案例1.4.1 导入kafka客户端1.4.2 编写生产者消费者1.4.3 启动测试1.4.4 多消费者启动 1.5 kafka分区机制1.5.1 topic剖析 1.6 kafka高可用设计1.7 kafka生产者详解1.7.1 同步发送1.7.2 异…...
非线性特征曲线线性化插补器(CODESYS 完整ST代码)
1、如何利用博途PLC和信捷PLC实现非线性特征曲线的线性化可以参考下面文章链接: 非线性特征曲线线性化(插补功能块SCL源代码+C代码)_scl直线插补程序-CSDN博客文章浏览阅读382次。信捷PLC压力闭环控制应用(C语言完整PD、PID源代码)_RXXW_Dor的博客-CSDN博客闭环控制的系列文章…...
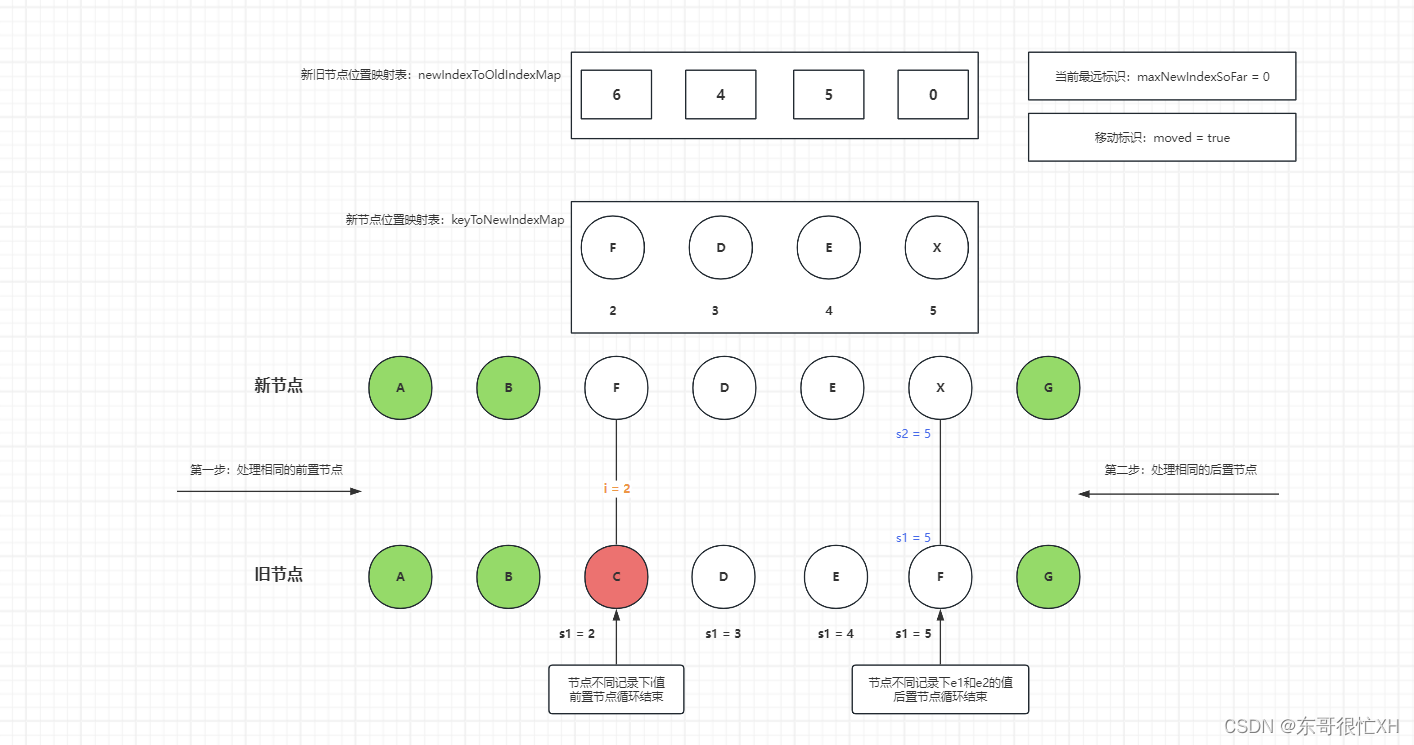
vue3从精通到入门4:diff算法的实现
Vue 3 的 diff 算法相较于 Vue 2 有了一些改进和优化,主要是为了应对更复杂的组件结构和更高的性能需求。 以下是 Vue 3 diff 算法在处理列表更新时的大致步骤: 头头比较:首先,比较新旧列表的头节点(即第一个节点&…...
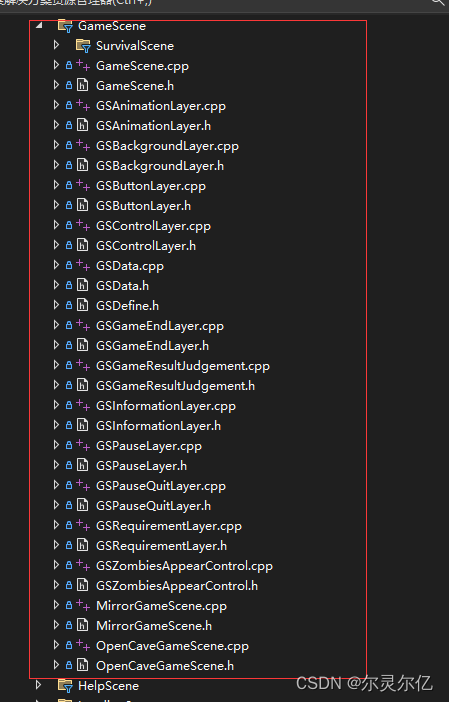
(三)C++自制植物大战僵尸游戏项目结构说明
植物大战僵尸游戏开发教程专栏地址http://t.csdnimg.cn/ErelL 一、项目结构 打开项目后,在解决方案管理器中有五个项目,分别是libbox2d、libcocos2d、librecast、libSpine、PlantsVsZombies五个项目,除PlantsVsZombies外,其他四个…...

【高频电子线路】从抽头到变压器:解锁谐振功率放大器的阻抗变换实战
1. 高频电路中的阻抗匹配为什么重要 我第一次调试射频功放时,烧掉了三个末级晶体管才明白一个道理:高频电路里,阻抗不匹配就像让卡车走自行车道。那个周末实验室里飘着的焦糊味,至今让我对阻抗变换保持敬畏。 在高频环境下&#x…...

工业小白也能懂:5分钟上手Modbus Poll,像聊天一样调试你的设备
工业小白也能懂:5分钟上手Modbus Poll,像聊天一样调试你的设备 想象一下,你刚拿到一台环境监测设备,厂商告诉你它支持Modbus协议。作为软件开发者,你可能对"寄存器地址"、"功能码"这些工业术语一头…...

革命性Vue3跑马灯组件:下一代智能动态展示解决方案
革命性Vue3跑马灯组件:下一代智能动态展示解决方案 【免费下载链接】vue3-marquee A simple marquee component with ZERO dependencies for Vue 3. 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-marquee Vue3-Marquee是一款零依赖的Vue 3跑马灯组件&a…...

拆解彩虹电热毯的IC闭环温控:LM358P芯片与微触发可控硅BY406的电路分析
彩虹电热毯IC闭环温控系统深度解析:从LM358P到BY406的工程智慧 电热毯作为冬季居家必备的取暖设备,其温控系统的可靠性直接关系到用户安全与使用体验。彩虹1503型电热毯采用的IC闭环控制方案,代表了当前中高端电热毯的技术路线。本文将跳出常…...

引用格式错乱导致学术不端?Perplexity官方未公开的4种强制校准法,仅限内部研究员使用!
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用格式设置教程 Perplexity 本身不提供原生的参考文献管理功能,但其生成的回答可导出为 Markdown 或纯文本,便于后续在学术写作中按标准格式(如 APA、ML…...

贾子理论体系:公理化东方智慧与现代科学工程化的认知范式
贾子理论体系:公理化东方智慧与现代科学工程化的认知范式摘要 贾子(本名贾龙栋,笔名Kucius)于2025–2026年间构建以“1-2-3-4-5”公理架构为核心的跨学科认知体系,涵盖思想主权元公理、两大规律、三大定律、四大支柱与…...

产品兼容性实战:硬件与软件设计的平衡艺术与工程策略
1. 产品兼容性:一个永恒的工程与商业困境在硬件开发,尤其是数据采集、测试测量这类领域里,产品经理和工程师们几乎每天都在面对一个看似无解的难题:新产品的功能要向前狂奔,但老用户的兼容性需求却像一根锚,…...

开源游戏串流革命:Sunshine如何重新定义家庭游戏共享体验
开源游戏串流革命:Sunshine如何重新定义家庭游戏共享体验 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在游戏设备日益多样化的今天,你是否曾想过将高性能…...

ProxyClaw住宅代理实战:破解反爬虫,赋能AI智能体与数据工程
1. 项目概述:ProxyClaw,一个为AI与数据工程而生的住宅代理网络 如果你正在构建一个需要从互联网上大规模、稳定抓取数据的AI智能体、自动化机器人或者数据管道,那么“被目标网站封禁”这件事,大概率是你最头疼的日常。无论是电商平…...

学术人必抢的实时检索红利,Perplexity这4个隐藏功能90%研究者至今未启用,错过再等半年!
更多请点击: https://intelliparadigm.com 第一章:Perplexity实时学术搜索怎么用 Perplexity 是一款面向研究者与开发者设计的实时学术搜索引擎,其核心优势在于直接对接 arXiv、PubMed、ACL Anthology、Semantic Scholar 等权威学术数据库&a…...