mysql慢查询:pt-query-digest 分析
"某些SQL语句执行效率慢",这个问题总体上分为两类:
- 出现了慢查询语句
- 某些查询语句没有使用索引
由于数据的写入量非常大,所以要想直接打开慢查询日志来查看到底哪些语句有问题几乎是不可能的,因为日志的刷新速度太快了,于是想起了pt工具,pt工具中的pt-query-digest比较擅长解决这个问题。
子曰:“工欲善其事,必先利其器”
善于利用好的性能分析工具可以使运维效率事半功倍。
pt-query-digest 属于 Percona Toolkit 工具集中较为常用的工具,用于分析 slow log,可以分析 MySQL 数据库的 binary log 、 general log 日志,同时也可以使用 show processlist 或从 tcpdump 抓取的 MySQL 协议数据来进行分析。
# wget https://www.percona.com/downloads/percona-toolkit/3.2.1/binary/redhat/7/x86_64/percona-toolkit-3.2.1-1.el7.x86_64.rpm
# yum -y localinstall percona-toolkit-3.2.1-1.el7.x86_64.rpm
根据时间点,这里我们用alert_time来表示,那么导致报警的SQL很有可能在这个时间点附近。
这里用到Linux中的sed命令来把日志先截取出来,sed命令的使用方法如下:
sed -n '/2019-02-27T01:55:04/,/2019-02-27T02:02:04/p' /path/to/mysql-slow.log > mysql-slow.log.tmp
这个命令将格林尼治时间01:55:04到02:05:04的慢日志打印出来,重定向到一个mysql-slow.log.tmp的文件中,需要注意的是格林尼治时间加上8小时就是北京时间。
发现这个mysql-slow.log.tmp也比较大,所以我又重新把时间定格在60s之内,这样得到了一个比较小的tmp文件,这个时候,就该pt工具上场了。
如果不想用sed命令,其实pt工具本身也自带一些参数,可以通过--since参数和 --until参数来把日志中固定时间段的日志打印出来:
pt-query-digest --since='2019-02-27 09:30:00' --until=2019-02-27 09:31:00' /path/to/mysql-slow.log > mysql-slow.log.tmp
用pt工具分析慢日志的结果如下,总体分为三个部分。
第一部分是总体统计结果,如下:
该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 480ms user time, 10ms system time, 26.18M rss, 206.09M vsz
工具执行时间
# Current date: Wed Feb 27 10:51:36 2019
主机名
# Hostname:
被分析的文件名
# Files: yyz.tmp
语句总数量,唯一的语句数量,QPS,并发数
# Overall: 1.00k total, 32 unique, 8.45 QPS, 0.02x concurrency ___________
日志记录的时间范围
# Time range: 2019-02-27T02:34:04 to 2019-02-27T02:36:03
属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
语句执行时间
# Exec time 2s 97us 515ms 2ms 5ms 21ms 799us
锁占用时间
# Lock time 85ms 32us 448us 84us 131us 32us 80us
发送到客户端的行数
# Rows sent 237.45k 0 2.36k 241.93 1.96k 551.62 0
select语句扫描的行数
# Rows examine 3.53M 0 536.64k 3.60k 4.07k 33.64k 685.39
发送改变的行数(update,delete,insert)语句
# Rows affecte 0 0 0 0 0 0 0
发送多少bytes的查询结果集
# Bytes sent 65.63M 0 1.31M 66.87k 753.18k 221.17k 346.17
查询语句的字符数
# Query size 107.70k 56 303 109.74 223.14 48.96 92.72
第二部分是查询分组的统计结果,包含了一些花费时间比较长的SQL语句,如下:
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xCB9AD73BDFEDCAD9 0.9584 42.9% 2 0.4792 0.01 UPDATE SELECT dic_push_dao_assistant tem_selectAssDAO
# 2 0x2AEA2001E6ED5A86 0.3696 16.5% 288 0.0013 0.00 SELECT dic_alert_alarm_msg
# 3 0xE2874B8D2170C494 0.2174 9.7% 18 0.0121 0.00 SELECT dic_fsm_cccd_info
# 4 0xEB9DC21456584EF6 0.0919 4.1% 18 0.0051 0.00 SELECT dic_fsm_info
# 5 0xF3A68A619C5E8B35 0.0906 4.1% 18 0.0050 0.00 SELECT dic_fsm_info
# 6 0x5C1B79C191BDA497 0.0725 3.2% 118 0.0006 0.00 SELECT original_dic_fsm_info
# 7 0x5DB1B21F7EEC9EF4 0.0597 2.7% 18 0.0033 0.00 SELECT dic_fsm_config_info
# 8 0xA88FE251DC1A981A 0.0584 2.6% 18 0.0032 0.00 SELECT dic_fsm_config_info
# 9 0x69E716E15CCC4A0F 0.0539 2.4% 118 0.0005 0.00 SELECT original_dic_fsm_config_info
# 10 0x0A6FC9E2C8542E17 0.0476 2.1% 18 0.0026 0.00 SELECT dic_cal_expression
# 11 0x7C0C6F0CFBADF271 0.0427 1.9% 19 0.0022 0.00 SELECT dic_cal_expression
# 12 0x872EBAFA1A73057B 0.0311 1.4% 19 0.0016 0.00 SELECT dic_guide_list_info
# 13 0xE73D713D87E945FC 0.0232 1.0% 102 0.0002 0.00 SELECT dic_alert_refresh
# 14 0x194B14BA91941B81 0.0204 0.9% 18 0.0011 0.00 SELECT dic_fsm_map_relation
# MISC 0xMISC 0.0960 4.3% 213 0.0005 0.0 <18 ITEMS>
Rank:所有语句的排名,默认按查询时间降序排列Query ID:语句的IDResponse:总的响应时间time:该查询在本次分析中总的时间占比calls:执行次数,即本次分析总共有多少条这种类型的查询语句R/Call:平均每次执行的响应时间V/M:响应时间Variance-to-mean的比率
可以看到,有一些语句一秒钟之内call了大概288次,并发量算是比较高了。
还有第一行的update语句大概占用了将近一半的运行时间,但是我们可以看到,这个响应时间是很短的,几乎都在1s之内,按道理不会出现在慢查询日志上面。
之所以这些执行时间在1s之内的SQL语句会出现在慢查询日志上面,是因为MySQL中开启了一个参数,如下:
1 mysql> show variables like '%index%';2+----------------------------------------+--------------------------------------------+3| Variable_name | Value |4+----------------------------------------+--------------------------------------------+5| eq_range_index_dive_limit | 200 |6| expand_fast_index_creation | OFF |7| innodb_adaptive_hash_index | ON |8| innodb_adaptive_hash_index_parts | 8 |9| innodb_cmp_per_index_enabled | OFF |
10| log_bin_index | /path/to/mysqlbin.index |
11| log_queries_not_using_indexes | ON |
12| log_throttle_queries_not_using_indexes | 0 |
13| performance_schema_max_index_stat | -1 |
14| relay_log_index | /path/to/slave-relay-bin.index |
15+----------------------------------------+--------------------------------------------+
1610 rows in set (0.00 sec)
也就是第11行的log_queries_not_using_indexes参数,这个参数开启的话,MySQL会默认将没有使用index的SQL语句也记录在慢日志中,如果数据量比较小的话,这些SQL语句看着没什么大的问题,一旦表中的数据变的很大的时候,这些SQL极有可能出现性能问题。
第三部分是第二部分查出来的每一个SQL语句的详细统计结果。如下:
1# Query 1: 0.03 QPS, 0.02x concurrency, ID 0xCB9AD73BDFEDCAD9 at byte 604302# This item is included in the report because it matches --limit.3# Scores: V/M = 0.014# Time range: 2019-02-27T02:34:32 to 2019-02-27T02:35:325# Attribute pct total min max avg 95% stddev median6# ============ === ======= ======= ======= ======= ======= ======= =======7# Count 0 28# Exec time 42 958ms 443ms 515ms 479ms 515ms 51ms 479ms9# Lock time 0 254us 116us 138us 127us 138us 15us 127us
10# Rows sent 0 0 0 0 0 0 0 0
11# Rows examine 29 1.05M 536.64k 536.64k 536.64k 536.64k 0 536.64k
12# Rows affecte 0 0 0 0 0 0 0 0
13# Bytes sent 0 0 0 0 0 0 0 0
14# Query size 0 252 126 126 126 126 0 126
15# String:
16# Databases tgp_db
17# Hosts 127.0.0.1
18# Last errno 0
19# Stored routi tgp_db.PCall_TGP_GetAssDAO
20# Users dba_admin
21# Query_time distribution
22# 1us
23# 10us
24# 100us
25# 1ms
26# 10ms
27# 100ms ################################################################
28# 1s
29# 10s+
30# Tables
31# SHOW TABLE STATUS FROM `tgp_db` LIKE 'dic_push_dao_assistant'\G
32# SHOW CREATE TABLE `tgp_db`.`dic_push_dao_assistant`\G
33# SHOW TABLE STATUS FROM `tgp_db` LIKE 'tem_selectAssDAO'\G
34# SHOW CREATE TABLE `tgp_db`.`tem_selectAssDAO`\G
35update `dic_push_dao_assistant`
36 set `state` = 1
37 where `id` in
38 (
39select `id`
40 from `tem_selectAssDAO`
41 )\G
42# Converted for EXPLAIN
43# EXPLAIN /*!50100 PARTITIONS*/
44select `state` = 1 from `dic_push_dao_assistant` where `id` in
45 (
46select `id`
47 from `tem_selectAssDAO`
48 )\G
这里给出的每一个语句执行的时候的一些信息,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应Databases:数据库名Users:各个用户执行的次数(占比)Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。Tables:查询中涉及到的表
通过上面的SQL语句分析,可以看出查询的时候是把update操作转化成了select操作,然后这个select操作里面扫描了tem_selectAssDAO全表,所以导致SQL的执行时间比较长,如果表中的数据量很大的话,这无疑是一个慢SQL。
pt-query-digest常用方法:
1.直接分析慢查询文件:
pt-query-digest slow.log > slow_report.log2.分析最近12小时内的查询:
pt-query-digest --since=12h slow.log > slow_report2.log3.分析指定时间范围内的查询:
pt-query-digest slow.log --since '2017-01-07 09:30:00' --until '2017-01-07 10:00:00' > slow_report3.log4.分析指含有select语句的慢查询
pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' slow.log > slow_report4.log5针对某个用户的慢查询
pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log > slow_report5.log6.查询所有全表扫描或full join的慢查询
pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' slow.log > slow_report6.log7.把查询保存到query_review表pt-query-digest --user=root -password=abc123 --review h=localhost,D=test,t=query_review --create-review-table slow.log8.分析binlog
mysqlbinlog mysql-bin.000093 > mysql-bin000093.sql
pt-query-digest --type=binlog mysql-bin000093.sql > slow_report10.log9.分析general log
pt-query-digest --type=genlog localhost.log > slow_report11.log
参考
MySQL 5.7 Reference Manual / The Slow Query Log
https://dev.mysql.com/doc/refman/5.7/en/slow-query-log.html
pt-query-digest - Analyze MySQL queries from logs, processlist, and tcpdump
https://docs.percona.com/percona-toolkit/pt-query-digest.html
MySQL日常运维之percona-toolkit工具pt-query-digest
https://www.modb.pro/db/42424
pt-query-digest查询日志分析工具
http://t.zoukankan.com/hfclytze-p-pt-query-digest.html
相关文章:

mysql慢查询:pt-query-digest 分析
"某些SQL语句执行效率慢",这个问题总体上分为两类: 出现了慢查询语句某些查询语句没有使用索引 由于数据的写入量非常大,所以要想直接打开慢查询日志来查看到底哪些语句有问题几乎是不可能的,因为日志的刷新速度太快了…...

git的使用整合
git的下载和安装暂时不论述了,将git安装后会自动配置环境变量,所以环境变量也不需要配置。 一、初始化配置 打开git bash here(使用linux系统下运行的口令),弹出一个类似于cmd的窗口。 (1)配置属性 git config --glob…...

XCPC第九站———背包问题!
1.01背包问题 我们首先定义一个二维数组f,其中f[i][j]表示在前i个物品中取且总体积不超过j的取法中的最大价值。那么我们如何得到f[i][j]呢?我们运用递推的思想。由于第i个物品只有选和不选两种情况,当不选第i个物品时,f[i][j]f[i…...

【软考 系统架构设计师】论文范文④ 论基于构件的软件开发
>>回到总目录<< 文章目录 论基于构件的软件开发范文摘要正文论基于构件的软件开发 软件系统的复杂性不断增长、软件人员的频繁流动和软件行业的激烈竞争迫使软件企业提高软件质量、积累和固化知识财富,并尽可能地缩短软件产品的开发周期。 集软件复用、分布式对…...

spring-integration-redis中分布式锁RedisLockRegistry的使用
pom依赖:<!-- redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.integ…...
城市通电(prim算法)
acwing3728 蓝桥杯集训每日一题 平面上遍布着 n 座城市,编号 1∼n。 第 i 座城市的位置坐标为 (xi,yi) 不同城市的位置有可能重合。 现在要通过建立发电站和搭建电线的方式给每座城市都通电。 一个城市如果建有发电站,或者通过电线直接或间接的与建…...

【动态规划】
动态规划1引言题目509. 斐波那契数70. 爬楼梯746. 使用最小花费爬楼梯小结53. 最大子数组和结语引言 蓝桥杯快开始了啊,自从报名后还没认真学过算法有(>﹏<)′,临时抱一下佛脚,一起学学算法。 题目 509. 斐波那契数 斐波那契数 &am…...

秒懂算法 | DP概述和常见DP面试题
动态(DP)是一种算法技术,它将大问题分解为更简单的子问题,对整体问题的最优解决方案取决于子问题的最优解决方案。本篇内容介绍了DP的概念和基本操作;DP的设计、方程推导、记忆化编码、递推编码、滚动数组以及常见的DP面试题。 01、DP概述 1. DP问题的特征 下面以斐波那…...
)
【C++提高编程】C++全栈体系(二十五)
C提高编程 第四章 STL- 函数对象 一、函数对象 1. 函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象函数对象使用重载的()时,行为类似函数调用,也叫仿函数 本质: 函数对象(仿函数)是一个类&…...

【云原生】k8s核心技术—集群安全机制 Ingress Helm 持久化存储-20230222
文章目录一、k8s集群安全机制1. 概述2. RBAC——基于角色的访问控制二、Ingress三、Helm1. 引入2. 使用功能Helm可以解决哪些问题3. 介绍4. 3个重要概念5. helm 版本变化6. helm安装及配置仓库7. 使用helm快速部署应用8. 自己创建chart9. 实现yaml高效复用四、持久化存储1.nfs—…...
【Linux】实现简易的Shell命令行解释器
大家好我是沐曦希💕 文章目录一、前言二、准备工作1.输出提示符2.输入和获取命令3.shell运行原理4.内建命令5.替换三、整体代码一、前言 前面学到了进程创建,进程终止,进程等待,进程替换,那么通过这些来制作一个简易的…...

再获认可!腾讯安全NDR获Forrester权威推荐
近日,国际权威研究机构Forrester发布最新研究报告《The Network Analysis And Visibility Landscape, Q1 2023》(以下简称“NAV报告”),从网络分析和可视化(NAV)厂商规模、产品功能、市场占有率及重点案例等…...
代码审计之旅之百家CMS
前言 之前审计的CMS大多是利用工具,即Seay昆仑镜联动扫描出漏洞点,而后进行审计。感觉自己的能力仍与零无异,因此本次审计CMS绝大多数使用手动探测,即通过搜索危险函数的方式进行漏洞寻找,以此来提升审计能力…...
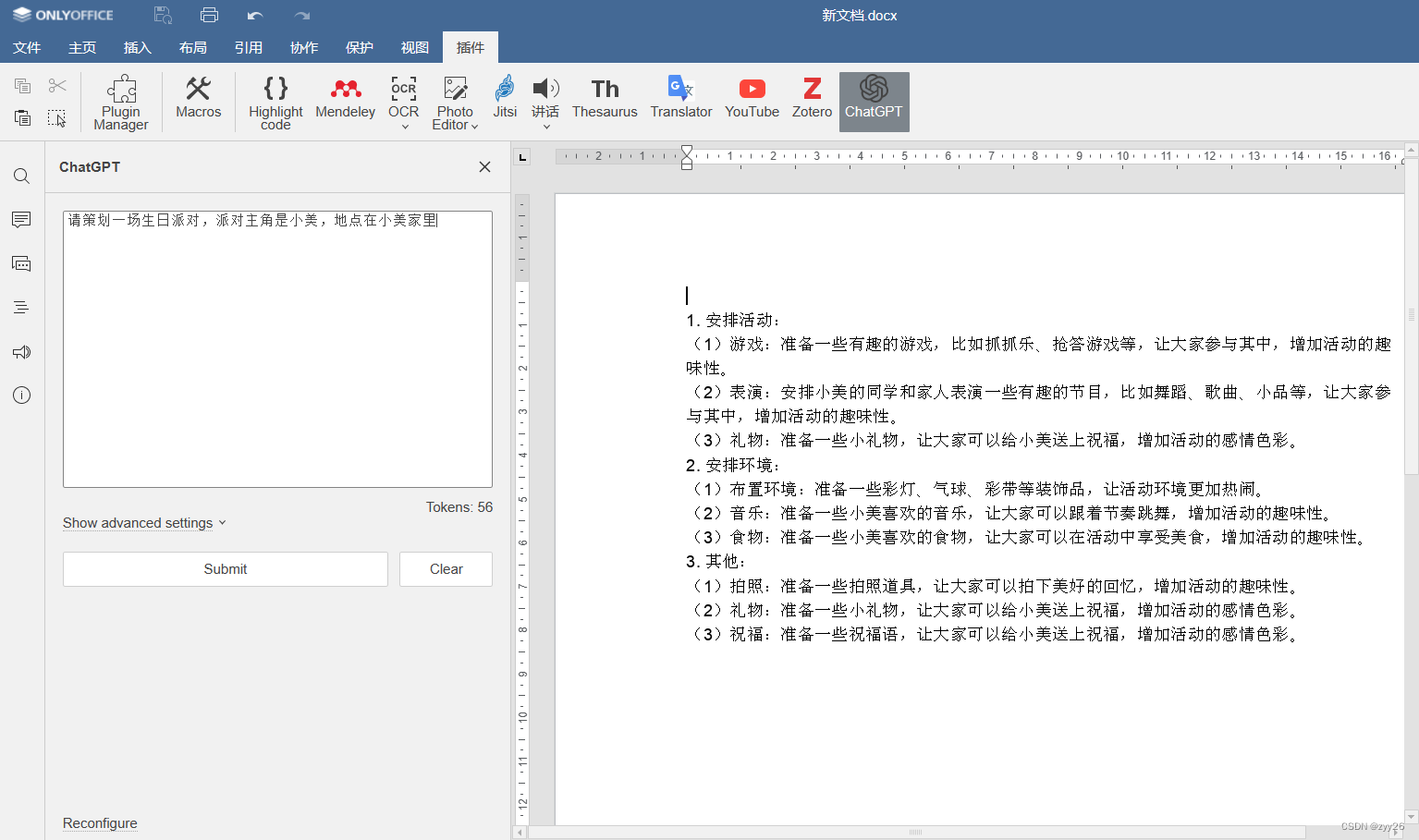
ONLYOFFICE中利用chatGPT帮助我们策划一场生日派对
近日,人工智能chatGPT聊天机器人爆火,在去年年底发布后,仅仅两个月就吸引了全球近一亿的用户,成为史上最快的应用消费程序,chatGPT拥有强大的学习和交互能力 可以被学生,教师,上班族各种职业运…...
)
Java面试题-线程(一)
在典型的 Java 面试中, 面试官会从线程的基本概念问起, 如:为什么你需要使用线程,如何创建线程,用什么方式创建线程比较好(比如:继承 thread 类还是调用 Runnable 接口),…...

一篇普通的bug日志——bug的尽头是next吗?
文章目录[bug 1] TypeError: method object is not subscriptable[bug 2] TypeError: unsupported format string passed to numpy.ndarray.__format__[bug 3] ValueError:Hint: Expected dtype() paddle::experimental::CppTypeToDataType<T>::Type()[bug 4] CondaSSLE…...

Vue 3 第八章:Watch侦听器
文章目录Watch侦听器1. 基础概念1.1. Watch的基本用法例子1:监听单个ref的值,直接监听例子2:监听多个ref的值,采用数组形式例子3:深度监听例子4:监听reactive响应式对象单一属性,采用回调函数的…...
GlassFish的安装与使用
一、产品下载与安装glassfish下载地址:https://download.oracle.com/glassfish/5.0.1/release/index.html下载后解压即完成安装,主要目录说明:bin目录:为asadmin命令所在目录。glassfish为主目录:glassfish\bin目录为命…...
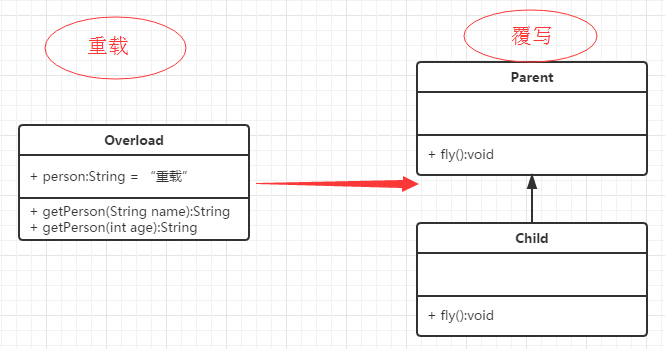
【java】Java 重写(Override)与重载(Overload)
文章目录重写(Override)方法的重写规则Super 关键字的使用重载(Overload)重载规则实例重写与重载之间的区别总结重写(Override) 重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写! 重写的好处在于…...
OpenCV-PyQT项目实战(12)项目案例08:多线程视频播放
欢迎关注『OpenCV-PyQT项目实战 Youcans』系列,持续更新中 OpenCV-PyQT项目实战(1)安装与环境配置 OpenCV-PyQT项目实战(2)QtDesigner 和 PyUIC 快速入门 OpenCV-PyQT项目实战(3)信号与槽机制 …...

跨境社媒账号做不稳 很多时候不是内容不够好而是气质不够稳定
很多团队做跨境社媒时,最容易把注意力集中在“内容创意”上。 选题够不够新,切口够不够巧,视频开头能不能抓住人,标题会不会让人点开,这些当然都重要。但真正做久了之后会发现,一个账号能不能长期跑起来&am…...
)
别再死记硬背!用Python+OpenCV实战推导相机内外参与FOV公式(附代码)
用PythonOpenCV实战推导相机内外参与FOV公式:从代码中理解数学本质 在计算机视觉领域,相机参数的数学推导常常让开发者陷入公式记忆的困境。本文提供一种全新的学习路径——通过Python代码动态模拟相机成像过程,将抽象的数学公式转化为可交互…...

从“能用”到“可靠”:基于SonarQube与Jenkins的代码质量防线构建实战
当测试覆盖率不再只是一串数字,而是合并代码前的“一票否决权” 1. 为什么你的“质量门禁”只是个摆设? 在很多团队的CI/CD流水线中,SonarQube的集成往往停留在“能跑就行”的阶段。流水线里确实有代码扫描这一步,日志里也打印出…...

品牌AI印相失效90%源于这7个参数误设,可口可乐级商业输出必须校准的4项色彩/构图硬指标
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coca Cola印相失效的底层归因诊断 Midjourney v6 及后续版本中,针对品牌标识(如 Coca-Cola 经典红白波浪字体与动态弧线)的“印相”(prompt i…...

从键值对到时序数据:FlashDB在智能家居传感器上的两种实战用法
从键值对到时序数据:FlashDB在智能家居传感器上的两种实战用法 清晨6点,卧室的温湿度传感器悄然启动。它需要在电池耗尽前完成三项任务:读取当前环境数据、检查预设报警阈值、通过LoRaWAN网络上传信息。当网络不稳定时,这些数据必…...

AI营销技能库:模块化设计提升Claude Code与智能体工作流效率
1. 项目概述:一个为AI营销工作流设计的技能库如果你正在用Claude Code、Cursor这类AI编程工具做营销、内容创作或增长相关的工作,并且感觉每次都要花大量时间写重复的提示词,或者希望团队能有一套标准化的AI工作流程,那么这个名为…...
)
Google Docs接入Gemini后,这6类高频写作场景效率飙升210%(附可复制Prompt库)
更多请点击: https://intelliparadigm.com 第一章:Gemini深度集成Google Docs的底层机制解析 Gemini 与 Google Docs 的深度集成并非简单的 API 调用叠加,而是依托 Google 的统一 AI 基础设施(AISI)和文档实时协作协议…...

Kimi融资超376亿商业化成熟,DeepSeek拟募资500亿估值超515亿美元,谁能笑到最后?
Kimi是融资最多的创业派,DeepSeek是估值最高的技术派,前者拼商业,后者拼“国运”。 最近,被并称为“中国AI开源双子星”的Kimi(月之暗面)和DeepSeek(深度求索)频繁刷屏。先是新模型接…...

AI智能体记忆系统设计:分层架构与向量化检索实战
1. 项目概述:一个为AI智能体设计的记忆系统最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的痛点:如何让这些智能体拥有“记忆”?不是那种简单的对话历史记录,而是更接近人类工作记忆和…...

孤舟笔记 IO 与网络编程篇五 网络编程你真的懂吗?从Socket到TCP连接全解析
文章目录一、先说结论:网络编程核心事实二、TCP 编程:三次握手的 Socket 视角三、UDP 编程:无连接的数据报四、服务端线程模型演进模型一:一连接一线程(最原始)模型二:线程池(改进&a…...