【多模态检索】Coarse-to-Fine Visual Representation
快手文本视频多模态检索论文
论文:Towards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning
链接:https://arxiv.org/abs/2401.00701
摘要
近些年,基于CLIP的text-to-video检索方法广为流行,但大多从视觉文本对齐方法上演进。按照原文:design a heavy fusion block for sentence (words)-video (frames) interaction,而忽视了复杂度和检索效率。
- 升级点
- 本文采用多粒度视觉特征学习,捕获从抽象到具体的视觉内容。Multi-granularity visual feature learning, ensuring the model’s comprehensiveness in capturing visual content features spanning from abstract to detailed levels during the training phase.
- 设计两阶段检索框架,优点在于 balances the coarse and fine granularity of retrieval content.
- 在训练阶段,设计一个parameter-free text-gated interaction block (TIB) 模块用于细粒度视觉表征学习并嵌入一个额外的 Pearson Constraint来优化跨模态表示学习。
- 在检索阶段,使用粗粒度视觉表征快速检索topk结果,然后使用细粒度视觉表示rerank(recall-then-rerank pipeline)。
- 效果:nearly 50 times faster
- 难点:对比原始图像文本匹配任务(包含较少的视觉信息),聚合整个视频表示易导致过度抽象以及误导。在视觉文本检索任务中,一个句子通常只描述一个感兴趣的视频子区域。现有工作很多不够合理与成熟,衍生出很多CLIP的变体,大体分为两个方向。例如CLIP4Clip,仅仅是将预训练的CLIP简单进行MeanPooling就从image-text迁移到video-text领域。
- 设计a heavy fusion block来加强视觉和文本的交互以达到模态间更好地对齐的目的;
- 优化text-driven video representations,keep multi-grained features including video-level and frame-level for brute-force search。
- 近些年方法虽然有效果提升,但却需要巨大的计算成本(text-video similarity calculation)。
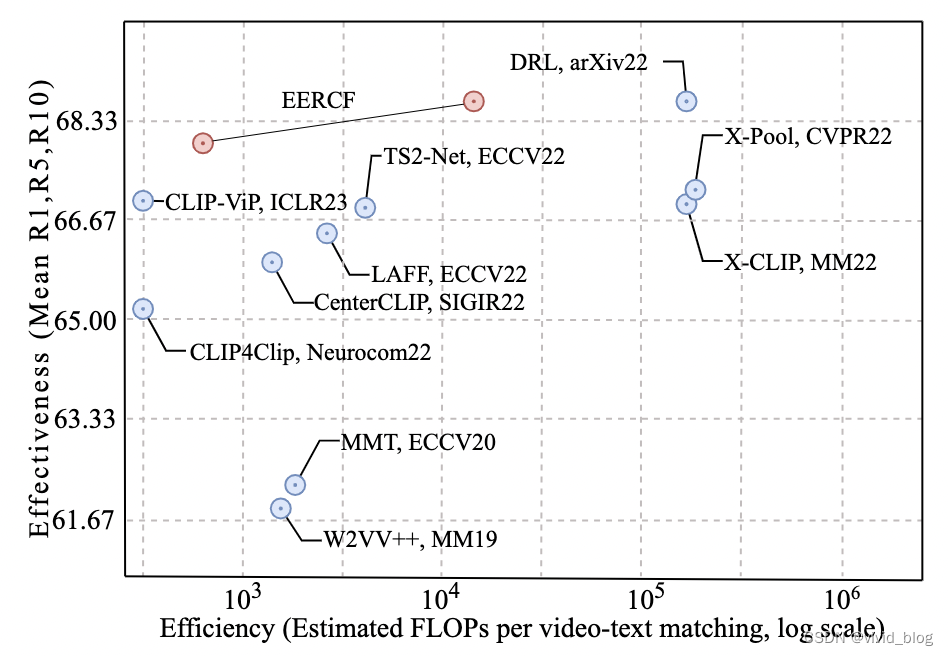
过于细粒度的计算可能会放大视频局部噪声,降低检索效率。需要在有效性和效率上做trade-off。
方法
-
整体架构
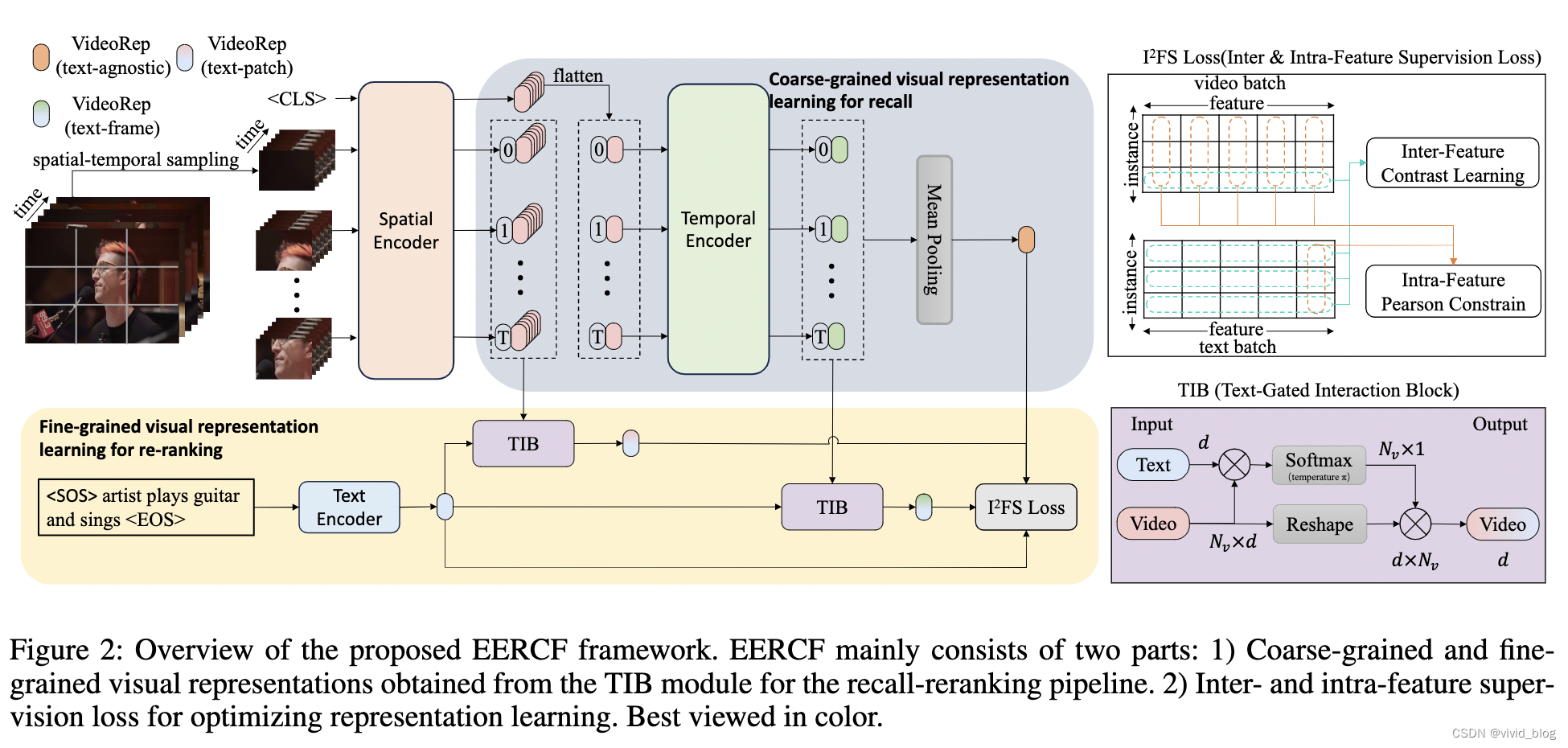
-
特征输入:a video v consists ofT sequential frames {f1, f2, …, fT |fi ∈ RH ×W ×C};each frame is divided into N patches {f 1i , f 2i , …, f N i |f n i ∈RP×P×C} with P × P size;text t。
-
模型结构
-
视觉端
- a spatial encoder (SE) with 12 transformer layers initialized by the public CLIP checkpoints
- a temporal encoder (TE) with 4 transformer layers to model temporal relationship among sequential frames, [CLS] enocde patch to frame(0th patch feature represent frame)
- a MeanPooling layer (MP) to aggregate all frame-level features into a text-agnostic feature vector
注:patch 和 frame都包含位置编码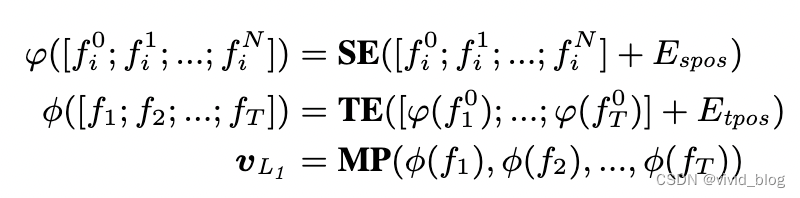
-
视觉文本交互 – Text-Gated Interaction Block
- 简单的attention机制,π is the temperature,决定多少视觉信息被保留(A small value of π only emphasizes those most relevant visual cues, while a large value pays attention to much more visual cues.)
- 未引入任何参数
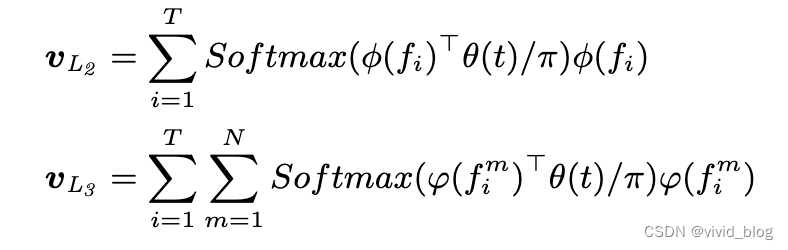
-
-
损失函数(Inter- and Intra-Feature Supervision Loss)
- 数据形式:Each batch of B video-text pairs,in each pair, the text tb is a corresponding description of the video vb
- Contrastive Loss for Inter-Feature Supervision - infoNCE loss,batch内其他为负样本
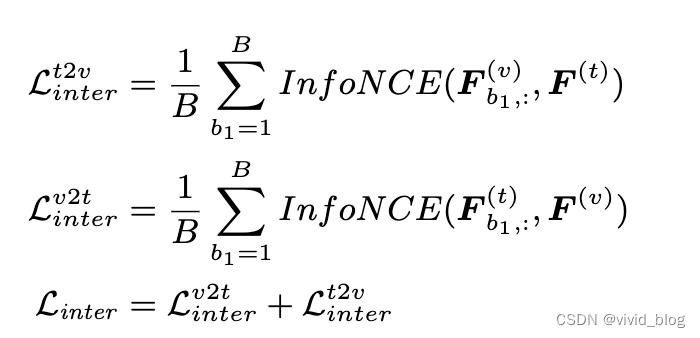
- Pearson Constraint for Intra-Feature Supervision
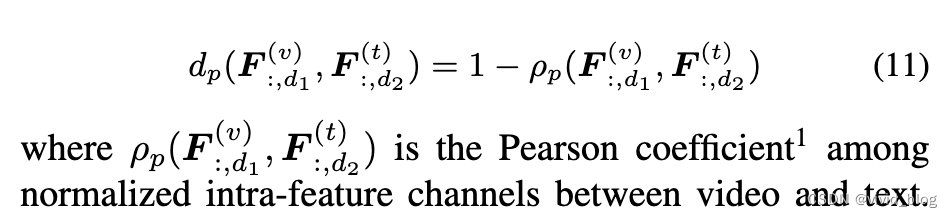

- Total Loss

-
检索中的两阶段策略 - To balance the efficiency and effectiveness
- 使用VL1作为tok召回阶段特征
- rerank这些召回结果用VL2和VL3
- 两阶段的优点:效率提升 & 过于细粒度的特征可能会导致对局部噪声的过度关注。
实验
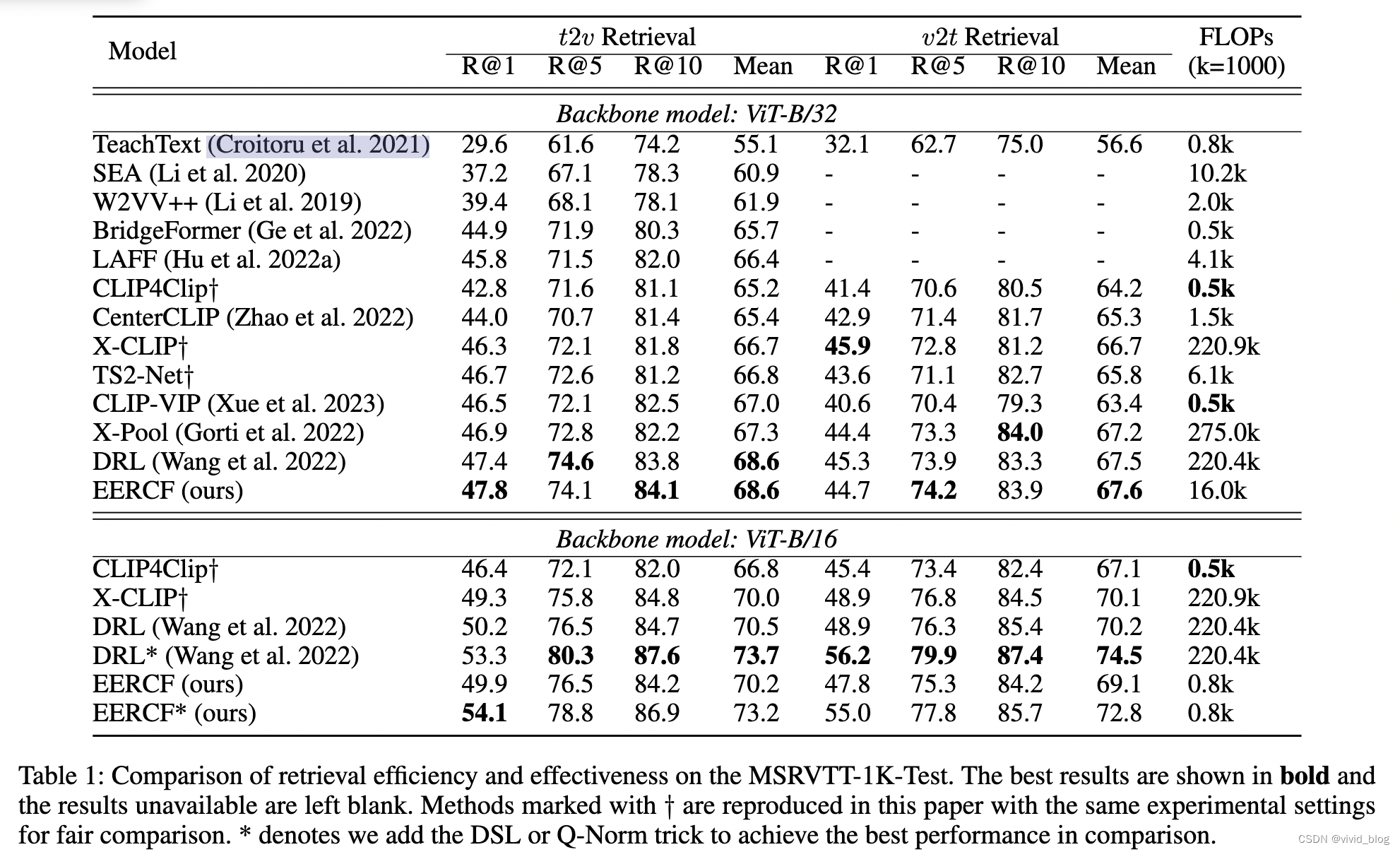
主实验:
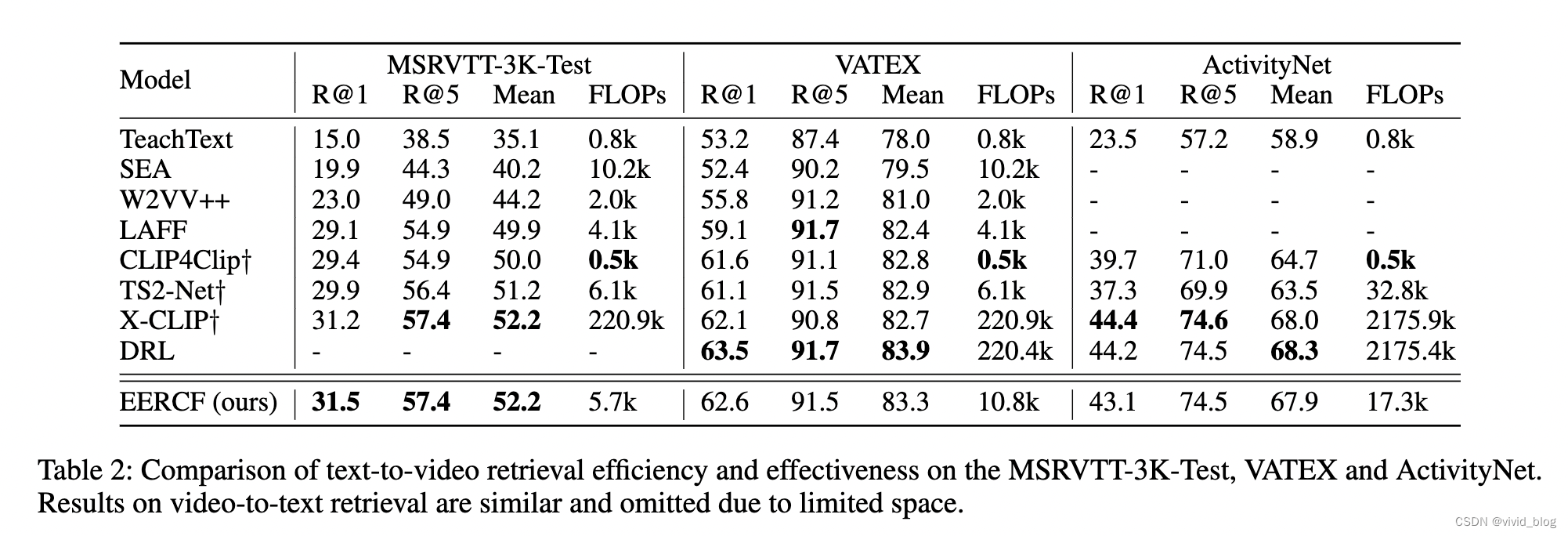
其他数据集:
消融实验:
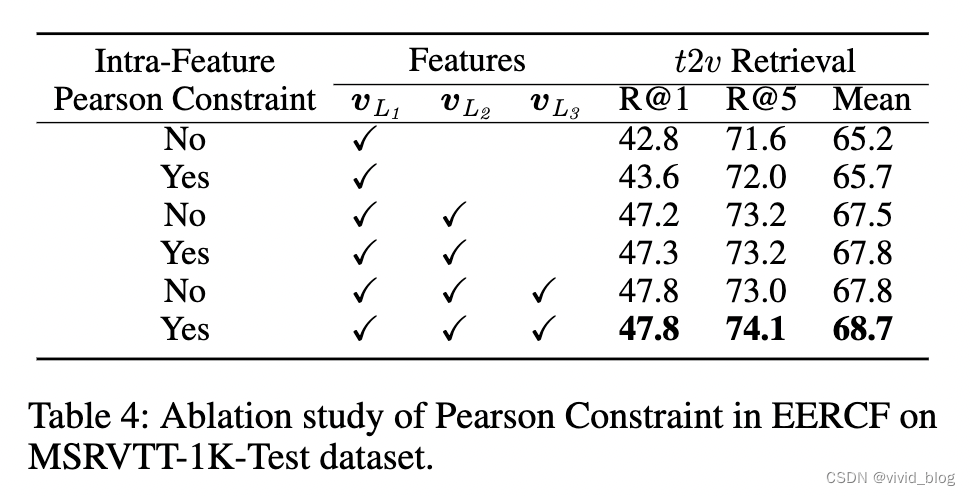
可以看到去掉帧粒度的文本交互特征指标下降明显。当去掉所有文本交互特征时,只使用视觉特征会引入很多噪声(引入喝多与文本无关的特征),mislead the matching process。
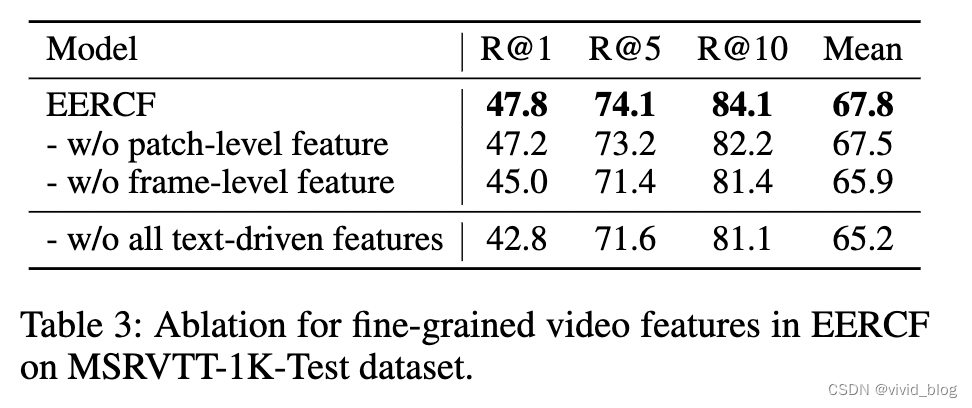
top100的下降可能是由于重新排序阶段过度关注视觉局部细节,增加 top-k 引入的噪声会对重新排序阶段造成更多的干扰
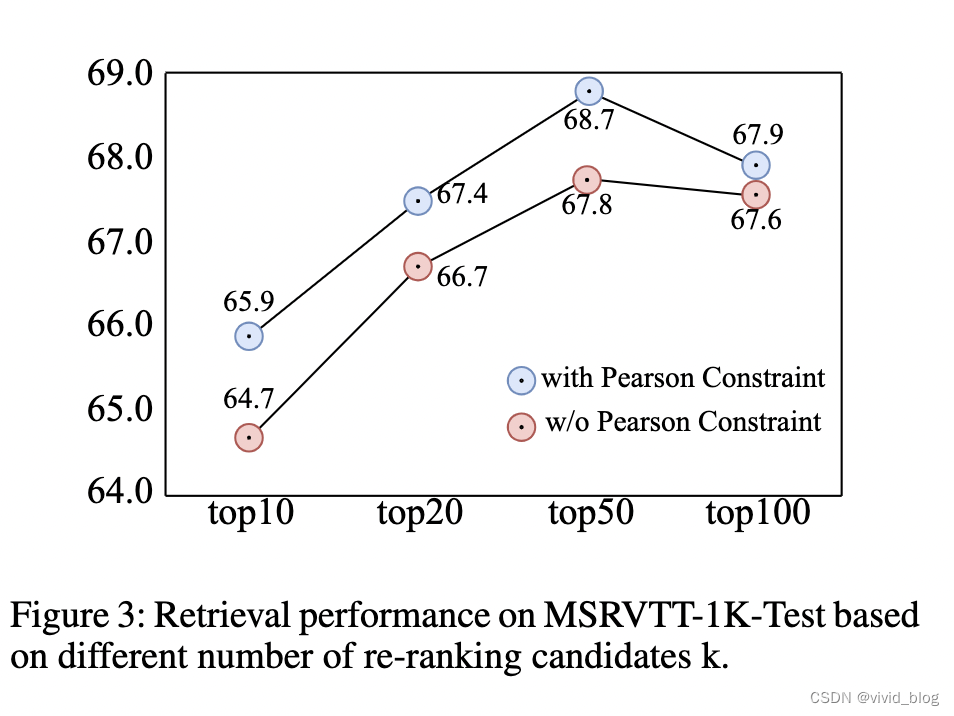
Re-ranking 消融
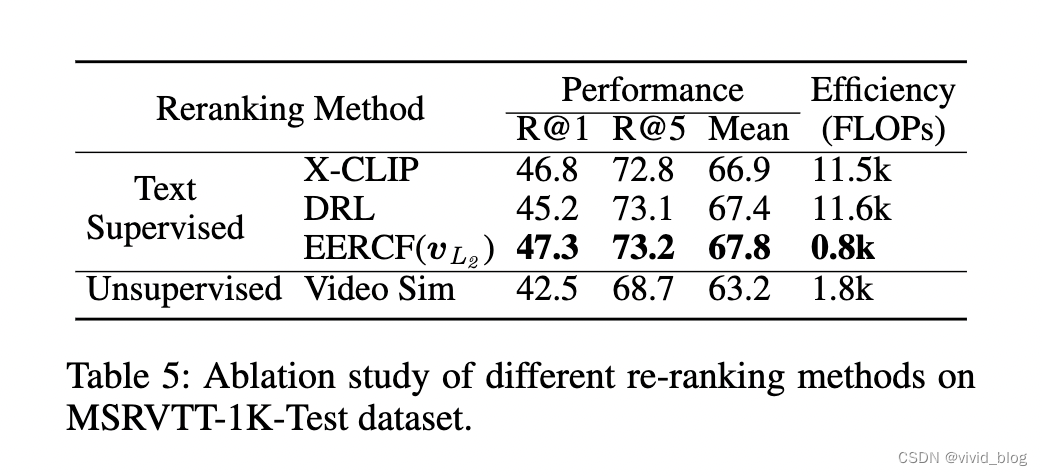
Intra-Feature Pearson Constraint消融
Visualization of Coarse-to-Fine Retrieval

相关文章:
【多模态检索】Coarse-to-Fine Visual Representation
快手文本视频多模态检索论文 论文:Towards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning 链接:https://arxiv.org/abs/2401.00701 摘要 近些年,基于CLIP的text-to-video检索方法…...
VRRP——虚拟路由冗余协议
什么是VRRP 虚拟路由冗余协议VRRP(Virtual Router Redundancy Protocol)是一种用于提高网络可靠性的容错协议。 通过VRRP,可以在主机的下一跳设备出现故障时,及时将业务切换到备份设备,从而保障网络通信的连续性和可…...
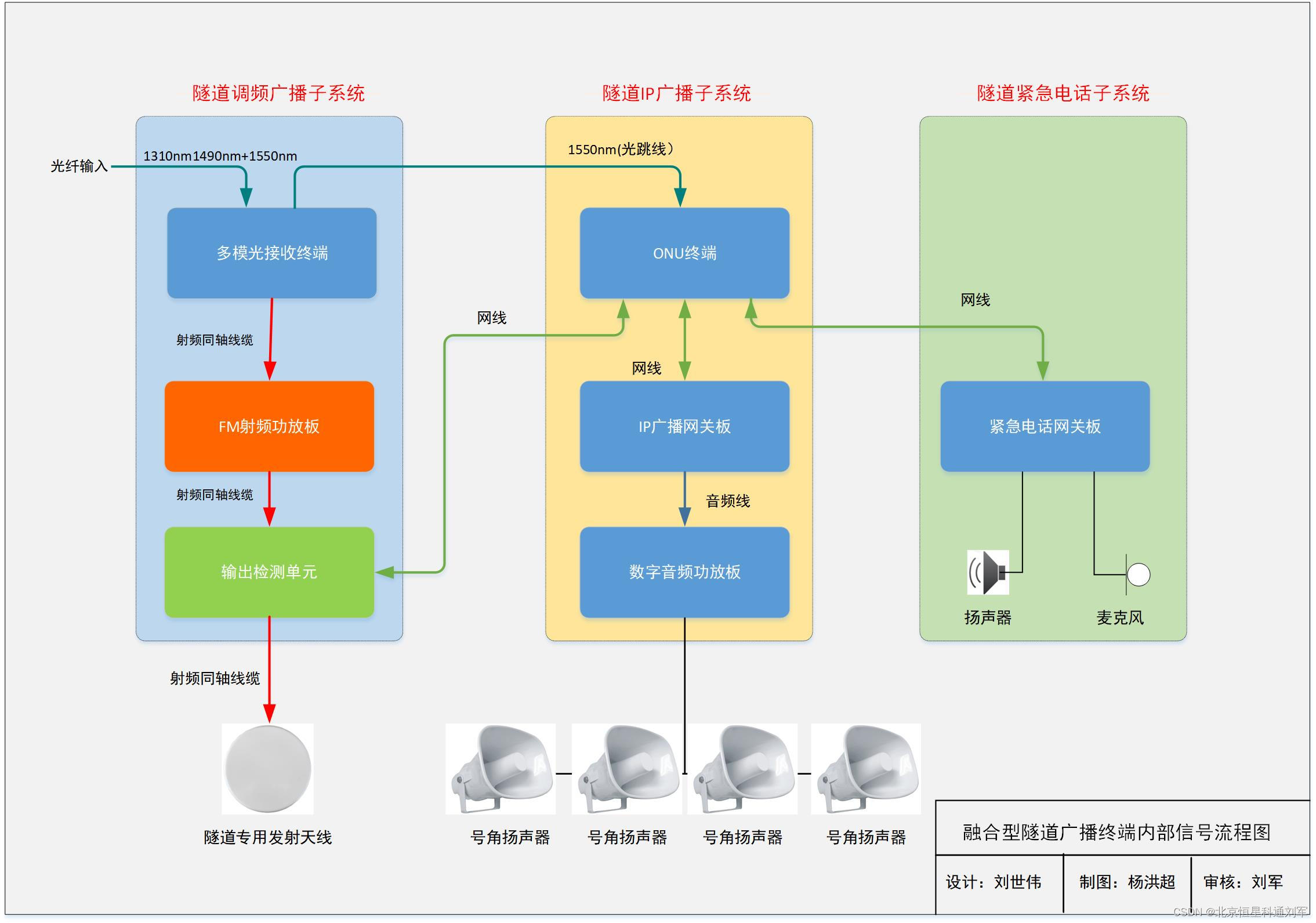
隧道应急广播应该如何搭建?
隧道应急广播系统的搭建需遵循以下关键步骤,确保在紧急情况下能够迅速、准确地传达信息,保障人员安全: 1. 需求分析与规划设计: 明确目标:确定广播系统覆盖范围(如隧道全长、出入口、避难所等关键位置&…...
OpenHarmony实战开发-Worker子线程中解压文件。
介绍 本示例介绍在Worker 子线程使用ohos.zlib 提供的zlib.decompressfile接口对沙箱目录中的压缩文件进行解压操作,解压成功后将解压路径返回主线程,获取解压文件列表。 效果图预览 使用说明 1.点击解压按钮,解压test.zip文件,…...
中国科学院大学学位论文LaTeX模版
Word排版太麻烦了,公式也不好敲,推荐用LaTeX模版,全自动 官方模版下载位置:国科大sep系统 → \rightarrow → 培养指导 → \rightarrow → 论文 → \rightarrow → 论文格式检测 → \rightarrow → 撰写模板下载百度云&#…...
秘塔和Kimi AI在资料查询和学习中的使用对比
一、引言 最近老猿在网上查资料时,基本上都使用Kimi AI进行查询,发现其查询资料后总结到位,知识点的准确度较高。今天早上收到一个消息,说新推出的秘塔AI比Kimi更新进,老猿利用在学习的《统计知识学习》简单对比试用了…...

apk反编译
APK文件可以通过多个工具反编译,以便查看包含在其中的Java源文件。但是,需要注意的是,通常通过反编译得到的不是原始的Java源代码,而是反编译后的代码,这意味着它可能已经被转换成了类似于原始Java代码的形式ÿ…...

修改百度百科的词条的方法
百度百科作为国内最大的百科全书网站之一,是广大网民获取各类知识的重要途径之一。所以,如何修改百度百科的词条成为了很多人关心的话题。本文将介绍修改百度百科的方法,并提供一些技巧和注意事项。 注册百度账号 首先,进入百度百…...

更改ip地址的几种方式有哪些
在数字化时代,IP地址作为网络设备的标识,对于我们在网络世界中的活动至关重要。然而,出于多种原因,如保护隐私、访问特定网站或进行网络测试,我们可能需要更改IP地址。虎观代理将详细介绍IP地址的更改方法与步骤&#…...
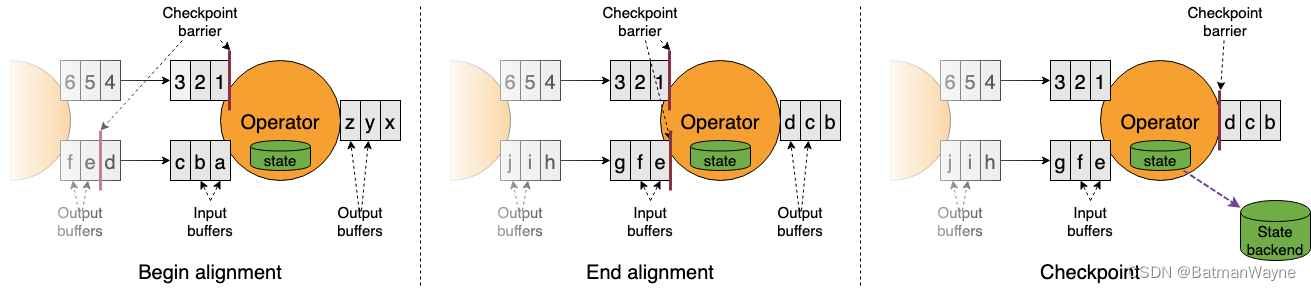
Flink学习(六)-容错处理
前言 Flink 是通过状态快照实现容错处理 一、State Backends 由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上&#x…...
行为型之备忘录模式)
设计模式(020)行为型之备忘录模式
备忘录模式是一种行为型设计模式,用于在不破坏封装性的前提下捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后可以将该对象恢复到之前的状态。这种模式通常用于需要记录对象状态历史、撤销操作或实现“回到过去”功能的场景。 在…...

Android 系统锁屏息屏休眠时Handler CountDownTimer计时器停止运行问题解决
1.前言 在进行app开发的过程中,在进行某些倒计时的功能项目开发中,会遇到在锁屏息屏休眠一段时间的情况下, 在唤醒屏幕的情况下发现倒计时已经停止了,这是因为在系统处于休眠的状态下cpu也停止了工作,所以 handler和countdowntimer倒计时也停止了工作,接下来就来看怎么样…...

Java中如何提取视频文件的缩略图
在Java中,可以使用FFmpeg库来提取视频文件的缩略图。以下是一种使用FFmpeg的方法来提取视频缩略图的示例代码: import java.io.File; import java.io.IOException;public class VideoThumbnailExtractor {public static void main(String[] args) {Stri…...

总结 HashTable, HashMap, ConcurrentHashMap 之间的区别
前言 HashMap 本身不是线程安全的. 在多线程环境下使用哈希表可以使用: Hashtable(不推荐使用)ConcurrentHashMap(推荐使用) HashMap HashMap数据结构 根本: 数组 链表(jdk1.7)/数组链表红黑…...
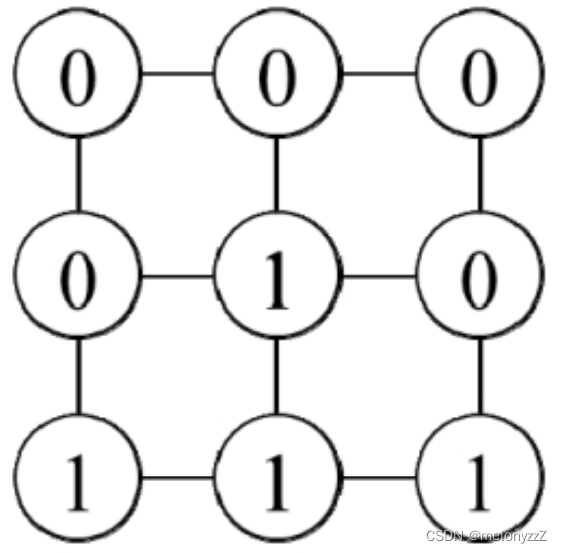
《剑指 Offer》专项突破版 - 面试题 107 : 矩阵中的距离(C++ 实现)
题目链接:矩阵中的距离 题目: 输入一个由 0、1 组成的矩阵 M,请输出一个大小相同的矩阵 D,矩阵 D 中的每个格子是矩阵 M 中对应格子离最近的 0 的距离。水平或竖直方向相邻的两个格子的距离为 1。假设矩阵 M 中至少有一个 0。 …...

揭秘智慧礼品背后的故事
如若不是从事技术行业,在罗列礼品清单时,可能不会想到 “数据”,但幸运的是,我们想到了。如何将AI技术应用到当季一些最受青睐的产品中去,训练数据是这一智能技术的背后动力。很多电子设备或名称中带有“智能”一词的设…...

NVM的安装与配置
目录 一、简介二、下载2.1、windows环境下载地址2.2、安装 三、配置3.1、查看可安装版本3.2、安装版本3.3、使用和切换版本3.4、模块配置 四、其他4.1、全局安装pnpm4.2、常用nvm命令 一、简介 NVM,全称为Node Version Manager,是一个流行的命令行工具&a…...
[Java EE] 多线程(一) :线程的创建与常用方法(上)
1. 认识线程 1.1 概念 1.1.1 什么是线程 ⼀个线程就是⼀个"执⾏流".每个线程之间都可以按照顺序执⾏⾃⼰的代码.多个线程之间"同时"执⾏ 着多份代码. 还是回到我们之前的银⾏的例⼦中。之前我们主要描述的是个⼈业务,即⼀个⼈完全处理⾃⼰的…...
Linux安装docker(含Centos系统和Ubuntu系统)
一、Centos系统 1. 卸载旧版本依赖 sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine 2. 设置仓库 安装所需的软件包。yum-utils 提供了 yum-config-manager &…...

【第十五届蓝桥杯大赛软件赛省赛】———— C/C++ 大学B组
蓝桥杯2024年15届省赛b组原题献上...

告别网盘限速困扰:网盘直链下载助手全面解析与应用指南
告别网盘限速困扰:网盘直链下载助手全面解析与应用指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 还在为网盘下载速度缓慢而烦恼吗?网盘直链下载助手作为一款免费…...

量子计算采购策略与技术路线比较
1. 量子计算采购的现状与挑战 量子计算技术正在经历从实验室研究向实际应用过渡的关键阶段。根据2023年全球量子计算产业报告,量子处理器市场规模预计将从2023年的4.7亿美元增长到2030年的65亿美元,年复合增长率高达45%。然而,面对超导、离子…...

告别TwinCAT:手把手教你用LinuxCNC+IGH搭建开源EtherCAT运动控制平台
告别商业软件束缚:LinuxCNCIGH开源运动控制平台实战指南 在工业自动化和运动控制领域,商业软件长期占据主导地位,但高昂的授权费用和封闭的生态系统让许多工程师和创客望而却步。开源运动控制平台的出现打破了这一局面,为追求灵活…...

AgenticROS:用自然语言操控ROS2机器人的AI Agent接口实践
1. 项目概述:当AI大模型遇见机器人操作系统如果你和我一样,既对AI大模型的能力着迷,又对机器人开发充满兴趣,那么你肯定想过一个问题:能不能让Claude、Gemini这样的AI,像我们人类工程师一样,直接…...

基于ChatGPT与Telethon的Telegram频道智能评论机器人开发指南
1. 项目概述与核心价值 如果你在运营Telegram频道,或者需要管理多个社群,肯定遇到过这样的场景:频道里每天都有大量新消息,你想保持活跃度、引导讨论,但手动回复每一条消息不仅耗时耗力,还很难保证回复的质…...

GTX 1660实战AI视频生成:低显存环境下的模型瘦身与帧插值方案
1. 项目概述:在入门级显卡上跑通AI视频生成最近看到不少朋友对AI视频生成很感兴趣,但总被“需要RTX 4090”、“至少24GB显存”这类硬件门槛劝退。作为一个常年混迹于“丐版”硬件圈的老玩家,我决定用我手头这块服役多年的GTX 1660(…...

AI安全控制框架:应对能力超越控制的风险与韧性防御策略
1. 项目概述:当能力超越控制“Project Glasswing”这个名字本身就充满了隐喻。玻璃翼,轻盈、透明、脆弱,却又能在阳光下折射出复杂的光谱。这像极了我们今天要讨论的核心议题:人工智能的能力边界正以前所未有的速度扩张࿰…...

掌握Windows 11精简艺术:Tiny11Builder实战手册
掌握Windows 11精简艺术:Tiny11Builder实战手册 【免费下载链接】tiny11builder Scripts to build a trimmed-down Windows 11 image. 项目地址: https://gitcode.com/GitHub_Trending/ti/tiny11builder 你是否曾因Windows 11的臃肿而烦恼?老旧设…...
)
别再折腾Windows了!用Mac或Linux搞定ACM LaTeX模板的字体难题(附保姆级配置流程)
跨平台LaTeX写作:为什么macOS和Linux是ACM模板的最佳选择 第一次接触ACM LaTeX模板的研究人员,往往会在字体兼容性问题上耗费大量时间——特别是Windows用户。当你反复尝试安装Libertine字体、解决各种编译错误时,是否想过问题可能出在操作系…...

5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案
5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而头疼吗?复…...