Java快速排序知识点(含面试大厂题和源码)
快速排序(Quick Sort)是一种高效的排序算法,采用分治法(Divide and Conquer)的策略来对一个数组进行排序。快速排序的平均时间复杂度为 O(n log n),在最坏的情况下为 O(n^2),但这种情况很少发生。快速排序因其高效性而在实际应用中非常受欢迎。
快速排序的工作原理:
- 选择基准值:从数组中选择一个元素作为基准值(pivot),选择方法有多种,如第一个元素、最后一个元素、中间元素或随机元素。
- 分区操作:重新排列数组,所有比基准值小的元素摆放在基准值的前面,所有比基准值大的元素摆放在基准值的后面(相等的可以到任一边)。在这个分区退出之后,基准值所在的位置就是其最终位置。
- 递归排序:递归地对基准值左侧和右侧的子数组进行快速排序。
快速排序的优缺点:
优点:
- 在平均情况下,快速排序具有很好的性能,时间复杂度为 O(n log n)。
- 快速排序是原地排序,不需要额外的存储空间。
缺点:
- 最坏情况下的时间复杂度为 O(n^2),但可以通过随机化来避免。
- 快速排序是不稳定的排序方法,相等的元素可能会在排序后相对位置发生变化。
快速排序的Java实现:
public class QuickSort {public void quickSort(int[] arr, int low, int high) {if (low < high) {int pivotIndex = partition(arr, low, high);quickSort(arr, low, pivotIndex - 1);quickSort(arr, pivotIndex + 1, high);}}private int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {QuickSort solution = new QuickSort();int[] arr = {10, 7, 8, 9, 1, 5};solution.quickSort(arr, 0, arr.length - 1);System.out.println("Sorted array: " + Arrays.toString(arr));}
}
在面试中,快速排序是一个重要的知识点,它考察应聘者对分治法策略和递归思想的理解。通过实现快速排序,可以展示你对基本算法和数据结构的掌握程度。希望这些知识点和示例代码能够帮助你更好地准备面试!快速排序是一种流行且高效的排序算法,经常被用于面试中考察应聘者的算法实现能力。以下是三道可能出现在大厂面试中的与快速排序相关的编程题目,以及相应的Java源码实现。
题目 1:快速排序实现
描述:
实现快速排序算法,对给定数组进行排序。
示例:
输入: [3, 6, 8, 10, 1, 2, 1]
输出: 经过排序后的数组
Java 源码:
import java.util.Arrays;public class QuickSortImplementation {public void quickSort(int[] arr, int low, int high) {if (low < high) {int pivotIndex = partition(arr, low, high);quickSort(arr, low, pivotIndex - 1);quickSort(arr, pivotIndex + 1, high);}}private int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {QuickSortImplementation solution = new QuickSortImplementation();int[] arr = {3, 6, 8, 10, 1, 2, 1};solution.quickSort(arr, 0, arr.length - 1);System.out.println("Sorted array: " + Arrays.toString(arr));}
}
题目 2:快速排序的变种 - 三数取中法的基准选择
描述:
在快速排序中,基准值的选择对性能有很大影响。使用三数取中法选择基准值,即在数组中随机选择三个元素,然后取它们的中值作为基准值。
示例:
输入: [3, 6, 8, 10, 1, 2, 1]
输出: 经过排序后的数组
Java 源码:
import java.util.Random;public class QuickSortMedianOfThree {// 其他方法与上题相同,仅 partition 方法改变private int partition(int[] arr, int low, int high) {Random random = new Random();int pivotIndex = medianOfThree(arr, low, high);swap(arr, pivotIndex, high);int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private int medianOfThree(int[] arr, int low, int high) {int mid = low + (high - low) / 2;if (arr[low] > arr[mid]) swap(arr, low, mid);if (arr[low] > arr[high]) swap(arr, low, high);if (arr[mid] > arr[high]) swap(arr, mid, high);swap(arr, mid, high);return high;}// swap 方法与上题相同// main 方法与上题相同
}
题目 3:快速排序优化 - 尾递归优化
描述:
在快速排序中,对较小的子数组使用尾递归优化,以减少递归深度。
示例:
输入: [3, 6, 8, 10, 1, 2, 1]
输出: 经过排序后的数组
Java 源码:
public class QuickSortTailRecursion {// quickSort 方法与上题相同private int partition(int[] arr, int low, int high) {// ... 与上题相同}private void swap(int[] arr, int i, int j) {// ... 与上题相同}public static void main(String[] args) {QuickSortTailRecursion solution = new QuickSortTailRecursion();int[] arr = {3, 6, 8, 10, 1, 2, 1};solution.quickSort(arr, 0, arr.length - 1);System.out.println("Sorted array: " + Arrays.toString(arr));}// 添加 tailRecursiveQuickSort 方法进行尾递归优化public void tailRecursiveQuickSort(int[] arr, int low, int high) {while (low < high) {int pivotIndex = partition(arr, low, high);if (pivotIndex - low < high - pivotIndex) {tailRecursiveQuickSort(arr, low, pivotIndex - 1);low = pivotIndex + 1;} else {tailRecursiveQuickSort(arr, pivotIndex + 1, high);high = pivotIndex - 1;}}}
}
这些题目和源码展示了快速排序的不同应用和优化技巧。在面试中,能够根据问题的特点选择合适的算法并实现其解决方案是非常重要的。希望这些示例能够帮助你更好地准备面试!
相关文章:
)
Java快速排序知识点(含面试大厂题和源码)
快速排序(Quick Sort)是一种高效的排序算法,采用分治法(Divide and Conquer)的策略来对一个数组进行排序。快速排序的平均时间复杂度为 O(n log n),在最坏的情况下为 O(n^2),但这种情况很少发生…...

SpringBoot整合Swagger2
SpringBoot整合Swagger2 1.什么是Swagger2?(应用场景)2.项目中如何使用2.1 导入依赖2.2 编写配置类2.3 注解使用2.3.1 controller注解:2.3.2 方法注解2.3.3 实体类注解2.3.4 方法返回值注解2.3.5 忽略的方法 3.UI界面 1.什么是Swa…...

C++算法题 - 矩阵
目录 36. 有效的数独54. 螺旋矩阵48. 旋转图像73. 矩阵置零289. 生命游戏 36. 有效的数独 LeetCode_link 请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。 数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现…...

记录一个没测出来,有点严重的Bug
前提: 人物:若干个 部门:若干个 部门有一个人物选择框,可以选择所有的人物,且为非必填字段 bug现象: 部门中 的人物选择框每次都少一个人物 代码分析: F12接口后端没问题,定位为前端的问题。 前…...

科学突破可能开创6G通信新时代
格拉斯哥大学开发的火柴盒大小的天线可以为全息通话、改进自动驾驶和更好的医疗保健的世界铺平道路。 格拉斯哥大学表示,这种创新的无线通信天线将超材料的独特特性与复杂的信号处理相结合,有助于构建未来的 6G 网络。 数字编码动态超表面天线…...
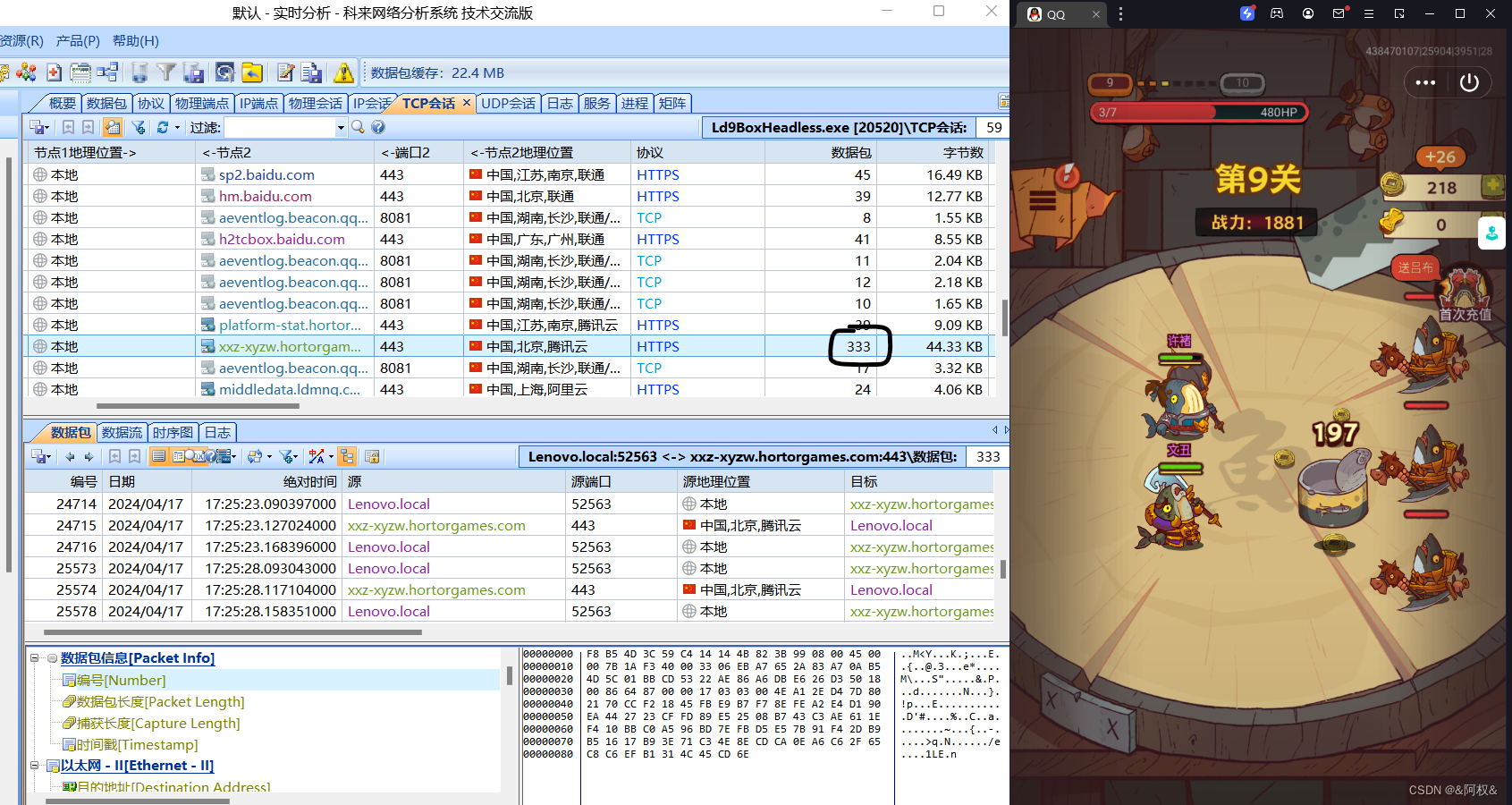
游戏、app抓包
文章目录 协议app抓包游戏抓包 协议 在抓包之前,首先我们要对每个程序使用什么协议有个大致的了解,比如网页这种就是走的http协议。 在一些app中我们通过发送一个请求,然后服务器接受,响应,返回一个数据包,…...
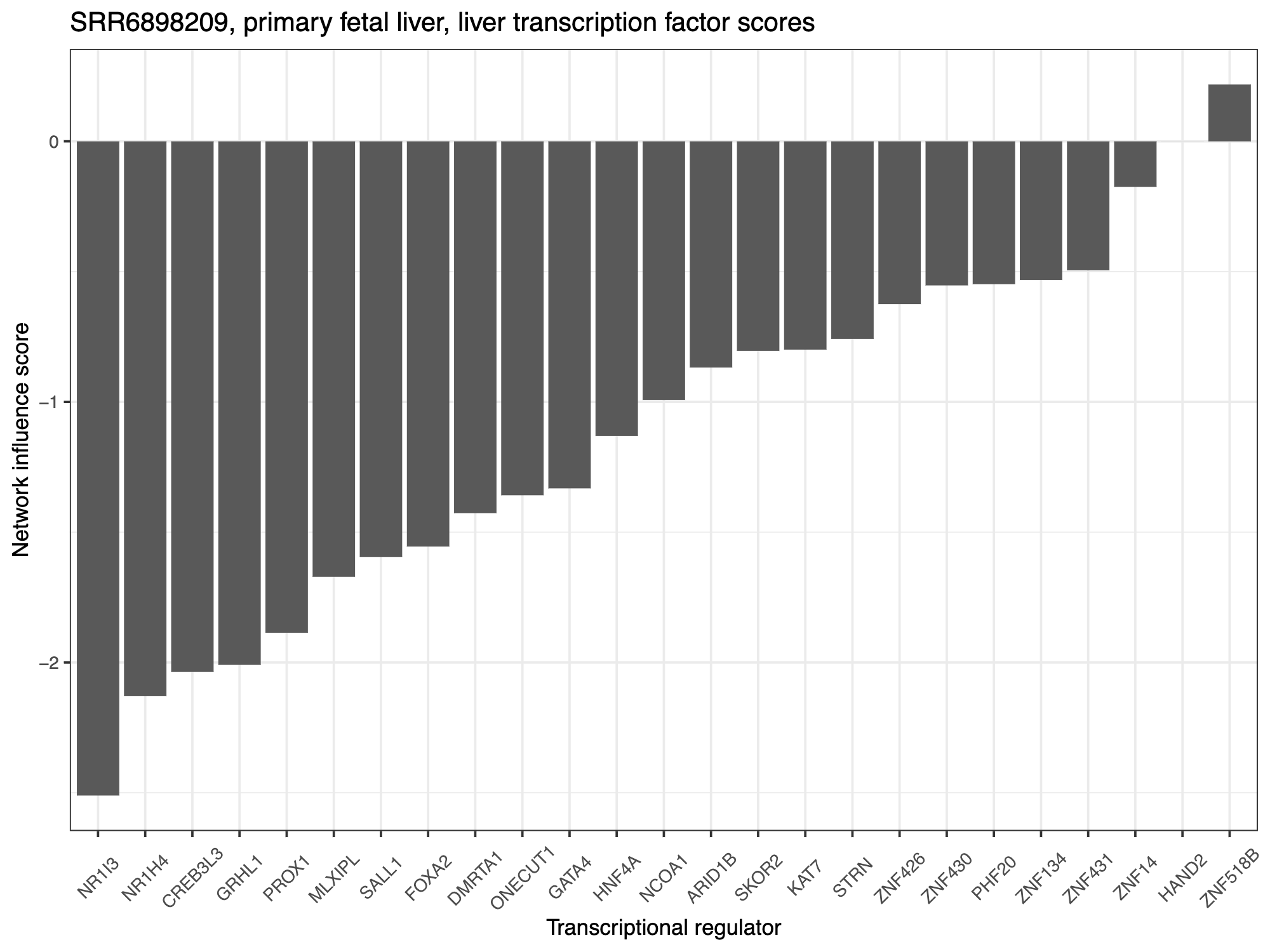
PACNet CellNet(代码开源)|bulk数据作细胞分类,评估细胞命运性能的一大利器
文章目录 1.前言2.CellNet2.1CellNet简介2.2CellNet结果 3.PACNet3.1安装R包与加载R包3.2加载数据3.3开始训练和分类3.4可视化分类过程3.5可视化分类结果 4.细胞命运分类和免疫浸润比较 1.前言 今天冲浪看到一个细胞分类性能评估的R包——PACNet,它与转录组分析方法…...
 Object Pascal 学习笔记---第10章第1节(定义属性))
(delphi11最新学习资料) Object Pascal 学习笔记---第10章第1节(定义属性)
第10章 属性和事件 在过去的三章中,我已经介绍了Object Pascal中面向对象编程(OOP)的基础知识,解释了这些概念并展示了大多数面向对象编程语言中通用特性是如何具体实现的。自Delphi的早期,Object Pascal语言就是一…...
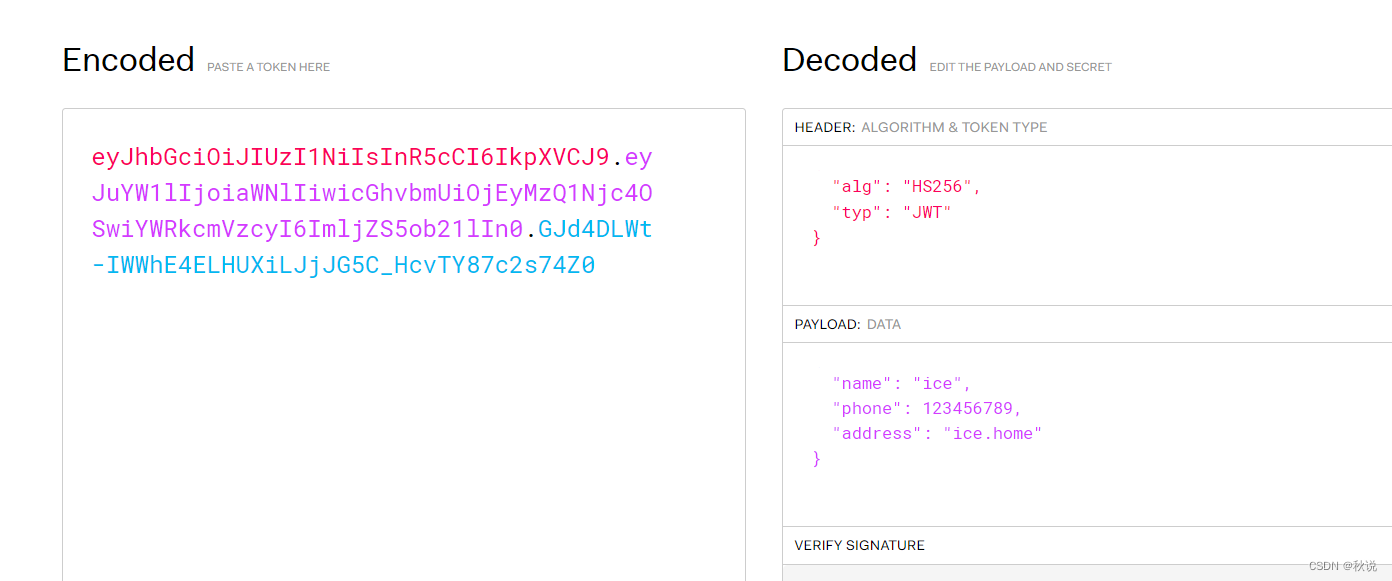
【网络安全 | 密码学】JWT基础知识及攻击方式详析
前言 JWT(Json Web Token)是一种用于在网络应用之间安全地传输信息的开放标准。它通过将用户信息以JSON格式加密并封装在一个token中,然后将该token发送给服务端进行验证,从而实现身份验证和授权。 流程 JWT的加密和解密过程如…...
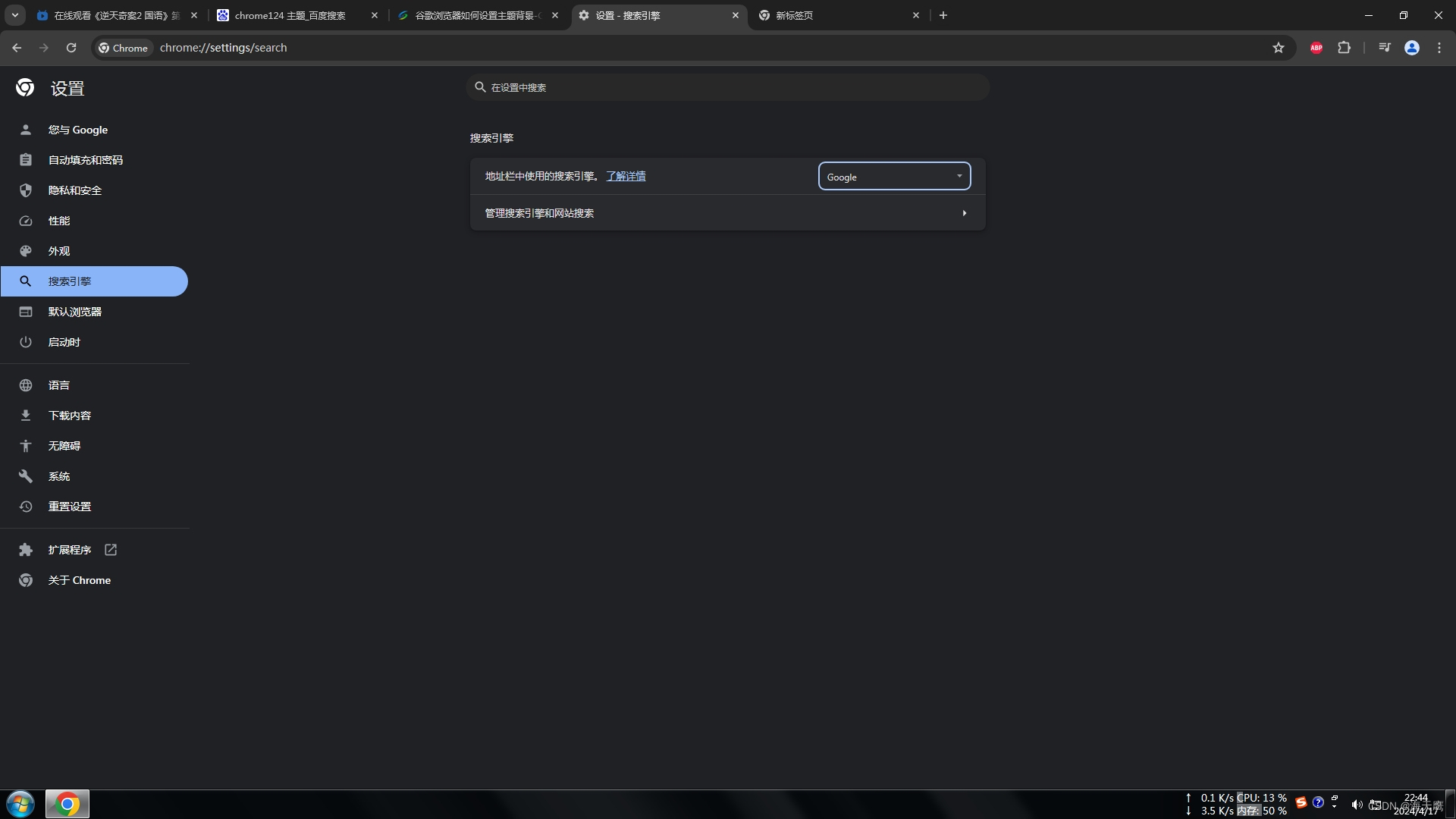
Chrome修改主题颜色
注意:自定义Chrome按钮只在搜索引擎为Google的时候出现。...

大数据:【学习笔记系列】Flink基础架构
Apache Flink 是一个开源的流处理框架,用于处理有界和无界的数据流。Flink 设计用于运行在所有常见的集群环境中,并且能够以高性能和可扩展的方式进行实时数据处理和分析。下面将详细介绍 Flink 的基础架构组件和其工作原理。 1. Flink 架构概览 Flink…...

Debezium系列之:部署Debezium采集Oracle数据库的详细步骤
Debezium系列之:部署Debezium采集Oracle数据库的详细步骤 一、部署Debezium Oracle连接器二、Debezium Oracle 连接器配置三、添加连接器配置四、可插拔数据库与不可插拔数据库一、部署Debezium Oracle连接器 部署的详细步骤可以参考博主这篇技术文章: Debezium系列之:安装…...

C语言通过键盘输入给结构体内嵌的结构体赋值——指针法
1 需求 以录入学生信息(姓名、学号、性别、出生日期)为例,首先通过键盘输入需要录入的学生的数量,再依次输入这些学生的信息,输入完成后输出所有信息。 2 代码 #include<stdio.h> #include<stdlib.h>//…...

AWS Key disabler:AWS IAM用户访问密钥安全保护工具
关于AWS Key disabler AWS Key disabler是一款功能强大的AWS IAM用户访问密钥安全保护工具,该工具可以通过设置一个时间定量来禁用AWS IAM用户访问密钥,以此来降低旧访问密钥所带来的安全风险。 工具运行流程 AWS Key disabler本质上是一个Lambda函数&…...
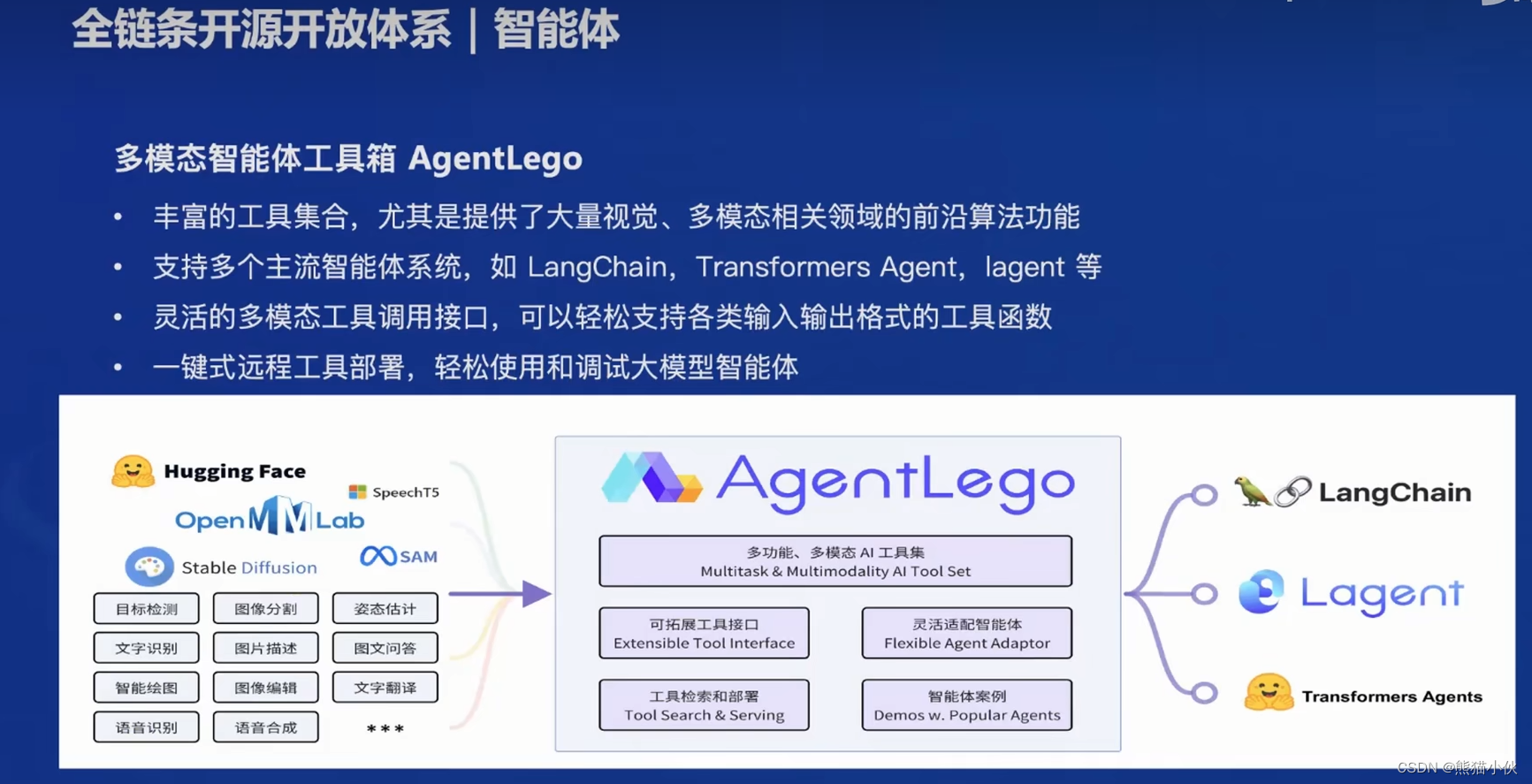
【第1节】书生·浦语大模型全链路开源开放体系
目录 1 简介2 内容(1)书生浦语大模型发展历程(2)体系(3)亮点(4)全链路体系构建a.数据b 预训练c 微调d 评测e.模型部署f.agent 智能体 3 相关论文解读4 ref 1 简介 书生浦语 InternLM…...

代码随想录-链表 | 707设计链表
代码随想录-数组 | 707设计链表 LeetCode 707-设计链表解题思路代码复杂度难点总结 LeetCode 707-设计链表 题目链接 题目描述 你可以选择使用单链表或者双链表,设计并实现自己的链表。 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点…...
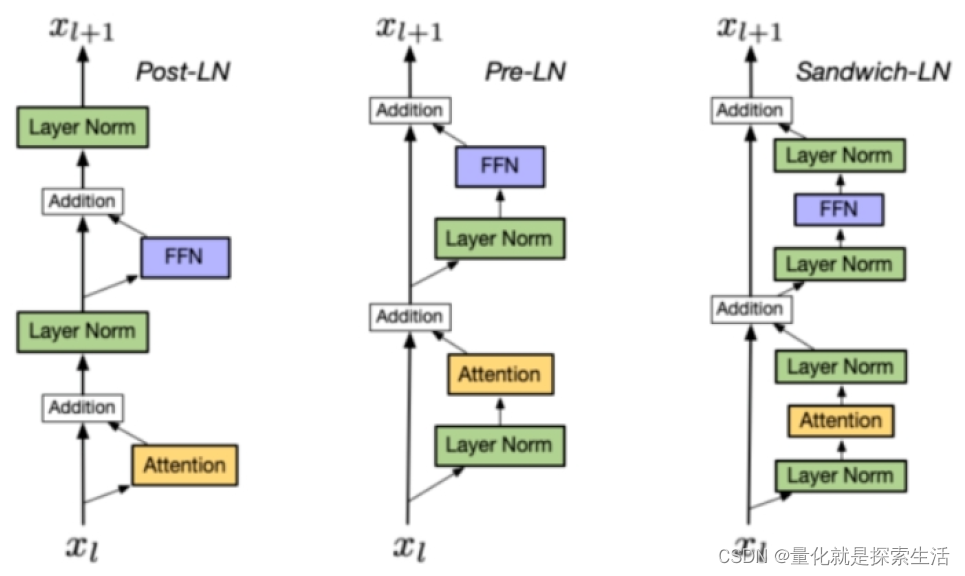
AIGC算法1:Layer normalization
1. Layer Normalization μ E ( X ) ← 1 H ∑ i 1 n x i σ ← Var ( x ) 1 H ∑ i 1 H ( x i − μ ) 2 ϵ y x − E ( x ) Var ( X ) ϵ ⋅ γ β \begin{gathered}\muE(X) \leftarrow \frac{1}{H} \sum_{i1}^n x_i \\ \sigma \leftarrow \operatorname{Var}(…...

【C语言】——字符串函数的使用与模拟实现(下)
【C语言】——字符串函数的使用与模拟实现(下) 前言五、长度受限类字符串函数5.1、 s t r n c p y strncpy strncpy 函数5.2、 s t r n c a t strncat strncat 函数5.3、 s t r n c m p strncmp strncmp 函数 六、 s t r s t r strstr strstr 函数6.1、函…...

mac安装nvm详细教程
0. 前提 清除电脑上原有的node (没有装过的可以忽略)1、首先查看电脑上是否安装的有node,查看node版本node -v2、如果有node就彻底删除nodesudo rm -rf /usr/local/{bin/{node,npm},lib/node_modules/npm,lib/node,share/man/*/node.*}2、保证自己的电脑上有安装git,不然下载n…...

上线流程及操作
上节回顾 1 搜索功能-前端:搜索框,搜索结果页面-后端:一种类型课程-APIResponse(actual_courseres.data.get(results),free_course[],light_course[])-搜索,如果数据量很大,直接使用mysql,效率非常低--》E…...

飞机在飞行中将电力传输至地面接收器
此次演示为太空太阳能新方案奠定了基础。在2025年11月一个狂风大作的日子,一架塞斯纳涡轮螺旋桨飞机在5000米的高度飞越宾夕法尼亚州上空时,遭遇了时速高达70节(约130公里/小时)的侧风,风速几乎与这架小型飞机的飞行速…...

智慧树自动刷课插件:5步实现高效学习自动化,节省70%学习时间
智慧树自动刷课插件:5步实现高效学习自动化,节省70%学习时间 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复性视频学习…...

Hitboxer SOCD Cleaner:键盘输入仲裁系统的底层实现与技术架构分析
Hitboxer SOCD Cleaner:键盘输入仲裁系统的底层实现与技术架构分析 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏领域,键盘输入精度直接影响玩家操作表现。传统键盘在处理同…...

词达人自动化助手终极指南:如何让英语学习效率提升10倍
词达人自动化助手终极指南:如何让英语学习效率提升10倍 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否曾经面对堆积如山的英语词汇任务感到力不…...

【GEO实战密码】GEO 的真正护城河,是 RAG
《GEO实战密码》节选:GEO 的真正护城河,是 RAG企业做生成式搜索优化,别只盯着外部曝光。AI 愿不愿意引用你,首先取决于你的内容值不值得被信任。最近和不少企业聊 GEO,也就是生成式搜索优化,发现一个非常典…...

graph-autofusion:CANN 的自动算子融合引擎
GE 的图优化 pass 里,算子融合是对推理性能影响最大的一个。但 GE 的融合规则是硬编码的——ConvBNReLU 写一条规则,BMMSoftmaxBMM 写一条规则。规则多了维护成本直线上升,总有覆盖不到的融合场景。 graph-autofusion 解决了这个问题。它是一…...

云原生安全新思路:基于DPU智能网卡的IPsec卸载实战,为K8s节点通信加密‘减负’
云原生安全新思路:基于DPU智能网卡的IPsec卸载实战 在Kubernetes集群中,节点间的网络通信安全一直是DevOps团队关注的焦点。传统IPsec加密方案虽然能有效保护数据传输,却不可避免地消耗大量主机CPU资源。当集群规模扩大时,这种加密…...
)
别急着加内存!PyTorch报错‘DefaultCPUAllocator: not enough memory’的另类解法(附一键修复脚本)
别急着加内存!PyTorch报错‘DefaultCPUAllocator: not enough memory’的另类解法 当你看到PyTorch抛出RuntimeError: DefaultCPUAllocator: not enough memory时,第一反应可能是检查任务管理器——然后发现物理内存明明还剩大半,这个报错就显…...

STAR-CCM+物理场实战:用‘伴随求解器’优化无人机气动,附完整仿真流程文件
STAR-CCM物理场实战:用‘伴随求解器’优化无人机气动,附完整仿真流程文件 无人机气动外形优化一直是工程仿真领域的难点与热点。传统方法依赖人工试错与经验调整,效率低下且难以找到全局最优解。本文将深入解析如何利用STAR-CCM的伴随求解器技…...

未来5年,程序员换工作,请做好降薪准备!
最近看到不少大厂的去年和一季度财报都公布了,不少人年终奖也发的差不多了,再加上金三银四也过了有一段时间了。按理来说,该晋升的晋升,该跳槽的跳槽,该加薪的加薪,基本尘埃落定,我公号后台应该…...