前端 vue单页面中请求数量过多问题 控制单页面请求并发数
需求背景:
页面中需要展示柜子,一个柜子需要调用 详情接口以及状态接口
也就是说有一个柜子就需要调用两个接口,在项目初期,接手的公司项目大概也就4-5个柜子,最多的也不超过10个,但是突然进来一个项目,这个项目中有 TM 300多台柜子,所以第一次渲染的时候,同时向服务器请求了600多个接口,导致接口超时,服务也挂了,主要也没想到会存在这种情况,咱也没遇到过啊,ok,既然问题来了,咱就解决问题
我一开始的代码逻辑就是先获取机柜数量,然后循环这个数组,在循环体中调用接口,不过我是通过添加到promise数组中,然后统一处理的,上代码
const getCabinetNum = async (id) => {let cabinetList = await cabinetApi.getCabinetList({projectId: id ? id : projectId.value})const promises = cabinetList?.map(async (cabinet) => {const data = await cabinetApi.getCabinetLive({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId})const status = await cabinetApi.getCabinetStatus({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId})return {...data, ...status}})if (promises && promises.length > 0) {const results = await Promise.all(promises)cabinetData.value = results}}
cabinetData.value 就是我最后渲染柜子的数据
这段代码的问题有两个:
1. 如果cabinetList 的长度过长 比如20个,我就要同时请求40个接口
2. 我在完全获取 cabinetData 之前,柜子是渲染不出来的,因为我封装的柜子组件是需要循环 cabinetData 去渲染的
那么,先来解决第一个问题,如何控制请求并发数量
思路:将 cabinetList 进行分割成组,控制每组的个数,然后通过组的形式向后端发送请求
const fetchCabinetDetailsInBatches = async (cabinetList, batchSize) => {// 计算需要分成的批次数量const batches = Math.ceil(cabinetList.length / batchSize)// 用于存储所有机柜详情的数组const allCabinetData = []// 循环每个批次for (let i = 0; i < batches; i++) {// 获取当前批次的起始索引和结束索引const startIndex = i * batchSizeconst endIndex = Math.min((i + 1) * batchSize, cabinetList.length)// 获取当前批次的机柜列表const batchCabinets = cabinetList.slice(startIndex, endIndex)// 定义一个数组,用于存储当前批次的所有 getCabinetLive 方法返回的 Promise 对象const promiseList = []// 循环遍历当前批次的机柜列表,为每个机柜调用 getCabinetLive,getCabinetStatus 方法,并将返回的 Promise 对象存储到 promiseList 中batchCabinets.forEach((cabinet) => {promiseList.push(Promise.all([cabinetApi.getCabinetLive({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId}),cabinetApi.getCabinetStatus({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId})]))})// 使用 Promise.all() 并行处理当前批次的所有 Promise 对象const batchResults = await Promise.all(promiseList)// 将当前批次的机柜数据存入 allCabinetData 数组中batchResults.forEach(([cabinetInfoList, status], index) => {allCabinetData[startIndex + index] = {...cabinetInfoList, status}})}return allCabinetData
}
这个函数是用来做分组以及处理数据的
使用如下
const getCabinetNum = async (id) => {let cabinetList = await cabinetApi.getCabinetList({projectId: id ? id : projectId.value})cabinetData.value = await fetchCabinetDetailsInBatches(cabinetList, 3)
}
其实主要还是利用promise.all 方法,分批处理每组的多个请求
2.下面解决第二个问题,如何能在完全获取到 cabinetData 之前渲染出柜子,并且,伴随着接口的请求,接着渲染呢
上面我提到了我是通过将 cabinetData 传递给子组件的,那么我只需要要监听 cabinetData 的变化,不断更新 cabinetData 不就好了,我首先想到的是 computed
const renderedCabinets = computed(() => {return cabinetData.value
})
通过不断变化的 cabinetData.value 将 renderedCabinets传递给子组件
但是上面的代码存在的问题就是 cabinetData.value还是需要等待全部获取,所以只要稍作修改即可
const fetchCabinetDetailsInBatches = async (cabinetList, batchSize) => {// 计算需要分成的批次数量const batches = Math.ceil(cabinetList.length / batchSize)// 用于存储所有机柜详情的数组const allCabinetData = []// 循环每个批次for (let i = 0; i < batches; i++) {// 获取当前批次的起始索引和结束索引const startIndex = i * batchSizeconst endIndex = Math.min((i + 1) * batchSize, cabinetList.length)// 获取当前批次的机柜列表const batchCabinets = cabinetList.slice(startIndex, endIndex)// 定义一个数组,用于存储当前批次的所有 getCabinetLive 方法返回的 Promise 对象const promiseList = []// 循环遍历当前批次的机柜列表,为每个机柜调用 getCabinetLive,getCabinetStatus 方法,并将返回的 Promise 对象存储到 promiseList 中batchCabinets.forEach((cabinet) => {promiseList.push(Promise.all([cabinetApi.getCabinetLive({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId}),cabinetApi.getCabinetStatus({cabinetId: cabinet.instanceUid,projectId: cabinet.projectId})]))})// 使用 Promise.all() 并行处理当前批次的所有 Promise 对象const batchResults = await Promise.all(promiseList)// 将当前批次的机柜数据存入 allCabinetData 数组中batchResults.forEach(([cabinetInfoList, status], index) => {allCabinetData[startIndex + index] = {...cabinetInfoList, status}})//这里!!!!!!!!!!!!!!!!!cabinetData.value = [...allCabinetData]}return allCabinetData
}
我在每次循环之后 将 cabinetData.value 赋值为最新获取的数据,这样每次循环,cabinetData.value就会改变,从而 renderedCabinets 也会改变
ok 这样就大功告成了
这段代码其实还有一个问题就是如果在接口没有请求完之前,你离开了当前页面,会导致在别的页面下,没请求完的接口依然在请求,会导致内存泄漏,就跟组件销毁前没销毁定时器是一个道理
可以利用axios的关闭请求的方法来解决,后续会更新代码
其实这个问题还有一种更简单高效的解决方案,就是懒加载,在用户滑动查看到新的柜子之前,不请求,滑动到未加载的机柜就请求接口,跟图片懒加载一个道理,这个方案更加简单明了,而且性能肯定比目前这个方案好,后续我也会试一下这个方案
相关文章:

前端 vue单页面中请求数量过多问题 控制单页面请求并发数
需求背景: 页面中需要展示柜子,一个柜子需要调用 详情接口以及状态接口 也就是说有一个柜子就需要调用两个接口,在项目初期,接手的公司项目大概也就4-5个柜子,最多的也不超过10个,但是突然进来一个项目&a…...

HarmonyOS开发实例:【分布式手写板】
介绍 本篇Codelab使用设备管理及分布式键值数据库能力,实现多设备之间手写板应用拉起及同步书写内容的功能。操作流程: 设备连接同一无线网络,安装分布式手写板应用。进入应用,点击允许使用多设备协同,点击主页上查询…...
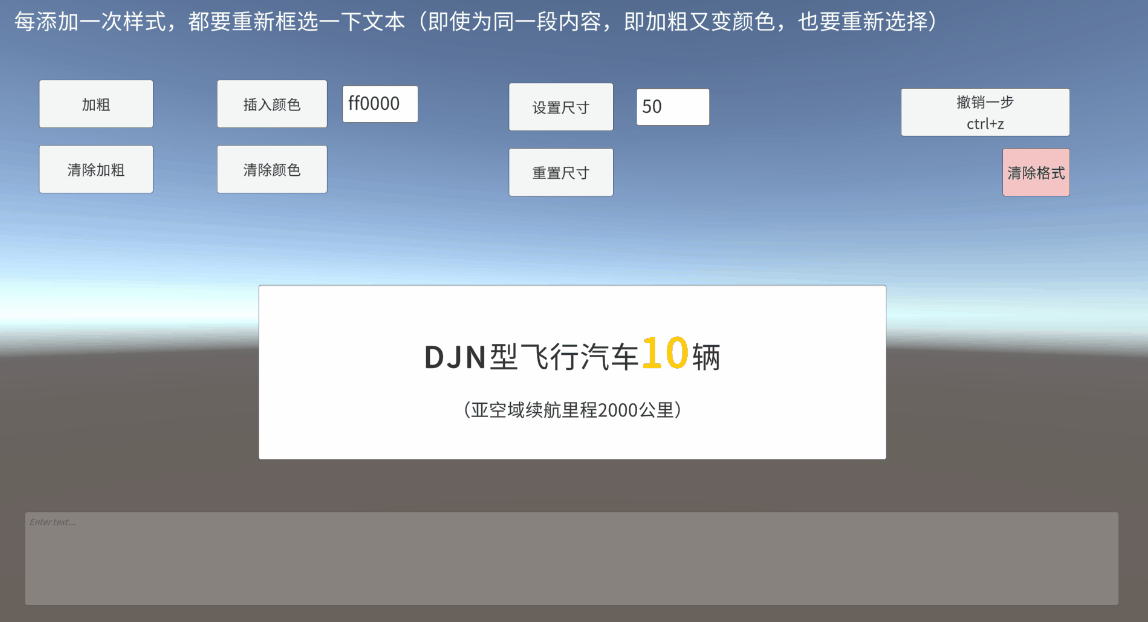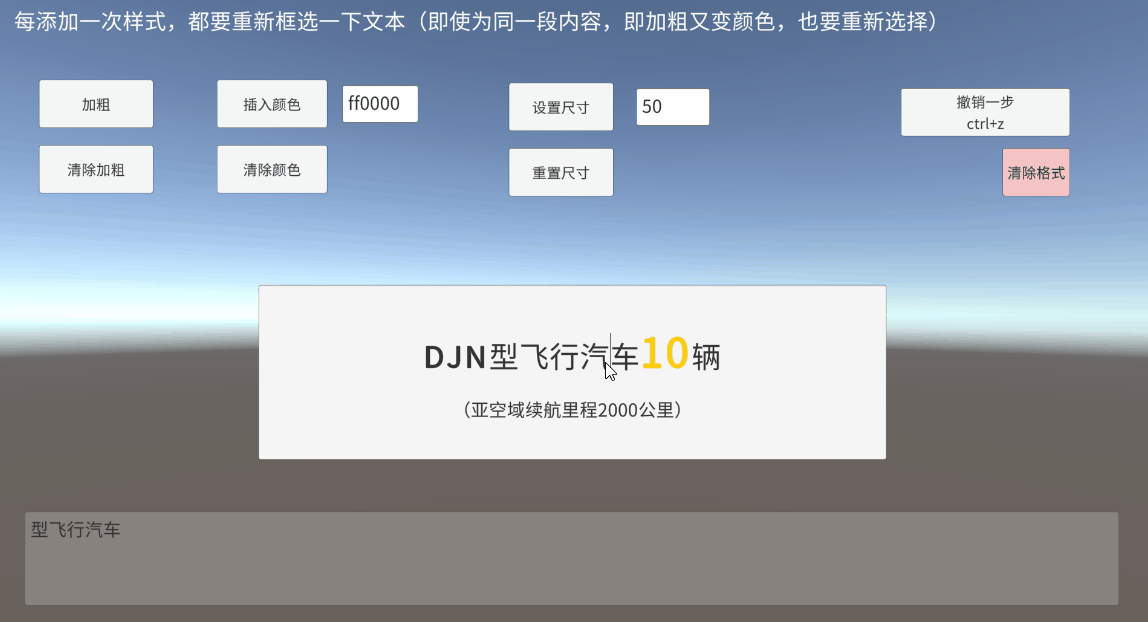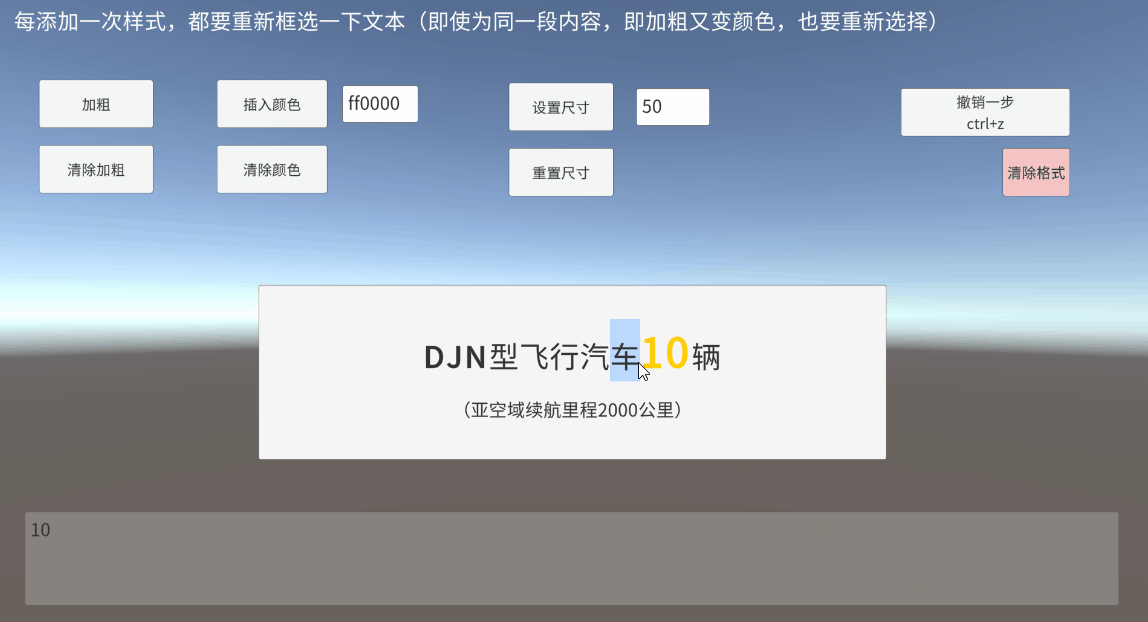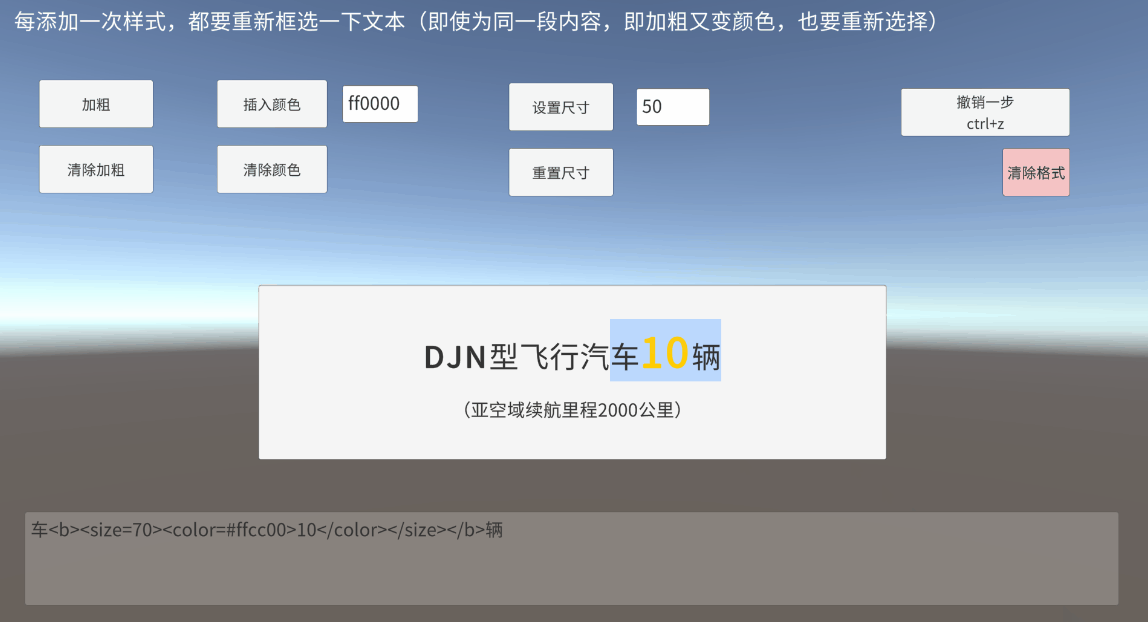
Unity TMP Inputfield 输入框 框选 富文本 获取真实定位
一、带富文本标签的框选是什么 UGUI的InputField提供了selectionAnchorPosition和selectionFocusPosition,开始选择时的光标下标和当前光标下标 对于未添加富文本标签时,直接通过以上两个值,判断一下框选方向(前向后/后向前&…...

如何在原生项目中集成flutter
两个前提条件: 从flutter v1.17版本开始,flutter module仅支持AndroidX的应用在release模式下flutter仅支持一下架构:x84_64、armeabi-v7a、arm6f4-v8a,不支持mips和x86;所以引入flutter前需要在app/build.gradle下配置flutter支持的架构 a…...

【设计模式】策略模式
目录 什么是策略模式 代码实现 什么是策略模式 策略模式是一种行为型设计模式,它定义了一系列算法,将每个算法封装成一个独立的对象,使得它们可以相互替换。 在策略模式中,通常有三个角色: 环境类(Cont…...

Java面试八股之Iterator和ListIterator的区别是什么
Iterator和ListIterator的区别是什么 这道题也是考查我们对迭代器相关的接口的了解程度,从代码中我们可以看出后者是前者的子接口,在此基础上做了一些增强,并且只用于List集合类型。 定义与基本概念 Iterator: 定义:…...
服务器中毒怎么办?企业数据安全需重视
互联网企业: 广义的互联网企业是指以计算机网络技术为基础,利用网络平台提供服务并因此获得收入的企业。广义的互联网企业可以分为:基础层互联网企业、服务层互联网企业、终端层互联网企业。 狭义的互联网企业是指在互联网上注册域名,建立网…...

k8s使用harbor私有仓库镜像 —— 筑梦之路
官方文档: Secret | Kubernetes ImagePullSecrets的设置是kubernetes机制的另一亮点,习惯于直接使用Docker Pull来拉取公共镜像,但非所有容器镜像都是公开的。此外,并不是所有的镜像仓库都允许匿名拉取,也就是说需要身份认证&…...
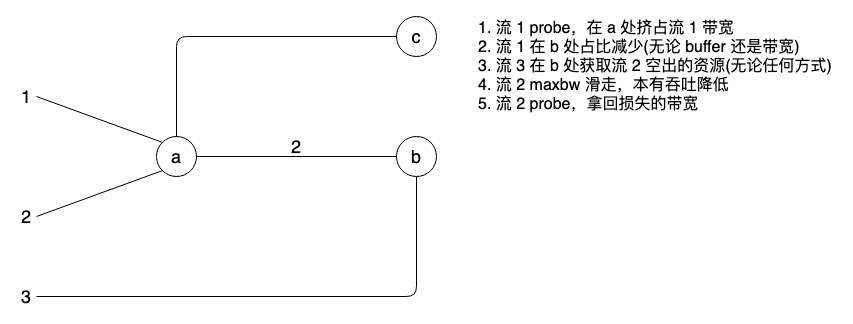
tcp bbr pacing 的对与错
前面提到 pacing 替代 burst 是大势所趋,核心原因就是摩尔定律逐渐失效,主机带宽追平交换带宽,交换机不再能轻易吸收掉主机突发,且随着视频类流量激增,又不能以大 buffer 做带宽后备。因此,主机必须 pacing…...

MySQL学习-非事务相关的六大日志、InnoDB的三大特性以及主从复制架构
一. 六大日志 慢查询日志:记录所有执行时间超过long_query_time的查询,方便定位并优化。 # 查询当前慢查询日志状态 SHOW VARIABLES LIKE slow_query_log; #启用慢查询日志 SET GLOBAL slow_query_log ON; #设置慢查询文件位置 SET GLOBAL slow_query_log_file …...
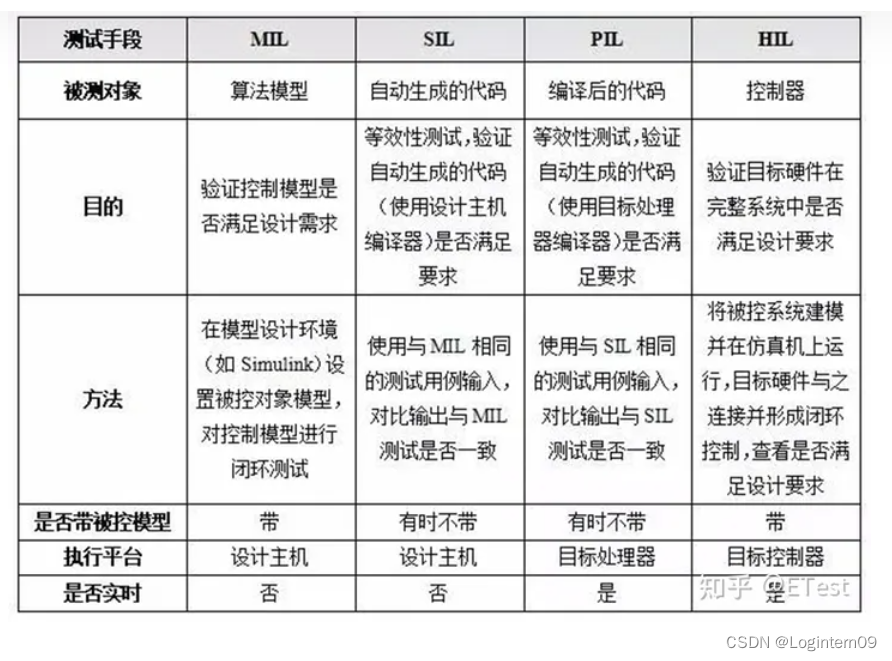
【软件测试】MIL/HIL/PIL/SIL测试
V字型开发流程 引用文章:汽车行业V模型开发详解 V模型开发(V-Model Development)是一种广泛应用于汽车行业的系统开发方法。它以字母“V”形状的图表形式展示了开发过程中不同阶段之间的关系,从需求分析到系统整合和验证&#x…...

WebKit结构深度解析:打造高效与安全的浏览器引擎
WebKit结构深度解析:打造高效与安全的浏览器引擎 在现代网络世界中,浏览器作为连接用户与互联网信息的桥梁,其背后的技术架构至关重要。WebKit,作为当今最流行的开源浏览器引擎之一,其结构设计和功能实现对于提升浏览…...

SQLSERVER对等发布问题处理
问题1: 无法对 数据库Sast_Business 执行 删除,因为它正用于复制。 (.Net SqlClient Data Provider) 处理: USE [master]; GO EXEC sp_replicationdboption dbname NSast_Business, optname Npublish, value Nfalse; EXEC sp_replica…...

CentOS 7 中时间快了 8 小时
1.查看系统时间 1.1 timeZone显示时区 [adminlocalhost ~]$ timedatectlLocal time: Mon 2024-04-15 18:09:19 PDTUniversal time: Tue 2024-04-16 01:09:19 UTCRTC time: Tue 2024-04-16 01:09:19Time zone: America/Los_Angeles (PDT, -0700)NTP enabled: yes NTP synchro…...

itext7 pdf转图片
https://github.com/thombrink/itext7.pdfimage 新建asp.net core8项目,安装itext7和system.drawing.common 引入itext.pdfimage核心代码 imageListener下有一段不安全的代码 unsafe{for (int y 0; y < image.Height; y){byte* ptrMask (byte*)bitsMask.Scan…...

搜维尔科技:Manus Xsens Metagloves新一代手指捕捉
Manus Xsens Metagloves新一代手指捕捉 搜维尔科技:Manus Xsens Metagloves新一代手指捕捉...

Python与Redis:提升性能,确保可靠性,掌握最佳实践
在 Python 中,有多个库可用于与 Redis 数据库进行交互,其中最受欢迎的是 redis-py。这是一个 Python 客户端库,提供了与 Redis 数据库进行通信的丰富功能。 Python操作Redis操作步骤 安装 redis-py 使用 pip 安装 redis-py: p…...

GPT国内能用吗
2022年11月,Open AI发布ChatGPT,ChatGPT展现了大型语模型在自然语言处理方面的惊人进步,其生成文本的流畅度和连贯性令人印象深刻,为AI应用打开了新的可能性。 ChatGPT的出现推动了AI技术在各个领域的应用,例如&#x…...
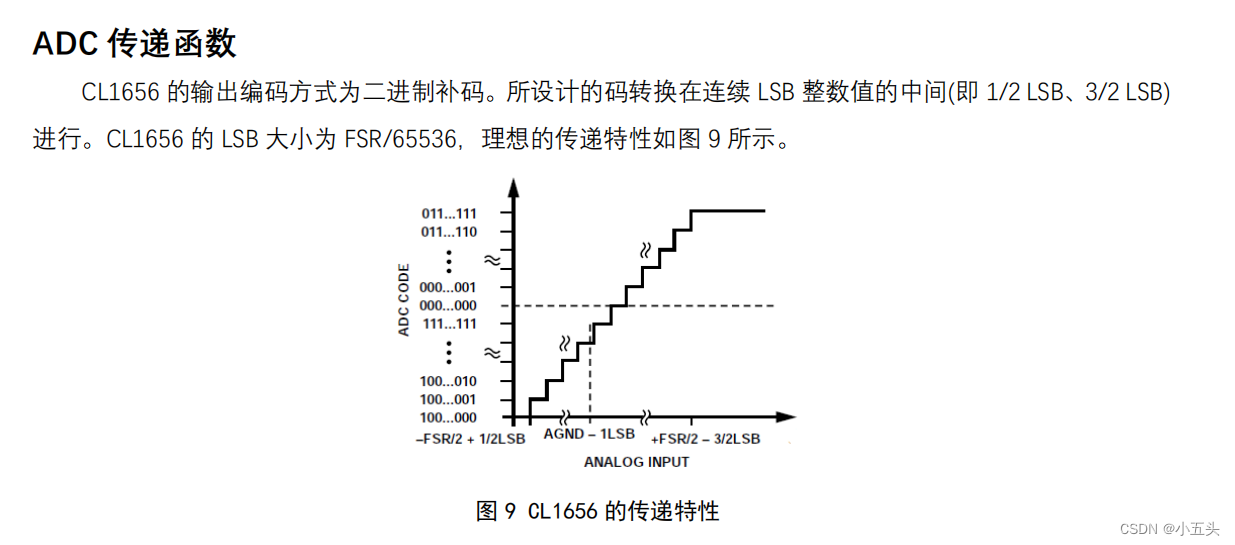
中科亿海微-CL1656功能验证开发板
I. 引言 A. 研究背景与意义 CL1656是一款精度高、功耗低、成本低的5V单片低功耗运放,由核心互联公司研发制造,CL1656 是一个 16-bit、快速、低功耗逐次逼近型 ADC,吞吐速率高达 250 kSPS,并且内置低噪声、宽 带宽采样保持放大器。…...

学习STM32第十五天
SPI外设 一、简介 STM32F4XX内部集成硬件SPI收发电路,可以由硬件自动执行时钟生成、数据收发等功能,减轻CPU负担,可配置8位/16位数据帧,高位(最常用)/低位先行,三组SPI接口,支持DMA…...

魔兽争霸3优化指南:5个常见问题与WarcraftHelper解决方案
魔兽争霸3优化指南:5个常见问题与WarcraftHelper解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否在玩《魔兽争霸3》时遇到过…...

使用 Taotoken 聚合 API 一周后的延迟与稳定性实际体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 聚合 API 一周后的延迟与稳定性实际体验分享 1. 项目背景与接入动机 最近在开发一个需要调用多种大语言模型的个人…...

EmbedClaw:RAG应用中文本智能分块与向量化检索的工程实践
1. 项目概述:一个面向嵌入向量检索的“机械爪”最近在折腾RAG(检索增强生成)应用,发现向量数据库的检索效果,很大程度上取决于你“喂”进去的文本是怎么被切成一块一块的(也就是分块,Chunking&a…...
)
告别底噪与失真:手把手教你用STM32 I2C驱动WM8988音频Codec(附完整寄存器配置代码)
嵌入式音频开发实战:WM8988音质优化全攻略 在嵌入式音频系统开发中,WM8988作为一款高性能低功耗的音频编解码芯片,因其出色的音质表现和灵活的配置选项,成为众多开发者的首选。然而,很多工程师在完成基础驱动后&#x…...

电子仪器CE标志合规:从技术文件到尽职调查的完整指南
1. CE标志合规:从品牌声誉到技术文件的完整闭环在电子设计与制造领域,无论你开发的是精密的数据采集卡、复杂的信号发生器,还是看似简单的万用表,只要你的产品最终要进入欧洲经济区(EEA)市场,CE…...

软件设计原则之DIP依赖倒置原则
(DIP) 依赖倒置原则 Dependency Inversion Principle核心原则抽象不应该依赖细节;细节应该依赖于抽象。场景描述在一个应用程序 Application 中需要使用到数据库,比如我们此时需要使用到 Mysql 数据库。Mysql 数据库分别具有连接,断开关闭&am…...

技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署
技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any upda…...

资本可以复制流量,却复制不了《凰标》的天命@凤凰标志
——《凰标》为何无法被批量复刻?一、资本逻辑:无限复制与批量复刻可复制元素资本操作手法结果爆款剧情换皮翻拍同质化内容泛滥流量模式买量算法短期数据狂欢国风外壳元素拼贴文化“快餐”营销套路热搜话题转瞬即逝的热度 资本的核心能力,是复…...

AI Agent开发实战:从核心范式到工程落地的完整指南
1. 项目概述:一场静悄悄的技术代际更迭最近和几个技术团队负责人聊天,话题总绕不开“AI Agent”。大家的感觉出奇地一致:这玩意儿的发展速度,快得有点让人喘不过气。新闻里、论文里、各种技术峰会上,关于智能体&#x…...

STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南
STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南 在嵌入式系统开发中,固件升级是一个永恒的话题。想象一下这样的场景:你的设备已经部署在客户现场,突然发现了一个需要紧急修复的Bug,或者需要增加新…...