大数据技术原理与技术简答
1、HDFS中名称节点的启动过程
- 名称节点在启动时,会将FsImage 的内容加载到内存当中,此时fsimage是上上次关机时的状态。
- 然后执行 EditLog 文件中的各项操作,使内存中的元数据保持最新。
- 接着创建一个新的FsImage 文件和一个空的 Editlog 文件,名称节点启动成功。
- 在运行过程中,HDFS 中的更新操作都会被写人 EditLog,而不是直接被写入Fslmage,所以在本次关机时,fsimage的内容仍是上次关机时的状态,只有下次开机时才会一步步执行editlog,更新fsimae为本次关机时的状态。
2、三级寻址
当要访问数据时,客户端首先在自己的缓存中查找是否有所需region的位置信息,若有则直接前往访问,若没有则三级寻址:首先访问 ZooKeeper,获取-ROOT表的所在Region服务器的位置信息,然后访的-ROOT-表,获得.META.表所在Region服务器的信息,接着访问.META.表,找到所需的 Region 具体位于哪个 Regio服务器,最后到该 Region 服务器读取数据。
**读写数据:
读:先在memstore查找,没有找到再去storefile查找
写:先写入memstore和hlog,memstore缓存满时才刷新写入磁盘
3、HLog的工作原理
- 每个region服务器配置了个HLog文件
- 写入:用户更新数据必须首先被记入HLog日志才能写入 MemStore 缓存。
- 刷新:直到 MemStore缓存内容对应的HLog日志已经被写入磁盘之后,该缓存内容才会被刷新写入磁盘。
- 故障:
- Master 主服务器首先会处理该故障 Region 服务器上面遗留的 HLog 文件
- 根据HLog每条日志记录所属的 Region 对象对 HLog 数据进行拆分
- 将失效的 Region与该 Region 对象相关的HLog日志记录重新分配到可用的 Regien 服务器中。
- Region服务器接收到region及与之相关的hlog日志后会重新做一遍日志记录中的操作,把日志记录中的数据写入MemStore缓存,然后刷新到磁盘的StoreFile 文件中,完成数据恢复。
4、NoSQL四大类型的特点及代表产品
都具有良好的可扩展性
- 键值数据库:使用key,value键值对存储,由key可以定位value,只可以通过键来进行查询。优点是大量写操作的性能好,缺点是条件查询效率低,无法存储结构化数据。可分为内存键值数据库和持久化键值数据库,代表产品redis就是一种内存键值数据库。
- 文档数据库:通过键来定位一个文档,不仅可以通过键来构建索引,也可以通过文档内容也就是值来构建索引,两个特点,一个是文档自描述,文档自身包含了其结构或模式的信息如xml,jason,html,第二个是文档自包含,文档自己包含了与其相关的所有信息,方便迁移。优点是复杂性低,灵活性高,缺点是缺乏统一的查询语言。MongoDB
- 列族数据库:以列族为单位进行存储,每行数据包含多个列族,优点是复杂性低,查找速度快,缺点是大多不支持强事务一致性。HBase,BigTable
- 图数据库:图作为数据模型来存储数据,处理高度相互关联的数据,有些甚至完全兼容ACID(原子性,一致性,隔离性,持久性)如代表产品Neo4J,优点是灵活,支持复杂图计算,缺点是复杂性高,只能支持一定的数据规模。
5、Map端的shuffle过程并画图展示
- 1. 输入数据(来自分布式文件系统)执行map任务,将输入的一个键值对转化为输出的多个键值对
- 将输出结果写入缓存
- 当缓存满时,启动溢写操作将缓存的数据写入磁盘,包含对键值对的分区(用哈希进行分区),排序(根据key进行排序),合并(可选的,将具有相同键的值加起来)
- 在map任务全部结束之前,将所有溢写文件进行归并(将具有相同键的值归在一起形成新的值),形成一个大的磁盘文件(本地),通知相应的reduce任务来领取属于自己分区的数据
6、Reduce端的shuffle过程并画图展示
- 从不同map机器领取回来所有属于自己分区的数据
- 对多个数据文件进行归并(如果缓存被占满也会像map端一样执行溢写,最终将所有溢写文件进行归并)
- 把数据输入给reduce任务
- 输出结果保存到分布式文件系统
7、Mapreduce的6个执行阶段

8、YARN体系结构中有哪些组件,各组件的功能
- ResourceManager,有两个组件,resourceschedule负责处理客户端请求、监控NodeManager、资源的分配与调度,applicationmanager负责applicationmaster的启动、监控、容错
- ApplicationManager,负责为应用程序申请资源并分配给内部map或reduce任务,负责任务的调度、监控、容错
- NodeManager,负责接收来自RM和AM的命令,负责单个节点上的资源管理
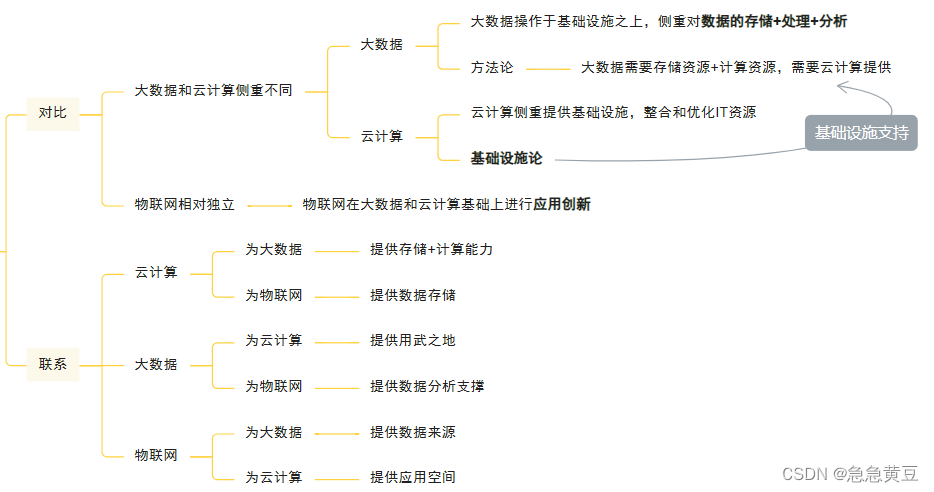
9、云计算、大数据、物联网三者的关系
10、HDFS HA实现原理
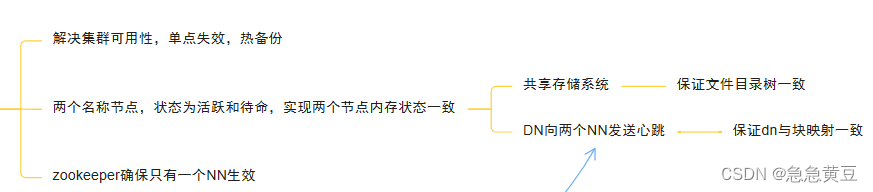
设置两个名称节点,其中一个名称节点处于“活跃”状态,另一个处于“待命”状态,在HDFS HA中,处于待命状态的名称节点提供“热备份”,也就是一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,这需要两个NN内存状态一致。以下两点保证:1、借助共享存储系统,活跃NN将更新数据写入共享存储系统,待命NN一直监听该系统,一旦发现有新的写入,就立即读取这些数据并加载到自己的内存中。2、每个DN向向两个NN发送心跳,报告自己所存块的映射信息。另外ZooKeeper保证只有一个NN生效。
11、第二名称节点辅助名称节点进行fsimage和editlog合并过程
- 替换:每隔一段时间,第二名称节点会和名称节点通信,请求其停止使用 EdiLog 文件,暂时将新到达的写操作添加到一个新的文件 EditLog.new 中。
- 合并:第二名称节点把名称节点中的 Fslmage 文件和 EdiLog文件拉回本地,在内存中逐条执行EdiLog中的操作,使 Fslmage 保持最新。
- 发回:合并结束后,第二名称节点把新的 Fslmage文件发回给名称节点,名称节点用该新的FsImage替换旧的 Fslmage 文件,用 EditLog.new 文件去替换 Editog 文件,从而减小了 EditLog 文件的大小。
12、HDFS采用块block的方式来存储数据的优势有哪些?
- 支持大规模文件存储,不受单个节点容量限制
- 简化系统设计,块的大小固定简化存储管理,且元数据和文件块分开存储方便元数据管理
- 适合数据备份,每个文件块可以冗余存储到多个节点上,提高系统容错。
13、spark与hadoop对比

14、RDD运行过程简述

15、sparkstreaming和storm的对比

15、impala和hive的对比

16、hive、pig、hbase的对比
- pig是一种数据流语言,常作为ETL工具,将外部数据转换为用户需要的数据格式
- 再使用hive进行数据分析工作,生成bi报表。
- hbase数据实时访问,有自己的数据模式
相关文章:
大数据技术原理与技术简答
1、HDFS中名称节点的启动过程 名称节点在启动时,会将FsImage 的内容加载到内存当中,此时fsimage是上上次关机时的状态。然后执行 EditLog 文件中的各项操作,使内存中的元数据保持最新。接着创建一个新的FsImage 文件和一个空的 Editlog 文件…...
Mybatis的简介和下载安装
什么是 MyBatis ? MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的…...
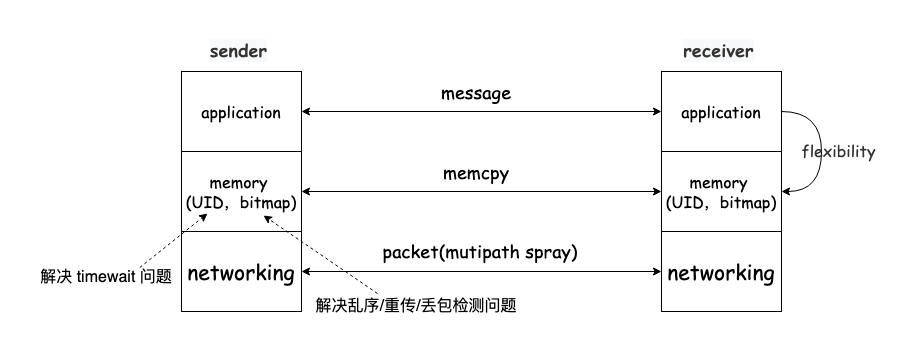
大历史下的 tcp:一个松弛的传输协议
如果 tcp 是一个相对松弛的协议,会发生什么。 所谓松弛感,意思是它允许 “漏洞”,允许可靠传输的不封闭,大致就是:“不求 100% 可靠,只要 90%(或多或少) 可靠,另外 10% 的错误可检测到” or “…...
加州大学欧文分校英语中级语法专项课程03:Tricky English Grammar 学习笔记
Tricky English Grammar Course Certificate Course Intro 本文是学习 https://www.coursera.org/learn/tricky-english-grammar?specializationintermediate-grammar 这门课的学习笔记 文章目录 Tricky English GrammarWeek 01: Nouns, Articles, and QuantifiersLearning …...

AI项目二十一:视频动态手势识别
若该文为原创文章,转载请注明原文出处。 一、简介 人工智能的发展日新月异,也深刻的影响到人机交互领域的发展。手势动作作为一种自然、快捷的交互方式,在智能驾驶、虚拟现实等领域有着广泛的应用。手势识别的任务是,当操作者做出…...

浅拷贝与深拷贝面试问题及回答
1. 浅拷贝和深拷贝的区别是什么? 答: 浅拷贝(Shallow Copy)仅复制对象的引用而不复制引用的对象本身,因此原始对象和拷贝对象会引用同一个对象。而深拷贝(Deep Copy)则是对对象内部的所有元素进…...

推荐算法顶会论文合集
SIGIR SIGIR 2022 | 推荐系统相关论文分类整理:8.74 https://mp.weixin.qq.com/s/vH0qJ-jGHL7s5wSn7Oy_Nw SIGIR2021推荐系统论文集锦 https://mp.weixin.qq.com/s/N7V_9iqLmVI9_W65IQpOtg SIGIR2020推荐系统论文聚焦: https://mp.weixin.qq.com/s…...

组合模式(Composite)——结构型模式
组合模式(Composite)——结构型模式 组合模式是一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能通过通用接口像独立整体对象一样使用它们。如果应用的核心模型能用树状结构表示, 在应用中使用组合模式才有价值。 例如一个场景…...
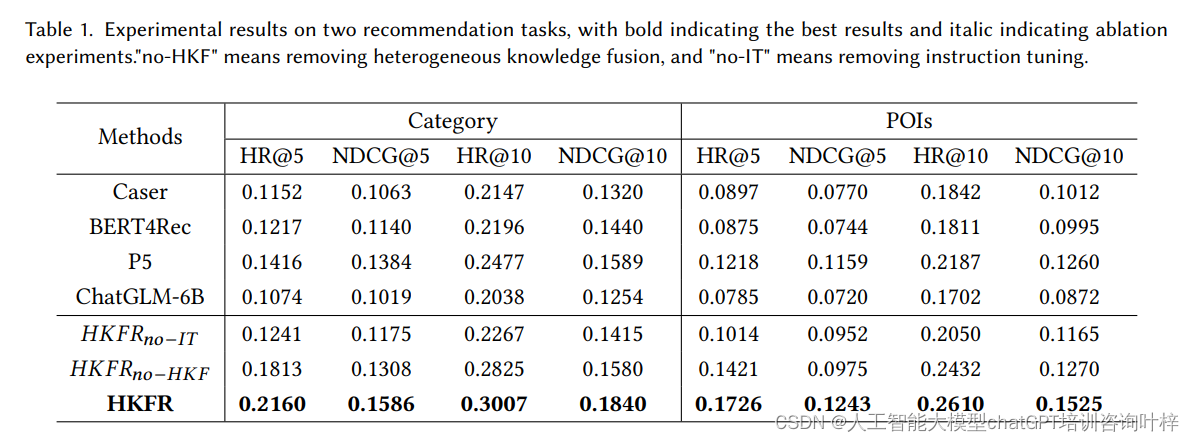
利用大模型提升个性化推荐的异构知识融合方法
在推荐系统中,分析和挖掘用户行为是至关重要的,尤其是在美团外卖这样的平台上,用户行为表现出多样性,包括不同的行为主体(如商家和产品)、内容(如曝光、点击和订单)和场景࿰…...

Dockerfile 里 ENTRYPOINT 和 CMD 的区别
ENTRYPOINT 和 CMD 的区别: 在 Dockerfile 中同时设计 CMD 和 ENTRYPOINT 是为了提供更灵活的容器启动方式。ENTRYPOINT 定义了容器启动时要执行的命令,而 CMD 则提供了默认参数。通过结合使用这两个指令,可以在启动容器时灵活地指定额外的参…...

腾讯的EdgeONE是什么?
腾讯的EdgeONE是一项边缘计算解决方案,具有一系列优势: 边缘计算能力强大:EdgeONE利用腾讯云在全球范围内的分布式基础设施,提供强大的边缘计算能力,可以实现低延迟和高可用性的服务。 智能化和自动化:Edg…...
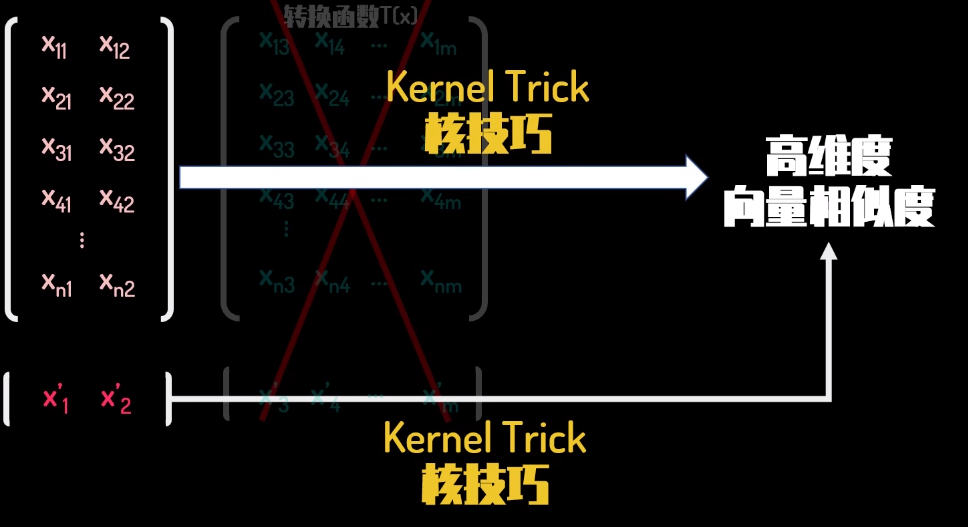
SVM直观理解
https://tangshusen.me/2018/10/27/SVM/ https://www.bilibili.com/video/BV16T4y1y7qj/?spm_id_from333.337.search-card.all.click&vd_source8272bd48fee17396a4a1746c256ab0ae SVM是什么? 先来看看维基百科上对SVM的定义: 支持向量机(英语:su…...
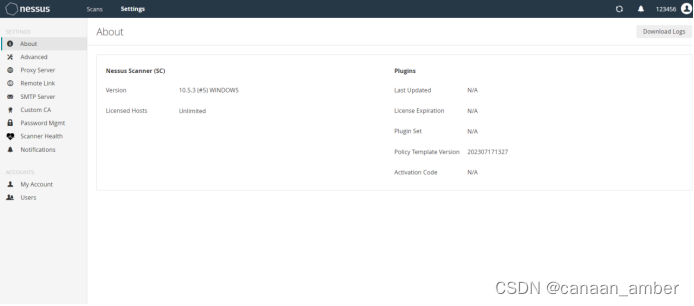
Nessus 部署实验
一、下载安装https://www.tenable.com/downloads/nessus 安装好之后,Nessus会自动打开浏览器,进入到初始化选择安装界面,这里我们要选择 Managed Scanner 点击继续,下一步选择Tenable.sc 点击继续,设置用户名和密码 等…...
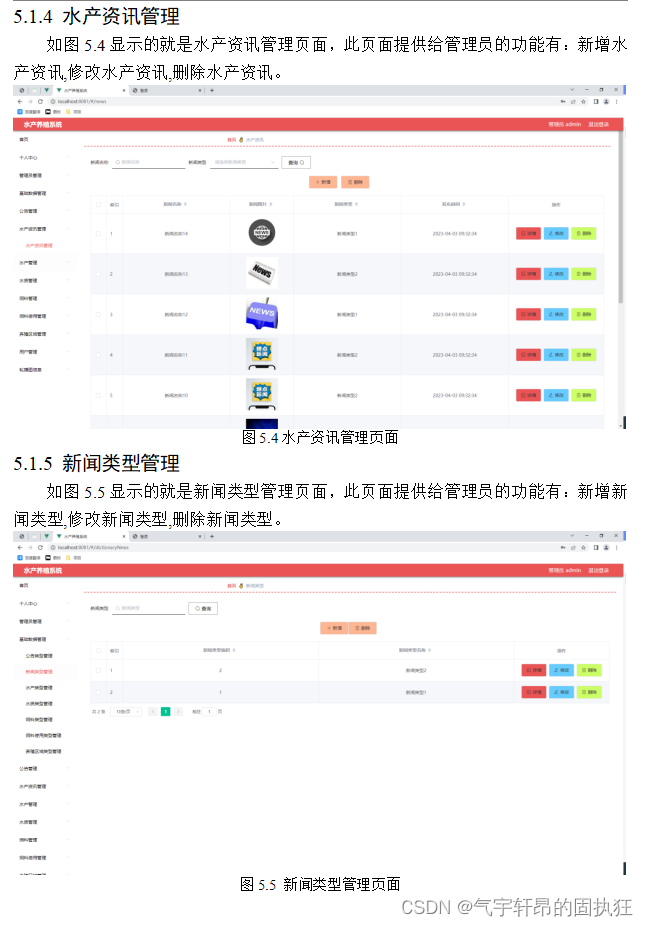
基于Springboot的水产养殖系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的水产养殖系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...
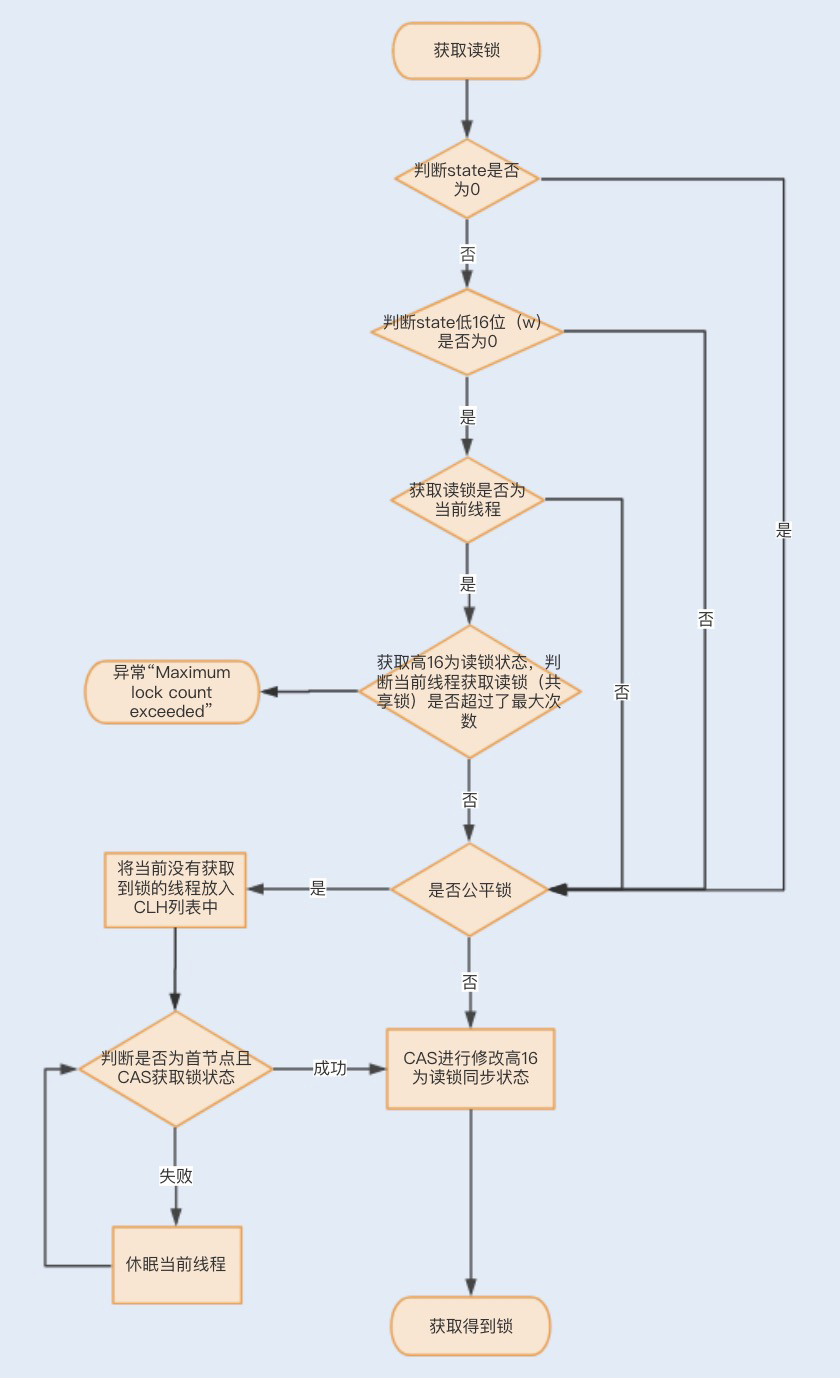
Java性能优化(五)-多线程调优-Lock同步锁的优化
作者主页: 🔗进朱者赤的博客 精选专栏:🔗经典算法 作者简介:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名) ❤️觉得文章还…...
 中 Attribute(属性)和 Property(属性))
WPF (Windows Presentation Foundation) 中 Attribute(属性)和 Property(属性)
在 WPF (Windows Presentation Foundation) 中,Attribute(属性)和 Property(属性)是两个相关但不同的概念。 Attribute(属性)是一种元数据,用于给类型、成员或其他代码元素添加附加…...
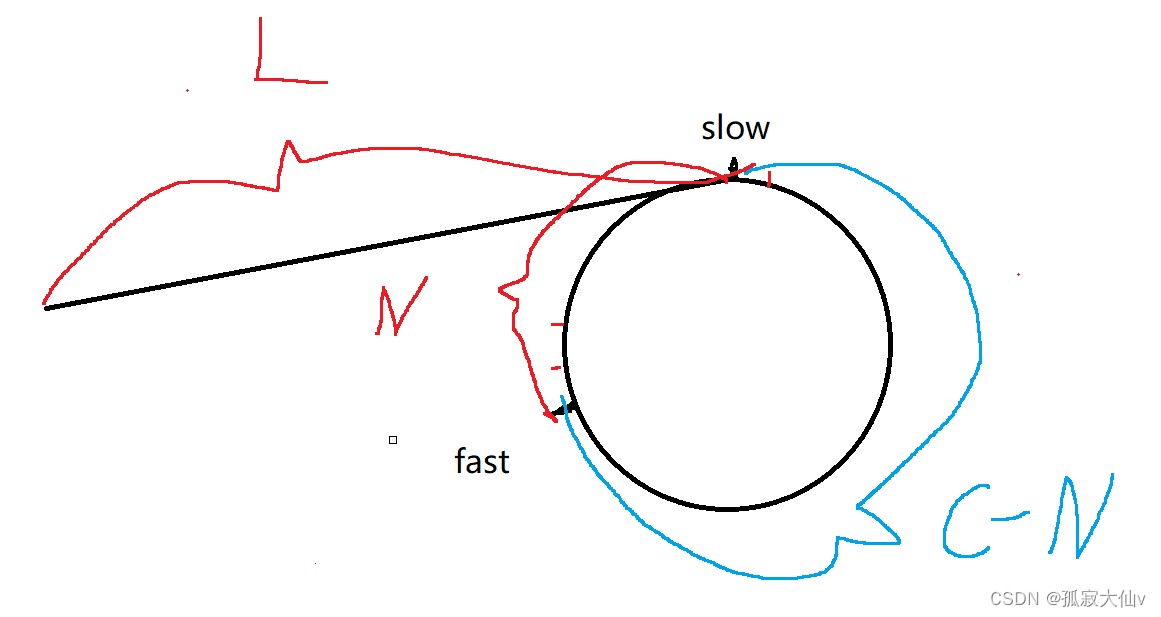
环形链表理解||QJ141.环形链表
在链表中,不光只有普通的单链表。之前写过的的一个约瑟夫环形链表是尾直接连向头的。这里的环形链表是从尾节点的next指针连向这链表的任意位置。 那么给定一个链表,判断这个链表是否带环。qj题141.环形链表就是一个这样的题目。 这里的思路是用快慢指…...

java本地锁与分布式锁-个人笔记 @by_TWJ
目录 1. 本地锁1.1. 悲观锁与乐观锁1.2. 公平锁与非公平锁1.3. CAS1.4. synchronized1.5. volatile 可见性1.6. ReentrantLock 可重入锁1.7. AQS1.8. ReentrantReadWriteLock 可重入读写锁 2. 分布式锁3. 额外的3.1. synchronized 的锁升级原理3.2. synchronized锁原理 1. 本地…...

【每日刷题】Day33
【每日刷题】Day33 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. 20. 有效的括号 - 力扣(LeetCode) 2. 445. 两数相加 II - 力扣(…...
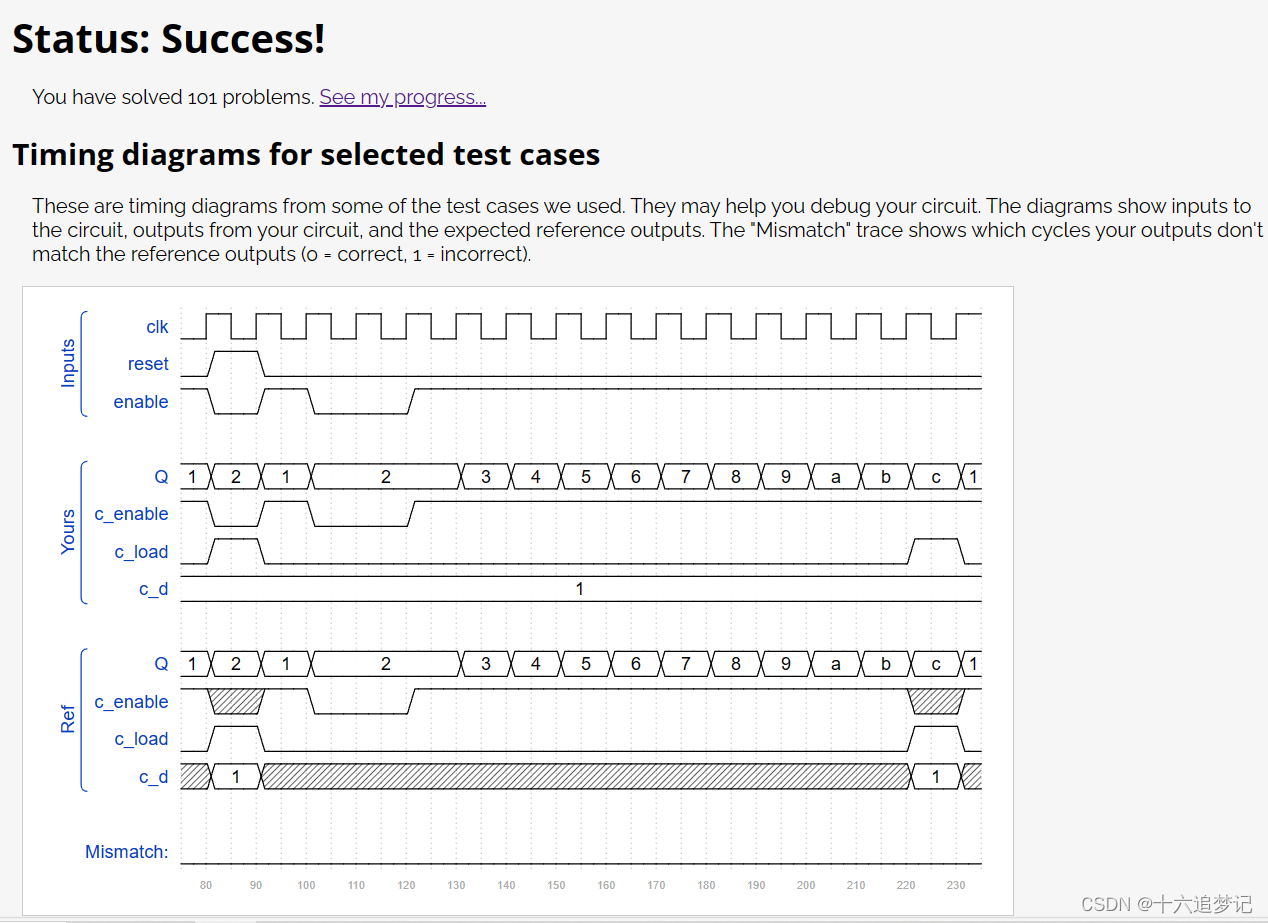
vivado刷题笔记46
题目: Design a 1-12 counter with the following inputs and outputs: Reset Synchronous active-high reset that forces the counter to 1 Enable Set high for the counter to run Clk Positive edge-triggered clock input Q[3:0] The output of the counter c…...

从U-Net到DocUNet:一个图像分割经典架构如何“跨界”解决文档矫正难题?
从U-Net到DocUNet:经典分割架构如何重塑文档图像矫正技术 当你在咖啡馆随手拍下一张皱巴巴的收据时,是否想过手机镜头捕捉的二维图像如何还原成平整的文档?这个看似简单的需求背后,隐藏着计算机视觉领域一个极具挑战性的几何变换问…...
动态扩散Transformer(DyDiT++)技术解析与优化
1. 动态扩散Transformer(DyDiT)技术解析在视觉生成领域,扩散模型(Diffusion Models)已成为当前最主流的生成技术之一。这类模型通过逐步去噪的过程,能够合成高质量的图像和视频内容。然而,随着模…...

LeetCode热题100-从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,15,7] 思…...

群晖Docker部署iptv-m3u-maker保姆级教程:自动检测直播源,告别失效频道
群晖NAS上打造智能IPTV系统:Docker容器化部署与自动化直播源管理实战 在家庭媒体中心搭建领域,群晖NAS凭借其出色的硬件性能和灵活的软件生态,已成为众多技术爱好者的首选平台。而将IPTV服务整合进NAS系统,不仅能实现传统电视节目…...

EB Garamond 12终极指南:如何免费获取经典优雅的学术排版字体
EB Garamond 12终极指南:如何免费获取经典优雅的学术排版字体 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 在数字设计的世界里,寻找一款既具有历史韵味又能满足现代学术需求的字体常常让人头疼。今…...

ARM Cortex-M微控制器与瑞萨RA系列开发实战指南
1. 项目概述:从“ARM”到“瑞萨RA”的认知之旅在嵌入式开发的江湖里,如果你还在纠结于8位、16位单片机的选型,或者对“ARM Cortex-M”这个名词感到既熟悉又陌生,那么这篇文章就是为你准备的。我接触过不少从传统8051、AVR转型过来…...

ASML财报解读:高毛利与利润倍增背后的光刻机技术垄断与市场逻辑
1. 财报核心数据深度解读:高毛利与利润倍增的背后 看到ASML最新发布的Q2财报,最抓人眼球的两个数字无疑是“毛利率超50%”和“每股净利润增长近一倍”。这不仅仅是两个亮眼的财务指标,更是理解这家全球光刻机巨头当前市场地位、技术壁垒和未来…...

Windows电脑直接运行安卓应用:APK安装器完全指南
Windows电脑直接运行安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾幻想过在Windows电脑上流畅运行安卓应用ÿ…...

3步掌握CSDN博客下载器:革命性批量下载与智能离线阅读终极方案
3步掌握CSDN博客下载器:革命性批量下载与智能离线阅读终极方案 【免费下载链接】CSDNBlogDownloader 项目地址: https://gitcode.com/gh_mirrors/cs/CSDNBlogDownloader 在信息时代,技术博客是我们获取知识的重要窗口,但网络内容的不…...

Rdkit实战:从2D到3D,解锁分子构象生成与优化的全流程
1. 从2D到3D:分子构象生成的基础概念 第一次接触分子构象生成时,我完全被各种术语搞晕了——距离几何、ETKDG、MMFF这些名词听起来就像天书。直到用RDKit实际操作了几次,才发现这个过程其实就像搭积木:先有个平面设计图ÿ…...