SparkSQL优化
SparkSQL优化
优化说明
缓存数据到内存
Spark SQL可以通过调用spark.sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务时,只需扫描必需的列,从而以减少扫描数据量、提高性能。通过缓存数据,Spark SQL还可以自动调节压缩,从而达到最小化内存使用率和降低GC压力的目的。调用sqlContext.uncacheTable("tableName")可将缓存的数据移出内存。
通过sc.broadcast(spark.table("表名")),将表广播出去,进行表与表之间的join相关操作。
可通过两种配置方式开启缓存数据功能:
1)使用spark.sqlContext的setConf方法。
2)执行SQL命令 SET key=value。
表-2 优化方式
| Property Name | Default | Meaning |
| spark.sql.inMemoryColumnarStorage.compressed | true | 如果假如设置为true,SparkSql会根据统计信息自动的为每个列选择压缩方式进行压缩 |
| spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 控制列缓存的批量大小。批次大有助于改善内存使用和压缩,但是缓存数据会有OOM的风险 |
参数调优
可以通过配置下表中的参数调节Spark SQL的性能。
表-3 参数调优
| Property Name | Default | Meaning |
| spark.sql.files.maxPartitionBytes | 134217728 (128 MB) | 获取数据到分区中的最大字节数。 |
| spark.sql.files.openCostInBytes | 4194304 (4 MB) | 该参数默认4M,表示小于4M的小文件会合并到一个分区中,用于减小小文件,防止太多单个小文件占一个分区情况。 |
| spark.sql.broadcastTimeout | 300 | 广播等待超时时间,单位秒。 |
| spark.sql.autoBroadcastJoinThreshold | 10485760 (10 MB) | 最大广播表的大小。设置为-1可以禁止该功能。当前统计信息仅支持Hive Metastore表。 |
| spark.sql.shuffle.partitions | 200 | 设置shuffle分区数,默认200。 |
SQL炸裂函数
Explode:SparkSql中的列转行函数:专门针对array或map操作。
//使用explode方法必须导入下面的包:
import org.apache.spark.sql.functions._
object explode_Demo{def main(args: Array[String]): Unit = {//创建程序入口val spark: SparkSession = SparkSession.builder().appName("createDF").master("local[*]").getOrCreate()//调用sparkContextval sc: SparkContext = spark.sparkContext//设置控制台日志输出级别sc.setLogLevel("WARN")//导包import spark.implicits._//加载数据val positionDF = spark.read.json("E:\\资料\\position.json")//查看表结构positionDF.printSchema()//DSL方法处理val listData: DataFrame = positionDF.select(explode($"data.list")).toDF("position")//查看表结构listData.printSchema()//查看表数据listData.show(false)//查看workName并统计个数listData.select($"position.workName" as "positions").groupBy($"positions").count().orderBy($"count".desc).show()}
}//SQL风格操作/*positionDF.createOrReplaceTempView("t_position")val sql ="""|select position.workName as workNames,count(*) as counts|from(|select explode(data.list) as position|from t_position)|group by workNames|order by counts desc""".stripMarginspark.sql(sql).show()*/SparkSQL运行架构
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
1)Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等。
2)Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等。
3)Hive: 负责对Hive数据进行处理。
4)Hive-ThriftServer: 主要用于对hive的访问。
DataFrame性能上比RDD要高,主要有两方面原因:
1)定制化内存管理:Rdd数据都放在堆内存,JAVA(JVM)内存,内存管理回收分配不是由spark管理,是由JAVA(GC)管理,有时候会出现资源不一致问题,spark不是直接的内存管理者。
2)DataFrame数据以二进制的方式存在于非堆内存,节省了大量空间之外,还摆脱了GC的限制。涉及到序列化和反序列化,如图-13。

图-13 GC占比关系图
优化的执行计划
查询计划通过Spark catalyst optimiser进行优化,例子如图-14。

图-14 案例图
SparkSQL针对案例优化如图-15所示:

图-15 优化流程
为了说明查询优化,我们来看图-15展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
得到的优化执行计划在转换成物理执行计划的过程中,还可以根据具体的数据源的特性将过滤条件下推至数据源内。最右侧的物理执行计划中Filter之所以消失不见,就是因为溶入了用于执行最终的读取操作的表扫描节点内。
对于普通开发者而言,查询优化器的意义在于,即便是经验并不丰富的程序员写出的次优的查询,也可以被尽量转换为高效的形式予以执行。

相关文章:
SparkSQL优化
SparkSQL优化 优化说明 缓存数据到内存 Spark SQL可以通过调用spark.sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务…...
STM32——基础篇
技术笔记! 一、初识STM32 1.1 ARM内核系列 A 系列:Application缩写。高性能应用,比如:手机、电脑、电视等。 R 系列:Real-time缩写。实时性强,汽车电子、军工、无线基带等。 M 系列:Microcont…...
【从零开始学架构 架构基础】架构设计的本质、历史背景和目的
本文是《从零开始学架构》的第一篇学习笔记,主要理解架构的设计的本质定义、历史背景以及目的。 架构设计的本质 分别从三组概念的区别来理解架构设计。 系统与子系统 什么是系统,系统泛指由一群有关联的个体组成,根据某种规则运作&#…...

Learning C# Programming with Unity 3D
作者:Alex Okita 源码地址:GitHub - badkangaroo/UnityProjects: A repo for all of the projects found in the book. 全书 686 页。...

北京车展现场体验商汤DriveAGI自动驾驶大模型展现认知驱动新境界
在2024年北京国际汽车展的舞台上,众多国产车型纷纷亮相,各自展示着独特的魅力。其中,小米SUV7以其精美的外观设计和宽敞的车内空间,吸引了无数目光,成为本届车展上当之无愧的明星。然而,车辆的魅力并不仅限…...
企业终端安全管理软件有哪些?终端安全管理软件哪个好?
终端安全的重要性大家众所周知,关系到生死存亡的东西。 各类终端安全管理软件应运而生,为企业提供全方位、多层次的终端防护。 有哪些企业终端安全管理软件? 一、主流企业终端安全管理软件 1. 域智盾 域智盾是一款专为企业打造的全面终端…...
媒体驱动框架整理--HDMI框架(2))
Linux内核--设备驱动(七)媒体驱动框架整理--HDMI框架(2)
目录 一、引言 二、drm框架 ------>2.1、画布( FrameBuffer ) ------>2.2、绘图现场(CRTC) ------>2.3、输出转换器(Encoder ) ------>2.4、连接器 (Connector ) ------>2.5、显示面(Planner) 三、VOP部分详解 ------>3.1、dts ------>3.2、v…...

3.3 Gateway之自定义过滤器
1.Gateway过滤器种类 过滤器种类描述GatewayFilter路由过滤器,作用于任意指定的路由。默认不生效,要配置到路由后生效GlobalFilter全局过滤器,作用范围是所有路由。声明后自定生效 2.Gateway过滤器参数 参数描述ServerWebExchangeGateway内…...
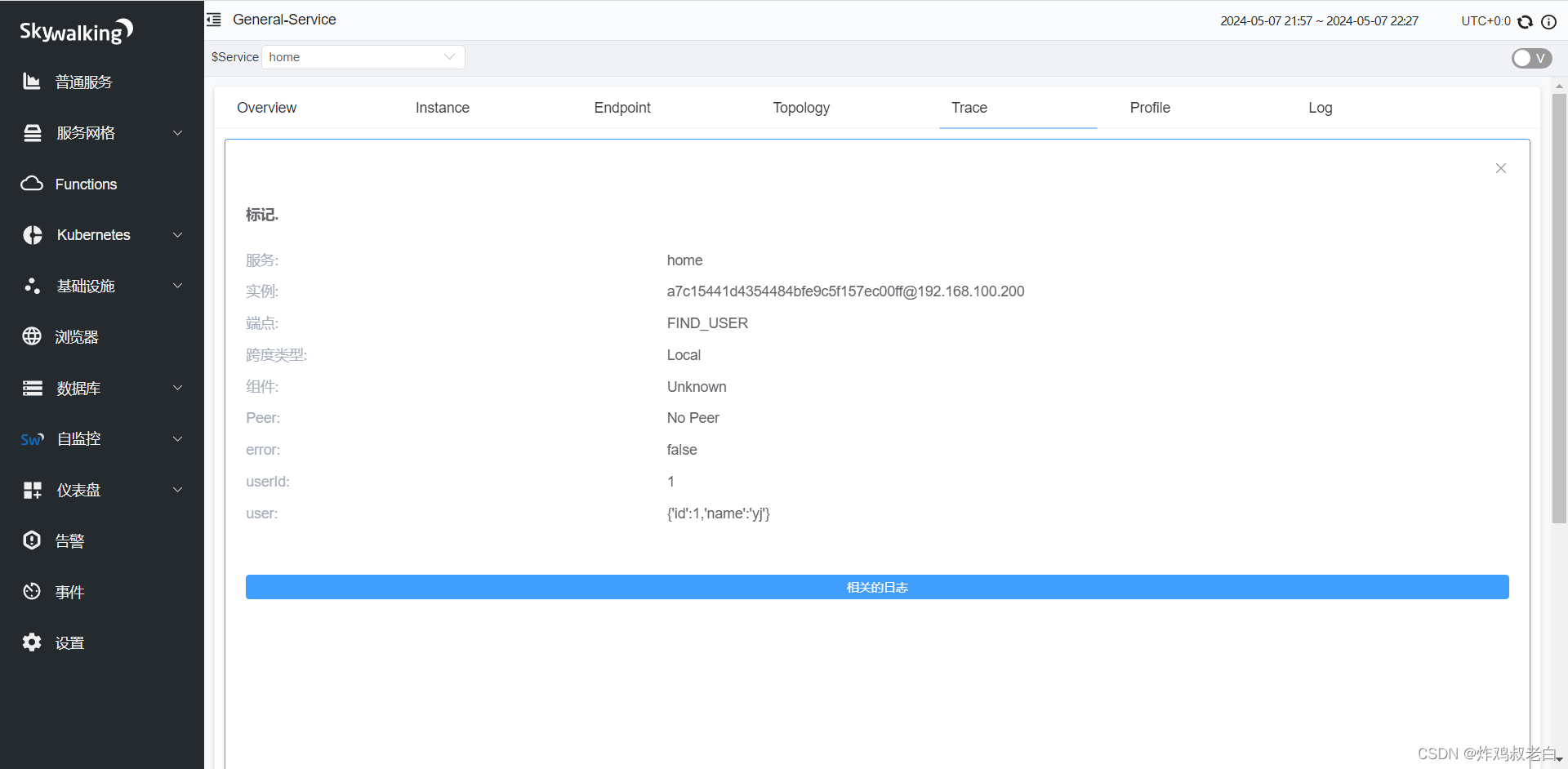
Skywalking数据持久化与自定义链路追踪
学习本篇文章之前首先要了解一下Sky walking的基础知识 分布式链路追踪工具Skywalking详解 一,Sky walking数据持久化 Sky walking提供了es,MySQL等数据持久化方案,默认使用h2基于内存的数据库,重启之后数据即会丢失。 在实际工…...
设计模式之模板模式TemplatePattern(五)
一、模板模式介绍 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern), 在一个抽象类公开定义了执行它的方法的模板。它的子类可以更需要重写方法实现,但可以成为典型类中…...
划重点!PMP报考条件、报考步骤、考试内容、适合人群
参加PMP认证的好处,可以从几个方面来认识: 一、参加PMP认证与考试的过程,同时是一个系统学习和巩固项目管理知识的过程 二、参加PMP认证,您可以获得由PMI颁发的PMP证书 而拥有PMP认证表示你已经成为一个项目管理方面的专业人员…...

Java | Leetcode Java题解之第74题搜索二维矩阵
题目: 题解: class Solution {public boolean searchMatrix(int[][] matrix, int target) {int m matrix.length, n matrix[0].length;int low 0, high m * n - 1;while (low < high) {int mid (high - low) / 2 low;int x matrix[mid / n][m…...

C#高级编程笔记-泛型
本章的主要内容如下: ● 泛型概述 ● 创建泛型类 ● 泛型类的特性 ● 泛型接口 ● 泛型结构 ● 泛型方法 目录 1.1 泛型概述 1.1.1 性能 1.1.2 类型安全 1.1.3 二进制代码的重用 1.1.4 代码的扩展 1.1.5 命名…...
(超简单)SpringBoot中简单用工厂模式来实现
简单讲述业务需求 业务需要根据不同的类型返回不同的用户列表,比如按角色查询用户列表、按机构查询用户列表,用户信息需要从数据库中查询,因为不同的类型查询的逻辑不相同,因此简单用工厂模式来设计一下; 首先新建一个…...

java中的条件、循环和scanner类
if else ; 单行逻辑大括号可以省略;但是不建议省略; public static void main(String[] args) {boolean bool1 (Math.random() * 1000) % 2 > 1;System.out.println((Math.random() * 1000) % 2 "-" bool1);if(bool1) {System.out.prin…...
【Qt QML】Frame组件
Frame(框架)包含在: import QtQuick.Controls继承自Pane控件。用于在可视框架内布局一组逻辑控件。简单来说就是用来包裹和突出显示其他可视元素。Frame不提供自己的布局,但需要自己对元素位置进行设置和定位,例如通过…...

Web API之DOM
DOM 一.认识DOM二.获取元素三.事件基础四.操作元素(1).改变元素内容(2).修改元素属性(str、herf、id、alt、title)(3).修改表单属性(4).修改样式属性操作(5).小结 五.一些思想(1).排他思想(2).自定义属性的操作 六.节点操作1.认识2.节点层级关系3.创建和添加、删除、…...
)
windows驱动开发-内核编程技术汇总(六)
在驱动程序中使用文件 内核模式组件通过其对象名称引用文件,该对象名称是连接到文件的完整路径的 \DosDevices 。 在 Microsoft Windows 2000 及更高版本的操作系统上, \?? 等效于 \DosDevices。例如,C:\WINDOWS\example.txt 文件的对象名…...
Windows Server 2019虚拟机安装
目录 第一步、准备工作 第二步、部署虚拟机 第三步、 Windows Server 2019系统启动配置 第一步、准备工作 下载Windows Server 2019系统镜像 官网下载地址:Windows Server 2019 | Microsoft Evaluation Center VMware Workstation 17下载地址: 链…...
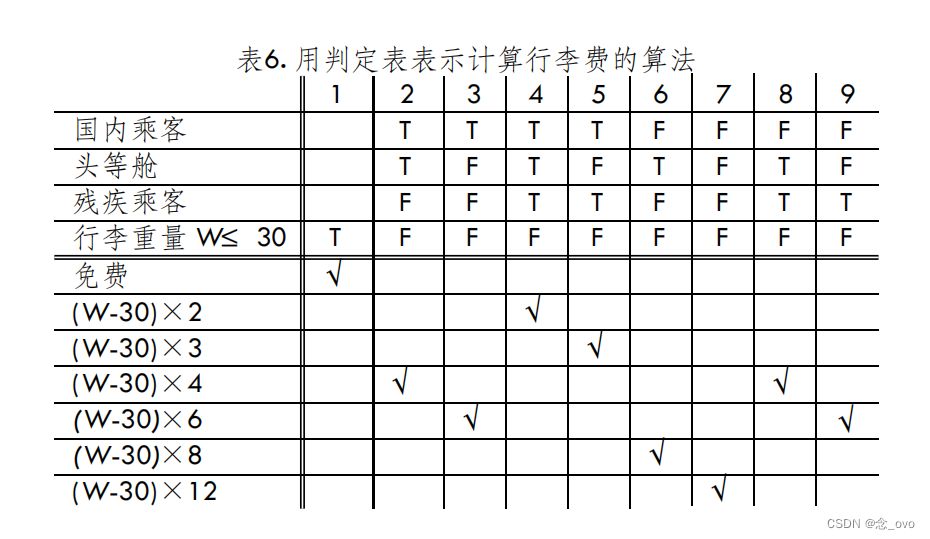
【软件工程】详细设计
目录 前言详细设计算法设计工具——判定表 前言 软件工程生命周期分为八个阶段: 问题定义—>可行性研究—>需求分析 —>概要设计—>详细设计—>编码与单元测试 —>综合测试—>软件维护 这节我们讲的是软件开发流程中的一个阶段,需求…...

终极color库API参考手册:从入门到精通CSS颜色处理
终极color库API参考手册:从入门到精通CSS颜色处理 【免费下载链接】color 项目地址: https://gitcode.com/gh_mirrors/col/color color库是一个功能强大的JavaScript库,专为颜色转换和操作而设计,支持CSS颜色字符串,让开发…...

喜马拉雅音频下载工具:技术实现与高效使用指南
喜马拉雅音频下载工具:技术实现与高效使用指南 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字化学习与娱乐场景…...

Magika:AI驱动的文件类型检测神器,准确率高达99%+
Magika:AI驱动的文件类型检测神器,准确率高达99% 【免费下载链接】magika 项目地址: https://gitcode.com/GitHub_Trending/ma/magika 你是否曾经遇到过这样的情况:下载了一个文件却不知道它是什么格式?或者在处理大量文件…...

不止是上网:用PVE虚拟的OpenWRT旁路由解锁Docker、AdGuard Home和异地组网玩法
解锁PVE虚拟OpenWRT旁路由的进阶玩法:从Docker到智能家居中枢 在家庭网络架构中,OpenWRT旁路由早已超越了简单的网关转发角色。当它运行在PVE虚拟化环境中时,这个轻量级Linux系统(仅需1G内存)可以变身为多功能家庭网络…...

zteOnu:核心功能全解析与实战指南
zteOnu:核心功能全解析与实战指南 【免费下载链接】zteOnu 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 解锁高级配置:工厂模式激活指南 场景描述 网络管理员在配置中兴光猫时,发现普通用户权限无法修改关键网络参数&…...

小白也能玩转的AI语音合成:超级千问语音世界快速体验报告
小白也能玩转的AI语音合成:超级千问语音世界快速体验报告 1. 初识超级千问语音世界 第一次打开超级千问语音世界,我仿佛穿越回了童年玩红白机的时代。复古的像素风界面、跳跃的蘑菇按钮、会移动的小乌龟,这哪里是AI工具,分明是个…...

学术探险家的秘密武器:书匠策AI,解锁课程论文新宇宙!
在学术的浩瀚星空中,每一位学子都是勇敢的探险家,怀揣着对知识的渴望,踏上探索未知的征途。而课程论文,则是这场探险中不可或缺的“星际导航图”,指引着我们穿越知识的迷雾,抵达真理的彼岸。但你是否曾遇到…...

从规格书到点亮屏幕:RK3568+GM8775C双通道LVDS调试全流程解析
RK3568GM8775C双通道LVDS屏幕调试实战:从参数解析到设备树配置 第一次拿到一块非标准LVDS屏幕时,我盯着规格书里密密麻麻的表格和数据完全无从下手。作为硬件工程师,我们常常需要面对各种定制化显示屏的驱动问题。本文将带你深入理解如何从屏…...
)
机械原理课程设计 洗瓶机机构设计(设计说明书+3张CAD图纸+连杆机构设计软件)
洗瓶机作为工业清洗领域的核心设备,其机构设计的合理性直接影响清洗效率与质量。机械原理课程设计中的洗瓶机机构设计,聚焦于通过连杆机构实现瓶体的连续输送、定位与翻转,确保清洗液均匀覆盖瓶内壁。设计核心在于构建多自由度运动系统&#…...

告别调参玄学:在GID遥感数据集上优化DeeplabV3+的5个实战技巧
告别调参玄学:在GID遥感数据集上优化DeeplabV3的5个实战技巧 遥感影像分割一直是计算机视觉领域的难点任务,尤其是面对GID这类包含复杂地物边界和多尺度目标的数据集时。许多研究者在初步跑通DeeplabV3模型后,往往会陷入mIoU指标停滞不前的困…...