ubuntu20安装colmap
系统环境
ubuntu20 ,cuda11.8 ,也安装了anaconda。因为根据colmap的官方文档说的,如果根据apt-get安装的话,默认是非cuda版本的,而我觉得既然都安装了cuda11.8了,自然也要安装cuda版本的colmap。
安装步骤
整体的安装步骤就是参考的官方文档:https://colmap.github.io/install.html
- 安装依赖
sudo apt-get install \git \cmake \ninja-build \build-essential \libboost-program-options-dev \libboost-filesystem-dev \libboost-graph-dev \libboost-system-dev \libeigen3-dev \libflann-dev \libfreeimage-dev \libmetis-dev \libgoogle-glog-dev \libgtest-dev \libsqlite3-dev \libglew-dev \qtbase5-dev \libqt5opengl5-dev \libcgal-dev \libceres-dev
注意这里是安装了ceres这个非线性优化库了,所以也就没必要再自己手动去源码安装。
如果apt-get的时候遇到问题了,可以参考这篇博客:https://www.cnblogs.com/gooutlook/p/17682885.html
我在安装这些依赖的时候没有遇到问题,所以直接下一步。
- 克隆代码
git clone https://github.com/colmap/colmap.git
cd colmap
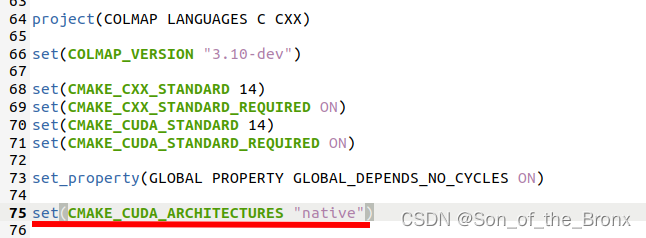
- 在编译之前根据文档的提示,需要在CMakeLists中设置参数来使cuda生效。
就是下面这段原话:
Or, manually install latest CUDA from NVIDIA’s homepage. During CMake configuration specify CMAKE_CUDA_ARCHITECTURES as “native”, if you want to run COLMAP on your current machine only, “all”/”all-major” to be able to distribute to other machines, or a specific CUDA architecture like “75”, etc.
所以在CMakeLists中添加一句:
set(CMAKE_CUDA_ARCHITECTURES "native")
结果如下:
然后就可以继续下面的编译安装。
- 编译安装
mkdir build
cd build
cmake .. -GNinja
ninja
sudo ninja install
在cmake的时候需要注意,如果你是安装了anaconda的话,还需要将anaconda的路径从当前终端去掉,否则很多库会被anaconda覆盖而造成版本不一致报错。具体参考我的这篇博客:anaconda与ros联合使用
在ninja的时候会等待一点时间:

结果:因为前面的依赖安装很顺利,所以比较轻松的安装好了colmap。
- 测试
colmap gui
打开可以用于3D高斯训练的数据集:File->Import model->data->train->spase->0
可以看到稀疏的火车点云。
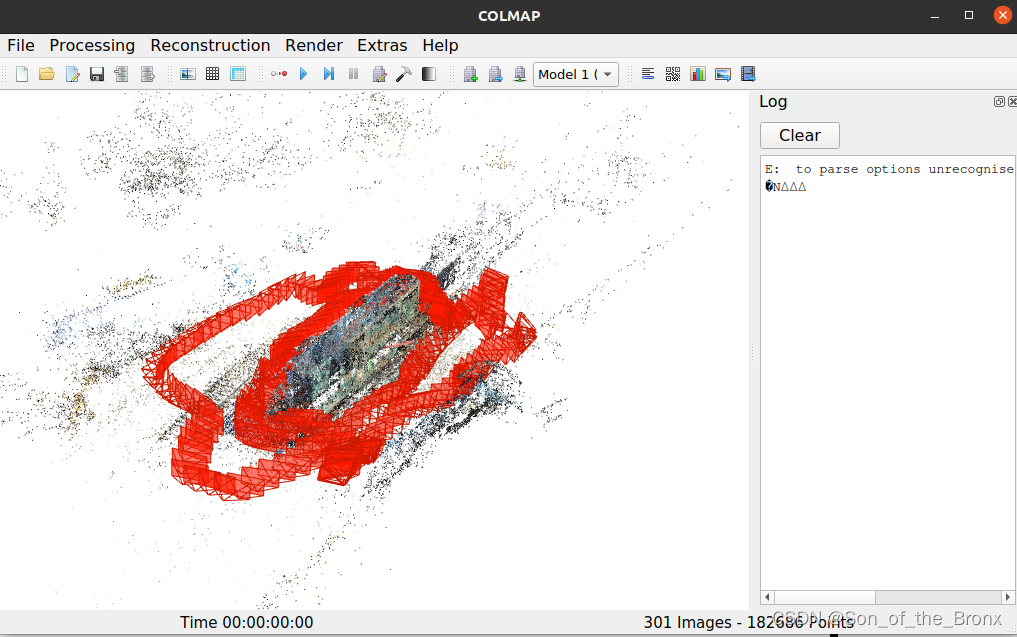
结束
主要是安装依赖的时候,按照官方文档去装,注意配置cmakelist和消去anaconda的影响,就可以装上colmap。
相关文章:
ubuntu20安装colmap
系统环境 ubuntu20 ,cuda11.8 ,也安装了anaconda。因为根据colmap的官方文档说的,如果根据apt-get安装的话,默认是非cuda版本的,而我觉得既然都安装了cuda11.8了,自然也要安装cuda版本的colmap。 安装步骤…...
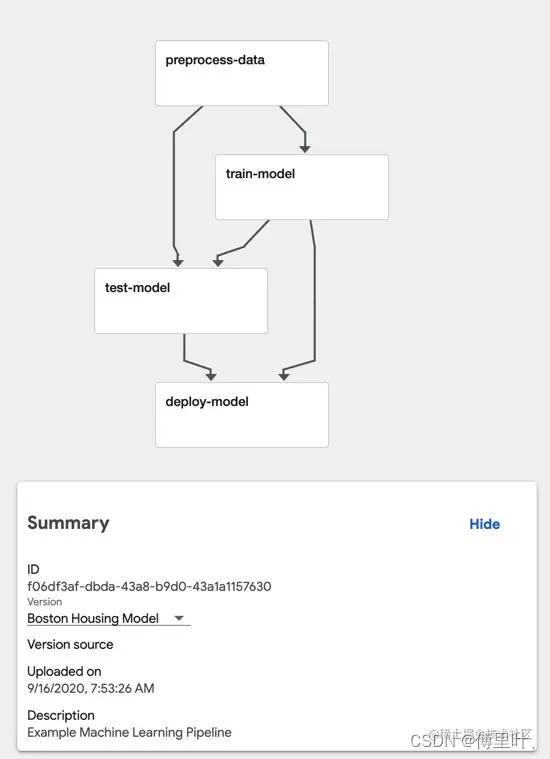
kubeflow简单记录
kubeflow 13.7k star 1、Training Operator 包括PytorchJob和XGboostJob,支持部署pytorch的分布式训练 2、KFServing快捷的部署推理服务 3、Jupyter Notebook 基于Web的交互式工具 4、Katib做超参数优化 5、Pipeline 基于Argo Workflow提供机器学习流程的创建、编排…...

ARM的工作模式
ARM处理器设计有七种工作模式,这些模式允许处理器在不同的情境下以不同的权限级别执行任务,下面是这七大工作模式的概述: 用户模式(User,USR): 这是非特权模式,大多数应用程序在此…...
为家庭公网IP配置DDNS域名
文章目录 域名配置域名更新frp配置修改 在成功完成frp改造Windows笔记本实现家庭版免费内网穿透之后,某天我突然发现内网穿透失效了,一番排查之后原来是路由器对应的公网IP更换了。果然我分到的并不是固定的公网IP,而是会定期变化的。为了免受…...

QT-TCP通信
网上的资料太过于书面化,所以看起来有的让人云里雾里,看不懂C-tcpsockt和S-tcpsocket的关系 所以我稍微画了一下草图帮助大家理解两个套接字之间的关系。字迹有的飘逸勉强看看 下面是代码 服务端: MainWindow::MainWindow(QWidget *parent) …...

SparkSQL优化
SparkSQL优化 优化说明 缓存数据到内存 Spark SQL可以通过调用spark.sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务…...
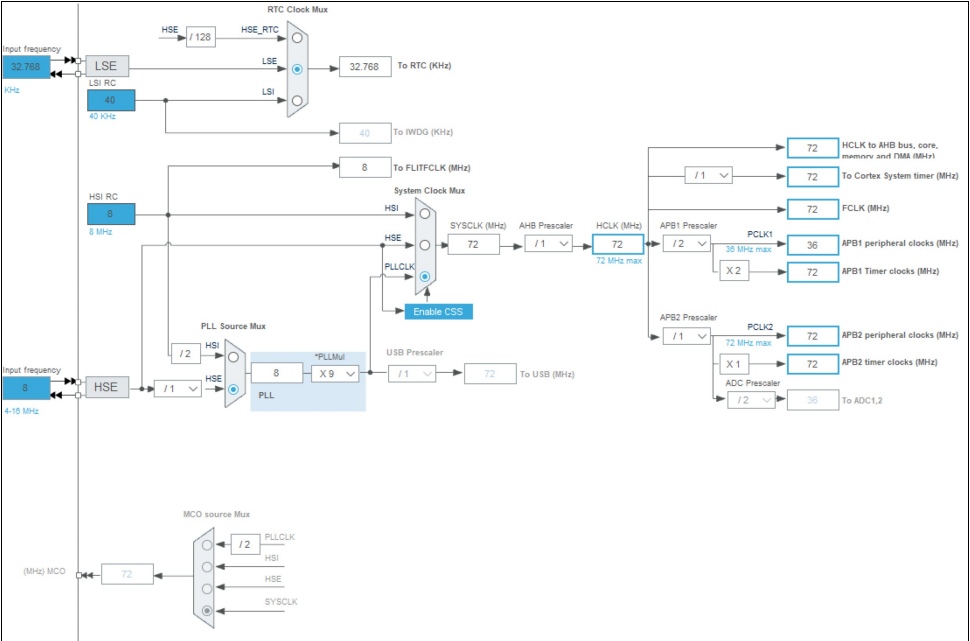
STM32——基础篇
技术笔记! 一、初识STM32 1.1 ARM内核系列 A 系列:Application缩写。高性能应用,比如:手机、电脑、电视等。 R 系列:Real-time缩写。实时性强,汽车电子、军工、无线基带等。 M 系列:Microcont…...
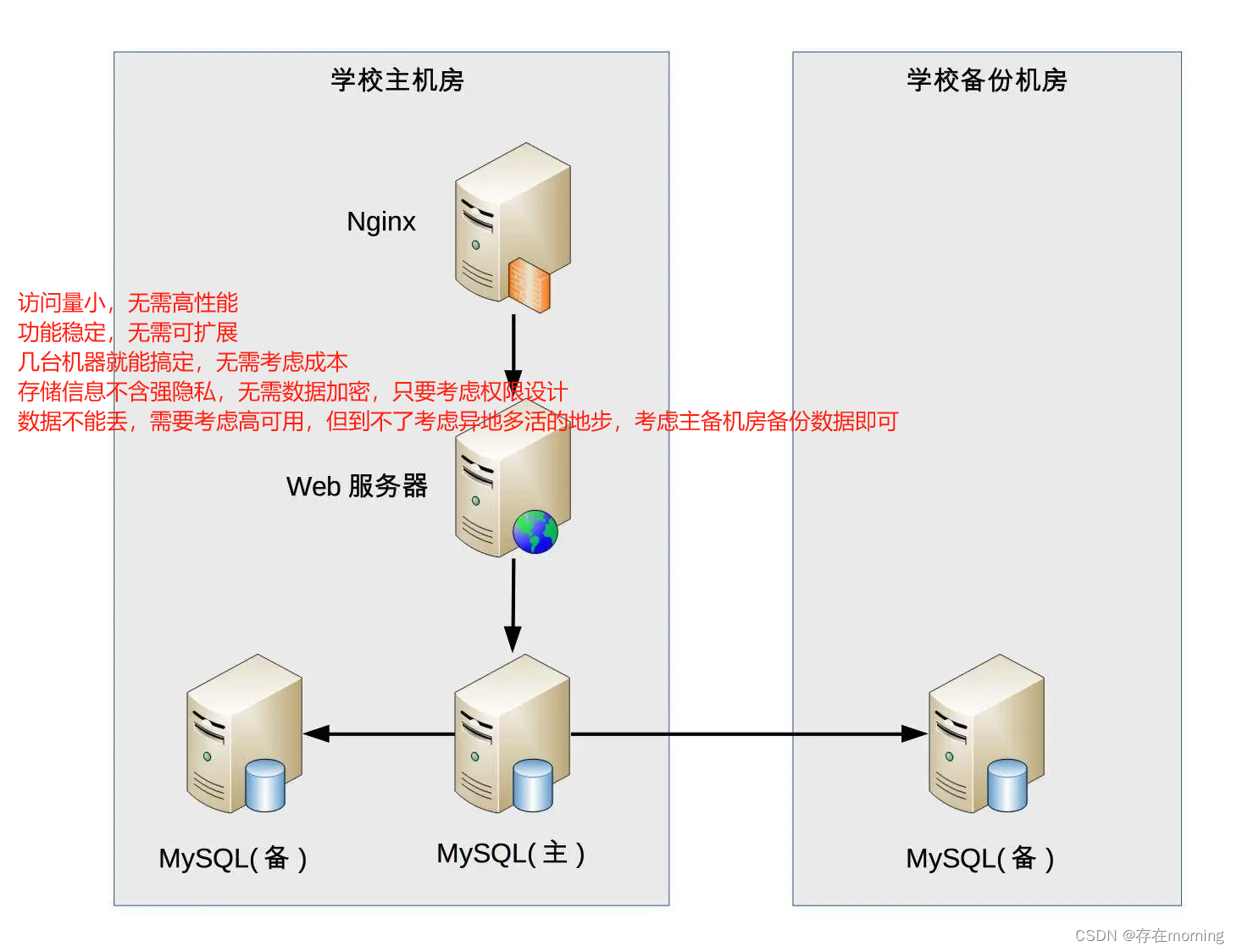
【从零开始学架构 架构基础】架构设计的本质、历史背景和目的
本文是《从零开始学架构》的第一篇学习笔记,主要理解架构的设计的本质定义、历史背景以及目的。 架构设计的本质 分别从三组概念的区别来理解架构设计。 系统与子系统 什么是系统,系统泛指由一群有关联的个体组成,根据某种规则运作&#…...

Learning C# Programming with Unity 3D
作者:Alex Okita 源码地址:GitHub - badkangaroo/UnityProjects: A repo for all of the projects found in the book. 全书 686 页。...

北京车展现场体验商汤DriveAGI自动驾驶大模型展现认知驱动新境界
在2024年北京国际汽车展的舞台上,众多国产车型纷纷亮相,各自展示着独特的魅力。其中,小米SUV7以其精美的外观设计和宽敞的车内空间,吸引了无数目光,成为本届车展上当之无愧的明星。然而,车辆的魅力并不仅限…...
企业终端安全管理软件有哪些?终端安全管理软件哪个好?
终端安全的重要性大家众所周知,关系到生死存亡的东西。 各类终端安全管理软件应运而生,为企业提供全方位、多层次的终端防护。 有哪些企业终端安全管理软件? 一、主流企业终端安全管理软件 1. 域智盾 域智盾是一款专为企业打造的全面终端…...
媒体驱动框架整理--HDMI框架(2))
Linux内核--设备驱动(七)媒体驱动框架整理--HDMI框架(2)
目录 一、引言 二、drm框架 ------>2.1、画布( FrameBuffer ) ------>2.2、绘图现场(CRTC) ------>2.3、输出转换器(Encoder ) ------>2.4、连接器 (Connector ) ------>2.5、显示面(Planner) 三、VOP部分详解 ------>3.1、dts ------>3.2、v…...

3.3 Gateway之自定义过滤器
1.Gateway过滤器种类 过滤器种类描述GatewayFilter路由过滤器,作用于任意指定的路由。默认不生效,要配置到路由后生效GlobalFilter全局过滤器,作用范围是所有路由。声明后自定生效 2.Gateway过滤器参数 参数描述ServerWebExchangeGateway内…...
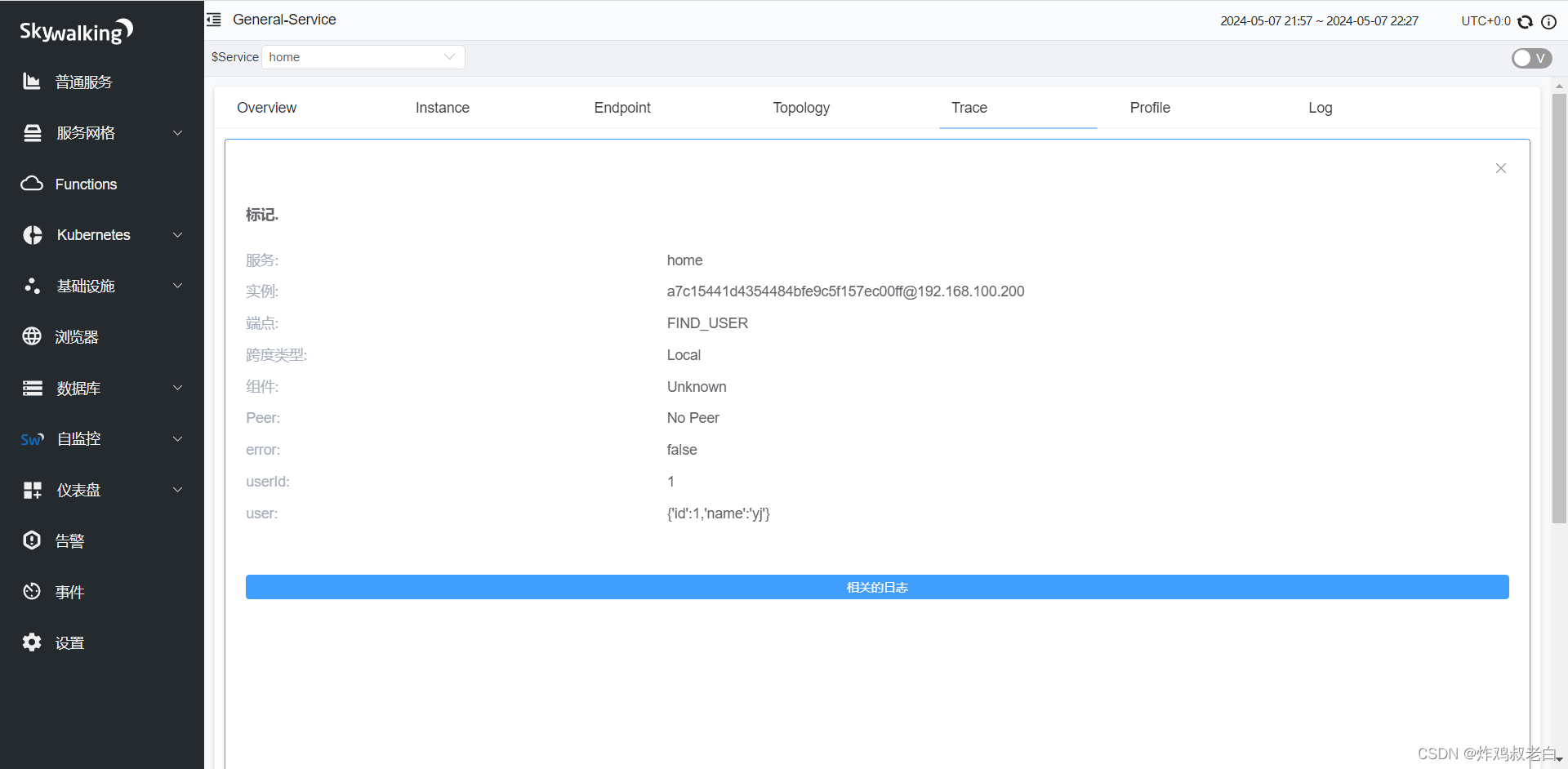
Skywalking数据持久化与自定义链路追踪
学习本篇文章之前首先要了解一下Sky walking的基础知识 分布式链路追踪工具Skywalking详解 一,Sky walking数据持久化 Sky walking提供了es,MySQL等数据持久化方案,默认使用h2基于内存的数据库,重启之后数据即会丢失。 在实际工…...
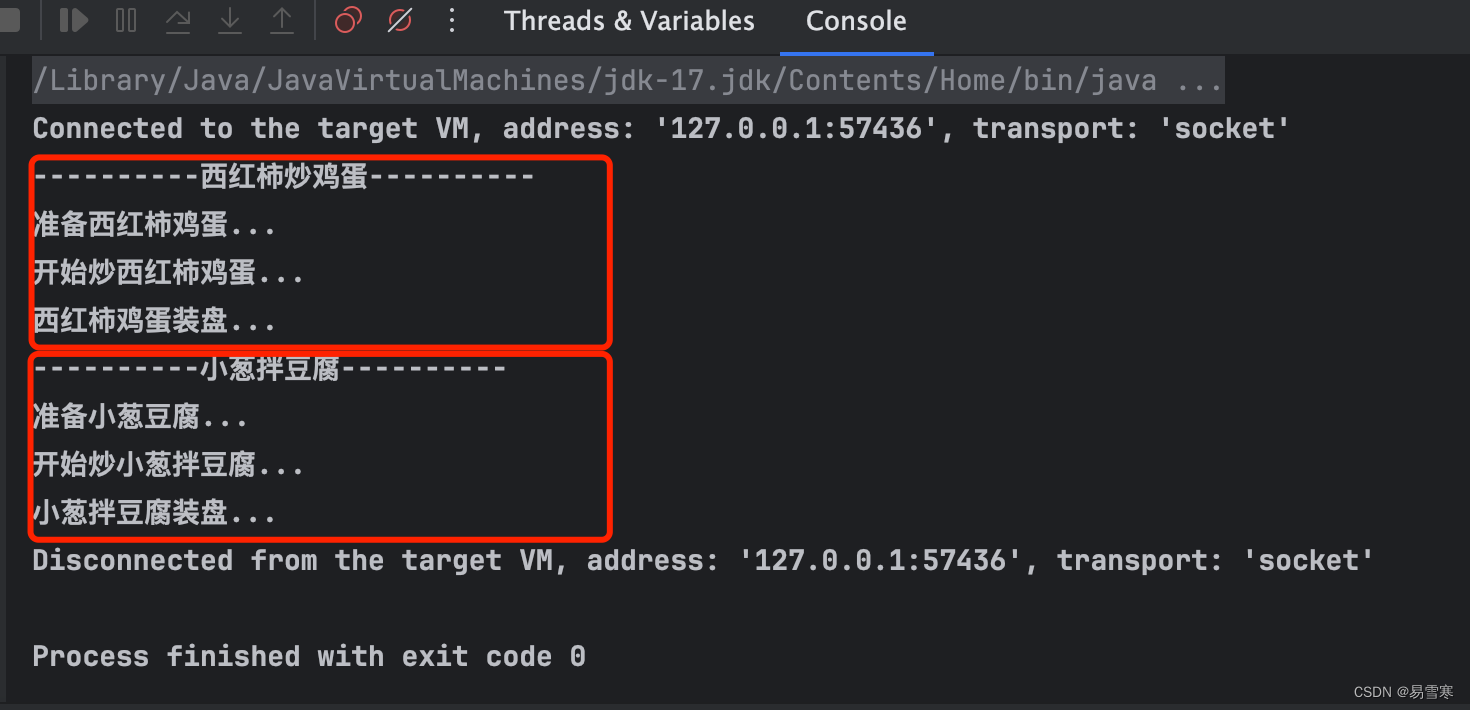
设计模式之模板模式TemplatePattern(五)
一、模板模式介绍 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern), 在一个抽象类公开定义了执行它的方法的模板。它的子类可以更需要重写方法实现,但可以成为典型类中…...
划重点!PMP报考条件、报考步骤、考试内容、适合人群
参加PMP认证的好处,可以从几个方面来认识: 一、参加PMP认证与考试的过程,同时是一个系统学习和巩固项目管理知识的过程 二、参加PMP认证,您可以获得由PMI颁发的PMP证书 而拥有PMP认证表示你已经成为一个项目管理方面的专业人员…...

Java | Leetcode Java题解之第74题搜索二维矩阵
题目: 题解: class Solution {public boolean searchMatrix(int[][] matrix, int target) {int m matrix.length, n matrix[0].length;int low 0, high m * n - 1;while (low < high) {int mid (high - low) / 2 low;int x matrix[mid / n][m…...

C#高级编程笔记-泛型
本章的主要内容如下: ● 泛型概述 ● 创建泛型类 ● 泛型类的特性 ● 泛型接口 ● 泛型结构 ● 泛型方法 目录 1.1 泛型概述 1.1.1 性能 1.1.2 类型安全 1.1.3 二进制代码的重用 1.1.4 代码的扩展 1.1.5 命名…...
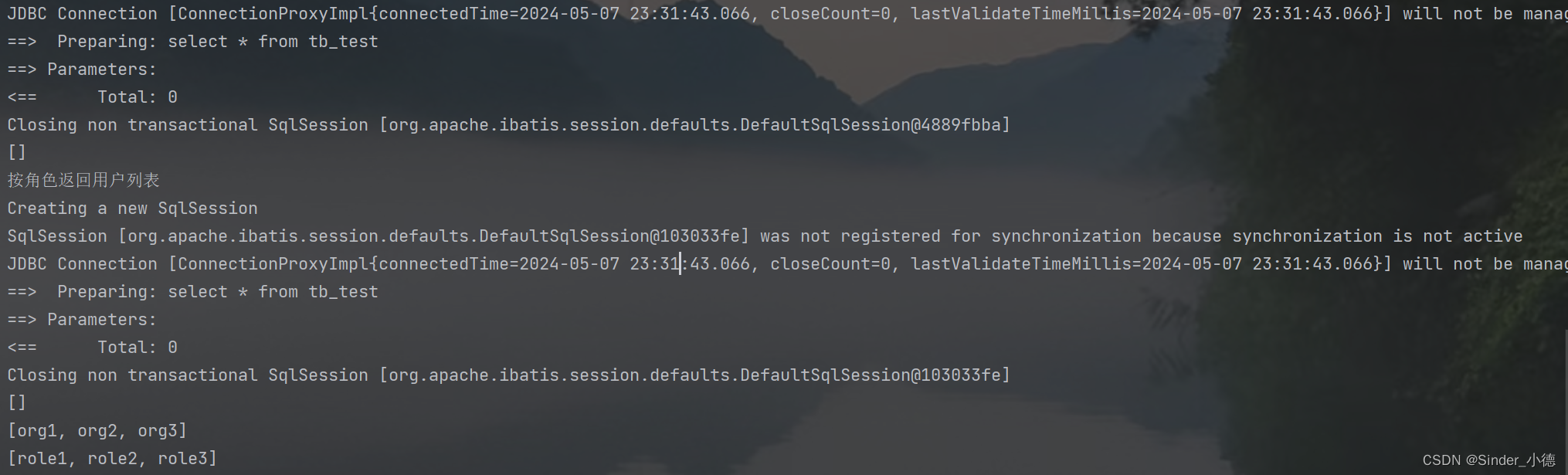
(超简单)SpringBoot中简单用工厂模式来实现
简单讲述业务需求 业务需要根据不同的类型返回不同的用户列表,比如按角色查询用户列表、按机构查询用户列表,用户信息需要从数据库中查询,因为不同的类型查询的逻辑不相同,因此简单用工厂模式来设计一下; 首先新建一个…...

java中的条件、循环和scanner类
if else ; 单行逻辑大括号可以省略;但是不建议省略; public static void main(String[] args) {boolean bool1 (Math.random() * 1000) % 2 > 1;System.out.println((Math.random() * 1000) % 2 "-" bool1);if(bool1) {System.out.prin…...

精准识别胡椒成熟度!YOLO-AVCA-CBAMNet 让智慧农业更高效
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 https://pmc.ncbi.nlm.nih.gov/articles/PMC12830288/ 计算机视觉研究院专栏 Column of Computer Vision Institute 本文提出YOLO-…...
)
ESP8266透传总失败?手把手教你用Arduino IDE和串口助手搞定Blinker配网(避坑大全)
ESP8266透传配置终极指南:从AT指令到Blinker配网全解析 物联网开发者们,是否曾被ESP8266模块的透传配置折磨得焦头烂额?当你在深夜调试AT指令却只收到一堆乱码时,那种挫败感我深有体会。本文将带你彻底攻克这个物联网入门的第一道…...

Air001实战指南:利用Arduino生态快速构建智能硬件原型
1. Air001芯片与Arduino生态的完美结合 第一次拿到Air001开发板时,我完全被它的小巧震惊了——这个只有指甲盖大小的芯片,居然内置了ARM Cortex-M0内核,还能跑48MHz主频。更让我惊喜的是,它完美兼容Arduino生态,这意味…...

告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南
告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在任何设备上流畅玩PC游戏?无论是躺…...

Python DXF文件处理终极指南:使用ezdxf库快速掌握CAD数据操作
Python DXF文件处理终极指南:使用ezdxf库快速掌握CAD数据操作 【免费下载链接】ezdxf Python interface to DXF 项目地址: https://gitcode.com/gh_mirrors/ez/ezdxf Python DXF文件处理在现代工程设计和自动化流程中扮演着重要角色,而ezdxf库正是…...

STM32固件防抄攻略:手把手教你用Programmer CLI读取芯片ID并实现简易加密
STM32固件防抄实战:基于芯片ID的低成本加密方案设计与实现 在硬件产品开发中,固件安全往往是被忽视的一环。许多中小团队在产品量产前夕才意识到,精心设计的电路和算法可能因为固件被轻易复制而失去竞争优势。STM32系列MCU凭借其丰富的产品线…...

CGI Studio 3.11:AI驱动与安全合规的嵌入式HMI开发平台解析
1. 项目概述:为什么我们需要CGI Studio这样的HMI设计工具?在嵌入式系统开发领域,尤其是在汽车、工业和高端家电行业,图形用户界面的复杂度和美观度要求正以前所未有的速度提升。十年前,一个简单的单色LCD屏幕配上几个按…...

当贝叶斯遇见流数据:在线变点检测在IoT异常监控中的实战指南
贝叶斯在线变点检测:IoT实时异常监控的智能引擎 工厂车间里,数百个温度传感器正以每秒10次的频率向中央系统发送数据流。突然,3号机床的轴承温度读数开始出现微妙波动——这是设备过热的早期信号,但传统阈值报警系统却毫无反应。两…...
)
女神异闻录5:皇家版2026最新官方破解版加修改器免费下载 一键转存 永久更新 (看到速转存 资源随时走丢)
下载链接 无形的面具与双面人生:《女神异闻录5:皇家版》深度解析 《女神异闻录5:皇家版》(以下简称“P5R”)是日本知名游戏厂商ATLUS(阿特拉斯)旗下的招牌角色扮演游戏。作为《女神异闻录5》的…...

从提示词到成片:2026年AI视频工作流效率革命——Top 5工具的Prompt工程兼容度、重绘响应延迟与跨平台资产复用率实测
更多请点击: https://intelliparadigm.com 第一章:2026年AI视频生成工具全景图谱与评测方法论 截至2026年,AI视频生成已从实验性原型迈入工业化应用阶段,工具生态呈现“三极分化”格局:消费级轻量工具专注短视频创意提…...