OCR文本识别模型CRNN
CRNN网络结构
论文地址:https://arxiv.org/pdf/1507.05717
参考:https://blog.csdn.net/xiaosongshine/article/details/112198145
git:https://github.com/shuyeah2356/crnn.pytorch
CRNN文本识别实现端到端的不定长文本识别。
CRNN网络把包含三部分:卷积层(CNN)、循环层(RNN)和转录层(CTC loss)
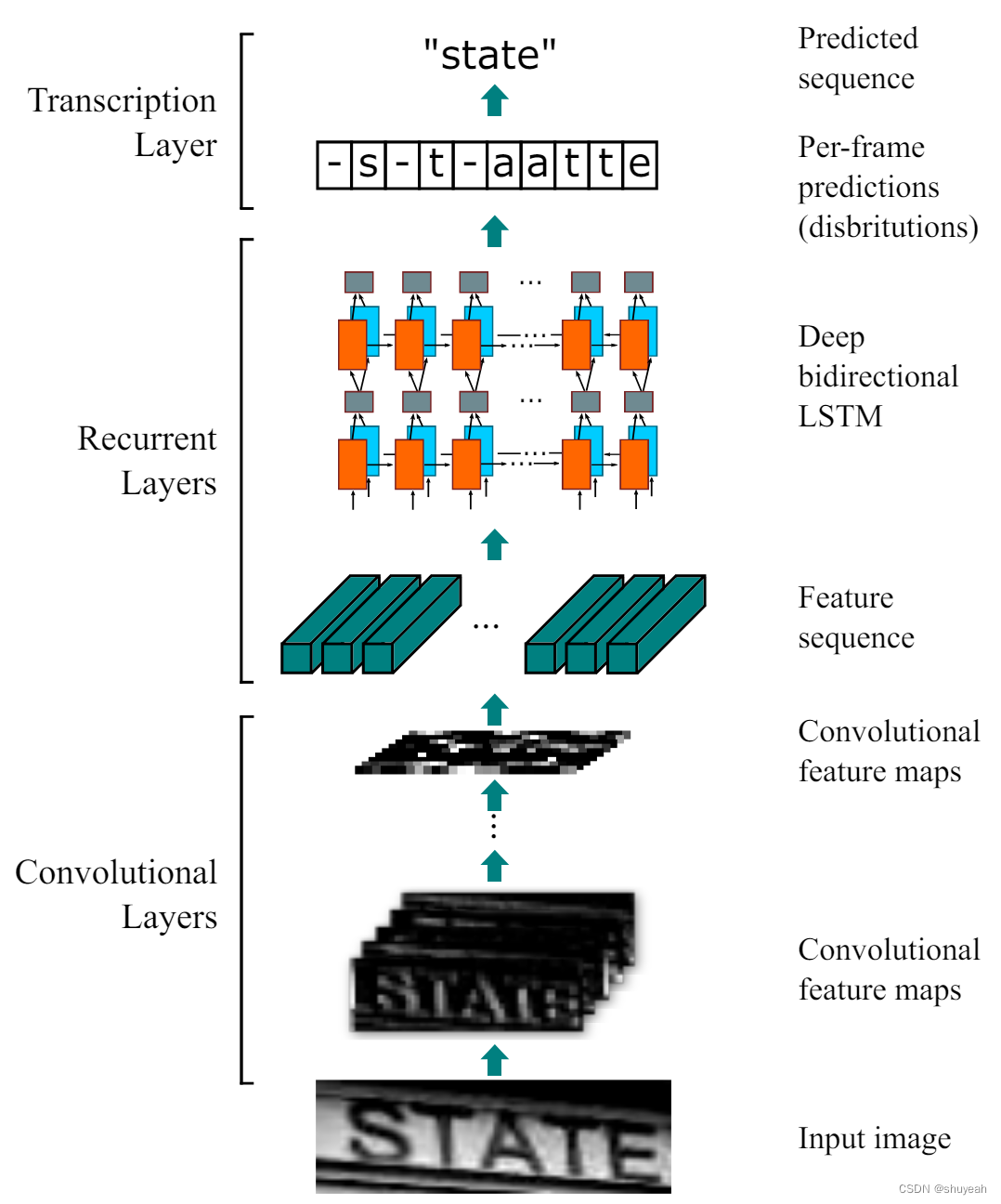
1、卷积层::通过深层卷积操作对输入图像做特征提取,得到特征图;
2、循环层: 循环层使用双向LSTM(BLSTM)对特征序列进行预测,对序列中的每一个特征向量进行学习,并输出预测标签(真实值)的分布;
3、转录层:转录层使用CTC loss ,把循环层获取的一系列标签分布转换成最终的标签序列。
对于输入图片:
输入图像为灰度图(单通道);
高度为32,经过卷积处理后高度变为1;
输入图片宽度为100,输入图片大小为(100,32,1)
CNN输出尺寸为(512, 1, 40),卷积操作输出512个特征图,每一个特征图高度为1,宽度为26。
在代码中有判断图片的高度能够被16整除。
assert imgH % 16 == 0
1、CNN
卷积层用来提取文图像的特征,堆叠使用卷积层和最大池化层,特别的,最后两个最大池化层在宽度和高度上的步长是不相等的池化的窗口尺寸是(w,h):(1,2),因为待识别的文本图片多数是高较小而宽较长,使用1×2的池化窗口尽量不丢失在宽度方向的信息。
卷积操作的具体实现代码:
# 输入图片大小为(160,32,1)
assert imgH % 16 == 0, 'imgH has to be a multiple of 16 图片高度必须为16的倍数'# 一共有7次卷积操作ks = [3, 3, 3, 3, 3, 3, 2] # 卷积层卷积尺寸3表示3x3,2表示2x2ps = [1, 1, 1, 1, 1, 1, 0] # padding大小ss = [1, 1, 1, 1, 1, 1, 1] # stride大小nm = [64, 128, 256, 256, 512, 512, 512] # 卷积核个数,卷积操作输出特征层的通道数cnn = nn.Sequential()def convRelu(i, batchNormalization=False): # 创建卷积层nIn = nc if i == 0 else nm[i - 1] # 确定输入channel维度,如果是第一层网络,输入通道数为图片通道数,输入特征层的通道数为上一个特征层的输出通道数nOut = nm[i] # 确定输出channel维度cnn.add_module('conv{0}'.format(i),nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i])) # 添加卷积层# BN层if batchNormalization:cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))# Relu激活层if leakyRelu:cnn.add_module('relu{0}'.format(i),nn.LeakyReLU(0.2, inplace=True))else:cnn.add_module('relu{0}'.format(i), nn.ReLU(True))# 卷积核大小为3×3,s=1,p=1,输出通道数为64,特征层大小为100×32×64convRelu(0)# 经过2×2Maxpooling,宽高减半,特征层大小变为50×16×64cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2))# 卷积核大小为3×3,s=1,p=1,输出通道数为128,特征层大小为50×16×128convRelu(1)# 经过2×2Maxpooling,宽高减半,特征层大小变为25×8×128cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2))# 卷积核大小为3×3,s=1,p=1,输出通道数为256,特征层大小为25×8×256,卷积后面接BatchNormalizationconvRelu(2, True)# 卷积核大小为3×3,s=1,p=1,输出通道数为256,特征层大小为25×8×256convRelu(3)# 经过MaxPooling,卷积核大小为2×2,在h上stride=2,p=0,s=2,h=(8+0-2)//2+1=4,w上的stride=1,p=1,s=1,w=(25+2-2)//1+1=26通道数不变,26×4×256cnn.add_module('pooling{0}'.format(2),nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 参数 (h, w)# 卷积核大小为3×3,s=1,p=1,输出通道数为512,特征层大小为50×16×512,卷积后面接BatchNormalizationconvRelu(4, True)# 卷积核大小为3×3,s=1,p=1,输出通道数为512,特征层大小为26×4×512convRelu(5)# 经过MaxPooling,卷积核大小为2×2,在h上stride=2,p=0,s=2,h=(4+0-2)//2+1=2,w上的stride=1,p=1,s=1,w=(26+2-2)//1+1=27通道数不变,27×2×512cnn.add_module('pooling{0}'.format(3),nn.MaxPool2d((2, 2), (2, 1), (0, 1)))# 卷积核大小为2×2,s=1,p=0,输出通道数为512,特征层大小为26×1×512convRelu(6, True)
对应的网络结构:
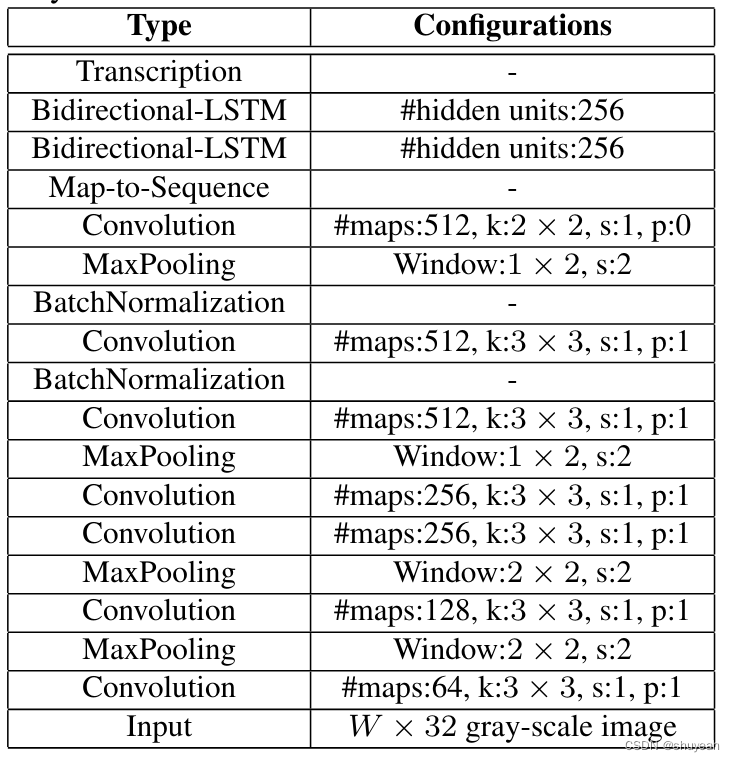
这里卷积操作后的特征图大小为26×1×512
2、RNN
对于卷积操作输出的结果经过处理之后才能输入到RNN中。
卷积操作输出的特征图高度一定为1,代码中也做约束
assert h == 1
将h,w维度合并,合并后的维度变为输入到RNN中的时间不长(time_step),每一个序列的长度为原始特征层的通道数512
输入到LSTM中的特征图大小是多少(面试被问到的问题):
每次输入到LSTM中的特征,时间不长的数量为原始特征的h×w(26),每次输入一个序列,序列长度为原始特征层的通道数512
def forward(self, input):# conv featuresconv = self.cnn(input)b, c, h, w = conv.size()# batch_size,512,1,26assert h == 1, "the height of conv must be 1"# 将宽高维度合并,特征层大小为(batch_size, 512, 26)conv = conv.squeeze(2)# 维度顺序调整(26, batch_size, 512),w作为时间步长(作为LSTM中的一个时间不长time_step)conv = conv.permute(2, 0, 1) # rnn featuresoutput = self.rnn(conv)# print(output.size())return output
序列是按照列从左到右生成的,每一列包含512为特征,输入到LSTM中的第i个特征是特征图第i列像素的连接。

对于卷积操作、Maxpooling层和BatchNormalization卷积操作具有平移不变性。每一个从左到右的序列对应原始图像中的一个矩形区域,且顺序是对应的。特征序列中的每一个向量对一个原图中的一个感受野。

将特征序列按照time_step输入到RNN中,RNN隐藏层的神经元数量为256,使用多层的双向LSTM。
输入时间不长的数量为26,经过RNN得到26个特征向量,输出特征向量的类别分类结果。
每一个特征向量对应的是原图中的一个小的矩形区域。RNN来判断这个矩形区域属于哪个字符。
根据输入的特征向量得到所有字符的softmax概率分布,这是一个长度为待识别字符类别总数量的向量,RNN的输出向量作为转录层CTC的输入。
LSTM实现的代码:
class BidirectionalLSTM(nn.Module):def __init__(self, nIn, nHidden, nOut):super(BidirectionalLSTM, self).__init__()self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True) # nIn:输入神经元个数# *2因为使用双向LSTM,将双向的隐藏层单元拼接在一起,两层个256单元的双向LSTMself.embedding = nn.Linear(nHidden * 2, nOut)def forward(self, input):# 经过RNN输出feature map特征结果recurrent, _ = self.rnn(input)T, b, h = recurrent.size() # T:时间步长,b:batch size,h:hiden unitt_rec = recurrent.view(T * b, h)# 第一次LSTM得到特征层[26×256,256],view成[26, 256, 256]# 第二次LSTM得到特征层[26×256,num_class],view成[26, 256, num_class]output = self.embedding(t_rec) # [T * b, nOut]output = output.view(T, b, -1)return output
# nh为隐藏层神经节点数,nclass为所有识别字符的类别总数
self.rnn = nn.Sequential(BidirectionalLSTM(512, nh, nh), # 输入的时间步长为512BidirectionalLSTM(nh, nh, nclass))
第一次LSTM得到特征层[26×256,256],view成[26, 256, 256]
第二次LSTM得到特征层[26×256,num_class],view成[26, 256, num_class]
3、转录层CTC(Connectionist Temporal Classification)
转录层将RNN对每个特征向量做的预测转换成标签序列的过程。对于不定长序列的对齐问题。
RNN进行序列分类时,可能会出现一个字被识别多次,需要去除冗余机制。
处理的方法(引入blank机制)这一过程称为解码过程:
- 在重复的字符之间增加一个空格‘-’,
- 删除连续重复的字符,
- 再去掉路径中左右的‘-’字符
编码过程是由神经网络来实现的。
文本标签可以有多个不同的字符组合路径得到。
CTC loss如何计算:
在训练阶段根据这些概率分布向量和对应的文本标签计算损失函数。
根据能得到对应标签的所有路径的分数之和类计算损失函数。
每条路径的概率为每一个时间步中对应字符的分数的乘积。CTC损失函数定义为概率的负最大似然函数,为了计算方便对函数取对数。
p(l|y)= ∑ π : B ( π ) p ( π ∣ y ) \sum\limits_{π:B(π)}p(π|y) π:B(π)∑p(π∣y)
预测过程如何实现
先使用标准的CNN网络提取文本特征;
利用BLSTM将特征向量进行融合,已提取字符序列的上下文特征,得到每列特征的概率分布;
最后通过CTC进行预测得到文本序列。
在训练阶段CRNN将特征图像统一缩放到w×32,而在测试阶段对于输入的图片拉伸会导致识别率降低。CRNN保持输入图像尺寸比例,但是图像的高度h必须统一为32,卷积特征图的尺寸动态决定了LSTM的时序长度(时间步长)。
感谢:
https://blog.csdn.net/xiaosongshine/article/details/112198145
https://github.com/meijieru/crnn.pytorch
https://www.bilibili.com/video/BV1Wy4y1473z?p=2&vd_source=91cfed371d5491e2973d221d250b54ae
相关文章:
OCR文本识别模型CRNN
CRNN网络结构 论文地址:https://arxiv.org/pdf/1507.05717 参考:https://blog.csdn.net/xiaosongshine/article/details/112198145 git:https://github.com/shuyeah2356/crnn.pytorch CRNN文本识别实现端到端的不定长文本识别。 CRNN网络把包含三部分&…...

【数据结构】闲谈A股实时交易的数据结构-队列
今天有点忙,特意早起,要不先写点什么。看到个股的红红绿绿, 突然兴起,要不写篇文章分析下A股交易的简易版数据结构。 在A股实时股票交易系统中,按照个人理解,大致会用队列来完成整个交易。队列(…...

深入探索van Emde Boas树:原理、操作与C语言实现
van Emde Boas (vEB) 树是一种高效的数据结构,用于处理整数集合。它是由荷兰计算机科学家Jan van Emde Boas在1977年提出的。vEB树在处理整数集合的查找、插入、删除和迭代操作时,能够以接近最优的时间复杂度运行。vEB树特别适合于那些元素数量在某个较小…...

正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-14-主频和时钟配置
前言: 本文是根据哔哩哔哩网站上“正点原子[第二期]Linux之ARM(MX6U)裸机篇”视频的学习笔记,在这里会记录下正点原子 I.MX6ULL 开发板的配套视频教程所作的实验和学习笔记内容。本文大量引用了正点原子教学视频和链接中的内容。…...
tomcat打开乱码修改端口
将UTF-8改成GBK 如果端口冲突,需要修改tomcat的端口...

03 JavaSE-- 访问控制权限、接口、抽象类、内部类、Object类、异常
1. Exception 异常 在 Java 中,异常分为两种主要类型:强制性异常(Checked Exceptions)和非强制性异常(Unchecked Exceptions)。 强制性异常(Checked Exceptions): 强制…...
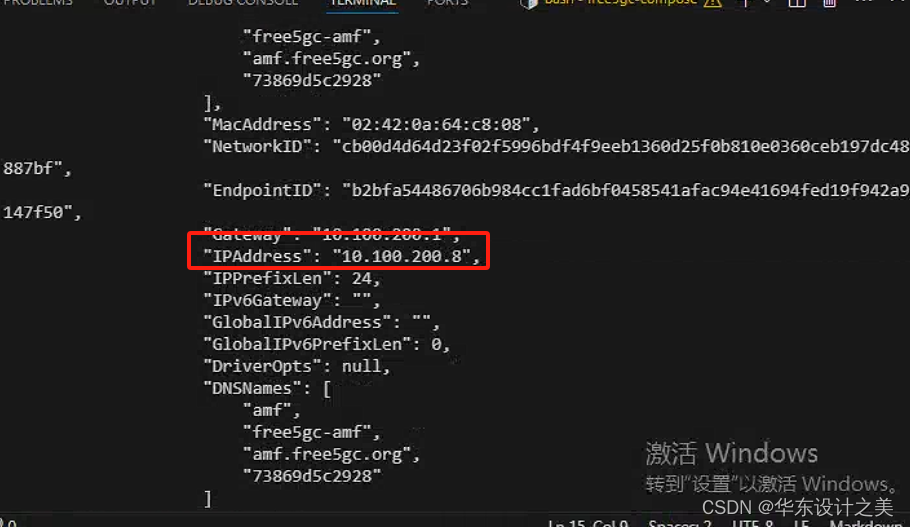
free5gc+ueransim操作
启动free5gc容器 cd ~/free5gc-compose docker-compose up -d 记录虚拟网卡地址,eth0 ifconfig 查看并记录amf网元的ip地址 sudo docker inspect amf "IPAddress"那一行,后面记录的即是amf的ip地址 记录上述两个ip地址,完成UER…...

麦肯锡精英高效阅读法笔记
系列文章目录 如何有效阅读一本书笔记 读懂一本书笔记 麦肯锡精英高效阅读法笔记 文章目录 系列文章目录序章 无法读书的5个理由无法读书的理由① 忙于工作,没时间读书无法读书的理由② 不知应该读什么无法读书的理由③ 没读完的书不断增多无法读书的理由④ 工作繁…...

高速、简单、安全的以太彩光,锐捷网络发布极简以太全光 3.X 方案
从 2021 年 3 月正式推出到现在,锐捷网络极简以太全光方案已经走进第四个年头。IT 仍在不断向前发展,数字化进程深入,数字化业务增多,更广泛的终端设备接入企业级园区网络,对园区网络提出了更高的要求,例如…...

图书管理系统
一、图书管理系统菜单 🍓管理员菜单 1.查找图书 2.新增图书 3.删除图书 4.显示图书 0.退出系统 --------------------------------------------------------------------------------------------------------------------------------- 🌼用户菜…...
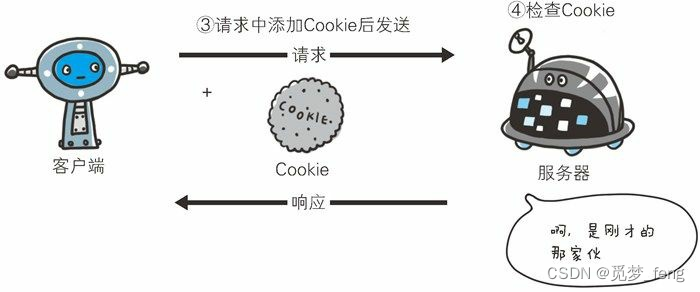
图解HTTP(2、简单的 HTTP 协议)
HTTP 协议用于客户端和服务器端之间的通信 请求访问文本或图像等资源的一端称为客户端,而提供资源响应的一端称为服务器端。 通过请求和响应的交换达成通信 请求必定由客户端发出,而服务器端回复响应报文 请求报文是由请求方法、请求 URI、协议版本、…...

小鹅知识付费系统登录,网课怎么推广与宣传?有啥获客方法?
现在很多教育机构都开始做网络课程,同行之间的竞争也愈发激烈,机构的网课想要盈利就需要对课程进行宣传推广,网课要怎么推广和宣传呢? 在线课程要想推广获客方法有几种,不同推广方法获客效果也是不同的,只有…...
韩顺平0基础学Java——第5天
p72——p86 今天同学跟我说别学java,真的吗?唉,先把这视频干完吧。 逻辑运算符练习 x6,y6 x6,y5 x11,y6 x11,y5 z48 错了&a…...

单片机为什么能直接烧录程序?
在设计芯片的时候,关于烧录的环节是一个不得不考虑的问题。首先排除掉,由外部硬件直接操控FLASH的方案,这个方案有很多缺点。 1、每个IC使用的FLASH型号各不相同,每种型号的FLASH的烧录命令和流程都有差别,这会导致烧…...
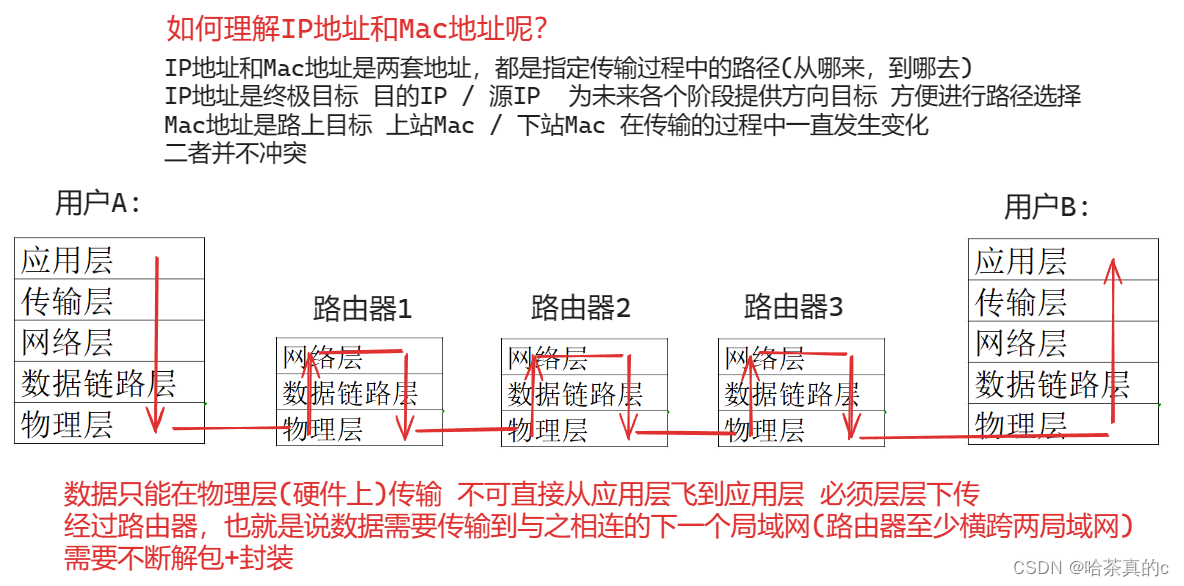
【Linux】25. 网络基础(一)
网络基础(一) 计算机网络背景 网络发展 独立模式: 计算机之间相互独立; 网络互联: 多台计算机连接在一起, 完成数据共享; 其实本质上一台计算机内部也是一个小型网络结构(如果我们将计算机内部某个硬件不存放在电脑中,而是拉根长长的线进行连接。这其实也就是网…...
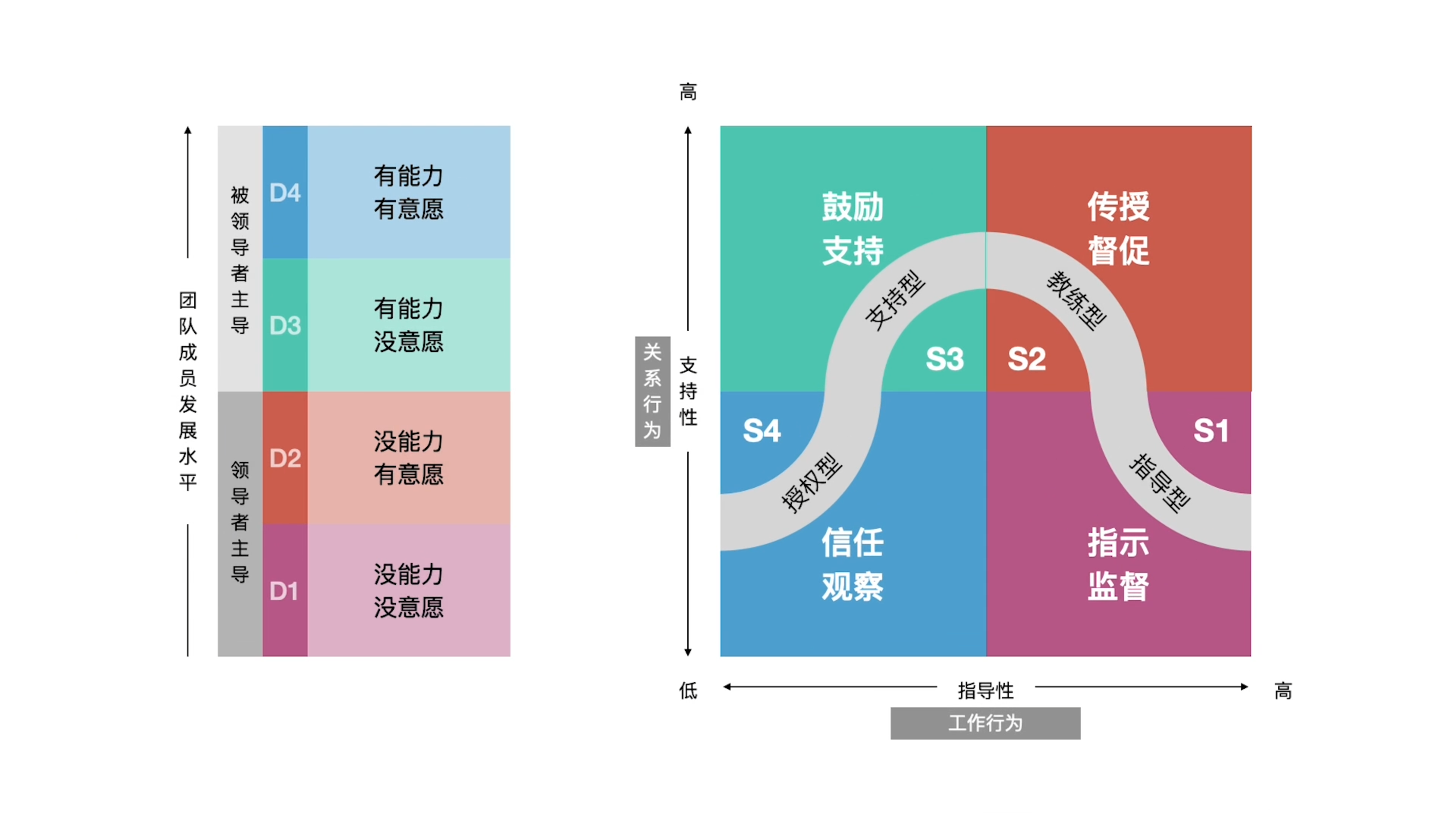
项目经理【人】任务
系列文章目录 【引论一】项目管理的意义 【引论二】项目管理的逻辑 【环境】概述 【环境】原则 【环境】任务 【环境】绩效 【人】概述 【人】原则 【人】任务 一、定义团队的基本规则&塔克曼阶梯理论 1.1 定义团队的基本规则 1.2 塔克曼阶梯理论 二、项目经理管理风格 …...
)
Linux学习(嵌入式硬件知识)
GPU和CPU GPU(Graphics Processing Unit,图形处理单元)和 CPU(Central Processing Unit,中央处理单元)是计算机中两种不同的处理器。它们在功能、设计和用途上有所不同。 CPU(中央处理单元&…...

英语学习笔记4——Is this your ...?
Is this your …? 词汇 Vocabulary suit /sut/ n. 西装,正装 suit 的配套: shirt n. 衬衫tie n. 领带,领结belt n. 腰带trousers n. 裤子shoes n. 鞋子 school /skuːl/ n. 学校 所有学校 搭配:middle school 初中 hig…...

Hive Bucketed Tables 分桶表
Hive Bucketed Tables 分桶表 1.分桶表概念 2.分桶规则 3.语法 4.分桶表的创建 5.分桶表的好处...

【拆位法 决策包容性 位运算】2871. 将数组分割成最多数目的子数组
本文涉及知识点 拆位法 贪心 位运算 决策包容性 位运算、状态压缩、子集状态压缩汇总 LeetCode2871. 将数组分割成最多数目的子数组 给你一个只包含 非负 整数的数组 nums 。 我们定义满足 l < r 的子数组 nums[l…r] 的分数为 nums[l] AND nums[l 1] AND … AND nums[r…...
)
别只傻等候补了!用Bypass分流抢票监控12306“捡漏”全攻略(含微信通知设置)
别只傻等候补了!用Bypass分流抢票监控12306"捡漏"全攻略(含微信通知设置) 春节临近,当你在12306官网上看到心仪车次显示"候补"或"无票"时,是否已经放弃希望?其实,…...

Claude Code + Superpowers 实战:AI 驱动智能客服管理系统开发
当"会干活的 AI"遇上"会按流程干活的 AI",研发效率的质变由此开始 一、引言:AI 编程的"甜蜜陷阱" 在 AI 编程助手普及的今天,你可能有这样的体验: 让 AI "加个购物车功能",它…...

RTX 40系列显卡需求强劲的背后:技术迭代、AI驱动与市场理性回归
1. 项目概述:从“矿难”到“复苏”,显卡市场的十字路口“显卡最坏的日子过去了?”——这大概是过去两年里,每一个关注PC硬件、游戏或者内容创作的玩家和从业者,心里反复掂量过无数次的问题。从2020年底开始,…...

STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战
STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战 嵌入式开发中,SPI接口的Flash存储器因其高速、稳定和易用性而广受欢迎。W25Q128作为一款128Mbit容量的SPI Flash芯片,在数据存储、固件升级等场景中扮演着重要角色。然而&#…...

CANN/asc-devkit Round接口文档
Round 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

[开源] 护理语音医嘱转换系统:面向移动护理终端的结构化记录工具,自动解析床号、操作、参数与通知状态
本项目是一个专为临床一线护士设计的轻量级命令行工具,解决移动护理终端中语音描述转结构化医嘱记录的断点问题。我们不对接医院HIS或EMR系统,也不要求部署服务端,而是以本地可执行方式嵌入护士日常操作流:护士口述「14床测血压&a…...

c++11的初见
列表初始化 c11以后支持{ }的列表初始可以使用{ }括住数据来进行初始化,使用{ }初始化时可以省略号{ }中的数据要匹配构造;使用{ }可以统一初始化方式。#include<iostream> #include<vector> using namespace std; int main(){vector<pai…...

别再死记硬背物联网四层架构了!用LoRa和ESP32手把手搭个智能花盆,实战理解每一层
从智能花盆实战理解物联网四层架构:LoRaESP32全流程拆解 每次翻开物联网教材,总能看到那个经典的四层架构图:感知层、网络层、平台层、应用层。但真正动手做项目时,却发现理论和实践之间隔着一道鸿沟。今天我们就用最接地气的方式…...

通过 Taotoken CLI 工具一键配置开发环境中的多模型访问密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 Taotoken CLI 工具一键配置开发环境中的多模型访问密钥 在接入多个大模型服务时,开发者通常需要为不同的工具&…...
驱动安装与验证)
保姆级教程:在Ubuntu 22.04上搞定DCU-Z100(ZiFang)驱动安装与验证
保姆级教程:在Ubuntu 22.04上搞定DCU-Z100(ZiFang)驱动安装与验证 国产DCU(Deep Computing Unit)正逐渐成为高性能计算领域的新选择,而DCU-Z100(代号ZiFang)作为其中的代表产品&…...