Deeplab的复现(pytorch实现)
DeepLab复现的pytorch实现
本文复现的主要是deeplabv3。使用的数据集和之前发的文章FCN一样,没有了解的可以移步到之前发的文章中去查看一下。
1.该模型的主要结构
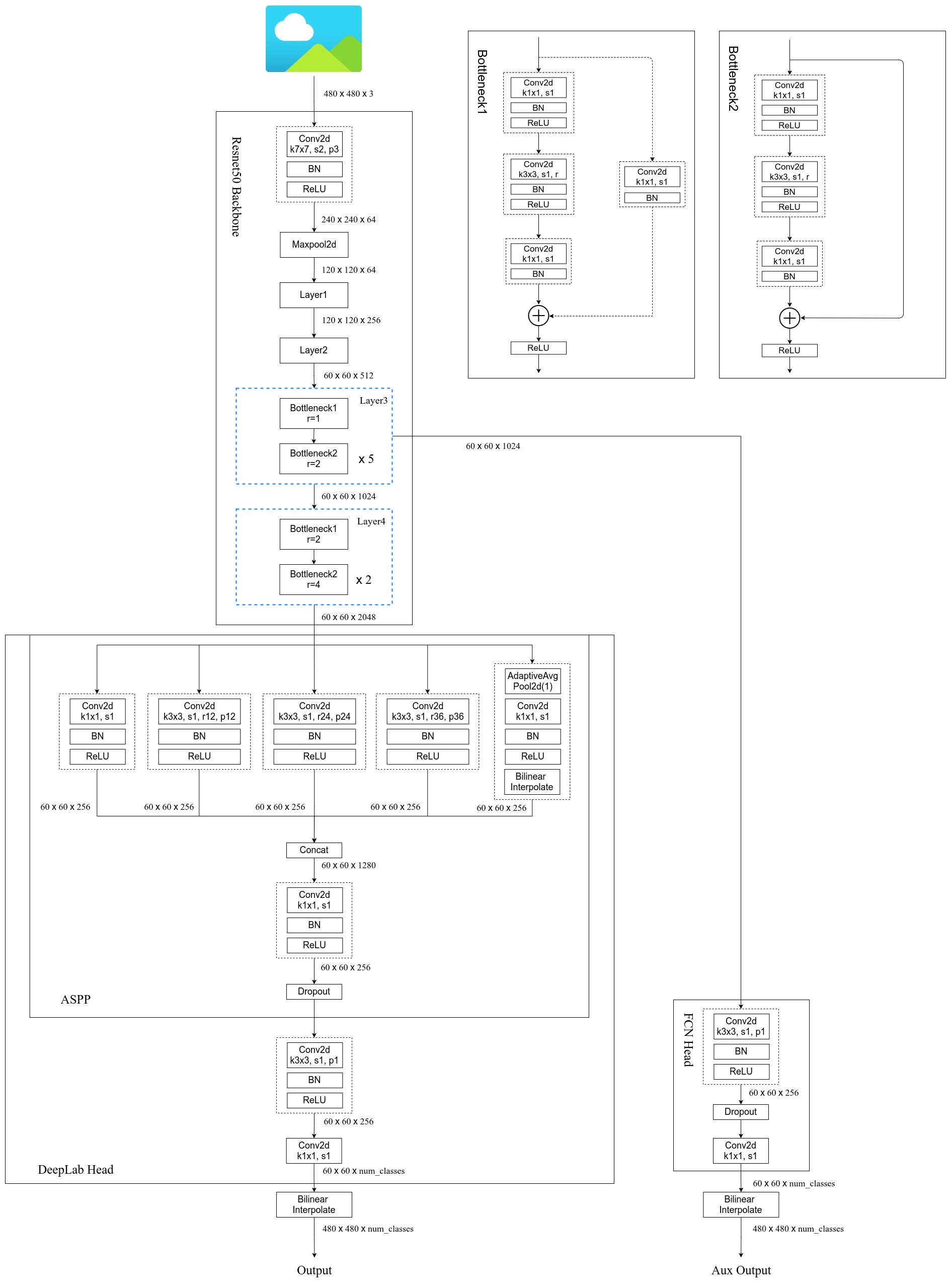
对于代码部分,主要只写了模型部分的,其他部分内容基本和FCN的一致,在下面也会给出完整代码仓库的地址方便大家进行学习。
from collections import OrderedDictfrom typing import Dict, Listimport torch
from torch import nn, Tensor
from torch.nn import functional as F
from .resnet_backbone import resnet50, resnet101
from .mobilenet_backbone import mobilenet_v3_largeclass IntermediateLayerGetter(nn.ModuleDict): # 获取模型指定的中间层输出"""Module wrapper that returns intermediate layers from a modelIt has a strong assumption that the modules have been registeredinto the model in the same order as they are used.This means that one should **not** reuse the same nn.Moduletwice in the forward if you want this to work.Additionally, it is only able to query submodules that are directlyassigned to the model. So if `model` is passed, `model.feature1` canbe returned, but not `model.feature1.layer2`.Args:model (nn.Module): model on which we will extract the featuresreturn_layers (Dict[name, new_name]): a dict containing the namesof the modules for which the activations will be returned asthe key of the dict, and the value of the dict is the nameof the returned activation (which the user can specify)."""_version = 2__annotations__ = {"return_layers": Dict[str, str],}def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:if not set(return_layers).issubset([name for name, _ in model.named_children()]):raise ValueError("return_layers are not present in model")orig_return_layers = return_layersreturn_layers = {str(k): str(v) for k, v in return_layers.items()}# 重新构建backbone,将没有使用到的模块全部删掉layers = OrderedDict()for name, module in model.named_children():layers[name] = moduleif name in return_layers:del return_layers[name]if not return_layers:breaksuper(IntermediateLayerGetter, self).__init__(layers)self.return_layers = orig_return_layersdef forward(self, x: Tensor) -> Dict[str, Tensor]:out = OrderedDict()for name, module in self.items():x = module(x)if name in self.return_layers:out_name = self.return_layers[name]out[out_name] = xreturn outclass DeepLabV3(nn.Module):"""Implements DeepLabV3 model from`"Rethinking Atrous Convolution for Semantic Image Segmentation"<https://arxiv.org/abs/1706.05587>`_.Args:backbone (nn.Module): the network used to compute the features for the model.The backbone should return an OrderedDict[Tensor], with the key being"out" for the last feature map used, and "aux" if an auxiliary classifieris used.classifier (nn.Module): module that takes the "out" element returned fromthe backbone and returns a dense prediction.aux_classifier (nn.Module, optional): auxiliary classifier used during training"""__constants__ = ['aux_classifier']def __init__(self, backbone, classifier, aux_classifier=None):super(DeepLabV3, self).__init__()self.backbone = backboneself.classifier = classifierself.aux_classifier = aux_classifierdef forward(self, x: Tensor) -> Dict[str, Tensor]:input_shape = x.shape[-2:]# contract: features is a dict of tensorsfeatures = self.backbone(x)result = OrderedDict()x = features["out"]x = self.classifier(x)# 使用双线性插值还原回原图尺度x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)result["out"] = xif self.aux_classifier is not None:x = features["aux"]x = self.aux_classifier(x)# 使用双线性插值还原回原图尺度x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)result["aux"] = xreturn resultclass FCNHead(nn.Sequential):def __init__(self, in_channels, channels):inter_channels = in_channels // 4 # 两个//表示地板除,即先做除法,然后向下取整super(FCNHead, self).__init__(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),nn.BatchNorm2d(inter_channels),nn.ReLU(),nn.Dropout(0.1),nn.Conv2d(inter_channels, channels, 1))class ASPPConv(nn.Sequential):def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:super(ASPPConv, self).__init__(nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())class ASPPPooling(nn.Sequential):def __init__(self, in_channels: int, out_channels: int) -> None:super(ASPPPooling, self).__init__(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())def forward(self, x: torch.Tensor) -> torch.Tensor:size = x.shape[-2:]for mod in self:x = mod(x)return F.interpolate(x, size=size, mode='bilinear', align_corners=False)class ASPP(nn.Module):def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:super(ASPP, self).__init__()modules = [nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())]rates = tuple(atrous_rates)for rate in rates:modules.append(ASPPConv(in_channels, out_channels, rate))modules.append(ASPPPooling(in_channels, out_channels))self.convs = nn.ModuleList(modules)self.project = nn.Sequential(nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Dropout(0.5))def forward(self, x: torch.Tensor) -> torch.Tensor:_res = []for conv in self.convs:_res.append(conv(x))res = torch.cat(_res, dim=1)return self.project(res)class DeepLabHead(nn.Sequential):def __init__(self, in_channels: int, num_classes: int) -> None:super(DeepLabHead, self).__init__(ASPP(in_channels, [12, 24, 36]),nn.Conv2d(256, 256, 3, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, num_classes, 1))def deeplabv3_resnet50(aux, num_classes=21, pretrain_backbone=False):# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'# 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth'backbone = resnet50(replace_stride_with_dilation=[False, True, True])if pretrain_backbone:# 载入resnet50 backbone预训练权重backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))out_inplanes = 2048aux_inplanes = 1024return_layers = {'layer4': 'out'}if aux:return_layers['layer3'] = 'aux'backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return modeldef deeplabv3_resnet101(aux, num_classes=21, pretrain_backbone=False):# 'resnet101_imagenet': 'https://download.pytorch.org/models/resnet101-63fe2227.pth'# 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth'backbone = resnet101(replace_stride_with_dilation=[False, True, True])if pretrain_backbone:# 载入resnet101 backbone预训练权重backbone.load_state_dict(torch.load("resnet101.pth", map_location='cpu'))out_inplanes = 2048aux_inplanes = 1024return_layers = {'layer4': 'out'}if aux:return_layers['layer3'] = 'aux'backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return modeldef deeplabv3_mobilenetv3_large(aux, num_classes=21, pretrain_backbone=False):# 'mobilenetv3_large_imagenet': 'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'# 'depv3_mobilenetv3_large_coco': "https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth"backbone = mobilenet_v3_large(dilated=True)if pretrain_backbone:# 载入mobilenetv3 large backbone预训练权重backbone.load_state_dict(torch.load("mobilenet_v3_large.pth", map_location='cpu'))backbone = backbone.features# Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.# The first and last blocks are always included because they are the C0 (conv1) and Cn.stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "is_strided", False)] + [len(backbone) - 1]out_pos = stage_indices[-1] # use C5 which has output_stride = 16out_inplanes = backbone[out_pos].out_channelsaux_pos = stage_indices[-4] # use C2 here which has output_stride = 8aux_inplanes = backbone[aux_pos].out_channelsreturn_layers = {str(out_pos): "out"}if aux:return_layers[str(aux_pos)] = "aux"backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return model----------------------------------------------------------------------------------分割线-------------------------------------------from typing import Callable, List, Optionalimport torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partialdef _make_divisible(ch, divisor=8, min_ch=None): # 为了使每一层的通道数都可以被8整除"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_ch is None:min_ch = divisornew_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_ch < 0.9 * ch:new_ch += divisorreturn new_chclass ConvBNActivation(nn.Sequential):def __init__(self,in_planes: int,out_planes: int,kernel_size: int = 3,stride: int = 1,groups: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,activation_layer: Optional[Callable[..., nn.Module]] = None,dilation: int = 1):padding = (kernel_size - 1) // 2 * dilationif norm_layer is None:norm_layer = nn.BatchNorm2dif activation_layer is None:activation_layer = nn.ReLU6super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,dilation=dilation,padding=padding,groups=groups,bias=False),norm_layer(out_planes),activation_layer(inplace=True))self.out_channels = out_planesclass SqueezeExcitation(nn.Module):def __init__(self, input_c: int, squeeze_factor: int = 4):super(SqueezeExcitation, self).__init__()squeeze_c = _make_divisible(input_c // squeeze_factor, 8)self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)def forward(self, x: Tensor) -> Tensor:scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))scale = self.fc1(scale)scale = F.relu(scale, inplace=True)scale = self.fc2(scale)scale = F.hardsigmoid(scale, inplace=True)return scale * xclass InvertedResidualConfig:def __init__(self,input_c: int,kernel: int,expanded_c: int,out_c: int,use_se: bool,activation: str,stride: int,dilation: int,width_multi: float):self.input_c = self.adjust_channels(input_c, width_multi)self.kernel = kernelself.expanded_c = self.adjust_channels(expanded_c, width_multi)self.out_c = self.adjust_channels(out_c, width_multi)self.use_se = use_seself.use_hs = activation == "HS" # whether using h-swish activationself.stride = strideself.dilation = dilation@staticmethoddef adjust_channels(channels: int, width_multi: float):return _make_divisible(channels * width_multi, 8)class InvertedResidual(nn.Module):def __init__(self,cnf: InvertedResidualConfig,norm_layer: Callable[..., nn.Module]):super(InvertedResidual, self).__init__()if cnf.stride not in [1, 2]:raise ValueError("illegal stride value.")self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)layers: List[nn.Module] = []activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU# expandif cnf.expanded_c != cnf.input_c:layers.append(ConvBNActivation(cnf.input_c,cnf.expanded_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer))# depthwisestride = 1 if cnf.dilation > 1 else cnf.stridelayers.append(ConvBNActivation(cnf.expanded_c,cnf.expanded_c,kernel_size=cnf.kernel,stride=stride,dilation=cnf.dilation,groups=cnf.expanded_c,norm_layer=norm_layer,activation_layer=activation_layer))if cnf.use_se:layers.append(SqueezeExcitation(cnf.expanded_c))# projectlayers.append(ConvBNActivation(cnf.expanded_c,cnf.out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity))self.block = nn.Sequential(*layers)self.out_channels = cnf.out_cself.is_strided = cnf.stride > 1def forward(self, x: Tensor) -> Tensor:result = self.block(x)if self.use_res_connect:result += xreturn resultclass MobileNetV3(nn.Module):def __init__(self,inverted_residual_setting: List[InvertedResidualConfig],last_channel: int,num_classes: int = 1000,block: Optional[Callable[..., nn.Module]] = None,norm_layer: Optional[Callable[..., nn.Module]] = None):super(MobileNetV3, self).__init__()if not inverted_residual_setting:raise ValueError("The inverted_residual_setting should not be empty.")elif not (isinstance(inverted_residual_setting, List) andall([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")if block is None:block = InvertedResidualif norm_layer is None:norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)layers: List[nn.Module] = []# building first layerfirstconv_output_c = inverted_residual_setting[0].input_clayers.append(ConvBNActivation(3,firstconv_output_c,kernel_size=3,stride=2,norm_layer=norm_layer,activation_layer=nn.Hardswish))# building inverted residual blocksfor cnf in inverted_residual_setting:layers.append(block(cnf, norm_layer))# building last several layerslastconv_input_c = inverted_residual_setting[-1].out_clastconv_output_c = 6 * lastconv_input_clayers.append(ConvBNActivation(lastconv_input_c,lastconv_output_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Hardswish))self.features = nn.Sequential(*layers)self.avgpool = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),nn.Hardswish(inplace=True),nn.Dropout(p=0.2, inplace=True),nn.Linear(last_channel, num_classes))# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def _forward_impl(self, x: Tensor) -> Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef forward(self, x: Tensor) -> Tensor:return self._forward_impl(x)def mobilenet_v3_large(num_classes: int = 1000,reduced_tail: bool = False,dilated: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation.dilated: whether using dilated conv"""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1dilation = 2 if dilated else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilationbneck_conf(16, 3, 16, 16, False, "RE", 1, 1),bneck_conf(16, 3, 64, 24, False, "RE", 2, 1), # C1bneck_conf(24, 3, 72, 24, False, "RE", 1, 1),bneck_conf(24, 5, 72, 40, True, "RE", 2, 1), # C2bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),bneck_conf(40, 3, 240, 80, False, "HS", 2, 1), # C3bneck_conf(80, 3, 200, 80, False, "HS", 1, 1),bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),bneck_conf(80, 3, 480, 112, True, "HS", 1, 1),bneck_conf(112, 3, 672, 112, True, "HS", 1, 1),bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2, dilation), # C4bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),]last_channel = adjust_channels(1280 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)def mobilenet_v3_small(num_classes: int = 1000,reduced_tail: bool = False,dilated: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation.dilated: whether using dilated conv"""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1dilation = 2 if dilated else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilationbneck_conf(16, 3, 16, 16, True, "RE", 2, 1), # C1bneck_conf(16, 3, 72, 24, False, "RE", 2, 1), # C2bneck_conf(24, 3, 88, 24, False, "RE", 1, 1),bneck_conf(24, 5, 96, 40, True, "HS", 2, 1), # C3bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),bneck_conf(40, 5, 120, 48, True, "HS", 1, 1),bneck_conf(48, 5, 144, 48, True, "HS", 1, 1),bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2, dilation), # C4bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation),bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation)]last_channel = adjust_channels(1024 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)在上述代码中,也将之前FCNmodel中没有的mobilenet作为backbone的模型代码也加了上来。
参考链接:
288, 96 // reduce_divider, True, “HS”, 2, dilation), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, “HS”, 1, dilation),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, “HS”, 1, dilation)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)
在上述代码中,也将之前FCNmodel中没有的mobilenet作为backbone的模型代码也加了上来。参考链接:[deep-learning-for-image-processing/pytorch_segmentation/fcn/src/fcn_model.py at bf4384bfc14e295fdbdc967d6b5093cce0bead17 · WZMIAOMIAO/deep-learning-for-image-processing (github.com)](https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/bf4384bfc14e295fdbdc967d6b5093cce0bead17/pytorch_segmentation/fcn/src/fcn_model.py)
相关文章:
Deeplab的复现(pytorch实现)
DeepLab复现的pytorch实现 本文复现的主要是deeplabv3。使用的数据集和之前发的文章FCN一样,没有了解的可以移步到之前发的文章中去查看一下。 1.该模型的主要结构 对于代码部分,主要只写了模型部分的,其他部分内容基本和FCN的一致…...

input上添加disabled=“true“,点击事件失效处理办法
当我们给input标签上添加disabled"true"时,再添加点击事件,点击事件会不生效,处理办法如下: 给input标签添加样式style"pointer-events: none;" 代码如下: <input style"pointer-event…...

精酿啤酒的魅力:啤酒的与众不同风味
啤酒,作为世界上古老的酒精饮品之一,一直以来都以其与众不同的魅力吸引着无数人的味蕾。而精酿啤酒,作为啤酒中的佼佼者之一,更是以其丰富的口感和多样的风格,成为了啤酒爱好者的心头好。在这其中,Fendi cl…...

检测机构的双资质是什么?
CMA和CNAS是两种在检测、校准和认证领域具有权威性的资质。 CMA资质全称为“检验检测机构资质认定”(China Inspection Body and Laboratory Mandatory Approval)。它是根据《中华人民共和国计量法》等相关法规,由国家认证认可监督管理委员会…...
基于springboot的校园食堂订餐系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式 🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 &…...
基于SpringBoot的高校推荐系统
项目介绍 当前,随着高等教育的不断普及,越来越多的学生选择考研究生来提高自身的学术水平和竞争力。然而,考研生在选择报考院校和专业时面临着众多的选择和信息不对称的问题。为了解决这些问题,一些网站和APP已经推出了相关的院校…...

了解 websocket
1. 概念 1、 websocket 是一种双向通行协议。实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的; 2、websocket连接成功后,只要连接不断开,通信就会一保持着; 3、要打开一个 WebS…...

C++中erase函数的用法
在C中,erase函数用于从容器中删除一个或一系列元素。它通常用于删除容器中的指定位置的元素或特定值的元素。 erase函数通常有两种用法: 删除指定位置的元素:erase(iterator position) 这种用法会删除容器中迭代器position指向的元素。 st…...

数字旅游以科技创新为核心竞争力:推动旅游服务的智能化、高效化,满足游客日益增长的旅游需求
一、引言 随着科技的飞速发展,数字旅游作为旅游业与信息技术结合的产物,正以其独特的魅力改变着传统旅游业的格局。科技创新作为数字旅游的核心竞争力,不仅推动了旅游服务的智能化、高效化,更满足了游客日益增长的旅游需求。本文…...
(MATLAB)安装指南
参考链接:MATLAB2019a安装教程(避坑版)...

社区智能奶柜:创业新机遇
社区智能奶柜:创业新机遇 在追求高质量生活的今天,健康食品成为大众焦点。社区智能奶柜适时登台,革新了居民获取新鲜牛奶的传统模式,为创业者开辟了一片蓝海市场。 一、新兴创业蓝海:牛奶随享站 日常膳食中…...

地盘紧固的关键技术——SunTorque智能扭矩系统
底盘紧固件是汽车底盘系统中不可或缺的一部分,它们负责连接和固定各个部件,确保车辆行驶的安全和稳定。底盘紧固件的开发涉及到多个环节和关键技术,下面SunTorque智能扭矩系统将详细介绍底盘紧固件开发流程和关键技术。 一、底盘紧固件开发的…...

Mybatis plus update PG json 类型 报错解决
Mybatis plus update PG json 类型 报错解决 1. 定义的PG数据库对象2. 自定义 JSON Handler3. update Wrapper4. update 报错信息4.1 No hstore extension installed.4.2 Error setting non null for parameter #1 with JdbcType null . Try setting a different JdbcType for …...

精通 Docker:简化开发、部署与安全保障
踏上 Docker 之旅,每一条命令都是高效与可靠的新境界。Docker 彻底改变了软件开发,为构建、部署和保障应用程序提供了前所未有的便利。从打造精益敏捷的镜像到编排复杂的微服务架构,Docker 让开发人员和运维人员都倍感轻松。让我们深入探索 D…...
)
KIMI的API使用:重点是他的API在使用的适合可以实时调用tool(外部联网等)
User: 如何获取kimi 的API Kimi: 要获取Kimi的API,您需要按照以下步骤操作: 注册账号:首先,您需要访问Kimi开放平台(platform.moonshot.cn/console)并注册一个账号。 获取API Key:登录后,在平台的“账户总览”部分查看平台赠送的免费额度。然后,点击“API Key 管理”…...

Android内核之Binder读写通信:binder_ioctl_write_read用法实例(七十)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
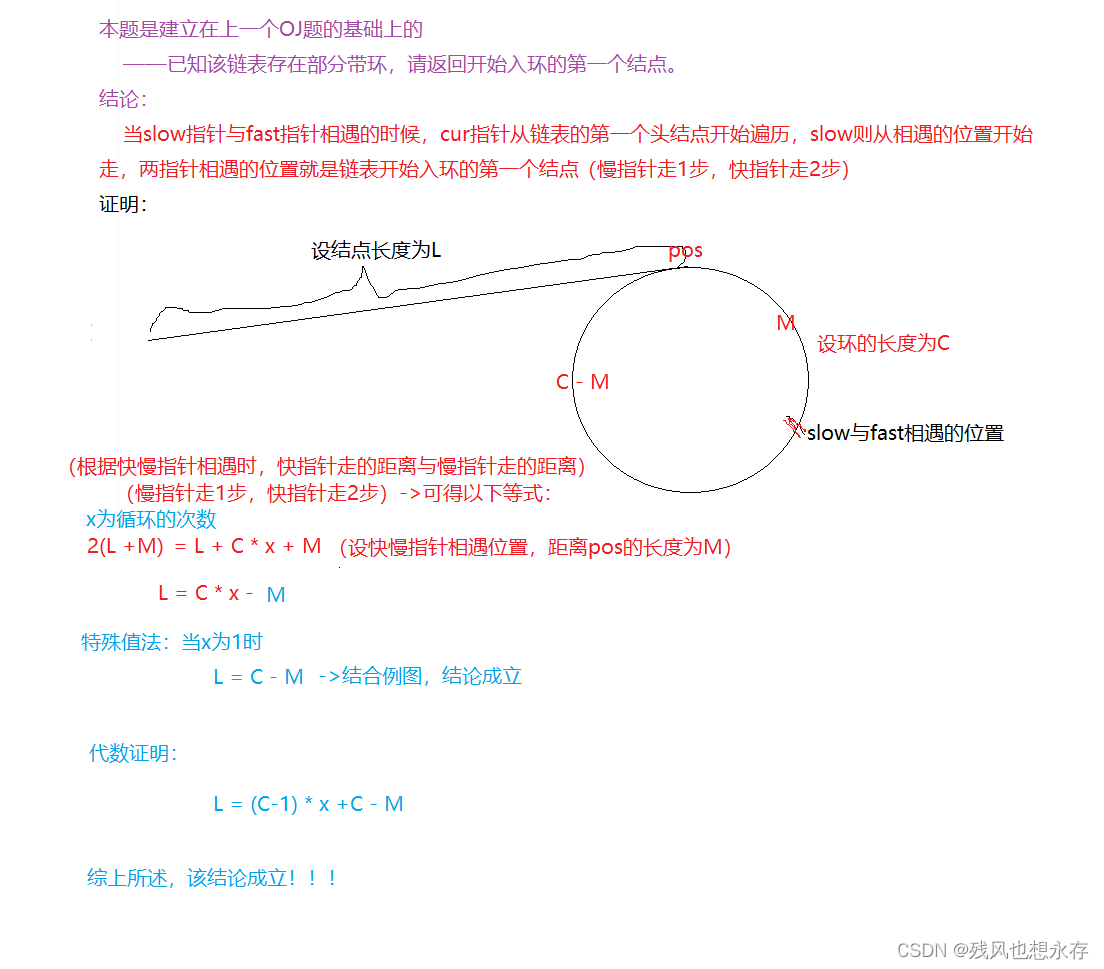
【C语言/数据结构】经典链表OJ习题~第二期——链中寻环
🎈🎈🎈欢迎采访小残风的博客主页:残风也想永存-CSDN博客🎈🎈🎈 🎈🎈🎈本人码云 链接:残风也想永存 (FSRMWK) - Gitee.com🎈…...
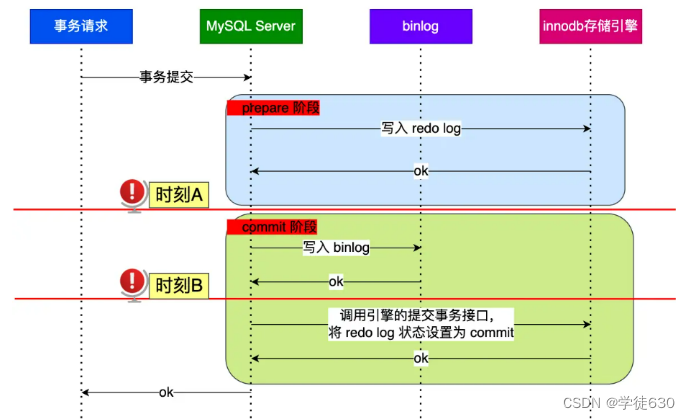
MySQL日志机制【undo log、redo log、binlog 】
前言 SQL执行流程图文分析:从连接到执行的全貌_一条 sql 执行的全流程?-CSDN博客文章浏览阅读1.1k次,点赞20次,收藏12次。本文探讨 MySQL 执行一条 SQL 查询语句的详细流程,从连接器开始,逐步介绍了查询缓存、解析 S…...

SSL通信、证书认证原理和失败原因
目录 SSL通信SSL认证原理SSL证书认证失败的原因分析 SSL通信 SSL通信指的是使用SSL(Secure Sockets Layer)协议进行的加密通讯。SSL是一种标准的安全技术,用于建立一个加密链接,确保从用户的浏览器到服务器之间的数据传输是私密和…...

【MsSQL】数据库基础 库的基本操作
目录 一,数据库基础 1,什么是数据库 2,主流的数据库 3,连接服务器 4,服务器,数据库,表关系 5,使用案例 二,库的操作 1,创建数据库 2,创建…...

C51外部代码空间读取技术:CBYTE/CWORD宏详解
1. C51外部代码空间读取技术解析在8051单片机开发中,经常需要从外部程序存储器(Code Space)读取数据,这是嵌入式系统开发中的一项基础但关键的操作。许多开发者在使用Keil C51工具链时,会遇到如何正确读取外部程序存储器的问题。本文将深入解…...
 (H strain) ;CVVIVGRVVLSGLK)
HCV NS4A Protein (22-34) (H strain) ;CVVIVGRVVLSGLK
一、基础信息多肽名称:丙型肝炎病毒 NS4A 蛋白片段 (22-34) H 株英文:HCV NS4A Protein (22-34) (H strain)三字母序列:Cys-Val-Val-Ile-Val-Gly-Arg-Val-Val-Leu-Ser-Gly-Lys单字母序列:CVVIVGRVVLSGLK氨基酸数量:13 …...

VScode搭建一体化ROS开发环境:从配置到调试的完整实践指南
1. 项目概述与核心价值最近在带几个新同事上手机器人项目,发现他们配置ROS开发环境时,总会在各种依赖、路径和编译问题上卡壳,一折腾就是大半天。这让我想起自己刚接触ROS那会儿,也是被环境配置搞得焦头烂额,明明照着官…...

用HyperLynx VX2.5做LPDDR4X与高速串行总线仿真的完整工作流
HyperLynx VX2.5实战:LPDDR4X与高速串行总线仿真全流程解析 在当今高速电路设计领域,信号完整性问题已成为制约产品性能的关键瓶颈。尤其对于搭载LPDDR4X内存和高速串行总线的移动设备与服务器,工程师们常常陷入这样的困境:设计阶…...

【实战】Latex|在保留ACM-Reference-Format格式的前提下,实现参考文献按引用顺序排列
1. 问题背景与核心痛点 当你使用ACM官方模板撰写论文时,参考文献格式要求必须采用ACM-Reference-Format样式。这个格式有个让人头疼的特性:它会强制按作者姓氏字母顺序排列参考文献,而不是按照文中实际引用顺序。想象一下,你精心设…...

巧用Charles代理,根治Xposed资源库HTTPS迁移引发的下载难题
1. 当Xposed遇上HTTPS:一场协议升级引发的"断粮危机" 去年给家里老人用的那台小米4刷机时,突然发现Xposed框架死活下载不了资源包。屏幕上赫然显示着那个熟悉的错误提示:"Xposed Installer:下载http://dl.xposed.info/repo/fu…...

避坑指南:在Docker里部署OpenWrt做软路由,这几个macvlan和网络配置的坑你别踩
DockerOpenWrt软路由避坑实战:macvlan网络疑难解析与高阶配置 当你在双网口服务器上尝试用Docker部署OpenWrt软路由时,是否经历过这样的绝望时刻:所有配置看似正确,但客户端设备就是无法上网;宿主机与容器仿佛身处平行…...

AI 测试必修课:深入理解 LLM 的 Token、上下文与温度参数
一位资深测试工程师的血泪忠告:“你花三个月搭建的测试框架崩溃了——不是因为代码逻辑有bug,而是因为昨天 temperature 是 0 的时候模型输出是‘PASS’,今天同样的代码、同样的输入,模型说‘FAIL’。你以为温度设成 0 就稳了?天真。” 这是一篇写给 AI 测试工程师、LLM 应…...

跨平台流媒体下载神器:N_m3u8DL-RE的完整使用指南
跨平台流媒体下载神器:N_m3u8DL-RE的完整使用指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 你…...

Serverless冷启动优化全攻略:从原理到实战的性能提升方案
1. 项目概述:直面Serverless的“阿喀琉斯之踵”在Serverless架构的实践中,有一个问题几乎每个深度使用者都绕不开,那就是“冷启动”。想象一下,你精心设计的函数,在无人访问时安静地“休眠”以节省资源。当第一个请求突…...