Kafka 位移提交
Kafka 位移提交
- 自动提交
- 手动提交
Consumer 的消费位移 : 记录 Consumer 下一条消息的消费位移
- 如 : Consumer 已消费 5 条消息 (位移: 0 - 4) , 此时 Consumer 位移 = 5 : 指向下一条消息的位移
提交位移 (Committing Offsets) : Consumer 向 Kafka 汇报位移数据
- Consumer 能同时消费多个分区的数据,Consumer 要维护每个分区提交各自的位移数据
- 当 Consumer 重启后,能从之前位移继续消费,避免重新消费整个消息
Consumer API 的提交位移的方法 :
- 从用户分 : 自动提交 , 手动提交
- 从 Consumer 分 : 同步提交 , 异步提交
- 自动提交 : Consumer 在后台提交位移,用户无需操作
- 手动提交 : 用户提交位移,Consumer 不管
| 提交位移 | 自动提交 | 配置 | enable.auto.commit = true |
|---|---|---|---|
| 手动提交 | 同步提交 | KafkaConsumer.commitSync | |
| 异步提交 | KafkaConsumer.commitAsync | ||
| 细化位移提交 | commitSync(Map<TopicPartition, OffsetAndMetadata>) | ||
commitAsync(Map<TopicPartition, OffsetAndMetadata>) |
自动提交
Consumer 参数 :
enable.auto.commit = true: 自动提交位移auto.commit.interval.ms(默认值是 5 秒) : Kafka 每 5 秒自动提交一次位移
自动提交位移 :
- 可能出现重复消费
- 例子:Consumer 每 5 秒自动提交一次位移。提交位移 3 秒后出现 Rebalance。在 Rebalance 后,所有 Consumer 从上一次提交的位移处继续消费,但该位移已经是 3 秒前的位移数据,在 Rebalance 发生前 3 秒消费的所有数据都会重新消费
设置自动提交位移 :
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "2000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}
}
手动提交
enable.auto.commit = false : 手动提交位移
手动提交位移 :
- 好处 : 更灵活,能把控位移提交的时机和频率
- 缺点 : 用 commitSync() 时,Consumer 处于阻塞状态,直到 Broker 返回提交结果,影响整个应用程序的 TPS
commitSync() :
while (true) {// 返回最新位移。一直等位移提交后才返回 (同步操作)ConsumerRecords<String, String> records =consumer.poll(Duration.ofSeconds(1));process(records); // 处理消息try {consumer.commitSync();} catch (CommitFailedException e) {handle(e); // 处理提交失败异常}
}
commitAsync() :
- 异步操作,会立即返回,不会阻塞,不影响 Consumer 的 TPS
- 用回调函数 (callback) 实现提交后的逻辑,如 : 记录日志或处理异常
- 无法自动失败重试
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));process(records); // 处理消息consumer.commitAsync((offsets, exception) -> {if (exception != null)handle(exception);});
}
异步无阻塞式 :
- 用 commitSync 自动重试避免瞬时错误,如 : 网络的瞬时抖动,Broker 端 GC
- 异步处理,不影响 TPS
// 实现异步无阻塞式的位移管理,保证 Consumer 位移的正确性
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));process(records); // 处理消息commitAysnc(); // 使用异步提交规避阻塞}
} catch (Exception e) {handle(e); // 处理异常
} finally {try {consumer.commitSync(); // 最后一次提交使用同步阻塞式提交} finally {consumer.close();}
}
更精细的位移管理 :
commitSync(Map<TopicPartition, OffsetAndMetadata>)commitAsync(Map<TopicPartition, OffsetAndMetadata>)- 参数 : Map 对象 : 键 = TopicPartition (消费的分区),值 = OffsetAndMetadata 对象 (位移数据)
// 创建 Map 对象,保存 Consumer 消费要提交的分区位移
private Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
int count = 0;
//...
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record: records) {process(record); // 处理消息// 构造要提交的位移值offsets.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 1);// 每 100 条消息提交一次位移if(count % 100 == 0){consumer.commitAsync(offsets, null); // 回调处理逻辑是 null}count++;}
}
相关文章:

Kafka 位移提交
Kafka 位移提交自动提交手动提交Consumer 的消费位移 : 记录 Consumer 下一条消息的消费位移 如 : Consumer 已消费 5 条消息 (位移: 0 - 4) , 此时 Consumer 位移 5 : 指向下一条消息的位移 提交位移 (Committing Offsets) : Consumer 向 Kafka 汇报位移数据 Consumer 能同…...
kubernetes--监控容器运行时:Falco
目录 Falco介绍 Falco架构 Falco的安装 告警规则示列 威胁场景测试: 监控容器创建的不可信任进程(自定义规则) Falco支持五种输出告警方式falco.yaml: Falco告警集中化展示: Falco介绍 Falco是一个Linux安全工具…...
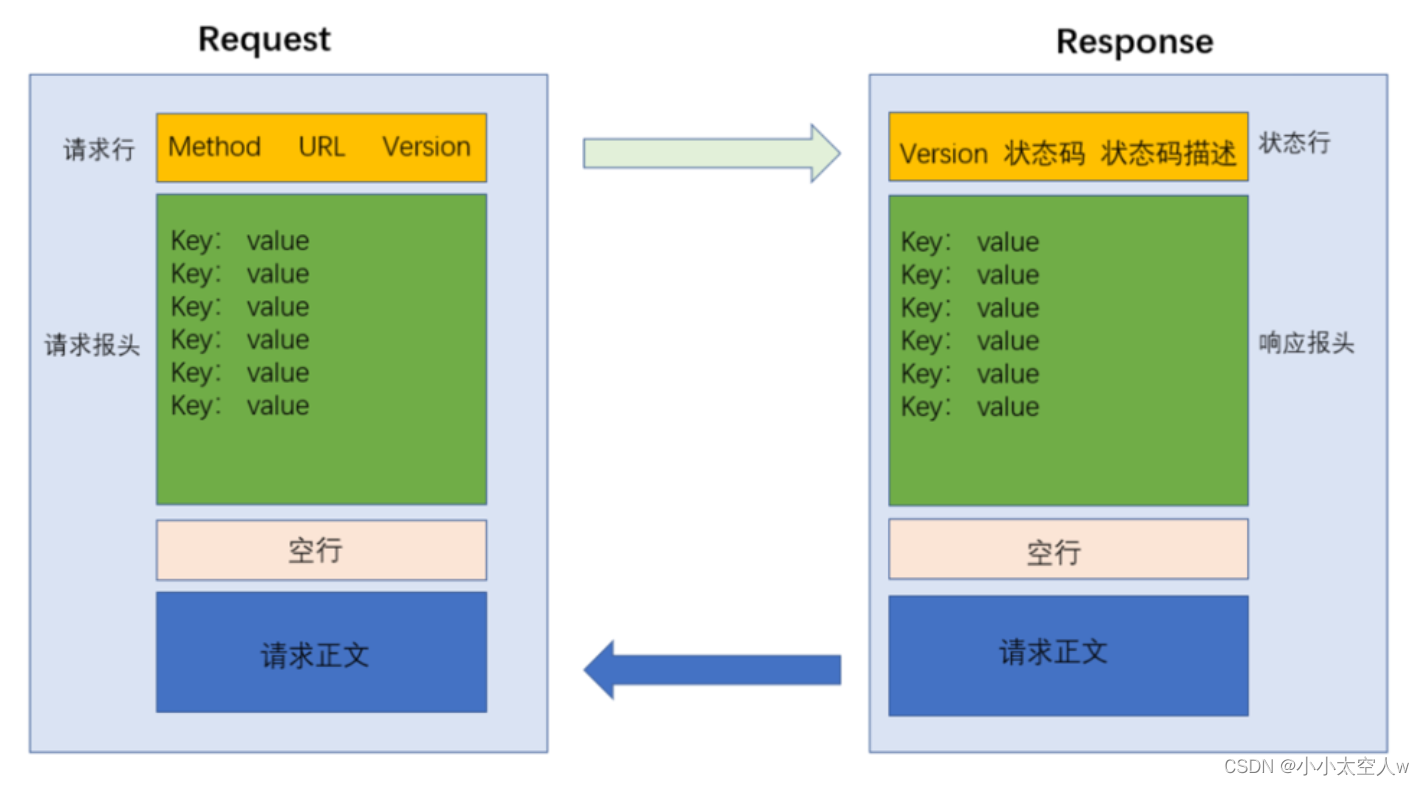
HTTP协议详解(上)
目录 前言: 认识URL HTTP协议方法 通过Fiddler抓包 GET和POST之间典型区别 header详解 HTTP响应状态码 常见状态码解释 状态码分类 HTTP协议报文格式 小结: 前言: HTTP协议属于应用层协议,称为超文本传输协议ÿ…...

java性能-原生内存-内存分析
原生内存最佳实践 内存占用 jVM使用的原生内存和堆内存总和就是一个应用程序的总内存——操作系统角度 jvm启动时候加载的类路径下的jar文件相关的内存和系统其他进程共享资源的可能 测量内存占用 线程是个例外——每当创建一个线程操作系统都会分配一些原生内存存储线程栈…...
c++类与对象
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章 🔥座右铭:“不要等到什么都没有了,才下定决心去做” …...
Java并发编程与API详解
文章目录前言操作系统——进程和线程进程进程组成进程状态进程控制进程创建进程终止进程阻塞和唤醒进程通信线程线程组成线程状态线程控制线程的实现方式用户线程内核线程混合方式CPU调度调度的层次调度的实现调度器调度的时机、切换与过程进程调度的方式闲逛进程两种线程的调度…...
【冲刺蓝桥杯的最后30天】day5
大家好😃,我是想要慢慢变得优秀的向阳🌞同学👨💻,断更了整整一年,又开始恢复CSDN更新,从今天开始更新备战蓝桥30天系列,一共30天,如果对你有帮助或者正在备…...

大厂与小厂招人的区别,看完多少有点不敢相信
前两天在头条发了一条招人的感慨,关于大厂招人和小公司招人的区别。 大厂:有影响力,有钱,能够吸引了大量的应聘者。因此,也就有了筛选的资格,比如必须985名校毕业,必须35岁以下,不能…...
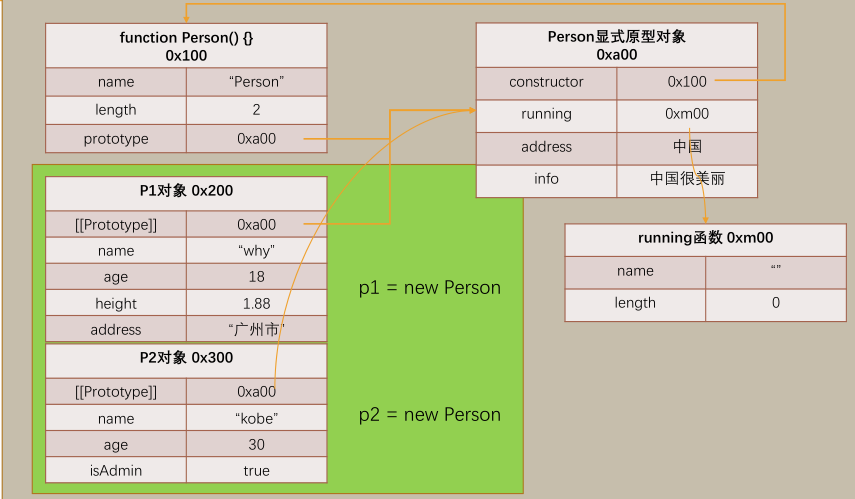
前端ES5对象特性
ES5对象特性 对象和函数的原型 JS中每一个对象都有一个特殊的内置属性,这个特殊的对象可以指向其他的对象 我们通过引用对象的属性key来获取一个value时,它会触发 Get 的操作首先检查该对象是否有对应的属性,如果有的话就使用对象内的如果…...

Linux入门介绍及Linux文件与目录结构
前言 本文小新为大家带来 Linux 入门介绍及Linux 文件与目录结构 相关知识,具体内容包括Linux入门介绍(包括:Linux概述,Linux与Windows区别,CentOS 下载地址),Linux文件与目录结构等进行详尽介绍…...
超赞,用python实现流媒体服务器功能,寥寥几句搞定。
步骤: 要使用Python将实时摄像机传送流写入H5页面,可以使用以下步骤。 1、安装必要的软件包。您需要安装OpenCV和Flask以及gunicorn 与 gevent 。您可以通过在终端中运行以下命令来执行此操作。 pip install opencv-python pip install Flask pip ins…...

冥想第七百二十一天
1.3.3周五,又是周五了。今天又运动了5公里,很舒服轻松。 2.还是往常的生活,休息的也很好,开春后跑的一直很好。 3.早上30分钟健康操。中午转了圈, 给大哥说下周去上海。 4.感谢父母,感谢朋友,感…...

06-Oracle表空间与用户管理
本讲主要内容: 1.表空间管理:表空间的作用,创建,修改,删除及管理; 2.用户管理:创建用户,修改用户,删除用户,修改密码,解锁; 3.用户…...
Mysql 索引特点
承接上文Mysql Server原理简介聚簇索引、二级索引、联合索引分别具备什么样的特点?聚簇索引数据跟索引放在一起的叫聚簇索引;数据和索引分开存储的叫非聚簇索引;innodb存储引擎,数据和文件都放在ibd文件中,实际的数据是…...

读书笔记-终身学习
前言人需要终身成长,也需要终身学习,以下是记录个人读书学习的笔记总结,希望能给大家一点借鉴,仅供参考。笔记1、《匠人精神》秋山利辉是日本神奈川县横滨市都筑区“秋山木工”的经营者,从事订制家具制作业务。是一家小…...

了解栈Stack一篇文章就够了
什么是栈栈是一种特殊的线性表,只允许一端进行数据的插入和删除,即先进后出原则。类似于弹夹先装进去的子弹后面出,后放入的子弹先出。栈的底层原理栈是一种线性结构,所以既能使用数组实现,也能使用链表实现࿰…...

CNStack 助推龙源电力扛起“双碳”大旗
作者:CNStack 容器平台、龙源电力:张悦超 、党旗 龙源电力容器云项目背景 龙源电力集团是世界第一大风电运营商, 随着国家西部大开发战略推进,龙源电力已经把风力发电场铺设到全国各地,甚至是交通极不便利的偏远地区&…...
ruoyi-vue-plus1(控制台相关的输出日志)(p6spy插件)(jackson全局配置)(StopWatch)
Jackson配置在启动项目时,我们发现日志打印出这样几行字,初始化了jacdson配置,我们去查看一下来源找。我们找到了一个全局序列化配置类,其中重写了BigNumberSerializer.INSTANCE进去查看发现了这里对于部分范围的数字进行了转为为…...

【Mybatis】| 如何创建MyBatis的工具类
目录🌟更多专栏请点击👇一、前言二、实现过程1. 创建一个ThreadLocal对象2. 初始化SqlSessionFactory3. 获取并存储sqlSession对象4. 关闭sqlSession对象三、 总代码🌟更多专栏请点击👇 专栏名字🔥Elasticsearch专栏e…...

【Java】DT怎么写?
几个重要的注解 怎么用mockito写单元测试? package Biz;import Client.FileIOClient; import Req.FileRequest; import Res.FileResponse; import org.junit.Assert; import org.junit.Test; import org.junit.runner.RunWith; import org.mockito.InjectMocks;…...

ab、Postman、JMeter并发测试真相:协议层、运行时与系统瓶颈解析
1. 为什么你测出来的“并发”根本不是并发——从一次线上服务雪崩说起上周五下午三点,我们一个核心订单查询接口突然响应时间从80ms飙升到2.3秒,错误率冲到17%,监控大盘一片血红。运维拉出负载曲线,CPU和内存都正常;开…...

如何轻松配置开源工具:3步实现WeMod高级功能解锁
如何轻松配置开源工具:3步实现WeMod高级功能解锁 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod Pro订阅费烦恼吗?W…...

小红书数据采集Python实战:3个技巧让你轻松获取公开内容
小红书数据采集Python实战:3个技巧让你轻松获取公开内容 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 你是否曾经想要分析小红书上的热门话题,却苦…...

微信小程序逆向分析终极指南:快速掌握wxappUnpacker完整实战技巧
微信小程序逆向分析终极指南:快速掌握wxappUnpacker完整实战技巧 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 作为一名微信小程序开发者&am…...

别再乱用apt --fix-broken了!详解Ubuntu下unixodbc依赖报错的根本原因与安全修复流程
深入解析Ubuntu中unixodbc依赖冲突的根源与系统化修复方案当你在Ubuntu终端中看到"未满足的依赖关系"和"试图覆盖文件"的错误提示时,是否曾盲目执行过apt --fix-broken install命令?这种条件反射式的操作可能暂时解决问题࿰…...

C166架构下XDATA解决全局变量内存溢出问题
1. 问题现象与背景分析在C166架构的嵌入式开发中,当程序包含大量初始化全局变量时,开发者经常会遇到两个经典错误:*** ERROR 172 IN LINE 9 OF test.c: HDATA0: length exceeded: act172032, max65536 Error 106: Section Overflow Section: …...

基于Hugging Face BART模型构建文本摘要服务:从原理到部署实战
1. 项目概述:从零构建一个可用的文本摘要服务文本摘要,这个听起来有点学术的词,其实离我们很近。想想看,每天面对海量的新闻、报告、论文,甚至冗长的会议纪要,谁不想快速抓住核心要点?这就是文本…...

量子机器学习安全威胁:NISQ时代的数据投毒攻击与防御挑战
1. 量子机器学习与NISQ时代的安全隐忧量子机器学习(QML)正站在一个激动人心的十字路口。它承诺将量子计算的指数级并行能力与经典机器学习的模式识别潜力相结合,为解决药物发现、材料科学和金融建模中的复杂问题开辟新路径。其核心在于&#…...

小样本下机器学习模型性能稳定性评估:分位数与置信区间实战
1. 项目概述与核心价值在机器学习项目的落地过程中,我们常常会面临一个灵魂拷问:这个模型到底有多“稳”?你辛辛苦苦调参、优化,在某个特定测试集上跑出了95%的准确率,但换个数据划分方式,或者重新初始化一…...

[智能体-30]:curl、requests、Ollama、Ollama API、OpenAI API各种的作用和他们之间的关系
五者作用 层级关系极简梳理一、各自定义与作用curl 命令行 HTTP 请求工具,终端发请求、调试接口、测试连通性。requests Python 代码 HTTP 请求库,代码层面收发网络数据。OpenAI API云端官方大模型接口标准,规定请求格式、字段、交互协议。O…...