Colab/PyTorch - 001 PyTorch Basics
Colab/PyTorch - 001 PyTorch Basics
- 1. 源由
- 2. PyTorch库概览
- 3. 处理过程
- 2.1 数据加载与处理
- 2.2 构建神经网络
- 2.3 模型推断
- 2.4 兼容性
- 3. 张量介绍
- 3.1 构建张量
- 3.2 访问张量元素
- 3.3 张量元素类型
- 3.4 张量转换(NumPy Array)
- 3.5 张量运算
- 3.6 CPU v/s GPU 张量
- 4. 参考资料
1. 源由
认知一件事,或者一个物,了解事物的最初源于对这个事物的理解。因此,我们还是非常循着逻辑循序渐进的方式,首先来认识事物的基本属性、特性。
这里将来看下PyTorch的一些基础知识、流程、定义。
2. PyTorch库概览
我们知道PyTorch是基于Python的科学计算包,让我们看一看PyTorch计算包在处理深度机器学习的基本流程。下面的图描述了一个典型的工作流程以及与每个步骤相关的重要模块。
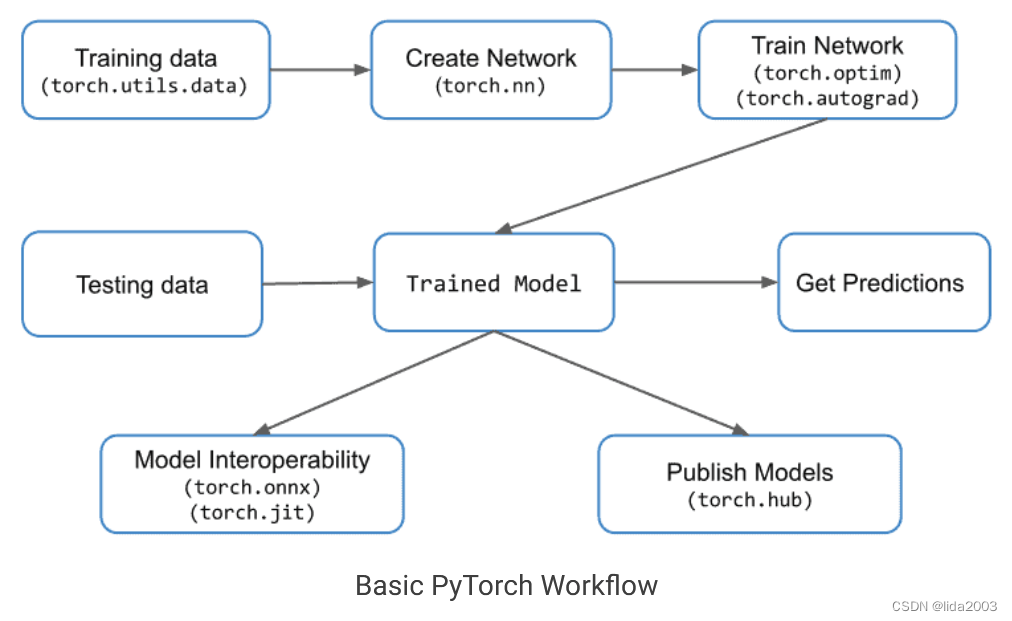
注:重要PyTorch模块包括:torch.nn、torch.optim、torch.utils和torch.autograd。
3. 处理过程
2.1 数据加载与处理
在任何深度学习项目中,第一步都是处理数据的加载和处理。PyTorch通过torch.utils.data提供了相应的工具。
该模块中的两个重要类是Dataset和DataLoader。
- Dataset建立在张量数据类型之上,主要用于自定义数据集。
- DataLoader用于大型数据集并且希望在后台加载数据以便在训练循环中准备好并等待时使用。
注:如果可以访问多台机器或GPU,还可以使用torch.nn.DataParallel和torch.distributed。
2.2 构建神经网络
torch.nn模块用于创建神经网络。它提供了所有常见的神经网络层,如全连接层、卷积层、激活函数和损失函数等。
一旦网络架构被创建并且数据准备好被馈送到网络中,需要不断来更新权重和偏差,以便网络开始学习。这些实用工具在torch.optim模块中提供。类似地,在反向传播过程中需要的自动微分,我们使用torch.autograd模块。
2.3 模型推断
模型训练完成后,它可以用于对测试用例甚至新数据集进行输出预测。这个过程称为模型推断。
2.4 兼容性
提供了TorchScript,可以用于在不依赖Python运行时的情况下运行模型。这可以被视为一个虚拟机,其中的指令主要针对张量。
还可以格式转换,使用PyTorch训练的模型转换为ONNX等格式,这样可以在其他深度学习框架(如MXNet、CNTK、Caffe2)中使用这些模型。也可以将ONNX模型转换为TensorFlow。
3. 张量介绍
张量简单来说就是对矩阵的一种称呼。如果熟悉NumPy数组,理解和使用PyTorch张量将会非常容易。标量值由一个零维张量表示。类似地,列/行矩阵使用一维张量表示,以此类推。下面给出了一些不同维度的张量示例,供理解:
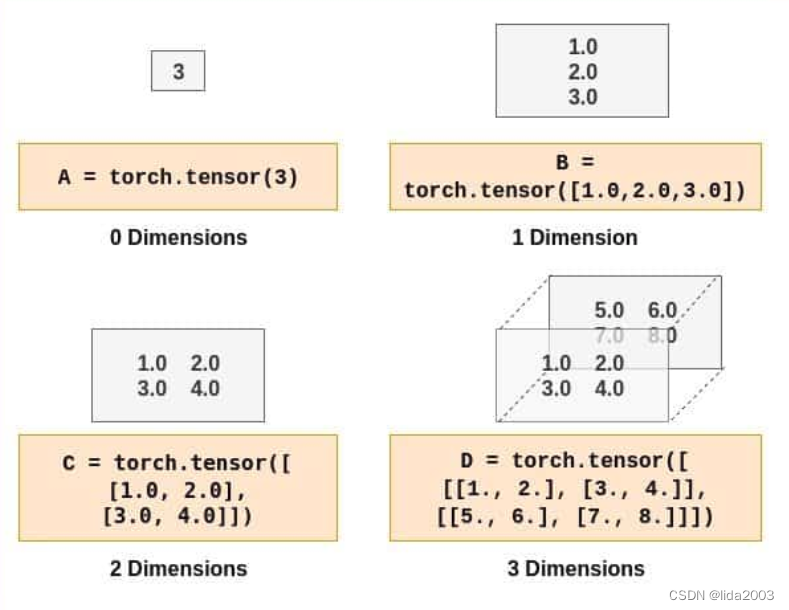
测试代码:PyTorch_for_Beginners
3.1 构建张量
import torch# Create a Tensor with just ones in a column
a = torch.ones(5)# Print the tensor we created
print(a)# tensor([1., 1., 1., 1., 1.])# Create a Tensor with just zeros in a column
b = torch.zeros(5)
print(b)# tensor([0., 0., 0., 0., 0.])c = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
print(c)# tensor([1., 2., 3., 4., 5.])d = torch.zeros(3,2)
print(d)# tensor([[0., 0.],
# [0., 0.],
# [0., 0.]])e = torch.ones(3,2)
print(e)# tensor([[1., 1.],
# [1., 1.],
# [1., 1.]])f = torch.tensor([[1.0, 2.0],[3.0, 4.0]])
print(f)# tensor([[1., 2.],
# [3., 4.]])# 3D Tensor
g = torch.tensor([[[1., 2.], [3., 4.]], [[5., 6.], [7., 8.]]])
print(g)# tensor([[[1., 2.],
# [3., 4.]],
#
# [[5., 6.],
# [7., 8.]]])print(f.shape)
# torch.Size([2, 2])print(e.shape)
# torch.Size([3, 2])print(g.shape)
# torch.Size([2, 2, 2])
3.2 访问张量元素
- 1D
# Get element at index 2
print(c[2])# tensor(3.)
- 2D/3D
# All indices starting from 0# Get element at row 1, column 0
print(f[1,0])
# We can also use the following
print(f[1][0])# tensor(3.)# Similarly for 3D Tensor
print(g[1,0,0])
print(g[1][0][0])# tensor(5.)
- 访问部分张量
# All elements
print(f[:])# All elements from index 1 to 2 (inclusive)
print(c[1:3])# All elements till index 4 (exclusive)
print(c[:4])# First row
print(f[0,:])# Second column
print(f[:,1])
3.3 张量元素类型
int_tensor = torch.tensor([[1,2,3],[4,5,6]])
print(int_tensor.dtype)# torch.int64# What if we changed any one element to floating point number?
int_tensor = torch.tensor([[1,2,3],[4.,5,6]])
print(int_tensor.dtype)# torch.float32print(int_tensor)# tensor([[1., 2., 3.],
# [4., 5., 6.]])# This can be overridden as follows
int_tensor = torch.tensor([[1,2,3],[4.,5,6]], dtype=torch.int32)
print(int_tensor.dtype)# torch.int32
print(int_tensor)# tensor([[1, 2, 3],
# [4, 5, 6]], dtype=torch.int32)
3.4 张量转换(NumPy Array)
# Import NumPy
import numpy as np# Tensor to Array
f_numpy = f.numpy()
print(f_numpy)# array([[1., 2.],
# [3., 4.]], dtype=float32)# Array to Tensor
h = np.array([[8,7,6,5],[4,3,2,1]])
h_tensor = torch.from_numpy(h)
print(h_tensor)# tensor([[8, 7, 6, 5],
# [4, 3, 2, 1]])
3.5 张量运算
# Create tensor
tensor1 = torch.tensor([[1,2,3],[4,5,6]])
tensor2 = torch.tensor([[-1,2,-3],[4,-5,6]])# Addition
print(tensor1+tensor2)
# We can also use
print(torch.add(tensor1,tensor2))# tensor([[ 0, 4, 0],
# [ 8, 0, 12]])# Subtraction
print(tensor1-tensor2)
# We can also use
print(torch.sub(tensor1,tensor2))# tensor([[ 2, 0, 6],
# [ 0, 10, 0]])# Multiplication
# Tensor with Scalar
print(tensor1 * 2)
# tensor([[ 2, 4, 6],
# [ 8, 10, 12]])# Tensor with another tensor
# Elementwise Multiplication
print(tensor1 * tensor2)
# tensor([[ -1, 4, -9],
# [ 16, -25, 36]])# Matrix multiplication
tensor3 = torch.tensor([[1,2],[3,4],[5,6]])
print(torch.mm(tensor1,tensor3))
# tensor([[22, 28],
# [49, 64]])# Division
# Tensor with scalar
print(tensor1/2)
# tensor([[0, 1, 1],
# [2, 2, 3]])# Tensor with another tensor
# Elementwise division
print(tensor1/tensor2)
# tensor([[-1, 1, -1],
# [ 1, -1, 1]])
3.6 CPU v/s GPU 张量
PyTorch针对CPU和GPU有不同的Tensor实现。可以将每个张量转换为GPU,以执行大规模并行、快速的计算。所有对张量执行的操作都将使用PyTorch提供的专用于GPU的例程进行。
# Create a tensor for CPU
# This will occupy CPU RAM
tensor_cpu = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], device='cpu')# Create a tensor for GPU
# This will occupy GPU RAM
tensor_gpu = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], device='cuda')
CPU v/s GPU张量转换
# Move GPU tensor to CPU
tensor_gpu_cpu = tensor_gpu.to(device='cpu')# Move CPU tensor to GPU
tensor_cpu_gpu = tensor_cpu.to(device='cuda')
测试代码:001 PyTorch for Beginners
4. 参考资料
【1】Colab/PyTorch - Getting Started with PyTorch
相关文章:
Colab/PyTorch - 001 PyTorch Basics
Colab/PyTorch - 001 PyTorch Basics 1. 源由2. PyTorch库概览3. 处理过程2.1 数据加载与处理2.2 构建神经网络2.3 模型推断2.4 兼容性 3. 张量介绍3.1 构建张量3.2 访问张量元素3.3 张量元素类型3.4 张量转换(NumPy Array)3.5 张量运算3.6 CPU v/s GPU …...

翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习三
合集 ChatGPT 通过图形化的方式来理解 Transformer 架构 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习一翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习二翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深…...

基于Seata实现分布式事务实现
Seata 是一个开源的分布式事务解决方案,它提供了高性能和简单易用的分布式事务服务。Seata 将事务的参与者分为 TC(Transaction Coordinator)、TM(Transaction Manager)和 RM(Resource Manager)…...
adss光缆是什么意思
adss光缆,adss光缆型号,adss光缆用途 什么是adss光缆 ADSS用于高压输电线路并利用电力系统输电塔干,整个光缆为非金属介质,自承悬挂于电力铁塔上的电力强度最小的位置。它运用于已建高压输电线路,具有安全性高&#…...
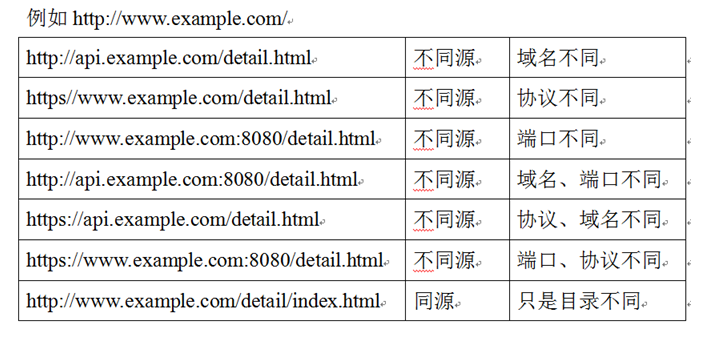
JavaScript异步编程——04-同源和跨域
同源和跨域 同源 同源策略是浏览器的一种安全策略,所谓同源是指,域名,协议,端口完全相同。 跨域问题的解决方案 从我自己的网站访问别人网站的内容,就叫跨域。 出于安全性考虑,浏览器不允许ajax跨域获取…...

出差——蓝桥杯十三届2022国赛大学B组真题
问题分析 该题属于枚举类型,遍历所有情况选出符合条件的即可。因为只需要派两个人,因此采用两层循环遍历每一种情况。 AC_Code #include <bits/stdc.h> using namespace std; string str;//选择的两人 bool ok(){if(str.find("A")!-1…...
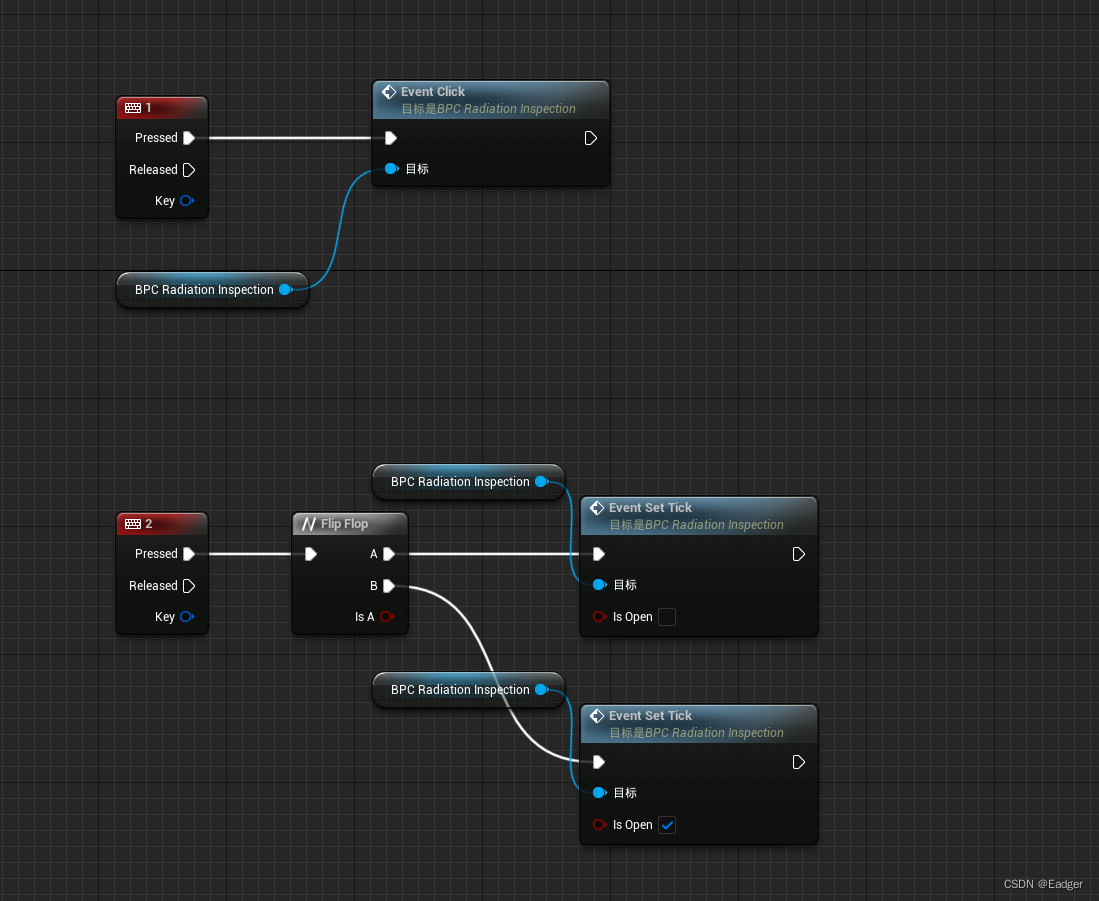
UE5(射线检测)学习笔记
这一篇会讲解射线检测点击事件、离开悬停、进入悬停事件的检测,以及关闭射线检测的事件,和射线检测蓝图的基础讲解。 创建一个简单的第三人称模板 创建一个射线检测的文件夹RadiationInspection,并且右键蓝图-场景组件-命名为BPC_Radiation…...
语音识别的基本概念
语音识别的基本概念 言语是一种复杂的现象。人们很少了解它是如何产生和感知的。天真的想法常常是语音是由单词构成的,而每个单词又由音素组成。不幸的是,现实却大不相同。语音是一个动态过程,没有明确区分的…...
OpenCV Radon变换探测直线(拉东变换)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 Radon变换可以将原始图像中直线特征的处理问题转化为变换域图像中对应点特征的处理问题,其中对应特征点的横坐标表示原始图像的旋转角度,一般来讲原始图像中的噪声不会分布在直线的特征上。因此,Radon变换在探测…...

六、Redis五种常用数据结构-zset
zset是Redis的有序集合数据类型,但是其和set一样是不能重复的。但是相比于set其又是有序的。set的每个数据都有一个double类型的分数,zset正是根据这个分数来进行数据间的排序从小到大。有序集合中的元素是唯一的,但是分数(score)是可以重复的…...

FPGA第一篇,FPGA现场可编程门阵列,从0开始掌握可编程硬件开发(FPGA入门指南)
简介:FPGA全称Field-Programmable Gate Array,是一种可编程逻辑器件,它通过可编程的逻辑单元和可编程的连接网络实现了灵活的硬件实现。与固定功能的集成电路(ASIC)相比,FPGA具有更高的灵活性和可重新配置性…...

C#实现简单音乐文件解析播放——Windows程序设计作业2
1. 作业内容 编写一个C#程序,要求实现常见音乐文件的播放功能,具体要求如下: 1). 播放MP3文件: 程序应能够读取MP3文件,并播放其中的音频。 2). 播放OGG文件: 应能够播放ogg文件。 …...

Python数据爬取超简单入门
## 什么是网络爬虫? 网络爬虫是一种自动浏览器程序,能够自动地从互联网获取数据。爬虫的主要任务是访问网页,分析网页内容,然后提取所需的信息。爬虫广泛应用于数据收集、数据分析、网页内容监控等领域。 ## 爬虫的基本步骤 1.…...

Dreamweaver 2021 for Mac 激活版:网页设计工具
在追求卓越的网页设计道路上,Dreamweaver 2021 for Mac无疑是您的梦幻之选。这款专为Mac用户打造的网页设计工具,集强大的功能与出色的用户体验于一身。 Dreamweaver 2021支持多种网页标准和技术,让您能够轻松创建符合现代网页设计的作品。其…...

【Git】Git学习-15:分支简介和基本操作
学习视频链接:【GeekHour】一小时Git教程_哔哩哔哩_bilibili编辑https://www.bilibili.com/video/BV1HM411377j/?vd_source95dda35ac10d1ae6785cc7006f365780https://www.bilibili.com/video/BV1HM411377j/?vd_source95dda35ac10d1ae6785cc7006f365780 git bran…...
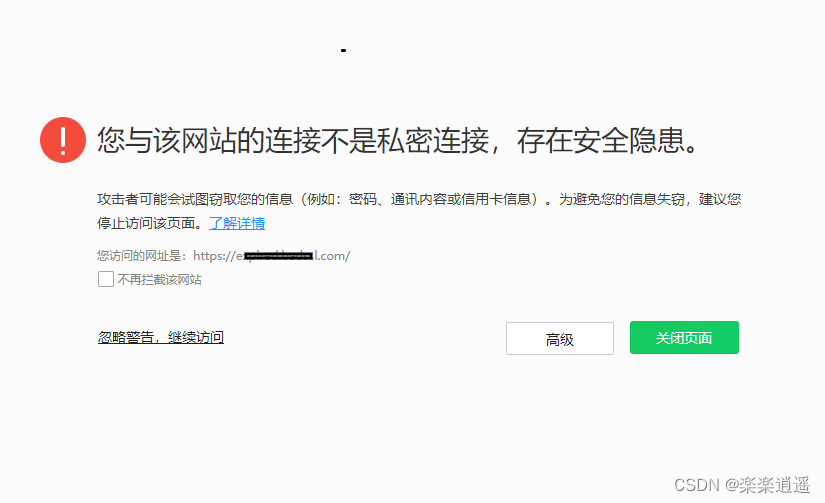
浏览器提示网站“不安全”原因及解决方法
是否经常会遇到访问的网站被浏览器提示访问不安全?那么,浏览器提示网站不安全通常有哪些原因又该如何处理这种不安全提醒,以下总结了几个原因及相应的处理办法: 一、网站管理者原因排查及处理办法: 1、网站没有部署S…...

Jmeter详细学习思路和教程
目录 1、JMeter环境准备 1.1、介绍 1.2、与LoadRunner比较 1.3、前提条件 1.4、安装配置 2、JMeter脚本 2.1、测试计划 2.2、线程组 2.3、Sampler 2.4、HTTP请求 2.5、查看结果树 2.6、HTTP Cookie管理器 2.7、HTTP信息头管理器 2.8、响应断言 2.9、参数化 3、JM…...
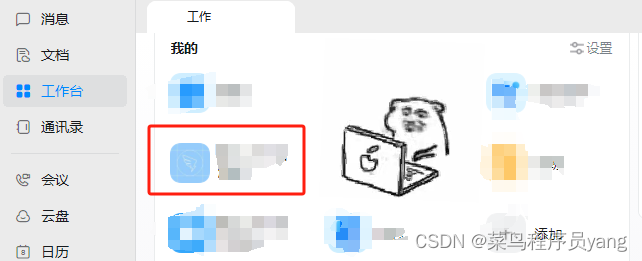
钉钉开放平台创建企业内部H5微应用或者小程序
前言: 在当今企业数字化转型的浪潮中,创建企业内部H5微应用或小程序已成为提升工作效率和促进内部沟通的重要举措。发话不多说本文将介绍如何利用钉钉平台快速创建这些应用,让企业内部的工作更加便捷高效。 步骤 1.在浏览器打开链接…...

Linux中每当执行‘mount’命令(或其他命令)时,自动激活执行脚本:输入密码,才可以执行mount
要实现这个功能,可以通过创建一个自定义的mount命令的包装器(wrapper)来完成。这个包装器脚本会首先提示用户输入密码,如果密码正确,则执行实际的mount命令。以下是创建这样一个包装器的步骤: 创建一个名为…...

【网络协议】----IPv6协议报文、地址分类
【网络协议】----IPv6协议简介 【网络协议】----IPv6协议简介IPv6特点IPv4 和 IPv6报文结构IPv6报文格式-拓展报头 IPv6地址分类IPv6地址表示IPv6单播地址可聚合全球单播地址链路本地地址唯一本地地址特殊地址补充 接口标识(主机位)生成方法通过EUI-64规…...

GeoJSON.io:3分钟创建专业地图,地理数据可视化从未如此简单
GeoJSON.io:3分钟创建专业地图,地理数据可视化从未如此简单 【免费下载链接】geojson.io A quick, simple tool for creating, viewing, and sharing spatial data 项目地址: https://gitcode.com/gh_mirrors/ge/geojson.io 你是否曾经需要在地图…...

PowerToys Awake终极指南:如何让Windows电脑在你需要时永不休眠?
PowerToys Awake终极指南:如何让Windows电脑在你需要时永不休眠? 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_…...

YOLO26改进 | featurefusion |红外小目标检测的自适应多尺度细节保融模块
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 本文给大家带来的教程是将YOLO26的特征融合替换为DPCF来提取特征。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和…...

书匠策AI:你的毕业论文“外挂“已上线,看完这篇你就懂了
各位同学们,我是你们的论文科普老朋友。 今天不讲格式、不讲开题报告怎么凑字数,咱们来聊一个能让你从"头秃"变成"头不秃"的神奇工具——书匠策AI。没错,就是那个官网 官网直达:www.shujiangce.com上让无数毕…...
)
保姆级避坑指南:在Ubuntu18.04上用ROS Melodic搞定UR5+Realsense D435i手眼标定(附旧版easy_handeye包)
深度避坑实战:Ubuntu18.04ROS Melodic手眼标定全流程精解 当机械臂的末端执行器需要与视觉系统协同工作时,手眼标定成为连接两者的关键桥梁。本文将以UR5机械臂搭配Realsense D435i相机为例,深入剖析在Ubuntu18.04和ROS Melodic环境下实现高精…...

观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现 在开发与测试环境中,虚拟机(VM)是常见的…...

Marchand Balun设计原理与IE3D电磁仿真实践
1. Marchand Balun设计基础与电磁仿真原理在射频和微波电路设计中,平衡-不平衡转换器(Balun)是实现单端信号与差分信号相互转换的关键无源器件。作为从业15年的射频工程师,我经常需要在各类高频电路中使用Balun结构,而…...

HuggingClaw:用开源模型模拟Claude API的本地开发与测试方案
1. 项目概述:当HuggingFace遇上Claude,一个AI模型管理新思路最近在GitHub上看到一个挺有意思的项目,叫“HuggingClaw”。光看名字,你大概就能猜到它想干什么——把HuggingFace和Claude这两个在AI领域响当当的名字结合到一起。作为…...
)
告别DETR训练慢!用Deformable DETR在COCO数据集上快速搞定小目标检测(附PyTorch代码)
告别DETR训练慢!用Deformable DETR在COCO数据集上快速搞定小目标检测(附PyTorch代码) 在目标检测领域,DETR(Detection Transformer)以其端到端的特性吸引了大量关注,但实际应用中暴露出两个致命…...

微信聊天记录永久保存:免费开源工具WeChatExporter完整使用指南
微信聊天记录永久保存:免费开源工具WeChatExporter完整使用指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾担心珍贵的微信聊天记录会随着手机更…...