VLM与基础分割模型的联合使用
最近做的项目里有涉及大模型,里面有一部分的功能是:
将图片输入VLM(视觉语言模型,我使用的是llava),询问图中最显著的物体,将其给出的答案作为基础分割模型(我使用的是Grounded-SAM)的text prompt,基础分割模型输出目标物体的mask
(可能会有uu疑问,为什么不直接问Grounded-SAM两次)
- 该项目目的是评估VLM的某项能力
- 基础分割模型的语言能力弱于VLM,输入的text prompt一般是单个词,指示希望分割出的目标
- 基础分割模型不能输出文本回答,无法进行“对话”
如果还是不理解这样做的理由(为什么不直接用既能多轮对话又能分割出mask的多模态大模型呢),那就把这篇当作两个大模型的使用记录吧
文章目录
- 整体流程
- 实现
- 使用模型
- LLaVA运行
- Grounded-SAM运行
- 代码
- 引入包
- llava_inference
- 非主要函数
- 包装Grounded-SAM的函数
- 主函数
- 运行bash文件
整体流程
为了方便理解,画了一个简单的示意图
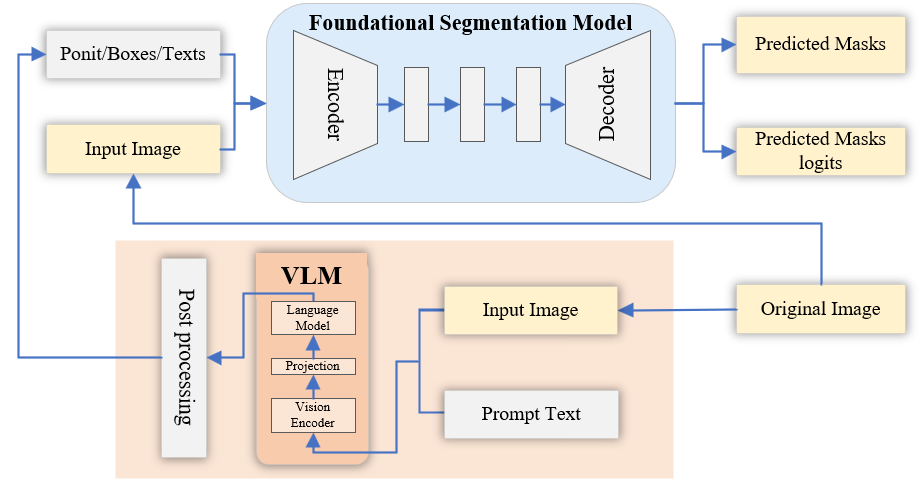
- 从右下开始看起,原图像(original image)和问题(prompt text)输入VLM,VLM输出回答,将回答进行后处理(post processing,如果答得准确,不需要提取关键字,也可以没有后处理)。
- 原图像(original image)和提示词(point/boes/texts)输入基础分割模型,输出预测的目标分割结果
Grounded-SAM的结果包含4个文件
- 原图像
- 带预测boxes+masks的原图
- 目标的实例分割图
- 记录预测目标分割的json文件
(1、2、3举例)
(4举例)


实现
使用模型
- VLM: llava-v1.5-7B
github: https://github.com/haotian-liu/LLaVA
huggingface(7B): https://huggingface.co/liuhaotian/llava-v1.5-7b/tree/main - 基础分割模型: Grounded-SAM
github:https://github.com/IDEA-Research/Grounded-Segment-Anything
需要下载两个权重,Grounded-SAM和SAM的,详细请见github
两个模型的运行网上已经有很多教程了,我给两个我参考过的,就不详细介绍了,会补充一些我认为需要注意的地方或是遇到的报错
LLaVA运行
参考:LLaVA模型安装、预测、训练详细教程
Grounded-SAM运行
参考:Grounded Segment Anything根据文字自动画框或分割环境配置和基本使用教程
代码
引入包
import argparse
import os
import sysimport numpy as np
import json
import torch
import re
import requests
from PIL import Image
from io import BytesIO
from transformers import TextStreamer
from torchvision import transformssys.path.append(os.path.join(os.getcwd(), "GroundingDINO"))
sys.path.append(os.path.join(os.getcwd(), "segment_anything"))# Grounding DINO
import GroundingDINO.groundingdino.datasets.transforms as T
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.util.utils import (clean_state_dict,get_phrases_from_posmap,
)# segment anything
from segment_anything import sam_model_registry, sam_hq_model_registry, SamPredictor
import cv2
import numpy as np
import matplotlib.pyplot as plt# llava
from llava.model.builder import load_pretrained_model
from llava.mm_utils import get_model_name_from_path
from llava.eval.run_llava import llava_inference, eval_model
# llava_inference是我根据eval_model修改的函数
from llava.constants import (IMAGE_TOKEN_INDEX,DEFAULT_IMAGE_TOKEN,DEFAULT_IM_START_TOKEN,DEFAULT_IM_END_TOKEN,
)
from llava.conversation import conv_templates, SeparatorStyle
from llava.model.builder import load_pretrained_model
from llava.utils import disable_torch_init
from llava.mm_utils import (process_images,tokenizer_image_token,get_model_name_from_path,
)
llava_inference
该项目需要进行多轮的对话,但又不想每次都加载一个新的模型,如你只进行一轮,可以直接在eval_model中增加返回: return outputs
def llava_inference(tokenizer, model, image_processor, args):# Modeldisable_torch_init()model_name = args.model_name# model_name = get_model_name_from_path(args.model_path)# tokenizer, model, image_processor, context_len = load_pretrained_model(# args.model_path, args.model_base, model_name# )qs = args.queryimage_token_se = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKENif IMAGE_PLACEHOLDER in qs:if model.config.mm_use_im_start_end:qs = re.sub(IMAGE_PLACEHOLDER, image_token_se, qs)else:qs = re.sub(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN, qs)else:if model.config.mm_use_im_start_end:qs = image_token_se + "\n" + qselse:qs = DEFAULT_IMAGE_TOKEN + "\n" + qsif "llama-2" in model_name.lower():conv_mode = "llava_llama_2"elif "mistral" in model_name.lower():conv_mode = "mistral_instruct"elif "v1.6-34b" in model_name.lower():conv_mode = "chatml_direct"elif "v1" in model_name.lower():conv_mode = "llava_v1"elif "mpt" in model_name.lower():conv_mode = "mpt"else:conv_mode = "llava_v0"if args.conv_mode is not None and conv_mode != args.conv_mode:print("[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}".format(conv_mode, args.conv_mode, args.conv_mode))else:args.conv_mode = conv_modeconv = conv_templates[args.conv_mode].copy()conv.append_message(conv.roles[0], qs)conv.append_message(conv.roles[1], None)prompt = conv.get_prompt()image_files = image_parser(args)images = load_images(image_files)image_sizes = [x.size for x in images]images_tensor = process_images(images, image_processor, model.config).to(model.device, dtype=torch.float16)input_ids = (tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).cuda())with torch.inference_mode():output_ids = model.generate(input_ids,images=images_tensor,image_sizes=image_sizes,do_sample=True if args.temperature > 0 else False,temperature=args.temperature,top_p=args.top_p,num_beams=args.num_beams,max_new_tokens=args.max_new_tokens,# use_cache=False,use_cache=True,)outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()return outputs
非主要函数
大部分都与原Grounded-SAM一致
def load_image(image_path):# load imageimage_pil = Image.open(image_path).convert("RGB") # load imagetransform = T.Compose([T.RandomResize([800], max_size=1333),T.ToTensor(),T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),])image, _ = transform(image_pil, None) # 3, h, wreturn image_pil, imagedef load_model(model_config_path, model_checkpoint_path, device):args = SLConfig.fromfile(model_config_path)args.device = devicemodel = build_model(args)checkpoint = torch.load(model_checkpoint_path, map_location="cpu")load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)print(load_res)_ = model.eval()return modeldef get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, device="cpu"
):caption = caption.lower()caption = caption.strip()if not caption.endswith("."):caption = caption + "."model = model.to(device)image = image.to(device)with torch.no_grad():outputs = model(image[None], captions=[caption])logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)logits.shape[0]# filter outputlogits_filt = logits.clone()boxes_filt = boxes.clone()filt_mask = logits_filt.max(dim=1)[0] > box_thresholdlogits_filt = logits_filt[filt_mask] # num_filt, 256boxes_filt = boxes_filt[filt_mask] # num_filt, 4logits_filt.shape[0]# get phrasetokenlizer = model.tokenizertokenized = tokenlizer(caption)# build predpred_phrases = []for logit, box in zip(logits_filt, boxes_filt):pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)if with_logits:pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")else:pred_phrases.append(pred_phrase)return boxes_filt, pred_phrasesdef show_mask(mask, ax, random_color=False):if random_color:color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_box(box, ax, label):x0, y0 = box[0], box[1]w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2))ax.text(x0, y0, label)def save_mask_data(output_dir, mask_list, box_list, label_list):value = 0 # 0 for backgroundmask_img = torch.zeros(mask_list.shape[-2:])for idx, mask in enumerate(mask_list):# mask_img[mask.cpu().numpy()[0] == True] = value + idx + 1mask_img[mask.cpu().numpy()[0] == True] = 255plt.figure() # figsize=(10, 10)plt.imshow(mask_img.numpy(), cmap="gray")plt.axis("off")plt.savefig(os.path.join(output_dir, f"mask.png"),bbox_inches="tight",dpi=300,pad_inches=0.0,)json_data = [{"value": value, "label": "background"}]for label, box in zip(label_list, box_list):value += 1name, logit = label.split("(")logit = logit[:-1] # the last is ')'json_data.append({"value": value,"label": name,"logit": float(logit),"box": box.numpy().tolist(),})with open(os.path.join(output_dir, f"mask.json"), "w") as f:json.dump(json_data, f)包装Grounded-SAM的函数
def gSAM_main(args, prompt, image_path, grounded_sam_model, predictor):# cfgoutput_dir = args.output_dirbox_threshold = args.box_thresholdtext_threshold = args.text_thresholdgrounded_device = args.grounded_device# device = "cpu"# image_pil = Image.open(image_path).convert("RGB")image_pil, image = load_image(image_path)# run grounding dino modelboxes_filt, pred_phrases = get_grounding_output(grounded_sam_model,image,prompt,box_threshold,text_threshold,device=grounded_device,)image = cv2.imread(image_path) # torch.Size([3, 800, 1211])image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)predictor.set_image(image)size = image_pil.sizeH, W = size[1], size[0]for i in range(boxes_filt.size(0)):boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])boxes_filt[i][:2] -= boxes_filt[i][2:] / 2boxes_filt[i][2:] += boxes_filt[i][:2]boxes_filt = boxes_filt.cpu()transformed_boxes = predictor.transform.apply_boxes_torch(boxes_filt, image.shape[:2]).to(grounded_device)masks, _, _ = predictor.predict_torch(point_coords=None,point_labels=None,boxes=transformed_boxes.to(grounded_device),multimask_output=False,)# draw output imageplt.figure(figsize=(10, 10))plt.imshow(image)for mask in masks:show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)for box, label in zip(boxes_filt, pred_phrases):show_box(box.numpy(), plt.gca(), label)plt.axis("off")plt.savefig(os.path.join(output_dir, f"grounded_sam_output.png"),bbox_inches="tight",dpi=300,pad_inches=0.0,)save_mask_data(output_dir, masks, boxes_filt, pred_phrases)print(f"原图分割结果保存在:{os.path.abspath(output_dir)}")with open(os.path.join(output_dir, f"mask.json"), "r", encoding="utf8") as fp:json_data = json.load(fp)max_logit = json_data[1]["logit"]print(f"Prompt:{prompt}, Detected Object Number:{len(json_data)-1},Max Logit:{max_logit}")return max_logit, masks主函数
if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--model-path", type=str, default="facebook/opt-350m")parser.add_argument("--model-base", type=str, default=None)# parser.add_argument("--image-file", type=str, required=True)parser.add_argument("--device", type=str, default="cuda")parser.add_argument("--conv-mode", type=str, default=None)parser.add_argument("--temperature", type=float, default=0.2)parser.add_argument("--max-new-tokens", type=int, default=1024)parser.add_argument("--load-8bit", action="store_true")parser.add_argument("--load-4bit", action="store_true")parser.add_argument("--debug", action="store_true")# parser = argparse.ArgumentParser("Grounded-Segment-Anything Demo", add_help=True)parser.add_argument("--config", type=str, required=True, help="path to config file")parser.add_argument("--grounded_checkpoint", type=str, required=True, help="path to checkpoint file")parser.add_argument("--sam_version",type=str,default="vit_h",required=False,help="SAM ViT version: vit_b / vit_l / vit_h",)parser.add_argument("--sam_checkpoint", type=str, required=False, help="path to sam checkpoint file")parser.add_argument("--sam_hq_checkpoint",type=str,default=None,help="path to sam-hq checkpoint file",)parser.add_argument("--use_sam_hq", action="store_true", help="using sam-hq for prediction")parser.add_argument("--input_image", type=str, required=True, help="path to image file")# parser.add_argument("--text_prompt", type=str, required=True, help="text prompt")parser.add_argument("--output_dir","-o",type=str,default="outputs",required=True,help="output directory",)parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")parser.add_argument("--grounded_device",type=str,default="cpu",help="running on cpu only!, default=False",)args = parser.parse_args()# cfgconfig_file = args.config # change the path of the model config filegrounded_checkpoint = args.grounded_checkpoint # change the path of the modelsam_version = args.sam_versionsam_checkpoint = args.sam_checkpointsam_hq_checkpoint = args.sam_hq_checkpointuse_sam_hq = args.use_sam_hqimage_path = args.input_image# text_prompt = args.text_promptoutput_dir = args.output_dirbox_threshold = args.box_thresholdtext_threshold = args.text_thresholddevice = args.devicegrounded_device = args.grounded_device# 这部分有改动,在项目中两个模型会多次使用,这里各用一次model_path = args.model_pathmodel_base = args.model_baseprompt = ["What is the most obvious target object in the picture? Answer the question using a single word or phrase."]target = ""# make diros.makedirs(output_dir, exist_ok=True)# load imageimage_pil, image = load_image(image_path)# load modelmodel = load_model(config_file, grounded_checkpoint, device=grounded_device)# visualize raw imageimage_pil.save(os.path.join(output_dir, "image_0.png"))# initialize SAMpredictor = SamPredictor(sam_model_registry[sam_version](checkpoint=sam_checkpoint).to(grounded_device))# initialize llava# 禁用 Torch 初始化,可能由于多个进程同时访问 GPU 导致的问题# disable_torch_init()# load llava modelmodel_name = get_model_name_from_path(model_path)tokenizer, llava_model, image_processor, context_len = load_pretrained_model(model_path, model_base, model_name) llava_args = type("Args",(),{"model_path": model_path,"model_base": model_base,"model_name": model_name,"query": prompt[0],"conv_mode": None,"image_file": image_path,"sep": ",","temperature": 0,"top_p": None,"num_beams": 1,"max_new_tokens": 512,},)()# llava_output = eval_model(llava_args)llava_output = llava_inference(tokenizer, llava_model, image_processor, llava_args)# llava_output = re.findall(r"(.+?)</s>", llava_output)[0]# print("llava_output:", llava_output)if target == "": # 如果target没有预先设定target = llava_outputprint(f"将llava的输出{target}作为grounded-SAM的prompt输入")max_logit, _ = gSAM_main(args, target, args.input_image, model, predictor)
运行bash文件
项目运行目录: /{ }/Grounded-Segment-Anything/
/{ }/Grounded-Segment-Anything/test.sh如下
#!/bin/bashexport CUDA_VISIBLE_DEVICES="6,7"
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
export CUDA_HOME=/usr/local/cuda-11.7/python prompt_controller.py \--model-path /{}/llava-v1.5-7b \--config /{}/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint /{}/groundingdino_swint_ogc.pth \--sam_checkpoint /{}/sam_vit_h_4b8939.pth \--input_image /{}/test.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--grounded_device "cpu" \
前面的几个export请根据实际情况使用和更改
prompt_controller.py是文件名,请换成你自己的py名
–model-path: llava权重路径
–config: Grounded-SAM配置文件路径
–grounded_checkpoint: Grounded-SAM权重路径
–sam_checkpoint: SAM权重路径
–input_image: 输入的图片
–output_dir: Grounded-SAM输出结果的文件夹
–box_threshold/–text_threshold:
–grounded_device: Grounded-SAM使用设备(一般为cuda,但是我用gpu会报“_c”错,只好使用cpu推理)
运行项目时,cd /{ }/Grounded-Segment-Anything/, 在终端bash test.sh
相关文章:

VLM与基础分割模型的联合使用
最近做的项目里有涉及大模型,里面有一部分的功能是: 将图片输入VLM(视觉语言模型,我使用的是llava),询问图中最显著的物体,将其给出的答案作为基础分割模型(我使用的是Grounded-SAM)的text prom…...

JS数组去重的方法
目录 1、includes 2、indexOf 3、Set结合Array.from 4、filter 5、reduce 6、使用双重for循环 介绍一下数组常用的去重复方法 以以下数组为例子来介绍,一维的数字类型数组: const arr [1, 2, 2, 2, 3, 1, 6, 4, 4, 6, 5, 7] 1、includes funct…...
Go实战训练之Web Server 与路由树
Server & 路由树 Server Web 核心 对于一个 Web 框架,至少要提供三个抽象: Server:代表服务器的抽象Context:表示上下文的抽象路由树 Server 从特性上来说,至少要提供三部分功能: 生命周期控制&…...

C#中接口设计相关原则
在C#中,接口(Interface)是一种引用类型,它定义了一个契约,指定了一个类必须实现的成员(属性、方法、事件、索引器)。接口不提供这些成员的实现,只指定成员必须按照特定的方式被实现。…...
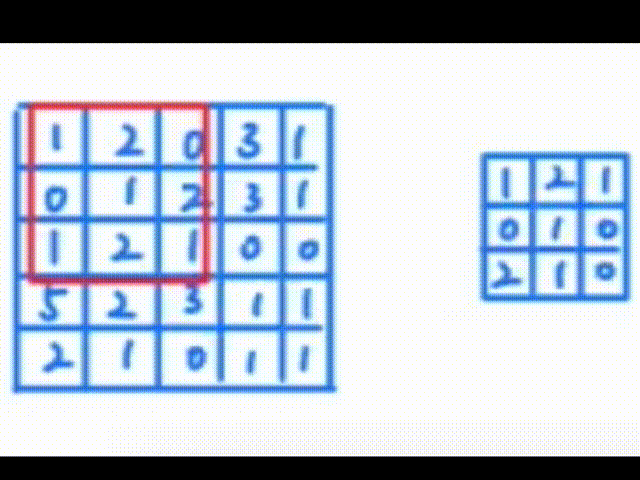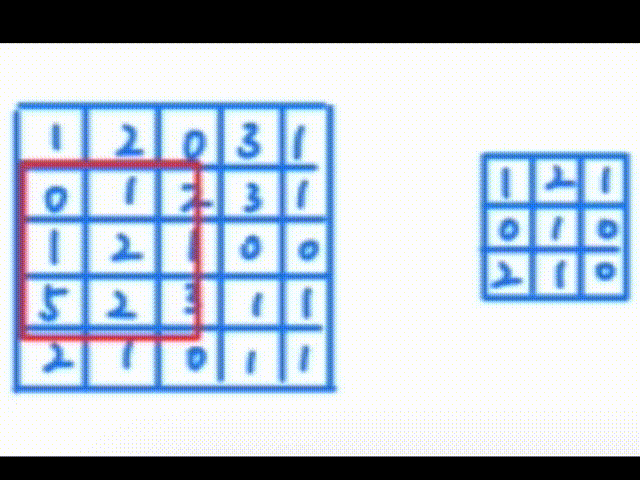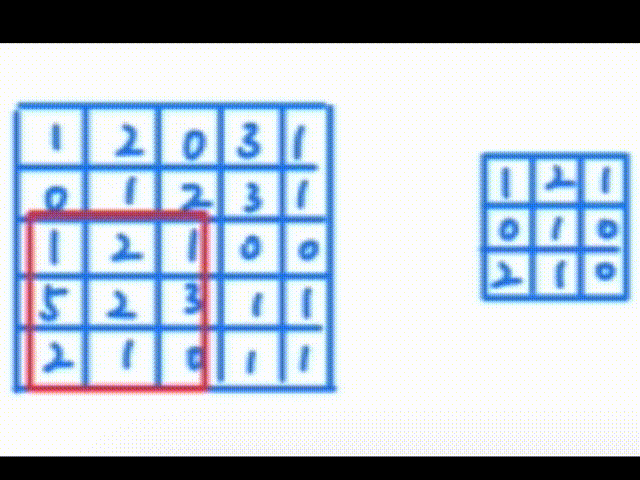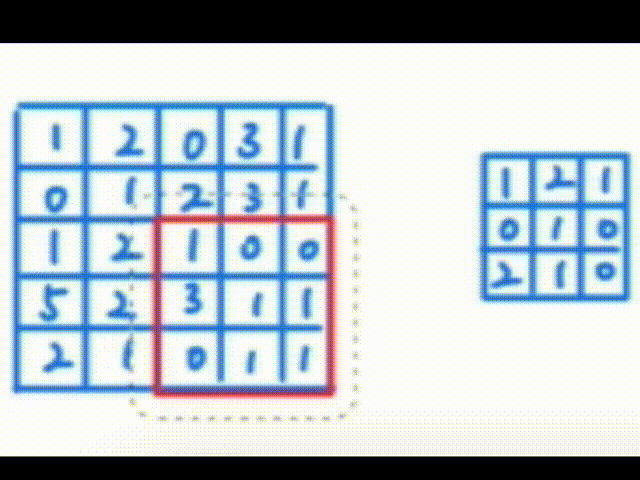
Pytorch学习笔记——卷积操作
一、认识卷积操作 卷积操作是一种数学运算,它涉及两个函数:输入函数(通常是图像)和卷积核(也称为滤波器或特征检测器)。卷积核在输入函数上滑动,将核中的每个元素与其覆盖的输入函数区域中的对应…...

探索鸿蒙开发:鸿蒙系统如何引领嵌入式技术革新
嵌入式技术已经成为现代社会不可或缺的一部分。而在这个领域,华为凭借其自主研发的鸿蒙操作系统,正悄然引领着一场技术革新的浪潮。本文将探讨鸿蒙开发的特点、优势以及其对嵌入式技术发展的深远影响。 鸿蒙操作系统的特点 鸿蒙,作为华为推…...
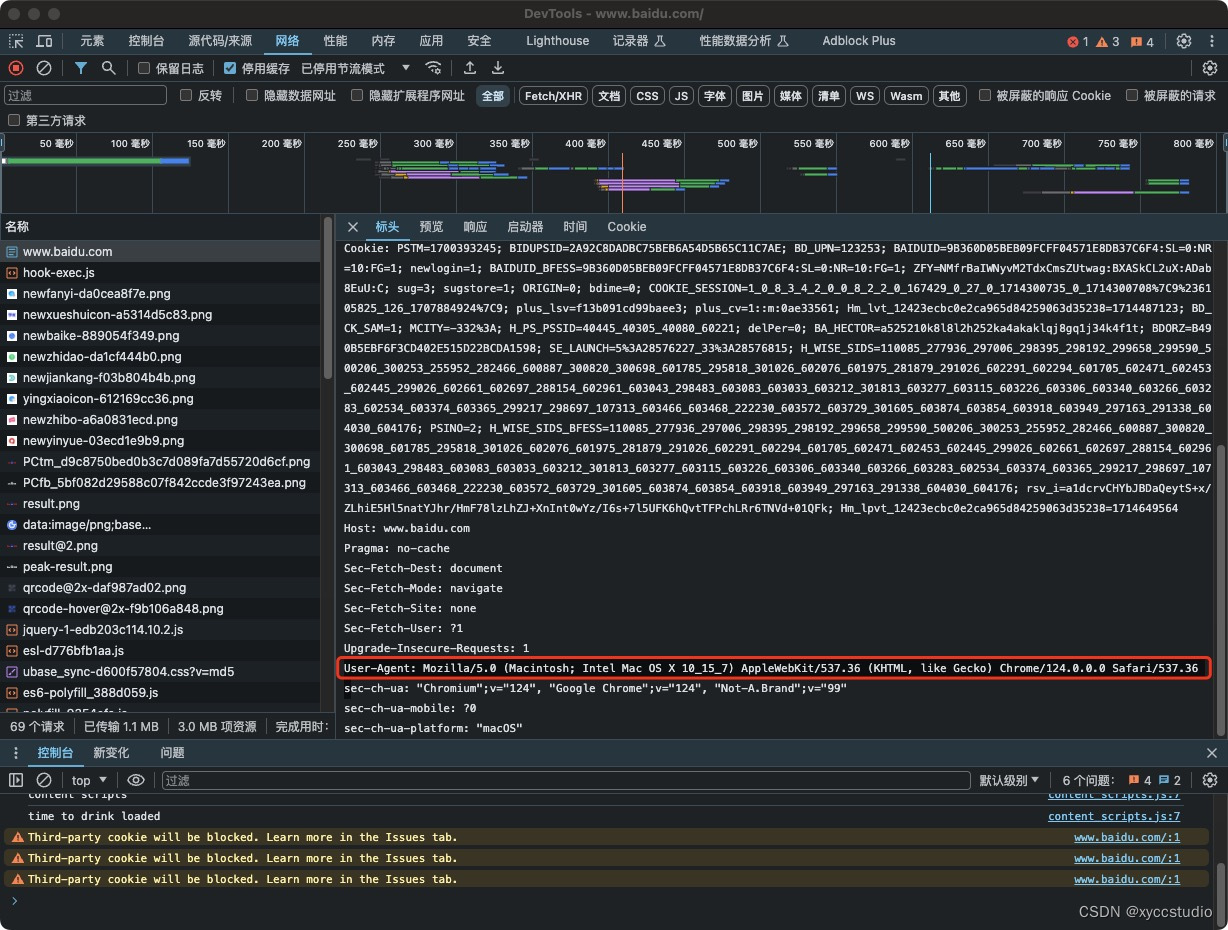
chrome extension插件替换网络请求中的useragent
感觉Chrome商店中的插件不能很好的实现自己想要的效果,那么就来自己动手吧。 本文以百度为例: 一般来说网页请求如下: 当前使用的useragent是User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safar…...

PHP基础【介绍,注释,更改编码,赋值,数据类型】
源码 <?php //单行注释 /* 多行注释 *///通过header()函数发送http头的请求信息用来指定页面的字符集编码 header("Content-type:text/html;Charsetutf-8"); //告诉浏览器,当前页面的内容类型是HTML,并且页面内容使用的是UTF-8编码。//ph…...
ASP.NET小型证券术语解释及翻译系统的设计与开发
摘 要 在系统设计上,综合各种翻译类型网站优缺点,设计出具有任何使用者都可添加术语信息的且只有管理员能够实现术语修改及删除等独特方式的术语查看管理系统。此方式能够使术语量快速增大,并且便于使用者及管理员操作,满足相互…...
硬件知识积累 音频插座的了解,看音频插座的原理图来了解音频插座的引脚。
1. 音频接口 音频插座是一种用于连接音频信号线路的电子元件,常见于音频设备(如音响、耳机、话筒等)中。它的主要作用是将电子信号转化为声音信号,以满足人们对于音乐、电影、游戏等方面的需求。 根据插头形状的不同,音…...
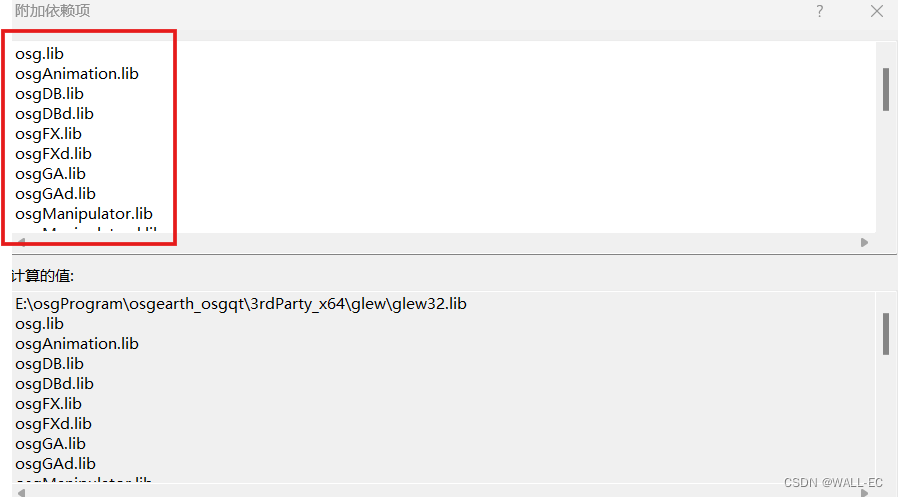
error LNK2001: 无法解析的外部符号 “__declspec(dllimport) public: __cdecl ......
运行程序时,报如上图所示错误,其中一条是: ReflectionProbe.obj : error LNK2001: 无法解析的外部符号 "__declspec(dllimport) public: __cdecl osg::Object::Object(bool)" (__imp_??0ObjectosgQEAA_NZ) 报这个错误一般是因为…...

邮箱Webhook API发送邮件的性能怎么优化?
邮箱Webhook API发送邮件的步骤?如何用邮箱API发信? 随着业务规模的扩大,如何高效地通过邮箱Webhook API发送邮件,成为了许多企业面临的关键问题。下面,AokSend将探讨一些优化邮箱Webhook API发送邮件性能的方法。 邮…...

并发编程实现
一、并行编程 1、Parallel 类 Parallel类是System.Threading.Tasks命名空间中的一个重要类,它提供数据并行和任务并行的高级抽象。 For和ForEach Parallel类下的For和ForEach对应着普通的循环和遍历(普通的for和foreach),但执行时会尝试在多个线程上…...
基于EBAZ4205矿板的图像处理:12图像二值化(阈值可调)
基于EBAZ4205矿板的图像处理:12图像二值化(阈值可调) 我的项目是基于EBAZ4205矿板的阈值可调的图像阈值二值化处理,可以通过按键调整二值化的阈值,key1为阈值加1,key4为阈值减1,key2为阈值加10,key5为阈值…...

人大金仓数据库报com.kingbase8.util.KSQLException: 致命错误: 用户 “SYSTEM“ Password 认证失败
com.kingbase8.util.KSQLException: 致命错误: 用户 “SYSTEM” Password 认证失败 解决办法: 问题在于用户权限只不足,相关配置文件在一般在 /data/sys hba.conf,修改IPV4 local connections选项中的改为trust。...
文件加密软件哪个好?文件加密软件排行榜前十名(好用软件推荐)
文件加密软件哪个好?这是许多个人和企业用户在面临数据保护需求时所关心的问题。随着数字化时代的推进,数据安全问题日益凸显,文件加密软件成为了保护数据安全的重要手段。本文将为您介绍当前市场上排名前十的文件加密软件,帮助您…...
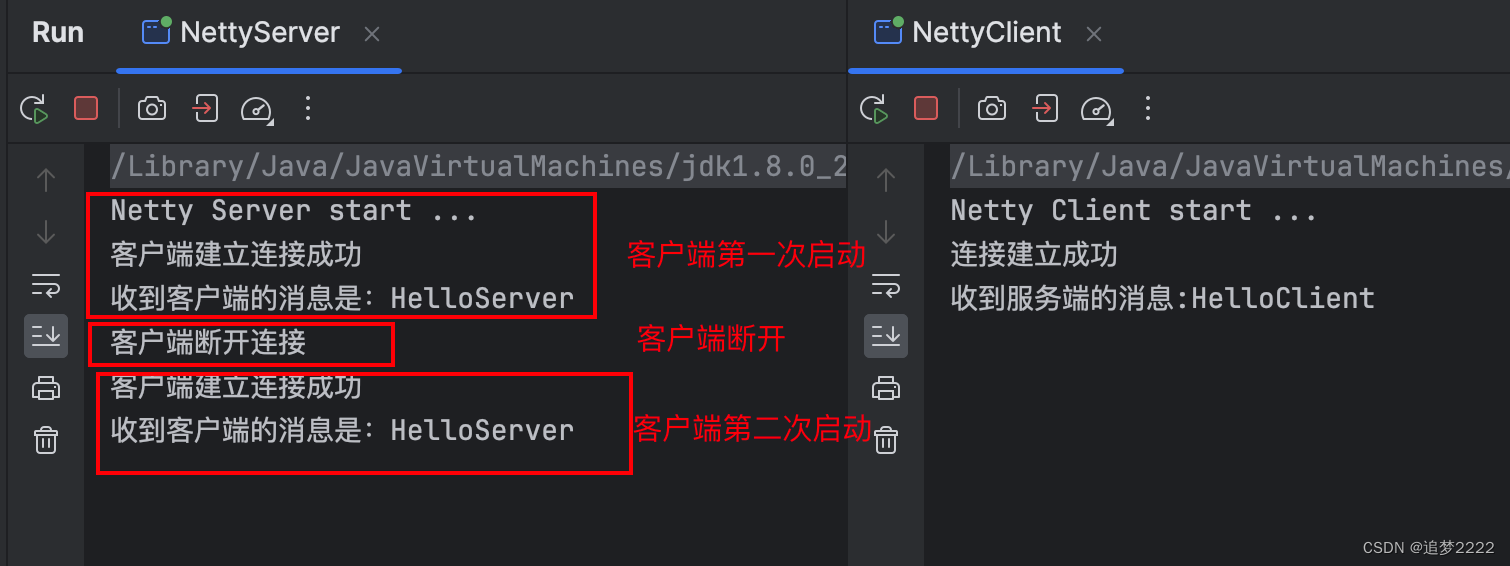
Netty的第一个简单Demo实现
目录 说明需求ClientServer写法总结 实现运行 说明 Netty 的一个练习,使用 Netty 连通 服务端 和 客户端,进行基本的通信。 需求 Client 连接服务端成功后,打印连接成功给服务端发送消息HelloServer Server 客户端连接成功后࿰…...
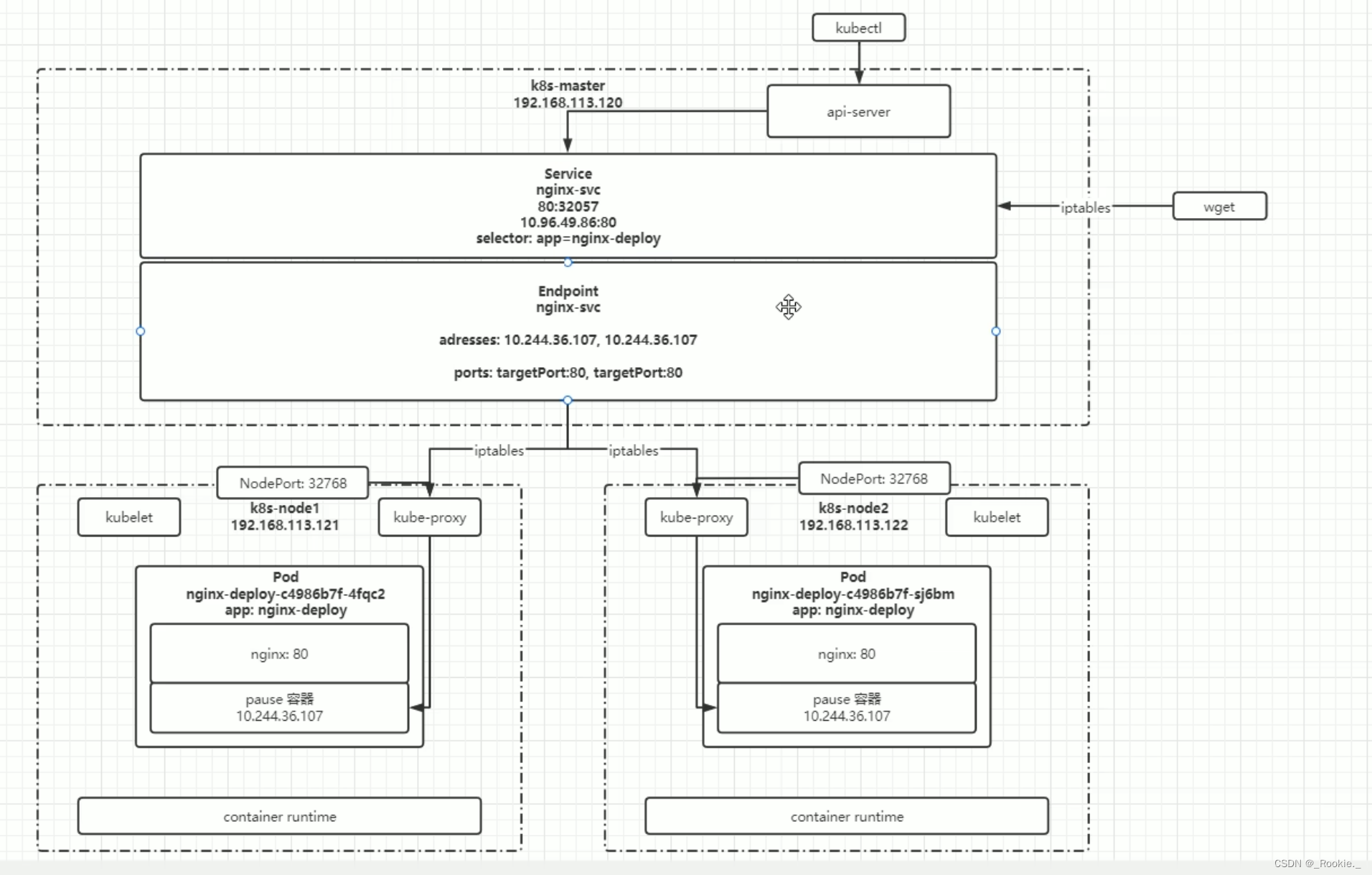
K8S 哲学 - 服务发现 services
apiVersion: v1 kind: Service metadata:name: deploy-servicelabels:app: deploy-service spec: ports: - port: 80targetPort: 80name: deploy-service-podselector: app: deploy-podtype: NodePort service 的 endPoint (ep) 主机端口分配方式 两…...
Springboot工程创建
目录 一、步骤 二、遇到的问题及解决方案 一、步骤 打开idea,点击文件 ->新建 ->新模块 选择Spring Initializr,并设置相关信息。其中组为域名,如果没有公司,可以默认com.example。点击下一步 蓝色方框部分需要去掉,软件包…...

日本站群服务器的优点以及适合该服务器的业务类型?
日本站群服务器的优点以及适合该服务器的业务类型? 日本站群服务器是指位于日本地区的多个网站共享同一台服务器的架构。这种服务器架构有着诸多优点,使其成为许多企业和网站管理员的首选。以下是日本站群服务器的优点以及适合该服务器的业务类型的分析࿱…...
)
ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板) Discord 的异步消息流、上下文截断机制与用户高频…...

使用Nodejs和Taotoken构建一个多轮对话代理服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken构建一个多轮对话代理服务 为全栈或后端开发者设计一个场景,利用Node.js环境下的openai包&#…...

Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进
Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

Halo Cursor:轻量级框架无关的动画光标库设计与实践
1. 项目概述:一个轻量、无框架绑定的动画光标库最近在重构一个前端项目,想给用户界面增加一点微妙的动态反馈,提升交互的精致感。我第一个想到的就是自定义光标效果。市面上这类库不少,但要么体积臃肿,要么和特定框架&…...

CAJ转PDF神器:caj2pdf-qt让学术文献格式转换变得如此简单
CAJ转PDF神器:caj2pdf-qt让学术文献格式转换变得如此简单 【免费下载链接】caj2pdf-qt CAJ 转 PDF 转换器(GUI 版本) 项目地址: https://gitcode.com/gh_mirrors/ca/caj2pdf-qt 还在为CAJ格式的学术文献无法在手机、平板或其他设备上阅…...

TI INA333数据手册没细说的5个细节:增益电阻怎么选?温漂怎么算?你的电路可能一直没优化
INA333电路设计进阶指南:数据手册没告诉你的5个关键优化点 在精密测量电路设计中,INA333作为TI经典的仪表放大器,被广泛应用于传感器信号调理、医疗设备和工业控制等领域。虽然数据手册提供了基本参数和典型应用电路,但许多工程师…...

凰标:让草根创作不再被资本随意定义@凤凰标志
——一场属于民间的反垄断革命当代文娱行业最大的不公,从来不是草根缺乏创作能力,而是资本垄断了全部的定义权与话语权。 长期以来,从作品好坏、内容价值、审美取向到行业前途,所有评判标准皆由资本制定、流量数据裁定。无数底层创…...
)
DataX实战避坑:手把手教你用Shell脚本搞定MySQL多表同步(附完整脚本)
DataX多表同步实战:从脚本优化到生产级部署的全链路指南 MySQL数据同步是数据仓库建设中的基础环节,而DataX作为阿里巴巴开源的高效数据同步工具,在实际生产环境中却常常因为脚本设计不当导致维护成本激增。本文将从一个真实电商平台的订单系…...

Android MediaProjection实战:从权限适配到异常处理,构建Android Q+的稳定截屏录屏功能
1. 理解MediaProjection的核心机制 在Android Q及以上版本中,MediaProjection API是系统级截屏和录屏功能的唯一官方入口。与早期版本直接调用adb screencap或反射获取Surface不同,这套机制通过用户显式授权的方式实现隐私保护。我曾在多个项目中遇到过因…...

OpenFOAM-dev后处理与数据可视化:ParaView与fieldFunctionObjects实战指南
OpenFOAM-dev后处理与数据可视化:ParaView与fieldFunctionObjects实战指南 【免费下载链接】OpenFOAM-dev OpenFOAM Foundation development repository 项目地址: https://gitcode.com/gh_mirrors/op/OpenFOAM-dev OpenFOAM-dev作为开源CFD领域的核心工具&a…...