【ytb数据采集器】按关键词批量爬取视频数据,界面软件更适合文科生!
一、背景介绍
1.1 爬取目标
用Python独立开发的爬虫工具,作用是:通过搜索关键词采集油管的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评论数,视频简介。
软件是通过调用ytb的谷歌官方API实现,并非通过网页爬虫,所以稳定性较高!
开通YouTube的API:【详细教程】手把手教你开通YouTube官方API接口(youtube data api v3)
开发成界面软件的目的:方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
软件界面截图:
爬取结果截图:
结果截图1:
结果截图2: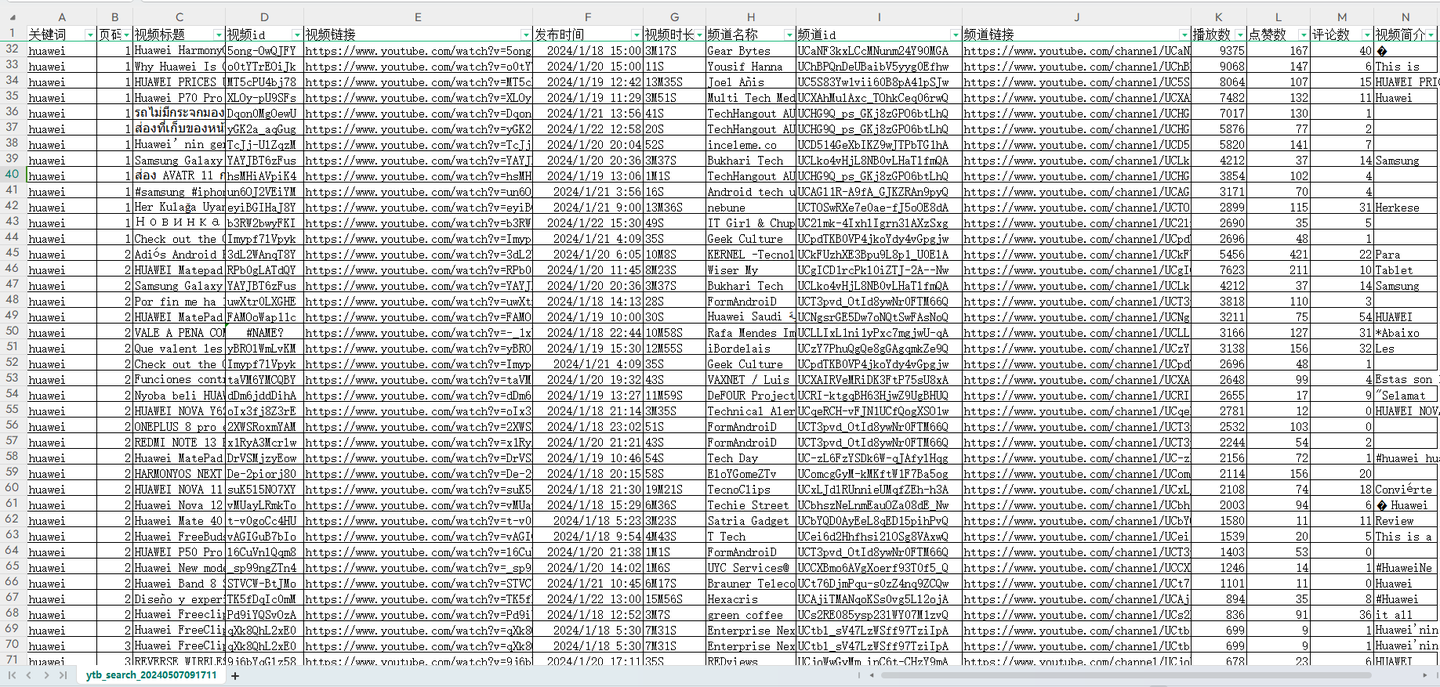
结果截图3: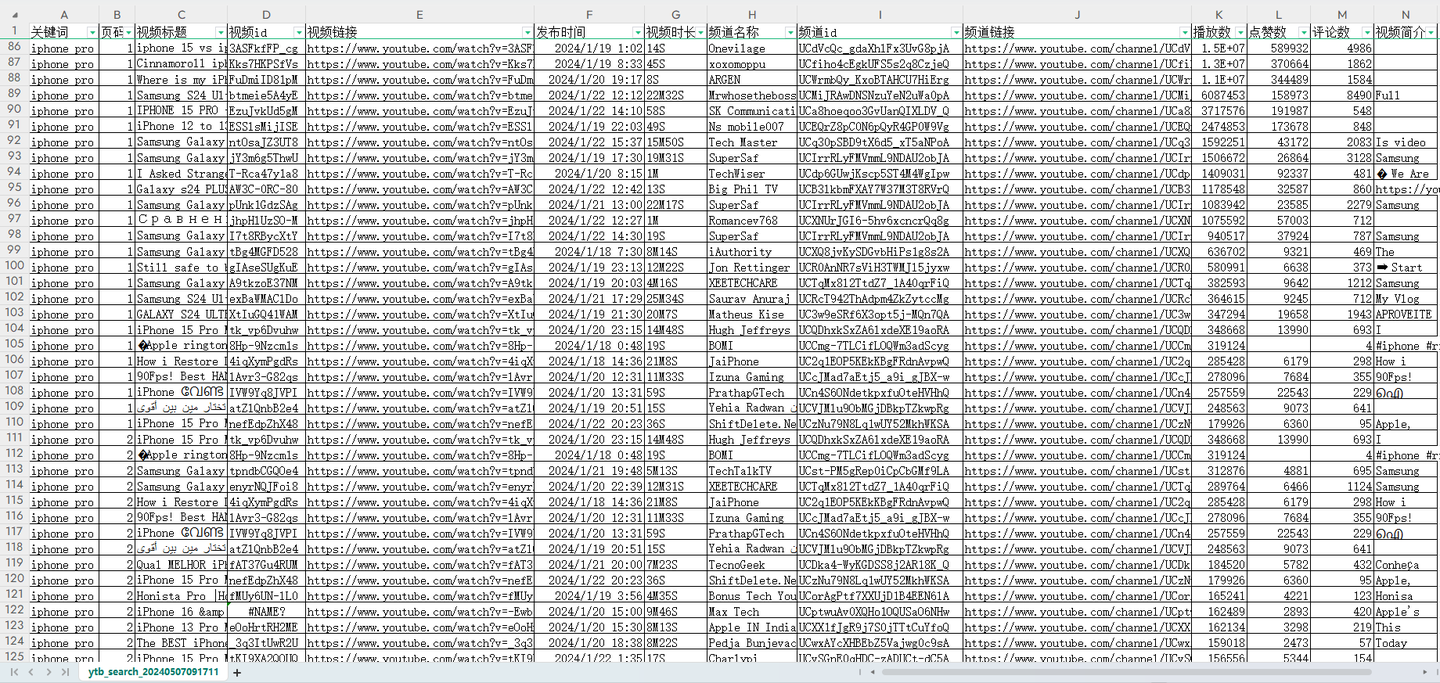
以上。
1.2 演示视频
软件使用演示:(不懂编程的小白直接看视频,了解软件作用即可,无需看代码)
【软件演示】youtube采集工具,根据关键词爬搜索结果
1.3 软件说明
几点重要说明:
以上。
二、代码讲解
2.1 调用API-搜索接口
先给大家看看搜索接口的返回json数据:
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://youtube.googleapis.com/youtube/v3/search'
定义一个请求头,用于伪造浏览器:
# 请求头
self.headers = {"Accept": "*/*","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {'part': 'snippet','maxResults': '25','q': search_keyword,'key': self.API_KEY,'pageToken': pageToken,'order': self.sort_by,'publishedBefore': str(self.end_date) + 'T00:00:00Z','publishedAfter': str(self.start_date) + 'T00:00:00Z',
}
2.2 调用API-详情接口
同样,先给大家看看详情接口的返回json数据:
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://youtube.googleapis.com/youtube/v3/videos?part=snippet%2CcontentDetails%2Cstatistics&id={}&key={}'.format(video_id, self.API_KEY)
定义一个请求头,用于伪造浏览器:
# 请求头
self.headers = {"Accept": "*/*","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
下面就是发送请求和接收数据:
# 发送请求
r = requests.post(url, headers=self.headers)
# 接收数据
json_data = r.json()
逐个解析字段数据,以"播放数"为例:
# 播放数
try:viewCount = json_data['items'][0]['statistics']['viewCount']
except:viewCount = ''
其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 保存csv文件
with open(self.result_file, 'a+', encoding='utf_8_sig', newline='') as f:writer = csv.writer(f)writer.writerow([search_keyword, page, title, videoId, video_url, create_time, duration, channelTitle,channelId, channel_url, viewCount, likeCount, commentCount, desc])
self.tk_show('csv保存成功:' + self.result_file)
我采用csv库保存结果,实现每爬一条存一次,防止中途异常停止丢失前面的数据。
完整代码中,还含有:读取API_KEY判断、循环结束条件判断、拼接频道URL、try异常保护、日志记录等关键实现逻辑。
2.3 API_KEY说明
API_KEY是访问YouTube官方接口的密钥,只有拿到密钥,并配置到代码里,才能正常调用API接口。
API开通的教程:【详细教程】手把手教你开通YouTube官方API接口(youtube data api v3)
拿到密钥之后,配置到当前文件的config.json里面即可,如下: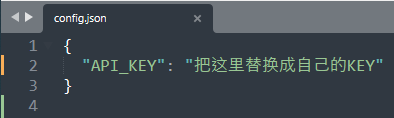
另外,魔法是一切的前提,此处不便多说!
2.4 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('爬YouTube搜索软件v1.0 | 马哥python说 | 定制+v:493882434')
# 设置窗口大小
root.minsize(width=850, height=650)
# 左上角图标
root.iconbitmap('mage.ico')
输入控件部分:
# keyword
tk.Label(root, justify='left', text='搜索关键词:').place(x=30, y=90)
entry_kw = tk.Text(root, bg='#ffffff', width=70, height=2, )
entry_kw.place(x=125, y=90, anchor='nw') # 摆放位置
tk.Label(root, justify='left', text='多关键词以|分隔', fg='red', ).place(x=630, y=90)
运行日志部分:
# 运行日志
tk.Label(root, justify='left', text='运行日志:').place(x=30, y=280)
show_list_Frame = tk.Frame(width=780, height=260) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=310, anchor='nw') # 摆放位置
底部版权部分:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.5 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):self.logger = logging.getLogger(__name__)# 日志格式formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'# 日志级别self.logger.setLevel(logging.DEBUG)# 控制台日志sh = logging.StreamHandler()log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')# info日志文件名info_file_name = time.strftime("%Y-%m-%d") + '.log'# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。case_dir = r'./logs/'info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,when='MIDNIGHT',interval=1,backupCount=7,encoding='utf-8')
日志文件截图: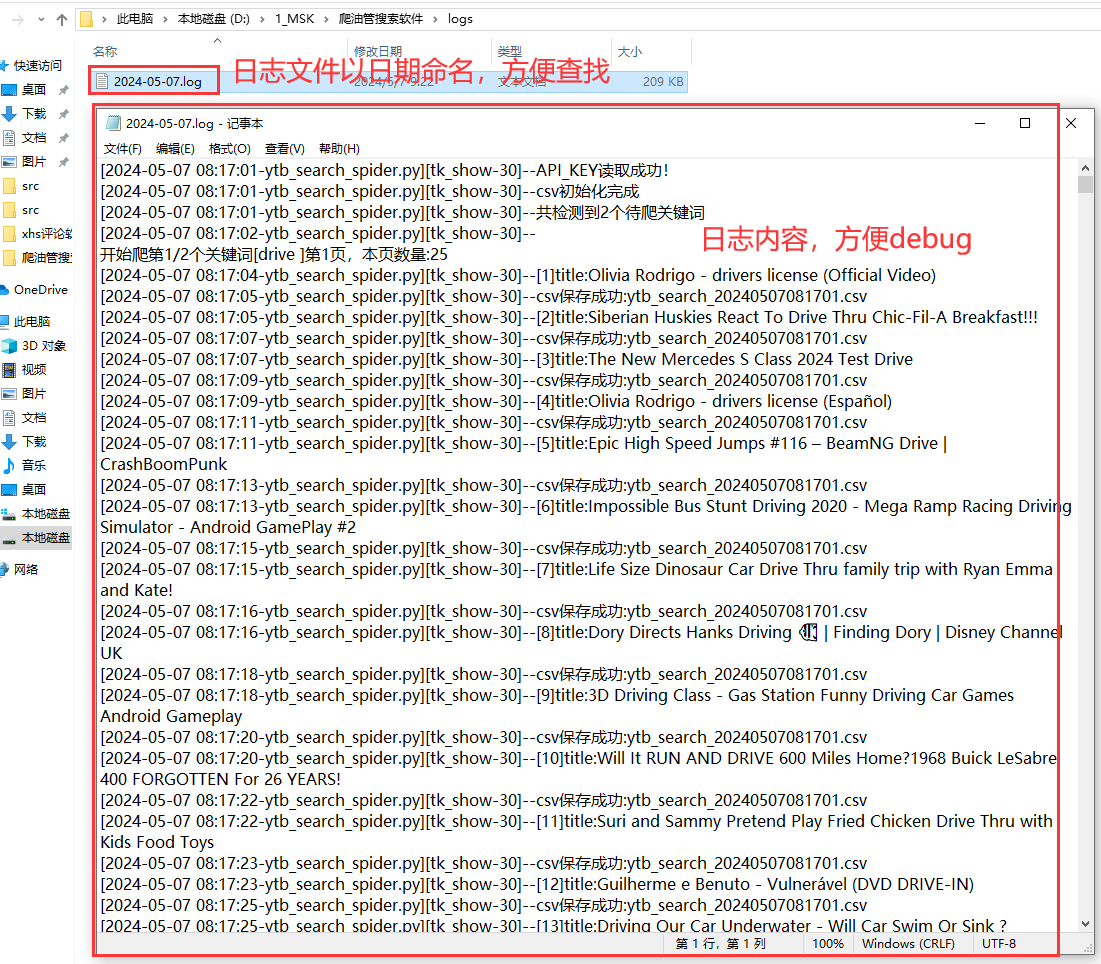
以上。
三、获取源码及软件
完整python源码及exe软件,微信公众号"老男孩的平凡之路“后台回复”爬油管搜索软件"即可获取。点击直达
相关文章:
【ytb数据采集器】按关键词批量爬取视频数据,界面软件更适合文科生!
一、背景介绍 1.1 爬取目标 用Python独立开发的爬虫工具,作用是:通过搜索关键词采集油管的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评论数…...

三条命令快速配置Hugging Face
大家好啊,我是董董灿。 本文给出一个配置Hugging Face的方法,让你在国内可快速从Hugging Face上下在模型和各种文件。 1. 什么是 Hugging Face Hugging Face 本身是一家科技公司,专注于自然语言处理(NLP)和机器学习…...

Python网络编程 03 实验:FTP详解
文章目录 一、小实验FTP程序需求二、项目文件架构三、服务端1、conf/settings.py2、conf/accounts.cgf3、conf/STATUS_CODE.py4、启动文件 bin/ftp_server.py5、core/main.py6、core/server.py 四、客户端1、conf/STATUS_CODE.py2、bin/ftp_client.py 五、在终端操作示例 一、小…...
)
个人银行账户管理程序(2)
在(1)的基础上进行改进 1:增加一个静态成员函数total,记录账户总金额和静态成员函数getTotal 2对不需要改变的对象进行const修饰 3多文件实现 account。h文件 #ifndef _ACCOUNT_ #define _ACCOUNT_ class SavingAccount {pri…...

2024.04.19校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、校招&转正实习 | 美团无人机业务部招聘(内推) 校招&转正实习 | 美团无人机业务部招聘(内推) 2、校招&实习 | 快手 这些岗位…...

Python并发编程 04 进程与线程基础
文章目录 一、操作系统简介二、进程三、线程四、线程的调用1、示例2、join方法3、setDaemon方法4、继承式调用(不推荐)5、其他方法 一、操作系统简介 ①操作系统是一个用来协调、管理和控制计算机硬件和软件资源的系统程序,它位于硬件和应用…...
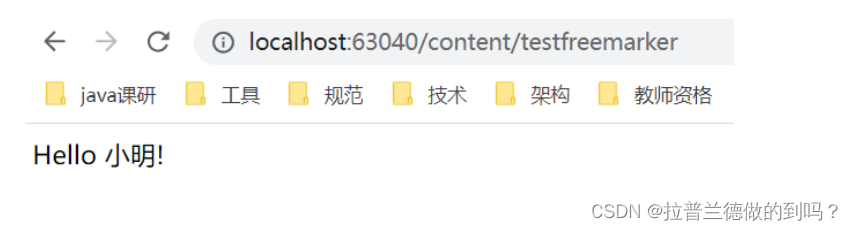
模板引擎Freemarker
什么是模板引擎 根据前边的数据模型分析,课程预览就是把课程的相关信息进行整合,在课程预览界面进行展示,课程预览界面与课程发布的课程详情界面一致。 项目采用模板引擎技术实现课程预览界面。什么是模板引擎? 早期我们采用的…...

刷题训练之模拟
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:熟练掌握模拟算法。 > 毒鸡汤:学习,学习,再学习 ! 学,然后知不足。 > 专栏选自:刷题训…...

视频监控平台:交通运输标准JTT808设备SDK接入源代码函数分享
目录 一、JT/T 808标准简介 (一)概述 (二)协议特点 1、通信方式 2、鉴权机制 3、消息分类 (三)协议主要内容 1、位置信息 2、报警信息 3、车辆控制 4、数据转发 二、代码和解释 (一…...
)
【C++】多态 — 多态的细节补充(下篇)
前言: 我们学习了多态的形式和如何使用多态,这一章我们将来讲一讲多态的原理… 目录 动态绑定与静态绑定: 动态绑定与静态绑定: 静态绑定又称为前期绑定(早绑定),在程序编译期间确定了程序的行为,也称为静态多态,比如…...
系统安全与应用【2】
1.开关机安全控制 1.1 GRUB限制 限制更改GRUB引导参数 通常情况下在系统开机进入GRUB菜单时,按e键可以查看并修改GRUB引导参数,这对服务器是一个极大的威胁。可以为GRUB 菜单设置一个密码,只有提供正确的密码才被允许修改引导参数。 实例&…...
EtherCAT总线速度轴控制功能块(COSESYS ST源代码)
测试环境为汇川PLC,型号 AM402-CPU1608TP、伺服驱动器为禾川X3E,具体通信配置可以参考下面文章链接: 1、使能和点动控制 汇川AM400PLC通过EtherCAT总线控制禾川X3E伺服使能和点动控制-CSDN博客文章浏览阅读31次。进行通信之前需要安装禾川X3E的XML文件,具体方法如下:1、汇…...

【码银送书第十九期】《图算法:行业应用与实践》
作者:嬴图团队 01 前言 在当今工业领域,图思维方式与图数据技术的应用日益广泛,成为图数据探索、挖掘与应用的坚实基础。本文旨在分享嬴图团队在算法实践应用中的宝贵经验与深刻思考,不仅促进业界爱好者之间的交流,…...
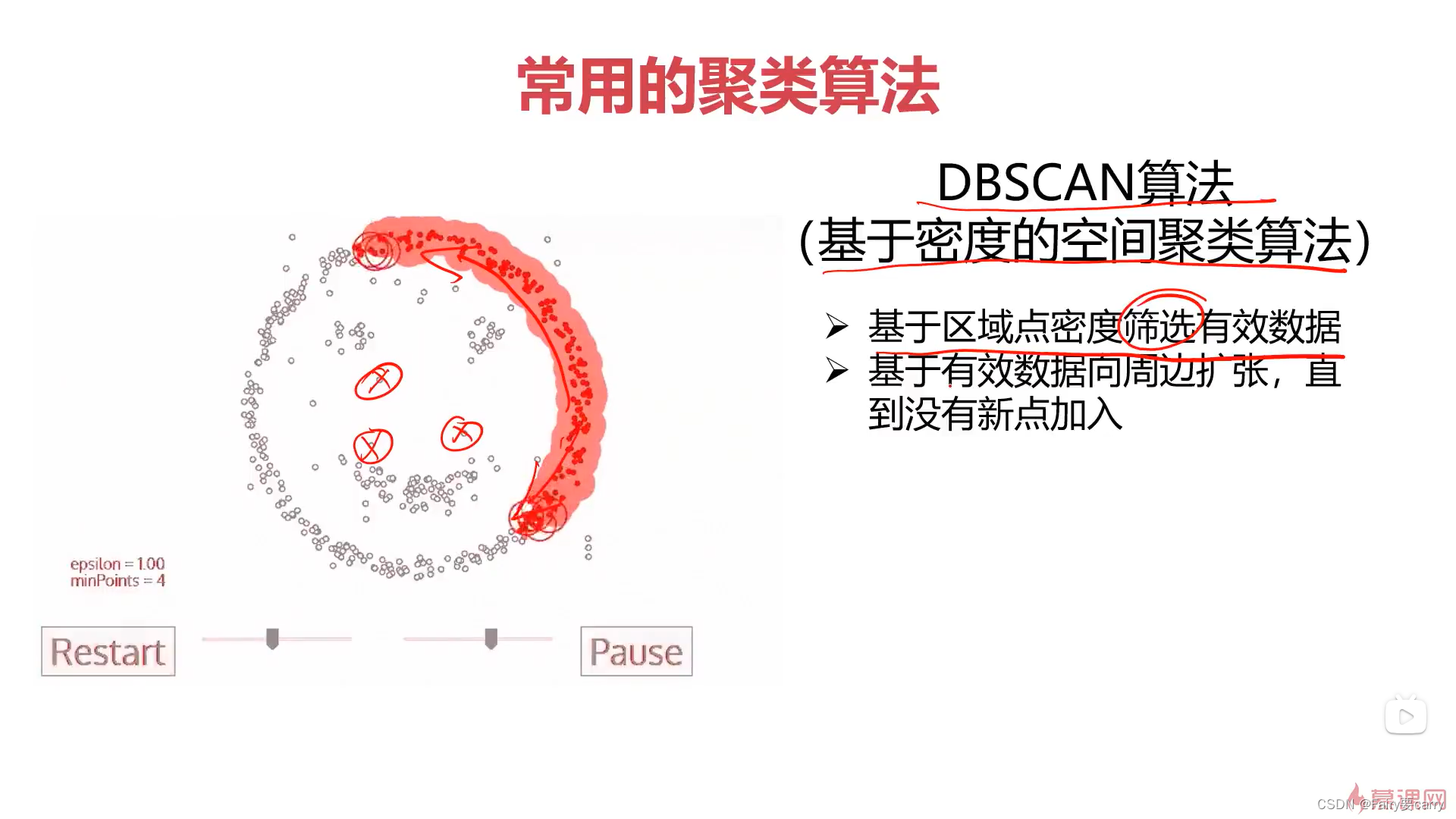
无监督式学习
1.是什么? 无监督式学习与监督式学习**最大的区别就是:**没有事先给定的训练实例,它是自动对输入的示例进行分类或者分群; 优点:不需要标签数据,极大程度上扩大了我们的数据样本,其次不受监督信…...

docker 安装镜像及使用命令
目录 1. Mysql2. Redis3. Nginx4. Elasticsearch官网指导 docker pull 容器名:版本号 拉取容器, 不指定版本号默认最新的 run 运行 -d 后台运行 -p 3306:3306 -p是port 对外端口:对内端口 –name xyy_mysql 容器名称 -e MYSQL_ROOT_PASSWORD123456 环境变量 -v 系统地址:docker…...

Python运维之多进程!!
本节的快速导航目录如下喔!!! 一、创建进程的类Process 二、进程并发控制之Semaphore 三、进程同步之Lock 四、进程同步之Event 五、进程优先队列Queue 六、多进程之进程池Pool 七、多进程之数据交换Pipe 一、创建进程的类Process mu…...

Redis(无中心化集群搭建)
文章目录 1.无中心化集群1.基本介绍2.集群说明 2.基本环境搭建1.部署规划(6台服务器)2.首先删除上次的rdb和aof文件(对之前的三台服务器都操作)1.首先分别登录命令行,关闭redis2.清除/root/下的rdb和aof文件3.把上次的…...
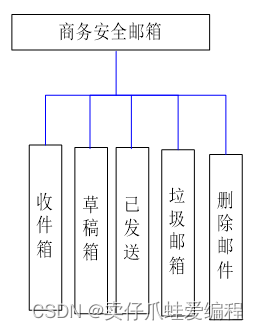
基于springboot+jsp+Mysql的商务安全邮箱邮件收发
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...
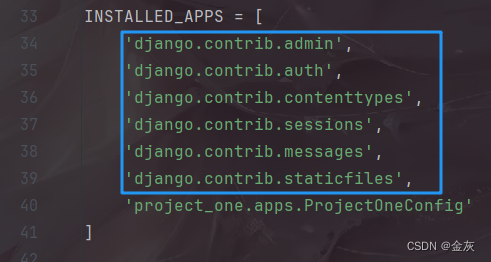
三.Django--ORM(操作数据库)
目录 1 什么是ORM 1.1 ORM优势 1.2ORM 劣势 1.3 ORM与数据库的关系 2 ORM 2.1 作用 2.2 连接数据库 2.3 表操作--设置字段 2.4 数据库的迁移 写路由增删改查操作 项目里的urls.py: app里的views.py: 注意点: 1 什么是ORM ORM中文---对象-关系映射 在MTV,MVC设计…...

【华为】AC直连二层组网隧道转发实验配置
【华为】AC直连二层组网隧道转发实验配置 实验需求拓扑配置AC数据规划表 AC的配置顺序AC1基本配置(二层通信)AP上线VAP组关联--WLAN业务流量 LSW1AR1STA获取AP的业务流量 配置文档 实验需求 AC组网方式:直连二层组网。 业务数据转发方式:隧道转发。 DHC…...

基于OpenClaw的GitHub趋势智能监控器:自动化追踪与AI摘要推送
1. 项目概述:一个为开发者打造的GitHub趋势智能监控器 作为一名长期泡在GitHub上的开发者,我深知每天手动刷“Trending”页面有多低效。热门项目层出不穷,但真正值得关注的往往就那么几个,而且很容易被淹没在信息流里。直到我遇到…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

图像识别与目标检测:从概念到实战的全面解析
1. 项目概述:从“认脸”到“找茬”的认知跃迁在计算机视觉这个行当里干了十几年,我见过太多刚入行的朋友,甚至是一些有经验的开发者,对“图像识别”和“目标检测”这两个词傻傻分不清楚。经常有人拿着一个“识别猫狗”的需求过来&…...

基于图特征选择与XGBoost的电动公交预测性维护模型构建
1. 项目概述:从数据洪流到精准预警的挑战在电动公交的日常运营中,车辆控制器局域网(CAN)总线每秒都在产生海量的传感器数据,从电池电压、电机温度到刹车片厚度,这些数据流如同车辆的“生命体征”。预测性维…...

NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档
NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档 【免费下载链接】NomNom NomNom is the most complete savegame editor for NMS but also shows additional information around the data youre about to change. You can also easily look up each item indi…...

clawhealth:本地化Garmin健康数据同步与自动化分析工具实践
1. 项目概述:打造你的本地健康数据中心如果你和我一样,手腕上常年戴着一块Garmin手表,每天看着它记录步数、心率、睡眠,但总觉得这些数据只是躺在Garmin Connect的云端,自己没法真正“拥有”和分析,那么cla…...

如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南
如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...

嵌入式Linux SPI屏驱动踩坑实录:fbtft模块加载失败与dmesg排错指南
嵌入式Linux SPI屏驱动深度排错指南:从dmesg到硬件配置的全链路解析 当你在树莓派或全志H3开发板上折腾那块SPI接口的TFT屏幕时,是否经历过这样的绝望时刻?设备树配置看起来完美无缺,insmod命令执行后却只收获一片漆黑的屏幕和满屏…...

移动安全架构:ECC加密与硬件加速实践解析
1. 移动安全架构的核心价值解析在2004年的移动通信市场,设备制造商正面临一个关键转折点。当时全球手机平均售价为163美元(智能手机高达360美元),而设备替换率预计将从2003年的22%增长到2009年的34%。在这个背景下,Cer…...

3D Tiles Tools终极指南:如何快速掌握3D模型格式转换与优化
3D Tiles Tools终极指南:如何快速掌握3D模型格式转换与优化 【免费下载链接】3d-tiles-tools 项目地址: https://gitcode.com/gh_mirrors/3d/3d-tiles-tools 在3D地理空间数据可视化领域,3D Tiles Tools是一套功能强大的开源工具集,专…...