常用SQL命令
应用经常需要处理用户的数据,并将用户的数据保存到指定位置,数据库是常用的数据存储工具,数据库是结构化信息或数据的有序集合,几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制,作为测试人员,掌握SQL语言是必要的。
我们一般对数据库的数据表进行增删改查的操作,以下是一些常用的SQL命令。
数据表增加数据
我们可以通过insert into语句向表中插入新记录
使用该命令有2种方式:
| 命令形式 | 描述 |
|---|---|
INSERT INTO table_name VALUES (value1,value2,value3,...),(value1_2,value2_2,value3_2,...),...,(value1_n,value2_n,value3_n,...); | 无需指定要插入数据的列名,只需提供被插入的值即可,但需要注意,被插入的表中有多少个字段(即列),则值就必须有多少个,且需要按照表字段排序进行赋值 |
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...),(value1_2,value2_2,value3_2,...),...,(value1_n,value2_n,value3_n,...); | 需要指定列名及被插入的值 ,column与value一一对应,即column1=value1,column2=value2 |
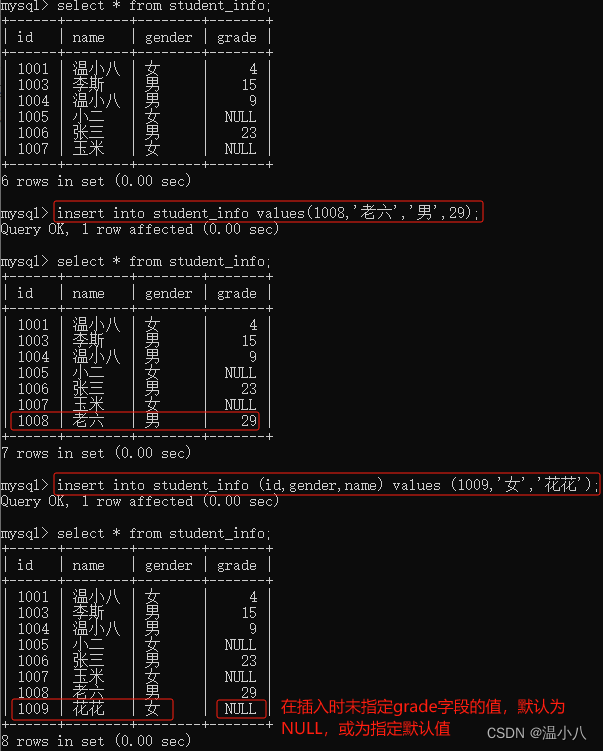
数据表删除数据
可以用DELETE命令删除指定的数据(工作中慎用,即使使用,必须检查where语句是否正确)
命令:DELETE FROM table_name WHERE xxx;
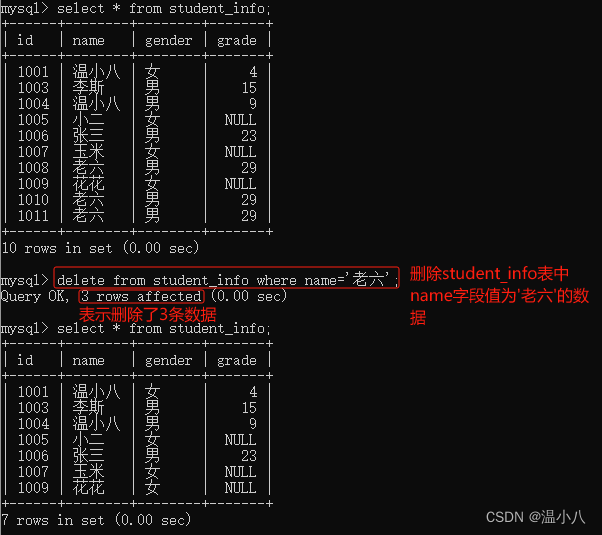
数据表修改数据
如果需要修改表中一些数据,可以使用UPDATE命令
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
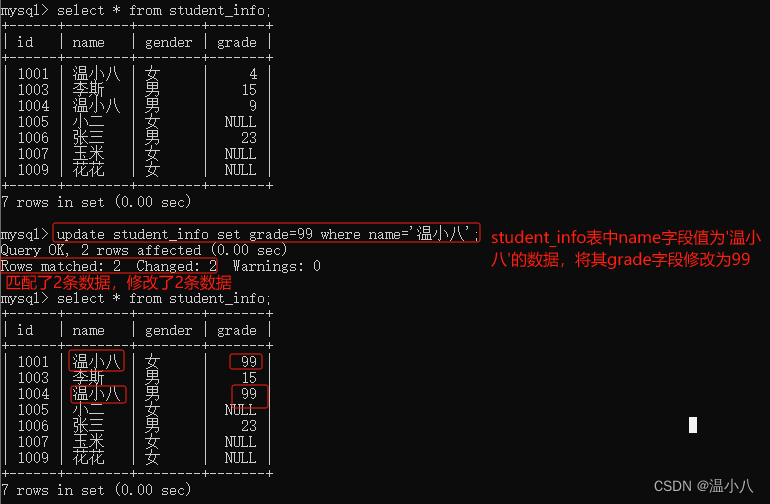
数据表查询数据
数据表操作最多的就是查询了,即SELECT语句,
| 命令形式 | 描述 |
|---|---|
SELECT column1, column2, ... FROM table_name [where xxx]; | 查询table_name表符合xxx条件的数据的指定字段值 |
SELECT * FROM table_name [where xxx]; | 查询table_name表符合xxx条件的数据的所有字段值 |
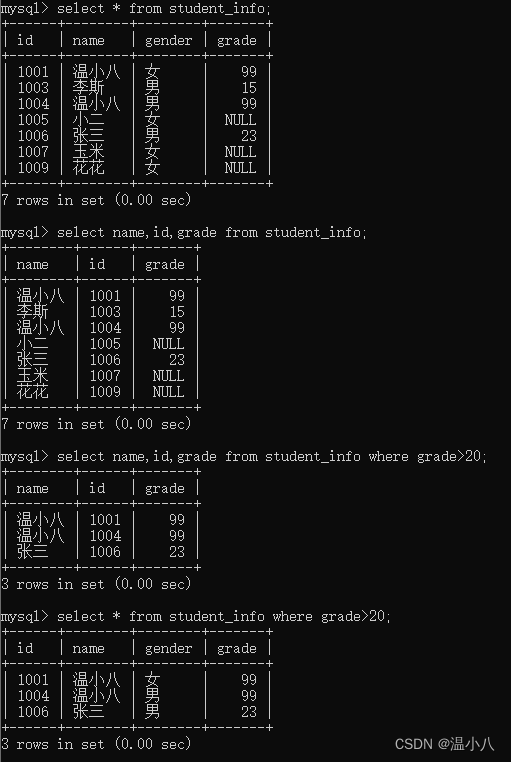
函数
在SELECT语句中,经常会用一些函数对数据进行统计,常用函数如下:
| 函数 | 说明 |
|---|---|
COUNT() | 返回符合条件的数据量 |
MAX() | 返回最大值 |
MIN() | 返回最小值 |
DISTINCT() | 在表中,一个列可能会包含多个重复值,该函数返回所在列去重后的所有值 |
ROUND() | 把数值字段四舍五入入为指定的小数位数 |
COUNT()
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入)
| 函数 | 说明 |
|---|---|
SELECT COUNT(*) FROM table_name[where xxx]; | 返回表中符合where条件的数据的总量 |
SELECT COUNT(column_name) FROM table_name[where xxx]; | 返回表中符合where条件的,且列column_name的值不为NULL的总量,类似于 SELECT COUNT(*) FROM table_name where column_name is not NULL[ and xxx]; |
SELECT COUNT(condition) FROM table_name[where xxx]; | 返回表中符合where条件,且满足condition!=null的数据量 |
SELECT COUNT(condition or NULL) FROM table_name[where xxx]; | 返回表中符合where条件,且满足condition的数据量 |
COUNT(*)和COUNT(column_name)
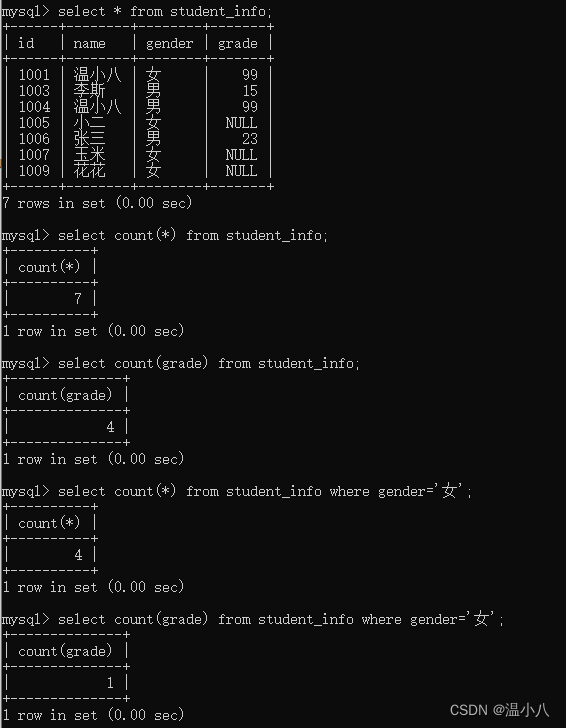
COUNT(condition)
前面说了,COUNT()函数是统计指定条件不为NULL的数据,所以对于SELECT COUNT(condition) FROM table_name[where xxx];语句,只要符合where条件的数据,在condition不为NULL,就会被统计进去,有几种比较常用的用法
我们有时会碰到COUNT(数字)的用法,因为统计指定条件不为NULL的数据,而数字肯定不是NULL,所以COUNT(数字)相当于统计符合where条件的数据量
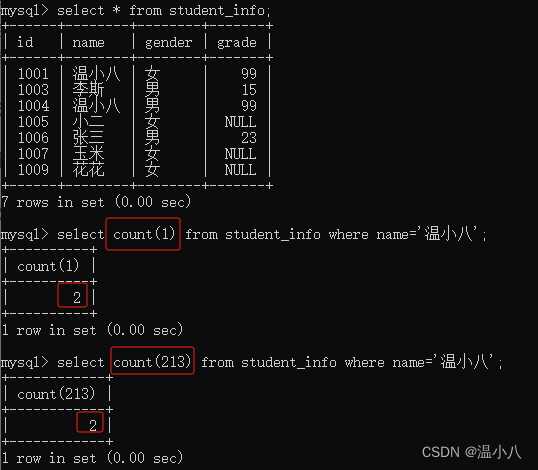
另一种就是条件表达式,我们需要统计的数据量除了要符合where条件外,还需要符合指定条件
如下图所示,在COUNT()函数里加上了条件表达式,但是条件表达式需要注意的一点是:COUNT()函数是根据值是否为NULL去统计的,所以条件表达式要根据结果为NULL去判断,即如果条件表达式得到的结果是true或false,对于COUNT()函数来说,都是可统计的,因为true和false都不是NULL,所以如果需要统计符合条件的,可以在条件表达式后加上or NULL,如果前面的条件表达式为true时,不会走后面为NULL的设置,如果为false时,则会走后面为NULL的设置
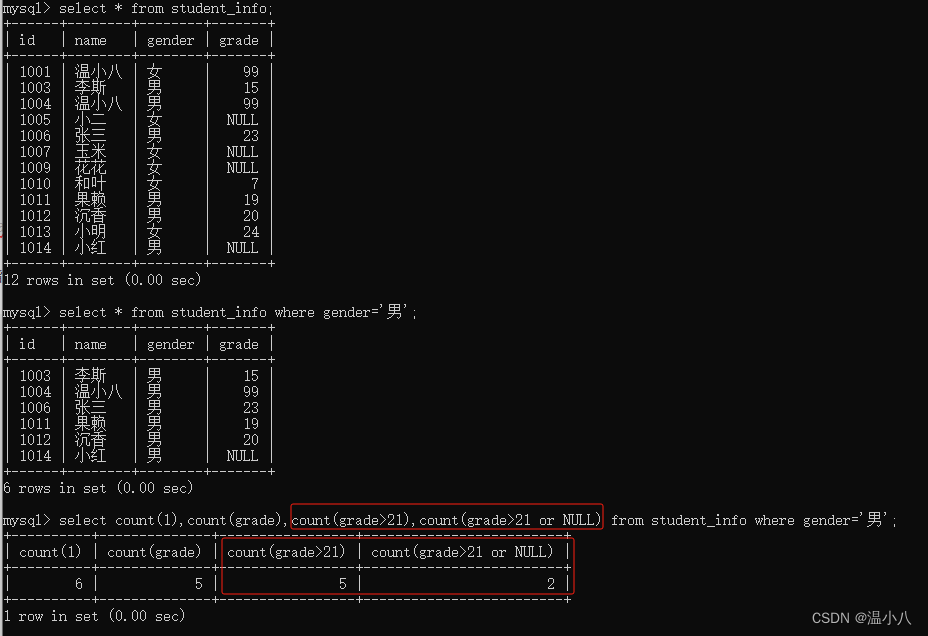
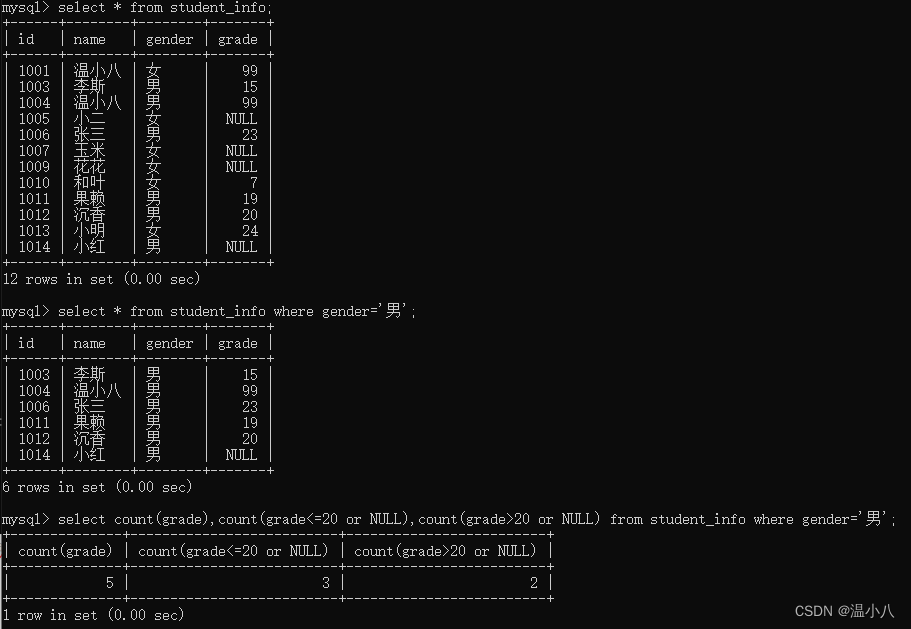
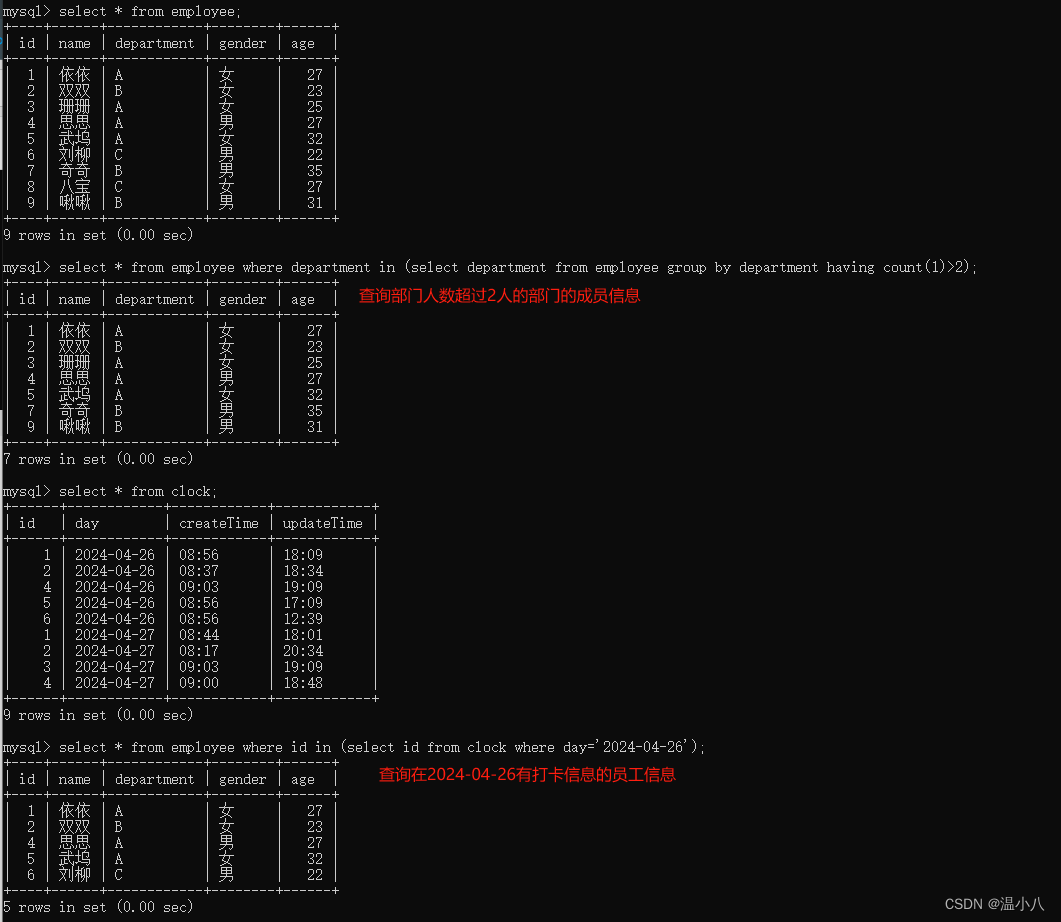
注意:可能有人会有疑问,如果还需要符合指定条件,为什么不在where条件中加上,而是在count()函数中指定?因为有些查询可能比较复杂,比如需要从不同的维度去查询的时候,where条件会将数据范围固定在某些条件中,count()则可以在指定的符合where条件的数据范围中去统计不同维度的数据,具体按照实际需要去使用即可,如下:
如统计男性中grade>20和grade<=20的数据量
MAX()和MIN()
| 命令 | 使用说明 |
|---|---|
SELECT MAX(column_name) FROM table_name[where xxx]; | 传入的是列名,结果是返回指定列的最大值 |
SELECT MIN(column_name) FROM table_name[where xxx]; | 传入的是列名,结果是返回指定列的最小值 |
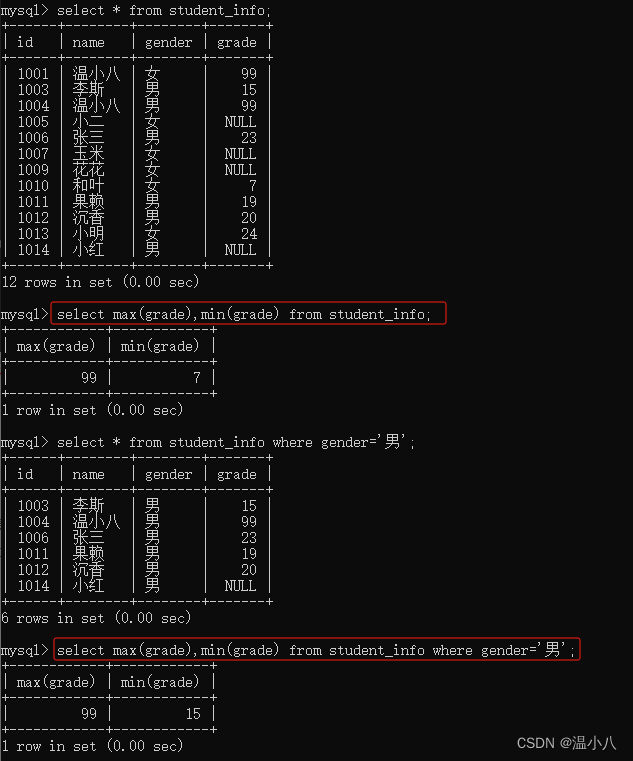
DISTINCT()
命令行:
SELECT DISTINCT column1, column2, ... FROM table_name[ where xxx];
描述:将column1, column2, …等字段值均不重复的数据返回(即去重)
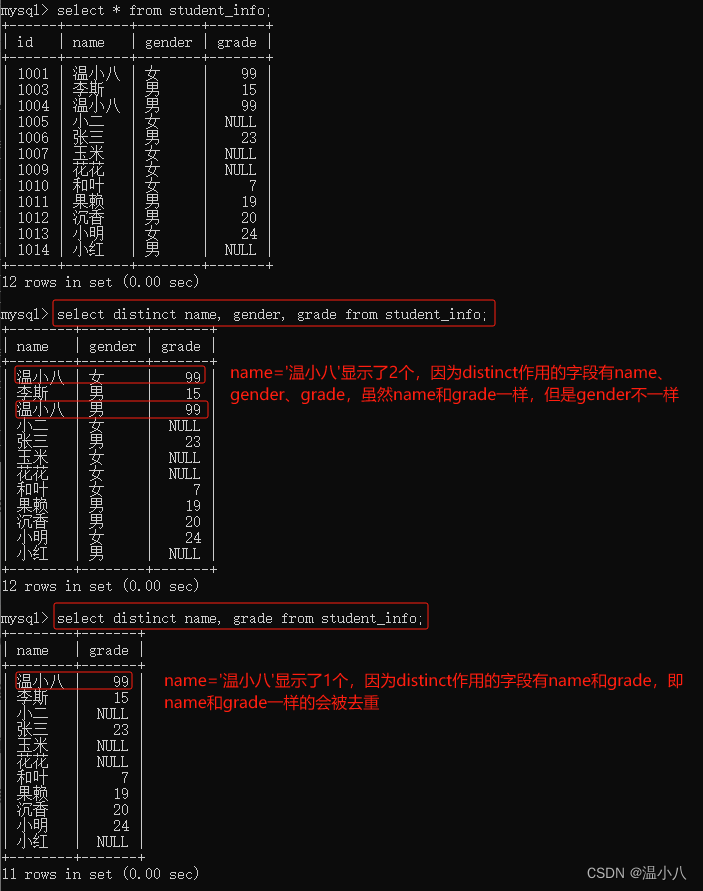
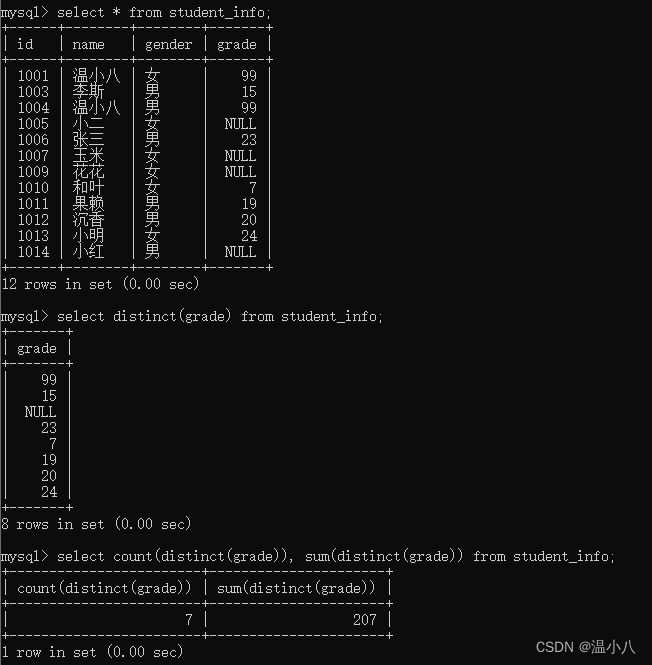
有时候DISTINCT()函数会和其他函数如COUNT()、SUM()一起使用
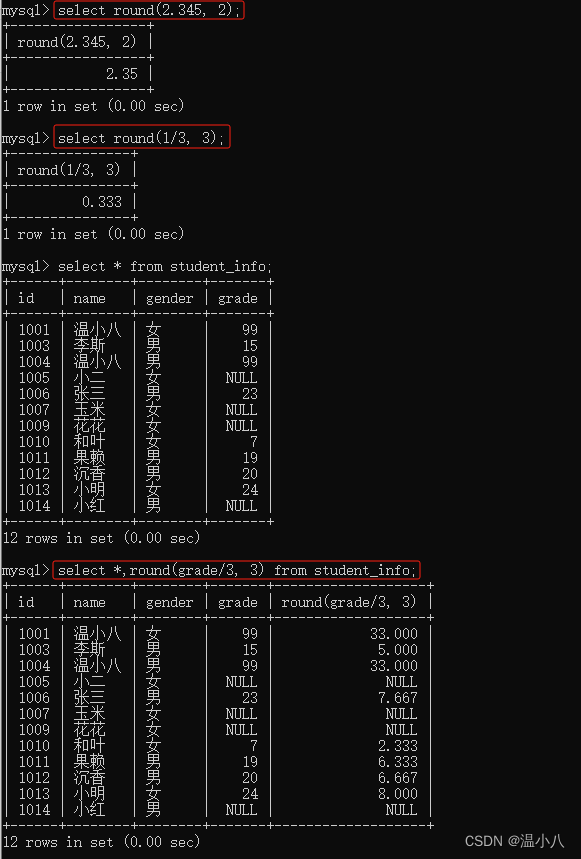
ROUND()
命令:
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;
说明:将column_name列的数值按照指定小数位(decimals)四舍五入
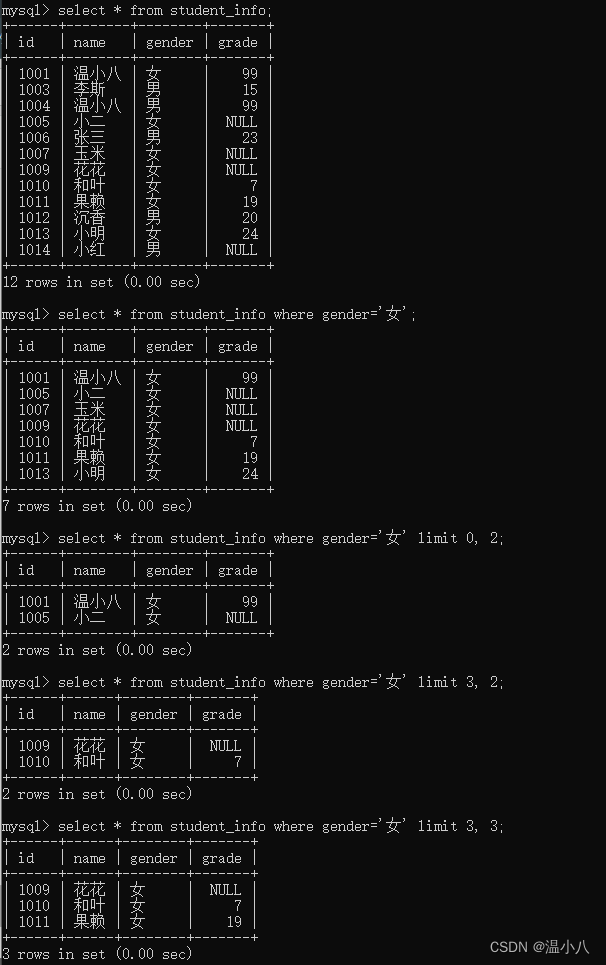
LIMIT
命令行:
select * from table_name [where xxx] limit [offset,] rows
描述:用于限制查询结果返回的数量,常用于分页查询
- offset:偏移量,即从哪个位置开始,如果未提供,则默认从0开始(数据表查询结果的位置从0开始算),如果offset超过了符合where条件的数据量或表的总数据量,则结果返回为空
- rows:取行数量,即最多取多少行
注意:并不是所有的数据库都支持LIMIT,也不是所有支持LIMIT语法的数据库,其LIMIT的用法都一致
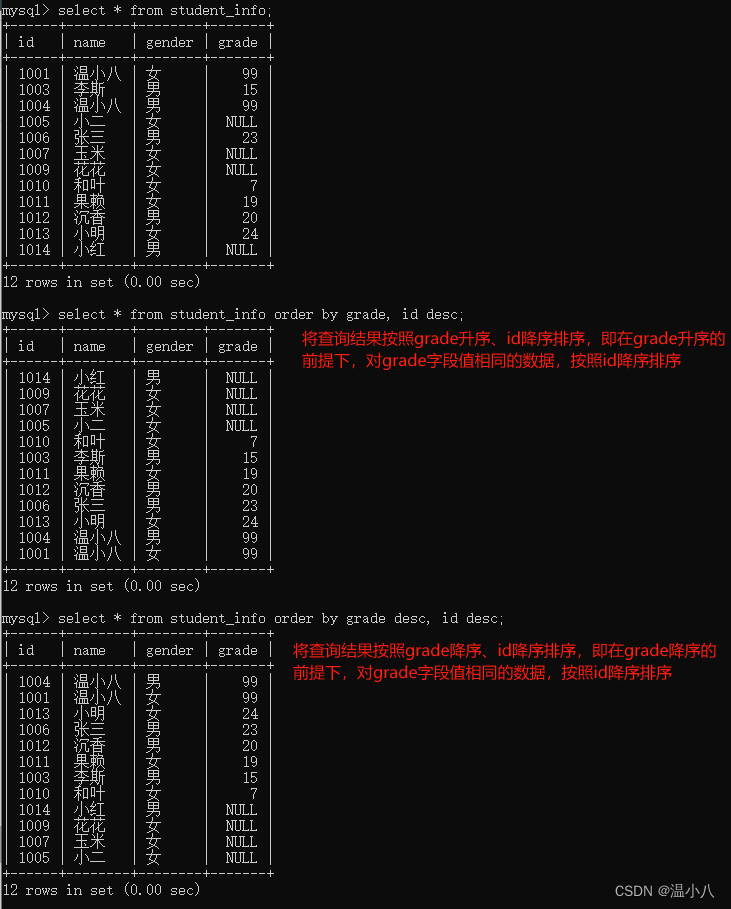
ORDER BY
命令行:
SELECT column1, column2, ... FROM table_name [where xxx] ORDER BY column1, column2, ... ASC|DESC;
描述:对结果集按照一个列或者多个列进行排序(默认升序排序)
- ASC:表示按升序排序。
- DESC:表示按降序排序。
分组查询GROUP BY和HAVING 子句
分组,即按照指定特征(列),将特征相同(字段值相同)的分为同一个组,不同的特征分为不同组,在数据表中,可以理解为按照某些列中,每一行数据的指定列的值进行区分,若这些列的值相同,则分为同一组,不相同,则不在同一个组。在用来分组的列上我们可以使用 COUNT()、 SUM()、MAX()等函数进行数据统计。
命令行:
SELECT column1, aggregate_function(column2) FROM table_name WHERE condition GROUP BY column1;

注意,如果SQL语句里有where子句,GROUP BY是对where子句筛选后的数据进行分组,不是对整张表进行分组
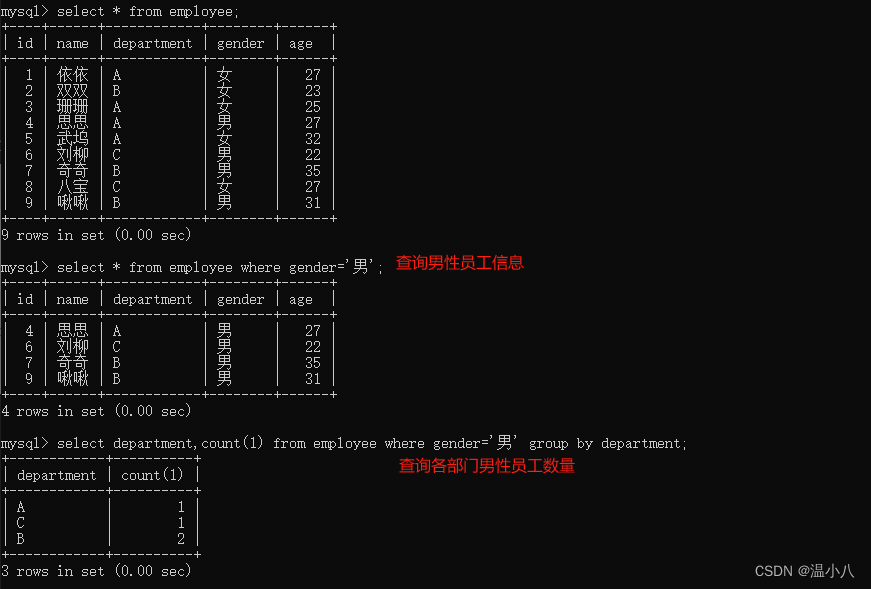
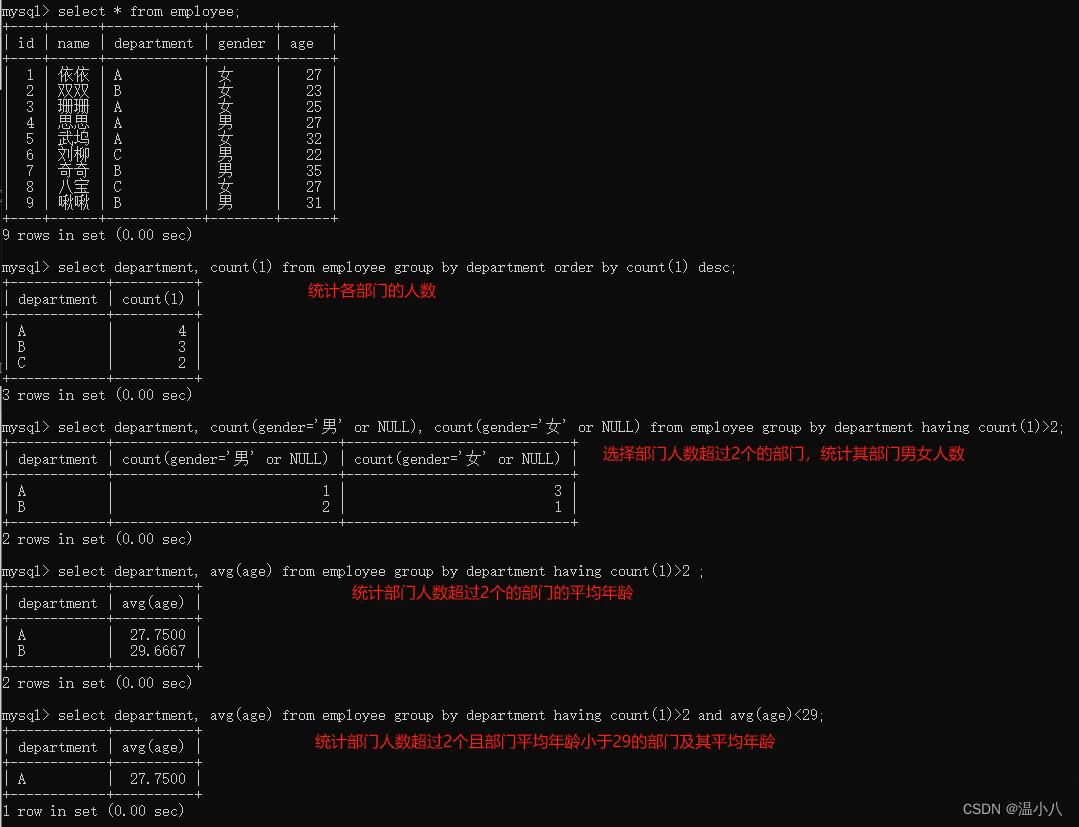
有时候我们需要对分组后的数据进行过滤,则可以使用HAVING,HAVING是对分组后的数据进行过滤
命令行:
SELECT column_1, aggregate_function(column_2) FROM table_name WHERE condition GROUP BY column_1,...,cloumn_n HAVING aggregate_function(column_xx)xxx;
EXISTS 运算符
命令行:
SELECT xx FROM table_name WHERE [not] EXISTS (SELECT xxx);
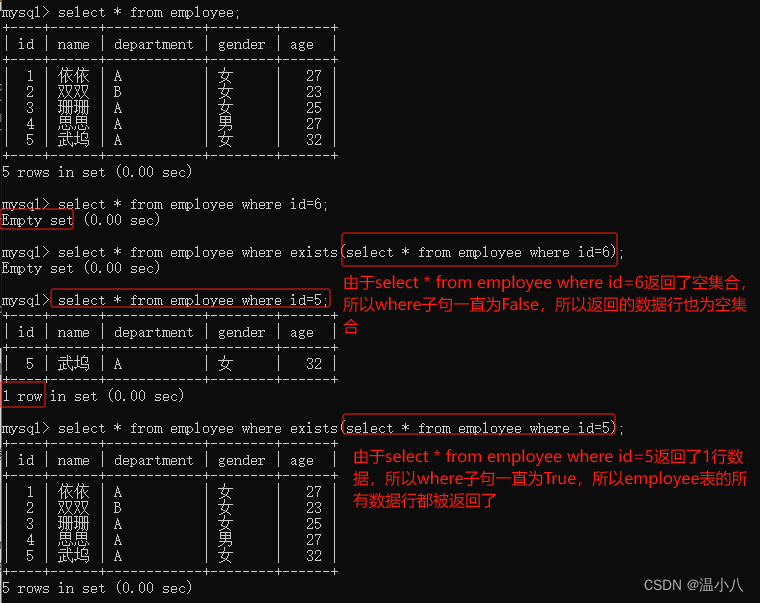
描述:EXISTS用于判断查询子句是否有记录,如果有至少一条记录存在返回 True,否则返回 False(如果where子句返回True,则显示该数据行,如果where子句返回False,则不显示该数据行)
如下图所示,select 1=2和select NULL都会返回1行记录,根据EXISTS子句如果有至少1条记录返回True,得到where子句一直为True,所有数据行被返回;由于select * from demo;返回了空集合(即1条记录都没有),所以EXISTS子句返回了False,即where子句一直为False,所以数据行都没有被返回。
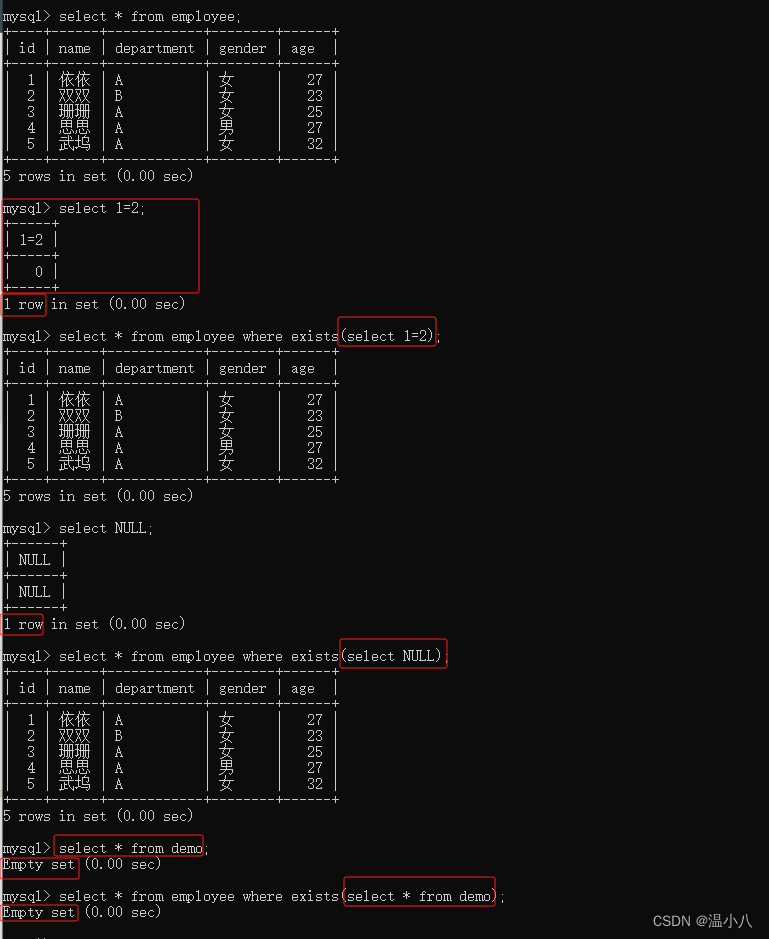
根据上面的例子,可以很容易理解以下的例子:
JOIN子句
JOIN相关子句是用于将两个或者多个表结合起来,再进行相关操作
| 函数 | 说明 |
|---|---|
inner join | 内连接,以连接条件(on t1.column1=t2.column1)作为判断,如果column1对应的值在2个表中都有数值,则进行数据行连接并返回,如果在其中一个表中没有对应值,则不返回 |
left join | 左连接,以左表为核心进行连接,即以连接条件(on t1.column1=t2.column1)作为判断,如果左表的column1字段值在右表column1字段中有同样的值,则进行数据行连接并返回,如果在右表column1字段中有没有同样的值,则以右表所有字段值为NULL与左表对应数据行进行连接然后返回 |
right join | 右连接,以右表为核心进行连接,即以连接条件(on t1.column1=t2.column1)作为判断,如果右表的column1字段值在左表column1字段中有同样的值,则进行数据行连接并返回,如果在左表column1字段中有没有同样的值,则以左表所有字段值为NULL与右表对应数据行进行连接然后返回 |
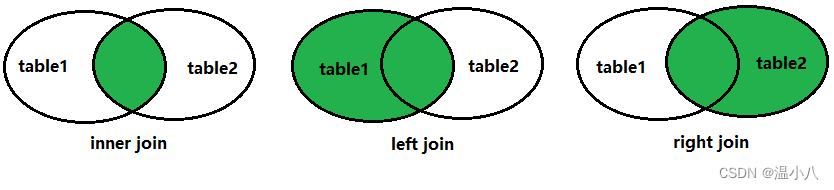
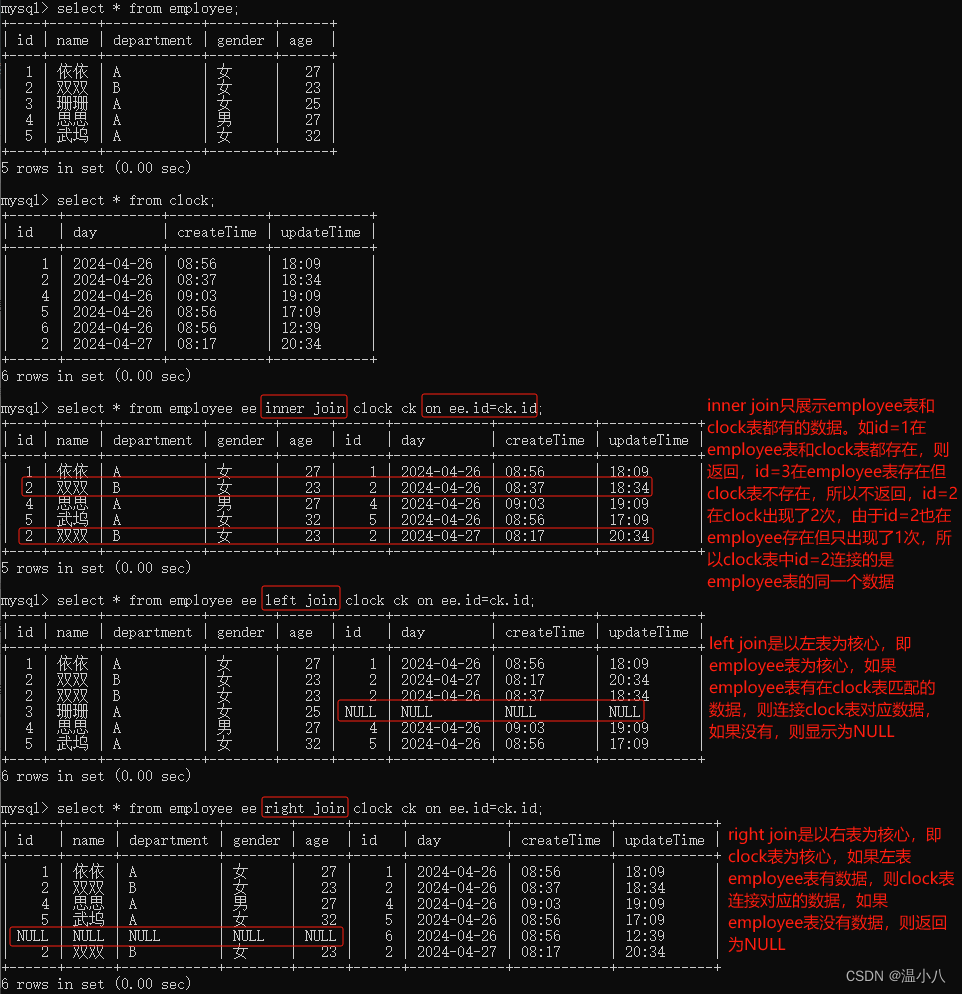
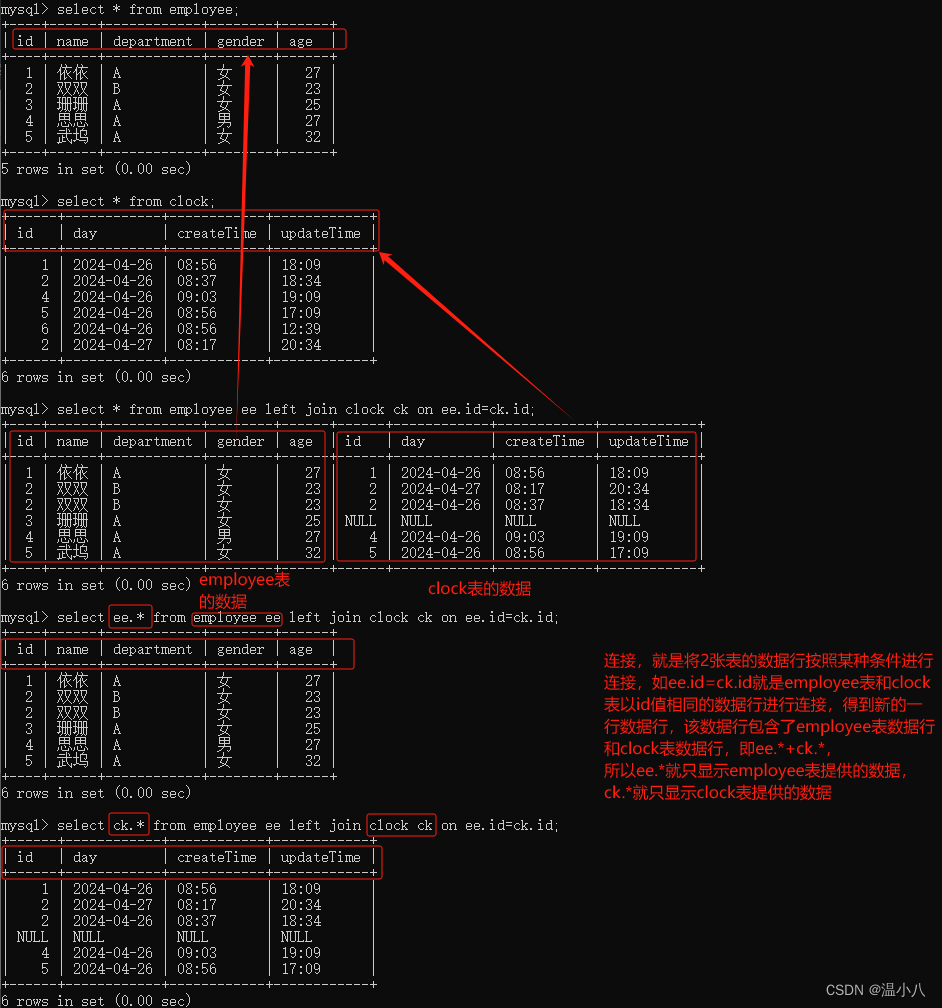
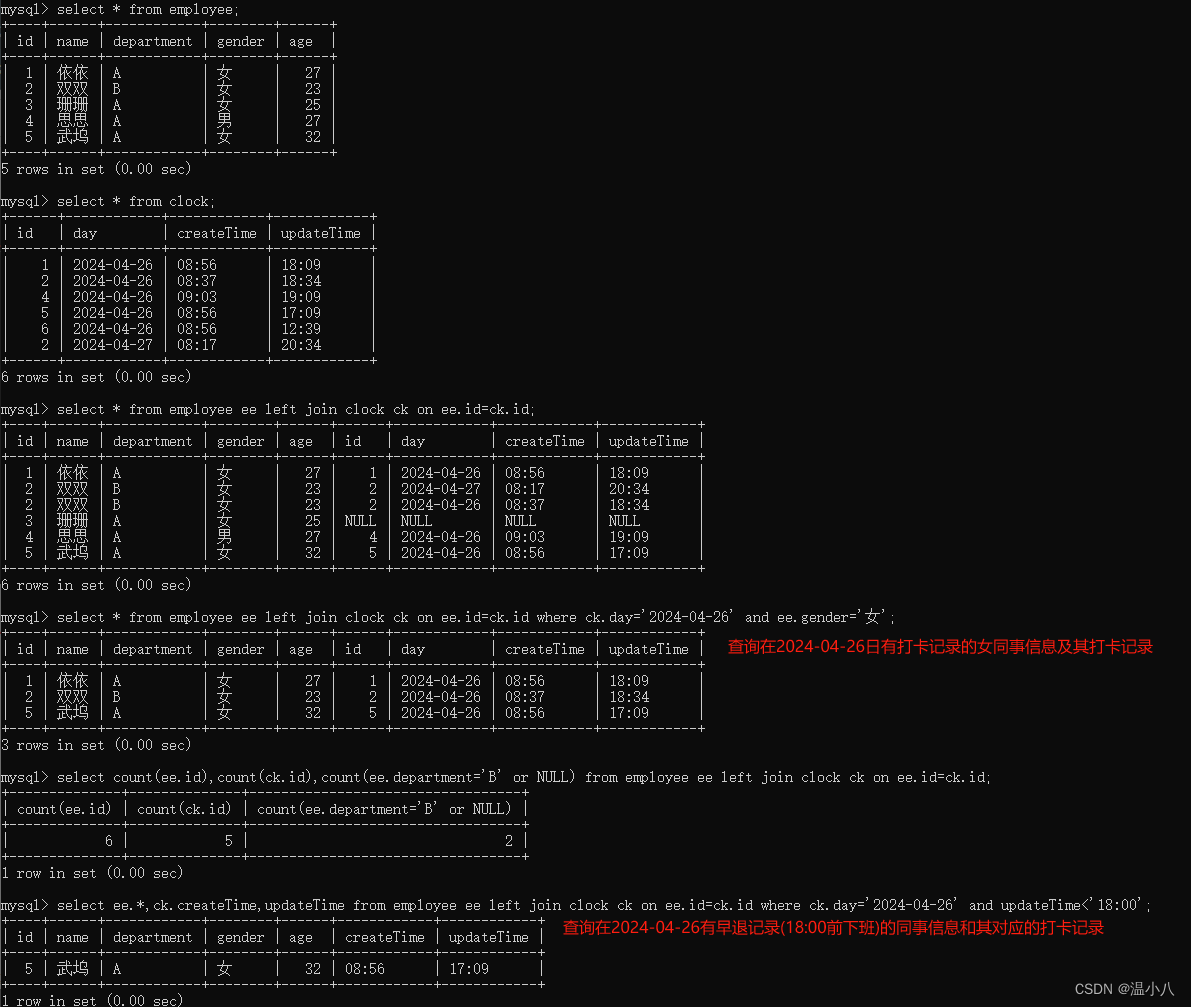
操作符
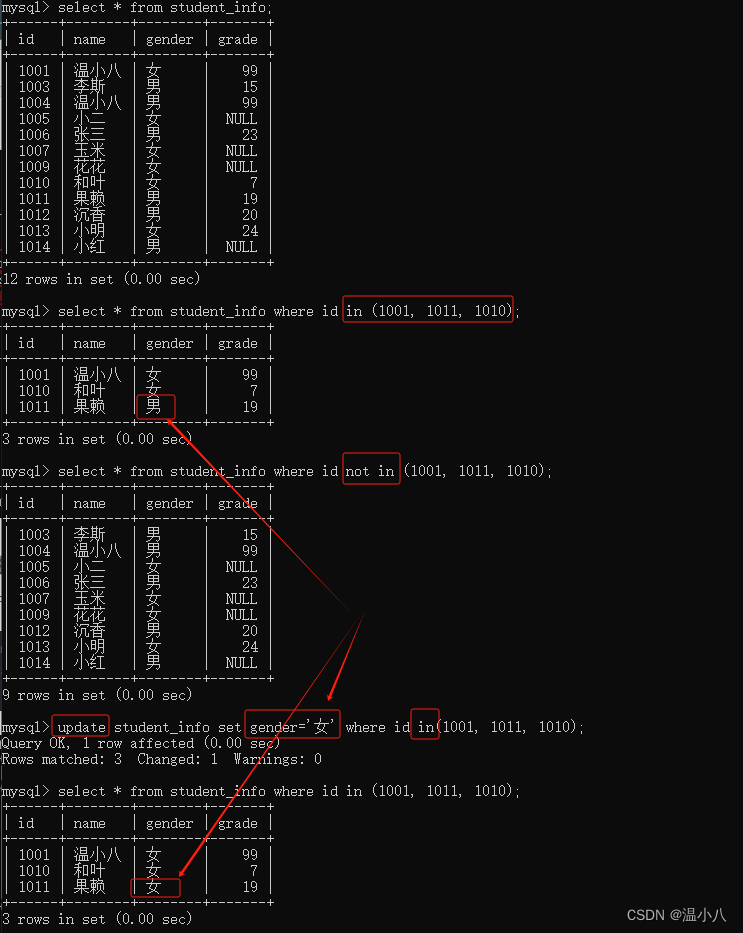
IN和NOT IN
| 命令 | 说明 |
|---|---|
SELECT/UPDATE/DELETE xxx WHERE column IN (value1, value2, ...); | 指定列(column)的值要在IN指定的范围内 |
SELECT/UPDATE/DELETE xxx WHERE column NOT IN (value1, value2, ...); | 指定列(column)的值要不在IN指定的范围内 |
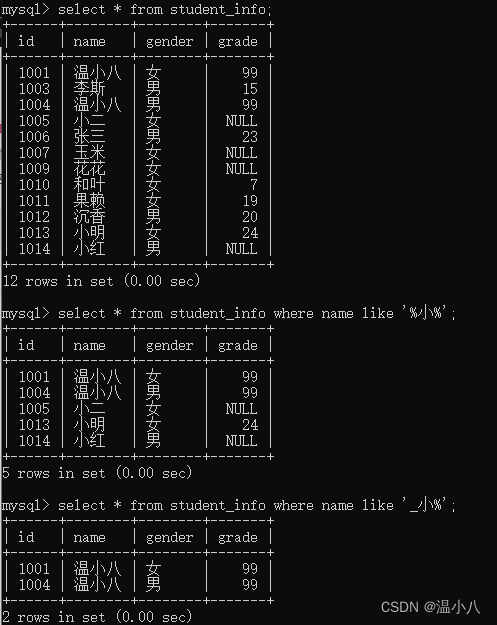
LIKE
命令:
SELECT/UPDATE/DELETE xxx WHERE column LIKE pattern;
描述:column列的值要模糊匹配指定模式
模式设置的有2个较常用的符号:
| 命令 | 说明 |
|---|---|
% | 匹配0个或多个字符 |
_ | 匹配一个字符 |
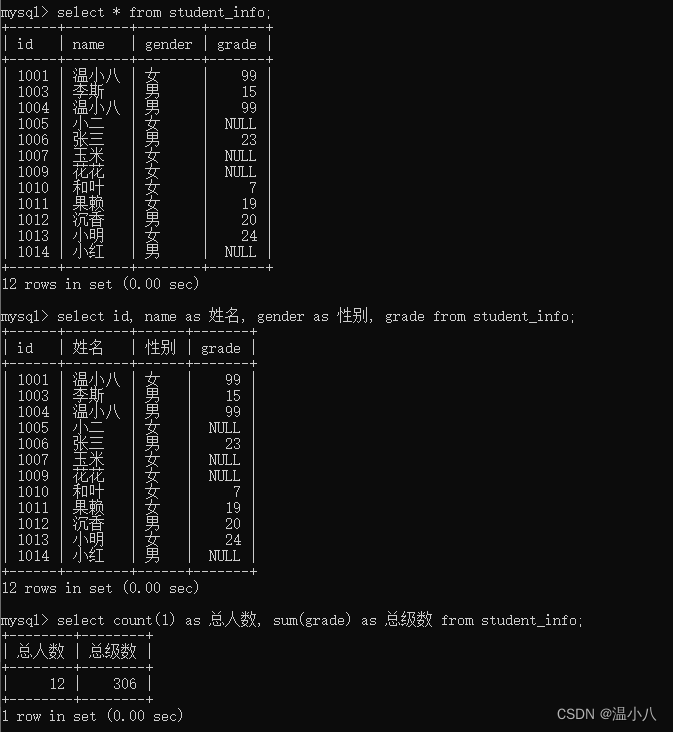
AS别名
别名,是为了让列名称或表名称的可读性更强,而给字段名称或表取的名称
给列名称取别名命令:SELECT column_name1 AS 别名1, column_name2 AS 别名2,... FROM table_name;
有时候一个SQL执行语句中有多张表,这个时候就需要给表取别名来增强可读性
给表取别名命令:SELECT 别名.column_name1, 别名.column_name2,... FROM table_name [as] 别名;

嵌套子查询
嵌套子查询可以简单理解为在where语句中嵌套了select语句
命令行:
SELECT/UPDATE/DELETE xxx WHERE column IN/=/like (select column from xxx [where xxx]);
注意:嵌套的select语句查询的结果集必须是指定列column的结果集
相关文章:
常用SQL命令
应用经常需要处理用户的数据,并将用户的数据保存到指定位置,数据库是常用的数据存储工具,数据库是结构化信息或数据的有序集合,几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制&…...

【neteq】tgcall的调用、neteq的创建及接收侧ReceiveStatisticsImpl统计
G:\CDN\P2P-DEV\Libraries\tg_owt\src\call\call.cc基本是按照原生webrtc的来的:G:\CDN\P2P-DEV\tdesktop-offical\Telegram\ThirdParty\tgcalls\tgcalls\group\GroupInstanceCustomImpl.cpptg对neteq的使用 worker 线程创建call Call的config需要neteqfactory Call::CreateAu…...

使用Python读取las点云,写入las点云,无损坐标精度
目录 1 为什么要写这个博文2 提出一些关键问题3 给出全部代码安装依赖源码(laspy v2.x) 1 为什么要写这个博文 搜索使用python读写las点云数据,可以找到很多结果。但是! 有些只是简单的demo,且没有发现/说明可能遇到的…...

python开发二
python开发二 requests请求模块 requests 是一个常用的 Python 第三方库,用于发送 HTTP 请求。它提供了简洁且易于使用的接口,使得与 Web 服务进行交互变得非常方便。 发送 GET 请求并获取响应 import requestsresponse requests.get("https:/…...
部署JVS服务出现上传文件不可用,问题原因排查。
事情的起因是这样的,部门经理让我部署一下JVS资源共享框架,项目的地址是在这里 项目资源地址 各位小伙伴们做好了,我要开始发车了,全新的“裂开之旅” 简单展示一下如何部署JVS文档 直达链接 撕裂要开始了 本来服务启动的好好…...

机器视觉检测为什么是工业生产的刚需?
机器视觉检测在工业生产中被视为刚需,主要是因为它具备以下几个关键优势: 提高精度与效率:机器视觉系统可以进行高速、高精度的检测。这对于保证产品质量、减少废品非常关键。例如,在生产线上,机器视觉可以迅速识别产品…...
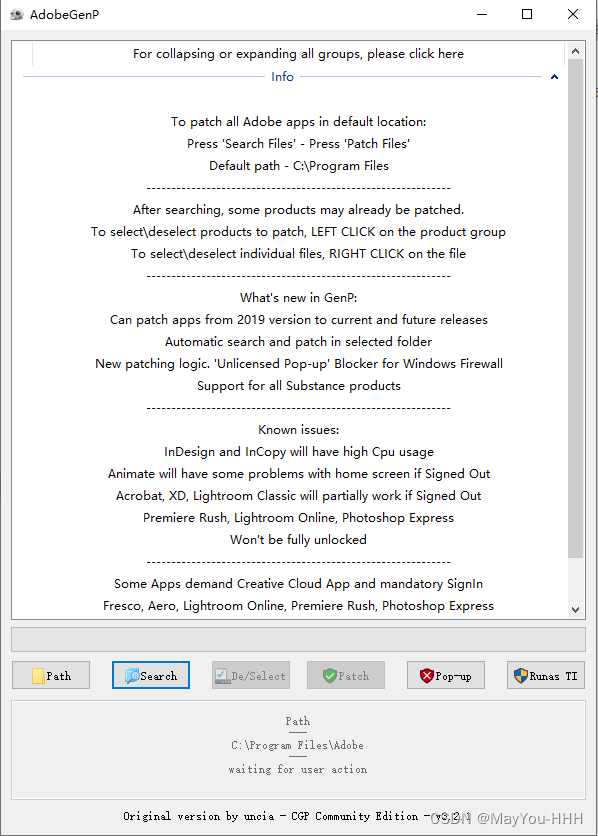
Adobe系列软件安装
双击解压 先运行Creative_Cloud_Set_Up.exe。 完毕后,运行AdobeGenP.exe 先Path,选路径,如 C:\Program Files\Adobe 后Search 最后Patch。 关闭软件,修图!...
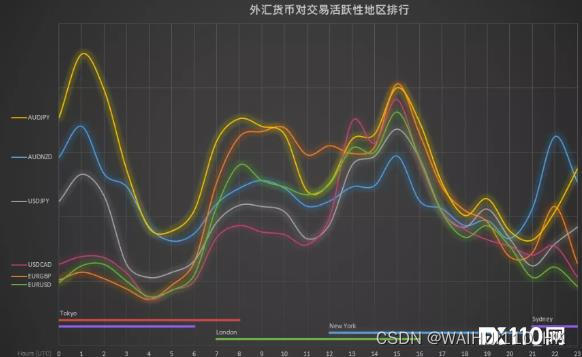
【FX110】2024外汇市场中交易量最大的货币对是哪个?
作为最大、最流动的金融市场之一,外汇市场每天的交易量高达几万亿美元,涉及到数百种货币。不同货币对的交易活跃程度并不一样,交易者需要根据货币对各自的特点去进行交易。 全年外汇市场中涉及美元的外汇交易超过50%! 实际上&…...
leetcode尊享面试100题(549二叉树最长连续序列||,python)
题目不长,就是分析时间太久了。 思路使用dfs深度遍历,先想好这个函数返回什么,题目给出路径可以是子-父-子的路径,那么1-2-3可以,3-2-1也可以,那么考虑dfs返回两个值,对于当前节点node来说&…...

C#面试题: 寻找中间值
给定一个数组,在区间内从左到右查找中间值,每次查找最小值与最大值区间内的中间值,且这个区间元素数量不小于3。 例如 1.给定数组float[] data { 1, 2.3f, 4, 5.75f, 8.125f, 10.5f, 13, 15, 20 } 输出:10.5、5.75、4、2.3、8…...
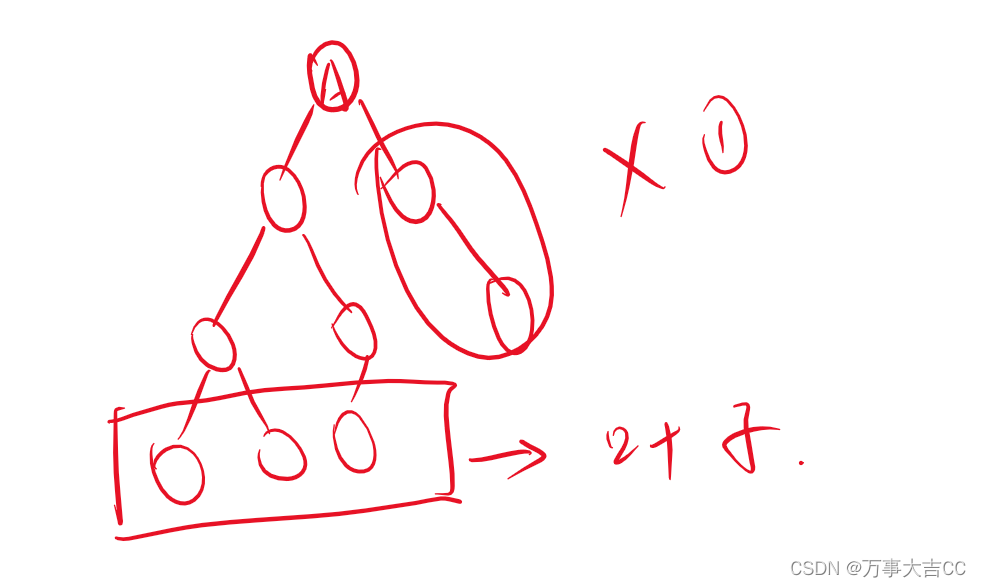
987: 输出用先序遍历创建的二叉树是否为完全二叉树的判定结果
解法: 一棵二叉树是完全二叉树的条件是: 对于任意一个结点,如果它有右子树而没有左子树,则这棵树不是完全二叉树。 如果一个结点有左子树但是没有右子树,则这个结点之后的所有结点都必须是叶子结点。 如果满足以上条…...

13:HAL---SPI
目录 一:SPL通信 1:简历 2:硬件电路 3:移动数据图 4:SPI时序基本单元 A : 开/ 终条件 B:SPI时序基本单元 A:模式0 B:模式1 C:模式2 D:模式3 C:SPl时序 A:发送指令 B: 指定地址写 C:指定地址读 5:NSS(CS) 6:时钟 二: W25Q64 1:简历 2…...

微服务---gateway网关
目录 gateway作用 gateway使用 添加依赖 配置yml文件 自定义过滤器 nacos上的gateway的配置文件 我们现在知道了通过nacos注册服务,通过feign实现服务间接口的调用,那对于不同权限的用户访问同一个接口,我们怎么知道他是否具有访问的权…...
HTML4(二)
文章目录 1 开发者文档2 基本标签2.1 排版标签2.2 语义化标签2.3 行内元素与块级元素2.4 文本标签2.5 常用标签补充 3 图片标签4 超链接标签4.1 跳转页面4.2 跳转文件4.3 跳转锚点4.4 唤起指定应用 5 列表5.1 有序列表5.2 无序列表5.3 自定义列表 6 表格6.1 基本结构6.2 表格标…...
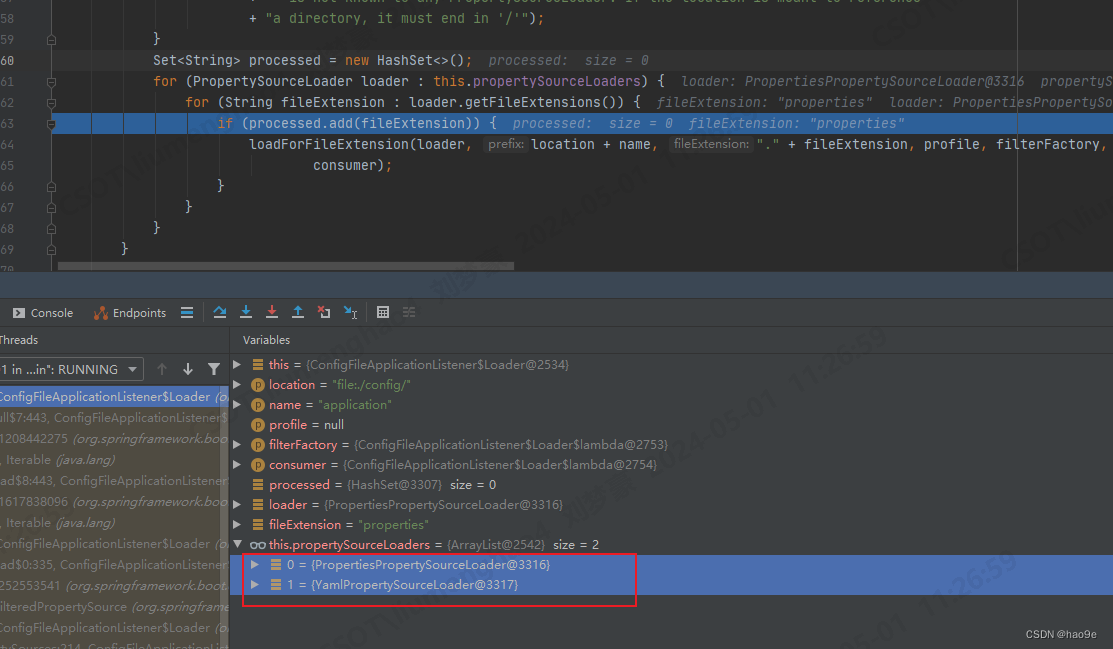
SpringBoot 扩展篇:ConfigFileApplicationListener源码解析
SpringBoot 扩展篇:ConfigFileApplicationListener源码解析 1.概述2. ConfigFileApplicationListener定义3. ConfigFileApplicationListener回调链路3.1 SpringApplication#run3.2 SpringApplication#prepareEnvironment3.3 配置environment 4. 环境准备事件 Config…...

蓝桥杯省三爆改省二,省一到底做错了什么?
到底怎么个事 这届蓝桥杯选的软件测试赛道,都说选择大于努力,软件测试一不卷二不难。省赛结束,自己就感觉稳啦,全部都稳啦。没想到一出结果,省三,g了。说落差,是真的有一点,就感觉和自己预期的…...
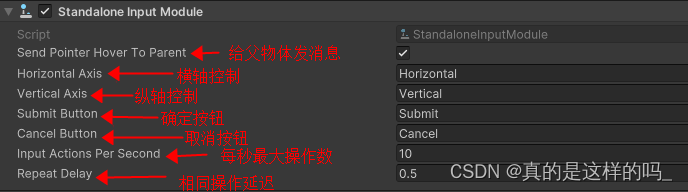
Unity EventSystem入门
概述 相信在学习Unity中,一定有被UI事件困扰的时候把,当添加UICanvas的时候,Unity会为我们自动添加EventSystem,这个是为什么呢,Unity的UI事件是如何处理的呢,在使用各个UI组件的时候,一定有不…...

第4章 Vim编辑器与Shell命令脚本
第4章 Vim编辑器与Shell命令脚本 1. Vim文本编辑器2. 编写Shell脚本2.2 接收用户的参数2.3 判断用户的参数 3. 流程控制语句3.1 if条件测试语句3.2 for条件循环语句3.3 while条件循环语句3.4 case条件测试语句 4. 计划任务服务程序复习题 1. Vim文本编辑器 Vim编辑器中设置了三…...
javaWeb快速部署到tomcat阿里云服务器
目录 准备 关闭防火墙 配置阿里云安全组 点击控制台 点击导航栏按钮 点击云服务器ECS 点击安全组 点击管理规则 点击手动添加 设置完成 配置web服务 使用yum安装heepd服务 启动httpd服务 查看信息 部署java通过Maven打包好的war包项目 Maven打包项目 上传项目 …...
[MQTT]Mosquitto的內網連接(intranet)和使用者/密碼權限設置
[MQTT | Raspberry Pi]Publish and Subscribe with RSSI Data of Esp32 on Intranet 延續[MQTT]Mosquitto的簡介、安裝與連接測試文章,接著將繼續測試在內網的兩台機器是否也可以完成發佈和訂閱作業。 同一網段的兩台電腦測試: 假設兩台電腦的配置如下: A電腦為發…...

高效大语言模型优化全攻略:从量化、LoRA到推理引擎实战
1. 项目概述:为什么我们需要关注高效大语言模型?最近在GitHub上看到一个叫“Awesome-Efficient-LLM”的项目,点进去一看,好家伙,简直是个宝藏。这个项目本质上是一个精心整理的资源列表,专门收集那些致力于…...

基于Gemini API构建多模态视觉应用:从原理到部署实践
1. 项目概述与核心价值最近在AI多模态领域,一个名为“gemini-vision-pro”的项目在开发者社区里引起了不小的讨论。这个项目本质上是一个基于Google Gemini API的视觉识别与图像理解应用,但它并非简单的API调用封装,而是提供了一个开箱即用、…...

Rust构建的跨平台数据备份工具relic:安全高效的快照管理与自动化策略
1. 项目概述:一个面向未来的跨平台数据备份与同步工具最近在整理个人工作流时,我一直在寻找一个能让我在不同设备、不同操作系统之间无缝同步项目配置、文档和代码片段的工具。市面上的云盘虽然方便,但总感觉不够“程序员友好”——要么同步粒…...
Transformer加速iLQR:机器人实时轨迹优化新方法
1. 项目概述 在机器人控制和自动驾驶领域,实时轨迹优化一直是个关键挑战。传统迭代线性二次调节器(iLQR)算法虽然能有效处理非线性系统,但其固有的串行计算特性严重制约了实时性能。想象一下,当四旋翼无人机需要快速避障时,或者当…...

DevUI布局系统完全指南:响应式设计的终极解决方案
DevUI布局系统完全指南:响应式设计的终极解决方案 【免费下载链接】ng-devui Angular UI Component Library based on DevUI Design 项目地址: https://gitcode.com/DevCloudFE/ng-devui DevUI布局系统是Angular UI组件库中的核心功能,为开发者提…...

开源技能库OpenClaw-Skill:构建标准化自动化技能模块的实践指南
1. 项目概述:从“OpenClaw-Skill”看开源技能库的构建与集成最近在社区里看到brabaflow/openclaw-skill这个项目,第一眼就被它的名字吸引了。“OpenClaw”听起来像是一个开源版的“机械爪”,而“Skill”则指向了技能或能力。这让我立刻联想到…...

AMEsim 3D动画制作避坑指南:从父子关系到相机视角,新手最易踩的5个雷
AMEsim 3D动画制作避坑指南:从父子关系到相机视角的进阶实战 当你第一次在AMEsim中成功让圆柱体上下移动时,那种成就感就像孩子搭起了第一块积木。但当你试图制作机械臂抓取物体或车辆底盘与悬挂联动的复杂动画时,突然发现部件像醉酒的水手一…...

Beyond Compare 5本地化激活终极指南:三步实现专业文件对比工具永久使用
Beyond Compare 5本地化激活终极指南:三步实现专业文件对比工具永久使用 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare作为专业的文件对比与合并工具,其…...

Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线
Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task 在当今的机器学习开发中&#x…...

【初阶数据结构】 左右逢源的分支诗律 二叉树1
📖 点击展开/收起 文章目录 文章目录树的概念***树的基础概念***森林树和森林的存储二叉树二叉树的性质二叉树的遍历二叉树的前序遍历二叉树的中序遍历二叉树的后序遍历希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力!树的概念 在讲解…...