多线程学习D10 收尾了应该
线程安全集合类概述

重点介绍java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent
Blocking 大部分实现基于锁,并提供用来阻塞的方法
CopyOnWrite 之类容器修改开销相对较重
Concurrent 类型的容器
内部很多操作使用 cas 优化,一般可以提供较高吞吐量
弱一致性
遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行 遍历,这时内容是旧的
求大小弱一致性,size 操作未必是 100% 准确
读取弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出
ConcurrentModificationException,不再继续遍历
ConcurrentHashMap原理
1. JDK 7 HashMap 并发死链
这得用jdk7才有效果,我没有jdk7,就体会一下把
public static void main(String[] args) {
// 测试 java 7 中哪些数字的 hash 结果相等System.out.println("长度为16时,桶下标为1的key");for (int i = 0; i < 64; i++) {if (hash(i) % 16 == 1) {System.out.println(i);}}System.out.println("长度为32时,桶下标为1的key");for (int i = 0; i < 64; i++) {if (hash(i) % 32 == 1) {System.out.println(i);}}
// 1, 35, 16, 50 当大小为16时,它们在一个桶内final HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
// 放 12 个元素map.put(2, null);map.put(3, null);map.put(4, null);map.put(5, null);map.put(6, null);map.put(7, null);map.put(8, null);map.put(9, null);map.put(10, null);map.put(16, null);map.put(35, null);map.put(1, null);System.out.println("扩容前大小[main]:"+map.size());new Thread() {@Overridepublic void run() {
// 放第 13 个元素, 发生扩容map.put(50, null);System.out.println("扩容后大小[Thread-0]:"+map.size());}}.start();new Thread() {@Overridepublic void run() {
// 放第 13 个元素, 发生扩容map.put(50, null);System.out.println("扩容后大小[Thread-1]:"+map.size());}}.start();}final static int hash(Object k) {int h = 0;if (0 != h && k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}原始链表,格式:[下标] (key,next)
[1] (1,35)->(35,16)->(16,null)
线程 a 执行到 1 处 ,此时局部变量 e 为 (1,35),而局部变量 next 为 (35,16) 线程 a 挂起
线程 b 开始执行
第一次循环
[1] (1,null)
第二次循环
[1] (35,1)->(1,null)
第三次循环
[1] (35,1)->(1,null)
[17] (16,null)
切换回线程 a,此时局部变量 e 和 next 被恢复,引用没变但内容变了:e 的内容被改为 (1,null),而 next 的内
容被改为 (35,1) 并链向 (1,null)
第一次循环
[1] (1,null)
第二次循环,注意这时 e 是 (35,1) 并链向 (1,null) 所以 next 又是 (1,null)
[1] (35,1)->(1,null)
第三次循环,e 是 (1,null),而 next 是 null,但 e 被放入链表头,这样 e.next 变成了 35 (2 处)
[1] (1,35)->(35,1)->(1,35)
已经是死链了
北究其原因,是因为在多线程环境下使用了非线程安全的 map 集合
JDK 8 虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
2. JDK 8 ConcurrentHashMap
重要属性和内部类
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的 新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
static final class ForwardingNode<K,V> extends Node<K,V> {}
// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// 作为 treebin 的头节点, 存储 root 和 first
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}重要方法
// 获取 Node[] 中第 i 个 Node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v)
// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
北构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ...
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}get 流程(全程没有加锁)
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// spread 方法能确保返回结果是正数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果头结点已经是要查找的 key
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash 为负数表示该 bin 在扩容中或是 treebin, 这时调用 find 方法来查找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 正常遍历链表, 用 equals 比较
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}put 流程(真是令人头秃)
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 其中 spread 方法会综合高位低位, 具有更好的 hash 性
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f 是链表头节点
// fh 是链表头结点的 hash
// i 是链表在 table 中的下标
Node<K,V> f; int n, i, fh;
// 要创建 table
if (tab == null || (n = tab.length) == 0)
// 初始化 table 使用了 cas, 无需 synchronized 创建成功, 进入下一轮循环
tab = initTable();
// 要创建链表头节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 添加链表头使用了 cas, 无需 synchronized
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 帮忙扩容
else if ((fh = f.hash) == MOVED)
// 帮忙之后, 进入下一轮循环
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 锁住链表头节点
synchronized (f) {
// 再次确认链表头节点没有被移动
if (tabAt(tab, i) == f) {
// 链表
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同的 key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// 更新
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 已经是最后的节点了, 新增 Node, 追加至链表尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// putTreeVal 会看 key 是否已经在树中, 是, 则返回对应的 TreeNode
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
// 释放链表头节点的锁
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加 size 计数
addCount(1L, binCount);
return null;
}
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield();
// 尝试将 sizeCtl 设置为 -1(表示初始化 table)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// 获得锁, 创建 table, 这时其它线程会在 while() 循环中 yield 直至 table 创建
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
// check 是之前 binCount 的个数
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if (
// 已经有了 counterCells, 向 cell 累加
(as = counterCells) != null ||
// 还没有, 向 baseCount 累加
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)
) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (
// 还没有 counterCells
as == null || (m = as.length - 1) < 0 ||
// 还没有 cell
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// cell cas 增加计数失败
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
) {
// 创建累加单元数组和cell, 累加重试
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 获取元素个数
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable 已经创建了,帮忙扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 需要扩容,这时 newtable 未创建
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}size 计算流程
size 计算实际发生在 put,remove 改变集合元素的操作之中
没有竞争发生,向 baseCount 累加计数
有竞争发生,新建 counterCells,向其中的一个 cell 累加计数
counterCells 初始有两个 cell
如果计数竞争比较激烈,会创建新的 cell 来累加计数
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
// 将 baseCount 计数与所有 cell 计数累加
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}Java 8 数组(Node) +( 链表 Node | 红黑树 TreeNode ) 以下数组简称(table),链表简称(bin)
初始化,使用 cas 来保证并发安全,懒惰初始化 table
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 它会让 get 操作在新table 进行搜索
扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时妙的是其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容,扩容时平均只有 1/6 的节点会把复制到新 table 中
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中。最后统计数量时累加即可
LinkedBlockingQueue 原理
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
static class Node<E> {
E item;
/**
* 下列三种情况之一
* - 真正的后继节点
* - 自己, 发生在出队时
* - null, 表示是没有后继节点, 是最后了
*/
Node<E> next;
Node(E x) { item = x; }
}
}初始化链表 last = head = new Node<E>(null); Dummy 节点用来占位,item 为 null

当一个节点入队 last = last.next = node;
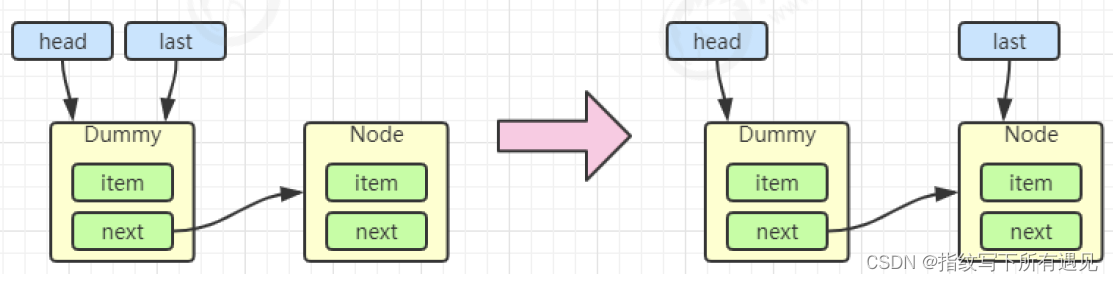 再来一个节点入队 last = last.next = node;
再来一个节点入队 last = last.next = node;
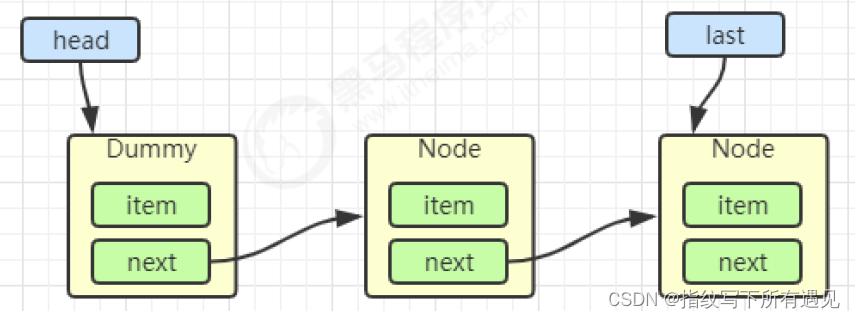
出队
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;h = head
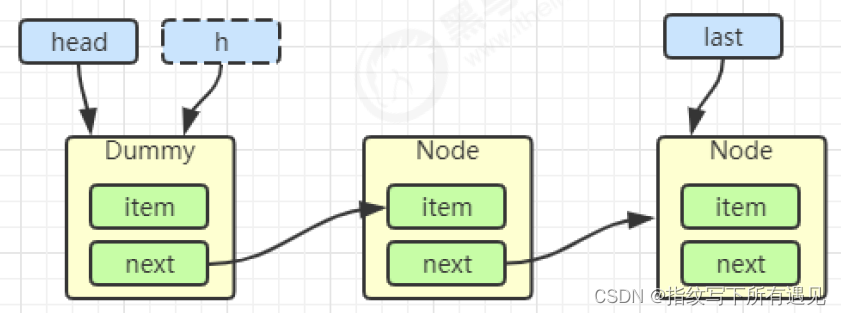
first = h.next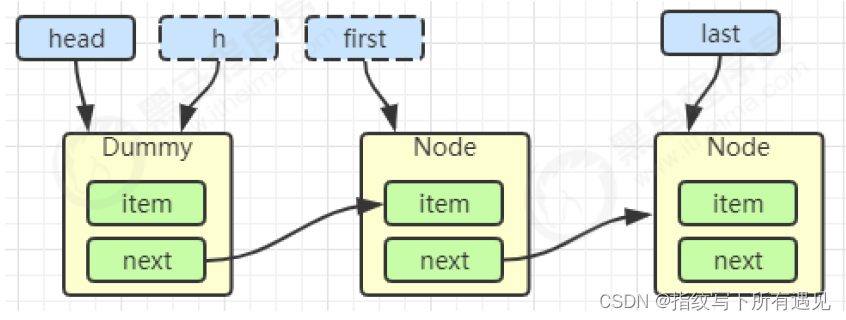
h.next = h
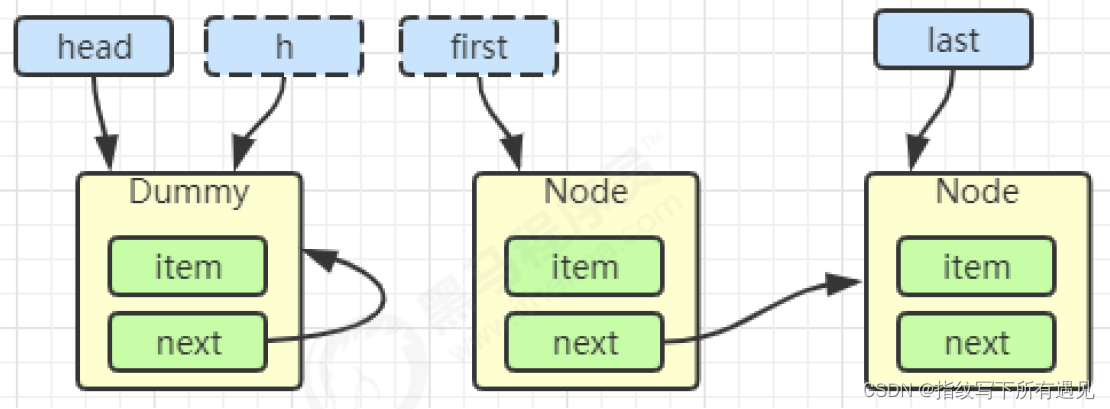
head = first
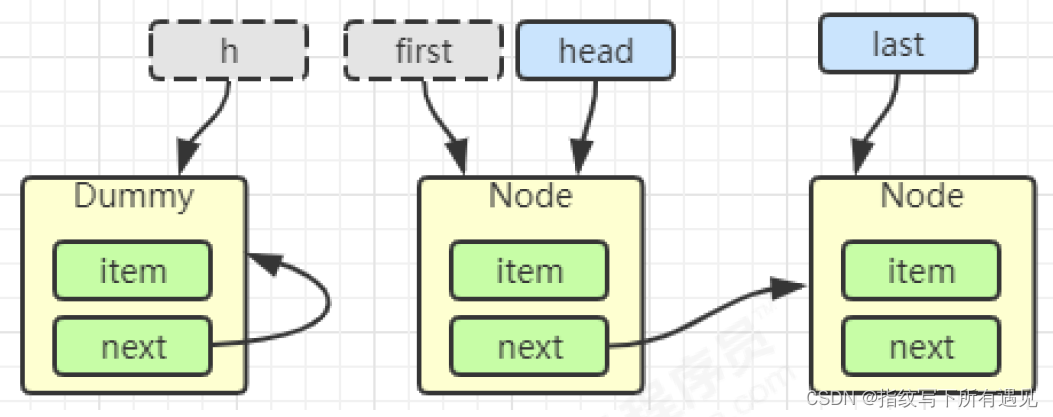
E x = first.item;
first.item = null;
return x;
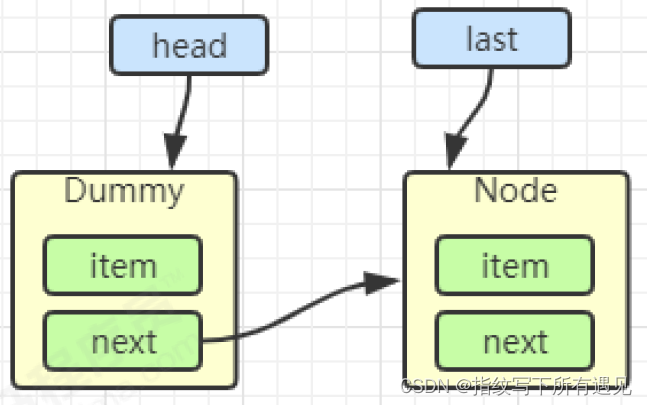
加锁分析
==高明之处==在于用了两把锁和 dummy 节点
用一把锁,同一时刻,最多只允许有一个线程(生产者或消费者,二选一)执行
用两把锁,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
消费者与消费者线程仍然串行
生产者与生产者线程仍然串行
线程安全分析
当节点总数大于 2 时(包括 dummy 节点),putLock 保证的是 last 节点的线程安全,takeLock 保证的是head 节点的线程安全。两把锁保证了入队和出队没有竞争
当节点总数等于 2 时(即一个 dummy 节点,一个正常节点)这时候,仍然是两把锁锁两个对象,不会竞争
当节点总数等于 1 时(就一个 dummy 节点)这时 take 线程会被 notEmpty 条件阻塞,有竞争,会阻塞
put 操作
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// count 用来维护元素计数
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 满了等待
while (count.get() == capacity) {
// 倒过来读就好: 等待 notFull
notFull.await();
}
// 有空位, 入队且计数加一
enqueue(node);
c = count.getAndIncrement();
// 除了自己 put 以外, 队列还有空位, 由自己叫醒其他 put 线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 如果队列中有一个元素, 叫醒 take 线程
if (c == 0)
// 这里调用的是 notEmpty.signal() 而不是 notEmpty.signalAll() 是为了减少竞争
signalNotEmpty();
}take 操作
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 如果队列中只有一个空位时, 叫醒 put 线程
// 如果有多个线程进行出队, 第一个线程满足 c == capacity, 但后续线程 c < capacity
if (c == capacity)
// 这里调用的是 notFull.signal() 而不是 notFull.signalAll() 是为了减少竞争
signalNotFull()
return x;
}LinkedBlockingQueue 与 ArrayBlockingQueue 的性能比较
Linked 支持有界,Array 强制有界
Linked 实现是链表,Array 实现是数组
Linked 是懒惰的,而 Array 需要提前初始化 Node 数组
Linked 每次入队会生成新 Node,而 Array 的 Node 是提前创建好的
Linked 两把锁,Array 一把锁
相关文章:
多线程学习D10 收尾了应该
线程安全集合类概述 重点介绍java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent Blocking 大部分实现基于锁,并提供用来阻塞的方法 CopyOnWrite 之类容器修改…...

ai可以做思维导图吗?当然是可以的!
ai可以做思维导图吗?在快节奏的现代生活中,思维导图作为一种高效的信息组织和表达工具,越来越受到人们的青睐。随着人工智能(AI)技术的不断发展,AI思维导图软件也应运而生,它们不仅能够帮助用户…...

景源畅信数字:抖音小店的入住门槛大不大?
近年来,随着短视频平台的崛起,抖音小店逐渐成为了众多商家和创业者关注的焦点。那么,抖音小店的入住门槛究竟大不大呢?本文将从四个方面对这一问题进行详细阐述。 一、注册流程 抖音小店的注册流程相对简单,只需按照官方指引完成…...
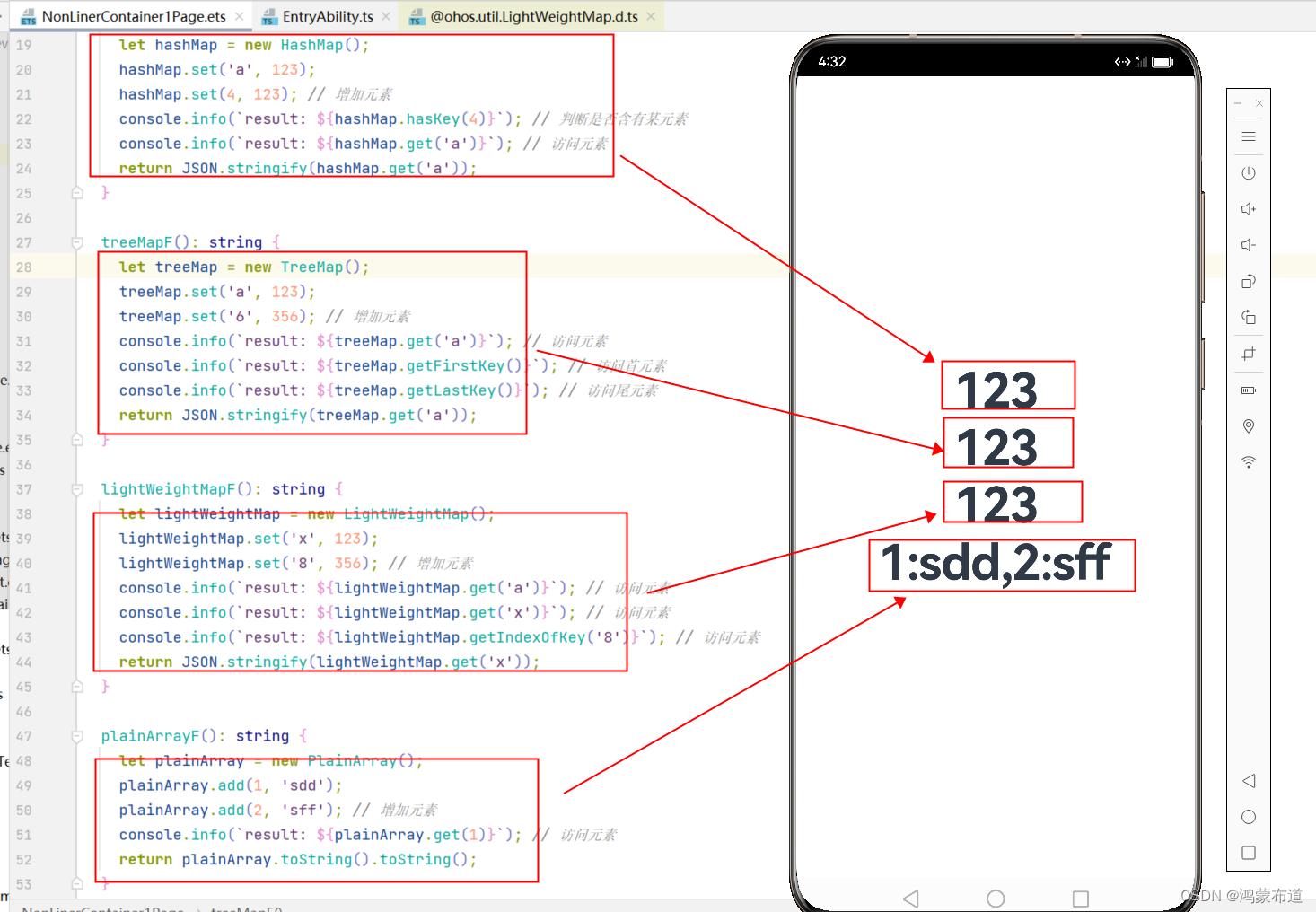
鸿蒙开发-ArkTS语言-容器-非线性容器
鸿蒙开发-UI-web 鸿蒙开发-UI-web-页面 鸿蒙开发-ArkTS语言-基础类库 鸿蒙开发-ArkTS语言-并发 鸿蒙开发-ArkTS语言-并发-案例 鸿蒙开发-ArkTS语言-容器 文章目录 前言 一、非线性容器 1.HashMap 2.HashSet 3.TreeMap 4.TreeSet 5.LightWeightMap 6.LightWeightSet 7.P…...

【C语言】指针篇- 深度解析Sizeof和Strlen:热门面试题探究(5/5)
🌈个人主页:是店小二呀 🌈C语言笔记专栏:C语言笔记 🌈C笔记专栏: C笔记 🌈喜欢的诗句:无人扶我青云志 我自踏雪至山巅 文章目录 一、简单介绍Sizeof和Strlen1.1 Sizeof1.2 Strlen函数1.3 Sie…...

【设计模式】单例模式的前世今生
文章目录 引言简介起航!向“确保某个类在系统中只有一个实例”进发 ⛵️Lazy SingletonDouble-checked locking(DCL) SingletonVolatile SingletonAtomic SingletonMeyers Singleton 附:C静态对象的初始化 引言 说起单例模式&…...

厦门网上在线教育系统,线下老师怎么转型到线上网上授课?
现在很多 线下老师都想转到线上做网课,但是在转线上过程中会出现很多问题,很多人都不知道怎么开始,今天小编和大家说一下要注意的。 一、你要有一套适合线上的教学视频 首先你要准备做的课程内容是什么,怎么讲,讲什么&…...
Spring底层入门(九)
boot的执行流程分为构造SpringApplication对象、调用run方法两部分 1、Spring Boot 执行流程-构造 通常我们会在SpringBoot的主启动类中写以下的代码: 参数一是当前类的字节码,参数二是main的args参数。 public class StartApplication {public static…...
)
掌握Android Fragment开发之魂:Fragment的深度解析(下)
在上一篇文章中,我们深入探讨了Fragment 通信,包含Fragment 向 Activity 传递数据、Activity 向 Fragment 传递数据、Fragment 之间的通信方式。感兴趣的朋友,请前往查阅: 掌握Android Fragment开发之魂:Fragment的深度…...
小巧简单实用的Linux端口转发工具Rinetd
Linux下实现端口转发有很多种方法,尤其是在可以联网的情况下,更是容易。最近在资源受限的定制系统中,找到一个方便离线安装和使用的端口转发工具Rinetd,安装包仅几十K,而且有很多版本的Linux发行系统的支持。 1、安装…...

HackBar 新手使用教程(入门)
啥是Hackbar? Hackbar是一个Firefox 的插件,它的功能类似于地址栏,但是它里面的数据不受服务器的相应触发的重定向等其它变化的影响。 有网址的载入于访问,联合查询,各种编码,数据加密功能。 这个Hackbar可以帮助你在测试SQL注入,XSS漏洞和网站的安全性,主要是帮助…...

<Linux> 权限
目录 权限人员相对于文件来说的分类更改权限文件的拥有者与所属组umask粘滞位 权限 权限是操作系统用来限制对资源访问的机制,权限一般分为读、写、执行。系统中的每个文件都拥有特定的权限、所属用户及所属组,通过这样的机制来限制哪些用户、哪些组可以…...

Nacos Docker 快速部署----解决nacos鉴权漏洞问题
Nacos Docker 快速部署 1. 说明 1.1 官方文档 官方地址 https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html docker启动文件的gitlhub地址 https://github.com/nacos-group/nacos-docker.git 问题: 缺少部分必要配置与说明 1.2 部署最新版本Nacos&…...
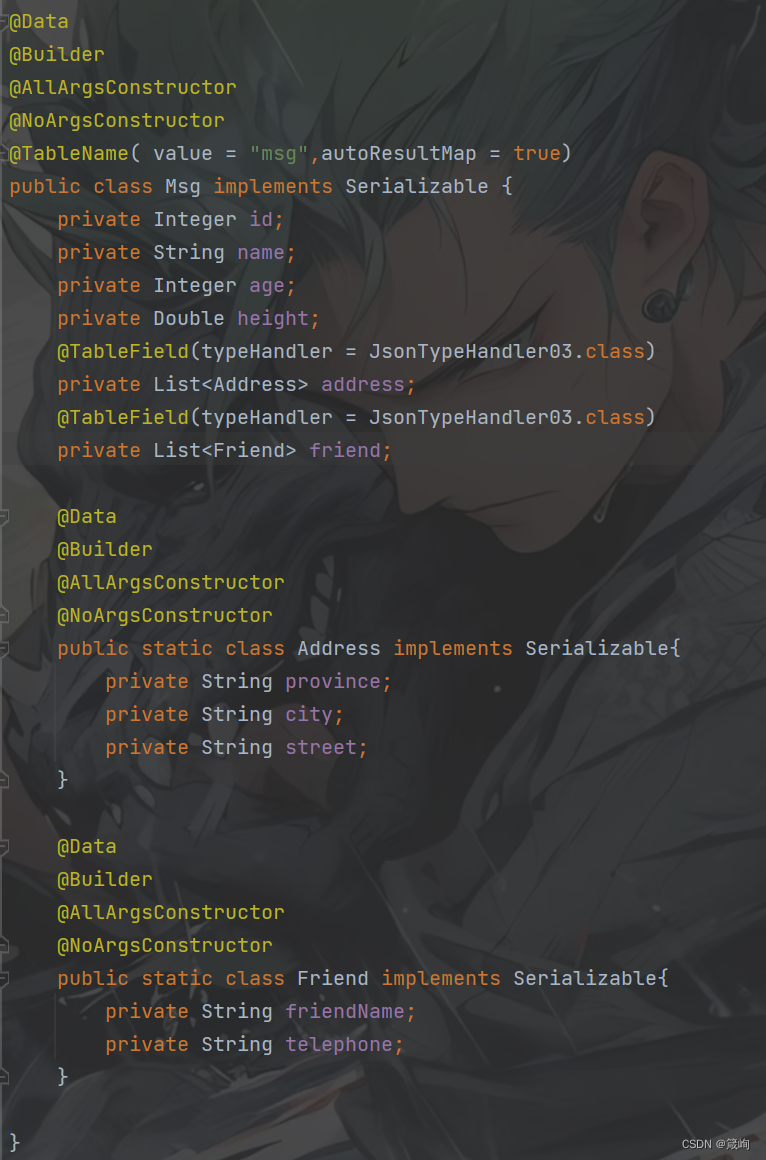
存储或读取时转换JSON数据
一、 数据库类型 二、使用Hutool工具 存储时将数据转换为JSON数据 获取时将JSON数据转换为对象 发现问题: 原本数据对象是Address 和 Firend但是转换完成后数据变成了JSONArray和JSONObject 三、自定义TypeHandler继承Mybatis的BaseTypeHandler处理器 package …...

Spring Data JPA的作用和用法
Spring Data JPA 是 Spring 框架的一个模块,它提供了一种数据访问抽象,允许以一种声明式和简洁的方式来处理数据库操作。它基于 Java Persistence API (JPA),是一个行业标准的 ORM(对象关系映射)规范,用于将…...
【go项目01_学习记录08】
学习记录 1 模板文件1.1 articlesStoreHandler() 使用模板文件1.2 统一模板 1 模板文件 重构 articlesCreateHandler() 和 articlesStoreHandler() 函数,将 HTML 抽离并放置于独立的模板文件中。 1.1 articlesStoreHandler() 使用模板文件 . . . func articlesSt…...

Java中的线程
一、创建线程的几种方式? ① 通过继承Thread类并重写run方法 ,实现简单但不可以继承其他类 Thread底层也是实现了Runnable接口,重写的是run而不是start方法 ②实现Runnable接口并重写run方法, 避免了单继承的局限性ÿ…...
(完整代码))
顺序表的实现(迈入数据结构的大门)(完整代码)
seqlist.h #pragma once typedef int SLDataType;#include<stdio.h> #include<stdlib.h> #include<assert.h>typedef struct SeqList {SLDataType* a;int size; // 有效数据个数int capacity; // 空间容量 }SL;//初始化和销毁 void SLInit(SL* ps); void SL…...

neo4j-5.11.0安装APOC插件or配置允许使用过程的权限
在已经安装好neo4j和jdk的情况下安装apoc组件,之前使用neo4j-community-4.4.30,可以找到配置apoc-4.4.0.22-all.jar,但是高版本neo4j对应没有apoc-X.X.X-all.jar。解决如下所示: 1.安装好JDK与neo4j 已经安装对应版本的JDK 17.0…...

mybatis 中 #{}和 ${}的区别是什么?
在 MyBatis 中,#{} 和 ${} 是两种用于参数替换的语法,但它们之间存在一些重要的区别,主要体现在安全性、预编译和动态 SQL 上。 安全性: #{}:这是预编译处理,MyBatis 会为传入的参数生成 PreparedStatement…...
)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点) 作为一名刚接触粒子探测器仿真的研究生,我花了整整两周时间才成功将SolidWorks设计的模型导入Geant4进行模拟。这个过程远比想象中复杂&#x…...

【技术解析】基于主成分分析与神经网络的航空安全风险建模:从QAR数据预处理到实时预警仿真
1. 航空安全风险建模的技术背景 每次坐飞机时,你可能都好奇过:机长是如何确保飞行安全的?其实背后有一整套数据驱动的安全体系在支撑。QAR(快速存取记录器)就像飞机的"黑匣子",记录了上百项飞行参…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...

Go语言构建开发者命令行工具箱:navis项目架构与实现解析
1. 项目概述:一个为开发者打造的“导航”工具箱最近在GitHub上看到一个挺有意思的项目,叫navis,作者是NaveenBuidl。光看名字,你可能会联想到“导航”或者“航行”,没错,这个项目的核心定位就是一个为开发者…...

从二维到三维:DIY LED视频立方体构建全攻略
1. 项目概述:从平面到立体的视觉革命几年前,当我第一次成功点亮一整面由32x32 RGB LED面板组成的视频墙时,那种由1024个像素点共同编织出的动态画面所带来的震撼,至今记忆犹新。但作为一个热衷于将技术推向边界的创作者࿰…...