傻白探索Chiplet,Modular Routing Design for Chiplet-based Systems(十一)
阅读了Modular Routing Design for Chiplet-based Systems这篇论文,是关于多chiplet通信的,个人感觉核心贡献在于实现了 deadlock-freedom in multi-chiplet system,而不仅仅是考虑单个intra-chiplet的局部NoC可以通信,具体的一些记录如下:
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
(2)目的
(3)结论
(4)主要实现手段
(5)实验结果
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
四、Why:为什么看这篇文献 (方便再次搜索)
五、Summary:文献方向归纳 (方便分类管理)
一、Article:文献出处(方便再次搜索)
(1)作者
- Jieming Yin, Onur Kayiran, Matthew Poremba, Muhammad Shoaib Bin Altaf, Gabriel H. Loh (Advanced Micro Devices, Inc. AMD超微半导体)
- Zhifeng Lin(南加州大学)
- Natalie Enright Jerger(多伦多大学)
(2)文献题目
- Modular Routing Design for Chiplet-based Systems
(3)文献时间
- 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture
- 计算机体系结构年度国际研讨会 ISCA
(4)引用
- J. Yin et al., "Modular Routing Design for Chiplet-Based Systems," 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 2018, pp. 726-738, doi: 10.1109/ISCA.2018.00066.
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
- 大背景:日益复杂的工艺技术导致成本的骤升,这是基于chiplet的SoC出现的动机。单个chiplet应该在不了解整个系统的情况下进行设计验证,但即使单个的chiplet都得到了验证,fully integrated system仍然存在正确性问题。
- 作者具体聚焦到互连网络,组装多个disparate chips(e.g., CPU, GPU, memory, FPGA)成为一个SoC,其correctness validation成为了一个挑战。具体来说,individual chiplets是独立设计的,有自己的NoC,无死锁且内部可以正常通信, 但将几个NoC连接在一起可能会引入新的resource cycle,从而导致跨芯片之间的循环依赖关系,很容易导致死锁。
(2)目的
- 通过引入一种简单的,模块化的,优雅的方法来确保multi-chiplet system的deadlock-free
- 以期通过independently-optimized chiplet-local NoCs来实现真正模块化和可重用的的chiplets
(3)结论
- 可在无需其它chiplets或者interposer's NoC细节的情况下独立设计,而prior-art(需要complete system-level information,比如CDG)不支持这个属性,故可以在高性能的情况下消除死锁,开发了一种composable, highly-modular, chiplet-based的方法来实现各种拓扑的routing
- 提出了一个关键抽象点:从单个chiplet的角度来看,系统的其余部分可以被抽象到单个虚拟节点中,基于此设置了boundary router 和 turn restriction的方法
(4)主要实现手段
总的来说,作者提出的chiplet-based的路由方法是composable, topologynostic, deadlock-free的,目标是:尽可能地隔离chiplets和interposer的设计,允许对chiplets和interposer进行独立的负载均衡优化,同时保持整个系统的routing是deadlock-free的。大致过程如下:
- 在每个chiplet的boundary router上设置unidirectional turn restrictions(决定了边界路由器的inbound和outbound reachability并且每个chiplet中不存在cyclic channel dependency),其余部分抽象成一个连接到boundary router的节点;
- 将这些reachability信息传播到interposer,这个interposer又负责将信息从一个边界路由器发送到另一个边界路由器;
- 通过了解边界路由器reachability,信息被发送到destination chiplet,最后local NoC会将其转发到final destination。
具体的核心实现技术如下:
-
Boundary Router Placement and Turn Restriction Algorithm

关键参数:
Number of Boundary Routers:边界路由器的数量决定了一个芯片为发送/接收intra-chiplet traffic所能维持的吞吐量;边界路由器越多,intra-chiplet traffic带宽就越高。虽然边界路由器可能的最大数量是芯片的面积函数,但最大有用带宽是其周长的函数。
Turn Restrictions at Boundary Routers:在选择prohibited turn时,我们的目标是最小化下式:Average_distance/ Average_reachability,较低的Average_distance和较高的Average_reachability的组合。
- 首先,避免将边界路由器聚类在一起,以减少创建网络热点的机会;
- 其次,边界路由器的放置应该平衡所有边界路由器的inbound和outbound reachability;
- 第三,首选采用半径较低的路由器。
-
Interposer NoC Confifiguration
- 如果一个目标只能通过一个边界路由器到达,则Interposer 必须将该消息路由到该特定的边界路由器。
- 否则,我们选择边界路由器来平衡跨边界路由器的网络负载(同样地利用芯片Interposer 带宽),同时最小化路径长度(避免仅仅为了负载平衡而以高度迂回的方式发送消息)
如何将片上节点分配给边界路由器的步骤:
- 首先,根据所有边界路由器,选择具有最少项目数量的路由器Ai (仅能通过i可达的节点集)。
- 然后,将Ci中的节点一个一个分配给Ai,直到Ai中的项目数量不再是最小的。当分配给Ai时,从Ci中删除一个项目。如果Ai仍然具有最少的项目数量,则从E{i,j}中一个一个分配节点给Ai。分配给Ai后,从Ei,j和Ej,i中删除项目。如果不能进行进一步的分配,则边界路由器i的节点分配完成。(Ci是在拓扑上离i比其它边界路由器近的节点列表,且这些节点不仅只通过1一个边界路由器可达;E{i,j}是与边界路由器i和j等距的节点列表,且这些节点至少与两个边界路由器等距)
- 重复步骤1-3,直到对于所有的边界路由器i和j,Ci = ∅和Ei,j = ∅为止。
(5)实验结果
- 实验配置
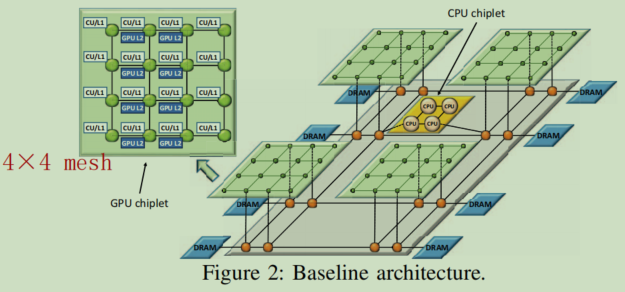
有4个GPU chiplet,每个芯片提供16个GPU SIMD计算单元(CUs),和一个中央CPU chiplet来支持GPGPU工作负载的CPU阶段。这5个chiplet被堆叠在一个active interposer上,该interposer实现了它自己的NoC来互连这些芯片和其他常见的系统功能,单个chiplet的网络是 4X4 mesh,interposer的网络也是 4X4 mesh,如下图2:
- benchmarks
- VC-based routing:需要很多VCs才能进行,且VC的分配需要提高一些全局CDG信息
- updown routing(flat network):不支持系统的模块化和可组合性,流量不均,根节点往往更拥挤
- segment-base routing(flat network)
- Nue routing(flat network):需要complete channel dependency graph (CDG)来构建生成树从而保证死锁自由
- shortest path :an idealized system,是一种理想化,不实际
- ours(composable)
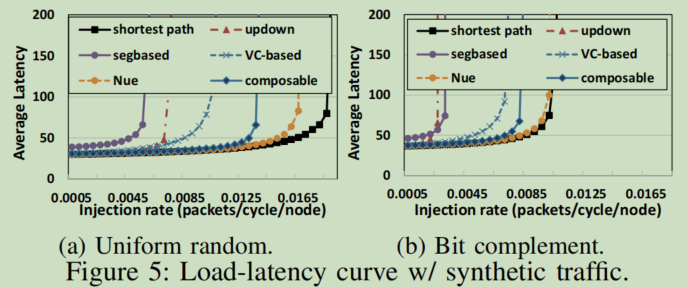
- 对比试验1:Basic Throughput Evaluations with Synthetic Traffific
- 在uniform random和bit complement下测试load-latency,结果表明:ours优于segbased/updown/VC-based,主要原因是:segbased 是基于2D mesh-like的网络,而本实验的全局拓扑仍然不规则,路由无法很好处理;updown 过早饱和,根节点比叶节点更拥挤,负载不太平衡;VC-based 需要的额外VCs减少了head-of-line blocking。而Nue优于我们,是因为它利用了完整的CDG知识来优化路由,可以更好的提供负载平衡,因而产生与shortest相似的性能;shortest虽然性能好但不切实际。总的来看,prior-art都不适用于模块化的SoC设计,ours能较为全面的进行全局负载均衡优化,无需先验complete CDG知识,也能保证在较高的正确性和性能下进行模块化设计。
-
对比试验2:Application-level Impact
-
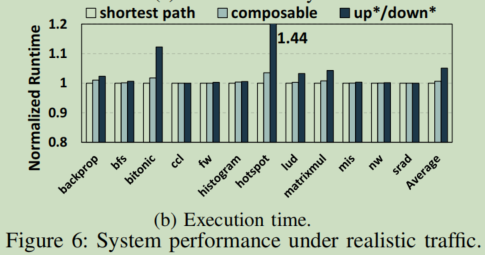
测试平均网络延迟。没有对比segbased方法,是因为它需要大量的不切实际的VCs来避免路由和协议级的死锁。如下图a,ours实现的网络延迟几乎与shortest相同,在bfs/nw/srad的情况下,ours优于shortest(考虑是由于偶尔情况下的负载/拥塞不平衡,往往出现在GPU比在CPU更频繁);updown方法是由于根节点的平均网络延迟增加超过了50%,在heavy traffic情况下成为瓶颈,从而限制了系统的有效带宽。
-
测试application performance。总体来看,对app的执行时间的影响是温和的,因为大多数的GPU app本身就对延迟不那么敏感。虽然updown方法偶尔有5-10%的波动,但ours的性能与shortest大致相同。
-
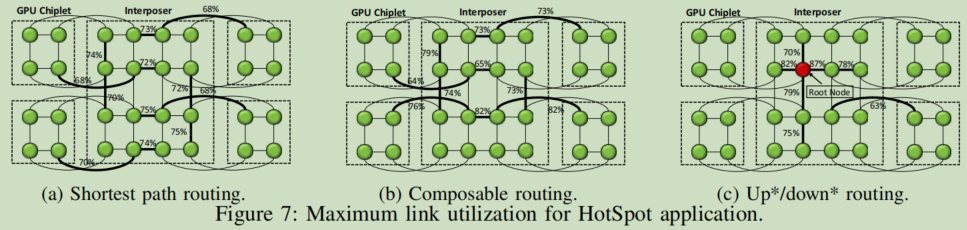
Case Study – HotSpot:在执行HotSpot时,测试利用率最高的链路的最大链路利用率。如图7,只显示GPU chiplet上的边界路由器和interposer,其余的CU 芯片利用率较低,每10000个周期,我们就对每条链路的利用率进行采样。图中标注的是最大链路利用率(整个过程中的最大采样结果),通过观察该值可以定位NoC的流量瓶颈,其中updown中的红点是根节点。
-

- 消融实验:broader applicability
- 验证实验设置guideline的有效性。
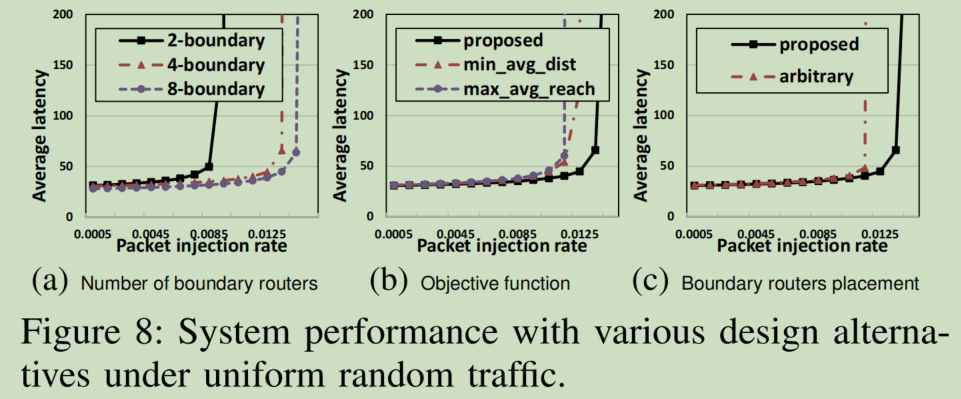
- 边界路由器数量设设置。下图8.a显示了边界路由器数量从2增加到8时,平均网络延迟的变化。可知,2->4的提升显著高于4->8的显著。虽然增加边界路由器会增加off-chiplet bandwidth,减少intra-chiplet communication,但是会增加router的复杂性面积,从而影响边界路由器的性能,提高了硬件成本,故4个边界路由器是合理设计。
- 选取turn restriction的objective function。下图8.b显示了不同objective function下的平均网络延迟,包括:最小化Average_distance和最大化 Average_reachability,但这往往会产生不平衡的on-chiplet traffic。实验能证明proposed function对turn restriction select的有效性。
- 边界路由器的位置。下图8.c考虑了一种与ours不同的placement methods—随机放置。但这会导致负载不均,使得某些链路的使用率高于其它链路,影响系统吞吐量。
- 敏感性研究:Sensitivity Studies
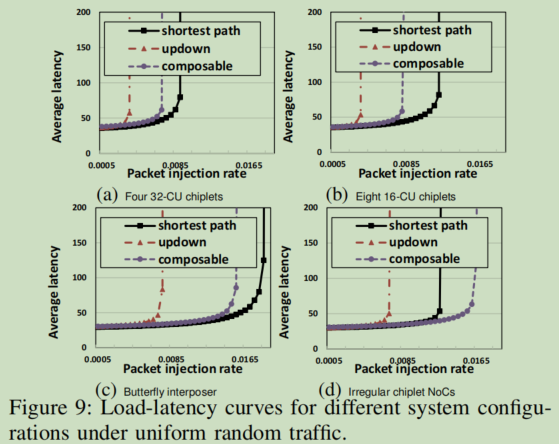
- System Size:将baseline中的64-CU替换成128-CU,使用两种方案:1) 4 chiplets with 32 CUs each;2) 8 chiplets with 16CUs each。如下图9.a和9.b,两者的区别是inter-chiplet和intra-chiplet的比率,其中ours显著优于updown,比起shortest,ours对流量分布的敏感性较低(图9中ours位置变化不明显)。
- Interposer NoC Topology:将baseline中interposer's mesh NoC替换成“Double Butterflfly” topology,如下图9.c,与baseline的性能相近,表明ours是独立于 interposer’s NoC topology的。
- Irregular Chiplet Topologies:将每个GPU chiplet替换成不同的local NoC topology,如下图9.d所示,ours甚至超过“ideal” shortest routing,推测是因为shortest倾向于靠近中心的interposer(见上图7.c的红点),ours可以更好的实现interposer traffic distribution。
- 验证实验设置guideline的有效性。
- 其它实验:Other Chiplet Packaging Options
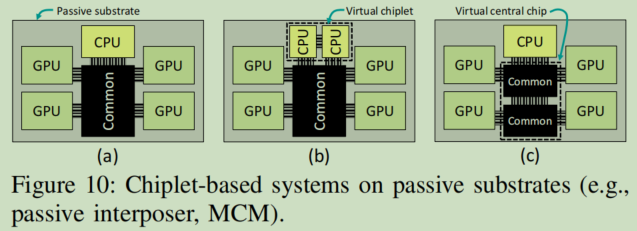
- 考虑取消“central chip”:如下图10.c,没有单个的“central chip”,而是将两个连接在一起的chip看作一个virtual chip。
- 考虑使用non-star topology in chiplets:如下图10.b,两个CPU chiplets拥有点对点链路(可以看作一个virtual chiplets),仍可以正常执行我们的算法,不会造成死锁。
- 考虑使用passive interposer:如下图10.a,the compute chiplets fan out from the central chip in a star-like topology。
-
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
第一次看互连网络的死锁路由,我没看出来啥,囫囵吞枣,和我的毕设没太大关系,先搁这儿,以后有用再回头细细琢磨。
- 虽然这篇是顶会,但是其实我觉得对读者来说并不友好,你没办法只通过introduction就明确它的贡献在哪里,必须要深入仔细的阅读,才能发现它是穿插在prior-art的结尾,作为对比来凸显contribution/difference。我还是倾向于总分总的结构,在introduction中明确问题/挑战,现有的work解决了什么问题,还存在哪些漏洞,针对这些问题如何获得motivation,进而迅速明确文章的亮点。
- 作者考虑的很全面,有非常完整的实验设计过程,但我有点疑问是,在最后一个实验(fig.10)说明方法的普适性时,缺乏数据的支撑?只是图示实验设计,并说明是可行的,就感觉说服力没那么强。当然我是个菜鸡,我不是很懂,知道的uu可以留言告诉我。
四、Why:为什么看这篇文献 (方便再次搜索)
了解课题背景:
- 师兄师姐推荐的文章,用于了解chiplet通信的一些背景
- 了解多chiplet通信的死锁问题
五、Summary:文献方向归纳 (方便分类管理)
deadlock-freedom in multi-chiplet system:
- active silicon interposer
- turn restrictions and boundary router
- highly-modular, simple, elegant, topologynostic routing
相关文章:
傻白探索Chiplet,Modular Routing Design for Chiplet-based Systems(十一)
阅读了Modular Routing Design for Chiplet-based Systems这篇论文,是关于多chiplet通信的,个人感觉核心贡献在于实现了 deadlock-freedom in multi-chiplet system,而不仅仅是考虑单个intra-chiplet的局部NoC可以通信,具体的一些…...

C语言静态库、动态库的封装和注意事项
1、动态库、静态库介绍 参考博客:《静态库和动态库介绍以及Makefile》; 2、代码目录结构和编译脚本 参考博客:《实际工作开发中C语言工程的目录结构分析》; 3、编写库的流程 (1)明确需求:需求是否合理、需求的使用场景、需求可能遇…...
MyBatis-Plus分页插件和MyBatisX插件
MyBatis-Plus分页插件和MyBatisX插件六、插件1、分页插件a>添加配置类b>测试八、代码生成器1、引入依赖2、快速生成十、MyBatisX插件1、新建spring boot工程a>引入依赖b>配置application.ymlc>连接MySQL数据库d>MybatisX逆向生成2、MyBatisX快速生成CRUD申明…...

年前无情被裁,面试大厂的这几个月…
2月份了,金三银四也即将来临,在这个招聘季,大厂也开始招人,但还是有很多人吐槽说投了很多简历,却迟迟没有回复… 另一面企业招人真的变得容易了吗?有企业HR吐槽,简历确实比以前多了好几倍&…...

基于Java的分片上传功能
起因:最近在工作中接到了一个大文件上传下载的需求,要求将文件上传到share盘中,下载的时候根据前端传的不同条件对单个或多个文件进行打包并设置目录下载。 一开始我想着就还是用老办法直接file.transferTo(newFile)就算是大文件,…...

KDS安装步骤
KDS kinetis design studio 软件 第一步官网(https://www.nxp.com/ 注册账号下载set成功下载软件。 随着AI,大数据这些技术的快速发展,与此有关的知识也普及开来。如何在众多网站中寻找最有价值的信息,如何在最短的时间内获得最新的技…...
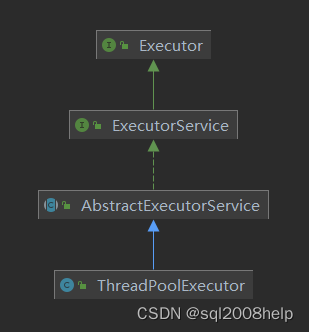
JavaSE-线程池(1)- 线程池概念
JavaSE-线程池(1)- 线程池概念 前提 使用多线程可以并发处理任务,提高程序执行效率。但同时创建和销毁线程会消耗操作系统资源,虽然java 使用线程的方式有多种,但是在实际使用过程中并不建议使用 new Thread 的方式手…...

开源代码的寿命为何只有1年?
说实话,如果古希腊的西西弗斯是一个在2016年编写开源代码的开发者,那他会有宾至如归的感觉。著名的西西弗斯处罚,是神话流传下来的,他被迫推一块巨大的石头上山,当登顶之后,只能眼睁睁看着它滚下去…...

完善登录功能--过滤器的使用
系列文章目录 Spring Boot读取配置文件内容的三种方式 Spring Boot自动配置–如何切换内置Web服务器 SpringBoot项目部署 上述为该系列部分文章,想了解更多可看我博客主页哦! 文章目录系列文章目录前言一、创建自定义过滤器LoginCheckFilter二、在启动类…...

CSS基础:属性和关系选择器
字体属性 color 文本颜色 div{ color:red;} div{ color:#ff0000;} div{ color:rgb(255,0,0);} div{ color:rgba(255,0,0,.5);}font-size 文本大小 h1 {font-size:40px;} h2 {font-size:30px;} p {font-size:14px;}注意:chrome浏览器接受最小字体是12px font-we…...
设计模式:原型模式解决对象创建成本大问题
一、问题场景 现在有一只猫tom,姓名为: tom, 年龄为:1,颜色为:白色,请编写程序创建和tom猫属性完全相同的10只猫。 二、传统解决方案 public class Cat {private String name;private int age;private String color;…...
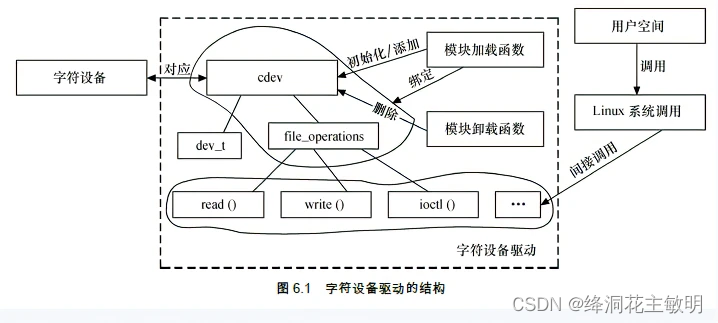
驱动开发(二)
一、驱动流程 驱动需要以下几个步骤才能完成对硬件的访问和操作: 模块加载函数 module_init注册主次设备号 <应用程序通过设备号找到设备>驱动设备文件 <应用程序访问驱动的方式> 1、手动创建 (mknod)2、程序自动创建file_oper…...

《狂飙》大结局,这22句经典台词值得细品
最近爆火的热播剧《狂飙》大家都看了吗? 剧情紧凑、演技炸裂、豆瓣评分9.0,可以说是开年评分最高的一部国产剧。 虽然大结局了。 里面有很多经典台词,值得每个人细细品味。 01 这世界不缺梦想 有本事你就去实现它 02 你这么善良 怎么跟坏…...

【计算机网络期末复习】第二章 物理层
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📣专栏定位:为想复习学校计算机网络课程的同学提供重点大纲,帮助大家渡过期末考~ 📚专栏地址: ❤️如果有收获的话,欢迎点…...
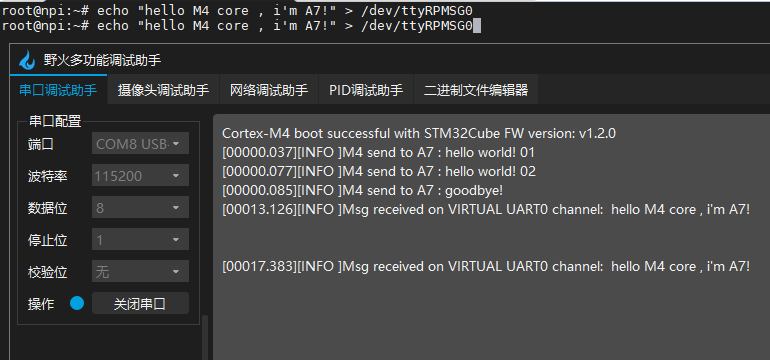
多核异构核间通信-mailbox/RPMsg 介绍及实验
1. 多核异构核间通信 由于MP157是一款多核异构的芯片,其中既包含的高性能的A7核及实时性强的M4内核,那么这两种处理器在工作时,怎么互相协调配合呢? 这就涉及到了核间通信的概念了。 IPCC (inter-processor communication contr…...

【Rust日报】2023-02-11 从头开始构建云数据库 RisingWave - 为什么我们从 C++ 转向 Rust...
GTK4发布v0.60gtk4-rs代码库包含GTK4的Rust crates。还有个庞大的GObject库生态系统,其中许多库基于gtk-rs中包含的Rust绑定工具。 特别是:gtk-rs-core,一些核心库的绑定,例如 glib、gio、pango、graphenegstreamer-rs,…...
Linux驱动开发(一)
linux驱动学习记录 一、背景 在开始学习我的linux驱动之旅之前,先提一下题外话,我是一个c语言应用层开发工作人员,在工作当中往往会和硬件直接进行数据的交互,往往遇到数据不通的情况,常常难以定位,而恰巧…...

Spring MVC 之返回数据(静态页面、非静态页面、JSON对象、请求转发与请求重定向)
文章目录1. 默认情况下返回静态页面2. 返回一个非静态页面的数据2.1 ResponseBody 返回页面内容2.2 RestController ResponseBody Controller3. 实现登录功能,返回 JSON 对象3.1 前端使⽤ ajax,后端返回 json 给前端3.2 前端发送 JSON 的标准格式4. 请…...
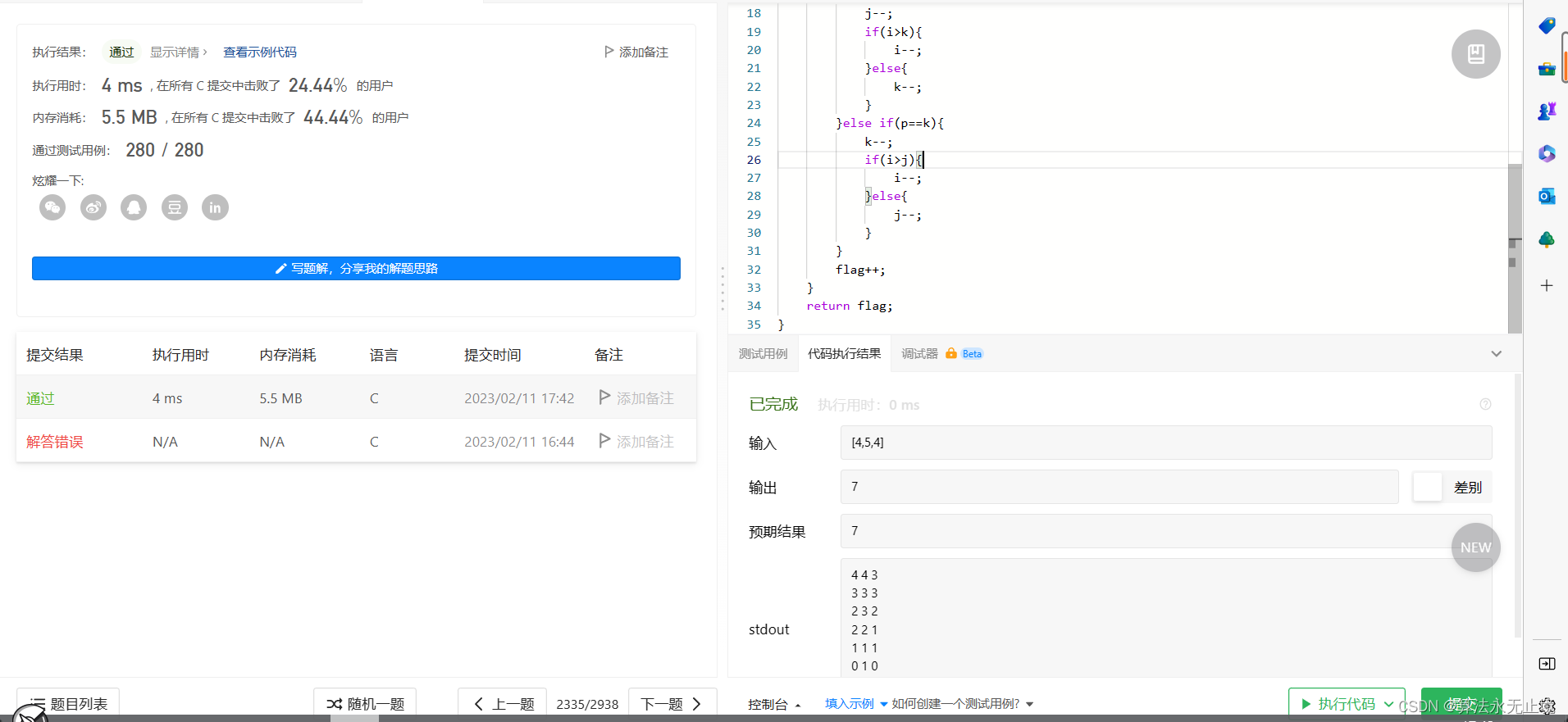
leetcode-每日一题-2335(简单,贪心)
自己打表看一下过程就可以发现,其实就是每次选两个大的进行--之后秒数加1即可现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。给你一个下标从 0 开始、长度为 3 的整数数组 amount &am…...
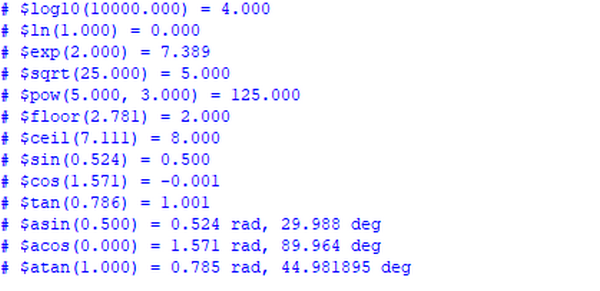
Verilog语法之数学函数
Verilog-2005支持一些简单的数学函数,其参数的数据类型只能是integer和real型。 Integer型数学函数 $clog2是一个以2为底的对数函数,其结果向上取整,返回值典型的格式: integer result; result $clog2(n); 最典型的应用就是通过…...

Animal-AI环境:用强化学习复现动物认知实验,评估AI智能水平
1. 项目概述:当AI走进“动物世界”如果你对强化学习(Reinforcement Learning, RL)和认知科学(Cognitive Science)的交叉领域感兴趣,那么Animal-AI环境绝对是一个值得你投入时间研究的宝藏项目。简单来说&am…...

基于HTML/CSS/JS+PHP的GPT API集成:从原理到部署的全栈实践
1. 项目概述:一个全栈Web开发者的效率工具箱 最近在GitHub上看到一个挺有意思的项目,叫“GPT-API-Integration-in-HTML-CSS-with-JS-PHP”。光看名字,你大概就能猜到它的核心:一个演示如何在传统的Web技术栈(HTML、CS…...

从LLM到多模态智能体:构建自主规划与协作的AI科研助手
1. 项目概述:当AI学会“思考”与“协作” 最近和几个搞科研的朋友聊天,大家不约而同地提到了一个词:AI智能体。这不再是那个只会根据指令生成文本或图片的“工具”了,而是一个能自己规划、执行、反思,甚至能和其他智能…...

Ocular开源企业AI搜索平台:基于RAG架构的私有知识库智能问答实战
1. 项目概述:当ChatGPT遇见企业搜索 如果你正在为团队寻找一个既能像Google一样快速检索内部文档,又能像ChatGPT一样智能对话、总结信息的工具,那么Ocular这个开源项目值得你花时间深入了解。简单来说,Ocular是一个“企业级的生成…...

从零构建个人知识库AI助手:RAG+智能体+LLM实战指南
1. 从零到一:构建你的“第二大脑”AI助手全景图你是否也经历过这样的场景:电脑里塞满了各种学习笔记、收藏的文章链接、项目文档和零散的想法,但当你想找某个特定信息时,却像大海捞针,只能对着混乱的文件夹和无数个浏览…...

纯Go实现Llama大模型推理引擎:llama.go架构解析与部署实践
1. 项目概述与核心价值最近在折腾大语言模型本地部署和推理时,发现了一个挺有意思的项目——gitctrlx/llama.go。简单来说,这是一个用纯Go语言实现的Llama系列大模型推理引擎。如果你和我一样,对在本地跑大模型感兴趣,但又不想被P…...

基于大语言模型的代码仓库自动化文档生成框架RepoAgent实战指南
1. 项目概述:当大模型遇上代码仓库,如何实现文档的“自动驾驶”?接手一个新项目,最头疼的是什么?对我而言,除了理解复杂的业务逻辑,就是面对一个庞大但文档稀疏、甚至过时的代码仓库。你需要在成…...

深度强化学习优化量子比特反馈控制:从DQN原理到实验部署
1. 项目概述与核心价值最近在实验室里折腾一个挺有意思的课题,就是怎么用强化学习去优化量子比特的测量和反馈控制。听起来有点跨界,对吧?量子计算和强化学习,一个在微观世界玩叠加和纠缠,一个在宏观世界搞决策和优化&…...

开源项目赞助管理平台Sponsio:自托管部署与核心架构解析
1. 项目概述:SponsioLabs/Sponsio 是什么?如果你在开源社区里泡过一段时间,肯定对“用爱发电”这个词不陌生。开发者们投入大量时间、精力,甚至金钱,维护一个项目,却常常面临一个现实问题:如何获…...

基于MCP协议的Windows AI自动化:winremote-mcp部署与实战指南
1. 项目概述:当AI助手学会“远程桌面”如果你和我一样,日常主力开发环境是Mac或Linux,但总有那么几个场景不得不和Windows打交道——可能是公司内网里那台跑着老旧ERP系统的服务器,也可能是家里那台专门用来打游戏的PC,…...