Python运维之定时任务模块APScheduler
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除

目录
定时任务模块APScheduler
一、安装及基本概念
1.1、APScheduler的安装
1.2、涉及概念
1.3、APScheduler的工作流程编辑
二、配置调度器
三、启动调度器
四、调度事件监听
定时任务模块APScheduler
APScheduler提供了基于日期、固定时间间隔以及crontab类型的任务,我们可以在主程序的运行过程中快速增加新作业或删除旧作业。如果把作业存储在数据库中,那么作业的状态会被保存,当调度器重启时,不必重新添加作业,作业会恢复原状态继续执行。
一、安装及基本概念
1.1、APScheduler的安装
pip install apscheduler
1.2、涉及概念
- 触发器(triggers):触发器包含调度逻辑,描述一个任务何时被触发,有按日期、按时间间隔、按cronjob描述式三种触发方式。每个作业都有自己的触发器,除了初始配置之外,触发器是完全无状态的。
- 作业存储器(job stores):指定了作业被存放的位置,默认的作业存储器是内存,也可以将作业保存在各种数据库中。当作业被存放在数据库中时,它会被序列化;当重新被加载时,会反序列化。作业存储器充当保存、加载、更新和查找作业的中间商。在调度器之间不能共享作业存储
- 执行器(executors):执行器是将指定的作业(调用函数)提交到线程池或进程池中运行,当任务完成时,执行器通知调度器触发相应的事件。
- 调度器(schedulers):任务调度器,控制器角色,通过它配置作业存储器、执行器和触发器、添加、修改和删除任务。调度器协调触发器、作业存储器、执行器的运行,通常只有一个调度程序运行在应用程序中,开发人员不需要直接处理作业存储器、执行器或触发器。配置作业存储器和执行器是通过调度器来完成的
1.3、APScheduler的工作流程
一个简单的间隔任务实例:
import osfrom datetime import datetimefrom apscheduler.schedulers.blocking import BlockingScheduler# 打印当前的时间def tick():print('Tick! The time is: %s' % datetime.now())if __name__ == '__main__':scheduler = BlockingScheduler()# 添加一个作业rick,触发器为interval,每隔3秒执行一次scheduler.add_job(tick, 'interval', seconds=3)print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))try:scheduler.start()except (KeyboardInterrupt, SystemExit):pass另外的触发器为date,cron。date按特定时间点触发,cron则按固定的时间间隔触发。
上述代码稍作修改可变为cron类的定时任务:
import osfrom datetime import datetimefrom apscheduler.schedulers.blocking import BlockingSchedulerdef tick():print('Tick! The time is: %s' % datetime.now())if __name__ == '__main__':scheduler = BlockingScheduler()scheduler.add_job(tick, 'cron', hour=19,minute=23)print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))try:scheduler.start()except (KeyboardInterrupt, SystemExit):pass定时cron任务也非常简单,直接给触发器trigger传入'cron'即可。hour=19,minute23,表示每天的19时23分执行任务
hour=19,minute=23hour='19',minute='23'minute='*/3' # 表示每3分钟执行一次hour='19-21',minute='23' # 表示19:23、20:23、21:23各执行一次任务二、配置调度器
调度器的主循环其实就是反复检查是否有到期需要执行的任务,具体分两步进行
- 询问自己的每一个作业存储器,有没有到期需要执行的任务。如果有则计算这些作业中每个作业需要 运行的时间点;如果时间点有多个,就做coalesce检查。
-
提交给执行器按时间点运行
各调度器的适用场景:
- BlockingSchduler:适用于调度程序,是进程中唯一运行的进程,调用start函数会阻塞当前线程,不能立即返回
- BackgroundScheduler:适用于调度程序,在应用程序的后台运行,调用start后主线程不会阻塞。
- AsyncIOScheduler:适用于使用了asyncio模块的应用程序
- GeventScheduler:适用于使用了gevent模块的应用程序
- TwistedScheduler:适用于构建Twisted的应用程序
- QtSchuduler:适用于构建Qt的应用程序。
作业存储器的选择:一是内存( 默认),而是数据库。
执行器的选择:默认的ThreadPoolExecutor足够OK,如果作业负载涉及CPU密集型操作,那么考虑使用ProcessPoolExecutor,甚至同时使用,将其作为二级执行器。
APScheduler可以使用字典,关键字参数传递配置调度器。首先实例化调度程序添加作业,然后配置调度器,获得最大的灵活性。
如果调度程序在应用程序的后台运行,则选择BackgroundScheduler,并使用默认的jobstore和executor
from apscheduler.schedulers.blocking import BlockingSchedulerscheduler = BlockingScheduler()
如果想配置更多的信息,就可设置两个执行器、两个作业存储器、调整新作业的默认值,并设置不同的时区。配置详情:
- 配置名为mongo的MongoDBjobStore作业存储器
- 配置名为default的SQLAlchemyJobStore(使用SQLite)
- 配置名为default的ThreadPoolExecutor,最大进程数为5
- UTC作为调度器的时区
- coalesce默认情况下关闭
- 作业的默认最大运行实例限制为3
方法一:
from pytz import utcfrom apscheduler.schedulers.background import BlockingSchedulerfrom apscheduler.jobstores.mongodb import MongoDBJobStorefrom apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStorefrom apscheduler.executors.pool import ThreadPoolExecutor,ProcessPoolExecutorjobstores = {'mongo':MongoDBJobStore(),'default':SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')}executors = {'default':ThreadPoolExecutor(20),'processpool':ProcessPoolExecutor(5)}job_defaults = {'coalesce':False,'max_instances':3}scheduler = BlockingScheduler(jobstores=jobstores,executors=executors,job_defaults=job_defaults,timezone=utc)方法二:
from apscheduler.schedulers.background import BlockingSchedulerscheduler = BlockingScheduler({'apscheduler.jobstores.mongo':{'type':'mongodb'},'apscheduler.jobstores.default':{'type':'sqlalchemy','url':'sqlite:///jobs.sqlite'},'apscheduler.executors.default':{'class':'apscheduler.executors.pool:ThreadPoolExecutor','max_workers':'5'},'apscheduler.job_defaults.coalesce':'fasle','apscheduler.job_defaults.max_instances':'3','apscheduler.timezone':'UTC',})方法三:
from pytz import utcfrom apscheduler.schedulers.background import BlockingSchedulerfrom apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStorefrom apscheduler.executors.pool import ThreadPoolExecutor,ProcessPoolExecutorjobstores = {'mongo':{'type':'mongodb'},'default':SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')}executors = {'default':{'type':'threadpool','max_workers':20},'processpool':ProcessPoolExecutor(max_workers=5)}job_defaults = {'coalesce':False,'max_instances':3}scheduler = BlockingScheduler()scheduler.configure(jobstores=jobstores,executors=executors,job_defaults=job_defaults,timezone=utc)三、启动调度器
启动调度器前需要先添加作业,有两种方法可以向调度器添加作业:一是通过接口add_job();二是通过使用函数装饰器,其中add_job()返回一个apscheduler.job.Job类的实例,用于后续修改或删除作业。
可以随时在调度器上调度作业。如果在添加作业时,调度器还没有启动,那么任务不会运行,并且它的第一次运行时间在调度器启动时计算。
调用调度器的start()方法启动调度器,下面用不同的作业存储器来举例:
from apscheduler.schedulers.blocking import BlockingSchedulerimport datetimefrom apscheduler.jobstores.memory import MemoryJobStorefrom apscheduler.executors.pool import ThreadPoolExecutor,ProcessPoolExecutorfdef my_job(id='my_job'):print(id,'-->',datetime.datetime.now())jobstores = {'default':MemoryJobStore()}executors = {'default':ThreadPoolExecutor(20),'processpool':ProcessPoolExecutor(10)}job_defaults = {'coalesce':False,'max_instance':3}scheduler =BlockingScheduler(jobstores=jobstores,executors=executors,job_defaults=job_defaults)scheduler.add_job(my_job,args=['job_interval',],id='job_interval',trigger='interval',seconds=5,replace_existing=True)scheduler.add_job(my_job,args=['job_cron',],id='job_cron',trigger='cron',month='4-8,5-6',hour='7-11',second='*/10',end_date='2024-06-06')scheduler.add_job(my_job,args=['job_once_now',],id='job_once_now')scheduler.add_job(my_job,args=['job_date_once',],id='job_date_once',trigger='date',run_date='2024-01-01 00:00:00')try:scheduler.start()except SystemExit:print('exit')exit()方法二:使用数据库作为作业存储器(修改第5行和11行)
from apscheduler.schedulers.blocking import BlockingSchedulerimport datetimefrom apscheduler.jobstores.memory import MemoryJobStorefrom apscheduler.executors.pool import ThreadPoolExecutor,ProcessPoolExecutorfrom apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStoredef my_job(id='my_job'):print(id,'-->',datetime.datetime.now())jobstores = {'default':SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')}executors = {'default':ThreadPoolExecutor(20),'processpool':ProcessPoolExecutor(10)}job_defaults = {'coalesce':False,'max_instance':3}scheduler =BlockingScheduler(jobstores=jobstores,executors=executors,job_defaults=job_defaults)scheduler.add_job(my_job,args=['job_interval',],id='job_interval',trigger='interval',seconds=5,replace_existing=True)scheduler.add_job(my_job,args=['job_cron',],id='job_cron',trigger='cron',month='4-8,5-6',hour='7-11',second='*/10',end_date='2024-06-06')scheduler.add_job(my_job,args=['job_once_now',],id='job_once_now')scheduler.add_job(my_job,args=['job_date_once',],id='job_date_once',trigger='date',run_date='2024-01-01 00:00:00')try:scheduler.start()except SystemExit:print('exit')exit()运行过之后,如果不注释添加作业的代码,则作业会重新添加到数据库中,这样就有了两个作业,为了避免这样的情况:设置(replace_existing=True)
scheduler.add_job(my_job,args=['job_interval',],id='job_interval',trigger='interval',seconds=5,replace_existing=True)如果想运行错过运行的作业,则使用misfire_grace_time:
scheduler.add_job(my_job,args=['job_cron',],id='job_cron',trigger='cron',month='4-8,5-6',hour='7-11',second='*/10',coalesce=True,misfire_grace_time=30,replace_existing=True,end_date='2024-06-06')其他操作如下:
scheduler.remove_job(job_id,jobstore=None) # 删除作业scheduler.remove_all_jobs(jobstore=None) # 删除所有作业scheduler.pause_job(job_id,jobstore=None) # 暂停作业scheduler.resume_job(job_id,jobstore=None) # 恢复作业scheduler.modify_job(job_id,jobstore=None,**changes) # 修改单个作业属性配置scheduler.reschedule_job(job_id,jobstore=None,trigger=None,**trigger_args) # 修改单个作业的触发器并更新下次运行时间scheduler.print_jobs(jobstore=None,out=sys.stdout) # 输出作业信息四、调度事件监听
日志记录和事件监听:
from apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.events import EVENT_JOB_EXECUTED,EVENT_JOB_ERRORimport datetimeimport logging# 配置日志记录信息 logging.basicConfig(level=logging.INFO,format='%(asctime)s %(filename)s[line:%(lineno)d %(levelname)s %(message)s',datefmt='%Y-%m-%d %H:%M:%S',filename='log1.txt',filemode='a')def aps_test(x):print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'),x)def date_test(x):print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'),x)print(1/0)def my_listener(event):if event.exception:print('任务出错了!!!!')else:print('任务照常运行...')scheduler = BlockingScheduler()scheduler.add_job(func=date_test,args=('一次性任务,会出错',),next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=15),id='date_task')scheduler.add_job(func=aps_test,args=('循环任务',),trigger='interval',seconds=3,id='interval_task')scheduler.add_listener(my_listener,EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)scheduler._logger = loggingscheduler.start()致谢
在此,我要对所有为知识共享做出贡献的个人和机构表示最深切的感谢。同时也感谢每一位花时间阅读这篇文章的读者,如果文章中有任何错误,欢迎留言批评指正。
学习永无止境,让我们共同进步
相关文章:
Python运维之定时任务模块APScheduler
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 目录 定时任务模块APScheduler 一、安装及基本概念 1.1、APScheduler的安装 1.2、涉及概念 1.3、APScheduler的工作流程编辑 二、配置调度器 …...

Linux技能
文章目录 Linux2024心得优秀博客 Linux2024 心得 会一些基本的命令,解决生产的问题有时候会用的到 优秀博客 02、Linux相关工具及操作03、Linux实用指令 cat xxx | grep “xx xx” 这个应用在从大量的日志文件中找到报错的信息 04、Linux高级部分05、JavaEE定制…...

算法有哪些分类
算法的分类可以根据不同的标准来进行,以下是一些常见的算法分类: 基本算法分类: 搜索算法:包括线性搜索、二分搜索、哈希搜索、深度优先搜索(DFS)、广度优先搜索(BFS)等。 排序算法…...

面试经典150题——找出字符串中第一个匹配项的下标
面试经典150题 day23 题目来源我的题解方法一 库函数方法二 自定义indexOf函数方法三 KMP算法 题目来源 力扣每日一题;题序:28 我的题解 方法一 库函数 直接使用indexOf函数。 时间复杂度:O(n) 空间复杂度:O(1) public int str…...
.Net MAUI 搭建Android 开发环境
一、 安装最新版本 VS 2022 安装时候选择上 .Net MAUI 跨平台开发 二、安装成功后,创建 .Net MAUI 应用 三、使用 VS 自带的 Android SDK 下载 ,Android镜像、编译工具、加速工具 四、使用Vs 自带的 Android Avd 创建虚拟机 五、使用 Android 手机真机调试...
编译适配纯鸿蒙系统的ijkplayer中的ffmpeg库
目前bilibili官方的ijkplayer播放器,是只适配Android和IOS系统的。而华为接下来即将发布纯harmony系统,是否有基于harmony系统的ijkplayer可以使用呢? 鸿蒙版ijkplayer播放器是哪个,如何使用,这个问题,大家…...

离线维护麒麟操作系统
1 本地源设置 a 首先传输一个镜像ISO文件到离线系统。 b 加载镜像文件作为源文件。 #mkdir /mnt/cdrom #mount -o path/镜像.iso /mnt/cdromc 修改源文件 # cd /etc/yum.repo.d/ # vi base.repo 修改baseurl file:///mnt/cdrom d update &install 然后就可以愉快的…...
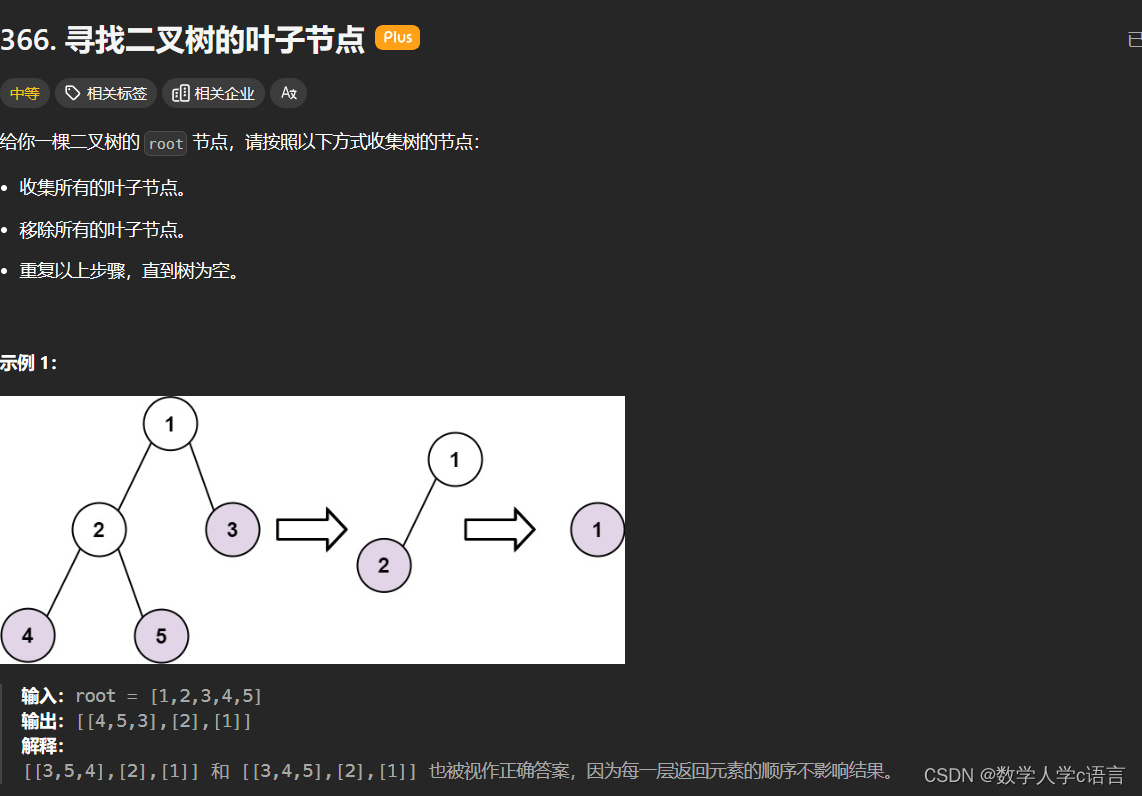
leetcode尊享面试——二叉树(python)
250.统计同值子树 使用dfs深度搜索,同值子树,要满足三个条件: 对于当前节点node,他的左子树血脉纯净(为同值子树),右子树血脉纯净(为同值子树),node的值等于…...
macbookpro 安装linux mint 无线wifi无法连接 解决方案
见欢迎页面—驱动管理...
抖音小店如此内卷,现在还值得投入吗?还能赚到钱吗?
大家好,我是电商笨笨熊 抖音小店已经经历4-5年的风霜,所以现在很多还未入驻的玩家都会有一个顾虑; 担心现在进入抖店是都还具备发展空间,还能不能赚到钱; 尤其是当一片市场逐渐加入越来越多商家的时候平台一定会内卷…...
)
Java基础知识(11)
Java基础知识(11) (包括:IO流高级流,网络爬虫基础,Commons-i0工具包和Hutool工具包) 目录 Java基础知识(11) 一.IO流高级流 1.缓冲流 【1】字节缓冲流 ࿰…...

iOS——SDWebImage源码学习
什么是SDWebImage SDWebImage是一个流行的iOS和macOS平台上的开源库,用于异步加载和缓存网络图片。它提供了一套简单易用的API,使得在应用中加载网络图片变得更加方便和高效。 主要特点和功能: 异步加载:SDWebImage通过异步方式…...

信创基础软件之中间件
信创基础软件之中间件 中间件概述 中间件是一种应用于分布式系统的基础软件,位于应用与操作系统、数据库之间,主要用于解决分布式环境下数据传输、数据访问、应用调度、系统构建和系统集成、流程管理等问题,是分布式环境下支撑应用开发、运…...
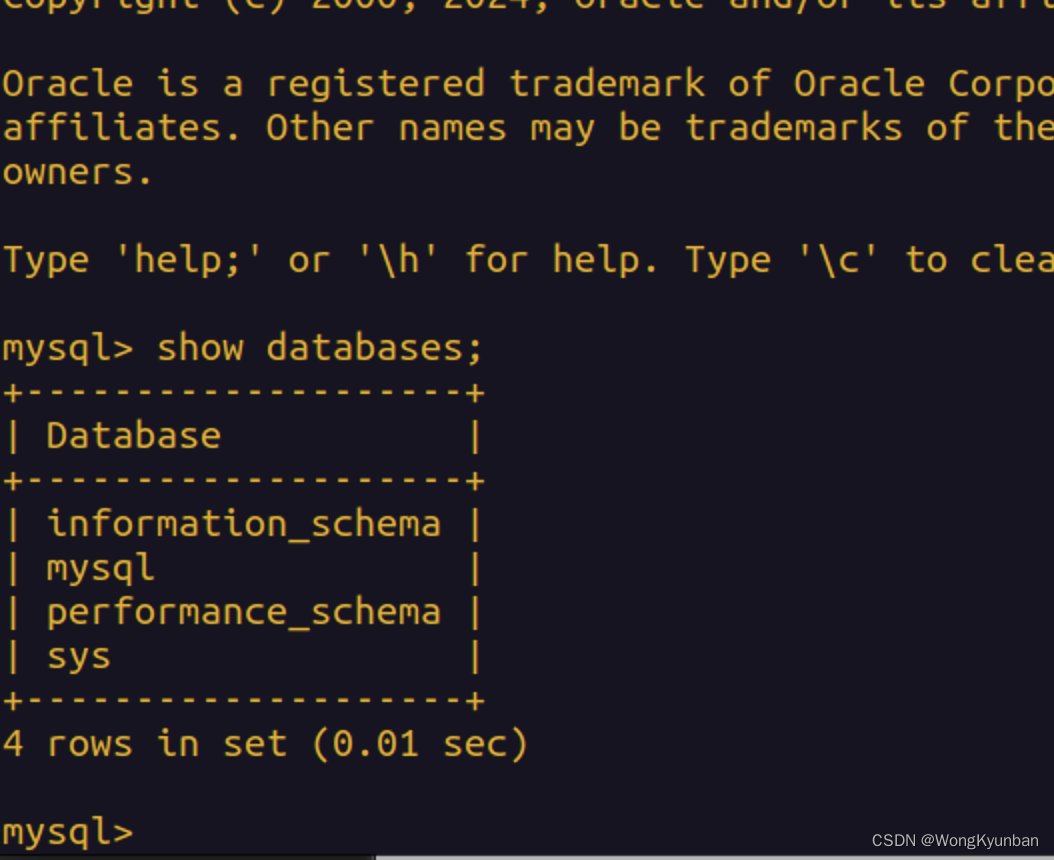
在Ubuntu linux操作系统上操作MySQL数据库常用的命令
检查是否安装了MySQL,或检查MySQL的状态: sudo systemctl status mysql或 sudo systemctl status mysql.service如果mysql有安装,上面这条命令会返回mysql的状态active或inactive。 卸载mysql数据库 第一步是停了数据库: sud…...

前端科举八股文-JAVASCRIPT篇
前端科举八股文-JAVASCRIPT篇 Js的变量类型,区别是什么平时有用过symbol吗函数闭包的理解?js的原型链? Function Function.constructor 返回值?promise的出现是为了解决什么问题?前端中的事件流事件委托?js的new操作符做了哪些…...

Docker私有仓库与Harbor部署使用
目录 一、本地私有仓库 1. 下载registry镜像 2. 在daemon.json文件中添加私有镜像仓库地址 编辑 3. 运行registry容器 4. Docker容器的重启策略如下 5. 为镜像打标签 6. 上传到私有仓库 7. 列出私有仓库的所有镜像 8. 列出私有仓库的centos镜像有哪些tag 9. 先删…...

Linux的iptables防火墙基础介绍
iptables 防火墙 应用层软件----管理 内核级netfilter 硬件-------内核----网络—netfilter/kvm----- app iptables iptables—控制netfilter 过滤:<smac/sip/dip/sport/dport/状态> TCP/IP 应用层 传输层 sport dport 状态 <三次握手/四次断开> 网…...
deepspeed+transformers模型微调
一、目录 代码讲解 二、实现。 1、代码讲解,trainer 实现。 transformers通过trainer 集成deepspeed功能,所以中需要进行文件配置,即可实现deepspeed的训练。 微调代码: 参数定义—>数据处理---->模型创建/评估方式----&…...

无人机摄影测量数据处理、三维建模及在土方量计算中的应用
专题一、无人机摄影测量技术应用现状及其发展 1、无人机摄影测量技术概述 2、摄影测量系统的发展 3、无人机摄影测量技术应用分析 专题二、基本原理和关键技术讲解 1、摄影测量基础知识 1)航空摄影 2)航摄像片的方位元素 3)共…...

《ESP8266通信指南》15-MQTT连接、订阅MQTT主题并打印消息(基于Lua|适合新手|非常简单)
往期 《ESP8266通信指南》14-连接WIFI(基于Lua)-CSDN博客 《ESP8266通信指南》13-Lua 简单入门(打印数据)-CSDN博客 《ESP8266通信指南》12-Lua 固件烧录-CSDN博客 《ESP8266通信指南》11-Lua开发环境配置-CSDN博客 《ESP826…...

Phi-4-reasoning-vision-15B企业应用:HR招聘系统简历截图信息结构化提取
Phi-4-reasoning-vision-15B企业应用:HR招聘系统简历截图信息结构化提取 1. 企业招聘场景的痛点与解决方案 在传统HR招聘流程中,简历筛选是最耗时耗力的环节之一。特别是当候选人通过邮件、社交平台或招聘网站发送简历时,HR经常面临以下挑战…...
,网盘资源速领)
10天掌握Python编程(附20节实战视频),网盘资源速领
1. 为什么选择Python作为编程入门首选? 如果你正在寻找一门适合零基础学习的编程语言,Python绝对是你的不二之选。作为一门解释型高级语言,Python以其简洁优雅的语法和强大丰富的生态圈闻名。我十年前刚开始接触编程时,就是从Pyth…...

CANopen协议实战指南:从对象字典到PDO映射
1. CANopen协议入门:从零理解工业通信基石 第一次接触CANopen协议时,我被它复杂的术语和抽象的概念搞得晕头转向。直到在某个电机控制项目中被迫深入使用后,才发现这套协议设计得如此精妙。CANopen本质上是一种建立在CAN总线上的应用层协议&a…...

macOS效率工具:Dozer极简菜单栏管理方案
macOS效率工具:Dozer极简菜单栏管理方案 【免费下载链接】Dozer Hide menu bar icons on macOS 项目地址: https://gitcode.com/gh_mirrors/do/Dozer 在现代工作环境中,macOS用户常常面临菜单栏图标过多导致的视觉混乱问题。随着各类应用程序的安…...

PROJECT MOGFACE开源社区贡献指南:从代码阅读到提交PR的全流程
PROJECT MOGFACE开源社区贡献指南:从代码阅读到提交PR的全流程 你是不是也遇到过这样的情况:在GitHub上看到一个很酷的开源项目,比如最近挺火的PROJECT MOGFACE,心里痒痒的,也想贡献点代码,但一打开那庞大…...
)
FMQL开发板实战:从Vivado到IAR的BOOT.bin生成全流程(附避坑指南)
FMQL开发板实战:从Vivado到IAR的BOOT.bin生成全流程(附避坑指南) 在嵌入式开发领域,复旦微电子FMQL系列开发板因其高性能和灵活性备受开发者青睐。然而,对于刚接触该平台的工程师来说,从零开始生成可启动的…...

Java程序员6年焦虑,转行AI后薪资暴涨40%!这8个岗位,普通人也能入局?年薪百万不是梦!
文章讲述了一位Java程序员老周因对纯业务开发感到焦虑,于去年3月开始系统学习AI相关技术,并于去年7月成功跳槽至AI创业公司,薪资涨幅达40%。文章分析了2026年AI相关岗位的招聘趋势,指出AI岗位需求旺盛,但需要程序员具备…...

别再手动发卡了!2025新版ZFAKA搭配宝塔面板,30分钟搞定你的专属自动售卡站
2025年ZFAKA自动售卡系统:零基础30分钟搭建全攻略 在数字商品交易日益火爆的今天,手动处理订单不仅效率低下,还容易出错。想象一下凌晨三点被订单提醒吵醒,手忙脚乱地复制卡密发给买家——这种场景对于个体创业者来说再熟悉不过了…...

RxDataSources编辑功能详解:如何实现TableView的增删改操作
RxDataSources编辑功能详解:如何实现TableView的增删改操作 【免费下载链接】RxDataSources UITableView and UICollectionView Data Sources for RxSwift (sections, animated updates, editing ...) 项目地址: https://gitcode.com/gh_mirrors/rx/RxDataSources…...

技术揭秘:SillyTavern角色卡片系统的架构设计与实战应用
技术揭秘:SillyTavern角色卡片系统的架构设计与实战应用 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 在AI角色扮演领域,如何将复杂的角色数据与视觉形象完美融合…...