deepspeed+transformers模型微调
一、目录
- 代码讲解
二、实现。
1、代码讲解,trainer 实现。
transformers通过trainer 集成deepspeed功能,所以中需要进行文件配置,即可实现deepspeed的训练。
微调代码: 参数定义—>数据处理---->模型创建/评估方式---->trainer 框架训练
注意: V100 显卡,不包括float16 精度训练。
import deepspeed
deepspeed.ops.op_builder.CPUAdamBuilder().load()
import nltk
import torch
import evaluate
import datasets
import numpy as np
from nltk.tokenize import sent_tokenize
from torch.nn.utils.rnn import pad_sequence
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
nltk.download("punkt")
import gc
import torch######################################定义参数####################################
dataset_name = "samsum" # 数据集名称
#model_name="google/flan-t5-xxl" # 模型名称
model_name="google/flan-t5-xl" # 模型名称
max_input_length = 256
max_gen_length = 128
output_dir = "checkpoints"
num_train_epochs = 5
learning_rate = 5e-5
deepspeed_config = "ds_config.json" # deepspeed配置文件
per_device_train_batch_size=5 # batch size设置为1,因为太大导致OOM
per_device_eval_batch_size=5
gradient_accumulation_steps=10 # 由于单卡的batch size为1,为了扩展batch size,使用梯度累加#################################加载数据集,与数据预处理#########################################
tokenizer = AutoTokenizer.from_pretrained(model_name)
dataset = datasets.load_dataset(dataset_name)
print(dataset["train"][0])def preprocess(examples):dialogues = ["summarize:" + dia for dia in examples["dialogue"]]# summaries = [summ for summ in examples["summary"]]model_inputs = tokenizer(dialogues, max_length=max_input_length, truncation=True)labels = tokenizer(text_target=examples["summary"], max_length=max_gen_length, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_dataset = dataset.map(preprocess, batched=True, remove_columns=["dialogue", "summary", "id"])
# print(tokenized_dataset["train"]["input_ids"][0]) # 打印结果 对map后的数据进行查看。def collate_fn(features):batch_input_ids = [torch.LongTensor(feature["input_ids"]) for feature in features]batch_attention_mask = [torch.LongTensor(feature["attention_mask"]) for feature in features]batch_labels = [torch.LongTensor(feature["labels"]) for feature in features]batch_input_ids = pad_sequence(batch_input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)batch_attention_mask = pad_sequence(batch_attention_mask, batch_first=True, padding_value=0)batch_labels = pad_sequence(batch_labels, batch_first=True, padding_value=-100)return {"input_ids": batch_input_ids,"attention_mask": batch_attention_mask,"labels": batch_labels}##############################加载模型,采用seq2seqLM模型,并进行测试##############################
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)#用于测试的代码
#dataloader = DataLoader(tokenized_dataset["test"], shuffle=False, batch_size=4, collate_fn=collate_fn)
# batch = next(iter(dataloader))
# #print(batch)
# # 用于测试的代码
# dataloader = DataLoader(tokenized_dataset["test"], shuffle=False, batch_size=4, collate_fn=collate_fn)
# batch = next(iter(dataloader))
# output = model(**batch)
#print(output)
#############################################模型训练,并采用trainer 架构####################################
print("==========train....================")
metric = evaluate.load("rouge")
def compute_metrics(eval_preds):preds, labels = eval_predsif isinstance(preds, tuple):preds = preds[0]decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)labels = np.where(labels != -100, labels, tokenizer.pad_token_id)decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)result = {k: round(v * 100, 4) for k, v in result.items()}prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]result["gen_len"] = np.mean(prediction_lens)return resulttraining_args = Seq2SeqTrainingArguments(output_dir=output_dir,per_device_train_batch_size=per_device_train_batch_size,per_device_eval_batch_size=per_device_eval_batch_size,gradient_accumulation_steps=gradient_accumulation_steps,eval_accumulation_steps=1, # 防止评估时导致OOMpredict_with_generate=True,learning_rate=learning_rate,num_train_epochs=num_train_epochs,# logging & evaluation strategieslogging_dir="logs",logging_strategy="steps",logging_steps=50, # 每50个step打印一次logevaluation_strategy="steps",eval_steps=500, # 每500个step进行一次评估save_steps=500,save_total_limit=2,load_best_model_at_end=True,deepspeed=deepspeed_config, # deepspeed配置文件的位置report_to="all"
)trainer = Seq2SeqTrainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["validation"],data_collator=collate_fn,compute_metrics=compute_metrics,
)
trainer.train()
gc.collect()
torch.cuda.empty_cache()
# 打印验证集上的结果
# print(trainer.evaluate(tokenized_dataset["validation"]))
# # 打印测试集上的结果
# print(trainer.evaluate(tokenized_dataset["test"]))
# 保存最优模型
trainer.save_model("best.pt")
#export NCCL_IB_DISABLE=1; export NCCL_P2P_DISABLE=1; NCCL_DEBUG=INFO deepspeed --include=localhost:0,1 test1.py
配置文件:ds_config.json
{"fp16": {"enabled": "auto"},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": false},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
启动: 单机多卡
export NCCL_IB_DISABLE=1; export NCCL_P2P_DISABLE=1; NCCL_DEBUG=INFO deepspeed --include=localhost:0,1 test1.py>output.log 2>&1 &
二、代码讲解,peft微调+trainer 实现。
import os
import torch
import random
import datasets
import numpy as np
from typing import Dict
from transformers import (AutoModelForCausalLM,AutoTokenizer,DataCollatorForSeq2Seq,TrainingArguments,Trainer
)
from peft import (LoraConfig,TaskType,get_peft_model,get_peft_model_state_dict,
)def set_random_seed(seed):if seed is not None and seed > 0:random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.random.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Trueset_random_seed(1234)# 1. 设置参数
# LoRA参数
LORA_R = 8
LORA_ALPHA = 32
LORA_DROPOUT = 0.1
# 训练参数
EPOCHS=3
LEARNING_RATE=5e-5
OUTPUT_DIR="./checkpoints"
BATCH_SIZE=4 # 2
GRADIENT_ACCUMULATION_STEPS=3
# 其他参数
MODEL_PATH = "bigscience/bloomz-7b1-mt"
DATA_PATH = "./data/belle_open_source_1M.train.json"
MAX_LENGTH = 512
PATTERN = "{}\n{}"
DS_CONFIG = "ds_zero2_config.json"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH) # 加载tokenizer
# 加载数据
dataset = datasets.load_dataset("json", data_files=DATA_PATH)
# print(dataset["train"][0])# 2. tokenize
def tokenize(text: str, add_eos_token=True):result = tokenizer(text,truncation=True,max_length=MAX_LENGTH,padding=False,return_tensors=None)# 判断是否要添加eos_tokenif (result["input_ids"][-1] != tokenizer.eos_token_idand len(result["input_ids"]) < MAX_LENGTHand add_eos_token):result["input_ids"].append(tokenizer.eos_token_id)result["attention_mask"].append(1)result["labels"] = result["input_ids"].copy()return resultdef preprocess(example: Dict, train_on_inputs: bool = False):prompt = example["input"]response = example["target"]text = PATTERN.format(prompt, response)tokenized_inp = tokenize(text)# 若train_on_inputs为False,则将label中与input相关的token替换为-100if not train_on_inputs:tokenized_prompt = tokenize(prompt,add_eos_token=False)prompt_tokens_len = len(tokenized_prompt["input_ids"])tokenized_inp["labels"] = [-100]*prompt_tokens_len + tokenized_inp["labels"][prompt_tokens_len:]return tokenized_inptrain_data = dataset["train"].shuffle().map(preprocess, remove_columns=["id", "input", "target"])
print(train_data[0])# pad_to_multiple_of=8表示padding的长度是8的倍数
collate_fn = DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True)# 2. 加载模型
evice_map = {"": int(os.environ.get("LOCAL_RANK") or 0)}
# device_map指定模型加载的GPU;troch_dtype=torch.float16表示半精度加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, torch_dtype=torch.float16, device_map=device_map)# 3. LoRA相关
lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=LORA_R, # LoRA中低秩近似的秩lora_alpha=LORA_ALPHA, # 见上文中的低秩矩阵缩放超参数lora_dropout=LORA_DROPOUT, # LoRA层的dropout
)
# 转换模型
model = get_peft_model(model, lora_config)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
).__get__(model, type(model))
# 打印模型中的可训练参数
model.print_trainable_parameters()# 4. 训练参数
args = TrainingArguments(output_dir=OUTPUT_DIR, # checkpoint的存储目录per_device_train_batch_size=BATCH_SIZE, # 单设备上的batch sizegradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS, # 梯度累加的step数warmup_steps=100,num_train_epochs=EPOCHS,learning_rate=LEARNING_RATE,fp16=True, # 使用混合精度训练logging_steps=50,evaluation_strategy="no", # 不进行评估save_strategy="steps",save_steps=2000, # 保存checkpoint的step数save_total_limit=5, # 最多保存5个checkpointdeepspeed=DS_CONFIG #deepspeed 配置
)# 5. 模型训练
trainer = Trainer(model=model,train_dataset=train_data,eval_dataset=None,args=args,data_collator=collate_fn
)
trainer.train()
model.save_pretrained("best_model")
{"train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","steps_per_print": 50,"gradient_clipping": 1.0,"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu"},"contiguous_gradients": true,"overlap_comm": true},"zero_allow_untested_optimizer": true,"fp16": {"enabled": true,"loss_scale": 0,"loss_scale_window": 1000,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "Adam","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"activation_checkpointing": {"partition_activations": true,"contiguous_memory_optimization": true},"wall_clock_breakdown": false
}
相关文章:
deepspeed+transformers模型微调
一、目录 代码讲解 二、实现。 1、代码讲解,trainer 实现。 transformers通过trainer 集成deepspeed功能,所以中需要进行文件配置,即可实现deepspeed的训练。 微调代码: 参数定义—>数据处理---->模型创建/评估方式----&…...

无人机摄影测量数据处理、三维建模及在土方量计算中的应用
专题一、无人机摄影测量技术应用现状及其发展 1、无人机摄影测量技术概述 2、摄影测量系统的发展 3、无人机摄影测量技术应用分析 专题二、基本原理和关键技术讲解 1、摄影测量基础知识 1)航空摄影 2)航摄像片的方位元素 3)共…...

《ESP8266通信指南》15-MQTT连接、订阅MQTT主题并打印消息(基于Lua|适合新手|非常简单)
往期 《ESP8266通信指南》14-连接WIFI(基于Lua)-CSDN博客 《ESP8266通信指南》13-Lua 简单入门(打印数据)-CSDN博客 《ESP8266通信指南》12-Lua 固件烧录-CSDN博客 《ESP8266通信指南》11-Lua开发环境配置-CSDN博客 《ESP826…...

LeetCode:两数之和
文章收录于LeetCode专栏 LeetCode地址 两数之和 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是数组中同一个元素在答案里不能重复出现。…...
CSDN我的创作纪念日128天||不忘初心|努力上进|勇往直前
机缘 Hello,大家好,我是景天,其实很早之前我就加入到了CSND的大军,彼时我还是个刚毕业的小白白,时常过来CSND汲取养料,就这样,慢慢的来提升自己,强大自己。工作锻炼了我,…...

MySQL数据库中的浮点类型和高精度类型有什么区别?为什么不推荐使用浮点类型?
在软件开发中,作为后端,无可避免的需要熟练使用 MySQL 数据库进行数据存储和读取。对于信息系统而言,数据库的的地位不言而喻。那作为软件开发工程师,在使用 MySQL 过程中,又有哪些需要注意的呢?我们从实际…...
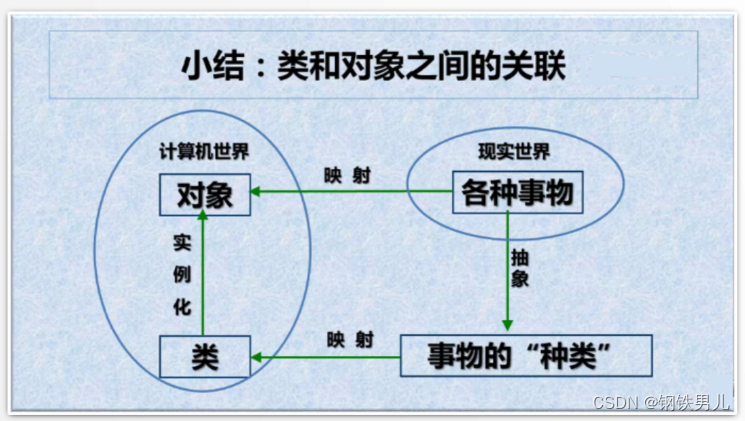
C++ 抽象与封装
一 抽象 抽象实例:时钟 数据抽象: 具有表面当前时间的时、分、秒 行为抽象: 具有设置时间和显示时间两个最基本的功能。 抽象实例:人 数据抽象:姓名、年龄、性别等。 行为抽象: 生物属性:吃…...

antV X6的简要使用教程
🧑🎓 个人主页:《爱蹦跶的大A阿》 🔥当前正在更新专栏:《VUE》 、《JavaScript保姆级教程》、《krpano》、《krpano中文文档》 ✨ 前言 在我们的日常开发工作中,我们经常需要构建复杂的交互式图…...
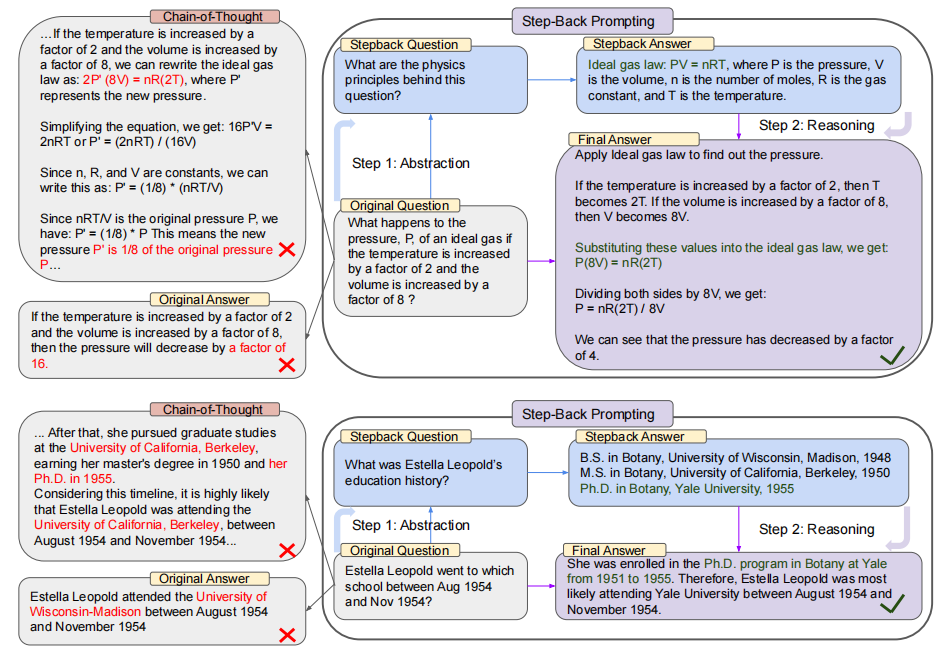
【LLM 论文】Step-Back Prompting:先解决更高层次的问题来提高 LLM 推理能力
论文:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models ⭐⭐⭐⭐ Google DeepMind, ICLR 2024, arXiv:2310.06117 论文速读 该论文受到的启发是:人类再解决一个包含很多细节的具体问题时,先站在更高的层次上解…...

Java——接口的补充
目录 一:接口的注意事项 1. 接口中不能有方法块; 2. 接口没有构造方法: 3.接口是可以多继承的; 4. 多个接口抽象方法重复 5. 类的父类方法与接口方法重复 二:类与接口 1. 继承与实现 2. 多个父接口的抽象…...

word转pdf的java实现(documents4j)
一、多余的话 java实现word转pdf可用的jar包不多,很多都是收费的。最近发现com.documents4j挺好用的,它支持在本机转换,也支持远程服务转换。但它依赖于微软的office。电脑需要安装office才能转换。鉴于没在linux中使用office,本…...

基于K8S构建Jenkins持续集成平台
文章目录 安装和配置NFSNFS简介NFS安装 在Kubernetes安装Jenkins-Master创建NFS client provisioner安装Jenkins-Master Jenkins与Kubernetes整合实现Jenkins与Kubernetes整合构建Jenkins-Slave自定义镜像 JenkinsKubernetesDocker完成微服务持续集成拉取代码,构建镜…...
PHPStudy 访问网页 403 Forbidden禁止访问
涉及靶场 upload-labd sqli-labs pikachu dvwa 以及所有部署在phpstudy中的靶场 注意:一定要安装解压软件 很多同学解压靶场代码以后访问报错的原因是:电脑上没有解压软件。 这个时候压缩包看起来就是黄色公文包的样子,右键只有“全部提取…...

热爱电子值得做的电子制作实验
加我zkhengyang,进嵌入式音频系统研究开发交流答疑群(课题组) AM/FM收音机散件制作,磁带随声听散件,黑白电视机散件制作,功放散件制作,闪光灯散件制作,声控灯散件,等等,可提高动手能…...

.class文件启动过程以及文件内容结构讲解
当你直接启动一个.class文件时,实际上是在操作系统中调用Java虚拟机(JVM),并将该.class文件传递给JVM以执行。现在让我们来解释一下.class文件的启动过程以及文件内容结构: 启动过程:操作系统通过指定的命…...
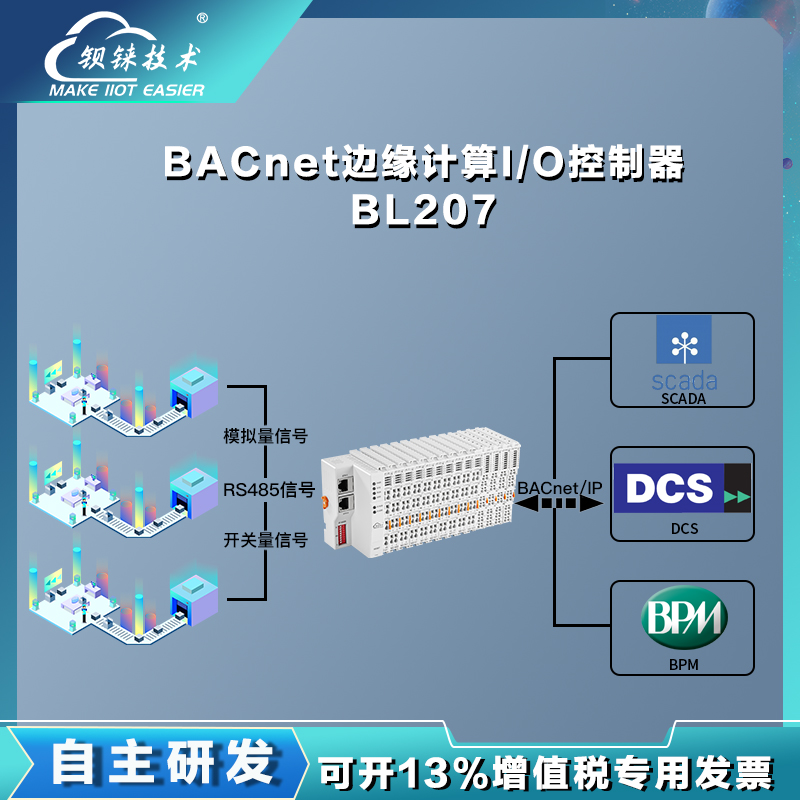
解锁楼宇自动化新维度西门子Insight+BACnet IP I/O控制器
数字城市的楼宇自动化已不再是一个遥不可及的概念,而是成为了现代建筑的标配。特别是在大型商业综合体、高端写字楼和公共设施中,高效的楼宇管理系统是确保环境舒适度与能源效率的关键。当提及楼宇自动化领域的佼佼者,西门子Insight楼宇自动化…...

2024.05.10作业
TCP服务器 头文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> #include <QTcpSocket> #include <QList> #include <QMessageBox> #include <QDebug>QT_BEGIN_NAMESPACE namespace Ui { class Widget; …...

基于POSIX标准库的读者-写者问题的简单实现
文章目录 实验要求分析保证读写、写写互斥保证多个读者同时进行读操作读者优先实例代码分析写者优先读写公平法示例代码分析实验要求 创建一个控制台进程,此进程包含n个线程。用这n个线程来表示n个读者或写者。每个线程按相应测试数据文件的要求进行读写操作。用信号量机制分别…...
重生我是嵌入式大能之串口调试UART
什么是串口 串口是一种在数据通讯中广泛使用的通讯接口,通常我们叫做UART (通用异步收发传输器Universal Asynchronous Receiver/Transmitter),其具有数据传输速度稳定、可靠性高、适用范围广等优点。在嵌入式系统中,串口常用于与外部设备进…...
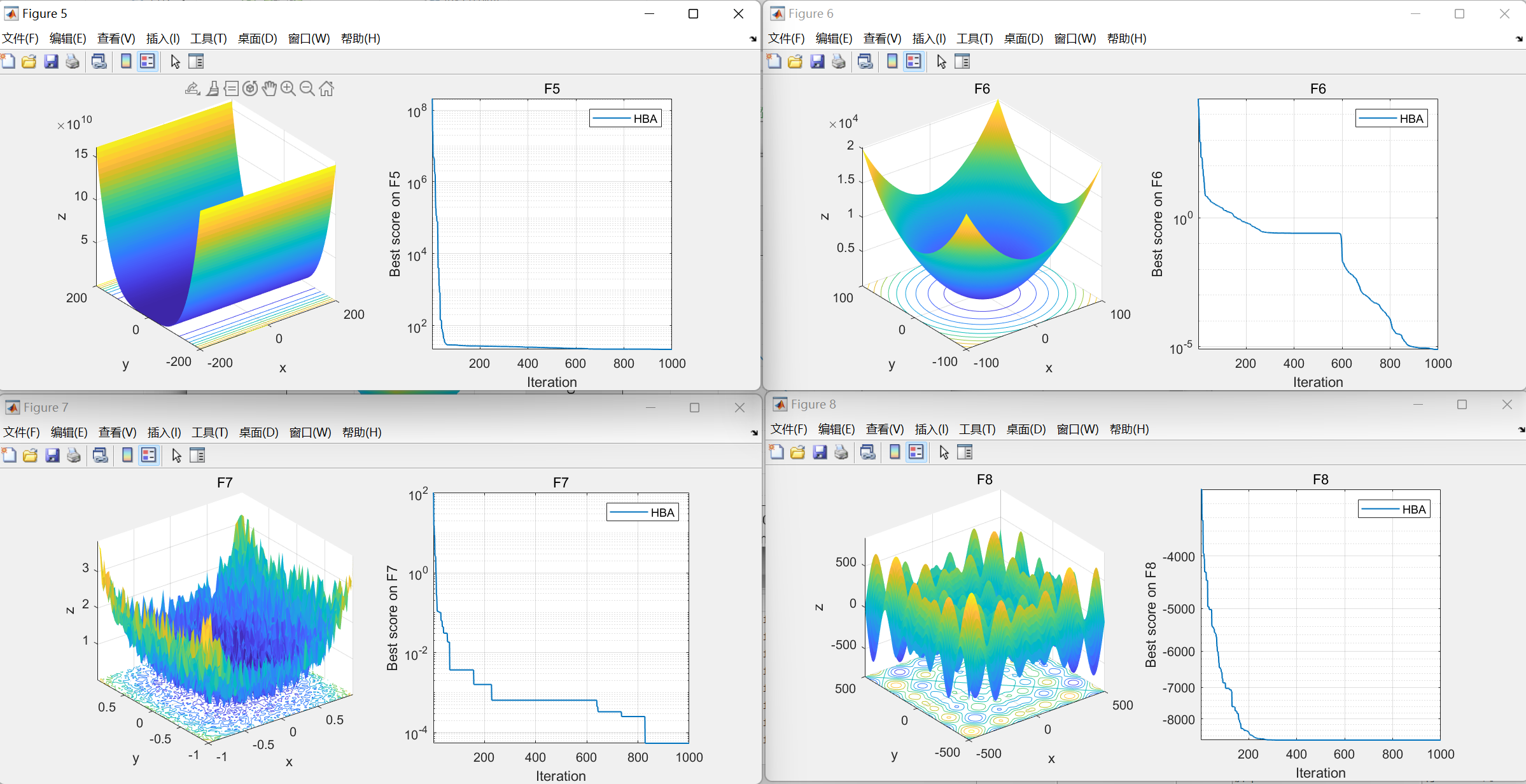
【智能优化算法】蜜獾优化算法(Honey Badger Algorithm,HBA)
蜜獾优化算法(Honey Badger Algorithm,HBA)是期刊“MATHEMATICS AND COMPUTERS IN SIMULATION”(IF 3.6)的2022年智能优化算法 01.引言 蜜獾优化算法(Honey Badger Algorithm,HBA)受蜜獾智能觅食行为的启发,从数学上发展出一种求解优化问题的…...

突破常规认知的编辑器革命:TinyEditor轻量级代码编辑器深度解析
突破常规认知的编辑器革命:TinyEditor轻量级代码编辑器深度解析 【免费下载链接】TinyEditor A functional HTML/CSS/JS editor in less than 400 bytes 项目地址: https://gitcode.com/gh_mirrors/ti/TinyEditor 当开发者在移动设备上调试代码,或…...
✅)
计算机毕业设计:Python二手车市场数据分析与价格预测系统 Django框架 随机森林 可视化 数据分析 汽车 车辆 大数据 hadoop(建议收藏)✅
1、项目介绍 技术栈 Python、Django、MySQL、机器学习随机森林算法、Echarts可视化、HTML、阿里云天池数据集 功能模块 注册登录界面不同车龄平均价格柱状图分析不同车龄数量分布饼图二手车售价分布饼图不同地区二手车平均价格柱状图分析里程价格折线图分析特征值和价格相关性分…...

探索五大革新能力:BetterGI如何全方位重塑原神自动化体验
探索五大革新能力:BetterGI如何全方位重塑原神自动化体验 【免费下载链接】better-genshin-impact 🍨BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动派遣 | 一键强化 - UI Automation Testing Tools …...

FlowScope:一款注重隐私的SQL数据血缘分析工具
最近团队接手了一个新的数据仓库项目,这个项目已经开发了很多年,包含了几百个表和几万行 ETL 存储过程代码。 目前我们经常面临的问题包括: 这个字段从哪里来?这张表被哪些存储过程用到了?修改这个字段会影响哪些 ET…...

测试报告编写核心技巧:让结果一目了然的专业模板指南
测试报告的价值重构在软件质量保障体系中,测试报告不仅是项目交付的最终凭证,更是驱动质量改进的战略工具。优秀的测试报告需实现三重价值:决策支持:为上线评审提供数据化依据问题追踪:形成缺陷治理的闭环链路效能度量…...

3分钟快速上手:免费Windows字体自定义工具No!! MeiryoUI终极指南
3分钟快速上手:免费Windows字体自定义工具No!! MeiryoUI终极指南 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 还在为Windows系统单调的…...

如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统
如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfra…...

探索时序并行门控网络TPGN:RNN的崭新继任者
一种RNN的新继任者—时序并行门控网络TPGN,用于时间序列预测。 作为RNN的新继任者。 PGN通过设计的历史信息提取(HIE)层直接从以前的时间步捕获信息,并利用门通机制选择并将其与当前时间步信息融合。 这将信息传播路径减少到0(1)&…...

从零搭建:4阶段实现wvp-GB28181-pro视频监控平台的容器化部署
从零搭建:4阶段实现wvp-GB28181-pro视频监控平台的容器化部署 【免费下载链接】wvp-GB28181-pro 项目地址: https://gitcode.com/GitHub_Trending/wv/wvp-GB28181-pro 在当今安防监控领域,GB28181协议作为国家标准被广泛应用于视频监控系统中。w…...

3步终结C盘爆红:WindowsCleaner革新性磁盘清理工具高效释放空间
3步终结C盘爆红:WindowsCleaner革新性磁盘清理工具高效释放空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 问题剖析:你是否正遭遇这些…...