CAP与BASE分布式理论
一、分布式理论
1.CAP理论
CAP理论是说对于分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容忍性(P,Partition Tolerance)中的两者。
CAP 理论又叫 Brewer 理论,这是加州大学伯克利分校的埃里克 · 布鲁尔(Eric Brewer)教授,在 2000 年 7 月“ACM 分布式计算原理研讨会(PODC)”上提出的一个猜想。
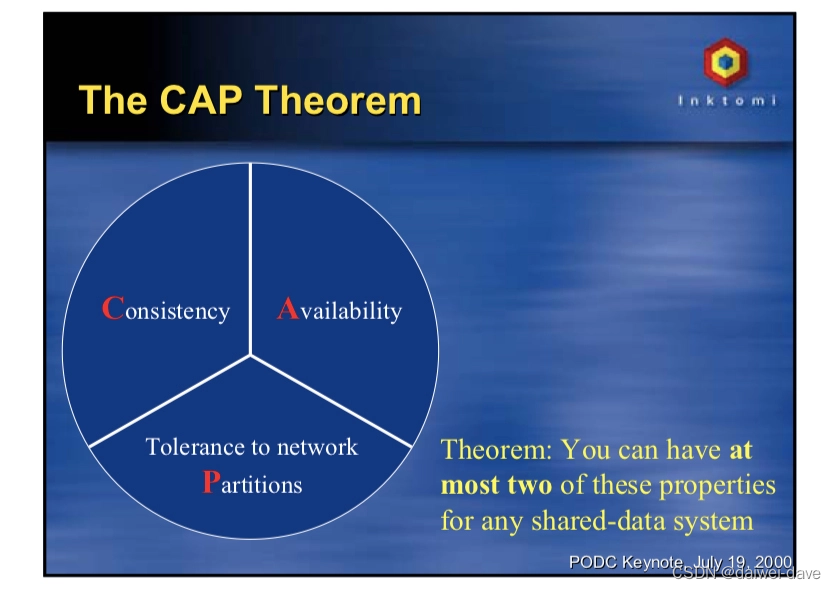
然后到了 2002 年,麻省理工学院的赛斯 · 吉尔伯特(Seth Gilbert)和南希 · 林奇(Nancy Lynch)就以严谨的数学推理证明了这个 CAP 猜想。在这之后,CAP 理论就正式成为了分布式计算领域公认的著名定理。
1.一致性
是指对于每一次读操作,都能够读到最新写入的数据,且每个节点读取到的数据是一致的。
对于客户端来说,一致性指的是并发访问更新过的数据如何获取的问题。
从服务端来看,则是更新如何复制分布到整个节点,以保证数据最终一致。
从多个应用系统来看,是保证各个业务系统冗余的数据和主数据系统的数据一致性。
1.一致性级别
1、强一致性
这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
2、弱一致性
这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
3、最终一致性
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型。
在实践中,多个系统要实现最终一致性的兜底解决办法多数是通过数据比对来实现的,如多个业务系统通过比对将生产者数据备份的大数据平台进行比对,从而实现各个业务系统的最终一致性。
2.可用性
可用性:是指对于每一次请求,都能够得到一个及时的、非错的响应。
系统能够很好的为用户服务,不出现用户访问服务时服务器不可用,或者访问超时等用户体验不好的情况。
3.分区容忍性
The system will continue to function when network partitions occur.
即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。
它跟趋向于单机模式的对比,如一台机器宕机了,其他机器一样能够提供同等的服务。但机器部署得越多,一致性和可用性就越难保证。
比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
2. CAP的选型
当然,单纯只看这个概念的话,CAP 是比较抽象的,我还是事例场景来说明一下,这三种特性对分布式系统来说都意味着什么。
事例场景:Fenix's Bookstore 是一个在线书店。一份商品成功售出,需要确保以下三件事情被正确地处理:
1.用户的账号扣减相应的商品款项;
2.商品仓库中扣减库存,将商品标识为待配送状态;
3.商家的账号增加相应的商品款项。
假设,Fenix's Bookstore 的服务拓扑如下图所示,一个来自最终用户的交易请求,将交由账号、商家和仓库服务集群中的某一个节点来完成响应:
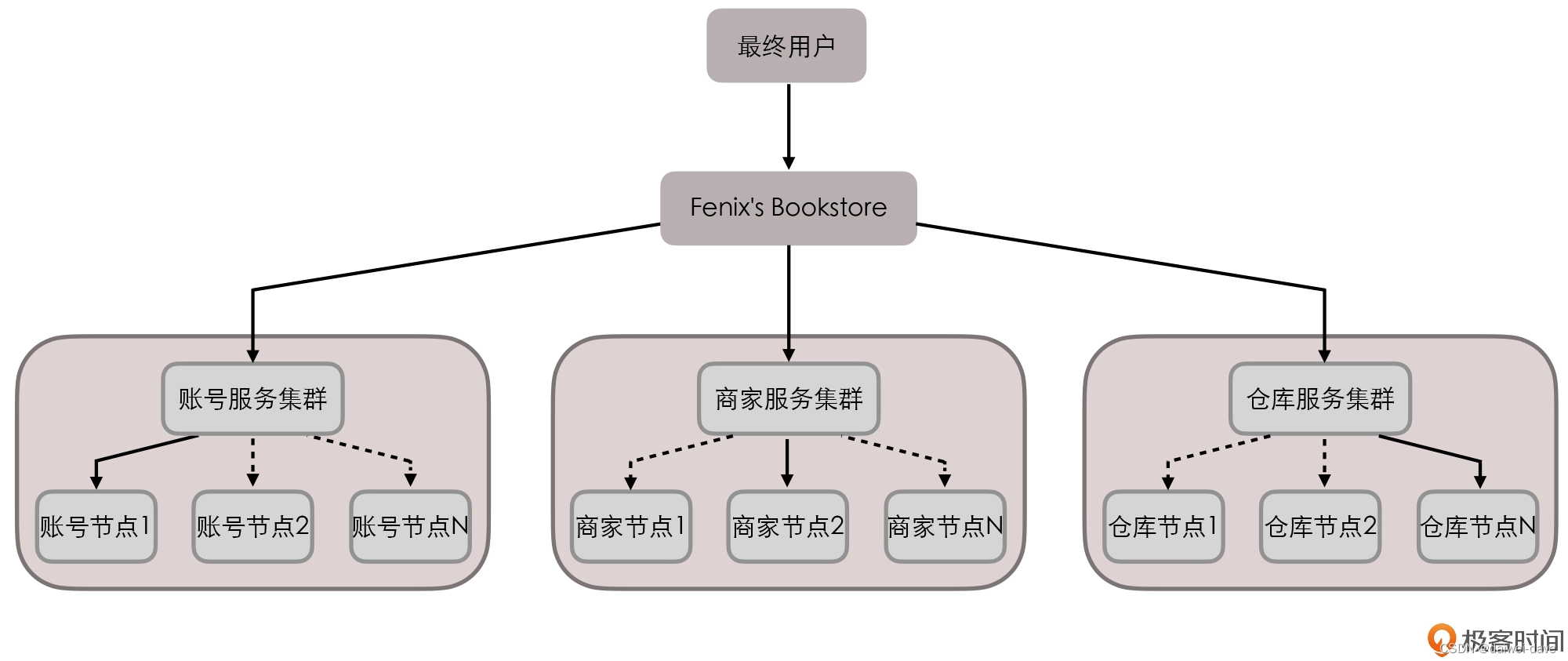
你可以看到,在这套系统中,每一个单独的服务节点都有着自己的数据库。
假设某次交易请求分别由“账号节点 1”“商家节点 2”“仓库节点 N”来进行响应,当用户购买一件价值 100 元的商品后,账号节点 1 首先应该给用户账号扣减 100 元货款。账号节点 1 在自己的数据库扣减 100 元是很容易的,但它还要把这次交易变动告知账号节点 2 到 N,以及确保能正确变更商家和仓库集群其他账号节点中的关联数据。
那么此时,我们可能会面临以下几种情况:
1.如果该变动信息没有及时同步给其他账号节点,那么当用户购买其他商品时,会被分配给另一个节点处理,因为没有及时同步,此时系统会看到用户账户上有不正确的余额,从而错误地发生了原本无法进行的交易。此为一致性问题。
2.如果因为要把该变动信息同步给其他账号节点,就必须暂停对该用户的交易服务,直到数据同步一致后再重新恢复,那么当用户在下一次购买商品时,可能会因为系统暂时无法提供服务而被拒绝交易。此为可用性问题。
3.如果由于账号服务集群中某一部分节点,因出现网络问题,无法正常与另一部分节点交换账号变动信息,那么此时的服务集群中,无论哪一部分节点对外提供的服务,都可能是不正确的,我们需要考虑能否接受由于部分节点之间的连接中断,而影响整个集群的正确性的情况。此为分区容忍性问题。
以上还只是涉及到了账号服务集群自身的 CAP 问题,而对于整个 Bookstore 站点来说,它更是面临着来自于账号、商家和仓库服务集群带来的 CAP 问题。
比如,用户账号扣款后,由于没有及时通知仓库服务,导致另一次交易中看到仓库中有不正确的库存数据而发生了超售。再比如,因为仓库中某个商品的交易正在进行当中,为了同步用户、商家和仓库此时的交易变动,而暂时锁定了该商品的交易服务,导致了可用性问题,等等。
不过既然 CAP 理论已经有了数学证明,也成为了业界公认的计算定理,我们就不去讨论为何 CAP 特性会存在不可兼得的问题了,直接来分析下在实际的应用场景中,我们要如何权衡取舍 CAP,然后看看这些不同取舍都会带来哪些问题。
如果放弃分区容错性(CA without P)
这意味着,我们将假设节点之间的通讯永远是可靠的。可是永远可靠的通讯在分布式系统中必定是不成立的,这不是你想不想的问题,而是网络分区现象始终会存在。在现实场景中,主流的 RDBMS(关系数据库管理系统)集群通常就是采用放弃分区容错性的工作模式。以 Oracle 的 RAC 集群为例,它的每一个节点都有自己的 SGA(系统全局区)、重做日志、回滚日志等,但各个节点是共享磁盘中的同一份数据文件和控制文件的,也就是说,RAC 集群是通过共享磁盘的方式来避免网络分区的出现。
如果放弃可用性(CP without A)
这意味着,我们将假设一旦发生分区,节点之间的信息同步时间可以无限制地延长,那么这个问题就相当于退化到了上一讲所讨论的全局事务的场景之中,即一个系统可以使用多个数据源。我们可以通过 2PC/3PC 等手段,同时获得分区容错性和一致性。在现实中,除了 DTP 模型的分布式数据库事务外,著名的 HBase 也是属于 CP 系统。以它的集群为例,假如某个 RegionServer 宕机了,这个 RegionServer 持有的所有键值范围都将离线,直到数据恢复过程完成为止,这个时间通常会是很长的。
如果放弃一致性(AP without C)
这意味着,我们将假设一旦发生分区,节点之间所提供的数据可能不一致。AP 系统目前是分布式系统设计的主流选择,大多数的 NoSQL 库和支持分布式的缓存都是 AP 系统。因为 P 是分布式网络的天然属性,你不想要也无法丢弃;而 A 通常是建设分布式的目的,如果可用性随着节点数量增加反而降低的话,很多分布式系统可能就没有存在的价值了(除非银行这些涉及到金钱交易的服务,宁可中断也不能出错)。以 Redis 集群为例,如果某个 Redis 节点出现网络分区,那也不妨碍每个节点仍然会以自己本地的数据对外提供服务。但这时有可能出现这种情况,即请求分配到不同节点时,返回给客户端的是不同的数据。
1.cap无法同时满足原因
CP和AP:分区容错是必须保证的,当发生网络分区的时候,如果要继续服务,那么强一致性和可用性只能 2 选 1
C A 满足的情况下,P不能满足的原因:
数据同步©需要时间,也要正常的时间内响应(A),那么机器数量就要少,所以P就不满足。
若p不能满足,就已经趋向于单机了。
CP 满足的情况下,A不能满足的原因:
数据同步©需要时间, 机器数量也多§,但是同步数据需要时间,所以不能再正常时间内响应,所以A就不满足
AP 满足的情况下,C不能满足的原因:
机器数量也多§,正常的时间内响应(A),那么数据就不能及时同步到其他节点,所以C不满足
2.CAP 关注的粒度是数据,而不是整个系统。
原文就只有一句话:
C 与 A 之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户而有所不同。
但这句话是理解和应用 CAP 理论非常关键的一点。CAP 理论的定义和解释中,用的都是 system、node 这类系统级的概念,这就给很多人造成了很大的误导,认为我们在进行架构设计时,整个系统要么选择 CP,要么选择 AP。但在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择 CP,有的数据必须选择 AP。而如果我们做设计时,从整个系统的角度去选择 CP 还是 AP,就会发现顾此失彼,无论怎么做都是有问题的。
以一个最简单的用户管理系统为例,用户管理系统包含用户账号数据(用户 ID、密码)、用户信息数据(昵称、兴趣、爱好、性别、自我介绍等)。通常情况下,用户账号数据会选择 CP,而用户信息数据会选择 AP,如果限定整个系统为 CP,则不符合用户信息数据的应用场景;如果限定整个系统为 AP,则又不符合用户账号数据的应用场景。
所以在 CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
- 正常运行情况下,不存在 CP 和 AP 的选择,可以同时满足 CA。
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
同样以用户管理系统为例,即使是实现 CA,不同的数据实现方式也可能不一样:用户账号数据可以采用“消息队列”的方式来实现 CA,因为消息队列可以比较好地控制实时性,但实现起来就复杂一些;而用户信息数据可以采用“数据库同步”的方式来实现 CA,因为数据库的方式虽然在某些场景下可能延迟较高,但使用起来简单。
- 放弃并不等于什么都不做,需要为分区恢复后做准备,即补偿机制
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么都不做。实际上,CAP 理论的“牺牲”只是说在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。例如,99.99% 可用性(俗称 4 个 9)的系统,一年运行下来,不可用的时间只有 50 分钟;99.999%(俗称 5 个 9)可用性的系统,一年运行下来,不可用的时间只有 5 分钟。分区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态。
最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到 CA 状态。
同样以用户管理系统为例,对于用户账号数据,假设我们选择了 CP,则分区发生后,节点 1 可以继续注册新用户,节点 2 无法注册新用户(这里就是不符合 A 的原因,因为节点 2 收到注册请求后会返回 error),此时节点 1 可以将新注册但未同步到节点 2 的用户记录到日志中。当分区恢复后,节点 1 读取日志中的记录,同步给节点 2,当同步完成后,节点 1 和节点 2 就达到了同时满足 CA 的状态。
而对于用户信息数据,假设我们选择了 AP,则分区发生后,节点 1 和节点 2 都可以修改用户信息,但两边可能修改不一样。例如,用户在节点 1 中将爱好改为“旅游、美食、跑步”,然后用户在节点 2 中将爱好改为“美食、游戏”,节点 1 和节点 2 都记录了未同步的爱好数据,当分区恢复后,系统按照某个规则来合并数据。例如,按照“最后修改优先规则”将用户爱好修改为“美食、游戏”,按照“字数最多优先规则”则将用户爱好修改为“旅游,美食、跑步”,也可以完全将数据冲突报告出来,由人工来选择具体应该采用哪一条。
3.分区的分布式架构

我们可以将用户 id 为 0 ~ 100 的数据存储在 Node 1,将用户 id 为 101 ~ 200 的数据存储在 Node 2,Client 根据用户 id 来决定访问哪个 Node。对于单个用户来说,读写操作都只能在某个节点上进行;对所有用户来说,有一部分用户的读写操作在 Node 1 上,有一部分用户的读写操作在 Node 2 上。
这样的设计有一个很明显的问题就是某个节点故障时,这个节点上的用户就无法进行读写操作了,但站在整体上来看,这种设计可以降低节点故障时受影响的用户的数量和范围,毕竟只影响 20% 的用户肯定要比影响所有用户要好。这也是为什么挖掘机挖断光缆后,支付宝只有一部分用户会出现业务异常,而不是所有用户业务异常的原因。
即这样设计能够保证CAP(其实更多的是CA,因为基本上是一个节点进行读写了),但是当节点发生故障时,会牺牲一定时间的无法写的操作,读操作当发现系统故障时可以路由到其他节点读取。
3. BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。
BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于CAP定理逐步演化而来的。
BASE理论的核心思想是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
接下来看一下BASE中的三要素:
1.基本可用
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用,这意味着,系统可以出现暂时不可用的状态,而后面会快速恢复。
注意:这绝不等价于系统不可用。
比如:
(1)响应时间上的损失–超时机制。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
(2)系统功能上的损失–服务降级机制:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
这里的关键词是“部分”和“核心”,具体选择哪些作为可以损失的业务,哪些是必须保证的业务,是一项有挑战的工作。
例如,对于一个用户管理系统来说,“登录”是核心功能,而“注册”可以算作非核心功能。因为未注册的用户本来就还没有使用系统的业务,注册不了最多就是流失一部分用户,而且这部分用户数量较少。如果用户已经注册但无法登录,那就意味用户无法使用系统。例如,充了钱的游戏不能玩了、云存储不能用了……这些会对用户造成较大损失,而且登录用户数量远远大于新注册用户,影响范围更大。
2.软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,且允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
即数据同步允许一定的延迟,此时可能存在不同节点的数据暂时不一致情况。
它是我们前面的“有状态”和“无状态”的服务的一种中间状态。也就是说,为了提高性能,我们可以让服务暂时保存一些状态或数据,这些状态和数据不是强一致性的。
3.最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态而不要求实时。
因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
这里的关键词是“一定时间” 和 “最终”,“一定时间”和数据的特性是强关联的,不同的数据能够容忍的不一致时间是不同的。
举一个微博系统的例子,用户账号数据最好能在 1 分钟内就达到一致状态,因为用户在 A 节点注册或者登录后,1 分钟内不太可能立刻切换到另外一个节点,但 10 分钟后可能就重新登录到另外一个节点了;而用户发布的最新微博,可以容忍 30 分钟内达到一致状态,因为对于用户来说,看不到某个明星发布的最新微博,用户是无感知的,会认为明星没有发布微博。“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
4.BASE理论和ACID的应用场景分析
举个例子,网上卖书的场景。
ACID 的玩法就是,大家在买同一本书的过程中,每个用户的购买请求都需要把库存锁住,等减完库存后,把锁释放出来,后续的人才能进行购买。于是,在 ACID 的玩法下,我们在同一时间不可能有多个用户下单,我们的订单流程需要有排队的情况,这样一来,我们就不可能做出性能比较高的系统来。
BASE 的玩法是,大家都可以同时下单,这个时候不需要去真正地分配库存,然后系统异步地处理订单,而且是批量的处理。因为下单的时候没有真正去扣减库存,所以,有可能会有超卖的情况。而后台的系统会异步地处理订单时,发现库存没有了,于是才会告诉用户你没有购买成功。
BASE 这种玩法,其实就是亚马逊的玩法,因为要根据用户的地址去不同的仓库查看库存,这个操作非常耗时,所以,不想做成异步的都不行。
在亚马逊上买东西,你会收到一封邮件说,系统收到你的订单了,然后过一会儿你会收到你的订单被确认的邮件,这时候才是真正地分配了库存。所以,有某些时候,你会遇到你先收到了下单的邮件,过一会又收到了没有库存的致歉的邮件。
有趣的是,ACID 的意思是酸,而 BASE 却是碱的意思,因此这是一个对立的东西。其实,从本质上来讲,酸(ACID)强调的是一致性(CAP 中的 C),而碱(BASE)强调的是可用性(CAP 中的 A)。
相关文章:
CAP与BASE分布式理论
一、分布式理论 1.CAP理论 CAP理论是说对于分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容忍性(P,Partition Tolerance&…...

JavaScript性能优化策略
JavaScript性能优化策略可以分为以下几个方面: 减少内存使用:避免创建不必要的对象和数组,使用对象池或数组缓存来重复利用已有的对象和数组。此外,及时释放不再需要的对象和数组,避免内存泄漏。 减少重绘和回流&…...

curl访问流式非流式大模型openai api接口
参考:https://platform.openai.com/docs/api-reference/making-requests 命令行访问: 直接是vllm的openai api接口 curl http://192.168.***:10860/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: EMPTY" -d {"mod…...

Go 使用 MongoDB
MongoDB 安装(Docker)安装 MongoDB Go 驱动使用 Go Driver 连接到 MongoDB在 Go 里面使用 BSON 对象CRUD 操作 插入文档更新文档查询文档删除文档 下一步 MongoDB 安装(Docker) 先装个 mongo,为了省事就用 docker 了。 docker 的 daemon.json 加一个国内的源地址…...

什么是g++-arm-linux-gnueabihf
2024年5月3日,周五晚上 g-arm-linux-gnueabihf 是针对 ARM 架构(ARMv7 和 ARMv8)的 Linux 系统开发的 GNU C 编译器套件,可以在 x86 或 x86_64 架构的主机上使用,用于交叉编译 ARM Linux 应用程序和库。 与 gcc-arm-l…...

Unity延时触发的几种常规方法
目录 1、使用协程Coroutine2、使用Invoke、InvokeRepeating函数3、使用Time.time4、使用Time.deltaTime5、使用DOTween。6、使用Vision Timer。 1、使用协程Coroutine public class Test : MonoBehaviour {// Start is called before the first frame updatevoid Start(){ …...
CSS文字描边,文字间隔,div自定义形状切割
clip-path: polygon( 0 0, 68% 0, 100% 32%, 100% 100%, 0 100% );//这里切割出来是少一角的正方形 letter-spacing: 1vw; //文字间隔 -webkit-text-stroke: 1px #fff; //文字描边1px uniapp微信小程序顶部导航栏设置透明,下拉改变透明度 onP…...

XWiki 服务没有正确部署在tomcat中,如何尝试手动重新部署?
1. 停止 Tomcat 服务 首先,您需要停止正在运行的 Tomcat 服务器,以确保在操作文件时不会发生冲突或数据损坏: sudo systemctl stop tomcat2. 清空 webapps 下的 xwiki 目录和 work 目录中相关的缓存 删除 webapps 下的 xwiki 目录和 work …...

【退役之重学Java】关于 Redis
一、Redis 都有哪些数据类型 String 最基本的类型,普通的set和get,做简单的kv缓存hash 这是一个类似map 的一种结构,这个一般可以将结构化的数据,比如一个对象(前提是这个对象没有嵌套其他的对象)给缓存在…...

DateKit
目录 1、 DateKit 1.1、 DaysBetween 1.2、 compareDate 1.3、 dateFormat 1.4、 birthdayFormat 1.5、 getYesterday...

百度智能云数据仓库 Palo 实战课程
通过本课程,您将学习如何使用 Palo 构建高性能、低延迟的分布式数仓服务,掌握数据建模、数据导入、查询优化和系统调优等技能,掌握如何管理和运维 Palo 集群,提高数据处理和分析的效率。同时,我们将进一步向您介绍 Pal…...
与去IO编程:Node.js的事件驱动和非阻塞IO模型,它是如何使JavaScript走向后端的)
服务端JavaScript(Node.js)与去IO编程:Node.js的事件驱动和非阻塞IO模型,它是如何使JavaScript走向后端的
在Node.js中,JavaScript代码运行在V8引擎上。由于JavaScript是单线程语言,一次只能处理一个事件。为了解决这个问题,Node.js引入了事件驱动模型。每个进行IO操作的函数都是异步的,当这个函数被调用的时候,它不会立即执…...

一键局域网共享工具
一键局域网共享工具:实现文件快速共享的新选择 在数字化时代,文件共享已成为我们日常工作和生活中的重要需求。无论是在家庭还是在办公环境中,我们经常需要在不同的设备之间传输文件。为了满足这一需求,一键局域网共享工具应运而…...

python实现把doc文件批量转化为docx
python实现把doc文件批量转化为docx import os from win32com import client as wcdef doSaveAas(doc_path,docx_path):#该函数参考https://blog.csdn.net/m0_38074612/article/details/128985384word wc.Dispatch(Word.Application)doc word.Documents.Open(doc_path) # 目…...

WEB基础---反射
什么是反射 相对官方解释 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力; 在运行时期,动态地去获取类中的信息(类的信息,方法信息,构造器信息,字段等信息); 在运行的时候获取到的类信息 封装一个字节码对象…...

impdp恢复表后发现比原表多了100多行
因客户删除数据,恢复表时发现恢复表后发现比原表多了100多行,啥原因暂不清楚,继续学习 [oraclehydb ~]$ more expdp_orcl_20240406_2100.log |grep "USR_HY"."T_COPIES". . exported "USR_HY"."T_COPIES…...

Jupyter配置远程访问的密码
安装 下载Anaconda的.sh文件后,上传到服务器,然后进行安装: chmod x anaconda.sh ./anaconda.sh创建虚拟环境 可以指定Python版本创建虚拟环境: conda create --name langchain python3.11.7 conda activate langchain conda …...

Windows下通过MySQL Installer安装MySQL服务
在Windows下,使用MySQL Installer来安装MySQL服务是一个相对简单的过程。以下是一步一步的详细指南: 下载MySQL Installer: 访问MySQL官方网站(https://www.mysql.com/downloads/),在下载页面选择合适的MyS…...
C语言 [力扣]详解环形链表和环形链表II
各位友友们,好久不见呀!又到了我们相遇的时候,每次相遇都是一种缘分。但我更加希望我的文章可以帮助到大家。下面就来具体看看今天所要讲的题目。 文章目录 1.环形链表2.环形链表II 1.环形链表 题目描述:https://leetcode.cn/problems/link…...
Threejs 学习笔记 | 灯光与阴影
文章目录 Threejs 学习笔记 | 灯光与阴影如何让灯光照射在物体上有阴影LightShadow - 阴影类的基类平行光的shadow计算投影属性 - DirectionalLightShadow类平行光的投射相机 聚光灯的shadow计算投影属性- SpotLightShadow类聚光灯的投射相机 平行光 DirectionalLight聚光灯 Sp…...

PostgreSQL表膨胀避坑指南:从监控到优化的完整解决方案
PostgreSQL表膨胀避坑指南:从监控到优化的完整解决方案 PostgreSQL作为一款强大的开源关系型数据库,在企业级应用中扮演着重要角色。然而,随着数据量的增长和业务复杂度的提升,表膨胀问题逐渐成为许多DBA和开发者的"隐形杀手…...

如何通过智能备份技术实现微信聊天记录的数据主权?本地化管理方案全解析
如何通过智能备份技术实现微信聊天记录的数据主权?本地化管理方案全解析 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_…...

Fritzing电子设计软件:从原型到PCB的完整开源解决方案
Fritzing电子设计软件:从原型到PCB的完整开源解决方案 【免费下载链接】fritzing-app Fritzing desktop application 项目地址: https://gitcode.com/gh_mirrors/fr/fritzing-app Fritzing是一款功能强大的开源电子设计自动化(EDA)软件…...

Java 开发 日志技术
1.概述为什么要在程序中记录日志呢?便于追踪应用程序中的数据信息、程序的执行过程。便于对应用程序的性能进行优化。便于应用程序出现问题之后,排查问题,解决问题。便于监控系统的运行状态。2.日志框架JUL:这是JavaSE平台提供的官…...

打造专属AI克隆:零基础构建个性化智能助手的完整指南
打造专属AI克隆:零基础构建个性化智能助手的完整指南 【免费下载链接】WeClone 欢迎star⭐。使用微信聊天记录微调大语言模型,并绑定到微信机器人,实现自己的数字克隆。 数字克隆/数字分身/LLM/大语言模型/微信聊天机器人/LoRA 项目地址: h…...

告别配置噩梦:OpCore-Simplify让黑苹果EFI构建效率提升90%
告别配置噩梦:OpCore-Simplify让黑苹果EFI构建效率提升90% 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果配置一直是许多技术爱好者…...

【方案、开源】从零到国一:空地协同消防无人机系统全栈技术解析
1. 空地协同消防无人机系统设计思路 第一次接触这个项目时,我和很多同学一样感到无从下手。直到把整个系统拆解成几个核心模块,思路才逐渐清晰。这个系统的关键在于"空地协同"四个字,简单说就是让无人机和小车像两个配合默契的消防…...

全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案
全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在数字直播时…...
)
生信分析效率翻倍:fastp多线程+UMI处理技巧全解析(含实战案例)
生信分析效率翻倍:fastp多线程UMI处理技巧全解析(含实战案例) 在肿瘤基因检测和ctDNA测序领域,数据预处理环节往往成为整个分析流程的瓶颈。传统工具在处理海量测序数据时,不仅耗时长达数小时,还经常面临内…...

Rufus高效使用实战指南:精通ext2/ext3/ext4文件系统格式化
Rufus高效使用实战指南:精通ext2/ext3/ext4文件系统格式化 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 在Linux系统管理和开发工作中,USB设备的格式化与启动盘制作是一…...