Mapreduce | 案例
根据提供的数据文件【test.log】
数据文件格式:姓名,语文成绩,数学成绩,英语成绩

完成如下2个案例:
(1)求每个学科的平均成绩
(2)将三门课程中任意一门不及格的学生过滤出来
(1)求每个学科的平均成绩
- 上传到hdfs

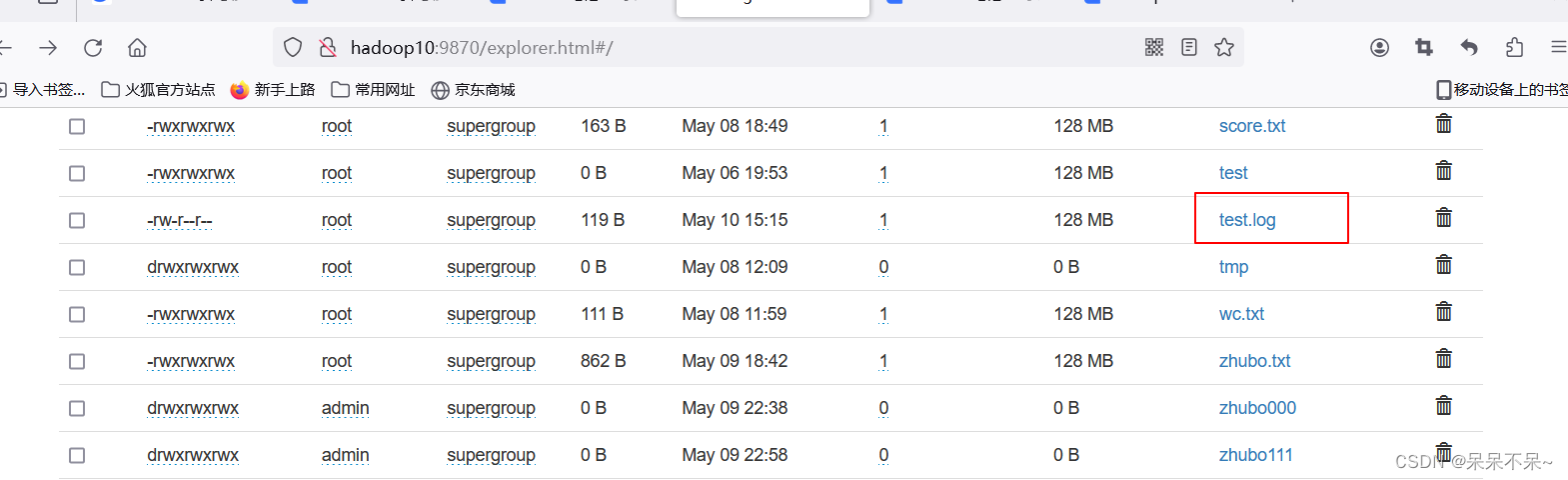
Idea代码:
package zz;import demo5.Sort1Job;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class ScoreAverageDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();conf.set("fs.defaultFS","hdfs://hadoop10:8020");Job job = Job.getInstance(conf);job.setJarByClass(ScoreAverageDriver.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);TextInputFormat.addInputPath(job,new Path("/test.log"));TextOutputFormat.setOutputPath(job,new Path("/test1"));job.setMapperClass(ScoreAverageMapper.class);job.setReducerClass(ScoreAverageReducer.class);//map输出的键与值类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//reducer输出的键与值类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);boolean b = job.waitForCompletion(true);System.out.println(b);}static class ScoreAverageMapper extends Mapper<LongWritable, Text, Text, IntWritable> {// 定义一个Text类型的变量subject,用于存储科目名称private Text subject = new Text();// 定义一个IntWritable类型的变量score,用于存储分数private IntWritable score = new IntWritable();// 重写Mapper类的map方法@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 将输入的Text值转换为字符串,并按逗号分割成数组String[] fields = value.toString().split(",");// 假设字段的顺序是:姓名,语文成绩,数学成绩,英语成绩String name = fields[0]; // 提取姓名int chinese = Integer.parseInt(fields[1]); // 提取语文成绩int math = Integer.parseInt(fields[2]); // 提取数学成绩int english = Integer.parseInt(fields[3]); // 提取英语成绩// 为Chinese科目输出成绩subject.set("Chinese"); // 设置科目为Chinesescore.set(chinese); // 设置分数为语文成绩context.write(subject, score); // 写入输出// 为Math科目输出成绩subject.set("Math"); // 设置科目为Mathscore.set(math); // 设置分数为数学成绩context.write(subject, score); // 写入输出// 为English科目输出成绩subject.set("English"); // 设置科目为Englishscore.set(english); // 设置分数为英语成绩context.write(subject, score); // 写入输出}}static class ScoreAverageReducer extends Reducer<Text, IntWritable, Text, IntWritable> {// 定义一个IntWritable类型的变量average,用于存储平均分数private IntWritable average = new IntWritable();// 重写Reducer类的reduce方法@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0; // 初始化分数总和为0int count = 0; // 初始化科目成绩的个数为0// 遍历该科目下的所有分数for (IntWritable val : values) {sum += val.get(); // 累加分数count++; // 计数加一}// 如果存在分数(即count大于0)if (count > 0) {// 计算平均分并设置到average变量中average.set(sum / count);// 写入输出,键为科目名称,值为平均分数context.write(key, average);}}}}
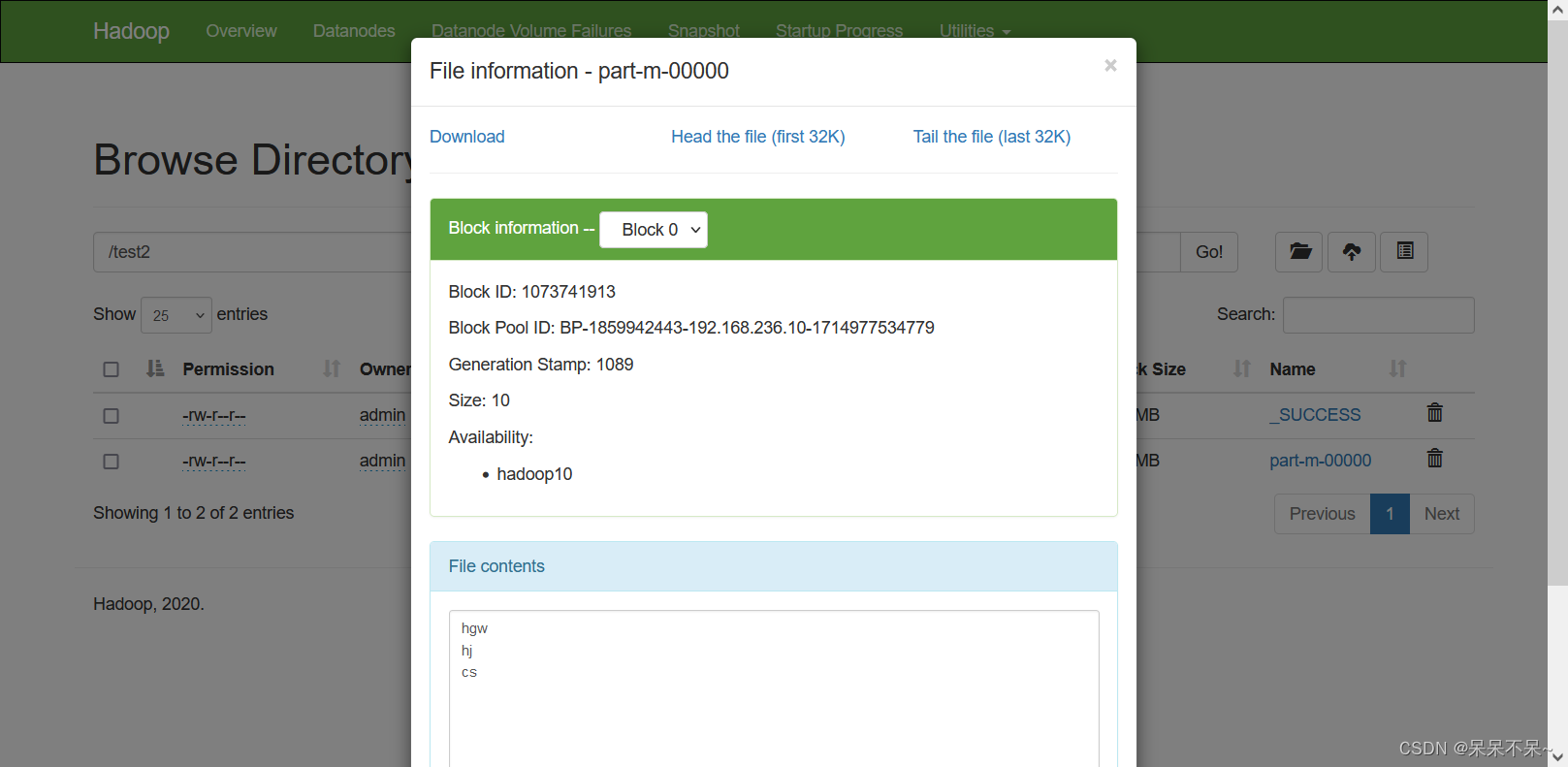
- 结果:
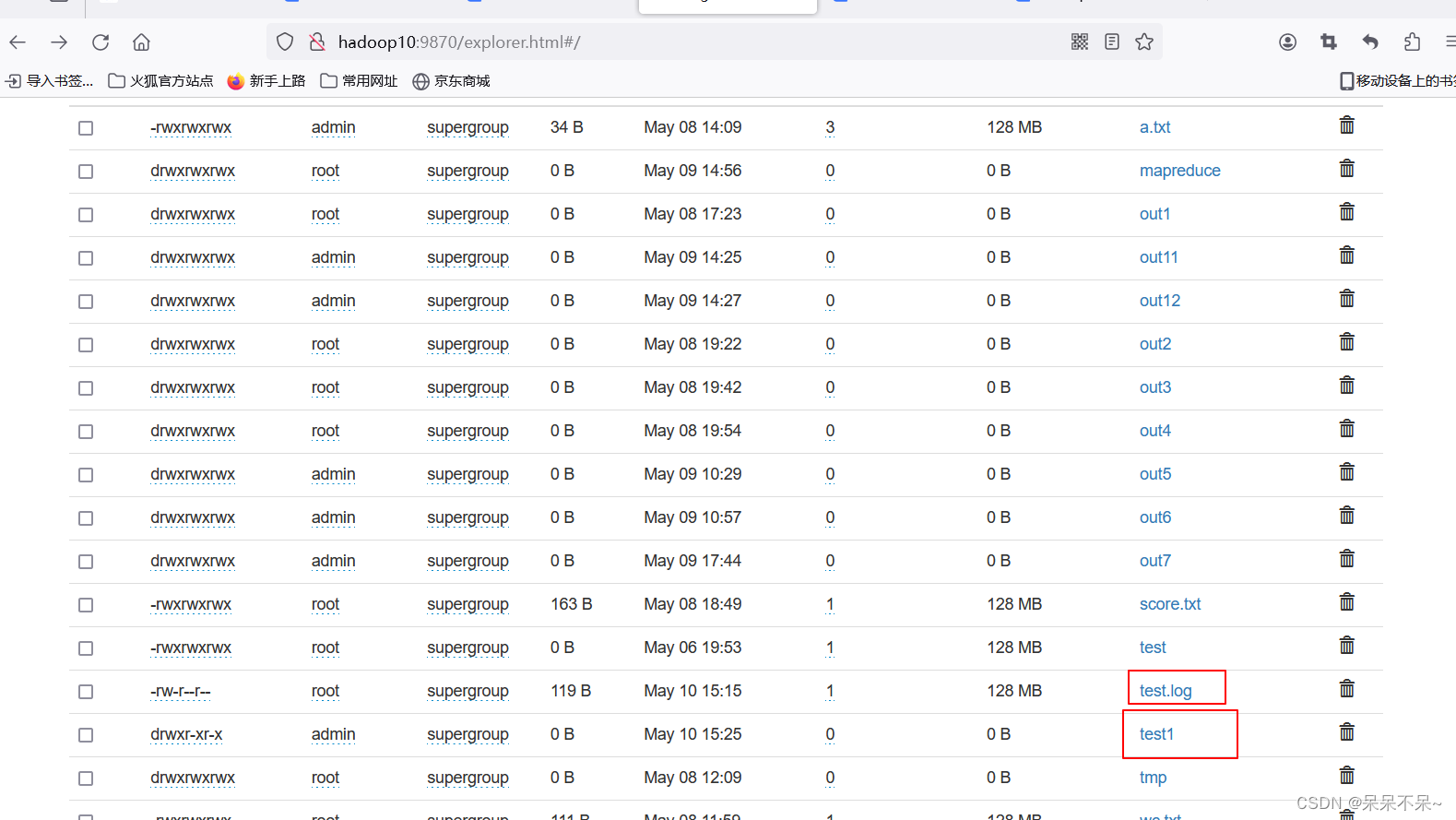
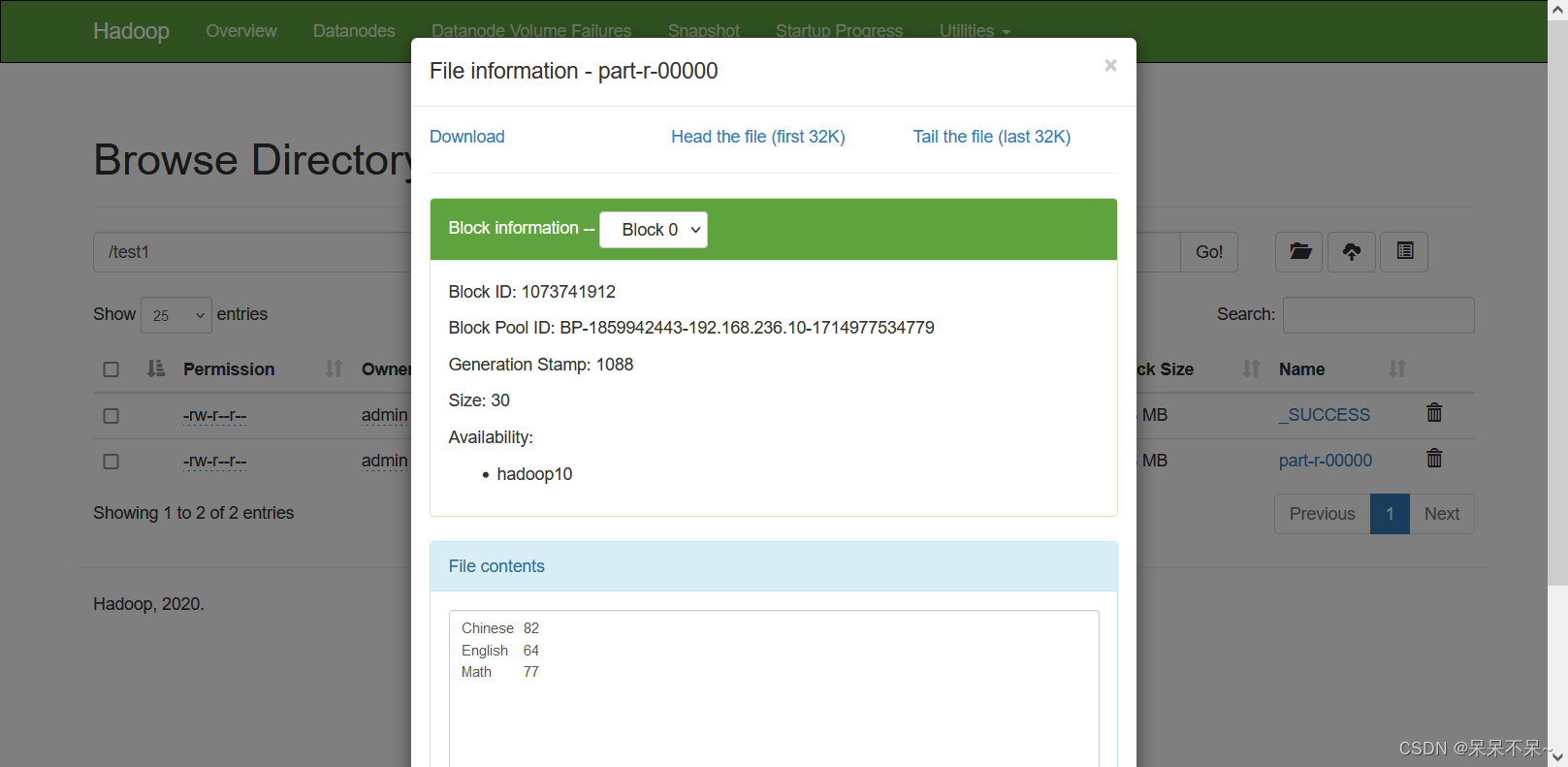
(2)将三门课程中任意一门不及格的学生过滤出来
- Idea代码
package zz;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class FailingStudentDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();conf.set("fs.defaultFS","hdfs://hadoop10:8020");Job job = Job.getInstance(conf);job.setJarByClass(FailingStudentDriver .class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);TextInputFormat.addInputPath(job,new Path("/test.log"));TextOutputFormat.setOutputPath(job,new Path("/test2"));job.setMapperClass(FailingStudentMapper.class);//map输出的键与值类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setNumReduceTasks(0);boolean b = job.waitForCompletion(true);System.out.println(b);}// 定义一个静态类FailingStudentMapper,它继承了Hadoop的Mapper类
// 该Mapper类处理的是Object类型的键和Text类型的值,并输出Text类型的键和NullWritable类型的值static class FailingStudentMapper extends Mapper<Object, Text, Text, NullWritable> {// 定义一个Text类型的变量studentName,用于存储不及格的学生姓名private Text studentName = new Text();// 定义一个NullWritable类型的变量nullWritable,由于输出值不需要具体的数据,所以使用NullWritableprivate NullWritable nullWritable = NullWritable.get();// 重写Mapper类的map方法,这是处理输入数据的主要方法@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 将输入的Text值转换为字符串,并按逗号分割成数组// 假设输入的Text值是"姓名,语文成绩,数学成绩,英语成绩"这样的格式String[] fields = value.toString().split(",");// 从数组中取出学生的姓名String name = fields[0];// 从数组中取出语文成绩,并转换为整数int chineseScore = Integer.parseInt(fields[1]);// 从数组中取出数学成绩,并转换为整数int mathScore = Integer.parseInt(fields[2]);// 从数组中取出英语成绩,并转换为整数int englishScore = Integer.parseInt(fields[3]);// 检查学生的三门成绩中是否有任意一门不及格(即小于60分)// 如果有,则将该学生的姓名写入输出if (chineseScore < 60 || mathScore < 60 || englishScore < 60) {studentName.set(name); // 设置studentName变量的值为学生的姓名context.write(studentName, nullWritable); // 使用Mapper的Context对象将学生的姓名写入输出}}}}- 结果:
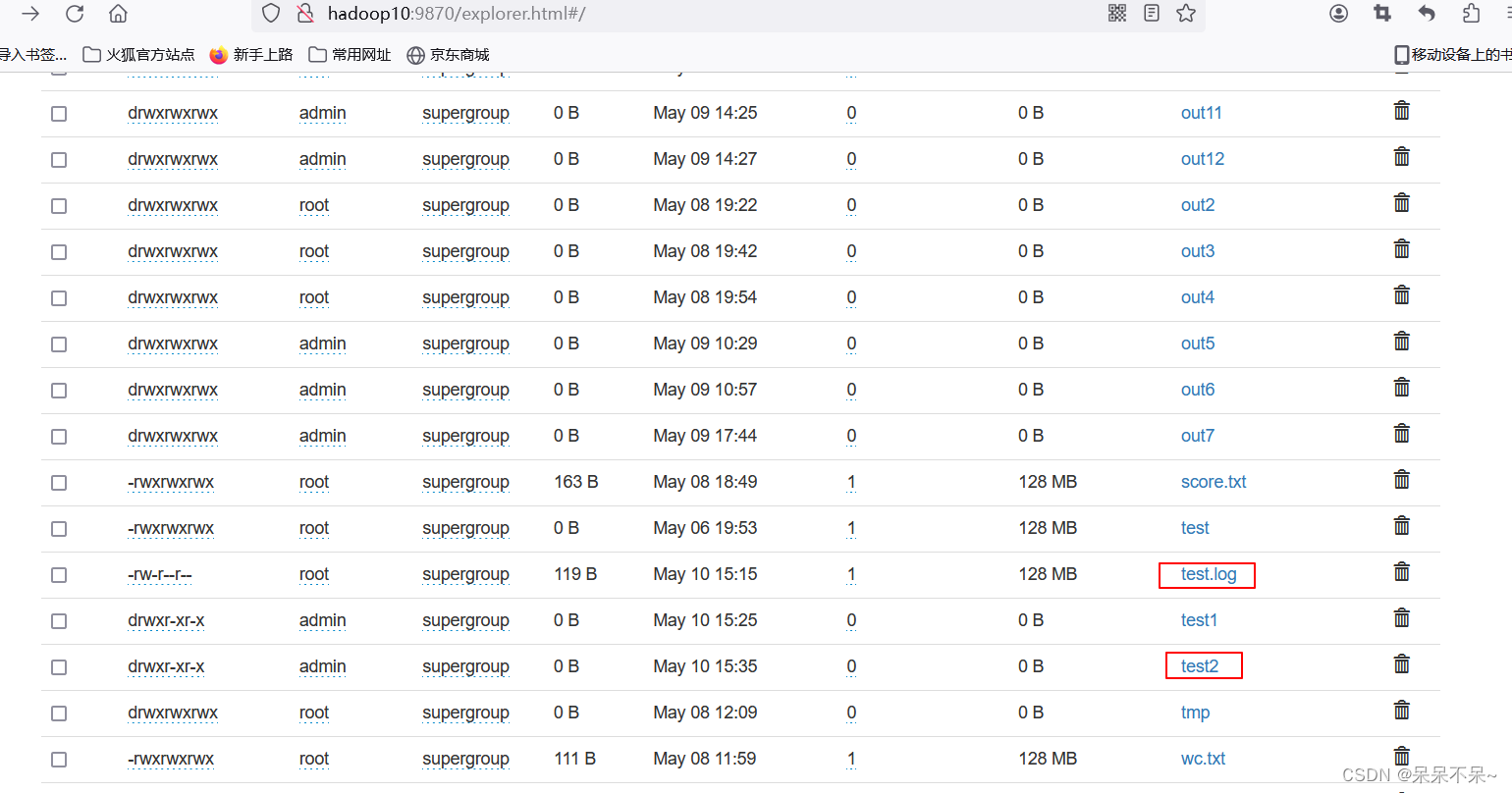
相关文章:
Mapreduce | 案例
根据提供的数据文件【test.log】 数据文件格式:姓名,语文成绩,数学成绩,英语成绩 完成如下2个案例: (1)求每个学科的平均成绩 (2)将三门课程中任意一门不及格的学生过滤出来 (1)求每…...

U盘文件剪切丢失怎么办?揭秘原因并给出恢复方法
在日常生活和工作中,U盘已成为我们不可或缺的数据存储和传输工具。但有时候,我们在对U盘中的文件进行剪切操作时,会遇到文件丢失的情况。这种突如其来的数据消失往往会让人感到惊慌和困惑。那么,为什么U盘剪切时文件会丢失呢&…...

软件设计师考试---访问控制列表、堆,栈和堆栈、防火墙、数据流图、嵌入式操作、绑定方式、uml、模式、传输协议
访问控制列表 访问控制列表(Access Control List,ACL) 是一种用于控制对资源(如文件、目录、网络资源等)访问权限的方法。ACL是在计算机安全领域广泛使用的概念,它允许系统管理员定义哪些用户或系统进程有…...

vlock工具:锁定Linux终端的安全智能方法
虚拟控制台是 Linux 非常重要的功能,它们为系统用户提供 shell 提示,以非图形设置方式使用系统,该设置只能在物理机上使用,而不能远程使用。 用户只需从一个虚拟控制台切换到另一个虚拟控制台即可同时使用多个虚拟控制台会话。 …...

【Linux】Docker 安装部署 Nacos
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 【Linux】Docker 安装部署 Nacos docker搜索na…...

纯血鸿蒙APP实战开发——阅读翻页方式案例
介绍 本示例展示手机阅读时左右翻页,上下翻页,覆盖翻页的功能。 效果图预览 使用说明 进入模块即是左右翻页模式。点击屏幕中间区域弹出上下菜单。点击设置按钮,弹出翻页方式切换按钮,点击可切换翻页方式。左右翻页方式可点击翻…...
如何从Mac电脑恢复任何删除的视频
Microsoft Office是包括Mac用户在内的人们在世界各地创建文档时使用的最佳软件之一。该软件允许您创建任何类型的文件,如演示文稿、帐户文件和书面文件。您可以使用 MS Office 来完成。所有Microsoft文档都可以在Mac上使用。大多数情况下,您处理文档&…...

【Halcon 内存泄漏记录 - C#】
Halcon 内存泄漏记录 - C# 1. Bitmap 转 HImage2. new 之后要Dispose()3. 切换配方后,内存会增加4. Parallel.For 嵌套Parallel.For, 会出现问题5. 图像预处理使用需要注意不能直接在原有变量上赋值 1. Bitmap 转 HImage 由于Bitmap 在转化时使用Bitmap…...
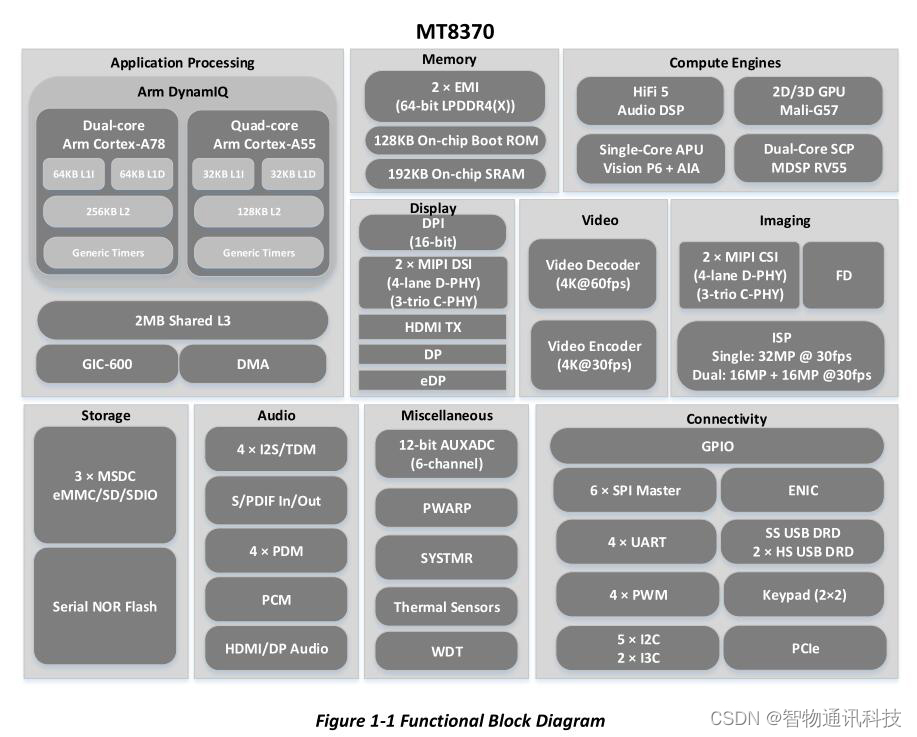
MT8370_联发科MTK8370(Genio 510)芯片性能规格参数
MT8370芯片是一款利用超高效的6nm制程工艺打造的边缘AI平台,具有强大的性能和功能。这款芯片集成了六核CPU(2x2.2 GHz Arm Cortex-A78 & 4x2.0 GHz Arm Cortex-A55)、Arm Mali-G57 MC2 GPU、集成的APU(AI处理器)和DSP,以及一个HEVC编码加速引擎&…...

【Qt 学习笔记】Qt常用控件 | 多元素控件 | Table Widget的说明及介绍
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt常用控件 | 多元素控件 | Table Widget的说明及介绍 文章编号&#…...
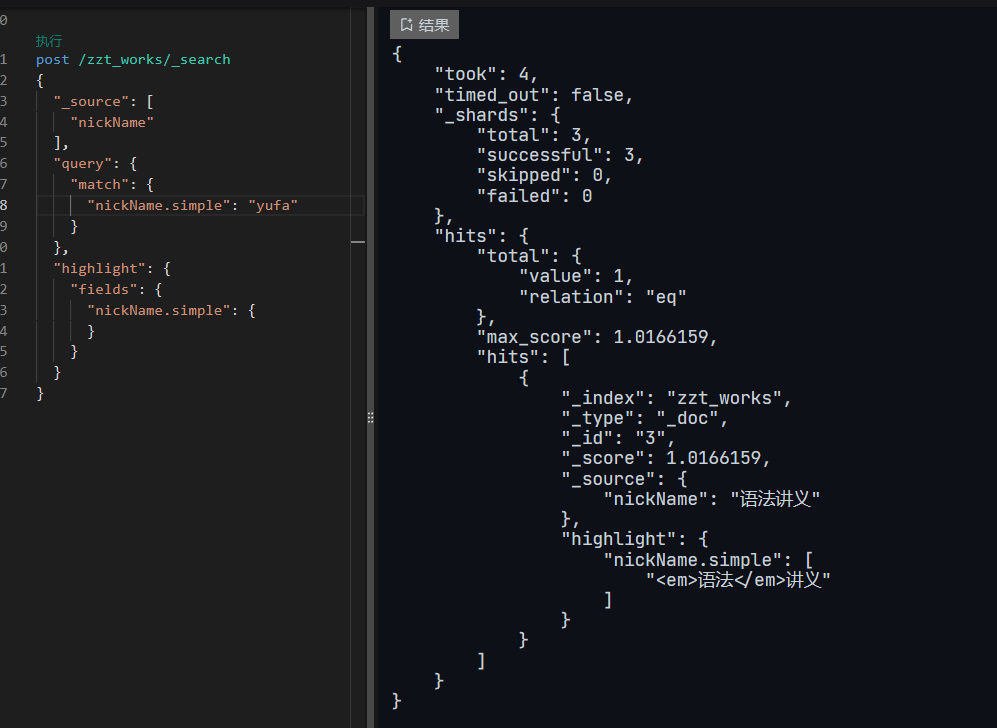
ES全文检索支持拼音和繁简检索
ES全文检索支持拼音和繁简检索 1. 实现目标2. 引入pinyin插件2.1 编译 elasticsearch-analysis-pinyin 插件2.2 安装拼音插件 3. 引入ik分词器插件3.1 已有作者编译后的包文件3.2 只有源代码的版本3.3 安装ik分词插件 4. 建立es索引5.测试检索6. 繁简转换 1. 实现目标 ES检索时…...

【DDR 终端稳压器】Sink and Source DDR Termination Regulator [C] S0 S1 S2 S3 S4 S5 6状态
TPS51200A-Q1 器件通过 EN 功能提供 S3 支持。EN引脚可以连接到终端应用中的SLP_S3信号。当EN 高电平(S0 状态)时,REFOUT 和 VO 引脚均导通。当EN 低电平(S3状态)时,VO引脚关断并通过内部放电MOSFET放电时…...
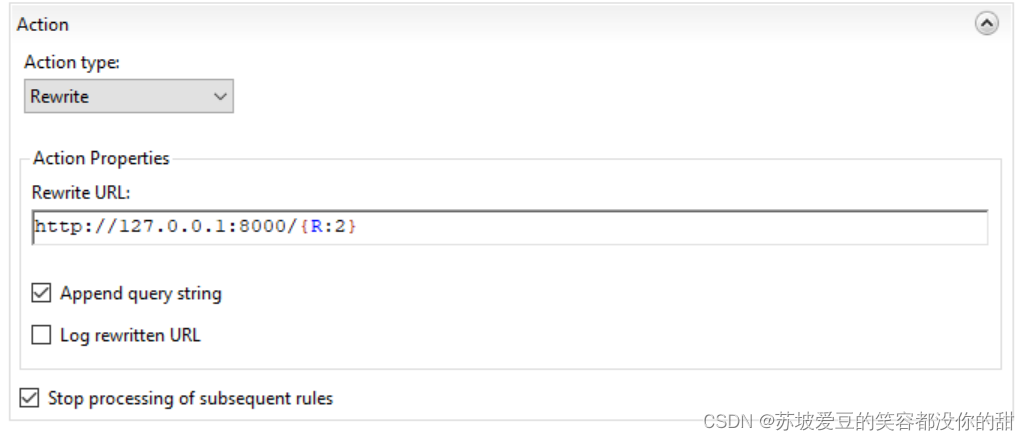
使用IIS部署Vue项目
前提 使用IIS部署Vue项目,后端必须跨域,不要在Vue中用proxy跨域,那个只在dev环境中有用! IIS安装,不用全部打勾,有些他默认就是方块 ■ 选择性安装的,就维持原样就可以。 添加网站配置 右键…...
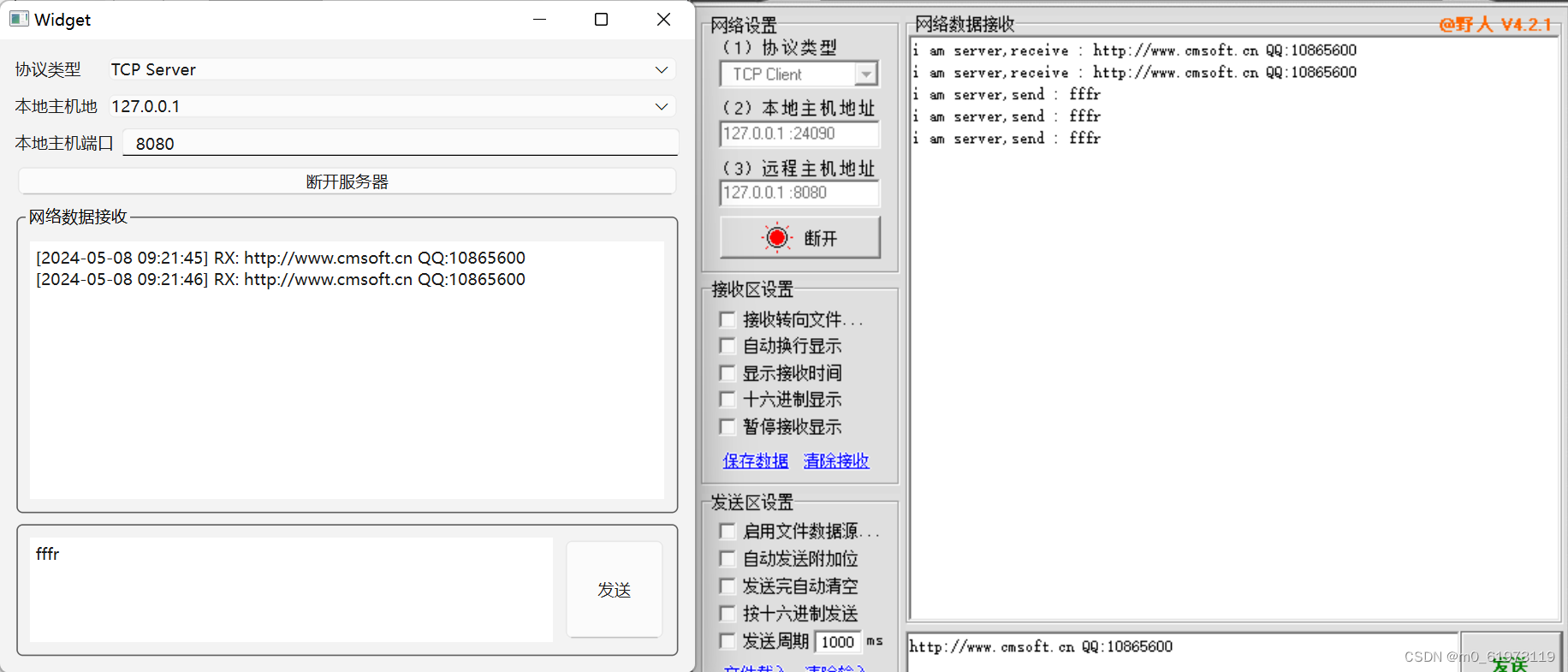
QT+多线程TCP服务器+进阶版
针对之前的服务器,如果子线程工作类里面需要使用socket发送消息,必须要使用信号与槽的方法, 先发送一个信号给父进程,父进程调用socket发送消息(原因是QT防止父子进程抢夺同一资源,因此直接规定父子进程不能…...
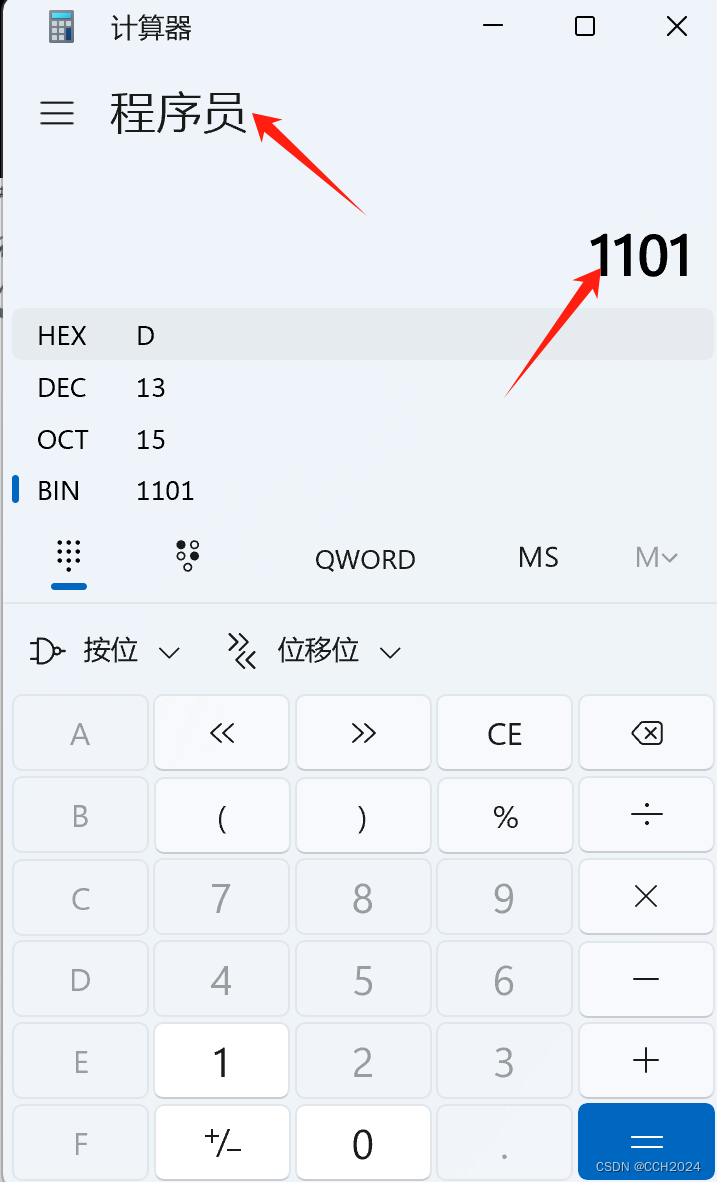
Java入门基础学习笔记12——变量详解
变量详解: 变量里的数据在计算机中的存储原理。 二进制: 只有0和1, 按照逢2进1的方式表示数据。 十进制转二进制的算法: 除二取余法。 6是110 13是1101 计算机中表示数据的最小单元:一个字节(byte&…...

bitmap requires a valid src attribute
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 未经允许不得转载 目录 一、导读二、概览三、问题记录四、 推…...

Java刷题-基础篇
目录 题目1:打印1~100内奇数和、偶数和 题目2:计算5的阶乘 题目3:计算 1!2!3!4!5! 的和 题目4:找1~100之间即能被3整除,又能被5整除的数字,要求必须使用break/continue 题目5:实现猜数字小…...

Linux——mysql运维篇
回顾基本语句: 数据定义语言 ( DDL ) 。这类语言用于定义和修改数据库的结构,包括创建、删除和修改数据库、表、视图和索引等对象。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 、 RENAME 、 TRUNCATE 等。 create database 数据库 &…...

力扣每日一题-统计已测试设备-2024.5.10
力扣题目:统计已测试设备 题目链接: 2960.统计已测试设备 题目描述 代码思路 根据题目内容,第一感是根据题目模拟整个过程,在每一步中修改所有设备的电量百分比。但稍加思索,发现可以利用已测试设备的数量作为需要减少的设备电…...
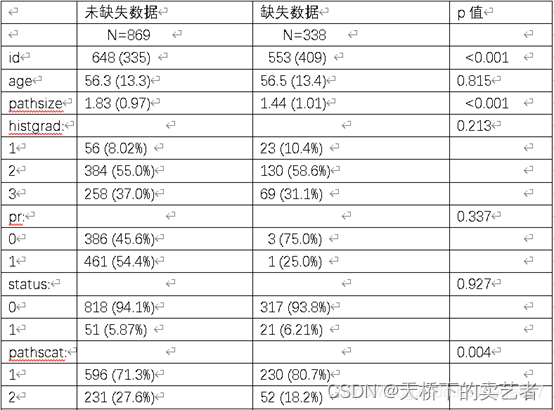
代码+视频,R言语处理数据中的缺失值
在SCI论文中,我们不可避免和缺失数据打交道,特别是在回顾性研究,对于缺失的协变量(就是混杂因素),我们可以使用插补补齐数据,但是对于结局变量和原因变量的缺失,我们不能这么做。部分…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
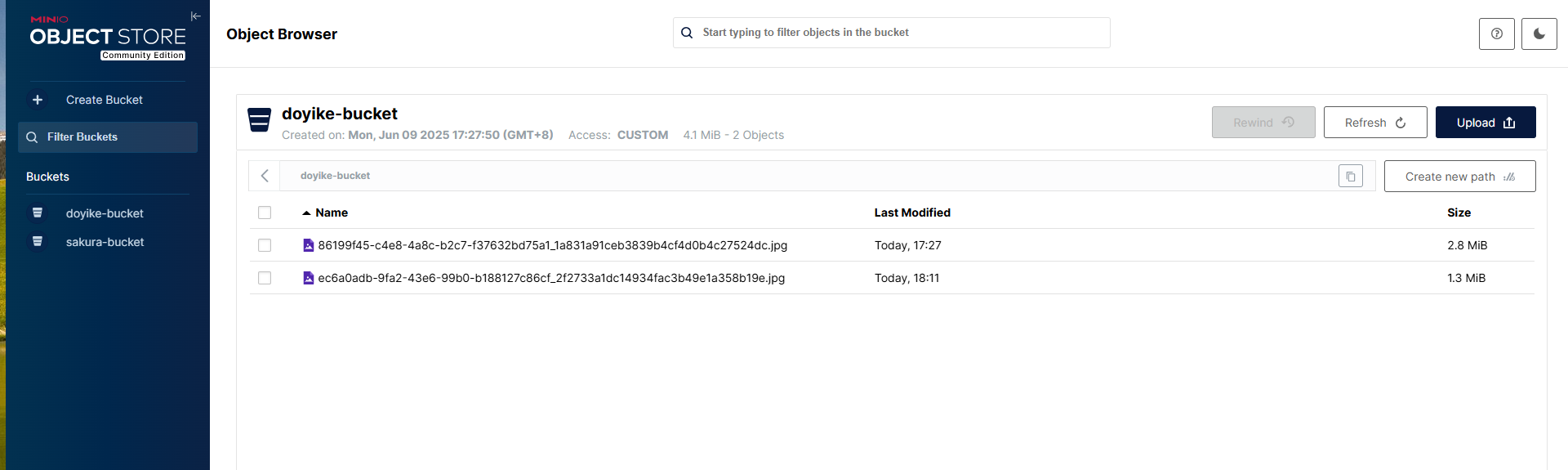
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...