1.基于python的单细胞数据预处理-降维可视化
目录
- 降维的背景
- PCA
- t-sne
- UMAP
- 检查质量控制中的指标
参考:
[1] https://github.com/Starlitnightly/single_cell_tutorial
[2] https://github.com/theislab/single-cell-best-practices
降维的背景
虽然特征选择已经减少了维数,但为了可视化,我们需要更直观的降维方法。降维将高维数据嵌入到低维空间中。低维表示仍然捕获数据的基本结构,同时尽可能少地持有维度。比如下图,我们将三维对象可视化为投影到二维空间中。

过去的研究独立比较了10种不同的降维方法的稳定性,准确性和计算成本。他们建议使用t-分布随机邻居嵌入(t-SNE),因为它产生了最佳的性能。统一流形逼近和投影(UMAP)显示出最高的稳定性,并且最好地分离了原始细胞群体。在这种情况下,值得一提的另一种降维方法是主成分分析(PCA),它仍然被广泛使用。
首先我们加载来自特征选择处理的数据:
import omicverse as ov
import scanpy as scov.ov_plot_set()adata = sc.read("./data/s4d8_preprocess.h5ad")
print(adata)
print(adata.X.max()) # 10.989398
在标准流程中,按照特征选择出的特征切片得到新矩阵后,我们还需要对新矩阵的计数进行scale(为了利于降维)。在omicverse中,我们将scale后的值存放进adata.layer,而不是像scanpy一样默认取代adata.X。但是注意,没有任何的证据表明,数据经过scale后会取得更好的差异基因分析结果,若盲目地使用scale后的计数值,还可能会导致使用dotplot或者violinplot中忽略了基因自身的特征信息,差异基因分析最好是使用缩放前的X。
比如我们关注的一个基因A的表达值在17-20区间,而基因B的表达值在0-3的区间,经过scale后,由于平均值被缩放成了0,基因A和基因B都在-2-2的区间范围内,这一定程度上失去了基因A表达量高的信息。故scale对差异基因分析似乎是不利的。
scale如下:
# 缩放
ov.pp.scale(adata,max_value=10)
print(adata)"""
AnnData object with n_obs × n_vars = 14814 × 2000obs: 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_20_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'log1p_total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'log1p_total_counts_hb', 'pct_counts_hb', 'outlier', 'mt_outlier', 'scDblFinder_score', 'scDblFinder_class'var: 'gene_ids', 'feature_types', 'genome', 'mt', 'ribo', 'hb', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'percent_cells', 'robust', 'mean', 'var', 'residual_variances', 'highly_variable_rank', 'highly_variable_features'uns: 'hvg', 'layers_counts', 'log1p'layers: 'counts', 'soupX_counts', 'scaled'
"""
可以发现adata的layers层多出了一个scaled,这就是我们经过scale后的数据。
PCA
基于scaled的数据进行PCA:
ov.pp.pca(adata,layer='scaled',n_pcs=50)
print(adata)
可以发现,adata.obsm层里多出了一个scaled|original|X_pca,这代表了我们使用的是layers中的scaled层数据进行的pca计算,当然我们也可以使用counts进行pca计算,效果如下:
ov.pp.pca(adata,layer='counts',n_pcs=50)
print(adata)
使用embedding函数,来对比基于两种不同的layers计算所得出的pca的差异:
import matplotlib.pyplot as plt
fig,axes=plt.subplots(1,2,figsize=(8,4))
ov.utils.embedding(adata,basis='scaled|original|X_pca',frameon='small',color='MS4A1',show=False,ax=axes[0])
ov.utils.embedding(adata,basis='counts|original|X_pca',frameon='small',color='MS4A1',show=False,ax=axes[1])
plt.savefig('./result/2-6_pca.png')

我们会发现基于scaled的pca结果,第一主成分和第二主成分有着相似的数量级,而基于counts的pca结果,第一主成分和第二主成分的数量级则有所差异,这对于后续的2维投影(比如t-sne和umap)可能会有显著的影响。
t-sne
t-SNE 是一种基于图的、非线性的降维技术,它将高维数据投影到 2D 或 3D 分量上。该方法基于数据点之间的高维欧几里得距离定义了一个高斯概率分布。随后,使用 t 分布在低维空间中重建概率分布,其中嵌入通过梯度下降进行优化。
分别对scaled的pca和counts的pca进行tsne:
sc.tl.tsne(adata, use_rep="scaled|original|X_pca")
# tsne函数默认是存放在adata.obsm['X_tsne']中的,我们将其存放在adata.obsm['X_tsne_scaled']中来区分counts的结果
adata.obsm['X_tsne_scaled']=adata.obsm['X_tsne']
sc.tl.tsne(adata, use_rep="counts|original|X_pca")
adata.obsm['X_tsne_counts']=adata.obsm['X_tsne']# 可视化
import matplotlib.pyplot as plt
fig,axes=plt.subplots(1,2,figsize=(8,4))
ov.utils.embedding(adata,basis='X_tsne_scaled',frameon='small',color='MS4A1',show=False,ax=axes[0])
ov.utils.embedding(adata,basis='X_tsne_counts',frameon='small',color='MS4A1',show=False,ax=axes[1])
plt.savefig('./result/2-6_tsne.png')

UMAP
UMAP 是一种基于图的、非线性的降维技术,原理上与 t-SNE 类似。它构建了数据集的高维图表示,并优化低维图表示,使其在结构上尽可能地与原始图相似。
我们首先基于PCA的结果,在单细胞数据上构建一个邻域图再运行umap:
sc.pp.neighbors(adata, n_neighbors=15, n_pcs=50,use_rep='scaled|original|X_pca')
sc.tl.umap(adata)
# umap函数默认是存放在adata.obsm['X_umap']中的,我们将其存放在adata.obsm['X_umap_scaled']中来区分counts的结果
adata.obsm['X_umap_scaled']=adata.obsm['X_umap']sc.pp.neighbors(adata, n_neighbors=15, n_pcs=50,use_rep='counts|original|X_pca')
sc.tl.umap(adata)
adata.obsm['X_umap_counts']=adata.obsm['X_umap']# 可视化
import matplotlib.pyplot as plt
fig,axes=plt.subplots(1,2,figsize=(8,4))
ov.utils.embedding(adata,basis='X_umap_scaled',frameon='small',color='MS4A1',show=False,ax=axes[0])
ov.utils.embedding(adata,basis='X_umap_counts',frameon='small',color='MS4A1',show=False,ax=axes[1])
plt.savefig('./result/2-6_umap.png')

检查质量控制中的指标
现在我们可以在scaled数据的UMAP中检查之前的质量控制指标,一般检查三个指标:total_counts,n_genes_by_counts,pct_counts_mt。
如果前面使用的是omicverse.pp.qc,那么我们将直接得到nUMIs,detected_genes,mito_perc三个变量,如果使用的是scanpy进行的质控,那么得到的将是total_counts,n_genes_by_counts 和 pct_counts_mt 三个变量。
我们使用numpy中的log2对数化,将数据可视化区间缩小,同时,我们定义最大最小值来衡量我们的数据质量,我们希望total_counts大于250,250的对数值是7.96,所以我们最小值设定为8,最大值则定义为30,000,即15,而线粒体的比例则在0-100的范围内。
import numpy as np
adata.obs['log2_nUMIs']=np.log2(adata.obs['total_counts'])
adata.obs['log2_nGenes']=np.log2(adata.obs['n_genes_by_counts'])
ov.utils.embedding(adata,basis='X_umap_scaled',color=['log2_nUMIs','log2_nGenes','pct_counts_mt'],title=['log2#(nUMIs)','log2#(nGenes)','Mito_Perc'],vmin=[0,0,0],vmax=[15,15,100],show=False,frameon='small',)
plt.savefig('./result/2-6_qc.png')
理想情况如下图,total_counts(全部高亮),n_genes_by_counts(全部高亮),pct_counts_mt(全部不高亮)。

然后保存数据用于后续分析:
adata.write_h5ad('./data/s4d8_dimensionality_reduction.h5ad', compression='gzip')
相关文章:
1.基于python的单细胞数据预处理-降维可视化
目录 降维的背景PCAt-sneUMAP检查质量控制中的指标 参考: [1] https://github.com/Starlitnightly/single_cell_tutorial [2] https://github.com/theislab/single-cell-best-practices 降维的背景 虽然特征选择已经减少了维数,但为了可视化࿰…...
【快捷部署】023_HBase(2.3.6)
📣【快捷部署系列】023期信息 编号选型版本操作系统部署形式部署模式复检时间023HBase2.3.6Ubuntu 20.04tar包单机2024-05-07 注意:本脚本非全自动化脚本,有2次人工干预,第一次是确认内网IP,如正确直接回车即可&#…...

Nginx配置项详解
Nginx,以其高性能、稳定性强、资源消耗低的特性,成为众多网站和应用首选的Web服务器及反向代理服务器。其配置文件的灵活性和丰富性是其强大功能的关键所在。本文将深入解析Nginx配置文件中的核心概念与关键配置项,帮助您更好地理解和定制Ngi…...
解决iview(view ui)中tabs组件中使用图片预览组件ImagePreview,图片不显示问题
同学们可以私信我加入学习群! 正文开始 前言一、问题描述二、原因分析三、解决方案总结 前言 最近在写个人项目的web端和浏览器插件,其中一个功能是base64和图片的转换。因为分成四个小功能,所以使用的iview的tabs来展示不同功能,…...

R2S+ZeroTier+Trilium
软路由使用ZeroTier搭建远程笔记 软路由使用ZeroTier搭建远程笔记 环境部署 安装ZeroTier安装trilium 环境 软路由硬件:友善 Nanopo R2S软路由系统:OpenWrt,使用第三方固件nanopi-openwrt。内网穿透:ZeroTier。远程笔记&…...
10 华三vlan技术介绍
AI 解析 -Kimi-ai Kimi.ai - 帮你看更大的世界 (moonshot.cn) 虚拟局域网(VLAN)技术是一种在物理网络基础上创建多个逻辑网络的技术。它允许网络管理员将一个物理网络分割成多个虚拟的局域网,这些局域网在逻辑上是隔离的,但实际…...
)
实现一个聊天室可发送消息语音图片视频表情包(任意文件)
文章目录 如何跑通代码仓库地址客户端登录发送消息接受消息发送文件接受文件 服务端接受消息并发送给各个客户端接受文件并发送给各个客户端 如何跑通 将手机和电脑都连自己的热点先运行服务器得到可监听的地址更新客户端安卓消息线程和文件线程的socker目标地址为可监听地址然…...
【SpringMVC 】什么是SpringMVC(一)?如何创建一个简单的springMvc应用?
文章目录 SpringMVC第一章1、什么是SpringMVC2、创建第一个SpringMVC的应用1-3步第4步第5步第6步7-8步3、基本语法1、进入控制器类的方式方式1:方式2:方式3:方式4:方式5:2、在控制器类中取值的方式方式1:方式2:方式3:方式4:方式5:方式6:超链接方式7:日期方式8:aja…...
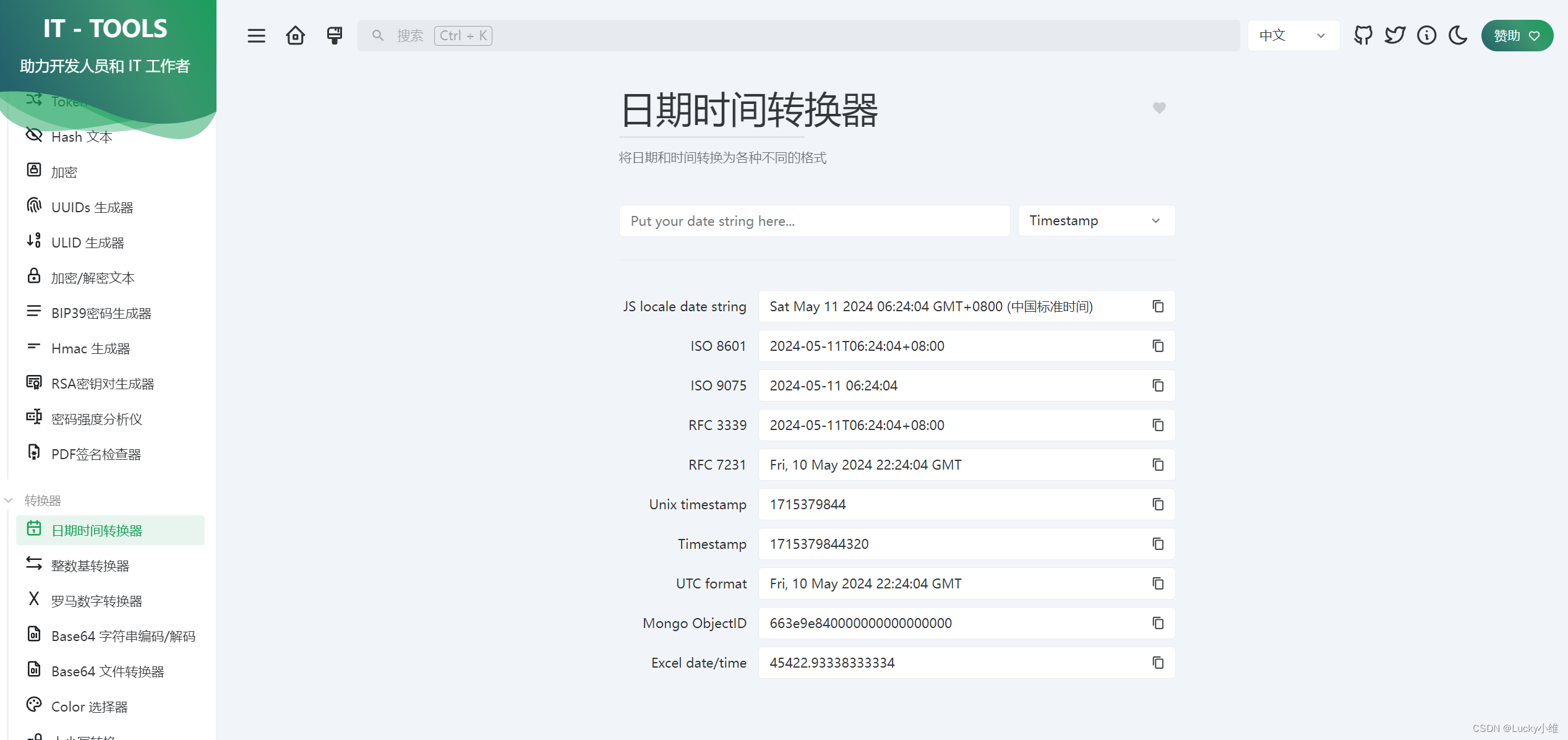
【配置】IT-Tools部署
github地址 docker运行如下,记得打开云服务器的9090端口 docker run -d --name it-tools --restart unless-stopped -p 9090:80 corentinth/it-tools:latestip:9090查看,很香大部分工具都有...

【Python】如何训练模型并保存本地和加载模型
这个年纪的我们 爱情跟不上分开的节奏 这个年纪的我们 更珍惜难得的自由 这个年纪的我们 比起从前更容易感动 这个年纪的我们 徘徊在理想与现实之中 🎵 齐一《这个年纪》 逻辑回归是一种常用的分类算法,能够根据输入特征预测目标变…...
浅谈如何利用 AI 提高内容生产效率?|TodayAI
在数字化时代,内容的创建和分发速度变得尤为关键。人工智能(AI)技术提供了加速这一过程的可能性,不仅提升了生产效率,还改善了内容的质量和受众的接受度。本文深入探讨AI如何在内容生成、分发与推广,以及内…...
毕业论文答辩PPT怎么做?推荐3个ai工具帮你一键生成答辩ppt
在我原本的认知里面,答辩PPT是要包含论文各个章节的,在答辩时需要方方面面都讲到的,什么摘要、文献综述、实证分析、研究结果样样不落。但是,这大错特错! 答辩PPT环节时长一般不超过5分钟,老师想要的答辩P…...

力扣 5-11
704. 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 这道题目的前提是数组为有序数组,同时题目还强…...

redisson 使用脚本实现判断元素不在队列中则插入的原子操作
脚本逻辑: 取出队列所有元素遍历元素查找值是否存在不存在则推入 final String scriptText """local valuesInTarget redis.call(lrange, KEYS[1], 0, -1);local index 0;for i, v in ipairs(valuesInTarget) doif v value thenindex ibreake…...
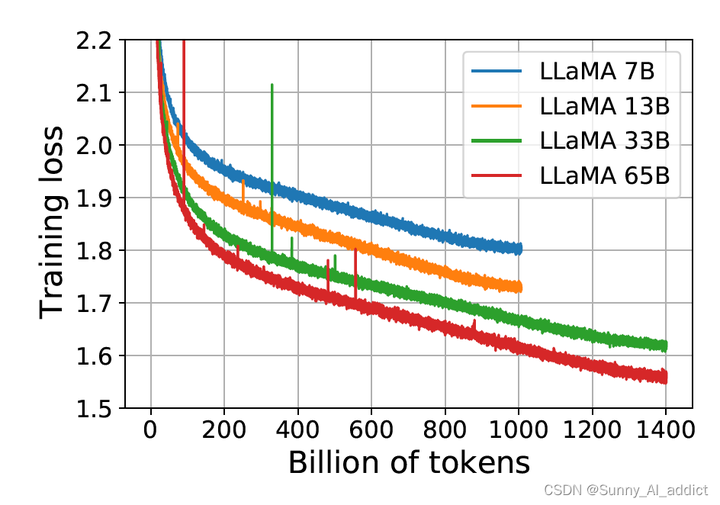
LLaMA详细解读
LLaMA 是目前为止,效果最好的开源 LLM 之一。精读 LLaMA 的论文及代码,可以很好的了解 LLM 的内部原理。本文对 LLaMA 论文进行了介绍,同时附上了关键部分的代码,并对代码做了注释。 摘要 LLaMA是一个系列模型,模型参…...

纯血鸿蒙APP实战开发——页面间共享组件实例的案例
介绍 本示例提供组件实例在页面间共享的解决方案:通过Stack容器,下层放地图组件,上层放Navigation组件来管理页面,页面可以共享下层的地图组件,页面中需要显示地图的区域设置为透明,并参考触摸交互控制&am…...

华为机考入门python3--(22)牛客22- 汽水瓶
分类:数字 知识点: 整除符号// 5//3 1 取余符号% 5%3 2 题目来自【牛客】 import sysdef calc_soda_bottles(n):if n 0: # 结束输入,不进行处理returnelse:# 循环进行汽水换算total_drunk 0 # 记录总共喝了多少瓶汽水while…...
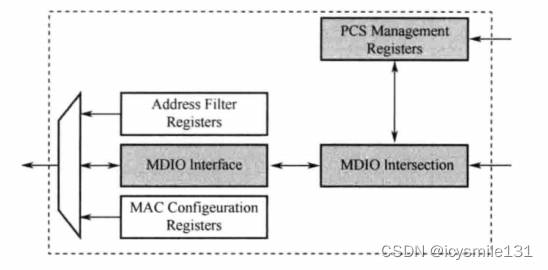
Xilinx 千兆以太网TEMAC IP核简介
Xilinx 公司提供了千兆以太网MAC控制器的可参数化LogiCORET™IP解决方案,通过这个IPCore可以实现FPGA与外部网络物理层芯片的互连。基于Xilinx FPGA 的以太网设计,大大降低了工程的设计复杂度,缩短了开发周期,加快了产品的面市速度…...

激光测径仪在胶管生产中扮演着什么角色?
关键词:激光测径仪,胶管,胶管测径仪,在线测径仪 胶管生产的基本工序为混炼胶加工、帘布及帆布加工、胶管成型、硫化等。不同结构及不同骨架的胶管,其骨架层的加工方法及胶管成型设备各异。 全胶胶管因不含骨架层,只需使用压出机压出胶管即可&…...

数据结构与算法===递归
文章目录 定义适用场景爬楼梯代码实现 小结 定义 递归(Recursion)是指函数的自身调用。 这个算法演变为了程序员之间的梗,所表达的意思近似于“套娃”,表示不断重复引用别人的话从而产生循环。 适用场景 这个应该很多的,像一些树的遍历&am…...

DICOM文件结构深度解析:从Tag到像素数据的完整指南
1. 揭开DICOM的神秘面纱:医疗影像的通用语言 第一次接触DICOM文件时,我完全被那些十六进制代码搞懵了。这就像拿到一份用外星语写的病历,明明知道里面藏着重要信息,却怎么也读不懂。后来才发现,DICOM其实是医疗影像界…...

3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南
3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft的level.dat文件…...

Gemini 辅助做创意写作:故事大纲、角色设定、世界观构建的 AI 协作
很多作者在创作卡壳时,其实不是“没有灵感”,而是缺一套可迭代的设计流程:大纲松散、角色像说明书、世界观看似宏大却前后不一致。2026 年的写作新趋势,是把 Gemini 当作“创作协作伙伴”而不是“代写引擎”,让它参与结…...

二十七、RZN2L CherryUSB移植与性能对比
一、目的/概述1、cherryusb还没有人支持瑞萨芯片,我们尝试在RZN2L CR52上移植CherryUSB协议栈2、在rzn2l芯片上实现USB CDC ACM 功能(实现cherryusb hal)3、对比CherryUSB与瑞萨原厂USB例程的性能差异4、验证全速(12Mbps)和高速(4…...

基于本地AI的语音转文字工具OpenWhisp:隐私优先的离线生产力方案
1. 项目概述:一个完全本地的语音转文字工具 作为一个长期在效率工具和本地AI应用领域折腾的开发者,我一直在寻找一个能让我彻底摆脱网络延迟和隐私顾虑的语音输入方案。市面上的云服务要么有订阅费,要么有数据上传的隐忧,直到我看…...

AI设计风格Prompt实战指南:从32种风格词典到精准生成
1. 项目概述:一份给AI设计师的“风格词典”如果你和我一样,经常用 Claude、Cursor 或者 v0 这类 AI 工具来生成网页界面,那你肯定遇到过这个头疼的问题:脑子里想的是“赛博朋克”或者“瑞士风格”,但打出来的 prompt 却…...

为AI智能体构建长期记忆系统:零配置集成与四通道混合检索实践
1. 项目概述:为AI智能体装上“长期记忆”在AI智能体(Agent)的开发与使用中,一个长期存在的痛点就是“健忘症”。无论是基于OpenAI API还是本地部署的大模型,标准的对话模式都是无状态的——每次交互对于模型来说都是一…...
)
Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图)
更多请点击: https://intelliparadigm.com 第一章:Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图) 当Sora 2输出的4K/60fps高动态范围视频序列导入…...

Windows Cleaner:彻底告别C盘爆红的免费开源解决方案
Windows Cleaner:彻底告别C盘爆红的免费开源解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 面对Windows系统使用过程中C盘空间不断告急的困扰…...
:从理论基石到信号分解实战)
经验小波变换(EWT):从理论基石到信号分解实战
1. 经验小波变换(EWT)的前世今生 我第一次接触EWT是在处理一段轴承振动信号时。当时用传统EMD方法分解出的IMF分量里,高频噪声和故障特征频率完全混在一起,就像把咖啡和牛奶搅成了拿铁——虽然都是白色液体,但根本分不…...