每日10亿数据的日志分析系统OOM
背景
一个每日10亿数据的日志清洗系统,主要工作就是从消息队列中消费各种各样的日志,然后对日志进行清洗,例如:用户敏感信息(姓名、手机号、身份证)进行脱敏处理,然后把清理完的数据交付给其他系统使用。
我们项目中,推荐系统、营销系统,大数据分析系统,都会使用清洗好的数据。

现场
收到线上的报警,发现日志清洗系统发生了OOM
查看日志发现是java.lang.OutOfMemoryError: java heap space
通过异常日志,能看到如下信息:
xx.xx.xx.log.clean.XXClass.process()
xx.xx.xx.log.clean.XXClass.xx()
xx.xx.xx.log.clean.XXClass.xx()
xx.xx.xx.log.clean.XXClass.process()
xx.xx.xx.log.clean.XXClass.xx()
xx.xx.xx.log.clean.XXClass.xx()
xx.xx.xx.log.clean.XXClass.process()
xx.xx.xx.log.clean.XXClass.xx()
xx.xx.xx.log.clean.XXClass.xx()
这里能够发现,同一个方法XXClass.process() 被反复调用了,最终导致了堆内存溢出的问题。
初步定位是,某处有不合理的递归调用,接下来使用MAT分析内存快照。
分析
- 通过MAT去分析的时候,我们就发现了一个问题,因为有大量的XXClass.process()方法的递归执行,每个XXClass.process()中都创建了大量的char数组!导致大量的char[] 数组,耗尽了内存。
- 此时,我们发现了一个问题,递归的次数不是很多,也就十几次到几十次递归。我们也观察了一下,所有创建的char[],占用的内存也就1G,这就有一个问题了,这次oom不全是代码的问题,可能是我们的jvm参数设置的不对,分配的堆内存空间太小了。
- 因为我们要分析是不是堆内存设置的太小了,就要分析jvm运行时的内存使用模型,只能去看jvm启动参数中加入的自动记录GC日志,在日志中,我们发现JVM启动时的核心参数:
-Xmx1024m -Xms1024m -XX:+PrintGCDetails -XX:+PrintGC() -XX:+HeapDumpOnOutOfMemoryError -
Xloggc:/opt/logs/gc.log -XX:HeapDumpPath=/opt/logs/dump
。 - 观察日志可以发现,jvm参数里指定了gc的日志路径,以及内存溢出时要导出的内存快照地址,还有给堆分配的内存-Xmx1024m -Xms1024m,这台机器是4 core 8G的,只分配1G内存太小了
- 接下来详细看下gc.log:
[Full GC (Allocation Failure) 866M->654M(1024M)]
[Full GC (Allocation Failure) 843M->633M(1024M)]
[Full GC (Allocation Failure) 855M->621M(1024M)]
[Full GC (Allocation Failure) 878M->612M(1024M)]
在日志中发现,allocation failure触发的Full GC很多,也就是堆内存无法分配内存给新的对象了,然后触发GC,根据数据发现,每次full gc只能回收一点对象,而且日志中显示,是每秒full gc一次,很可怕。导致一直full gc的原因有两个,一个是老年代内存满了,每秒钟执行young gc之前,会发现老年代可用空间不够,就会提前触发full gc;另外一个可能是young gc之后,存活的对象无法放入到survivor区,都要进入老年代,放不下,就会触发full gc; - 我们重启了系统,利用jstat分析了一下当时jvm运行时的内存模型,发现如下情况:
S0 S1 E O YGC FGC
0 100 57 69 36 0
0 100 57 69 36 0
0 100 65 69 37 0
0 100 0 99 37 0
0 100 0 87 37 1
jstat解析
YGC 从36 -> 37 表示发生一次young gc,但是我们发现old区从69 -> 99 ,表示young gc之后,survivor区放不下,直接进入lod区,紧接着发生了一次FGC,但是发现old区并没有回收掉多少内存,几次循环之后,内存就堆满了,直接触发oom。
优化
- 增加堆内存大小
给堆内存加大空间,直接给了堆内存5G的内存。 - 改代码
改写代码,让他不要占用过多的内存。当时代码之所以递归,就是因为在一条日志中,可能会出现很多用户的信息,一条日志也许会合并包含了十几个到几十个用户的信息。
这个时候代码中就是会递归十几次到几十次去处理这个日志,每次递归都会产生大量的char[]数组,是切割了日志用来处理的。
其实这个代码写的完全没有必要,因为对每一条日志,如果发现包含了多个用户的信息,其实就对这一条日志切割出来进行处理就可以
了,完全没有必要递归调用,每次调用都切割一次日志,生成大量的char[]数组。
所以把这一步代码优化了之后,一下子发现线上系统的内存使用情况降低了10倍以上。
总结
今天这个案例,大家会发现,我们先是通过OOM的排查方法去分析,发现主要是内存太小导致的问题。然后用gc日志和jstat分析,明显发现是内存不够用了,最后加大系统内存,并且优化代码就可以了。
相关文章:
每日10亿数据的日志分析系统OOM
背景 一个每日10亿数据的日志清洗系统,主要工作就是从消息队列中消费各种各样的日志,然后对日志进行清洗,例如:用户敏感信息(姓名、手机号、身份证)进行脱敏处理,然后把清理完的数据交付给其他系统使用。 我们项目中,…...

智能驱动,精准管理:打造高效干部管理系统
干部管理系统是现代组织管理中不可或缺的工具,它通过信息技术的应用,提高了干部管理的效率和准确性。干部管理系统的主要功能包括: 1. 信息管理:系统可以存储和管理干部的个人信息,包括基本资料、工作经历、教育背景、…...
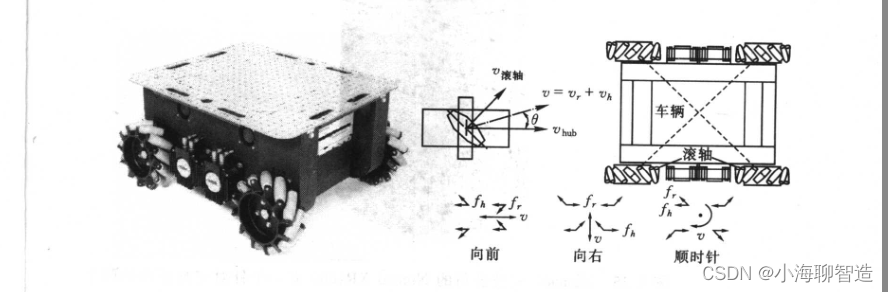
轮式机器人简介
迄今为止,轮子一般是移动机器人学和人造交通车辆中最流行的运动机构。它可达到很高的效率, 如图所示, 而且用比较简单的机械就可实现它的制作。 另外,在轮式机器人设计中,平衡通常不是一个研究问题。 因为在所有时间里,轮式机器人一般都被设计成在任何时间里所有轮子均与地接…...

已知哈夫曼节点个数,求哈夫曼字符编码数
哈夫曼编码(Huffman Coding)是一种用于无损数据压缩的嫡编码(权编码)算法。 在哈夫曼树中,每个叶子节点都代表一个字符,而节点的权重通常代表字符的频率。在哈夫曼编码中,每个字符都会被赋予一个二进制编码。为了获得这些编码,我…...

Kubernetes Cluster IP,Node IP,Pod IP间通信原理解析
目录 1、Cluster IP2、Node IP3、NodePort4、Pod IP5、LoadBalancer6、三种IP间通信6.1、Pod IP 与 Pod IP 通信6.2、Pod IP 与 Cluster IP 通信6.3、Node IP 与 Pod IP 通信6.4、Node IP 与 Cluster IP 7、YAML 示例7.1、ClusterIP Service7.2、LoadBalancer Service 1、Clust…...
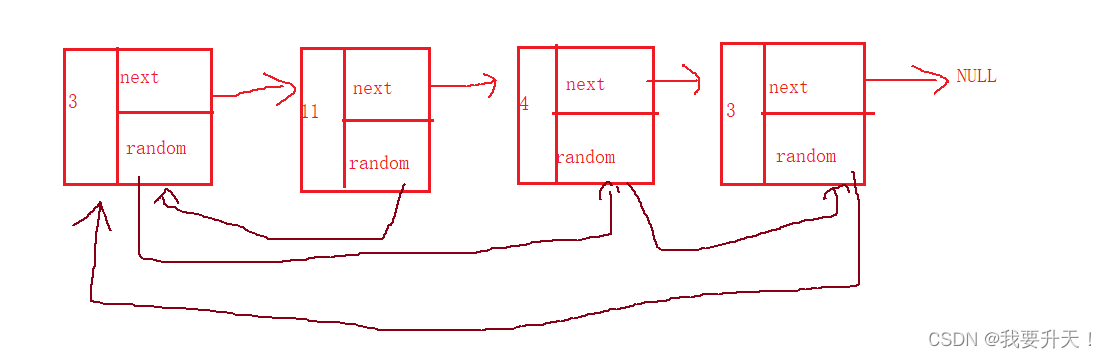
随机链表的深拷贝
1.题目 解题思路一:暴力求解,先创建新链表,然后把旧链表中的val和next指针给复制到新链表中,根据旧链表中的random指针所指向的旧链表中的val值找到所对应的节点,记录该节点的位置,就像数组一样,…...

328_C++_HTTP_HTTP协议传输data数据,为什么要进行base64编解码操作?
http传输data数据的时候,为什么必须进行base64转码后才能有效发送,接收方也必须base64转码后才能有效接受? HTTP HTTP传输数据时,使用Base64编码并不是必须的,但它确实在某些情况下非常有用。以下是为什么在某些情况…...
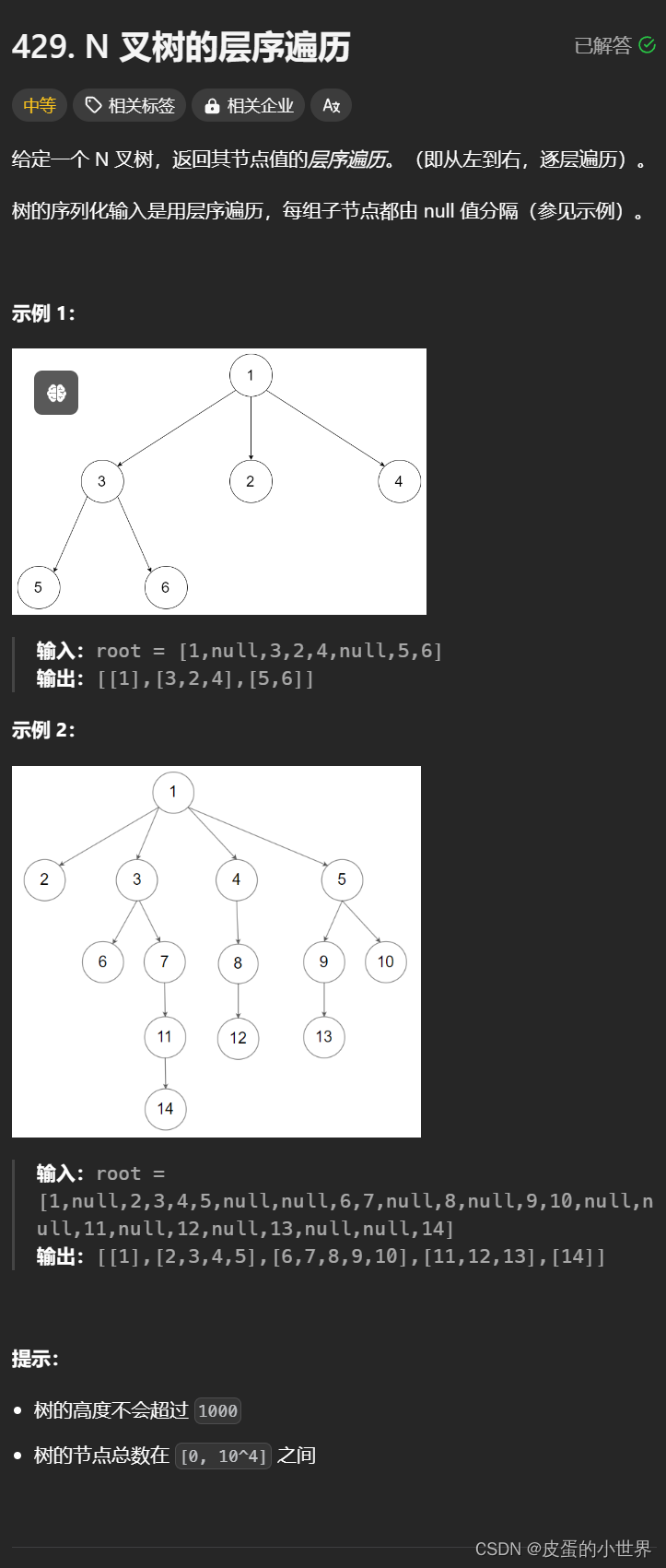
【二叉树】Leetcode N 叉树的层序遍历
题目讲解 429. N 叉树的层序遍历 算法讲解 在做层序遍历的时候由于它的每一个结点是有val vector child组成,所以在做层序遍历的时候需要考虑它每一层结点的个数,那我们就可以使用一个queue保存每一层的结点;那么我们在做第一层的时候&am…...

Spring AI
目录 一、Spring AI 1、Spring AI简介 1.1、四次工业革命发展和变革 1.2、什么是人工智能? 1.3、人工智能的发展历程 1.4、什么是大模型? 1.5、如何训练大模型? 一、Spring AI 1、Spring AI简介 Spring AI Java接入人工智能大模型 1.1、四次工业革命发展和变革 人类…...

fiori SAP ui5 动态改变控件颜色
使用CustomData动态改变控件颜色 有时候我们需要改变控件颜色,对于高度封装的控件,显然改变控件CSS是比较困难的,幸好SAP UI5预设了一个customData的属性,每个控件都能使用她。 如下代码是判断汇率是否有改变,如果改…...

RabbitMQ php amqp
Linux debian 安装 Windows php amqp 扩展 PECL :: Package :: amqp 将 php_amqp.dll 复制到 php 的 ext 目录下 将 rabbitmq.4.dll 复制到 c:\windows\system32 目录下 php.ini extensionamqp...
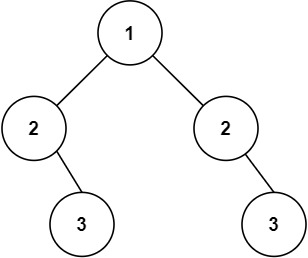
对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true示例 2: 输入:root [1,2,2,null,3,null,3] 输出:falses 思路:我刚开始是想着用…...

浅浅总结SQL中的事务.
在现实生活中有很多的线上支付的场景,当支付的时候,一方资金减少,另一方资金增加,在执行前后,两者的总体数额需要相同,为了保证这个操作的完整,所以提出了事务,那我们先来去写一个示例ÿ…...

C++ | Leetcode C++题解之第76题最小覆盖子串
题目: 题解: class Solution { public:unordered_map <char, int> ori, cnt;bool check() {for (const auto &p: ori) {if (cnt[p.first] < p.second) {return false;}}return true;}string minWindow(string s, string t) {for (const au…...

什么可以替代iframe?
网页嵌套中,iframe曾几何时不可一世,没有其他更好的选择! iframe即内联框架,作为网页设计中的一种技术,允许在一个网页内部嵌套另一个独立的HTML文档。尽管它在某些场景下提供了便利,但也存在多方面的缺陷…...

HTTP/1.0、HTTP/1.1、HTTP/2.0区别
文章目录 区别HTTP/1.0HTTP/1.11. 持久连接(长连接)2. 管道化3. Host头字段4. 分块传输编码5. 缓存机制6. 请求方法 HTTP/2.01. 二进制分帧2. 多路复用3. 服务器推送4. 优先级设置5. 头信息压缩6. 安全性7. 流量控制 区别 特性HTTP/1.0HTTP/1.1HTTP/2.0…...

鸿蒙内核源码分析(文件句柄篇) | 你为什么叫句柄
句柄 | handle int open(const char* pathname,int flags); ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count); int close(int fd);只要写过应用程序代码操作过文件不会陌生这几个函数,文件操作的几个关键步骤嘛,跟把大…...
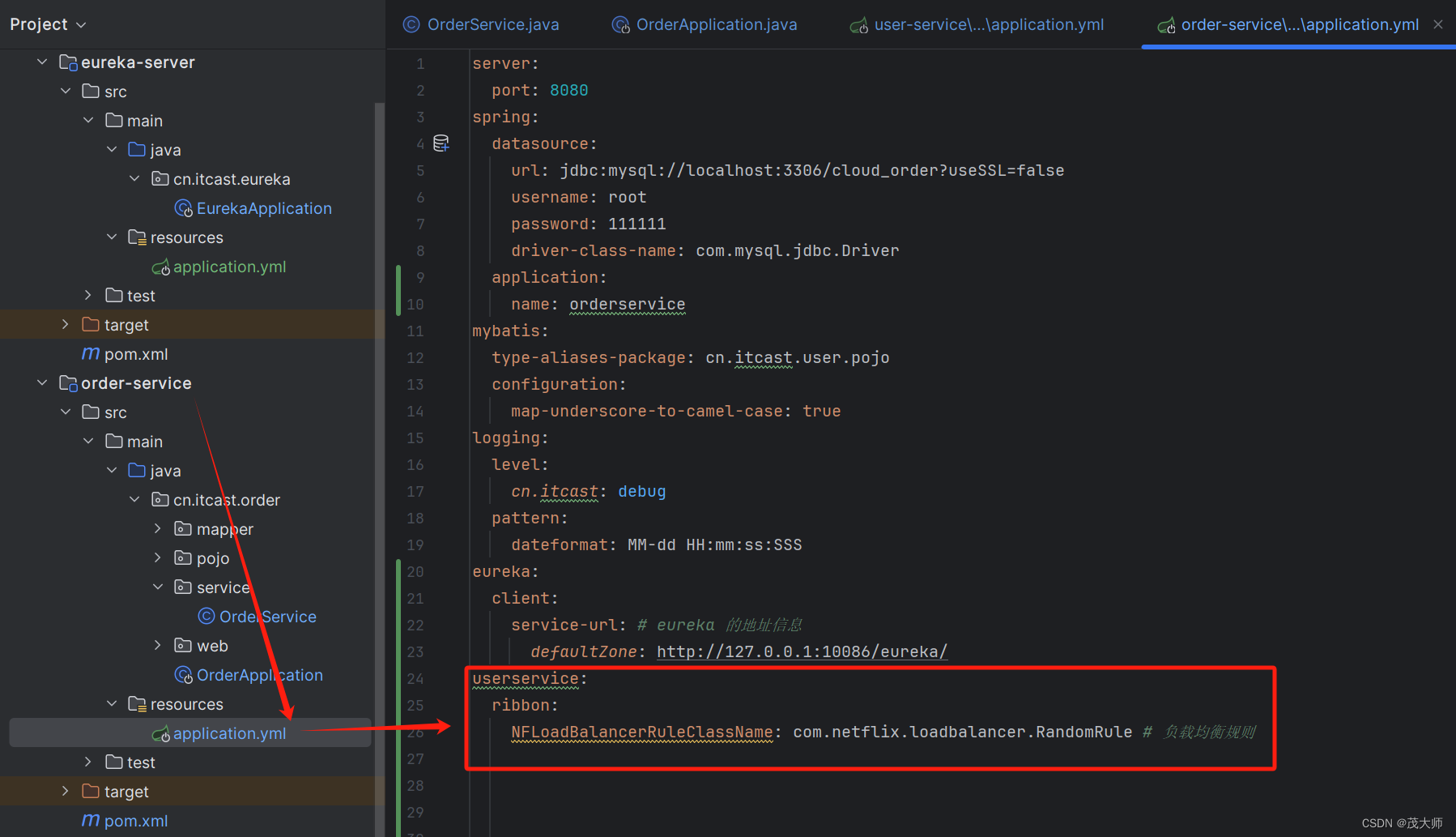
2024.5.8 关于 SpringCloud —— Ribbon 的基本认知
目录 Ribbon 负载均衡原理 工作流程 Ribbon 负载均衡规则 Ribbon 负载均衡自定义化 代码方式修改规则 配置文件方式修改规则 小总结 Ribbon 设定饥饿加载 Ribbon 负载均衡原理 工作流程 order-service 使用 RestTemplate 发送请求,随后该请求将会被 Ribbon 所…...

Lua 协程模拟 Golang 的 go defer 编程模式
封装go函数用于创建并启动一个协程: ---go函数创建并启动一个协程 ---param _co_task function 函数原型 fun(_co:thread) function go(_co_task)local co coroutine.create(_co_task) -- 创建一个暂停的协程coroutine.resume(co, co) -- 调用coroutine.resume激活…...
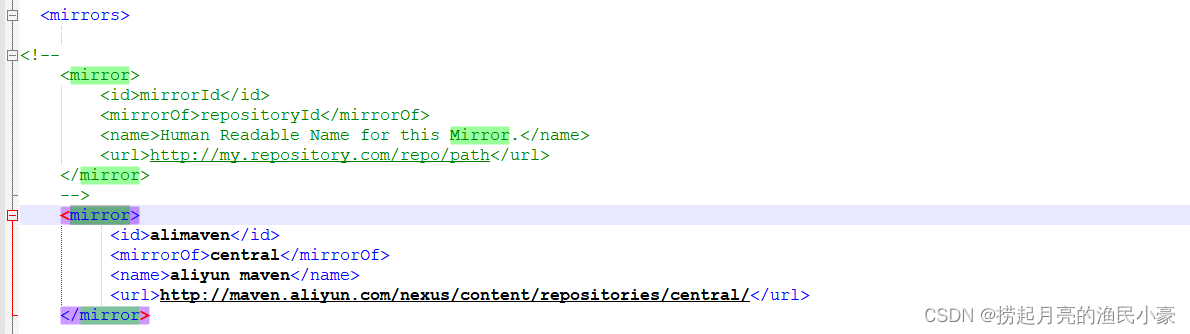
maven的安装与配置(超详细)
在Java开发中,配置Maven环境有几个重要的原因: 依赖管理:Maven 是一个强大的依赖管理工具,它能够帮助开发人员轻松地管理项目所需的各种第三方库和组件。通过在项目的 Maven 配置文件(pom.xml)中定义依赖&…...

进化发育生物学启发AI新范式:基因调控、弱连接与局部变异选择
1. 项目概述:从生物进化到机器学习的范式迁移在人工智能领域,我们常常陷入一种“局部最优”的困境:模型越做越大,参数越来越多,但系统的根本“智慧”——比如持续学习新任务而不遗忘旧知识、灵活重组已有技能解决新问题…...

OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现
OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 对于拥有2008年至2017年Intel Mac…...

5分钟快速上手:用FanControl打造你的Windows电脑静音散热系统
5分钟快速上手:用FanControl打造你的Windows电脑静音散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神
别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神 当项目规模从几千行扩展到几十万行代码时,技术债务就像房间里的大象——人人都知道存在,却少有人主动清理。去年我们团队在重构一个核心模块时,发现其中隐藏的…...

别再只玩开发板了!用吃灰的STM32核心板DIY一个专属游戏手柄,实战HID协议
从零构建STM32游戏手柄:深入解析HID协议与实战开发 你是否曾盯着抽屉里积灰的STM32核心板思考它能做什么?与其重复点亮LED的基础实验,不如挑战一个既实用又有趣的项目——打造专属游戏手柄。这不仅能让硬件资源重获新生,更是深入理…...

Gemini自动生成PPT实战手册:从零输入到专业演示文稿,3步完成95%的幻灯片工作流
更多请点击: https://intelliparadigm.com 第一章:Gemini自动生成PPT的核心原理与能力边界 Gemini 生成 PPT 的本质并非传统模板填充,而是基于多模态理解与结构化内容重构的端到端推理过程。其核心依赖于对用户输入(文本、大纲、…...

BetterRTX终极指南:三步免费提升Minecraft画质的完整方案
BetterRTX终极指南:三步免费提升Minecraft画质的完整方案 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX-Insta…...
)
AI原生图计算不是“加个GNN层”那么简单:SITS 2026定义的5层工程化成熟度模型(附自测清单+迁移路线图)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

别再只怪芯片了!拆解一个智能家居产品,看它的EMC静电防护设计到底哪里出了问题
智能家居静电防护失效分析:从产品拆解看EMC设计盲区 最近一位做智能门锁的创业者朋友向我吐槽:他们的旗舰产品在北方冬季频繁出现用户触摸时死机的情况,售后返修率飙升到15%。拆机检测却显示主板芯片完好,问题究竟出在哪里&#…...

Flutter Provider 状态管理完全指南
Flutter Provider 状态管理完全指南 引言 Provider 是 Flutter 中最流行的状态管理方案之一,它基于 InheritedWidget 实现,提供了简单而强大的状态管理方式。本文将深入探讨 Provider 的各种用法和高级技巧。 基础概念回顾 Provider 类型 Provider - 最基…...