redis深入理解之数据存储
1、redis为什么快
1)Redis是单线程执行,在执行时顺序执行
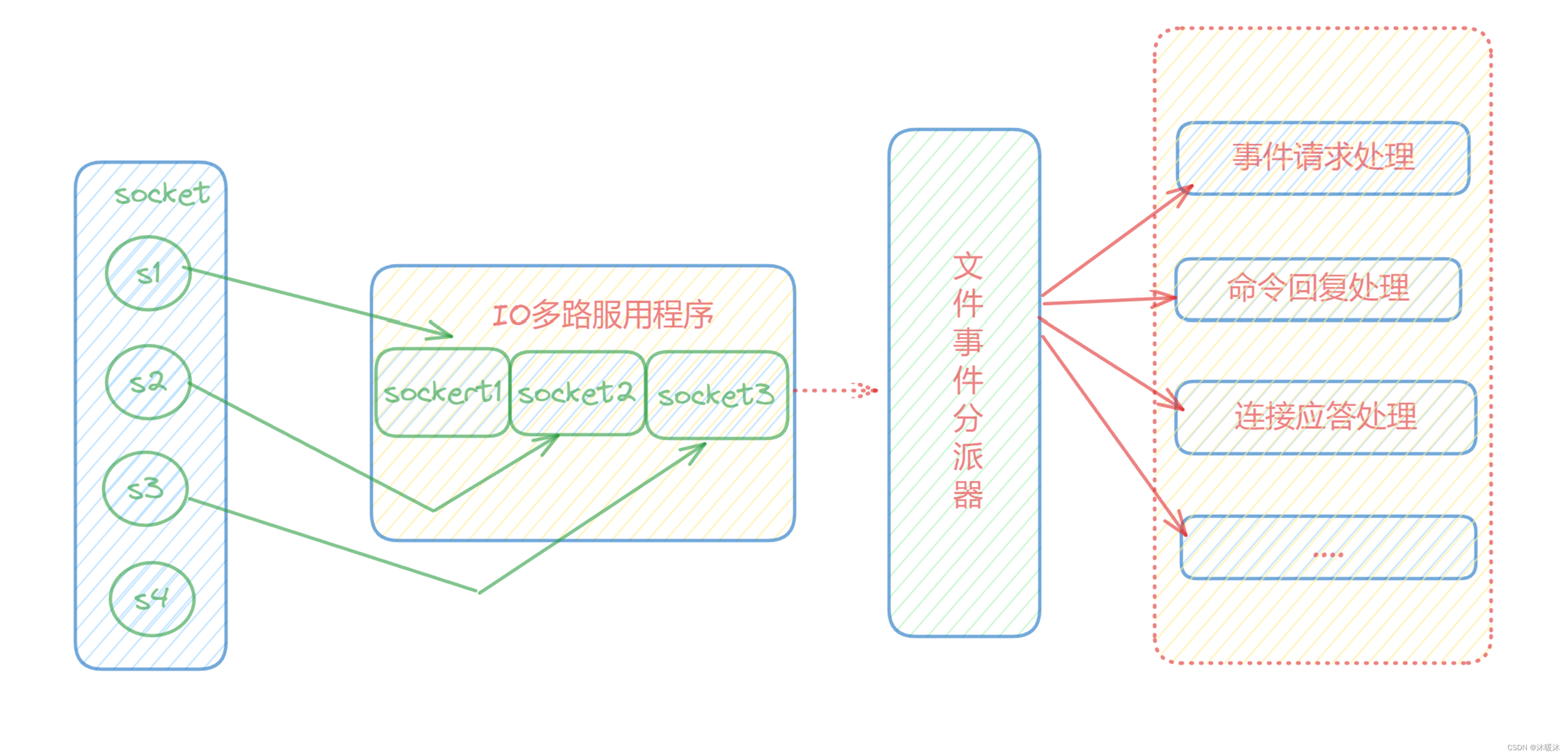
redis单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回 (socket 写)等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
2)redis的多路复用
从redis6.x开始采用io多路复用,让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
2、redis高效的数据结构
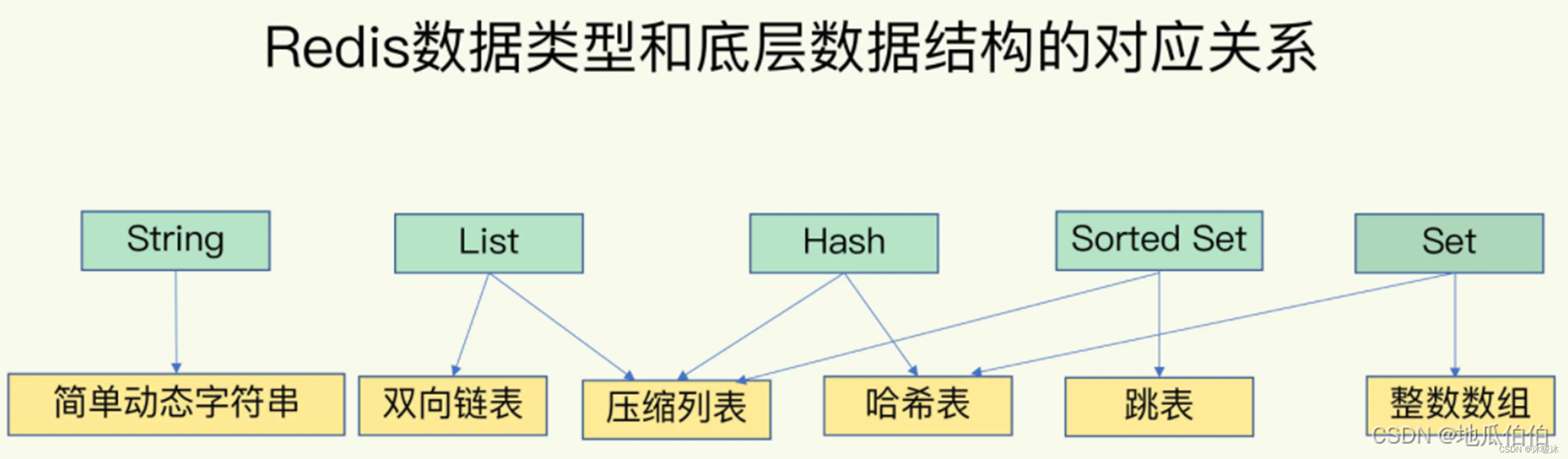
Redis支持五种主要数据结构:字符串(Strings)、列表(Lists)、哈希表(Hashes)、集合(Sets)和有序集合(SortedSets)。这些数据结构为开发者提供了灵活的数据操作方式,满足了不同场景下的数据存储需求。
• 字符串(Strings):最基本的数据类型,可以包含任何数据,如数字、字符串、二进制数据等。在Redis中,字符串是二进制安全的,这意味着它们可以有任何长度,并且不会因为包含空字符而被截断。
• 列表(Lists):简单的字符串列表,按照插入顺序排序。你可以添加一个元素到头部(左边)或者尾部(右边)。
• 哈希表(Hashes):是键值对的集合,是字符串类型的字段和值的映射表。适合存储对象。
• 集合(Sets):是字符串类型的无序集合。它是通过哈希表实现的,可以做到添加、删除、查找的时间复杂度都是O(1)。
• 有序集合(Sorted Sets):和Sets相似,但每个字符串元素都会关联一个浮点数类型的分数。元素的分数用来排序,如果两个成员有相同的分数,那么他们的排名按照字典序计算。
1)字符串的底层实现:简单动态字符串(SDS)

优势
预分配:SDS会为buf分配额外的未使用空间(通过free字段记录),这意味着当你向一个SDS字符串追加内容时,如果未使用空间足够,Redis就不需要重新分配内存。这减少了内存分配次数,从而提高了性能。
常数时间复杂度获取字符串长度:由于SDS结构内部维护了一个len字段来记录字符串的当前长度,获取字符串长度的操作可以在常数时间复杂度O(1)内完成,而不需要像C语言的原生字符串那样遍历整个字符串。
二进制安全:SDS可以存储任意二进制数据,包括空字符\0。C语言的原生字符串以空字符作为结束标志,这限制了它们不能包含空字符。而SDS则通过len字段来明确字符串的长度,因此不受此限制。
兼容C语言字符串函数:尽管SDS提供了自己的一套API来进行字符串操作,但它的buf字段实际上就是一个普通的C字符串(以\0结尾),这意味着在必要时,可以直接使用标准的C语言字符串处理函数来操作buf字段(尽管通常不推荐这样做,因为可能会破坏SDS结构的完整性)。
2)列表的底层实现:双向链表与压缩列表
双向链表
当列表的元素数量较多或者元素较大时,Redis会选择使用双向链表作为底层实现。双向链表中的每个节点都保存了前一个节点和后一个节点的指针,这使得在列表的任何位置插入或删除元素都变得相对容易。


优势
可以在O(1)时间复杂度内完成在列表头部或尾部的元素插入和删除。 当需要遍历列表时,可以从头部或尾部开始,沿着节点的指针依次访问。
压缩列表
当列表的元素数量较少且元素较小时,Redis会使用压缩列表(ziplist)作为底层实现来节省内存。压缩列表是一个紧凑的、连续的内存块,它按顺序存储了列表中的元素。
ZLBYTE: 压缩列表的头部信息,包含了特殊编码和压缩列表的长度信息。
LEN: 每个元素前的长度字段,用于记录该元素的长度或前一个元素到当前元素的偏移量。
‘one’, ‘two’: 实际的列表元素,它们被连续地存储在压缩列表中。
优势
内存利用率高,因为元素是连续存储的,没有额外的指针开销。
对于小列表,操作速度可以很快,因为所有数据都在一个连续的内存块中。
3)哈希的底层实现:Redis中的字典与压缩列表
Redis的哈希(Hashes)类型允许用户在单个键中存储多个字段和对应的值。为了高效地支持这种数据结构,Redis在底层使用了两种主要的数据结构来实现哈希:字典(也称为哈希表)和压缩列表。
字典(HASH表)
当哈希中的字段和值较多或者较大时,Redis会选择使用字典作为底层实现。字典是一种通过键(在Redis哈希中是字段)来直接访问值的数据结构,它能够在平均情况下提供O(1)时间复杂度的查找、插入和删除操作。


优势
提供了快速的字段查找、插入和删除操作。
哈希表的扩容机制可以保持较低的哈希冲突率,从而保证操作的效率。
压缩列表
当哈希中的字段和值较少且较小时,Redis会使用压缩列表作为底层实现来节省内存。压缩列表是一种紧凑的、连续的内存块,它按顺序存储了哈希中的字段和值对

优势
• 内存利用率高,因为字段和值是连续存储的,没有额外的指针和元数据开销。
• 对于小哈希,操作速度可以很快,因为所有数据都在一个连续的内存块中。
4)集合的底层实现:整数集合和字典
Redis的集合(Sets)是一个无序的、元素不重复的集合。为了高效地支持这种数据结构及其操作,Redis在底层使用了两种主要的数据结构:整数集合(intset)和字典(hashtable)。
整数集合(int set)
当集合中的元素都是整数,并且元素数量较少时,Redis会选择使用整数集合作为底层实现。整数集合是一个紧凑的数组,数组中的每个元素都是集合中的一个整数。
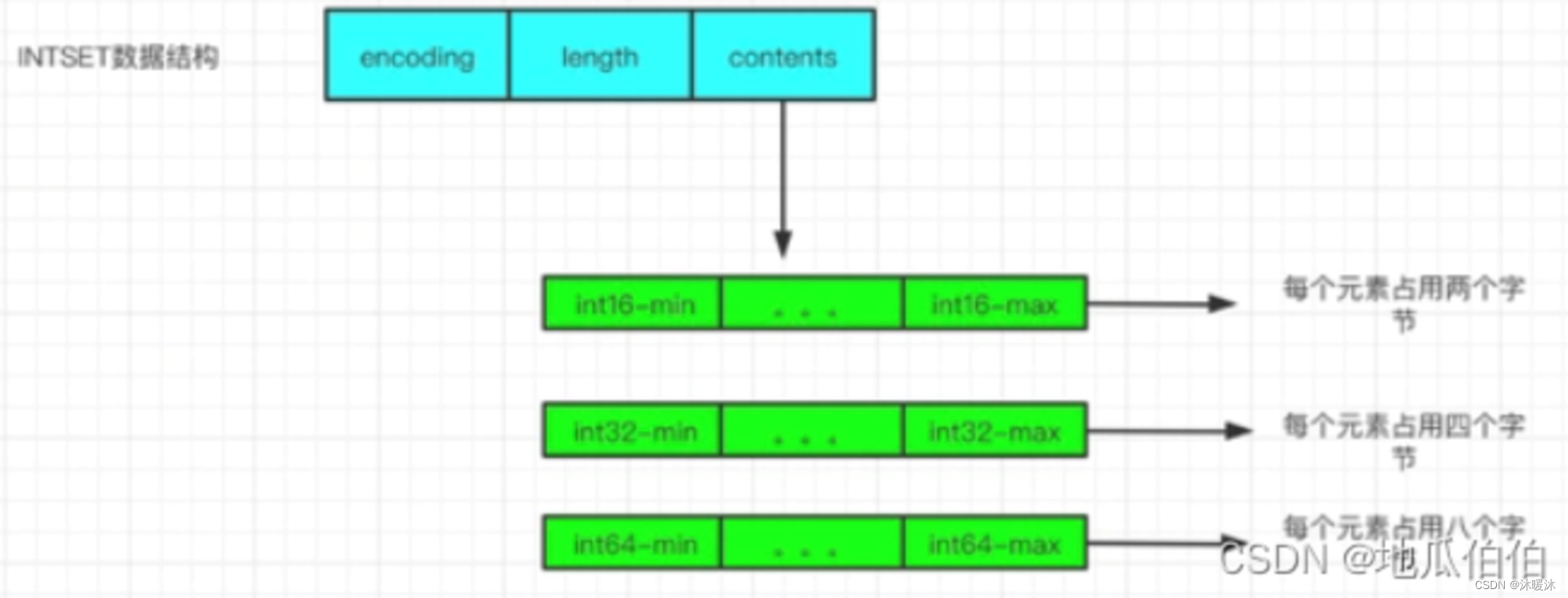
优势
• 内存利用率高:整数集合将整数紧密地存储在一个连续的内存块中,没有额外的指针或元数据开销。
• 操作速度快:对于整数集合中的元素,Redis可以直接通过数组索引访问,这使得查找、添加和删除整数的操作非常快速。 然而,整数集合也有其局限性。由于它要求集合中的元素必须是整数,并且元素数量较少,因此在处理非整数元素或大量元素时,整数集合可能不是最优的选择
5)有序集合的底层实现:跳表和压缩列表
Redis的有序集合(SortedSets)是一个有序的、元素不重复的集合,其中每个元素都关联了一个分数(score)。为了实现这种数据结构及其相关操作的高效性,Redis在底层主要使用了两种数据结构:压缩列表(ziplist)和跳表(skiplist)。
跳表(skiplist)
当有序集合的元素数量较多或元素的大小较大时,Redis会使用跳表作为底层实现。跳表是一种多层的有序链表,它通过维护多个层次的指针来加快查找、插入和删除操作的速度。

优势
• 查找效率高:通过维护多个层次的指针,跳表可以在平均情况下提供O(log N)时间复杂度的查找操作,其中N是元素的数量。
• 插入和删除操作快速:跳表的插入和删除操作只需要局部地调整指针,而不需要移动大量的数据。
• 支持范围查询:跳表可以方便地支持按照分数范围查询元素的操作
3、redis的持久化机制
Redis是一个基于内存的数据库,它的数据是存放在内存中,内存有个问题就是关闭服务或者断电会丢失。Redis的数据也支持写到硬盘中,这个过程就叫做持久化。
Redis提供如下2中持久化方式
RDB(Redis DataBase) :在指定的时间间隔内,定时的将 redis 存储的数据生成Snapshot快照并存储到磁盘等介质上;Redis默认开启了rdb存储。
AOF(Append Of File) :将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
AOF+RDB : RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高
3.1 RDB
RDB概述
RedisDatabase Backup file(Redis数据备份文件),也被叫作Redis数据快照。简单的来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件(二进制文件),恢复数据。快照文件称为RDB文件。
我们知道 Redis 是单线程程序,这个线程要同时负责多个客户端套接字的并发读写操作和内存数据结构的逻辑读写。
在服务线上请求的同时,Redis 还需要进行内存快照,内存快照要求 Redis 必须进行文件 IO 操作,这意味着单线程同时在服务线上的请求还要进行文件 IO 操作,文件 IO 操作会严重拖垮服务器请求的性能。还有个重要的问题是为了不阻塞线上的业务,就需要边持久化边响应客户端请求。

- 相关命令:
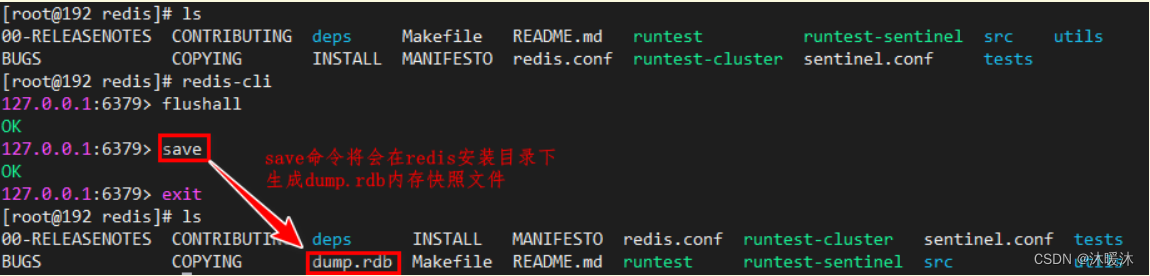
- save命令
- 作用:该命令将在redis安装目录中创建dump.rdb文件。
- 特点:该命令将立即执行持久化操作,同时会造成线程阻塞。
- 示例:
- bgsave命令
- 作用:将内存快照写入dump.rdb文件,完成持久化。
- 特点:该命令则会在台后异步执行持久化操作,不会造成线程阻塞,但不保证立即执行持久化。
- 策略执行时机:
- 当前已知的执行时机有:执行flushall命令后、正常关闭redis时,执行save、bgsave命令。
- 使用该策略里恢复数据
- redis启动时,会读取dump.rdb。当我们使用RDB模式时恢复数据,只需要将dump.rdb备份文件拷贝到redis启动目录,启动redis即可。
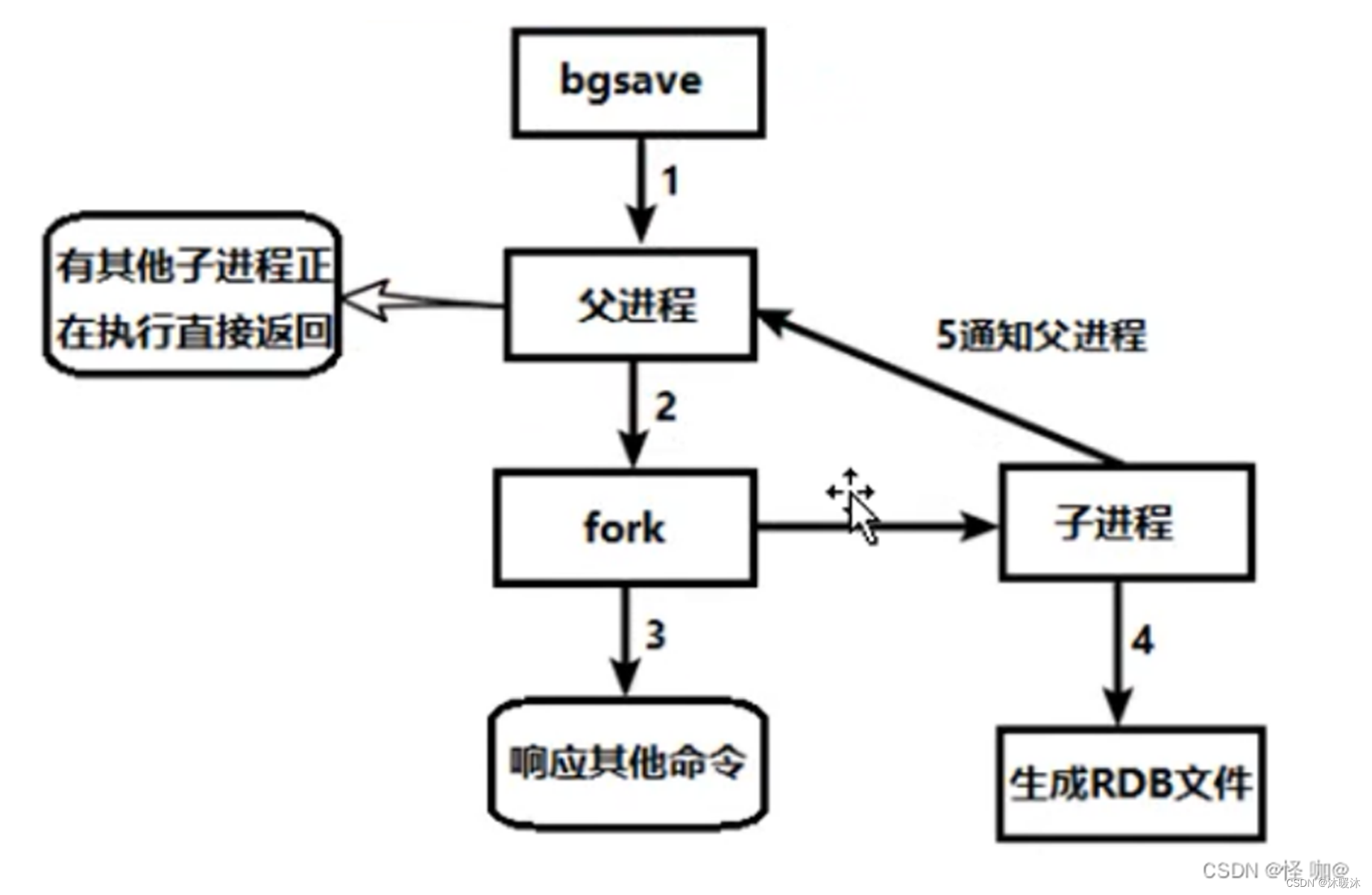
如果当redis子线程持久化的数据正常被父线程再修改的时候怎么办
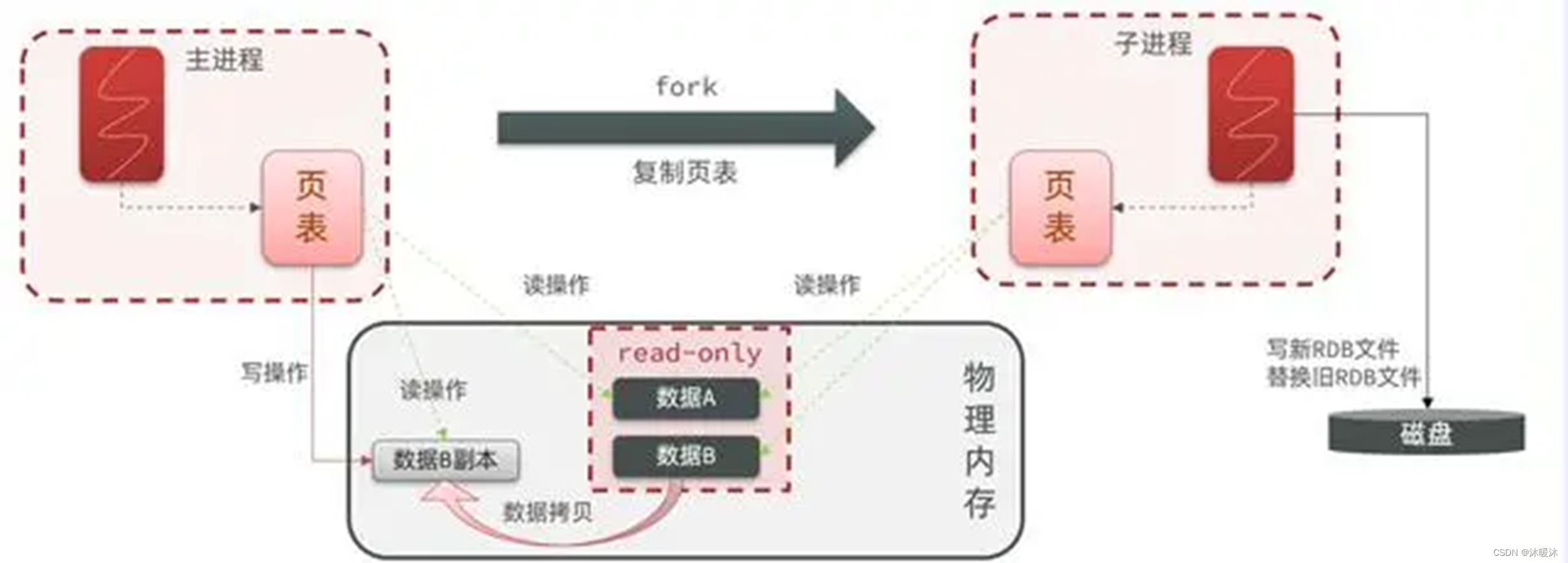
在Redis中,当子进程正在执行RDB持久化(即将内存中的数据写入磁盘的临时文件)时,如果父进程(即主线程)同时修改了内存中的数据,Linux操作系统的写时复制(Copy-On-Write, COW)机制会确保数据的一致性和完整性。
具体来说,当父进程修改内存中的某个页面时,由于子进程和父进程共享这些内存页面,Linux内核会为这个页面创建一个副本,并将修改应用到这个副本上,而不是直接修改原始的共享页面。这样,子进程在遍历和写入RDB文件时,它读取的是修改前的数据快照,而父进程可以继续处理客户端的请求并修改内存中的数据,两者互不影响。
一旦子进程完成了RDB文件的写入,它会用这个临时文件替换旧的RDB文件,从而完成了整个持久化过程。在这个过程中,由于写时复制机制的存在,父进程的修改不会影响到子进程正在写入的RDB文件的数据一致性。
需要注意的是,虽然RDB持久化可以确保数据的可靠性和持久性,但在Redis宕机或故障恢复时,可能会丢失最后一次RDB持久化之后的数据修改。因此,对于需要更高数据可靠性和一致性的应用,Redis还提供了另一种持久化方式——AOF(Append Only File),它可以将每一个写命令都追加到AOF文件中,从而在Redis重启时可以通过重新执行这些命令来恢复数据。
COPY-ON-WRITE(写时复制,cow)
Linux操作系统中fork()机制的一个重要特性——写时复制
概括Redis在使用快照(RDB)持久化时,如何通过fork()系统调用来创建一个子进程,并且这个子进程与父进程共享内存中的代码段和数据段
Redis在持久化时会调用 glibc 的函数 fork产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时你可以将父子进程想像成一个连体婴儿,共享身体。这是Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享起来。在进程分离的一瞬间,内存的增长几乎没有明显变化。
RDB优缺点
RDB 的优点
体积更小:相同的数据量 RDB 数据比 AOF 的小,因为 RDB 是紧凑型文件。
恢复更快:因为 RDB 是数据的快照,基本上就是数据的复制,不用重新读取再写入内存。
性能更高:父进程在保存 RDB 时候只需要fork一个子进程,无需父进程的进行其他io操作,也保证了服务器的性能。
RDB 的缺点
故障丢失:因为 RDB是全量的,我们一般是使用shell脚本实现30分钟或者1小时或者每天对 Redis 进行 RDB 备份,(注,也可以是用自带的策略),但是最少也要5分钟进行一次的备份,所以当服务死掉后,最少也要丢失5分钟的数据。
耐久性差:相对 AOF 的异步策略来说,因为 RDB 的复制是全量的,即使是 fork的子进程来进行备份,当数据量很大的时候对磁盘的消耗也是不可忽视的,尤其在访问量很高的时候,主线程 fork的时间也会延长,导致 cpu 吃紧,耐久性相对较差。
3.2 AOF
AOF概述
以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到回复数据的目的。AOF的主要作用是解决了数据持久化的实时性。
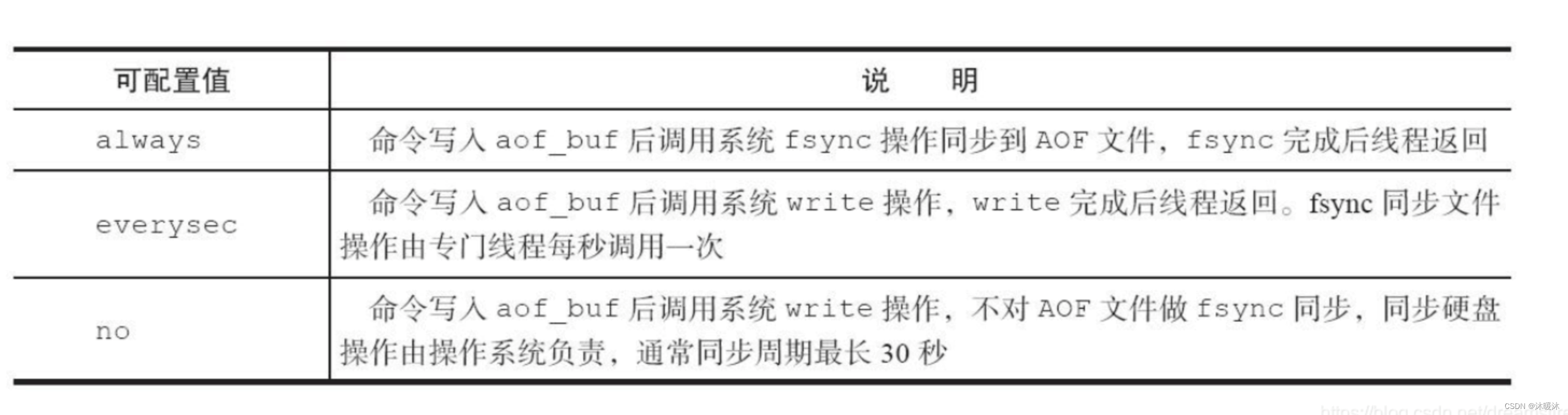
系统调用write和fsync说明:
Write操作会触发延迟写机制。Linux在内核提供页缓冲区用来提高硬盘IO性能。wirte操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制。例如:缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
fync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync将阻塞直到写入硬盘完成后返回,保证了数据持久化
AOF追加阻塞
当开启AOF持久化时,常用的同步硬盘的策略是everysec,用于平衡性能和数据安全性。对于这种方式,Redis使用另一条线程每秒执行fsync同步硬盘。当系统硬盘资源繁忙时,会造成Redis主线程阻塞
阻塞流程分析
1)主线程负责写入AOF缓冲区
2)AOF线程负责每秒执行一次同步磁盘操作,并记录最近一次同步时间
3)主线程负责对比上次AOF同步时间
如果距上次同步成功时间在2秒内,主线程直接返回。
如果距上次同步成功时间超过2秒,主线程将会阻塞,直到同步操作完成
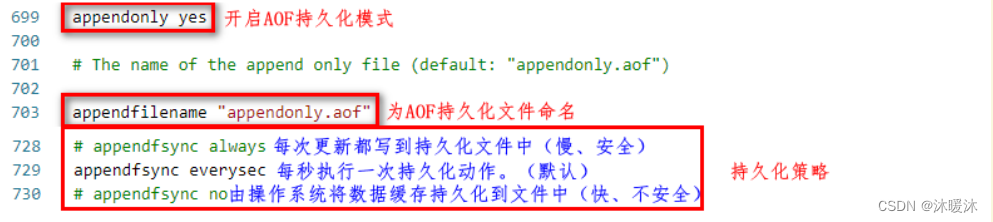
开启AOF功能需要设置配置: appendonly yes,默认不开启。AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同RDB持久化方式一致,通过dir配置指定。

- 使用该策略恢复redis
- 只需要将持久化文件copy到redis的启动目录,重启redis即可。
AOF重写
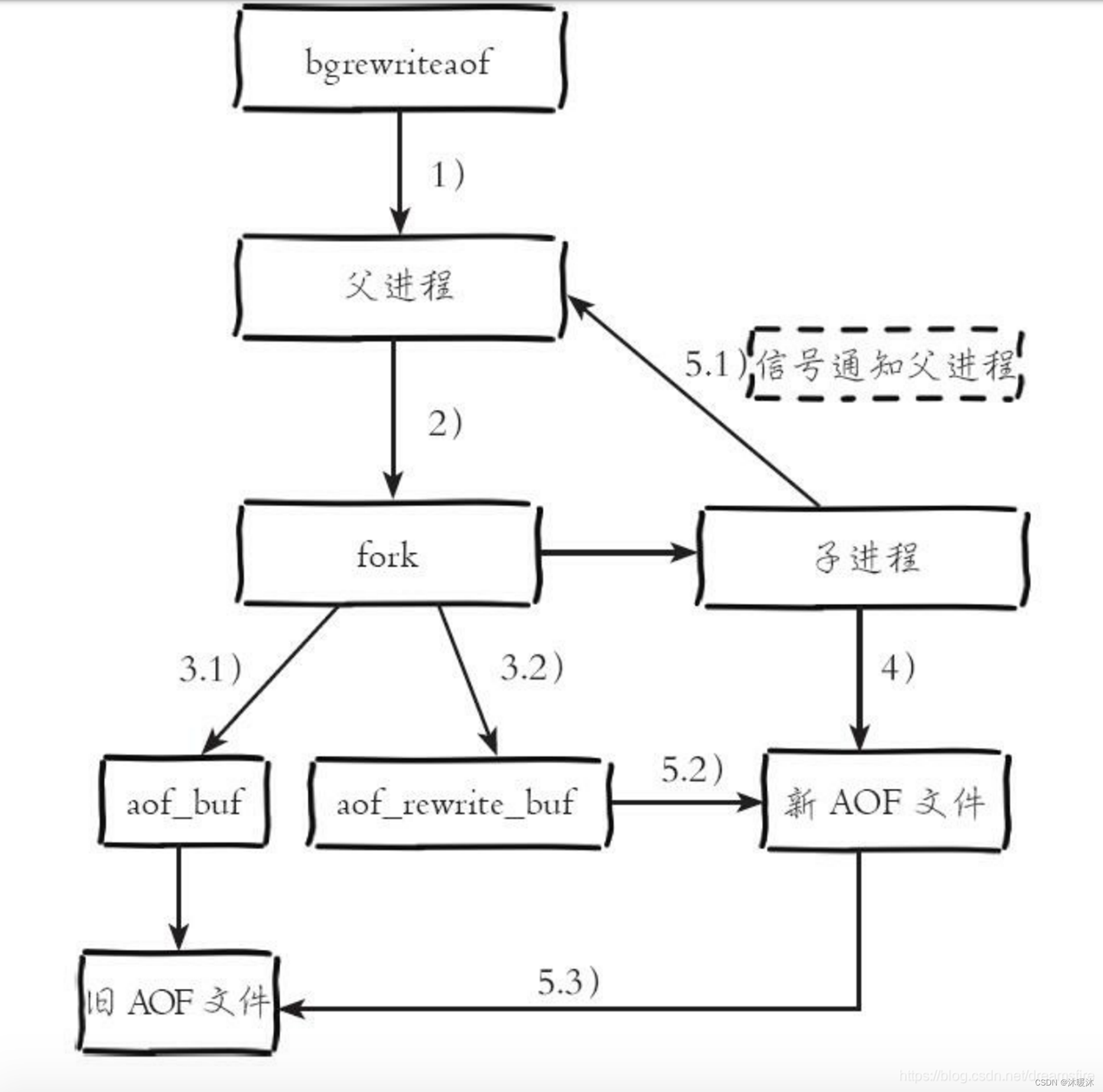
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,redis引入了AOF重写机制压缩文件体积。
AOF重写是基于什么进行重写的?
AOF(Append Only File)重写是基于Redis进程内的当前数据状态进行重写的。AOF重写的目的是压缩AOF文件的大小,提高Redis的性能,并清除AOF文件中的无用命令,减少冗余。
AOF重写的原理大致如下:
- 开启子进程:Redis会启动一个子进程来执行AOF重写操作。这个子进程会遍历Redis的所有键值对,并将其转化为一条条写命令。
- 写入临时文件:子进程将这些写命令写入到一个新的临时文件中,而不是直接修改原来的AOF文件。这个临时文件只包含当前有效和存在的数据的写入命令,而不是历史上所有的写入命令。
- 处理新写操作:在子进程进行AOF重写的过程中,主进程(父进程)会继续接收和处理客户端的请求。如果有新的写操作发生,主进程会将这些写操作追加到一个缓冲区中,并通过管道通知子进程。
- 合并新写操作:子进程在完成AOF重写后,会将缓冲区中的新写操作也追加到临时文件中。这一步是为了确保在AOF重写过程中发生的所有写操作都不会被遗漏。
- 替换AOF文件:子进程向主进程发送信号,通知主进程可以切换到新的AOF文件了。主进程在收到子进程的信号后,会用临时文件替换旧的AOF文件,并关闭旧的AOF文件。此时,AOF重写操作完成,Redis会开始使用新的AOF文件进行持久化。
AOF重写流程
AOF优缺点
AOF 的优点
数据保证:我们可以设置fsync策略,一般默认是 Everysec,也可以设置每次写入追加,所以即使服务死掉了,也最多丢失一秒数据
自动缩小:当 AOF 文件大小到达一定程度的时候,后台会自动的去执行 AOF 重写,此过程不会影响主进程,重写完成后,新的写入将会写到新的 AOF 中,旧的就会被删除掉。但是此条如果拿出来对比 RDB 的话还是没有必要算成优点,只是官网显示成优点而已。
AOF 的缺点
性能相对较差:它的操作模式决定了它会对Redis 的性能有所损耗。(主线程写文档)
体积相对更大:尽管是将 AOF 文件重写了,但是毕竟是操作过程和操作结果仍然有很大的差别,体积也毋庸置疑的更大。
恢复速度更慢:因为要重新加载每条命令的执行,恢复速度比较慢
3.3 持久化模式选择
- 根据业务需求选择。
- 需求一:允许少量数据丢失,则首选RDB模式。
- 需求二:不允许数据丢失,则首选AOF模式。
- 企业的选择:实现redis主从模式
- 主机:采用RDB模式
- 从机:采用AOF模式
3.4 问题总结
①RDB和AOF分别存储的是什么
1.RDB(Redis DataBase):
- RDB存储的是Redis在某个时间点的数据快照。具体来说,它保存了Redis在持久化时内存中的数据库状态。
- RDB文件是一个经过压缩的二进制文件,它包含了Redis中所有键值对的数据,并且是以一种紧凑的方式存储的。
- RDB的持久化过程是通过fork一个子进程来完成的,子进程会遍历Redis的内存数据,并将其写入到磁盘上的RDB文件中。这个过程中,父进程(即主进程)可以继续处理客户端的请求。
- RDB的优点是生成的文件体积较小,恢复速度快。但缺点是可能会丢失最后一次RDB持久化之后的数据修改。
2.AOF(Append Only File):
- AOF存储的是Redis服务器所执行的每一个写操作命令(如SET、DEL等),这些命令以文本的形式追加到AOF文件中。
- 与RDB不同,AOF文件是一个持续增长的文本文件,它记录了Redis从启动到当前时刻的所有写操作。
- AOF的持久化过程是通过将每一个写命令追加到AOF文件末尾来完成的。Redis在接收到写命令后,会先将命令写入到AOF缓冲区,然后再根据配置的AOF同步策略将缓冲区的内容同步到磁盘上的AOF文件中。
- AOF的优点是提供了更高的数据可靠性,因为它记录了所有的写操作。在Redis重启时,可以通过重新执行AOF文件中的命令来恢复数据。但缺点是AOF文件通常比RDB文件大,并且恢复速度相对较慢。
②COW(写时复制)还在哪些场景用到了?
1.文件系统:
- 一些文件系统,如Btrfs和ZFS,使用了COW技术来优化数据修改。当文件被修改时,文件系统不会立即覆盖原始数据,而是创建一个数据的副本,并在副本上进行修改。这样,多个进程或用户可以同时读取原始数据,而不会受到写操作的影响。
2.虚拟内存管理:
- 在操作系统中,虚拟内存管理经常使用COW技术来处理进程的内存页。当父进程创建子进程时,子进程会继承父进程的内存页,但这些内存页最初是共享的(即使用COW)。只有当某个进程尝试修改其内存页时,操作系统才会为该进程创建一个该页面的副本,并在副本上进行修改。
3.编程语言:
- 在一些编程语言中,COW技术被用于优化字符串和集合等数据结构。例如,在Java的String类中,由于字符串是不可变的(immutable),每次对字符串进行修改(如拼接、替换等)时,都会创建一个新的字符串对象。然而,为了优化性能,Java的某些实现可能会使用COW技术来延迟或避免不必要的字符串复制。
4.数据库:
- 在数据库系统中,COW技术可以用于实现多版本并发控制(MVCC)。MVCC允许多个事务同时读取同一份数据,并通过为每个事务提供数据的快照来实现并发控制。当某个事务尝试修改数据时,数据库系统可以使用COW技术为该事务创建一个数据的副本,并在副本上进行修改,从而避免与其他事务发生冲突。
5.容器技术:
- 在容器技术(如Docker)中,COW技术被用于实现容器的轻量级和快速启动。当创建一个新的容器时,容器管理器会基于一个已有的镜像(即基础文件系统)来创建容器的文件系统。由于容器和镜像之间使用了COW技术,因此容器在启动时只需要复制和修改与镜像不同的部分,从而实现了快速启动和轻量级的特性。
6.分布式系统:
- 在分布式系统中,COW技术可以用于实现数据复制和一致性。当多个节点需要共享数据时,可以使用COW技术来确保每个节点在读取数据时都看到相同的数据版本。当某个节点需要修改数据时,可以使用COW技术为该节点创建一个数据的副本,并在副本上进行修改。这样,其他节点可以继续读取原始数据,而不会受到写操作的影响。同时,通过一定的同步机制(如分布式锁、Raft等),可以确保所有节点最终都能看到一致的数据版本。
③哪种持久化方式丢失数据的风险最小
在Redis的持久化机制中,AOF(Append Only File)通常被认为丢失数据的风险最小,原因如下:
- 记录所有写操作:AOF持久化方式会记录Redis服务器所执行的每一个写操作命令,并将其追加到AOF文件中。这意味着即使发生宕机或异常,也可以通过重新执行AOF文件中的命令来恢复数据。
- 灵活性:AOF文件是一个文本文件,易于理解和处理。此外,Redis提供了多种AOF重写策略(如always、everysec和no),允许用户根据实际需求选择数据持久化的频率和性能之间的平衡。
- 数据完整性:由于AOF记录了所有的写操作,因此在恢复数据时,可以保证数据的完整性和一致性。即使在写操作过程中出现错误或异常,也可以通过AOF文件恢复到正确的状态。
- 持久性保证:AOF持久化方式提供了较高的持久性保证。在配置为always模式时,Redis会在每个写操作后都同步AOF文件,确保数据的实时持久化。而在everysec模式下,Redis会每秒同步一次AOF文件,提供了较好的性能和持久性之间的平衡。
然而,需要注意的是,虽然AOF丢失数据的风险较小,但AOF文件通常比RDB文件大,且恢复速度相对较慢。因此,在选择持久化方式时,需要根据实际需求和场景进行权衡和选择。如果对数据持久性的要求非常高,且可以接受较慢的恢复速度,则可以选择AOF持久化方式;如果对数据持久性的要求相对较低,且需要较快的恢复速度,则可以选择RDB持久化方式。
4、redis的内存优化策略
1.redis使用中可能存在的隐患
- 缓存穿透
- 产生原因:在高并发环境下访问数据库和缓存中都不存在的数据的现象。
- 解决方案:
- 禁用IP。
- 限流。
- 布隆过滤器。
- 缓存击穿
- 产生原因:某热点数据在缓存中突然失效,导致大量的用户直接访问数据库;而数据库无法抵抗并发压力而造成数据库服务器宕机或其它异常。
- 解决方案:
- 尽快可能将热点数据的超时时间设定的长一点。
- 设定多级缓存,并选择合适的内存优化策略。
- 缓存雪崩
- 产生原因:在缓存服务器中,由于大量的缓存数据失效,导致用户访问的命中率过低,导致大量用户直接访问数据库。
- 能够产生雪崩的操作
- flushall命令
- 解决方案:
- 设定超时时间时,应该采用随机算法
- 采用多级缓存。
2.内存优化策略作用
- 由于内存资源相对较少,而redis中的数据中保存在内存中,如果数据库的数据庞大时,则无法全部存在内存中。因此,需要确保redis缓冲中的数据是使用次数最多的数据。
- redis内存优化策略即是通过数据载入算法,使redis中的数据是使用最多数据,从而减少对数据库的访问。
3.redis内存优化策略
- LRU算法:最近最少使用算法
- 算法策略:将最近最久未使用的页面予以淘汰。
- 实现方式:
- 该算法赋予每个页面一个访问字段,用来记录一个页面上次被访问以来所经历的时间t。当须淘汰一个页面时,选择现有页面中t值最大的,即最近最少使用的页面予以淘汰。
- 淘汰标准:时间t
- LFU算法:最不经常使用算法。
- 算法策略:将使用次数最少的页面予以淘汰。
- 实现方式:
- 该算赋于每个页面一个访问字段,用来记录一个页面被访问的次数,在引用计数器定时右移一位,形成指数衰减后的平均次数。将平均次数最小的予以淘汰。
- 淘汰标准:平均使用次数。
- Random算法:随机淘汰算法。
- TTL算法:根据剩余的存活时间,排序,根据生存时间多少来淘汰数据。
4.redis的内存优化策略的设置
- 设置方式:修改redis.conf配置文件。

- 参数:
- 前缀:
- volatile-:在设定超时时间的数据中。
- allkeys-:在所有数据中。
- 参数实体:
- lru:LRU算法。
- lfu:LFU算法。
- random:RANDOM算法。
- ttl:TTL算法。(此参数只能使用于volatile-前缀中。)
- 无前缀参数
- noeviction:默认规则。如果内存满了,则不做任何操作,直接报错返回。
- 前缀:
5、redis的架构模式
Redis支持三种集群模式,分别为主从模式、哨兵模式和集群(Cluster)模式。
最初,Redis采用主从模式构建集群。在这种模式下,如果主节点(master)出现故障,需要手动将从节点(slave)转换为主节点。然而,这种模式在故障恢复方面效率不高。
为了提高系统的可用性,Redis引入了哨兵模式。在哨兵模式中,一个哨兵集群负责监控主节点和从节点。如果检测到主节点故障,系统可以自动将从节点晋升为新的主节点。这提高了故障恢复的自动化程度。
尽管如此,哨兵模式仍然面临内存容量和写入性能的限制,因为这种模式的写入能力仍然局限于单个节点。为了解决这一问题,Redis在3.x版本之后推出了Cluster集群模式。Cluster模式通过数据分片和节点的水平扩展,实现了更高效的内存利用和写入性能。
5.1 redis的主从架构模式
1)redis的主从架构
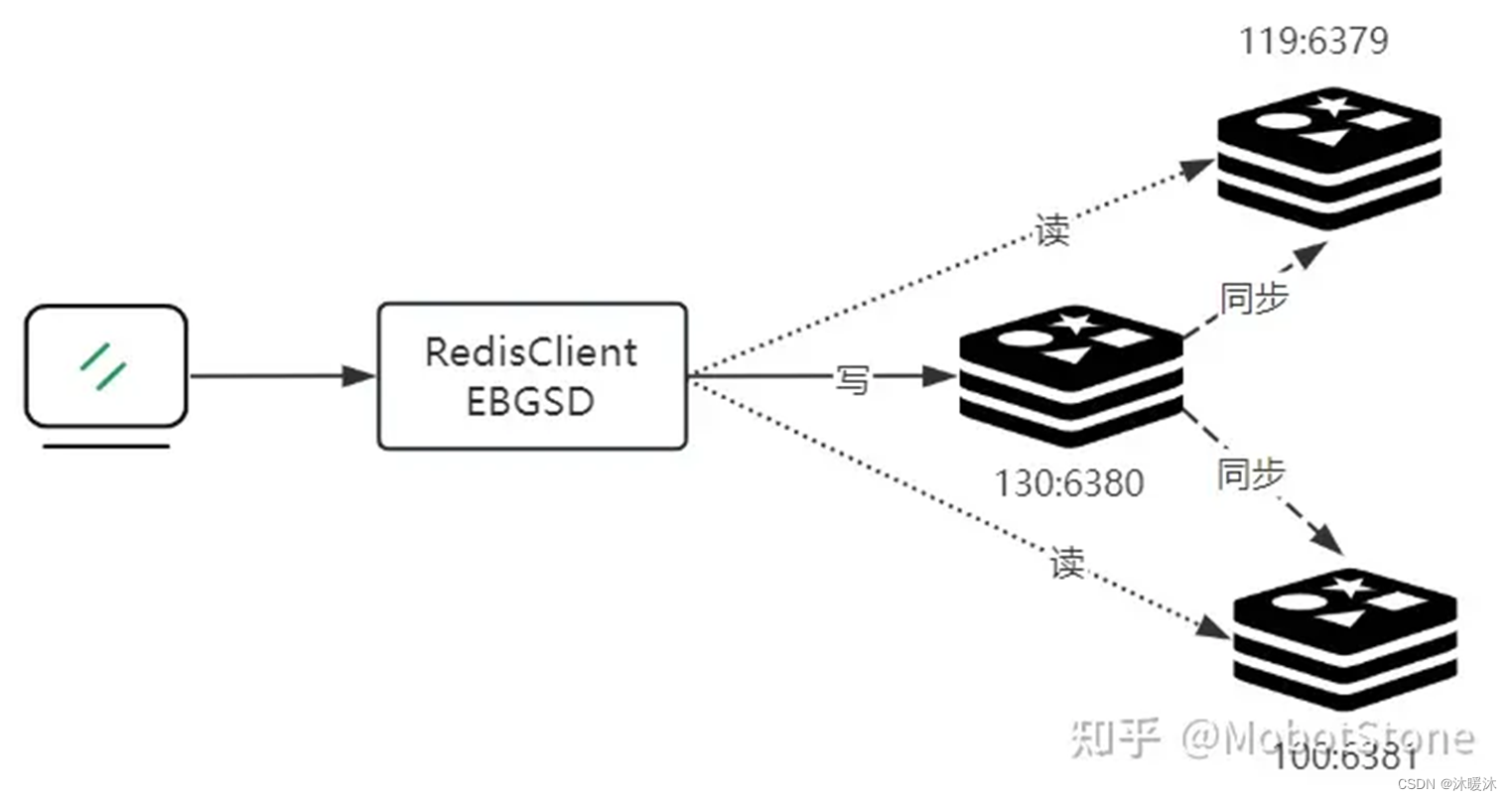
在Redis的主从复制架构中,系统通过定义主库(master)和从库(slave)的角色,实现数据的高效同步和备份。这一架构具体包含以下特点:
•master的读写能力:master是系统中的数据中心,它不仅承担全部的写操作,还能处理读请求。当在master上执行任何改变数据的操作时,这些更改会自动且实时地同步到所有slave。
•单向数据流:数据同步流是单向的,意味着数据只从master流向slave,确保了数据同步的一致性和可靠性。
•slave的只读特性:slave通常被配置为只读模式,它们接收并存储从master传来的数据。这样设计主要是为了分散读取压力,从而提高系统的整体读取性能。
•主slave的对应关系:一个master可以对应多个slave,形成一对多的关系。这种结构利于数据的冗余备份和读取负载的分散。相反,一个slave只能对应一个master,以保持数据同步的一致性。
•slave的容错性:如果某个slave出现故障,它对系统其他部分的影响是最小的。即便在slave宕机的情况下,其它slave仍能继续提供读服务,master也能保持正常的读写操作。当故障的slave恢复后,它会自动从master同步缺失的数据。
•master故障的影响:master的故障会导致Redis暂时无法处理新的写请求,但已连接的slave可以继续提供读服务。一旦master恢复,Redis会重新提供完整的读写服务。
•master故障的应对机制:在当前的master发生故障时,系统不会自动在slave中选择一个新的master。这需要通过额外的高可用性解决方案来实现,例如使用Redis
Sentinel或Redis Cluster来管理master的选举和故障转移。
2)redis的主从同步原理
Redis的主从同步(Replication)原理主要包括以下几个关键步骤和机制:
1.建立连接:
- 当配置一个Redis实例(Slave)为另一个实例(Master)的从服务器时,Slave会尝试与Master建立连接。
- 一旦连接建立成功,Slave会成为Master的一个客户端,并且这个连接是持久的,即使因为网络问题断开,Slave也会尝试重新连接。
2.数据同步:
- 当Slave第一次连接Master或者与Master的连接断开后重新连接时,Slave会向Master发送一个SYNC命令(在Redis 2.8及以后的版本中,这个命令被替换为PSYNC)。
- 对于第一次同步或全量同步(Full Synchronization),Master会执行一个BGSAVE命令来在后台异步生成一个RDB(Redis DataBase)持久化快照文件,同时收集所有在BGSAVE执行期间接收到的写命令,并缓存这些命令。
- 当BGSAVE完成后,Master会发送RDB文件给Slave,Slave会加载这个RDB文件到内存中,从而完成数据的全量同步。
- 在发送RDB文件的同时或之后,Master会把缓存的写命令发送给Slave,Slave会执行这些命令,完成增量同步(Partial Synchronization),使得Slave的数据状态与Master保持一致。
3.命令传播:
- 在完成初始的数据同步后,Master会将其接收到的写命令发送给Slave,Slave会执行这些命令,从而保持与Master的数据同步。
- 这种机制基于长连接,Master和Slave之间的连接在数据同步完成后会保持打开状态,以便进行后续的命令传播。
4.心跳检测:
- Slave会定期向Master发送心跳(Ping)命令,以检查Master是否仍然在线和可访问。
- 如果Slave在一定时间内没有收到Master的响应,它会认为Master可能已经宕机,然后尝试重新连接Master或进行故障转移(Failover)。
5.故障转移:
- 在Redis的主从架构中,通常还会配置一个或多个Sentinel(哨兵)实例来监控Master和Slave的状态。
- 如果Sentinel检测到Master宕机,它会从剩余的Slave中选择一个作为新的Master,并通知其他Slave和客户端进行更新。
①全量同步
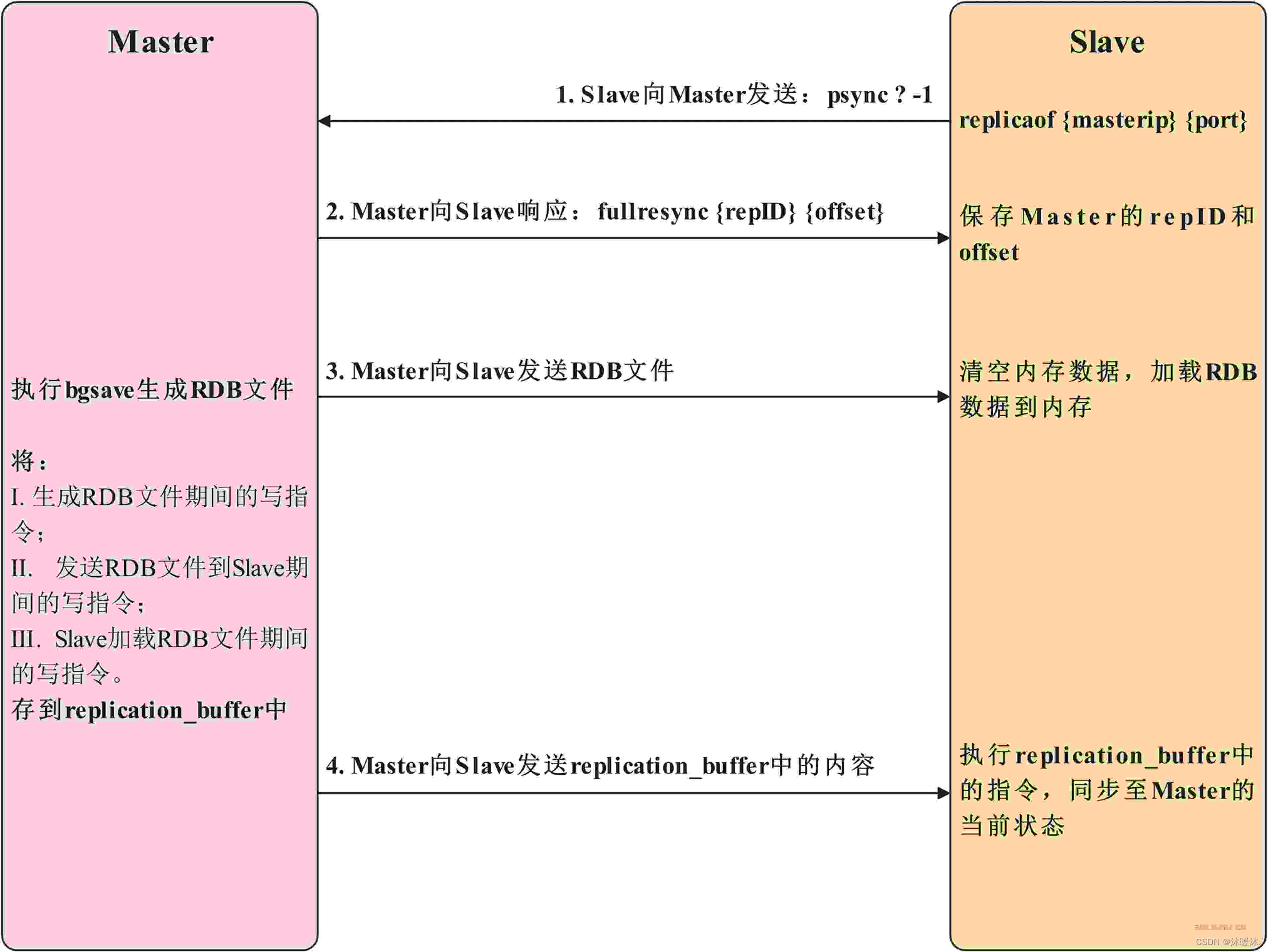
从节点通过配置文件中的replicaof {masterip} {port} 获得主节点ip和port,然后向主节点发送psync {repID} {offset} 指令,其中repID表示主节点唯一标识,offset为复制偏移量,因为当前从节点与主节点尚未连接,且尚未开始复制,所以repID为 ?,offset为-1;
主节点收到psync {repID} {offset} 指令后,会响应从节点并发送fullresync {repID} {offset} 指令,从节点会将主节点的repID和offset保存下来;
主节点收到psync {repID} {offset} 指令后,会执行bgsave异步的生成RDB文件,然后主节点将RDB文件发送给从节点,从节点接收到RDB文件后,会清空内存数据,然后加载RDB文件的数据到内存中;
由于主节点生成RDB文件时是异步生成的,此时主节点是非阻塞的,可以继续处理业务,所以在生成RDB文件期间,发送RDB文件期间和从节点加载RDB文件期间主节点执行的写指令均会存放到缓冲区replication_buffer中,所以当从节点加载完RDB文件后,主节点会将replication_buffer中的内容发送给从节点,从节点会执行replication_buffer中的指令,从而达到和主节点一致的状态。
②增量同步
主节点和从节点如果因为某些原因,断开了连接,而断开连接这段时间里主节点又处理了一些写指令,那么从节点重新连接后,应该怎么将断开连接那段时间里的写指令同步给重连的从节点?通常的想法就是再执行一次全量同步,在2.8之前的版本,确实是这么实现的,但从2.8版本开始,引入了增量同步
具体的实现如下:
主节点维护着一份repl_backlog_buffer缓冲区域,叫做复制积压缓冲区,主节点在任何时候执行写指令时,都会将写指令记录在repl_backlog_buffer中,repl_backlog_buffer是一个环形数组,所以当数组满时,后续再添加的写指令会覆盖旧的写指令,因此主节点还使用了一个叫做master_repl_offset的偏移量,来记录主节点的存到repl_backlog_buffer中的最新写指令的位置,master_repl_offset就是上面提到的offset,只不过在主节点中叫做master_repl_offset;
从节点也有一个偏移量叫做slave_repl_offset,用来记录从节点已经从主节点的repl_backlog_buffer中同步到的最新写指令的位置;
主节点收到写指令后,master_repl_offset增加,从节点从主节点的repl_backlog_buffer同步了写指令后,slave_repl_offset增加;
从节点断开重连后,会向主节点发送psync {repID} {slave_repl_offset} 指令,此时slave_repl_offset通常会小于master_repl_offset,所以主节点仅需要将slave_repl_offset到master_repl_offset之间的写指令同步给从节点,这就是增量同步。
特别注意:如果repl_backlog_buffer中记录的从节点断开连接期间的写指令已经被后续的写指令覆盖,那么此时不能执行增量同步,而是需要执行全量同步,所以需要将repl_backlog_buffer的大小设置一个合理的值,来尽可能的保证不出现重连后需要全量同步的情况。
5.2 哨兵架构模式
哨兵模式是主从复制模式的一种进阶形式,继承了主从复制的所有优势,如数据一致性和读写分离。它的核心优点在于能够自动实现主从切换和故障转移,从而提升了系统的可用性和鲁棒性。在哨兵模式下,系统能够从手动切换转变为自动切换,极大地增强了系统的自动化程度和稳定性。然而,哨兵模式也存在一定的局限性,特别是在在线扩容方面。当集群容量接近或达到上限时,进行扩容操作相对较为复杂和困难。
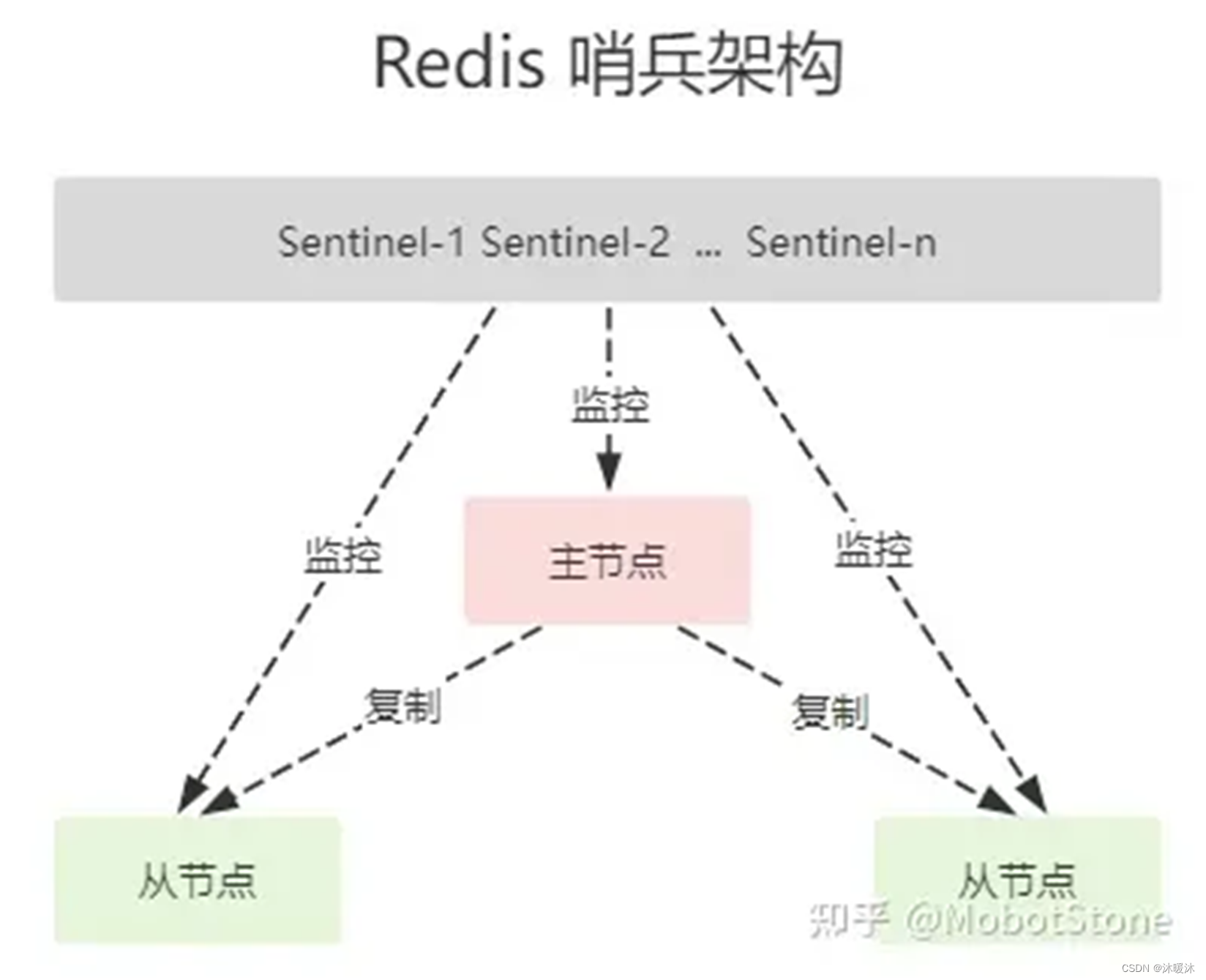
哨兵机制原理
哨兵通过发送命令(ping命令),等待Redis服务器响应,如果在指定时间内,主机Redis无响应,从机则判断主机宕机,选举从机上位,从而监控运行的多个Redis实例。

第一步:心跳机制
每个Sentinel 会每秒钟 一次的频率向它所知的 主服务器、从服务器 以及其他Sentinel 实例 发送一个 PING 命令,获取其拓扑结构和状态信息。
第二步:判断master节点是否下线
每个sentinel 哨兵节点每隔1s 向所有的节点发送一个PING命令,作用是通过心跳检测,检测主从服务器的网络连接状态。
如果master 节点回复 PING命令的时间超过down-after-milliseconds 设定的阈值(默认30s),则这个 master 会被sentinel 标记为主观下线。
第三步:基于Raft算法选举领头sentinel
master客观下线,那就需要一个sentinel来负责故障转移,所以需要通过选举一个sentinel的领头羊来解决。
第四步:故障转移
故障转移的一个主要问题和选择领头sentinel问题差不多,就是要选择一个slaver节点来作为master。
选择主Maseter过程大致如下:
① 选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高;
② 如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多;
③ 如果第二步offset也相同,选择run id较小的;
这样通过以上四大步骤,实现由Redis Sentinel自动完成故障发现和转移,实现自动高可用。
第五步:通知
通知所有子节点新的master,后边从新的master上边同步数据;广播通知所有客户端新的master。
5.3Cluster模式
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。

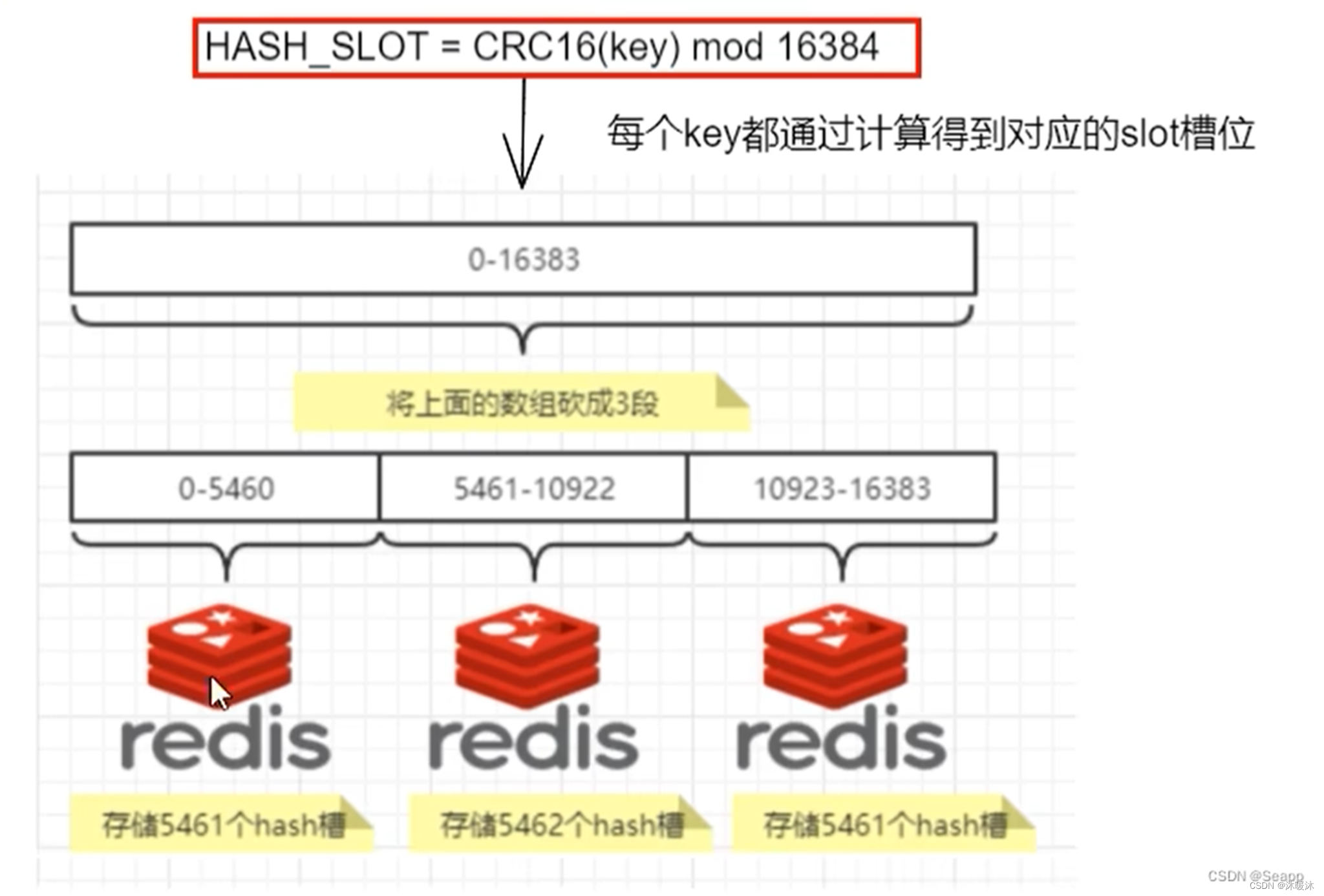
Redis hash槽
Redis集群没有使用一致性hash,而是引入了哈希槽的概念。
Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
举个例子:比如当前集群有3个节点,那么:集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于这 16384 个槽的其中一个,集群中的每个节点可以处理 0 个或最多 16384 个槽。
Key 与哈希槽映射过程可以分为两大步骤:
根据键值对的 key,使用 CRC16 算法,计算出一个 16 bit 的值;
将 16 bit 的值对 16384 执行取模,得到 0 ~ 16383 的数表示 key 对应的哈希槽。
6、redis和mysql一致性解决同步问题
-
双写模式:
在双写模式(即同时写入Redis和MySQL)中,先写Redis还是先写MySQL的顺序取决于特定的业务场景和需求。以下是两种顺序各自适合的情况:
①先写MySQL再写Redis
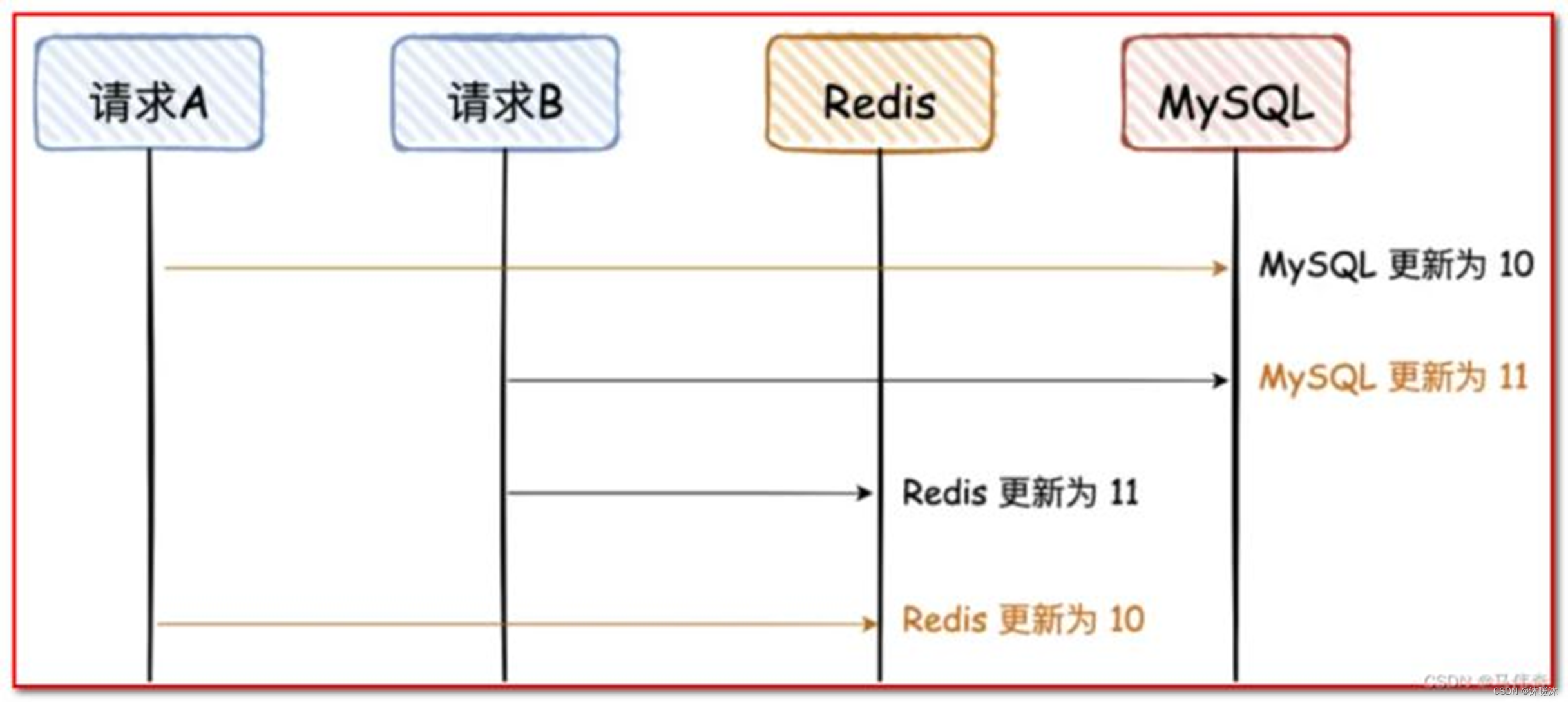
适用场景:
- 对数据一致性要求高:由于MySQL是持久化存储,先写入MySQL可以确保数据在磁盘上的安全性。即使Redis因为某些原因丢失数据,也可以从MySQL中恢复。
- Redis主要用于缓存:如果Redis主要用于缓存热点数据以加速读取,而不是作为数据源,那么先写入MySQL可以确保即使Redis中的数据丢失或不一致,也不会影响核心业务的正常运行。
- 可以容忍一定的延迟:由于网络延迟、Redis写入性能等因素,先写MySQL再写Redis可能会导致Redis中的数据相对MySQL有一定的延迟。如果这种延迟对业务来说是可接受的,那么这种顺序就是合适的。
注意事项:
- 需要确保Redis的写入操作在MySQL写入操作成功之后执行,以避免出现数据不一致的情况。
- 在Redis写入失败时需要有重试机制,以确保数据的最终一致性。
②先写Redis再写MySQL
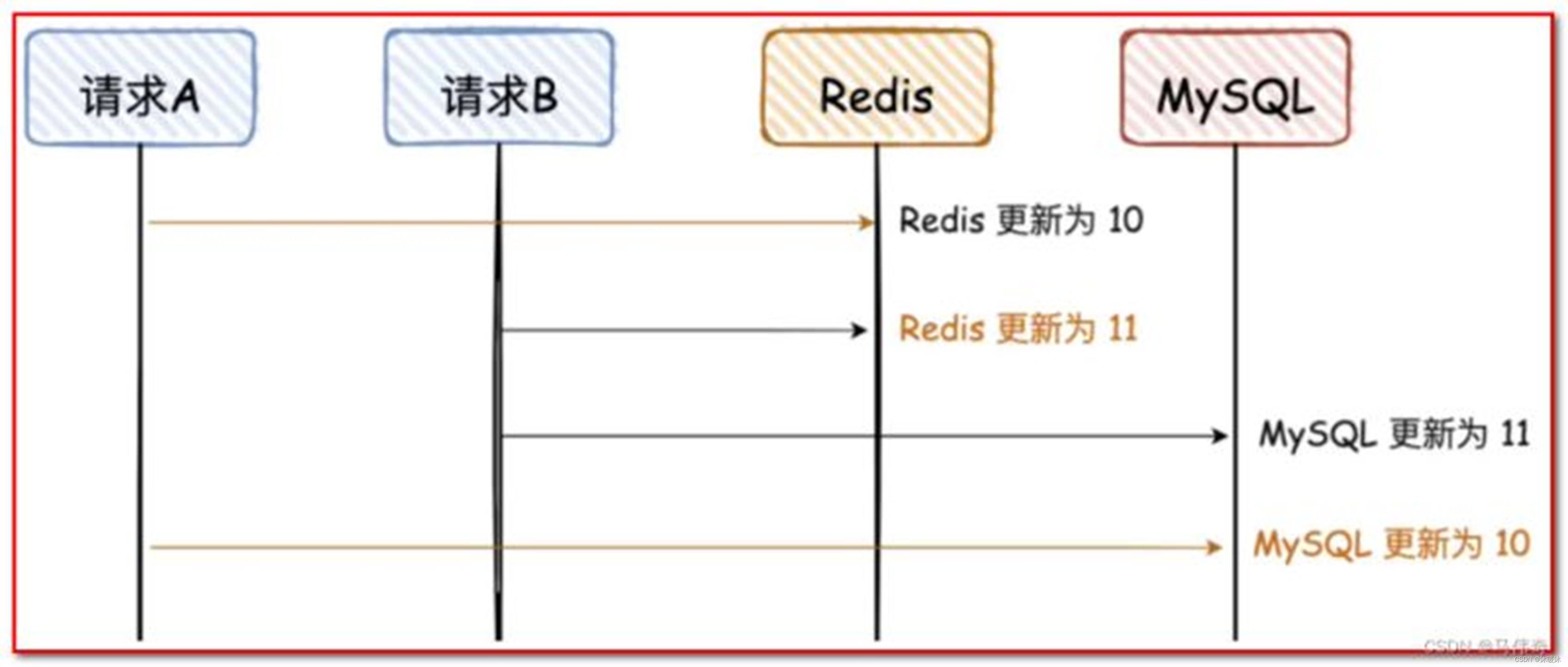
适用场景:
- 对性能要求极高:Redis作为内存数据库,写入性能远高于MySQL。在某些对性能要求极高的场景下,如实时计算、在线分析等,可能需要先写入Redis以满足性能需求。
- Redis作为数据源:在某些特殊场景下,Redis可能作为数据源使用,而MySQL只是用于备份或离线分析。在这种情况下,需要先写入Redis以确保数据的实时性。
注意事项:
- 由于Redis是内存数据库,存在数据丢失的风险。因此,在写入Redis之后必须确保MySQL的写入操作也成功执行,以确保数据的持久化存储。
- 同样需要处理Redis写入失败的情况,确保数据的最终一致性。
总结
选择先写Redis还是先写MySQL的顺序应该根据具体的业务需求和系统架构来决定。在大多数情况下,先写MySQL再写Redis是一个更稳妥的选择,因为它可以确保数据的一致性和安全性。但在某些对性能要求极高的场景下,可能需要考虑先写Redis再写MySQL的顺序。无论选择哪种顺序,都需要确保在写入过程中处理可能出现的失败情况,以确保数据的最终一致性。
异步更新:
RabbitMQ的使用
RabbitMQ是一个实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
RabbitMQ的主要特点包括:
- 可靠性:RabbitMQ基于AMQP协议,提供了持久化、可靠的消息传递机制。它确保消息能够在发送和接收之间进行可靠地传输,即使在出现故障的情况下也能保证消息的安全性。
- 灵活性:RabbitMQ支持多种消息传递模式,包括点对点、发布/订阅、请求/响应等。它允许开发人员根据应用程序的需求来选择合适的消息模式,实现灵活的消息传递。同时,它也支持水平扩展,可以在需要时添加更多的节点来处理更多的消息。
RabbitMQ的主要用途包括:
- 限流消峰:在系统处理高并发请求时,可以通过RabbitMQ将请求放入消息队列中进行排队,限制同时访问系统的请求数量,防止系统因过载而崩溃。
- 应用解耦:RabbitMQ可以作为消息队列,将不同的系统或应用进行解耦,降低系统间的耦合度,提高系统的可维护性和可扩展性。
- 异步处理:RabbitMQ支持异步处理,使得系统可以更加高效地处理请求和响应。在传统的同步通信方式中,请求方需要等待响应方返回结果后才能继续执行后续操作。而在异步通信方式中,请求方将请求发送到消息队列后立即返回,无需等待响应方返回结果。响应方可以在处理完请求后将结果发送到另一个消息队列中,供请求方或其他服务或组件异步获取。这种方式可以显著提高系统的吞吐量和响应速度,降低系统的延迟和阻塞。
导入依赖
<dependencies><dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>3.3.4</version></dependency>
</dependencies>RabbitMqConnection连接类
package rabbitMq;import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;import java.io.IOException;public class RabbitMqConnection {private static final ConnectionFactory connectionFactory;static {//定义一个链接工厂connectionFactory = new ConnectionFactory();//设置服务地址connectionFactory.setHost("localhost");//设定端口connectionFactory.setPort(5672);//设定用户名connectionFactory.setUsername("guest");//设定密码connectionFactory.setPassword("guest");//设定虚拟机connectionFactory.setVirtualHost("/");}public static Connection getConnection() throws IOException {try{return connectionFactory.newConnection();}catch (IOException e){System.out.println("获取链接失败");return null;}}
}
RabbitSender发送端
package rabbitMq;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;import java.io.IOException;public class RabbitSender {private final static String QUEUE_NAME = "hello";//交换机private final static String exchange_name = "test";public static void main(String[] argv) throws IOException {Connection connection = RabbitMqConnection.getConnection();if (connection != null){//创建通道Channel channel = connection.createChannel();//创建一个队列 QUEUE_NAME自定义队列名称channel.queueDeclare(QUEUE_NAME,false,false,false,null);String message = "hello lala";channel.basicPublish("",QUEUE_NAME,null,message.getBytes());System.out.println("发送消息:" + message);//关闭通道和连接channel.close();connection.close();}}
}
RabbitConsumer接收端
package rabbitMq;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.*;import java.io.IOException;public class RabbitConsumer {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws IOException {Connection connection = RabbitMqConnection.getConnection();if (connection != null) {Channel channel = connection.createChannel();channel.queueDeclare(QUEUE_NAME, false, false, false, null);DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {String message = new String(body);System.out.println("接收消息内容:" + message);}};// 监听队列,参数二:是否自动进行消息确认,false代表手动确认channel.basicConsume(QUEUE_NAME, true, defaultConsumer);}}
}
-
基于binlog的同步:
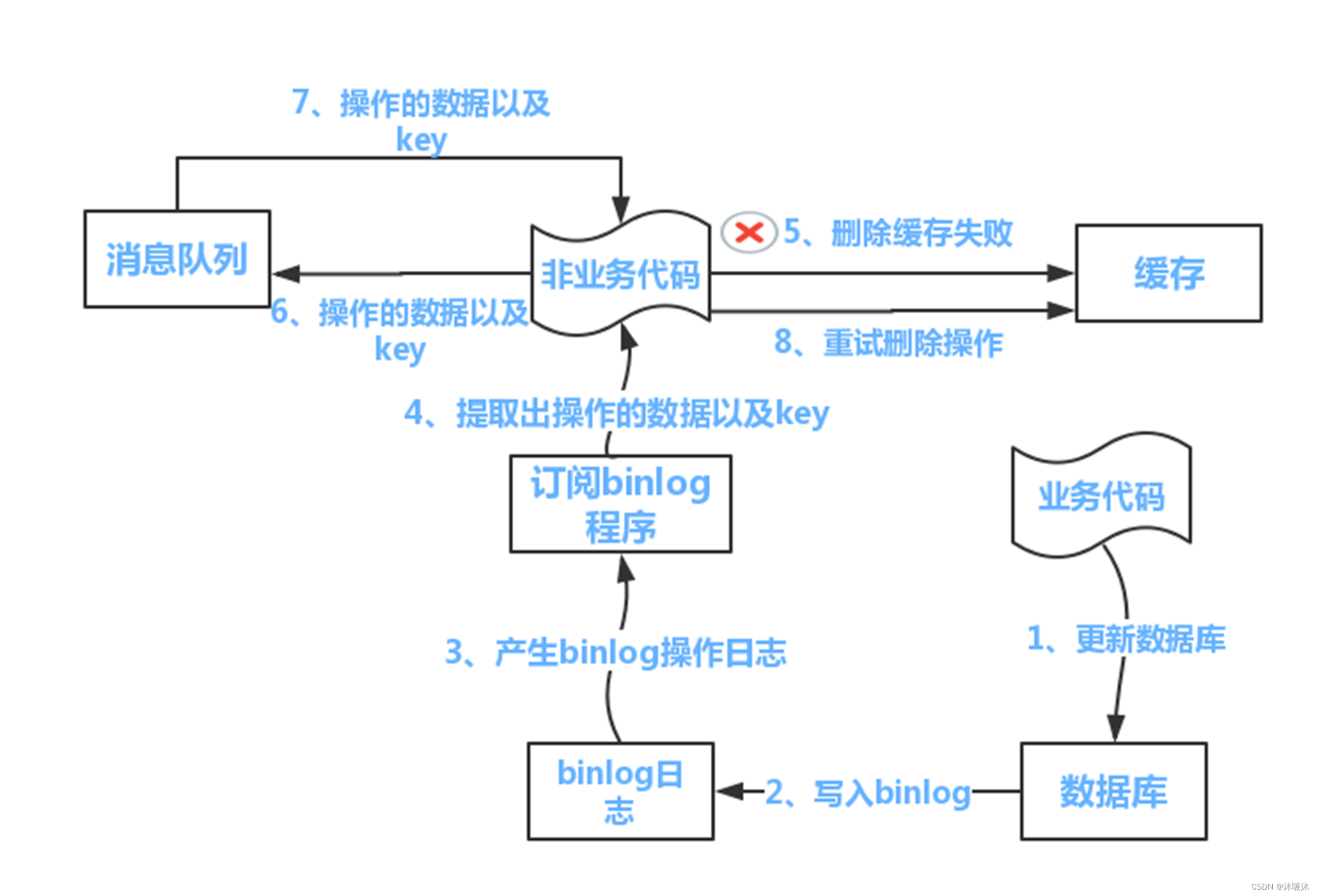
-
延迟双删:
- 当更新MySQL时,首先删除Redis中的相关缓存项。然后,在更新MySQL后等待一段时间(根据业务逻辑的耗时来确定)再次删除Redis中的同一缓存项。
- 这种方法可以减少在高并发场景下由于缓存覆盖导致的数据不一致问题。但是,它并不能完全解决所有的一致性问题。

1.延时双删,有等待环节,如果系统要求低延时,这种场景就不合适了。
2.延时双删,不适合“秒杀”这种频繁修改数据和要求数据强一致的场景。
3.延时双删,延时时间是一个预估值,不能确保 mysql 和 redis 数据在这个时间段内都实时同步或持久化成功了
-
分布式锁:
为什么要使用分布式锁?
本地锁只能锁住单台机器多线程请求的资源
分布式锁是多台机器共同访问redis中的一个数据,只有获取到锁的线程才能访问
如何设置分布式锁?
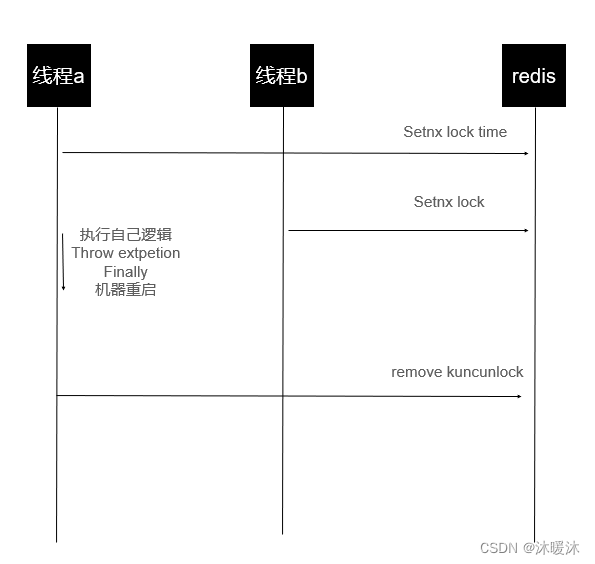
在分布式锁中如果程序突然中断,怎么释放锁?
在分布式锁中,如果程序突然中断,解决锁的释放问题主要有以下几种策略:
- 设置锁的超时时间:为锁设置一个合理的超时时间,即使程序突然中断,锁也会在超时后自动释放。这可以通过Redis的EXPIRE命令或SET命令结合EX选项来实现。这样可以避免因为程序中断而导致的死锁问题。
- 使用try-finally语句:在程序中,使用try-finally语句块来确保无论程序是否发生异常,finally块中的代码都会被执行。这样,你可以在finally块中添加释放锁的代码,以确保在程序中断时锁能够被正确释放。但是,这种方法无法解决服务器宕机或网络中断等极端情况。
- 利用Redis的键空间通知:Redis提供了键空间通知功能,可以在键被删除、过期等事件发生时发送通知。你可以利用这个功能来监听锁的键,当锁过期或被删除时,收到通知的客户端可以释放自己持有的锁。但是,这种方法需要额外的监听和处理逻辑,可能会增加系统的复杂性。
- 使用Redis的RedLock算法:RedLock算法是Redis官方推荐的一种分布式锁实现方式,它通过多个Redis节点来确保锁的可靠性和安全性。在RedLock算法中,如果客户端因为某种原因无法释放锁,其他客户端可以通过轮询或等待一段时间后尝试获取锁,从而避免死锁问题。
- 设计良好的锁释放策略:除了上述技术手段外,还需要设计良好的锁释放策略来避免死锁问题。例如,可以定期检测并清理过期的锁,或者为锁设置唯一的标识符并在释放时进行验证等。
如果锁的时间片到了,但是程序还没有执行完,这种情况怎么解决?
在分布式锁中,如果时间片(即锁的超时时间)到了,但程序还没有执行完,这可能会导致数据不一致或并发问题。针对这种情况,有几种常见的解决方案:
1.锁续命(Lock Renewal):
如果锁支持续命操作(如Redisson中的看门狗机制),你可以尝试在锁到期之前重新设置或延长其超时时间。这通常通过一个定时任务或后台线程来实现,定期检查锁的状态并在需要时续命。但请注意,这需要在锁被释放之前完成,否则可能会导致竞争条件。
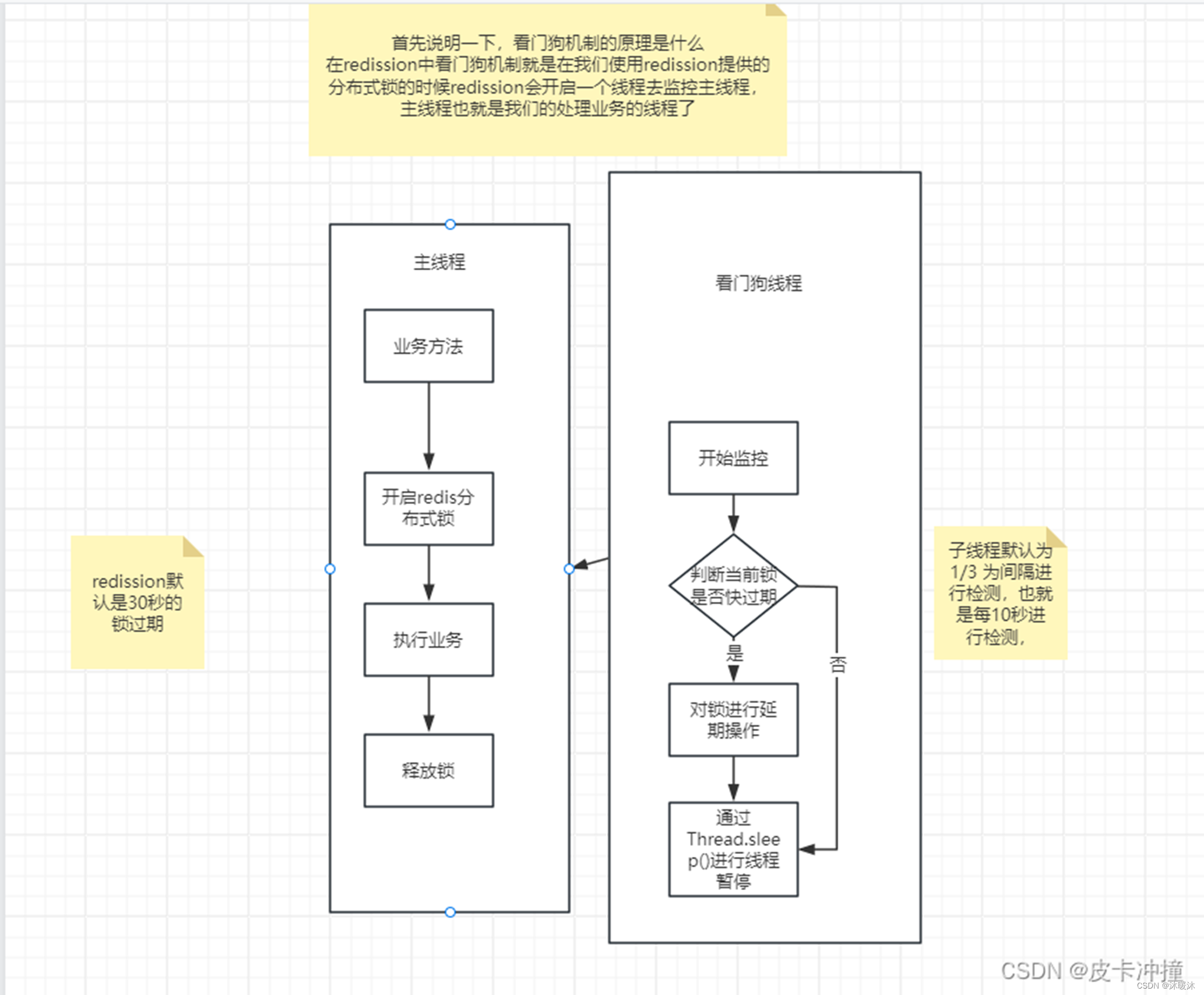
2.增加锁的超时时间:
如果任务确实需要较长时间来完成,并且你可以接受更长的等待时间,那么你可以考虑增加锁的超时时间。但请注意,过长的超时时间可能会增加死锁的风险,因为如果一个进程持有锁并因为某种原因崩溃或进入长时间阻塞状态,那么其他等待该锁的进程可能会被阻塞很长时间。
读写分离
- 将读操作从MySQL转移到Redis中,只在MySQL中执行写操作。这样可以提高系统的性能,但会导致读操作的数据与写操作的数据存在一定的延迟。
- 这种方法适用于对实时性要求不高的场景。
使用Redis的事务功能
- Redis支持MULTI/EXEC命令来实现事务功能,可以确保多个命令的原子性执行。在更新Redis数据时,可以将多个命令放在一个事务中执行,以确保数据的一致性。
相关文章:
redis深入理解之数据存储
1、redis为什么快 1)Redis是单线程执行,在执行时顺序执行 redis单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回 (socket 写)等都由一个顺序串行的主线…...

用20行python写一个最简单的网站
先安装flask框架,cmd命令行 pip install flask,或pycharm -> setting -> project -> python interpreter 搜索安装 # 引入Flask框架 from flask import Flask# 实例化Flask应用 app Flask(__name__)# 定义一个路由,当用户访问网站…...

零基础入门篇①③ Python可变序列类型--列表
Python从入门到精通系列专栏面向零基础以及需要进阶的读者倾心打造,9.9元订阅即可享受付费专栏权益,一个专栏带你吃透Python,专栏分为零基础入门篇、模块篇、网络爬虫篇、Web开发篇、办公自动化篇、数据分析篇…学习不断,持续更新,火热订阅中🔥专栏限时一个月(5.8~6.8)重…...

微服务项目 - SpringBoot 2.x 升级到 SpringBoot 3.2.5,保姆级避坑
目录 一、前言 二、取经之路 2.1、依赖版本情况 2.2、MyBatis-Plus 依赖改变...
【2024亚马逊云科技峰会】Amazon Bedrock + Llama3 生成式AI实践
在 4 月 18 日,Meta在官网上公布了旗下最新大模型Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k,据称,通过使用更高质量的训练数据…...

ApacheCordova 12 +Vs 2022 项目搭建教程_开发环境搭建教程
一、安装 cordova cli 并使用命令创建项目 npm install –g cordova 详细参考: Apache Cordova开发环境搭建(二)VS Code_天马3798-CSDN博客_cordova vscode 二、 Vs 2022 Android 开发搭建+调试 .Net MAUI 搭建Android 开发环境-CSDN博客 三、配置 JDK 环境变量、配置…...

地磁暴红色预警来袭,普通人该如何应对?绝绝子的防护指南来了
近日,国家空间天气监测预警中心发布了一则令人瞩目的消息——地磁暴红色预警。这一预警不仅提醒我们地磁暴即将影响我国的电离层和低轨卫星,更让我们深刻认识到地球空间环境的脆弱性和复杂性。对于普通公众而言,地磁暴的概念可能相对陌生&…...
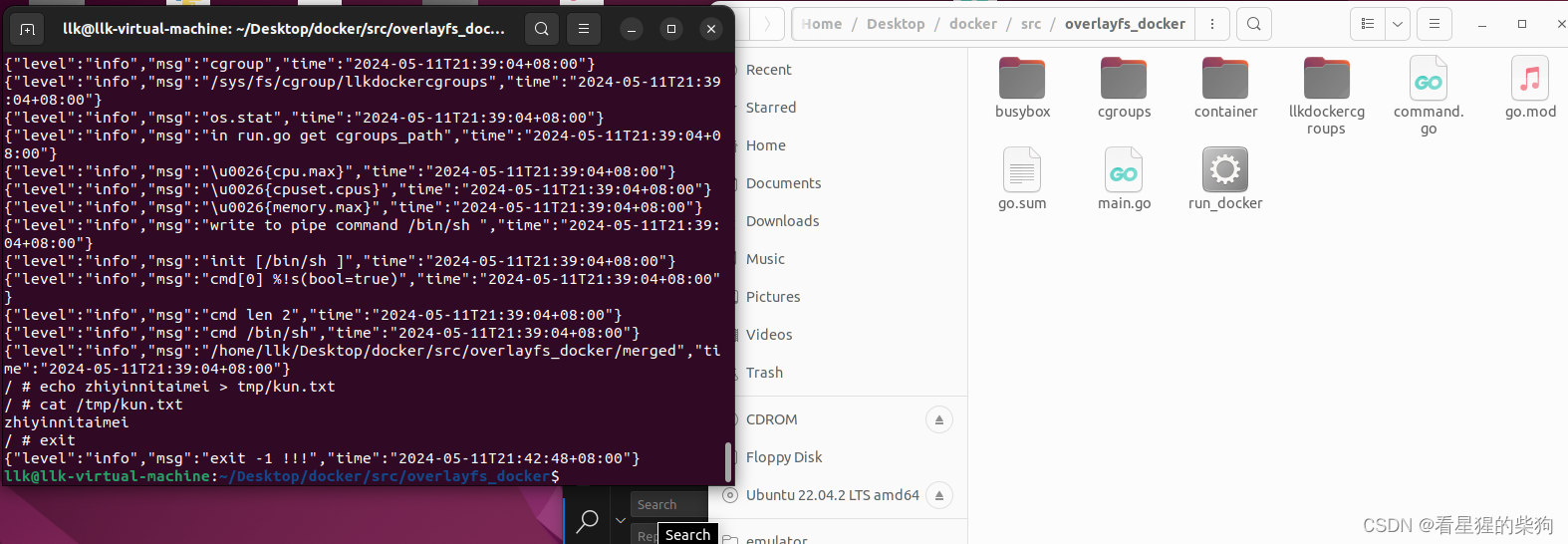
从零自制docker-12-【overlayfs】
文章目录 overlayfsexec.Command("tar", "-xvf", busyboxTarURL, "-C", busyboxURL).CombinedOutput()exec.Command格式差异 挂载mount卸载unmount代码地址结果演示 overlayfs 就是联合文件系统,将多个文件联合在一起成为一个统一的…...

凸优化理论学习一|最优化及凸集的基本概念
文章目录 一、优化问题(一)数学优化(二)凸优化 二、凸集(一)一些标准凸集(二)保留凸性的运算(三)正常锥和广义不等式(四)分离和支撑超…...
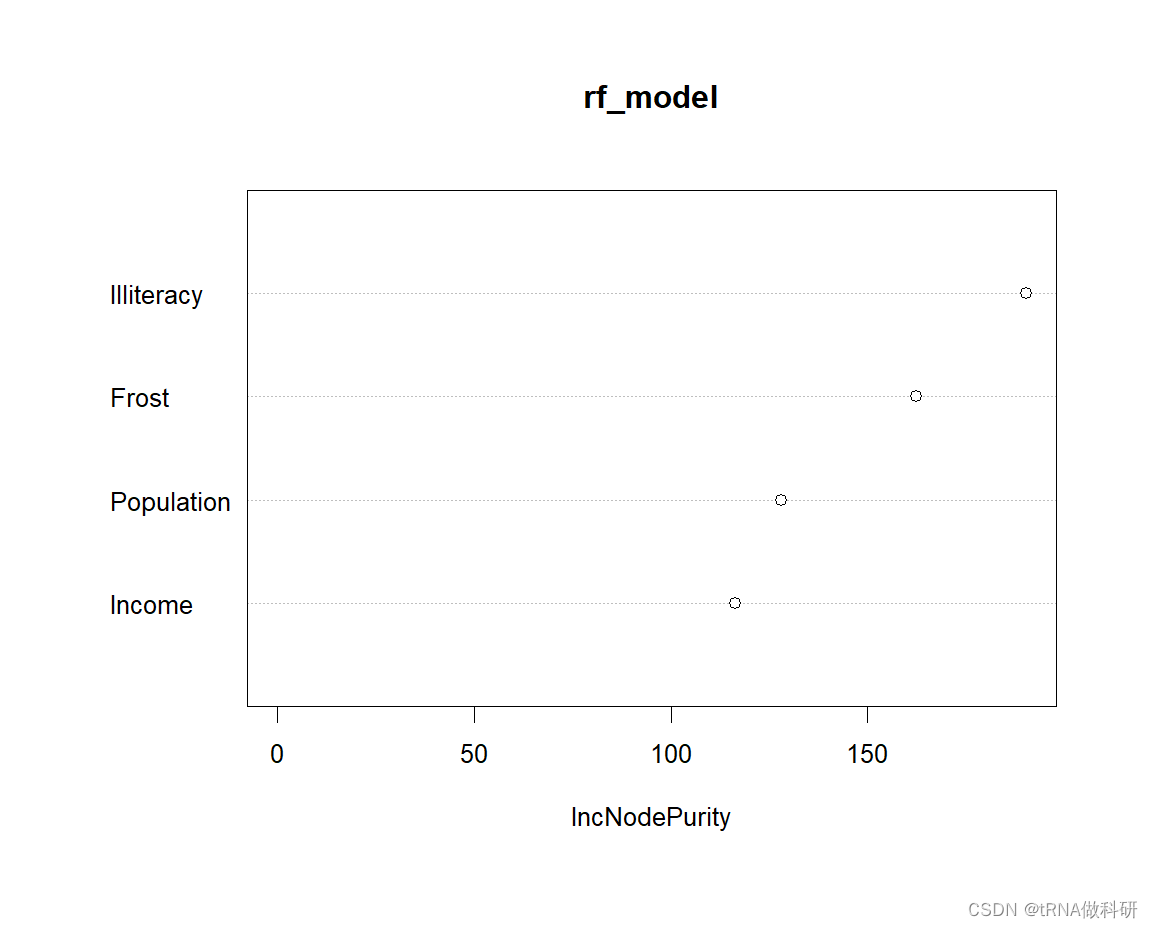
【R语言从0到精通】-4-回归建模
通过之前的文章,我们已经基本掌握了R语言的基本使用方法,那从本次教程开始,我们开始聚焦如何使用R语言进行回归建模。 4.1 回归简介 回归分析是一种统计学方法,用于研究两个或多个变量之间的相互关系和依赖程度。它可以帮助我们了…...
论文 学习 Transformer : Attention Is All You Need
目录 概述: 对摘要的理解: 框架解析 按比例缩放的点积注意力 多头注意力机制 前馈神经网络与位置编码 概述: transformer 是一个encoder ——decoder 结构的用于处理序列到序列转换任务的框架,是第一个完全依赖自注意力机制…...

工厂模式+策略模式
输入实体 基类 import lombok.Data;Data public class PersonInputDto {private Integer id;private String name; }子类 Data AllArgsConstructor NoArgsConstructor public class ManPerson extends PersonInputDto {private String sex; }Data AllArgsConstructor NoArgs…...
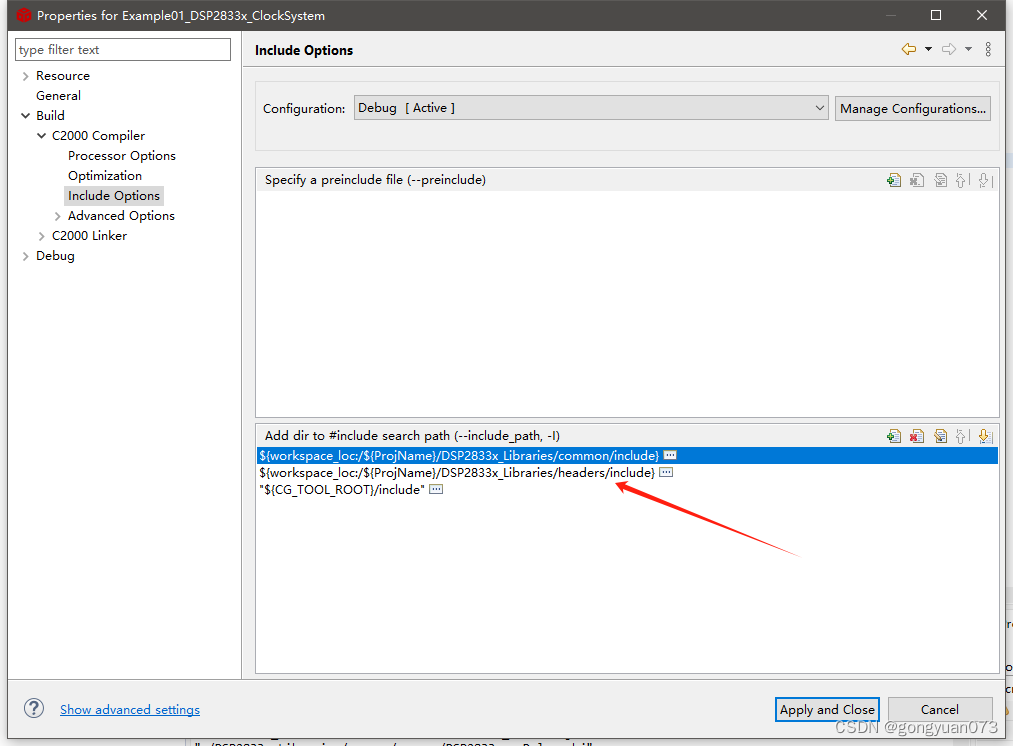
TMS320F28335学习笔记-时钟系统
第一次使用38225使用了普中的clocksystem例程进行编译,总是编译失败。 问题一:提示找不到文件 因为工程的头文件路径没有包含,下图的路径需要添加自己电脑的路径。 问题二 找不到库文件 例程种的header文件夹和common文件夹不知道从何而来…...

【Apache POI】Apache POI-操作Excel表格-简易版
Catalog Apache POI-操作Excel表格1. 需求2. 优点3. 缺点4. 应用场景5. 使用方法6. SpringBoot工程中处理Excel表格7. Demo示例 Apache POI-操作Excel表格 1. 需求 大多数项目的在运营过程中,会产生运营数据,如外卖系统中需要统计每日的订单完成数、每…...

MySQL系列之索引
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 往期热门专栏回顾 专栏…...

【问题分析】锁屏界面调起google语音助手后壁纸不可见【Android 14】
1 问题描述 为系统和锁屏分别设置两张不同的壁纸,然后在锁屏界面长按Power调起google语音助手后,有时候会出现壁纸不可见的情况,如以下截图所示: 有的时候又是正常的,但显示的也是系统壁纸,并非是锁屏壁纸…...
Java入门基础学习笔记8——注释
1、注释: 注释是写在程序中对代码进行解释说明的文件,方便自己和其他人查看,以便理解程序的。 package cn.ensource.note;/**文档注释文档注释 */ public class NoteDemo {public static void main(String[] args) {// 单行注释System.out.…...

上班工资太低了,哪些副业可以多赚钱?
今天给各位分享最赚钱的副业方式的知识,其中也会对比较赚钱的副业进行解释. 1、网站接单 一般20页左右的PPT报价基本在200-400元。如果能每周接单,一个月就有接近1000元的副业收入。提交摄影和绘画作品 比起画画,靠摄影赚点外快更容易一点。…...
原子学习笔记4——GPIO 应用编程
一、应用层如何操控 GPIO 与 LED 设备一样,GPIO 同样也是通过 sysfs 方式进行操控,进入到/sys/class/gpio 目录下,如下所示: gpiochipX:当前 SoC 所包含的 GPIO 控制器,我们知道 I.MX6UL/I.MX6ULL 一共包…...

查看iqn编码
cat /etc/iscsi/initiatorname.iscsi ## for each iSCSI initiator. Do NOT duplicate iSCSI InitiatorNames. InitiatorNameiqn.2004-10.com.ubuntu:01:9ebe1a68...

BurstGPT:大语言模型驱动高性能计算,实现自然语言科学仿真
1. 项目概述:当大语言模型遇上高性能计算最近在AI和HPC(高性能计算)的交叉领域,一个名为BurstGPT的项目引起了我的注意。乍一看这个标题,你可能会觉得有点“缝合怪”的味道——Burst通常指代计算资源的突发式使用或高性…...
)
从零到一:手把手教你为Nachos实现Exec和Exit系统调用(附完整代码与调试技巧)
从零构建Nachos系统调用:Exec与Exit的深度实现指南 1. 系统调用实现基础 在操作系统中,系统调用是用户程序与内核交互的唯一途径。Nachos作为一个教学用操作系统框架,其系统调用机制模拟了真实操作系统的核心设计思想。 寄存器交互机制是系统…...

如何实现一个延迟队列?
1. 基于 Sorted Set (ZSet) 的实现 这是最轻量级、最原生的 Redis 延迟队列实现方式。 核心思想:利用 ZSet 可以根据 score 进行排序的特性。我们将任务的预期执行时间戳作为 score,任务的具体内容(或任务 ID)作为 member。 生产…...

CSS Zen Garden设计趋势分析:过去20年的网页设计演变完全指南
CSS Zen Garden设计趋势分析:过去20年的网页设计演变完全指南 【免费下载链接】csszengarden.com The source of csszengarden.com 项目地址: https://gitcode.com/gh_mirrors/cs/csszengarden.com CSS Zen Garden作为网页设计领域的标志性项目,展…...

深入解析:parseInt 到底有几个参数?
🔢 深入解析:parseInt 到底有几个参数? 🤔 parseInt 的签名 parseInt 函数接收 两个 参数: parseInt(string, radix)string (必填):要被解析的值。如果参数不是字符串,会先转换为字符串。rad…...

Intel Wi-Fi 6 AX201网卡间歇性断连?华硕飞行堡垒8用户必看的节能模式与驱动管理避坑指南
Intel Wi-Fi 6 AX201网卡间歇性断连?华硕飞行堡垒8用户必看的节能模式与驱动管理避坑指南 当你的华硕飞行堡垒8笔记本突然无法连接Wi-Fi,设备管理器里Intel Wi-Fi 6 AX201网卡显示黄色感叹号并提示"代码10"错误时,这往往不是简单的…...
)
别再用Excel解方程了!手把手教你用C++实现高斯消元法(附洛谷P3389模板题实战)
从数学公式到AC代码:高斯消元法的竞赛级C实现 在算法竞赛和科学计算中,线性方程组求解是一个无法回避的经典问题。当你面对洛谷P3389这样的模板题时,是否曾困惑于如何将教科书上的数学步骤转化为高效的C代码?本文将彻底打破理论与…...

AI 内容生成 API 适合哪些团队?自媒体、电商、营销公司怎么用更省钱
现在很多团队都在用 AI 写内容。但很多人还停留在网页聊天阶段:打开一个 AI 工具,把需求复制进去,再把结果复制出来。这个方法适合个人临时用,但如果是团队长期做内容,尤其是自媒体、电商、营销公司、短视频团队&#…...

创建虚拟机、
...

Icarus Verilog终极指南:3分钟掌握开源Verilog仿真工具
Icarus Verilog终极指南:3分钟掌握开源Verilog仿真工具 【免费下载链接】iverilog Icarus Verilog 项目地址: https://gitcode.com/gh_mirrors/iv/iverilog 你是否正在寻找一个完全免费、跨平台的Verilog仿真解决方案?Icarus Verilog(…...