【MySQ】9.构建高可用数据库:MySQL集群模式部署大全
单个MySQL节点的主要风险在于它构成了一个单点故障,这意味着任何硬件故障、软件崩溃或维护需求都可能导致整个数据库服务中断,从而影响到业务的连续性和数据的安全性。此外,它还限制了系统的扩展性,使得性能提升和负载均衡变得困难,同时也缺乏数据冗余,增加了数据丢失或损坏的风险。为了解决这些问题,引入了MySQL的集群。
1.MySQL集群
MySQL集群是一种数据库架构,它通过在多个服务器上分布数据和负载来保障高可用性、可扩展性和容错性。
集群的主要目标是:
高可用性:确保数据库系统在面对硬件故障、网络问题或其他突发事件时仍能继续运行。
读写分离:通过将读操作和写操作分散到不同的服务器上,提高系统处理大量并发请求的能力。
负载均衡:将工作负载分散到多个服务器,避免单个数据库服务器的过载。
数据冗余:通过在多个节点上复制数据,提供数据备份,以防数据丢失或损坏。
2.MySQL集群的常见模式
主从复制:一个主节点负责写入操作,多个从节点复制主节点的数据。从节点可以处理读取操作,以此来提高读取性能。
MySQL Group Replication:一种基于InnoDB存储引擎的插件,提供多主或单主配置的高一致性集群。
MySQL NDB Cluster:一个高性能、高可用、可扩展的分布式数据库集群解决方案,适用于需要快速、实时数据访问的应用。
InnoDB Cluster:MySQL 8.0引入的基于Group Replication的集群解决方案,简化了配置和管理。
双主模式:两个主节点可以独立处理读写操作,适用于需要两个活跃写入节点的场景。
3.实现方式
3.1. 主从复制
MySQL的主从复制是一种数据复制技术,它允许将一个MySQL数据库服务器(主服务器或Master)上的数据自动复制到一个或多个服务器(从服务器或Slave)上。这种复制是异步的,主服务器将所有变更记录到二进制日志(binlog)中,从服务器则连接到主服务器并请求这些日志,然后在本地重放这些日志中的SQL语句,以保持数据的一致性。
优点
- 数据冗余:提供了数据的热备份,降低了数据丢失的风险。
- 性能提升:一主多从,不同用户从不同数据库读取,性能提升。
- 扩展性:流量增大时,可以方便地增加从服务器,不影响系统使用。
- 负载均衡:一主多从相当于分担了主机任务,做了负载均衡。
缺点
- 数据延迟:由于复制是异步的,存在数据复制延迟的风险。
- 复杂性增加:增加了系统的复杂性,需要更多的维护和管理。
- 额外资源消耗:需要额外的硬件资源来部署从服务器。
- 写入性能影响:所有写入操作都在主服务器上执行,可能成为性能瓶颈。
适用场景
- 读写分离:适用于读操作远多于写操作的场景。
- 数据备份:用于数据的实时备份,以防止数据丢失。
- 高可用性需求:需要保证服务连续性的关键应用。
配置文件
主从复制的配置涉及到修改MySQL的配置文件(通常是my.cnf或my.ini),并执行一系列的SQL命令来启动复制过程。
主服务器配置(my.cnf或my.ini):
[mysqld]
server-id=1 # 主服务器唯一ID
log-bin=mysql-bin # 二进制日志文件的名称
read-only=0 # 设置为0以允许写操作
从服务器配置(my.cnf或my.ini):
[mysqld]
server-id=2 # 从服务器唯一ID,不能与主服务器ID相同
relay-log=relay-log-bin # 中继日志文件的名称
read_only=1 # 设置为1以使从服务器只读
复制步骤:
-
在主服务器上创建复制用户并授权:
CREATE USER 'replica'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%'; FLUSH PRIVILEGES; -
在主服务器上查看当前的二进制日志文件和位置:
SHOW MASTER STATUS; -
在从服务器上配置主服务器信息:
CHANGE MASTER TO MASTER_HOST='主服务器IP', MASTER_USER='replica', MASTER_PASSWORD='password', MASTER_LOG_FILE='从SHOW MASTER STATUS获取的文件名', MASTER_LOG_POS=从SHOW MASTER STATUS获取的位置; -
启动从服务器复制进程:
START SLAVE; -
验证复制状态:
SHOW SLAVE STATUS \G;确保
Slave_IO_Running和Slave_SQL_Running的值为Yes。
请注意,具体的配置细节可能会根据MySQL的版本和操作系统有所不同,因此在配置前应参考官方文档或相关资源。
3.2 MySQL Group Replication
MySQL Group Replication
MySQL Group Replication(MGR)是一种提供高可用性、容错性和数据一致性的数据库复制解决方案。它基于Paxos协议,允许多个MySQL服务器组成一个集群,数据在集群中的每个节点上保持一致。
优点
- 高可用性:当一个节点失败时,集群可以继续运行,而不会影响服务的可用性。
- 自动故障转移:MGR可以自动处理节点故障并重新配置集群。
- 数据一致性:使用Paxos协议确保集群中所有节点的数据一致性。
- 写扩展性:在多主模式下,可以在多个节点上进行写操作,提高写入性能。
- 易于管理:可以使用MySQL Shell和系统变量来管理集群。
缺点
- 复杂性:相比于传统的主从复制,MGR的配置和维护更加复杂。
- 性能损耗:由于需要在集群节点间同步数据,可能会有一定的性能开销。
- 存储引擎限制:目前仅支持InnoDB存储引擎。
- 网络要求:对网络的稳定性和延迟有一定要求,因为节点间需要频繁通信。
适用场景
- 高可用性需求:需要确保数据库服务始终可用的应用。
- 多数据中心部署:跨越多个数据中心,需要数据同步和故障转移能力。
- 读写分离:需要在多个节点上进行读取操作以提高性能的场景。
配置文件
以下是MySQL Group Replication的基本配置,通常在每个节点的my.cnf或my.ini配置文件中设置:
[mysqld]
# 服务器唯一ID
server-id=1# 开启二进制日志
log-bin=mysql-bin# 开启GTID
gtid_mode=ON# 强制GTID一致性
enforce_gtid_consistency=ON# 设置需要加载的插件
plugin_load_add='group_replication.so'# 组复制的组名,需要是UUID格式
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"# 组复制的启动选项
group_replication_start_on_boot=off# 本地地址,用于组内通信
group_replication_local_address="127.0.0.1:33061"# 组内所有成员的地址
group_replication_group_seeds="127.0.0.1:33061,127.0.0.1:33062,127.0.0.1:33063"# 是否在引导组时启动
group_replication_bootstrap_group=off
如何使用
- 确保所有MySQL节点的
server-id是唯一的。 - 在每个节点上配置好
my.cnf文件,确保相关的组复制参数正确设置。 - 在每个节点上启动MySQL服务。
- 在一个节点上运行以下命令来初始化集群:
SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; - 在其他节点上运行以下命令来加入集群:
START GROUP_REPLICATION; - 确认集群状态:
SELECT * FROM performance_schema.replication_group_members;
实际部署时可能需要考虑更多的因素,如SSL配置、用户权限配置等。
3.3 MySQL NDB Cluster
MySQL NDB Cluster是一个高性能、高可用的分布式数据库集群系统,它允许在无共享的系统中部署“内存中”数据库的Cluster。NDB Cluster采用了NDB Cluster存储引擎,可以在一个Cluster中运行多个MySQL服务器。
优点
- 高可用性:提供99.999%的高可用性,确保了较强的故障恢复能力。
- 写入扩展性:通过自动分片实现高水平的写入扩展能力。
- 实时性能:提供实时的响应时间和吞吐量,满足苛刻的应用需求。
- 多站点集群:支持跨地域复制,提高灾难恢复能力和扩展能力。
- 在线扩展:允许在线添加节点和更新内容,支持快速变化和动态负载。
缺点
- 内存限制:基于内存,数据库的规模受集群总内存的大小限制。
- 网络依赖:多个节点通过网络实现通讯和数据同步,整体性能受网络速度影响。
- 存储引擎限制:需要对需要进行分片的表修改引擎为NDB,不支持外键。
- 事务隔离级别:NDB的事务隔离级别只支持Read Committed,而InnoDB支持所有事务隔离级别。
- 资源消耗:对内存和存储资源的消耗较大。
适用场景
- 大规模数据集:适用于需要处理大量数据和高并发读写操作的场景。
- 高可用性需求:对于需要几乎不间断服务的关键业务系统。
- 分布式计算环境:适用于需要跨多个地点分布数据的分布式应用。
配置文件
my.cnf(或my.ini,取决于操作系统)是MySQL服务器的主配置文件,它包含了用于调整数据库服务器行为的设置。要配置MySQL以使用NDB Cluster,您需要在my.cnf中设置特定的参数。以下是一个基本的配置示例:
[mysqld]
# 服务器的唯一ID,在集群中每个服务器的ID必须是唯一的
server-id=1# 设置数据目录
datadir=/path/to/mysql/data# 设置端口号(如果需要)
port=3306# 设置默认存储引擎为NDB
default-storage-engine=ndbcluster# 开启二进制日志
log-bin=mysql-bin# 设置binlog格式为ROW,NDB Cluster要求
binlog_format=row# 其他可能需要的配置项...
在配置my.cnf文件后,您还需要配置NDB Cluster的全局配置文件config.ini,这个文件包含了集群中所有节点的信息,如管理节点、数据节点和SQL节点的配置。
以下是config.ini文件的一个基本示例:
[ndbd default]
NoOfReplicas=2
DataMemory=64M[ndb_mgmd]
# 管理节点的ID
NodeId=1# 管理节点的主机名或IP地址
HostName=192.168.1.1# 管理节点的数据目录
DataDir=/path/to/ndb/mgmt/data[ndbd]
# 数据节点的ID
NodeId=2# 数据节点的主机名或IP地址
HostName=192.168.1.2# 数据节点的数据目录
DataDir=/path/to/ndb/data[mysqld]
# SQL节点的ID
NodeId=3# SQL节点的主机名或IP地址
HostName=192.168.1.3
需要根据实际的网络环境和系统配置来调整上述示例中的HostName和DataDir等参数。此外,可能还需要配置其他参数,如网络缓冲区大小、连接数限制等。
在修改配置文件后,需要重启MySQL服务以使更改生效。
如何使用
- 准备并配置
my.cnf和config.ini文件。 - 启动管理节点(
ndb_mgmd)。 - 在每个数据节点上启动数据节点守护进程(
ndbd)。 - 启动SQL节点(
mysqld)。 - 使用NDB管理工具(如
ndb_mgm)来管理集群。
3.4 InnoDB Cluster
InnoDB Cluster是MySQL官方提供的高可用性数据库解决方案,它基于MySQL Group Replication构建,提供易于管理的API、自动故障转移和路由、以及负载均衡等功能。
优点
- 高可用性:通过自动故障转移和恢复,确保服务的持续可用性。
- 读写分离:支持读写分离,提高数据库的读取性能。
- 负载均衡:内置MySQL Router提供负载均衡功能,优化资源使用。
- 易于管理:通过MySQL Shell的AdminAPI简化了集群的配置和管理。
- 自动数据同步:底层使用Group Replication技术,实现数据的自动同步。
缺点
- 复杂性:相比于传统的主从复制,配置和维护InnoDB Cluster更加复杂。
- 资源消耗:运行InnoDB Cluster需要额外的硬件资源和网络带宽。
- 有限的节点支持:虽然可以横向扩展,但集群中的节点数量有限。
适用场景
- 高可用性需求:适用于需要高可用性服务的关键业务系统。
- 大型企业级应用:适用于需要处理大量数据和请求的大型应用。
- 易于管理的集群:适用于需要简化集群管理并希望减少运维成本的场景。
配置文件
InnoDB Cluster的配置涉及到my.cnf配置文件的设置以及使用MySQL Shell进行集群管理。
my.cnf 配置示例(对于每个MySQL实例):
[mysqld]
server_id=1
log_bin=mysql-bin
binlog_format=row
gtid_mode=ON
enforce_gtid_consistency=ON# Group Replication的配置
group_replication_group_name="XX-XX-OO-OO"
group_replication_start_on_boot=off
group_replication_local_address="server-uuid:33061"
group_replication_group_seeds="server1-uuid:33061,server2-uuid:33062,server3-uuid:33063"
group_replication_bootstrap_group=off
如何使用
- 确保所有MySQL实例的
server_id是唯一的,并配置好Group Replication的相关参数。 - 在每个MySQL实例上启动Group Replication。
- 使用MySQL Shell连接到主节点,并使用AdminAPI创建InnoDB Cluster:
mysqlsh -u root -p var cluster = dba.createCluster('primary_instance', 'root', 'password'); cluster.addInstance('secondary_instance_1', 'root', 'password'); cluster.addInstance('secondary_instance_2', 'root', 'password'); - 使用MySQL Router进行读写分离和负载均衡。初始化MySQL Router并配置连接信息:
mysqlrouter --bootstrap root@primary_instance:3306 --user=root - 启动MySQL Router,并使用提供的连接信息进行数据库连接。
3.5 双主模式
双主模式是一种数据库复制配置,其中两个数据库节点都作为主节点,可以独立接受写入操作。当一个节点接收到写入请求时,更改会实时复制到另一个节点。
优点
- 写入扩展性:两个节点都可以处理写入操作,提高了写入操作的扩展性。
- 高可用性:在任一节点故障时,另一个节点仍可继续提供服务,包括写入操作。
- 故障转移:无需复杂的故障转移机制,因为两个节点都是活跃的。
缺点
- 数据一致性:需要复杂的冲突检测和解决机制来保持数据一致性。
- 网络要求:对网络稳定性和延迟有较高要求,因为节点间的实时同步对网络质量敏感。
- 额外开销:实时同步带来的额外网络和磁盘I/O开销。
适用场景
- 分布式应用:需要在不同地理位置提供写入能力的应用。
- 高写入负载:需要分散写入负载以提高性能的场景。
- 实时数据需求:需要在多个节点实时同步数据的应用。
配置文件
双主模式的配置通常涉及修改MySQL的配置文件(my.cnf或my.ini),并使用MySQL Shell进行管理。
my.cnf 配置示例(对于每个MySQL实例):
[mysqld]
server_id=1 # 每个节点的server_id必须唯一
log_bin=mysql-bin # 开启二进制日志
binlog_format=row # 使用row格式以支持双主复制
gtid_mode=ON # 开启GTID
enforce_gtid_consistency=ON # 保证GTID的一致性# Group Replication的配置
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" # 集群名称,需与所有节点相同
group_replication_start_on_boot=off # 禁止开机自启
group_replication_local_address="192.168.1.1:33061" # 本地地址和端口
group_replication_group_seeds="192.168.1.1:33061,192.168.1.2:33061" # 集群中所有节点的地址和端口
group_replication_bootstrap_group=off # 设置为off以防止自动成为主节点
如何使用
- 确保所有MySQL实例的
server_id是唯一的,并配置好Group Replication的相关参数。 - 在每个MySQL实例上启动Group Replication。
- 使用MySQL Shell连接到任一节点,并使用AdminAPI进行双主模式的配置:
mysqlsh -u root -p var cluster = dba.getCluster(); cluster.switchToMultiPrimaryMode(); - 这将把集群从单主模式切换到双主模式。
4.总结
为了应对单实例的局限性与风险,MySQL集群通过在多个服务器间分散数据和负载,提供了一种高可用性、可扩展和容错性强的数据库解决方案。它支持多种模式,包括主从复制、MySQL Group Replication、MySQL NDB Cluster和InnoDB Cluster,以及双主模式,以满足不同的业务需求。每种模式都有其独特的优点和局限性,选择合适的集群模式需要考虑业务场景、性能要求、维护成本和系统复杂性。通过精心配置和优化,MySQL集群能够显著提升数据库系统的整体性能和可靠性。
相关文章:

【MySQ】9.构建高可用数据库:MySQL集群模式部署大全
单个MySQL节点的主要风险在于它构成了一个单点故障,这意味着任何硬件故障、软件崩溃或维护需求都可能导致整个数据库服务中断,从而影响到业务的连续性和数据的安全性。此外,它还限制了系统的扩展性,使得性能提升和负载均衡变得困难…...
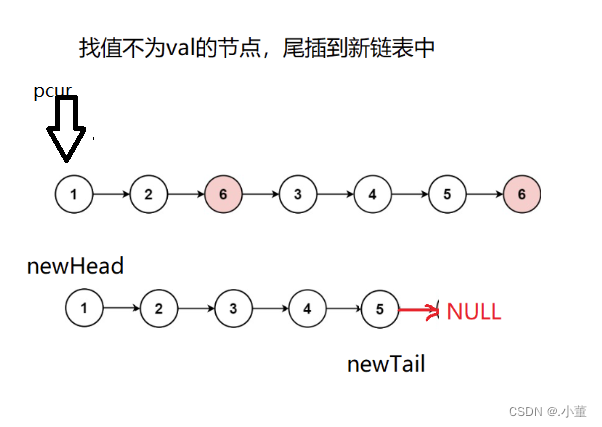
Leedcode题目:移除链表元素
题目: 这个题目就是要我们将我们的链表中的值是val的节点删除。 我们题目提供的接口是 传入了指向一个链表的第一个节点的指针,和我们要删除的元素的值val,不只要删除第一个, 思路 我们这里可以创建一个新的链表,…...

1_1. Linux简介
1_1. Linux简介 文章目录 1_1. Linux简介1. 我们用linux来干嘛2. 计算机组成3. 操作系统4. Linux哲学思想5. Linux目录6. Linux分区类型 1. 我们用linux来干嘛 1. 大家都知道linux是一个操作系统,它是一个基础的软件,操作系统是硬件与应用程序的中间层。…...

Swift 函数
函数 一、函数的定义与调用二、函数参数与返回值1、无参数函数2、多参数函数3、无返回值函数4、多重返回值函数5、可选元组返回类型6、隐式返回的函数 三、函数参数标签和参数名称1、指定参数标签2、忽略参数标签3、默认参数值4、可变参数5、输入输出参数 四、函数类型1、使用函…...
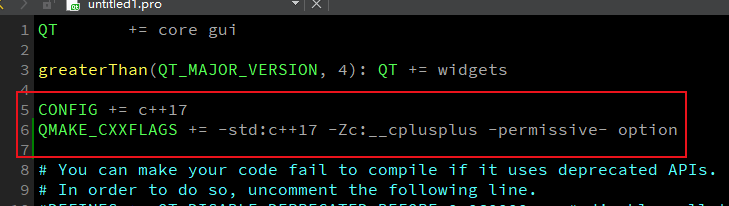
QT creator qt6.0 使用msvc2019 64bit编译报错
qt creator qt6.0报错: D:\Qt6\6.3.0\msvc2019_64\include\QtCore\qglobal.h:123: error: C1189: #error: "Qt requires a C17 compiler, and a suitable value for __cplusplus. On MSVC, you must pass the /Zc:__cplusplus option to the compiler."…...

scrapy常用命令总结
1.创建scrapy项目的命令: scrapy startproject <项目名字> 示例: scrapy startproject myspider 2.通过命令创建出爬虫文件,爬虫文件为主要的代码文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。 …...

【Linux系列】file命令
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

基于php+mysql+html简单图书管理系统
博主介绍: 大家好,本人精通Java、Python、Php、C#、C、C编程语言,同时也熟练掌握微信小程序、Android等技术,能够为大家提供全方位的技术支持和交流。 我有丰富的成品Java、Python、C#毕设项目经验,能够为学生提供各类…...
【Python系列】Python中列表属性提取
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
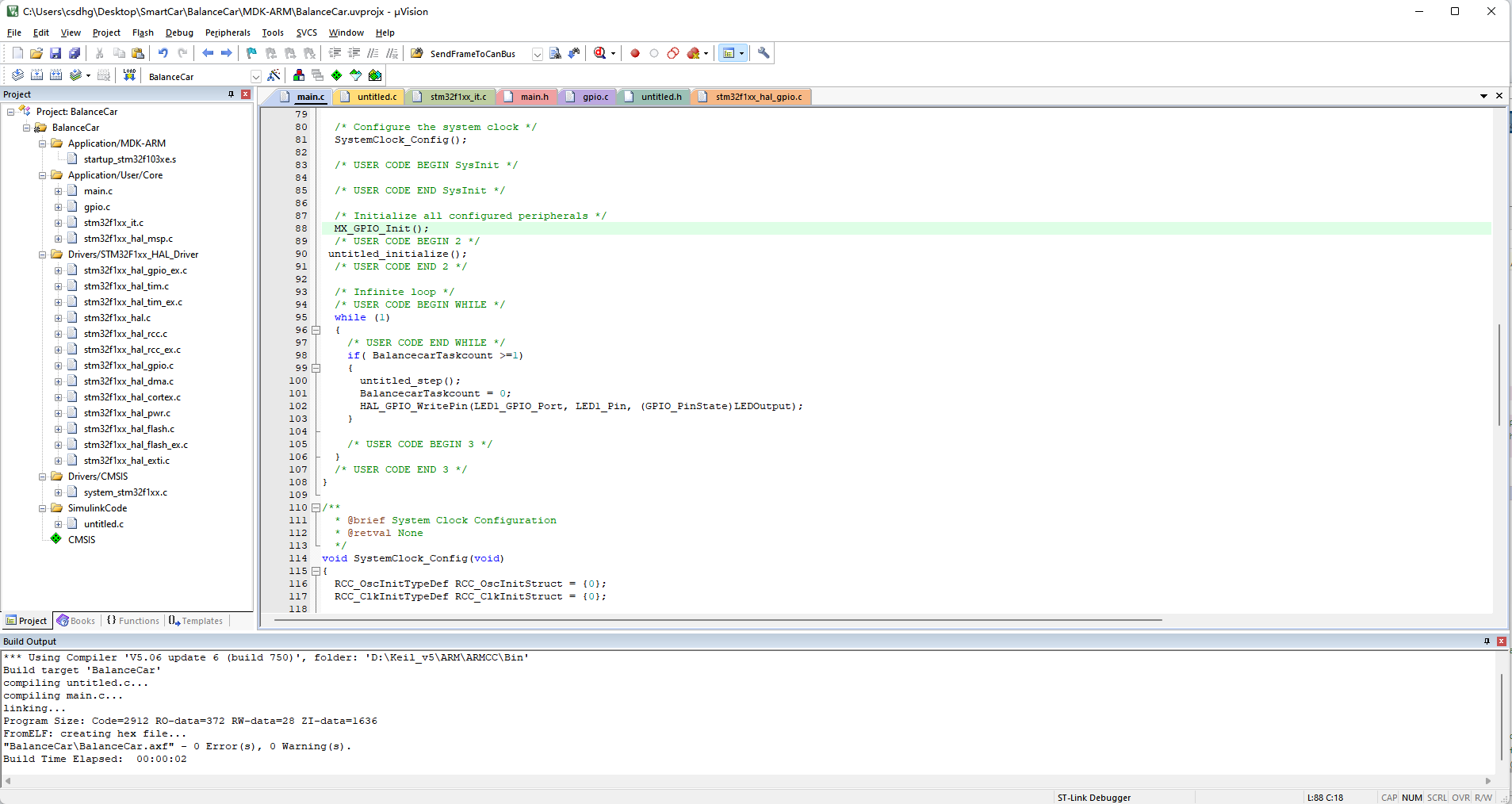
使用MATLAB/Simulink点亮STM32开发板LED灯
使用MATLAB/Simulink点亮STM32开发板LED灯-笔记 一、STM32CubeMX新建工程二、Simulink 新建工程三、MDK导入生成的代码 一、STM32CubeMX新建工程 1. 打开 STM32CubeMX 软件,点击“新建工程”,选择中对应的型号 2. RCC 设置,选择 HSE(外部高…...
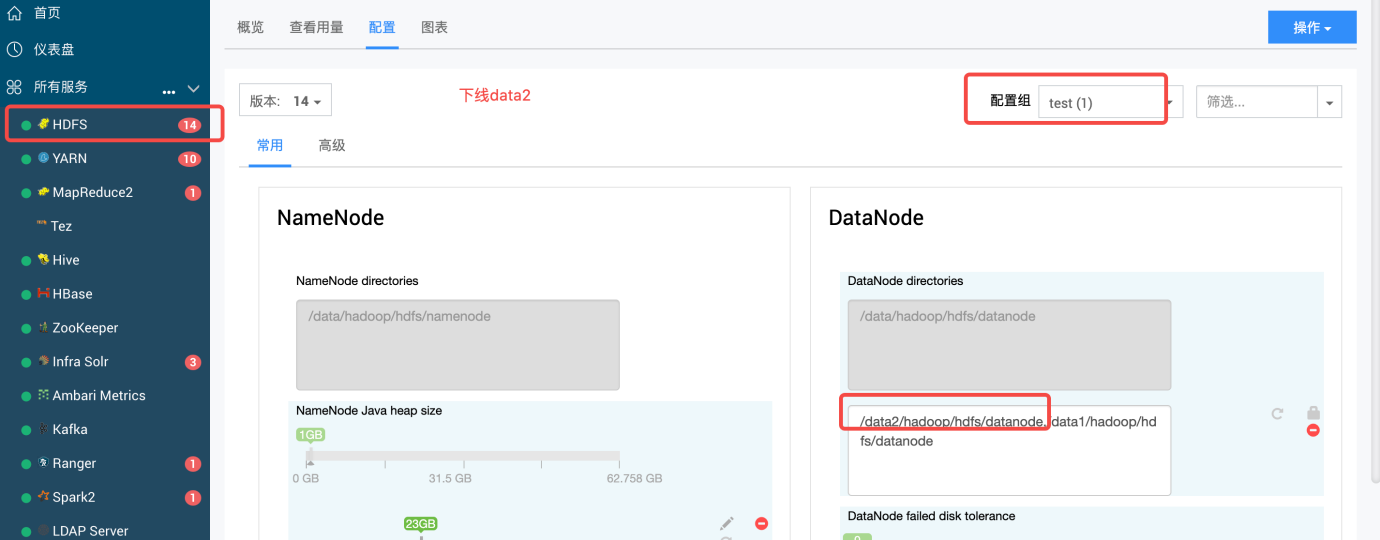
HDFS- DataNode磁盘扩缩容
HDFS- DataNode磁盘扩缩容 背景: 缩减/增加节点磁盘 方案介绍: 采用hdfs dfsadmin -reconfig 动态刷新配置实现,不停服扩缩容。 注意事项: 请在进行缩容之前,务必了解实际的数据量,并确保磁盘有足够的空间来容纳这些数据。还需要考虑未来的使用需求,要预留一定数量的空间…...
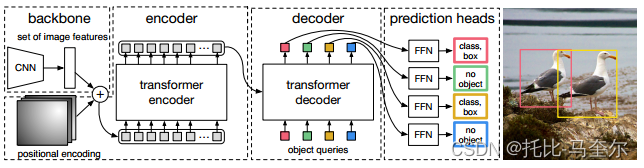
5.10.3 使用 Transformer 进行端到端对象检测(DETR)
框架的主要成分称为 DEtection TRansformer 或 DETR,是基于集合的全局损失,它通过二分匹配强制进行独特的预测,以及 Transformer 编码器-解码器架构。 DETR 会推理对象与全局图像上下文的关系,以直接并行输出最终的预测集。 1. …...
前端开发指导
前端开发指导 本文介绍了配置前端开发环境需要的软件、配置项等,指导如何开始进行UDM部门前端开发的全流程。本文以Windows系统下在Microsoft Virtual Studio Code中开发为基础。 一、综述 目标:零基础或者新员工依照此文档,能够完成开发环境的搭建及熟悉测试环境的搭建。…...

三方库的调用方法
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言三方库的调用方法1. **下载并安装Boost库(三方库)**2. **配置开发环境**3. **包含Boost(三方库)头文件**4. **编写代码**5. **链接Boost库(三…...

如何使用提示测试为LLMs构建单元测试?
原文地址:how-to-build-unit-tests-for-llms-using-prompt-testing 确保您的人工智能交付:快速测试完美生成应用程序的基本指南 2024 年 4 月 26 日 如果你曾经编写过软件,你就会知道测试是开发过程中必不可少的一部分。特别是单元测试&#…...

目前市面上堡垒机厂家有哪些?会帮忙部署吗?
随着大家对于网络安全的重视,越来越多的企业准备采购堡垒机了。不少企业在问,目前市面上堡垒机厂家有哪些?会帮忙部署吗?这里我们小编就来简单为大家回答一下,仅供参考哈! 目前市面上堡垒机厂家有哪些&…...

【备忘】在使用php-ffmpeg/php-ffmpeg开发时遇到Unable to load FFProbe时如何处理?
执行FFProbe::create()时,提示Unable to load FFProbe,php-ffmpeg/php-ffmpeg版本是用的^0.19.0,安装位置/usr/bin/ffprobe,现在提示这个错误要怎么解决呢 说个小技巧: 当在开发跟视频相关的功能时,总是出…...
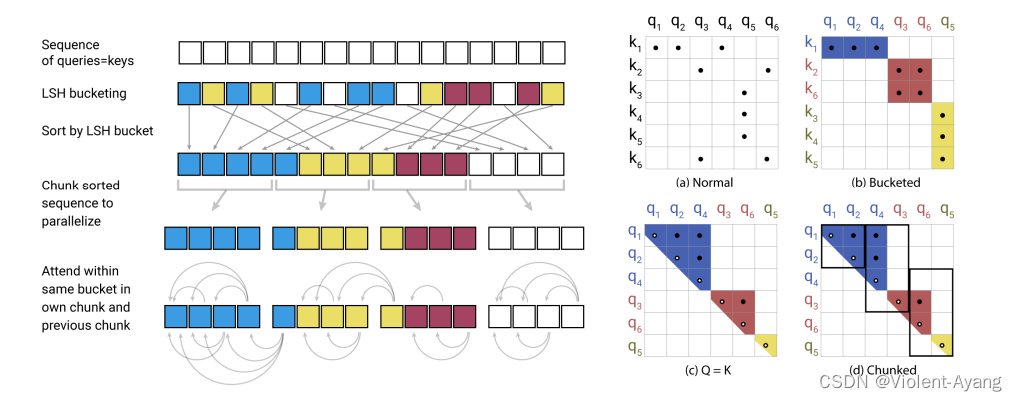
REFORMER: 更高效的TRANSFORMER模型
大型Transformer模型通常在许多任务上都能达到最先进的结果,但是训练这些模型的成本可能会非常高昂,特别是在处理长序列时。我们引入了两种技术来提高Transformer的效率。首先,我们用一种使用局部敏感哈希的点积注意力替换了原来的点积注意力…...
视频合并有妙招:视频剪辑一键操作,批量嵌套合并的必学技巧
在数字时代的今天,视频已经成为我们日常生活和工作中不可或缺的一部分。无论是记录生活点滴,还是制作专业项目,视频合并都是一个常见的需求。然而,对于许多人来说,视频合并却是一个复杂且繁琐的过程。现在有云炫AI智剪…...
安装SQL Server详细教程_sql server安装教程
一,SQL Server数据库安装 1.首先,下载安装程序 (1)从网盘下载安装exe 点击此处直接下载 (2)从官网下载安装exe文件 在官网选择Developer进行下载 2.开始安装 双击安装程序,开始安装 这里直…...

Ostrakon-VL-8B与传统算法对比展示:在复杂背景下的菜品分割
Ostrakon-VL-8B与传统算法对比展示:在复杂背景下的菜品分割 不知道你有没有遇到过这样的烦恼:想给美食拍张照,结果背景里堆满了杂乱的餐具、餐巾纸,甚至还有手机和钥匙,想单独把菜品抠出来,用传统的修图工…...

抖音直播数据抓取实战:零基础掌握直播间弹幕分析技术
抖音直播数据抓取实战:零基础掌握直播间弹幕分析技术 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2024最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 想要获取抖音直播间的…...

SpringBoot+Mybatis多数据源实战:TDengine与MySQL混搭的物联网数据存储方案
SpringBootMybatis多数据源实战:TDengine与MySQL混搭的物联网数据存储方案 在物联网系统开发中,数据存储架构的设计往往面临一个核心矛盾:海量设备时序数据的高效存储与业务数据的复杂关系处理如何平衡?传统单一数据库方案要么在时…...

Blender3mfFormat插件全攻略:从基础到进阶的3MF文件处理指南
Blender3mfFormat插件全攻略:从基础到进阶的3MF文件处理指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 一、基础认知:3MF格式与插件价值解析…...

Qwen3-ASR-1.7B语音识别实战:科研访谈录音转文本+主题自动聚类
Qwen3-ASR-1.7B语音识别实战:科研访谈录音转文本主题自动聚类 想象一下这个场景:你刚刚结束了一场长达两小时的深度科研访谈,录音文件静静地躺在你的电脑里。接下来,你需要逐字逐句地听录音、做笔记、整理成文字稿,然…...
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南 1. 为什么前端开发者需要关注视觉素材生成 作为一名Vue.js开发者,你可能经常遇到这样的困扰:产品经理突然要求给新功能加个炫酷的Banner图,设计师资源紧张排…...
的经典思想)
从‘折半查找’到‘二分答案’:LeetCode实战中如何活用这个O(log n)的经典思想
从二分查找到二分答案:LeetCode实战中的O(log n)思想进阶指南 在算法学习与面试准备过程中,二分查找(Binary Search)往往是第一个让初学者感受到算法效率之美的经典案例。这个看似简单的"折半查找"思想,却能…...

Java 25虚拟线程资源隔离配置,深度剖析JEP 477 ScopedValue与CarrierThread绑定机制
第一章:Java 25虚拟线程资源隔离配置概览Java 25正式将虚拟线程(Virtual Threads)纳入长期支持特性,并强化了其在高并发场景下的资源隔离能力。虚拟线程本身轻量、按需调度,但若缺乏显式资源约束,仍可能因共…...

SNOMED CT入门指南:从概念、关系到数据文件,手把手带你理解这个医学术语标准
SNOMED CT技术解析:从数据结构到医疗信息系统的实战指南 在医疗信息化领域,数据标准化是打破信息孤岛的关键。当不同医院的电子病历系统使用各自独立的术语体系时,跨机构的数据交换就像一场没有翻译的多国会议——充满误解和低效。这正是SNOM…...

写作压力小了!2026最新AI论文写作工具测评与推荐
2026年真正好用的AI论文写作工具,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...