pdf 文件版面分析--pdfplumber (python 文档解析提取)
pdfplumber 的特点
1、它是一个纯 python 第三方库,适合 python 3.x 版本
2、它用来查看pdf各类信息,能有效提取文本、表格
3、它不支持修改或生成pdf,也不支持对pdf扫描件的处理
import glob
import pdfplumber
import re
from collections import defaultdict
import jsonclass PDFProcessor:def __init__(self, filepath):self.filepath = filepath#打开文档,注意存放的位置self.pdf = pdfplumber.open(filepath)self.all_text = defaultdict(dict)self.allrow = 0self.last_num = 0def check_lines(self, page, top, buttom):# 文本数据lines = page.extract_words()[::]text = ''last_top = 0last_check = 0for l in range(len(lines)):each_line = lines[l]check_re = '(?:。|;|单位:元|单位:万元|币种:人民币|\d|报告(?:全文)?(?:(修订版)|(修订稿)|(更正后))?)$'if top == '' and buttom == '':if abs(last_top - each_line['top']) <= 2:text = text + each_line['text']#elif last_check > 0 and (page.height * 0.85 - each_line['top']) > 0 and not re.search(check_re, text):elif last_check > 0 and (page.height * 0.9 - each_line['top']) > 0 and not re.search(check_re, text):text = text + each_line['text']else:text = text + '\n' + each_line['text']elif top == '':if each_line['top'] > buttom:if abs(last_top - each_line['top']) <= 2:text = text + each_line['text']elif last_check > 0 and (page.height * 0.85 - each_line['top']) > 0 and not re.search(check_re,text):text = text + each_line['text']else:text = text + '\n' + each_line['text']else:if each_line['top'] < top and each_line['top'] > buttom:if abs(last_top - each_line['top']) <= 2:text = text + each_line['text']elif last_check > 0 and (page.height * 0.85 - each_line['top']) > 0 and not re.search(check_re,text):text = text + each_line['text']else:text = text + '\n' + each_line['text']last_top = each_line['top']last_check = each_line['x1'] - page.width * 0.85return textdef drop_empty_cols(self, data):# 删除所有列为空数据的列transposed_data = list(map(list, zip(*data)))filtered_data = [col for col in transposed_data if not all(cell is '' for cell in col)]result = list(map(list, zip(*filtered_data)))return result@staticmethoddef keep_visible_lines(obj):"""If the object is a ``rect`` type, keep it only if the lines are visible.A visible line is the one having ``non_stroking_color`` not null."""if obj['object_type'] == 'rect':if obj['non_stroking_color'] is None:return Falseif obj['width'] < 1 and obj['height'] < 1:return False# return obj['width'] >= 1 and obj['height'] >= 1 and obj['non_stroking_color'] is not Noneif obj['object_type'] == 'char':return obj['stroking_color'] is not None and obj['non_stroking_color'] is not Nonereturn Truedef extract_text_and_tables(self, page):buttom = 0page = page.filter(self.keep_visible_lines)tables = page.find_tables()if len(tables) >= 1:# 表格数据count = len(tables)for table in tables:if table.bbox[3] < buttom:passelse:count -= 1top = table.bbox[1]text = self.check_lines(page, top, buttom)text_list = text.split('\n')for _t in range(len(text_list)):self.all_text[self.allrow] = {'page': page.page_number, 'allrow': self.allrow,'type': 'text', 'inside': text_list[_t]}self.allrow += 1buttom = table.bbox[3]new_table = table.extract()r_count = 0for r in range(len(new_table)):row = new_table[r]if row[0] is None:r_count += 1for c in range(len(row)):if row[c] is not None and row[c] not in ['', ' ']:if new_table[r - r_count][c] is None:new_table[r - r_count][c] = row[c]else:new_table[r - r_count][c] += row[c]new_table[r][c] = Noneelse:r_count = 0end_table = []for row in new_table:if row[0] != None:cell_list = []cell_check = Falsefor cell in row:if cell != None:cell = cell.replace('\n', '')else:cell = ''if cell != '':cell_check = Truecell_list.append(cell)if cell_check == True:end_table.append(cell_list)end_table = self.drop_empty_cols(end_table)for row in end_table:self.all_text[self.allrow] = {'page': page.page_number, 'allrow': self.allrow,'type': 'excel', 'inside': str(row)}# self.all_text[self.allrow] = {'page': page.page_number, 'allrow': self.allrow, 'type': 'excel',# 'inside': ' '.join(row)}self.allrow += 1if count == 0:text = self.check_lines(page, '', buttom)text_list = text.split('\n')for _t in range(len(text_list)):self.all_text[self.allrow] = {'page': page.page_number, 'allrow': self.allrow,'type': 'text', 'inside': text_list[_t]}self.allrow += 1else:#文本数据text = self.check_lines(page, '', '')text_list = text.split('\n')for _t in range(len(text_list)):self.all_text[self.allrow] = {'page': page.page_number, 'allrow': self.allrow,'type': 'text', 'inside': text_list[_t]}self.allrow += 1first_re = '[^计](?:报告(?:全文)?(?:(修订版)|(修订稿)|(更正后))?)$'end_re = '^(?:\d|\\|\/|第|共|页|-|_| ){1,}'if self.last_num == 0:try:first_text = str(self.all_text[1]['inside'])end_text = str(self.all_text[len(self.all_text) - 1]['inside'])if re.search(first_re, first_text) and not '[' in end_text:self.all_text[1]['type'] = '页眉'if re.search(end_re, end_text) and not '[' in end_text:self.all_text[len(self.all_text) - 1]['type'] = '页脚'except:print(page.page_number)else:try:first_text = str(self.all_text[self.last_num + 2]['inside'])end_text = str(self.all_text[len(self.all_text) - 1]['inside'])if re.search(first_re, first_text) and '[' not in end_text:self.all_text[self.last_num + 2]['type'] = '页眉'if re.search(end_re, end_text) and '[' not in end_text:self.all_text[len(self.all_text) - 1]['type'] = '页脚'except:print(page.page_number)self.last_num = len(self.all_text) - 1def process_pdf(self):for i in range(len(self.pdf.pages)):self.extract_text_and_tables(self.pdf.pages[i])def save_all_text(self, path):with open(path, 'w', encoding='utf-8') as file:for key in self.all_text.keys():file.write(json.dumps(self.all_text[key], ensure_ascii=False) + '\n')def process_all_pdfs_in_folder(folder_path):file_paths = glob.glob(f'{folder_path}/*')file_paths = sorted(file_paths, reverse=True)for file_path in file_paths:print(file_path)try:processor = PDFProcessor(file_path)processor.process_pdf()save_path = 'RAG_ASMPLE_DATAS_TXTS/' + file_path.split('/')[-1].replace('.pdf', '.txt')processor.save_all_text(save_path)except:print('check')if __name__ == '__main__':# 需要解析的pdf文件路径pdf_path = r'C:\Users\WWS\RAG_ASMPLE_DATAS\2020-02-26__上海爱旭新能源股份有限公司__600732__爱旭股份__2019年__年度报告.pdf'# pdf解析后的txt内容文件out_path = r'C:\Users\WWS\RAG_ASMPLE_DATAS\2020-02-26__上海爱旭新能源股份有限公司__600732__爱旭股份__2019年__年度报告.txt'processor = PDFProcessor(pdf_path)processor.process_pdf()processor.save_all_text(out_path)
参考
版面分析–PDF解析神器pdfplumber
版面分析–富文本txt读取
补充
提取PDF中的图片并保存到本地
import pdfplumber
file_name = "**.pdf"# 需要解析的pdf的文件路径
output_file = "**.xlsx" # pdf解析后的内容with pdfplumber.open(file_name) as pdf:#获取第一页first_page = pdf.pages[1]print('页码:', first_page.page_number)print('page width:', first_page.width)print('page height:', first_page.height)# get the first page texttext = first_page.extract_text()print(text)# 获取第一页图片,获取到的是一个列表,列表中存储的是字典imgs = first_page.imagesi = 0for img in imgs:# 获取图片的二进制流print(img['stream'].get_data())with open(output_file, mode='wb') as f2:f2.write(img['stream'].get_data())
提取pdf 表格文本,保存为excel文件
import pdfplumber
from openpyxl import Workbook# 保存表格,需要安装openpyxl
file_name = '**.pdf'
output_file = '**.xlsx'
with pdfplumber.open(file_name) as pdf:page01 = pdf.pages[0]table = page01.extract_table()workbook = Workbook()sheet = workbook.activefor row in table:sheet.append(row)workbook.save(filename=output_file)
提取PDF表格 文本
import pdfplumber
file_name = '**.pdf'
output_file = '**.txt'
with pdfplumber.open(file_name) as p:page_count = len(p.pages)# 统计文档的页数for i in range(0, page_count):page = p.pages[i]# 提取每页的对象并存储textdata = page.extract_table()#提取每页的表格文字信息# table2 = page01.extract_tables()# 提取多个表格data = open(output_file , 'a') # 将 表格文字存放在需要存储的文档里面data.write(textdata )# 文档内容写入
提取PDF纯文本
import pdfplumber
file_name = '**.pdf'
output_file = '**.txt'
with pdfplumber.open(file_name) as p:page_count = len(p.pages)# 统计文档的页数for i in range(0, page_count):page = p.pages[i]# 提取每页的对象并存储textdata = page.extract_text()#提取每页的文字信息data = open(output_file , 'a') # 将 表格文字存放在需要存储的文档里面data.write(textdata )# 文档内容写入读取富文本txt
python 读取文件函数有三种 read()、readline()、readlines()
- read() 一次性读取所有文本
- readline() 读取第一行的内容
- readlines() 读取全部内容,以数列的格式返回
with open('rag_datas/story.txt', 'r', encoding='utf-8' ) as f:data = f.read()print(data)
with open('rag_datas/story.txt', 'r', encoding='utf-8' ) as f:data = f.readline()print(data)
with open('rag_datas/story.txt', 'r', encoding='utf-8' ) as f:for line in f.readlines():line = line.strip('\n')print(line)
相关文章:
)
pdf 文件版面分析--pdfplumber (python 文档解析提取)
pdfplumber 的特点 1、它是一个纯 python 第三方库,适合 python 3.x 版本 2、它用来查看pdf各类信息,能有效提取文本、表格 3、它不支持修改或生成pdf,也不支持对pdf扫描件的处理 import glob import pdfplumber import re from collection…...

PostgreSQL的学习心得和知识总结(一百四十三)|深入理解PostgreSQL数据库之Support event trigger for logoff
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...
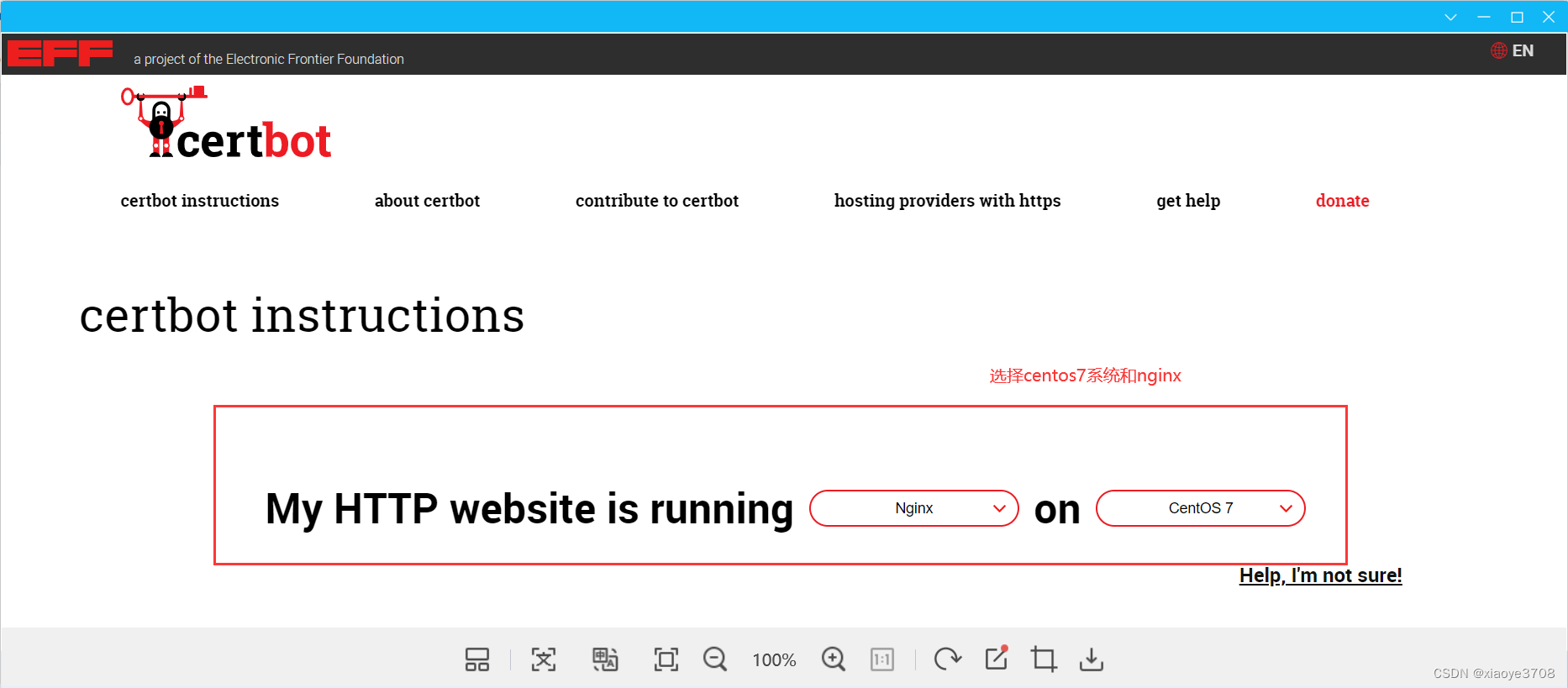
https免费证书获取
获取免费证书的网址: Certbot 1. 进入你的linux系统,先安装snapd, yum install snapd 2. 启动snapd service snapd start 3.安装 Certbot snap install --classic certbot 注意如下出现此错误时,需要先建立snap 软连接后&am…...

C语言 | Leetcode C语言题解之第74题搜索二维矩阵
题目: 题解: bool searchMatrix(int** matrix, int matrixSize, int* matrixColSize, int target) {int m matrixSize, n matrixColSize[0];int low 0, high m * n - 1;while (low < high) {int mid (high - low) / 2 low;int x matrix[mid /…...
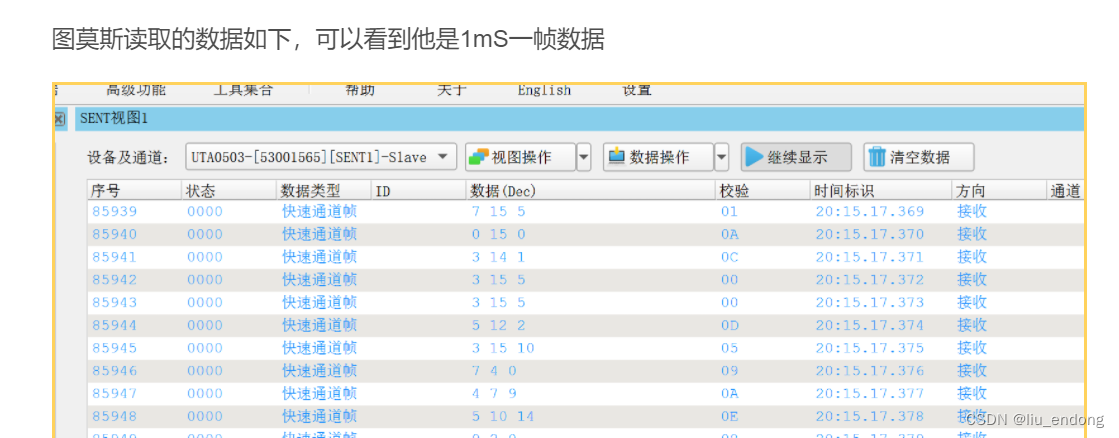
杰发科技AC7840——软件Sent_HAL39X
0. 序 使用PWM模拟Sent测试下7840的软件sent功能。 参考链接:SENT协议应用笔记 - TechPlus汽车工坊的文章 - 知乎 SENT协议 1. Sent功能测试 使用提供的软件Sent代码在7840上测试,接收数据OK 2. 参考资料 3. 数据解析 我们个根据上述参考资料尝试解析…...

IOS 开发 - block 使用详解
1.Blobk的定义 block的写法相对难记,不必司机应被,只需要在xcode里打出"inlineBlock"--回车, 系统会自动帮你把基础版写法给你匹配出来 //Block的基础声明//等号""之前是blobk的声明,等号“”后面是block的实现/*returnType:返回类型(void、int、String *…...
BUU-[极客大挑战 2019]Http
考察点 信息收集 http构造请求数据包 题目 解题步骤 参考文章:https://zhuanlan.zhihu.com/p/367051798 查看源代码 发现有一个a标签,但是οnclick"return false"就是点击后不会去跳转到Secret.php的页面 所以我就自己拼接url http://no…...
开发Web3 ETF的技术难点
开发Web3 ETF(Exchange-Traded Fund,交易所交易基金)软件时,需要注意以下几个关键问题。开发Web3 ETF软件是一个复杂的过程,涉及到金融、法律和技术多个领域的专业知识。开发团队需要综合考虑上述问题,以确…...

【K8s】Kubectl 常用命令梳理
Kubectl常用命令梳理 下面包含大致涵盖命令只需要替换对应的Pod \ NameSpace 查看 命名空间 是 ’worktest2‘ 下 名字包括 ’todo‘的所有 Pod kubectl -n worktest2 get pod|grep todo查看 所有命名空间下 名字包括 ’todo‘的所有 Pod kubectl get pods --all-namespace…...

机器学习-监督学习
监督学习是机器学习和人工智能中的一个重要分支,它涉及使用已标记的数据集来训练算法,以便对数据进行分类或准确预测结果。监督学习的核心在于通过输入数据(特征)和输出数据(标签或类别)之间的关系…...
搭建Docker私服镜像仓库Harbor
1、概述 Harbor是由VMware公司开源的企业级的Docker Registry管理项目,它包括权限管理(RBAC)、LDAP、日志审核、管理界面、自我注册、镜像复制和中文支持等功能。 Harbor 的所有组件都在 Dcoker 中部署,所以 Harbor 可使用 Docker Compose 快速部署。 …...
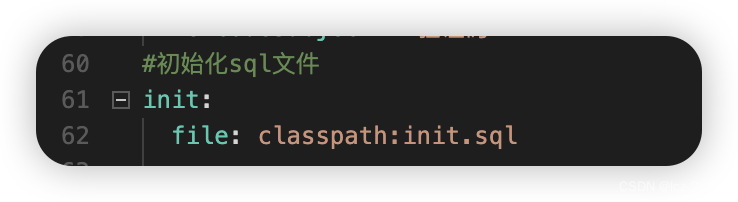
SpringBoot自定义初始化sql文件 支持多类型数据库
我在resources目录下有init.sql初始化sql语句 指定sql文件的地址 sql内容如下: /*角色表*/ INSERT INTO #{schema}ccc_base_role (id, create_time, create_user_id, is_delete, role_name, status, update_time, update_user_id) VALUES(b89e30d81acb88448d412…...

nginx--FastCGI
CGI 概念 nginx通过与第三方基于协议实现,即通过某种特定协议将客户端请求转发给第三方服务处理,第三方服务器会新建新的进程处理用户的请求,处理完成后返回数据给Nginx并回收进程(下次处理有需要新建),最后nginx在返回给客户端…...
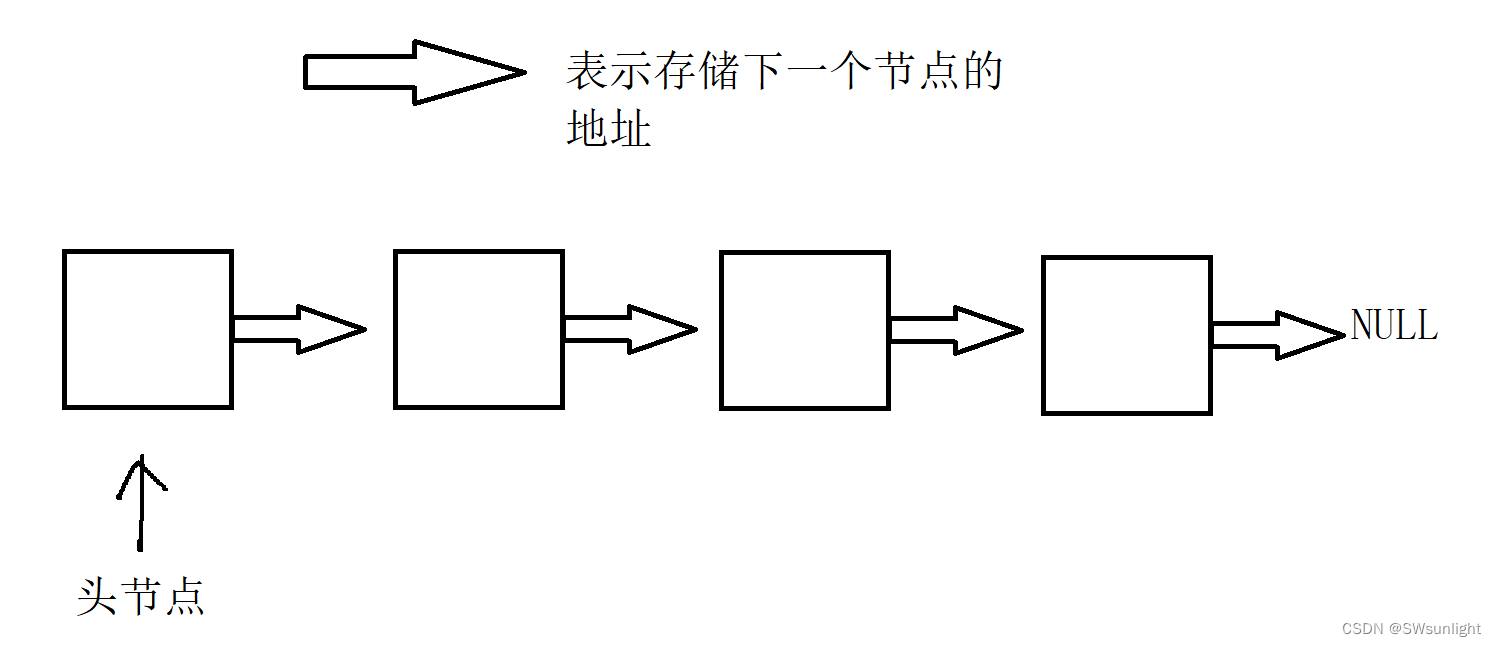
【数据结构】浅谈
✨✨✨专栏:数据结构 🧑🎓个人主页:SWsunlight 目录 一、概念: 二、物理结构: 1、顺序存储结构: 2、链式存储结构: 3、数据索引存储结构: 4、数据散列存储结构…...
简洁大气APP下载单页源码
源码介绍 简洁大气APP下载单页源码,源码由HTMLCSSJS组成,记事本打开源码文件可以进行内容文字之类的修改,双击html文件可以本地运行效果,也可以上传到服务器里面 效果截图 源码下载 简洁大气APP下载单页源码...

ICode国际青少年编程竞赛- Python-4级训练场-复杂嵌套for循环
ICode国际青少年编程竞赛- Python-4级训练场-复杂嵌套for循环 1、 for i in range(4):Dev.step(i6)for j in range(3):Dev.turnLeft()Dev.step(2)2、 for i in range(4):Dev.step(i3)for j in range(4):Dev.step(2)Dev.turnRight()Dev.step(-i-3)Dev.turnRight()3、 for i …...
Idea入门:一分钟创建一个Java工程
一,新建一个Java工程 1,启动Idea后,选择 [New Project] 2,完善工程信息 填写工程名称,根据实际用途取有意义的英文名称选择Java语言,可以看到还支持Kotlin、Javascript等语言选择包管理和项目构建工具Mav…...

QGraphicsView实现简易地图8『缓存视口周边瓦片』
前文链接:QGraphicsView实现简易地图7『异步加载-多瓦片-无底图』 前7篇的地图加载,都采用最少瓦片数量的算法,即用最少数量的瓦片覆盖视口,以获得最快的加载速度。但是这样会带来一个问题,那就是每当移动地图时&#…...
)
如何在Java项目中使用Spring Boot快速连接达梦数据库(DM)
前言 在Java开发领域,Spring Boot凭借其简洁快速的特性成为现代应用开发的首选框架。本文将详细介绍如何在Spring Boot项目中整合JDBC以快速连接达梦数据库(DM),并提供一个简单的示例来验证连接是否成功。 一、环境准备与依赖配置 在开始之前…...

QT中的容器
Qt中的容器 关于Qt中的容器类,下面我们来进行一个总结: Qt的容器类比标准模板库(STL)中的容器类更轻巧、安全和易于使用。这些容器类是隐式共享和可重入的,而且他们进行了速度和存储的优化,因此可以减少可…...

基于硬件虚拟化的AI智能体安全隔离方案Clawcage设计与实现
1. 项目概述:为AI智能体打造一个坚不可摧的“笼子”如果你最近在尝试运行一些本地的AI智能体,比如Claude Desktop、Cursor的Agent模式,或者各种开源的AI助手工具,心里可能总会有点打鼓。这些工具功能强大,但它们背后运…...
)
LInux(gcc处理器,库文件,动静态库)
//Dbug版本为可调试版本 生成的可执行的文件在包含调试信息 //Release版本为用户版本 无可调试信息 用gcc生成的就是Release版本 //用gcc生成的就是Release版本 -g 可以变成Dbug版本 //e.g gcc 1.c -o 1 -g // 变成Dbug版本后 输入gdb 文件名 进入调试模式 // 在完成调试…...
)
【仅限首批内测团队获取】AI Agent Serverless标准化交付套件(含Terraform模块+OpenTelemetry追踪模板+合规审计清单)
更多请点击: https://intelliparadigm.com 第一章:AI Agent Serverless应用的演进逻辑与范式跃迁 AI Agent 与 Serverless 的融合并非技术堆叠,而是计算范式在智能体自治性、事件驱动粒度和资源契约关系三重维度上的结构性重构。早期云函数仅…...

保姆级教程:用Lumerical FDTD参数扫描功能,分析WO3薄膜厚度对反射率的影响
从零到精通:Lumerical FDTD参数扫描在薄膜光学设计中的实战指南 在光电材料研究和器件设计中,薄膜厚度的精确控制往往直接影响器件的光学性能。以三氧化钨(WO₃)薄膜为例,其厚度变化会显著改变反射光谱特性,…...

常见404 500错误解析
一、常见404 500错误解析浏览器:用户发起请求的入口,地址栏输入 URL、AJAX 请求都从这里发。服务器:本质就是一台电脑,Tomcat 在这里负责接收请求、分发处理。前端层:存放静态页面,处理页面渲染、用户交互…...

OpenClaw Memory启动器:快速构建AI记忆系统的开源脚手架
1. 项目概述:一个为AI记忆系统设计的开源启动器最近在折腾AI应用开发,特别是那些需要长期记忆和上下文管理的项目时,发现了一个挺有意思的GitHub仓库:christiancaviedes/openclaw-memory-starter。这本质上是一个为“OpenClaw Mem…...

云原生监控一体化实践:从零部署mco实现指标、日志、追踪统一管理
1. 项目概述:一个面向现代容器化应用的开源监控解决方案最近在梳理团队的技术栈,发现随着微服务和Kubernetes的普及,传统的监控体系越来越力不从心。我们需要的不仅仅是对主机和进程的监控,更需要能深入理解容器、Pod、Service以及…...

芯片晶圆平面度如何测量?半导体制造中的光学形貌检测方案
晶圆作为集成电路的核心承载基片,表面形貌的精度直接关系到光刻聚焦质量、芯片电学性能及最终良率。从8英寸到12英寸的大尺寸晶圆制造中,平面度、翘曲度(Warp)、总厚度变化(TTV)及局部平面度(SF…...

MCP协议实战:构建AI智能体任务管理服务器与二次开发指南
1. 项目概述:一个为AI智能体“开眼”的MCP服务器最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解为给大模型(比如Claude、GPT-4&am…...

Arm编译器在嵌入式开发中的优化实践
1. Arm编译器嵌入式开发环境概述在嵌入式系统开发领域,工具链的选择往往决定了最终产品的性能上限。作为Arm架构的"原生"编译器,Arm Compiler for Embedded凭借其深度优化的代码生成能力,在物联网设备、工业控制器等资源受限场景中…...