基于docker 的elasticsearch冷热分离及生命周期管理
文章目录
- 冷热集群架构的应用场景
- 冷热集群架构的优势
- 冷热集群架构实战
- 搭建集群
- 索引生命周期管理
- 认识索引生命周期
- 索引生命周期管理的历史演变
- 索引生命周期管理的基础知识
- Rollover:滚动索引
冷热集群架构的应用场景
某客户的线上业务场景如下:系统每天增加6TB日志数据,高峰时段的写入和查询频率都很高,导致Elasticsearch集群压力大,经常出现查询缓慢的问题。
目前采用冷热集群架构,其中热节点使用SSD,并具有良好的索引和搜索性能,将数据保存4天后推送到温节点中,并使用HDD进行存储。改善架构后,集群性能有极大提升。
总之,在成本有限的情况下,让客户专注于实时数据和历史数据之间的硬件隔离可以最大化解决客户反映的检索响应慢的问题。
冷热集群架构的优势
Elasticsearch集群采用冷热集群架构会具有以下优势。
1)有效降低存储成本:将不常用的数据存储在冷节点上,可以减小热节点上索引大小并降低存储成本。这可有效降低硬件成本并提高索引查询效率。
2)更好地管理数据:将不同类型的数据分配到不同类型的节点上,可以更好地管理数据。这为索引生命周期管理提供了保障。
3)提高查询性能:将热节点用于处理最常访问的数据,而将冷节点用于存储不常用的数据,可以缩短查询响应时间并提高查询性能。
4)优化集群性能:将不同类型的任务分配给不同类型的节点,可以避免资源争夺现象,从而提高整个集群系统性能。
5)更好的可扩展性:使用冷热集群架构,在需要适应数据量增长或其他需求变化时,运维人员可以更容易地扩展集群、添加或删除节点。综上所述,Elasticsearch的冷热集群架构可以提高查询性能、降低存储成本、优化集群性能、更好地管理数据和提高可扩展性。这些优势使其成为处理PB级时序大数据的理想选择。
冷热集群架构实战
搭建集群
首先搭建一个具有3个节点的集群,划分冷、温、热节点角色。在节点层面设置节点类型,分别如下所示。
version: '2.2'
services:cerebro:image: lmenezes/cerebro:0.8.3container_name: hwc_cerebroports:- "9000:9000"command:- -Dhosts.0.host=http://elasticsearch:9200networks:- hwc_es7netkibana:image: docker.elastic.co/kibana/kibana:7.1.0container_name: hwc_kibana7environment:- XPACK_GRAPH_ENABLED=true- TIMELION_ENABLED=true- XPACK_MONITORING_COLLECTION_ENABLED="true"ports:- "5601:5601"networks:- hwc_es7netelasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_hotenvironment:- cluster.name=geektime-hwc- node.name=es7_hot- node.attr.box_type=hot- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_hot:/usr/share/elasticsearch/dataports:- 9200:9200networks:- hwc_es7netelasticsearch2:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_warmenvironment:- cluster.name=geektime-hwc- node.name=es7_warm- node.attr.box_type=warm- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_warm:/usr/share/elasticsearch/datanetworks:- hwc_es7netelasticsearch3:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_coldenvironment:- cluster.name=geektime-hwc- node.name=es7_cold- node.attr.box_type=cold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_cold:/usr/share/elasticsearch/datanetworks:- hwc_es7netvolumes:hwc_es7data_hot:driver: localhwc_es7data_warm:driver: localhwc_es7data_cold:driver: localnetworks:hwc_es7net:driver: bridge
三个节点冷热集群架构启动后,使用如下命令查看节点。
GET /_cat/nodes?v

查询节点属性使用如下命令
GET _cat/nodeattrs
es7_warm 172.21.0.6 172.21.0.6 ml.machine_memory 9698672640
es7_warm 172.21.0.6 172.21.0.6 ml.max_open_jobs 20
es7_warm 172.21.0.6 172.21.0.6 box_type warm
es7_warm 172.21.0.6 172.21.0.6 xpack.installed true
es7_cold 172.21.0.2 172.21.0.2 ml.machine_memory 9698672640
es7_cold 172.21.0.2 172.21.0.2 ml.max_open_jobs 20
es7_cold 172.21.0.2 172.21.0.2 box_type cold
es7_cold 172.21.0.2 172.21.0.2 xpack.installed true
es7_hot 172.21.0.4 172.21.0.4 ml.machine_memory 9698672640
es7_hot 172.21.0.4 172.21.0.4 box_type hot
es7_hot 172.21.0.4 172.21.0.4 xpack.installed true
es7_hot 172.21.0.4 172.21.0.4 ml.max_open_jobs 20方案一:在索引层面指定节点角色写入数据。
PUT mytest
{"settings":{"number_of_shards":1,"number_of_replicas":0,"index.routing.allocation.require.box_type":"cold"}
}
GET /_cat/shards/mytest?h=i,shard,p,node
mytest 0 p es7_cold
方案二:通过模板指定节点角色写入数据。
POST _template/my-template
{"index_patterns": "test-*","settings": {"index.number_of_replicas": "0","index.routing.allocation.require.box_type":"cold"}
}GET _template/my-templatePUT /test-01GET /_cat/shards/test-01?h=i,shard,p,node
索引生命周期管理
认识索引生命周期
在大规模系统中,特别是以日志、指标和实时时间序列为基础的系统中,集群索引的发展和变化遵循其固有规律。理论上来说,一旦创建了索引,它就可能永久存在。然而,在创建后,如果让索引无限制地扩张下去,则会演变成一个数据量庞大且过度膨胀的实体。这种情况可能导致一系列问题,例如,随着时间推移,时序数据和业务数据量逐步增加。
实际上,索引并非无限制存在的,举例如下。
❑集群单个分片的最大文档数上限约为20亿条(即232-1)。
❑根据官方的最佳实践建议,应将索引分片大小控制在30GB~50GB之间。
❑如果索引数据量过大,则可能出现健康问题,并导致整个集群核心业务停摆。
❑大型索引恢复所需时间远远超过小型索引。
❑大型索引检索单位速度较慢,并影响写入和更新操作。
❑在某些业务场景中用户更关注最近3天或7天的业务数据;而大型索引会将所有历史数据汇聚在一起,不利于查询特定需求的数据。
索引生命周期管理的历史演变
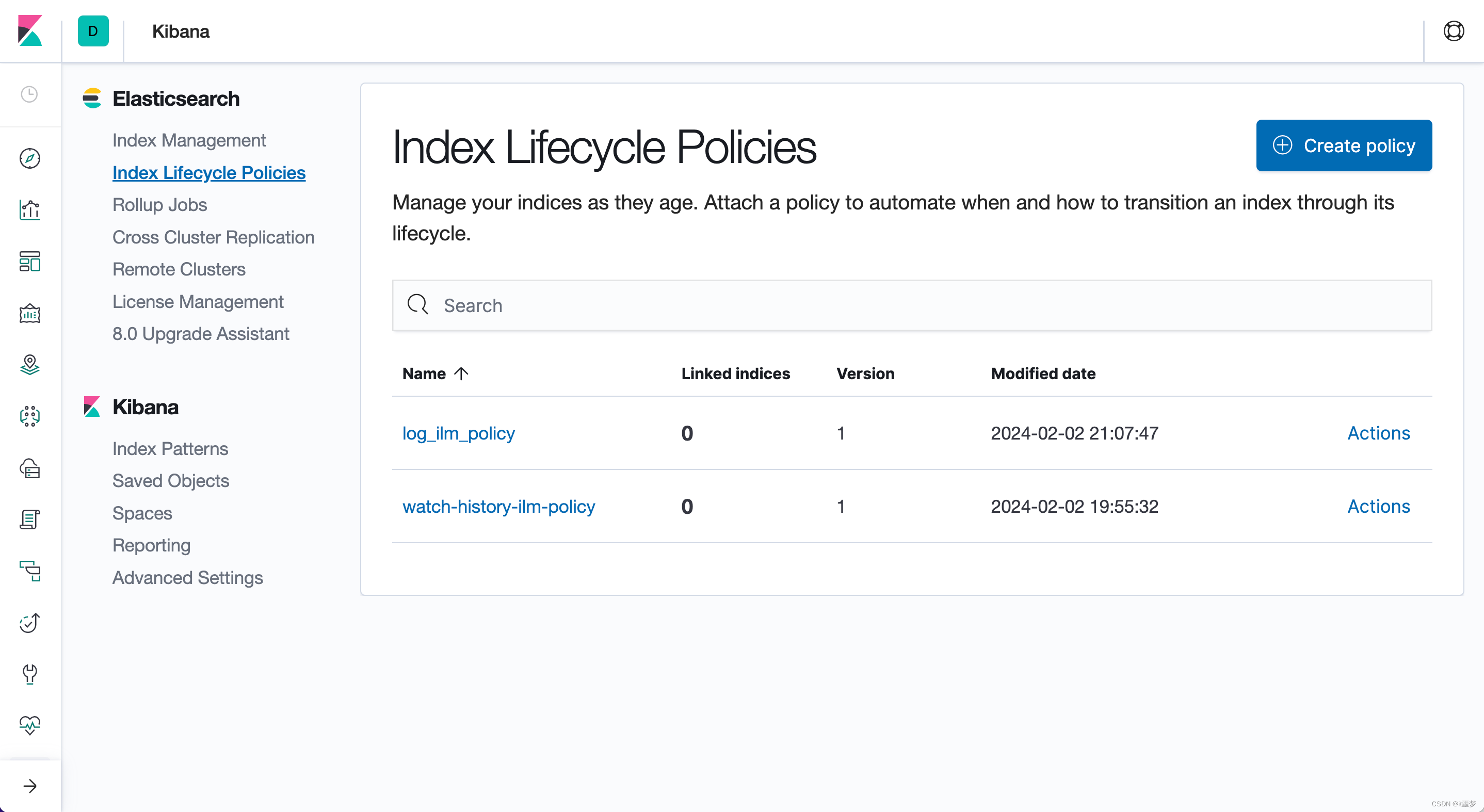
ILM(索引生命周期管理)是Elasticsearch 6.6(公测版)首次引入的功能,并于6.7版本正式推出。它是Elasticsearch的一部分,主要用于帮助用户管理索引。在没有ILM之前,索引生命周期的管理基于Rollover和Curator工具实现。Kibana 7.X版本提供了一个配置界面来进行索引生命周期管理,如图所示。
索引生命周期管理的基础知识
在3个节点的集群中,节点角色的设置分别如下。
❑节点node-1:主节点+数据节点+热节点。
❑节点node-2:主节点+数据节点+温节点。
❑节点node-3:主节点+数据节点+冷节点。
为了演示如何应用ILM,首先需要配置冷热架构,在上文中已经讲解了配置细节。如果磁盘数量不足,则待删除的冷数据在处理时具有最高优先级;如果硬件资源相对受限,则应将SSD作为热节点的首选配置。检索优先级最高的是热节点数据,因此检索热节点数据比检索全量数据的响应速度更快。
Rollover:滚动索引
自从Elasticsearch 5.X版本推出Rollover API以来,该API解决了使用日期作为索引名称的索引所具有的大小不均衡的问题。对于日志类数据而言,Rollover非常有用。通常情况下,我们按天对索引进行分割(如果数据量更大,则可以进一步拆分)。在没有Rollover之前,我们需要在程序中设置一个自动生成索引的模板。
以下讲解如何实践Rollover操作。
1)创建符合正则表达式规范(即中间是“-”字符并且后面是数字字符)的索引,并批量导入数据。否则会出现以下报错。

创建索引和导入数据操作如下。
###创建基于日期的索引
PUT my-index-20250709-0000001
{"aliases": {"my-alias": {"is_write_index": true}}
}
####批量导入数据
PUT my-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
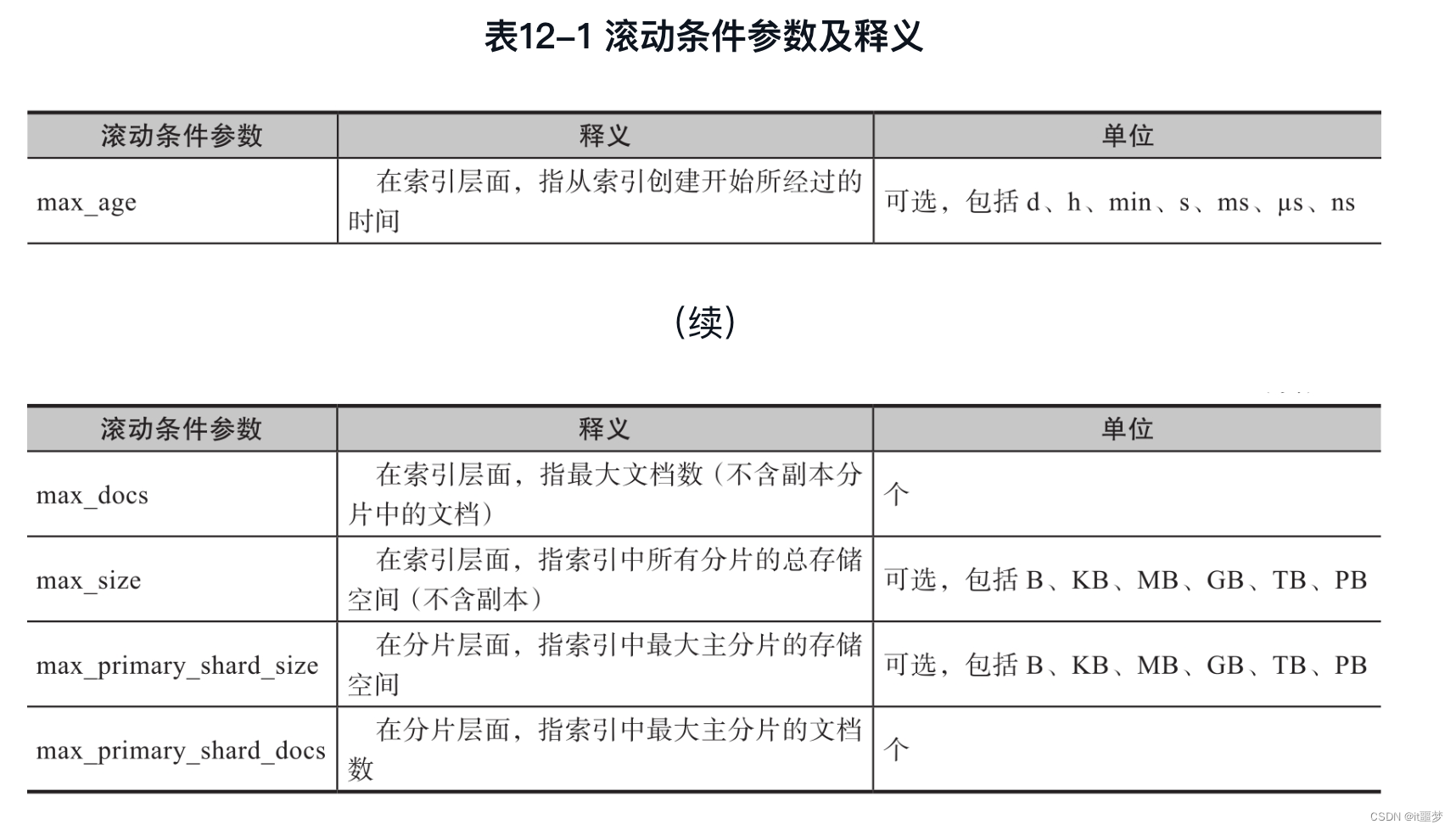
2)基于滚动的3个条件实现索引的滚动。
❑滚动条件1:数据写入时间超过7天。
❑滚动条件2:最大文档数超过5条。
❑滚动条件3:最大的主分片数大于50gb(这里的gb代表Gigabytes,可理解为GB)。
注意:
当3个条件是“或”的关系时,只要满足其中一个,索引就会滚动。在Elasticsearch 7.X版本中,可以设置的滚动条件如表12-1所示。
查看索引中所有主分片(pri.store.size)的总存储空间,命令如下。
GET _cat/indices?v&s=pri.store.size:desc
查看分片大小,且按照分片大小由大到小进行排序,命令行如下。其中p代表主分片,r代表副本分片。
GET /_cat/shards?v=true&s=store:desc
滚动索引操作如下。
# rollover滚动索引
POST my-alias/_rollover
{"conditions": {"max age": "7d","max docs": 5,"max_primary_shard_size": "50gb"}
}GET my-alias/ _count
#在满足滚动条件的前提下滚动索引
PUT my-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
#检索数据,验证滚动是否生效
GET my-alias/_search
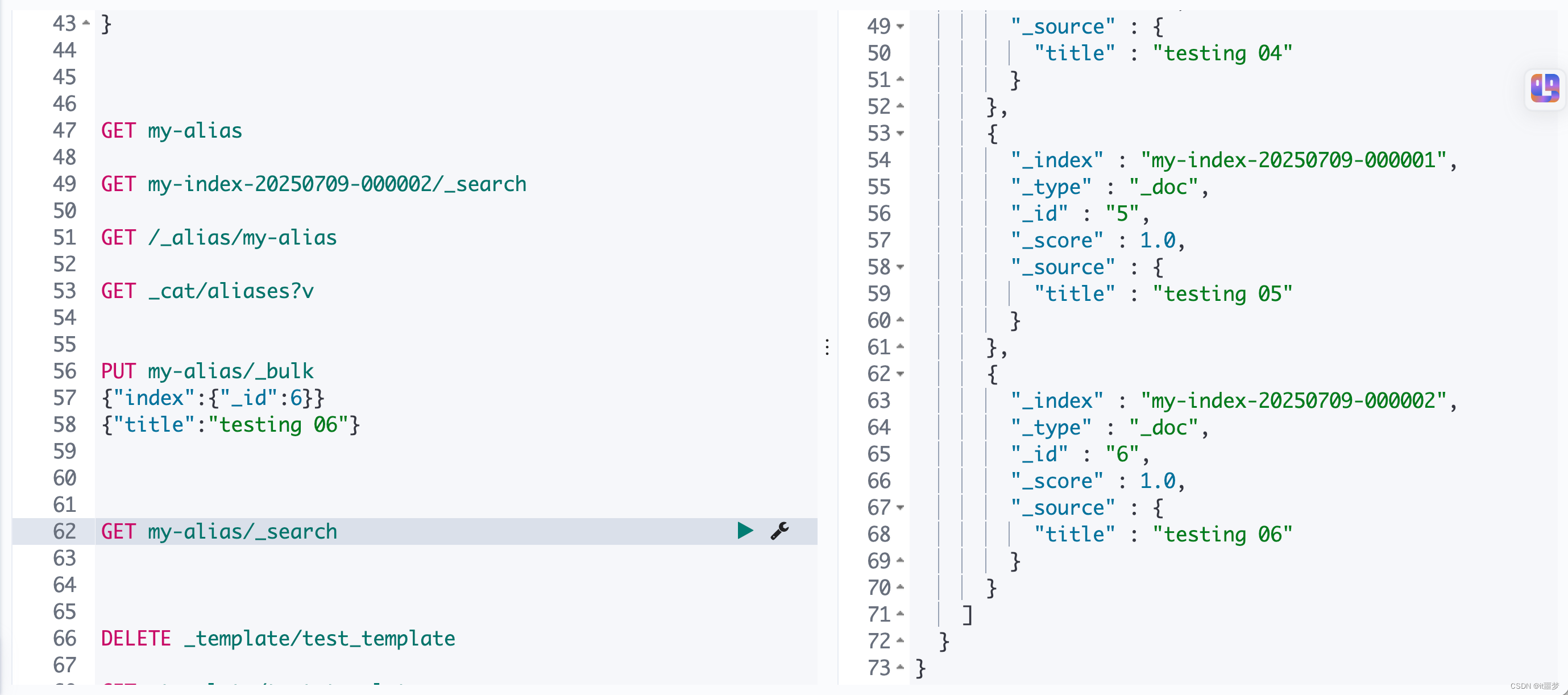
执行结果如下所示。我们可以清晰看到,插入第6条数据会触发max_docs:5的条件,原来的索引my-index-20250709-000001会继续保留,而新写入的第6条数据滚动到了新索引my-index-20250709-000002中。滚动索引操作的效果如图所示。
es 7.17.1
DELETE _template/test_templateGET _template/test_templatePUT _ilm/policy/my_policy
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_docs": 3 }}},"delete": {"min_age": "30d","actions": {"delete": {}}}}}
}PUT _template/test_template
{"order": 0,"index_patterns": ["test_*"],"settings": {"index": {"number_of_shards": "6","refresh_interval": "10s"},"lifecycle": {"name": "my_policy","rollover_alias" : "test_rollover"}},"mappings": {"properties": {"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"requestId": {"type": "keyword"},"title": {"type": "text","analyzer": "standard","fields": {"keyword": {"type": "keyword"}}}}},"aliases": {}
}PUT %3Ctest_%7Bnow%2Fd%7D-000001%3E
{"aliases": {"test_rollover": {"is_write_index": true}}
}GET %3Ctest_%7Bnow%2Fd%7D-000001%3EPOST /test_rollover/_rollover
{"conditions": {"max_docs": 3 }
}POST /test_rollover/_doc
{"businessInfo":"078"
}GET /test_rollover/_doc/_search## indices.lifecycle.poll_interval 索引生命周期策略默认是10分钟检查一次符合策略的索引GET _cluster/settings?include_defaults&flat_settingsGET _cat/nodeattrs?v&h=host,attr,value参考
https://juejin.cn/post/7217399337989488695#heading-3
https://help.aliyun.com/document_detail/178307.html
## 运行三个节点,分片 将box_type设置成 hot,warm和coldPUT _cluster/settings
{"persistent": {"indices.lifecycle.poll_interval":"1s"}
}PUT /_ilm/policy/log_ilm_policy
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_docs": 5}}},"warm": {"min_age": "10s","actions": {"allocate": {"include": {"box_type": "warm"}}}},"cold": {"min_age": "15s","actions": {"allocate": {"include": {"box_type": "cold"}}}},"delete": {"min_age": "20s","actions": {"delete": {}}}}}
}PUT /_template/log_ilm_template
{"index_patterns" : ["app_log-*"],"settings" : {"index" : {"lifecycle" : {"name" : "log_ilm_policy","rollover_alias" : "app_log"},"routing" : {"allocation" : {"include" : {"box_type" : "hot"}}},"number_of_shards" : "1","number_of_replicas" : "0"}},"mappings" : { },"aliases" : {}
}GET /_template/DELETE /_template/log_ilm_templatePUT %3Capp_log-%7Bnow%2Fs%7Byyyy.MM.dd-HHmm%7D%7D-000001%3E
{"aliases":{"app_log":{"is_write_index":true}}
}POST app_log/_doc
{"dfd":"qweqwe"
}DELETE app_log-2024.01.06-0749-000001GET app_log-2024.01.06-0800-000001/_settings- 安装 https://github.com/onebirdrocks/geektime-ELK
相关文章:
基于docker 的elasticsearch冷热分离及生命周期管理
文章目录 冷热集群架构的应用场景冷热集群架构的优势冷热集群架构实战搭建集群 索引生命周期管理认识索引生命周期索引生命周期管理的历史演变索引生命周期管理的基础知识Rollover:滚动索引 冷热集群架构的应用场景 某客户的线上业务场景如下:系统每天增…...
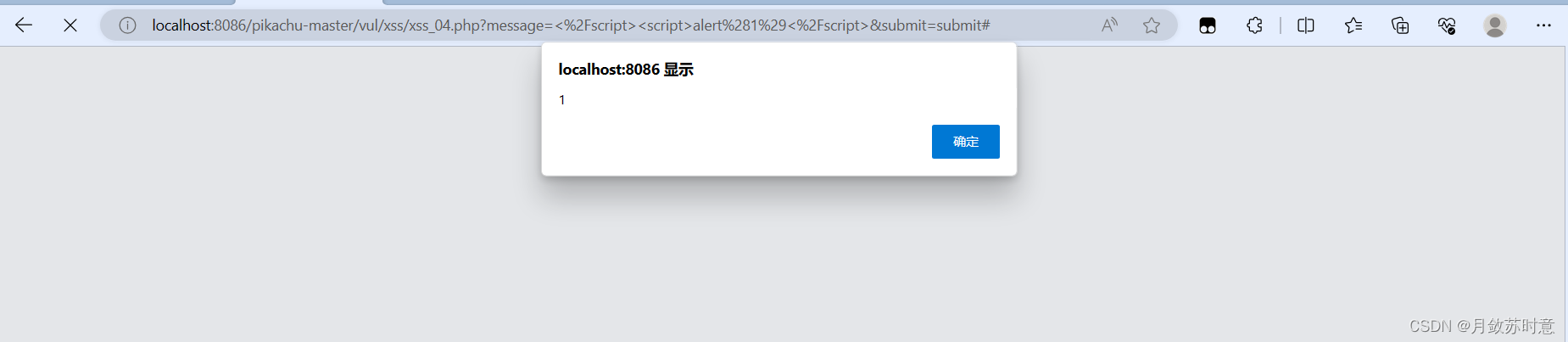
pikachu靶场(xss通关教程)
(注:若复制注入代码攻击无效,请手动输入注入语句,在英文输入法下) 反射型xss(get型) 1.打开网站 发现有个框,然后我们在框中输入一个“1”进行测试, 可以看到提交的数据在url处有显示…...

实验0.0 Visual Studio 2022安装指南
Visual Studio 2022 是一个功能强大的开发工具,对于计算机专业的学生来说,它不仅可以帮助你完成学业项目,还能为你将来的职业生涯打下坚实的基础。通过学习和使用 Visual Studio,你将能够更高效地开发软件,并在编程领域…...

数据结构之----线性表
线性表分为 顺序存储结构 和 链式存储结构 线性表的顺序存储结构: 线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。 1,顺序表的结构: #define MAXSIZE 20 typedef int El…...

thinkphp5.1 模型auto
在ThinkPHP5.1中,模型的自动完成功能可以通过在模型类中定义auto属性来实现。这个属性是一个数组,包含了需要自动填充的字段和对应的处理规则。 以下是一个简单的例子,展示了如何在ThinkPHP5.1的模型中使用自动完成功能: <?…...
企业微信创建应用(一)
登录到企业微信后台管理(https://work.weixin.qq.com/)进入自建应用(应用管理-应用-创建应用) 3.查看参数AgentId和 Secret 4.企业微信查看效果...

Cosmo Bunny Girl
可爱的宇宙兔女郎的3D模型。用额外的骨骼装配到Humanoid上,Apple混合了形状。完全模块化,包括不带衣服的身体。 技术细节 内置,包括URP和HDRP PDF。还包括关于如何启用URP和HDRP的说明。 LOD 0:面:40076,tris 76694,verts 44783 装配了Humanoid。添加到Humanoid中的其他…...

初始化linux数据盘(3TB)分区-格式化-挂载目录
场景说明:某云给我们服务器加载了一块3TB的硬盘扩容(没有直接扩,原因是原来的盘做的是mbr(什么年代了,谁干的)的分区,最大识别2TB) 确认磁盘 输入命令lsblk 查看数据盘信息 &#…...

NFS网络文件系统的应用
1.配置2台服务器要求如下: a)服务器1: 主机名:user-server.timinglee.org ip地址: 172.25.254.100 [rootserver100 桌面]# hostnamectl hostname user-server.timinglee.org [rootserver100 桌面]# ifconfig eth0: fl…...

AttributeError: module ‘PIL.Image‘ has no attribute ‘ANTIALIAS‘
问题描述 修改图片大小的时候,代码报错:AttributeError: module PIL.Image has no attribute ANTIALIAS 解决方案 在pillow的10.0.0版本中,ANTIALIAS方法被删除了。 方法1:修改版本(不推荐) pip instal…...

进程的共享主存通信实验
进程的共享主存通信 【预备知识】 共享存储区为进程提供了直接通过主存进行通信的有效手段,不像消息缓冲机制那样需要系统提供缓冲,也不像pipe机制那样需要事先建立一个特殊文件,而是由通信双方直接访问某些共享虚拟储存空间。在Linux中&…...

深度缓冲技术在AI去衣中的神奇作用
引言: 随着人工智能技术的飞速发展,其在图形处理和视觉领域的应用日益增多。AI去衣技术便是其中一个颇具争议但又技术上引人入胜的话题。今天,我们将深入探讨一项关键技术——深度缓冲(Depth Buffering),它…...

能效?性能?一个关于Windows下使用openssl speed进行速度测试的诡异问题
问题描述 最近的某个软件用到了openssl,所以就想着测试一下速度。我的电脑是惠普的,CPU是AMD Ryzen 7 PRO 6850HS,系统是Win11。我使用openssl自带的speed测试加密/解密的速度,命令大致如下: openssl speed -evp aes…...

block性能考虑和线程安全
性能考虑 频繁地创建和销毁大量的 block 可能会对性能造成影响,特别是当这些 block 被拷贝到堆上时。同时,block 捕获大量数据时也会增加内存使用。 在讨论性能考虑时,主要关注的是 block 的创建、拷贝到堆上以及捕获变量的成本。以下是针对…...

没有公网ip,如何实现外网访问内网?
目前拨号上网是最广泛的上网方式,这种方式优点是价格便宜,缺点是没有固定公网ip,每次重新您拨号ip地址都会变。如果有一台服务器,需要实现外网访问,在没有固定公网ip的环境下,该如何实现呢?使用…...

Python中如何将小数转化为百分数进行输出
小数转化为百分数 Python中如何将小数转化为百分数进行输出基本概念使用字符串格式化1. 使用字符串格式化操作符 %2. 使用str.format()方法3. 使用f-string(格式化字符串字面量) **重点内容**:**无论是通过使用%格式化操作符、str.format()方…...

加入全球少儿编程运动:Scratch让每个孩子都能成为创造者(Scratch最新版客户端和初/中/高级学习资料整理分享)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 文章内容 📒📝 安装与使用📝 社区与资源 🎈 获取方式 🎈⚓️ 相关链接 ⚓️ 📖 介绍 📖 你知道…...
引擎:主程渲染
一、引擎发展 二、引擎使用 1.游戏渲染流程 2.3D场景编辑器操作与快捷键 3.节点的脚本组件 脚本介绍 引擎执行流程 物体节点、声音组件\物理组件\UI组件、脚本组件 暴露变量到面板 4.节点的查找 基本查找 this.node:挂载当前脚本的节点A; this.nod…...

Java 高级面试问题及答案
问题6:请解释Java中的异常处理机制。 探讨过程: 异常处理是Java程序中错误处理的关键部分。正确地处理异常可以提高程序的稳定性和健壮性。 答案: Java中的异常处理机制允许程序在出现错误时,不会导致程序立即终止,而…...
)
邮件的安全认证(dkim/spf/dmarc)
dkim dkim是用来识别电子邮件合法以及完整性的一种技术手段,主要方式是通过非对称加密对邮件本身进行签名,邮件接收方可以使用发送方提供的公钥对签名进行校验,来确认邮件是否伪造或者被篡改。 如何查看dkim dkim签名被放在邮件原始内容的…...

STC32G单片机开发实战:GPIO模式配置与寄存器详解
1. STC32G单片机GPIO基础认知 第一次拿到STC32G开发板时,我习惯性地想用STM32那套HAL库来操作GPIO,结果发现根本行不通。这就像拿着汽车钥匙去开保险箱,虽然都是"开锁",但机制完全不同。STC32G作为增强型8051架构单片机…...

3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放
3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经下载了网易云音乐的NCM格式歌曲,却发现无法在其他设备上播放?这种专有加密格式虽然…...

【必记】2026年 {论文题} |范文记忆提纲-A
第一篇:规划绩效域《论信息系统项目的规划绩效域》一、项目背景段落1:平台立项背景目的:推进智能制造建筑工业化,达成高效、高质、低耗、低排发起方:市住建局平台模块:十大功能模块(市场监管、安…...

鲲鹏面对Agentic沙箱的思考与能力布局
Agent在今年迎来爆发式增长,传统云原生架构在Agent沙箱场景下面临启动慢、弹性差、资源冗余、隔离不足等五大痛点。鲲鹏沙箱以快照快启、共享Rootfs、超节点共享内存三大核心技术破局——将沙箱启动从分钟级压缩至毫秒级,通过写时复制(CoW&am…...

CANape测量启动报错“存储空间不足”的系统性排查与解决方案
1. 问题现象与根源剖析如果你是一名汽车电子工程师,或者从事车辆标定、诊断与测试工作,那么CANape这个软件对你来说,就像吃饭用的筷子一样熟悉。它强大的测量、标定和诊断功能,是我们在开发过程中不可或缺的利器。然而,…...

御坂翻译器:3分钟开启你的日语游戏无障碍之旅
御坂翻译器:3分钟开启你的日语游戏无障碍之旅 【免费下载链接】MisakaTranslator 御坂翻译器—Galgame/文字游戏/漫画多语种实时机翻工具 项目地址: https://gitcode.com/gh_mirrors/mi/MisakaTranslator 你是否曾经因为语言障碍而错过了那些精彩的日系游戏剧…...

HPM6750 LVGL性能优化:利用TCM与DMA突破嵌入式图形内存瓶颈
1. 项目概述:当LVGL遇上HPM6750,一场关于性能的极限探索最近在嵌入式图形界面开发的圈子里,一个话题热度很高:如何在HPM6750这颗高性能RISC-V MCU上,让LVGL的刷屏性能再上一个台阶?这听起来像是一个常规的优…...

Matlab 2020b隐藏技能:用Image Labeler制作自定义数据集,轻松喂给你的深度学习模型
Matlab 2020b图像标注实战:从零构建医学影像分割数据集 在医学影像分析领域,数据标注的质量直接决定了深度学习模型的性能上限。许多研究者花费大量时间调试模型结构,却忽略了最基础的数据准备环节。Matlab 2020b内置的Image Labeler工具&am…...

别再用strlen了!C++里sizeof和字符数组的坑,我帮你踩完了
别再用strlen了!C里sizeof和字符数组的坑,我帮你踩完了 在C编程中,处理字符串和字符数组时,sizeof和strlen这两个看似简单的概念常常让初学者陷入困惑。特别是在信息学竞赛或日常编程中,错误地使用它们可能导致难以察…...

C++中如何调用C语言的代码实现
为什么要是用 extern "C"在进行C开发的时候,由于C、C编译规则是不同的。C编译函数方法是 使用mangle的技术 。123456789101112void func(int age) {}void func(int age, int height) {}/*如果有这两个函数要被调用,在C语言中函数重载是不允许的…...