77. writerows写入多行
文章目录
- 1. 目标任务
- 2. 准备工作
- 3. writerow单行写入
- 4. writerows多行写入
- 5. a以追加的模式写入值
- 6. 总结
1. 目标任务
-
新建【各班级成绩】文件夹;
-
在该文件夹下新建一个【1班成绩单.csv】文件;
-
在该文件中写入下面的内容:
成绩 姓名
刘一 100
陈二 90
张三 80
李四 70
王五 60
2. 准备工作
-
在电脑D盘新建一个【77】文件夹。
-
用VScode编辑器打开【77】文件夹。
-
在【77】文件夹中新建一个
77.py文件。 -
打家在
77.py文件中编写代码。
3. writerow单行写入
【要写入的内容】
成绩 姓名
刘一 100
陈二 90
张三 80
李四 70
王五 60
第一行成绩 姓名是表头。
后面的5行是要写入的内容。
要写入的值有5行,我们需要用5个字典存储要写入的值。
【体验代码】
# 导入os 模块,用于创建文件目录
import os
# 导入 csv 模块,用于操作CSV文件
import csv# mkdir作用是创建目录
# 相对路径
os.mkdir("各班级成绩")# 用字典存储要写入CSV文件的信息
dict1 = {'姓名': '刘一', '成绩': '100'}
dict2 = {'姓名': '陈二', '成绩': '90'}
dict3 = {'姓名': '张三', '成绩': '80'}
dict4 = {'姓名': '李四', '成绩': '70'}
dict5 = {'姓名': '王五', '成绩': '60'}# 设置文件的表头,即列名
header = ['姓名', '成绩']# 文件的相对路径
file_path = r'各班级成绩\1班成绩单.csv'# 以自动关闭文件的方式创建文件对象
with open(file_path, 'w', encoding='utf-8', newline="") as f:# 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)# 写入文件的表头dw.writeheader()# writerow每次写入一行dw.writerow(dict1)dw.writerow(dict2)dw.writerow(dict3)dw.writerow(dict4)dw.writerow(dict5)
【对象语法回顾】
这里对几个大家比较陌生的语法点进行回顾。
回顾的次数多了,它就是你脑子里的东西了。
# 以自动关闭文件的方式创建文件对象
with open(file_path, 'w', encoding='utf-8', newline="") as f:
f是是with open 语句创建的文件对象。
# 实例化类 DictWriter(),得到 DictWriter 对象
dw = csv.DictWriter(f, fieldnames=header)
实例化列,创建对象语法:
对象名=类名()
dw是实例化类后创建的csv.DictWriter对象。
dw是对象名。
csv是模块名。
DictWriter是类名,作用是用字典的形式写入。
# writerow每次写入一行
dw.writerow(dict1)
调用类的方法语法:
对象名.方法名(值,…)
dw是对象名。
writerow是方法名,作用是每次写入一行。
dict1是要写入的值。
运行上面的代码,我们成功向CSV文件写入了上述5行值。

上面的代码我们写入5行值,调用了5次writerow方法。
# writerow每次写入一行
dw.writerow(dict1)
dw.writerow(dict2)
dw.writerow(dict3)
dw.writerow(dict4)
dw.writerow(dict5)
这样的写法太复杂了,不符合Python代码简洁的特性。
上述5行代码我们可以用一行代码进行替换。
# writerows多行写入
dw.writerows([dict1,dict2,dict3,dict4,dict5])
4. writerows多行写入
writerow:CSV模块中,写入一行数据。
writerows:CSV模块中,写入多行数据。
【体验代码】
# 导入 csv 模块,用于操作CSV文件
import csv# 用字典存储要写入CSV文件的信息
dict1 = {'姓名': '刘一', '成绩': '100'}
dict2 = {'姓名': '陈二', '成绩': '90'}
dict3 = {'姓名': '张三', '成绩': '80'}
dict4 = {'姓名': '李四', '成绩': '70'}
dict5 = {'姓名': '王五', '成绩': '60'}# 设置文件的表头,即列名
header = ['姓名', '成绩']# 文件的相对路径
file_path = r'各班级成绩\1班成绩单.csv'# 以自动关闭文件的方式创建文件对象
with open(file_path, 'w', encoding='utf-8', newline="") as f:# 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)# 写入文件的表头dw.writeheader()# writerows多行写入dw.writerows([dict1, dict2, dict3, dict4, dict5])
【温馨提示】
上面这段代码我删除了os相关的语句(下面的代码被删除):
# 导入os 模块,用于创建文件目录
import os# mkdir作用是创建目录
# 相对路径
os.mkdir("各班级成绩")
因为【各班级成绩】文件夹已经存在,如果我们在创建该目录,程序会报错。
【易错解析】
大家注意writerows的参数是一个列表类型:
# writerows多行写入
dw.writerows([dict1, dict2, dict3, dict4, dict5])
很多同学会写成下面这样的形式:
# writerows多行写入
dw.writerows(dict1, dict2, dict3, dict4, dict5)
没有列表类型,数据是会报错的。
5. a以追加的模式写入值

上面的代码with open语句的写入模式即mode参数都是w。
w就是不管我们的文件之前有什么内容,只要选用了w模式写入,之前的内容都会被覆盖。
a是追加模式,追加模式就是保留原有的内容。
下面我们将mode参数修改为a。
# 以自动关闭文件的方式创建文件对象
with open(file_path, 'a', encoding='utf-8', newline="") as f:
【体验代码】
# 导入 csv 模块,用于操作CSV文件
import csv# 用字典存储要写入CSV文件的信息
dict1 = {'姓名': '刘一', '成绩': '100'}
dict2 = {'姓名': '陈二', '成绩': '90'}
dict3 = {'姓名': '张三', '成绩': '80'}
dict4 = {'姓名': '李四', '成绩': '70'}
dict5 = {'姓名': '王五', '成绩': '60'}# 设置文件的表头,即列名
header = ['姓名', '成绩']# 文件的相对路径
file_path = r'各班级成绩\1班成绩单.csv'# 以自动关闭文件的方式创建文件对象
with open(file_path, 'a', encoding='utf-8', newline="") as f:# 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)# 写入文件的表头dw.writeheader()# writerows多行写入dw.writerows([dict1, dict2, dict3, dict4, dict5])
运行代码,得到的结果如下:

观察输出结果,注意绿色框的内容。
这里多了一个表头是我们不需要的,那怎么办呢?
writeheade是写入表头的意思。
删除这行代码就没有表头了。
# 写入文件的表头
dw.writeheader()
【体验代码】
# 导入 csv 模块,用于操作CSV文件
import csv# 用字典存储要写入CSV文件的信息
dict1 = {'姓名': '刘一', '成绩': '100'}
dict2 = {'姓名': '陈二', '成绩': '90'}
dict3 = {'姓名': '张三', '成绩': '80'}
dict4 = {'姓名': '李四', '成绩': '70'}
dict5 = {'姓名': '王五', '成绩': '60'}# 设置文件的表头,即列名
header = ['姓名', '成绩']# 文件的相对路径
file_path = r'各班级成绩\1班成绩单.csv'# 以自动关闭文件的方式创建文件对象
with open(file_path, 'a', encoding='utf-8', newline="") as f:# 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)# 不要表头就不需要这行代码#dw.writeheader()# writerows多行写入dw.writerows([dict1, dict2, dict3, dict4, dict5])

6. 总结
【写入表头】
dw.writeheader()
【writerow每次写入一行】
dw.writerow(dict1)
【writerows多行写入】
dw.writerows([dict1, dict2, dict3, dict4, dict5])w模式写入,之前的内容被覆盖。
a模式写入,保留原有的内容。
【综合代码】
# 导入os 模块,用于创建文件目录
import os
# 导入 csv 模块,用于操作CSV文件
import csv# mkdir作用是创建目录
# 相对路径
os.mkdir("各班级成绩2")# 用字典存储要写入CSV文件的信息
dict1 = {'姓名': '刘一', '成绩': '100'}
dict2 = {'姓名': '陈二', '成绩': '90'}
dict3 = {'姓名': '张三', '成绩': '80'}
dict4 = {'姓名': '李四', '成绩': '70'}
dict5 = {'姓名': '王五', '成绩': '60'}# 设置文件的表头,即列名
header = ['姓名', '成绩']# 文件的相对路径
file_path = r'各班级成绩2\1班成绩单.csv'# 以自动关闭文件的方式创建文件对象
with open(file_path, 'a', encoding='utf-8', newline="") as f:# 实例化类 DictWriter(),得到 DictWriter 对象dw = csv.DictWriter(f, fieldnames=header)# 写入文件的表头dw.writeheader()# writerow每次写入一行dw.writerow(dict1)# writerows多行写入dw.writerows([dict2, dict3, dict4, dict5])
相关文章:
77. writerows写入多行
文章目录1. 目标任务2. 准备工作3. writerow单行写入4. writerows多行写入5. a以追加的模式写入值6. 总结1. 目标任务 新建【各班级成绩】文件夹; 在该文件夹下新建一个【1班成绩单.csv】文件; 在该文件中写入下面的内容: 成绩 姓名 刘一…...

STM32MP157-Linux输入设备应用编程-多点触摸屏编程
文章目录前言多点触摸屏tslib库简介tslib库移植tslib库函数使用打开触摸屏设备配置触摸屏设备打开并配置触摸屏设备读取触摸屏设备多点触摸屏程序编写触点数据结构体定义事件定义计算触点数量判断单击、双击判断长按、移动判断放大、缩小外部调用代码流程图(草图&am…...
)
mybatis-plus的一般实现过程(超详细)
MyBatis-Plus 是 MyBatis 的增强工具,在 MyBatis 的基础上提供了许多实用的功能,如分页查询、条件构造器、自动填充等。下面是 MyBatis-Plus 的完整代码实现流程: ①、引入 MyBatis-Plus 依赖 在 Maven 中,可以通过以下方式引入 …...
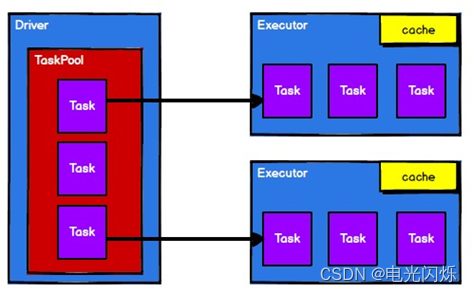
Spark(5):RDD概述
目录 0. 相关文章链接 1. 什么是RDD 2. RDD核心属性 3. 执行原理 0. 相关文章链接 Spark文章汇总 1. 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类&#x…...

面向对象 - 继承
Hello , 各位同学朋友大家好啊, 今天给大家分享的技术呢, 是面向对象三大特征之一的继承,我们今天主要按照以下几个点, 展开继承的讲解。目录 :* 继承的介绍* 继承的好处和弊端* 继承中成员访问特点 - 成员变量* 继承中成员访问特点 - 成员方法* 方法重写* 继承中成…...

计算机网络的166个概念你知道几个 第十二部分
计算机网络安全安全通信的四大要素:机密性、保温完整性、端点鉴别和运行安全性。机密性:报文需要在一定程度上进行加密,用来防止窃听者截取报文。报文完整性:在报文传输过程中,需要确保报文的内容不会发生改变。端点鉴…...

【RabbitMQ】RabbitMQ各版本的兼容性与技术支持时限
今天在研究RabbitMQ的监控时,发现这个消息队列软件的版本真的很令人崩溃,版本众多,且组件之间还存在版本的兼容性,此外各个组件还对操作系统存在兼容性关系。为了帮大家节省一些查阅官方文档的时间,我把官方文档里面涉…...
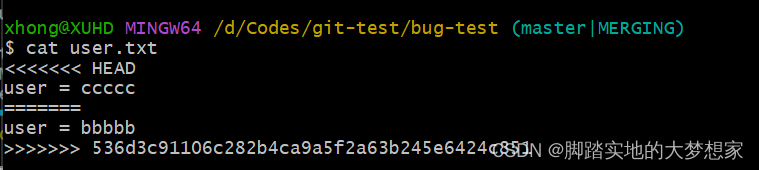
【Git】P5 Git 远程仓库(3)pull 发生冲突
pull 发生冲突冲突在什么场景下发生?为什么要先 pull 再 push构建一个冲突场景初始开始操作:程序员2:程序员1:程序员2:发生冲突:查看冲突:解决冲突:冲突在什么场景下发生?…...

关于世界坐标系,相机坐标系,图像坐标系,像素坐标系的一些理解
关于世界坐标系,相机坐标系,图像坐标系,像素坐标系的一些理解前言一、各坐标系的含义二、坐标系转换1.世界坐标系与相机坐标系(旋转与平移)2.相机坐标系与图像坐标系(透视)3.图像坐标系与像素坐…...

企业防护ddos的注意事项,你知道吗?
DDoS,分布式拒绝服务攻击,是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。在当下,DDoS 攻击是非常常见的一种攻击方式,大…...
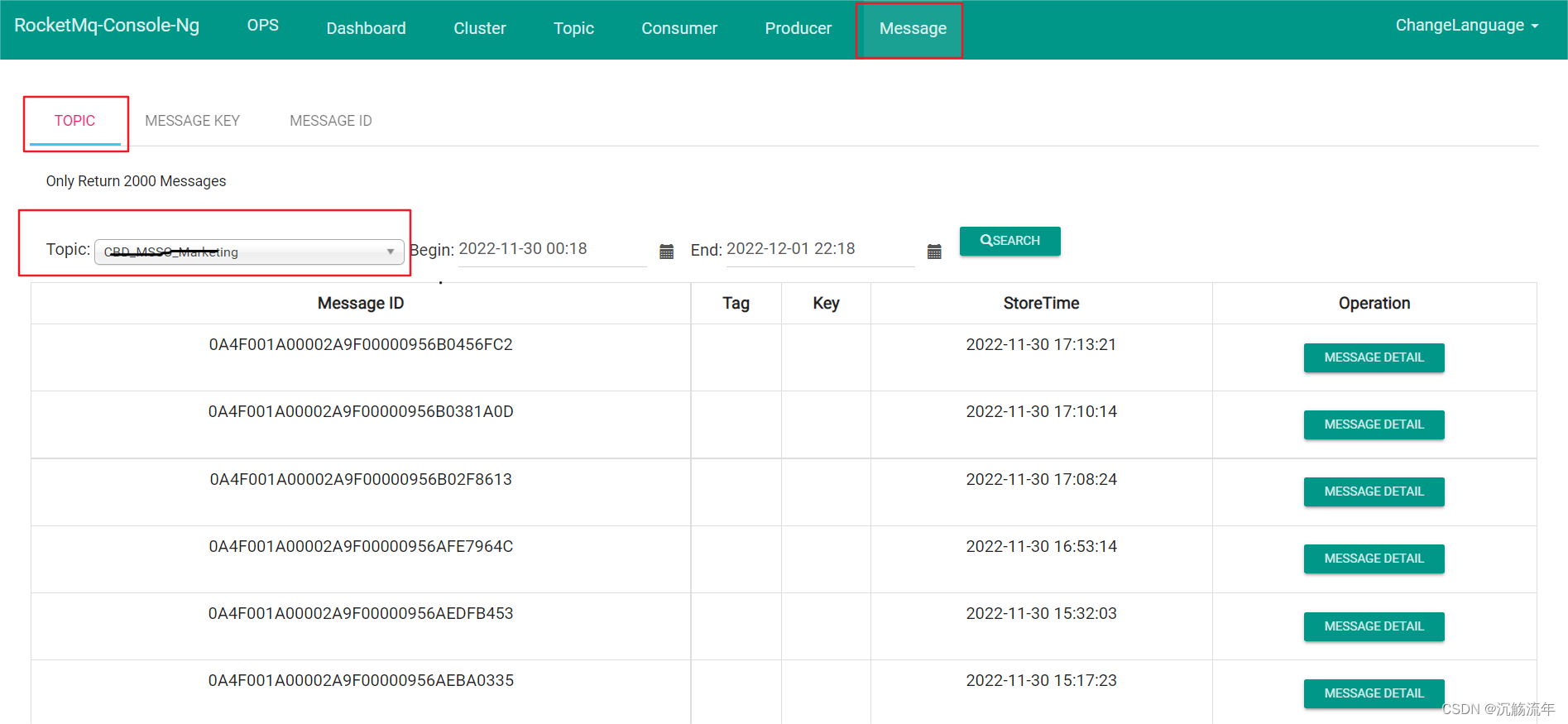
RocketMQ如何测试
RocketMQ如何测试MQ简介RocketMQRocketMQ测试点MQ简介 MQ:Message Queue,即消息队列,是一种应用程序之间的消息通信,简单理解就是A服务不断的往队列里发布信息,另一服务B从队列中读取消息并执行处理,消息发…...

SpringBoot中的bean注入方式和原理介绍
Spring Boot是一个非常流行的Java框架,它可以帮助开发者快速地构建高效、健壮的应用程序。其中一个重要的功能就是依赖注入,也就是将一个对象注入到另一个对象中,以便它们可以相互协作。在Spring Boot中,依赖注入是通过bean实现的…...

ESP32设备驱动-RFID-RC522模块驱动
RFID-RC522模块驱动 文章目录 RFID-RC522模块驱动1、RFID-RC522介绍2、硬件准备3、软件准备4、驱动实现1、RFID-RC522介绍 基于 NXP 的 MFRC522 IC 的 RC522 RFID 模块通常带有一个 RFID 卡标签和具有 1KB 内存的密钥卡标签。 最重要的是,它可以写一个标签,这样你就可以在里…...

SMETA认证有些客户是需要做窗口期的
【SMETA认证有些客户是需要做窗口期的】SMETA审核是常见的社会责任审核标准之一,中文全称为“Sedex 会员道德贸易审核”,英文为“Sedex Members Ethical Trade Audit”. SEDEX 官网:网页链接Sedex 作为目前市场流行的CSR审核标准,…...

面向对象设计模式:创建型模式之原型模式
文章目录一、引入二、代理模式,Prototype Pattern2.1 Intent 意图2.2 Applicability 适用性2.3 类图2.4 应用实例:使用下划线或消息框展示字符串2.4 应用实例:JDK java.lang.Object java.lang.Cloneable一、引入 二、代理模式,Pr…...
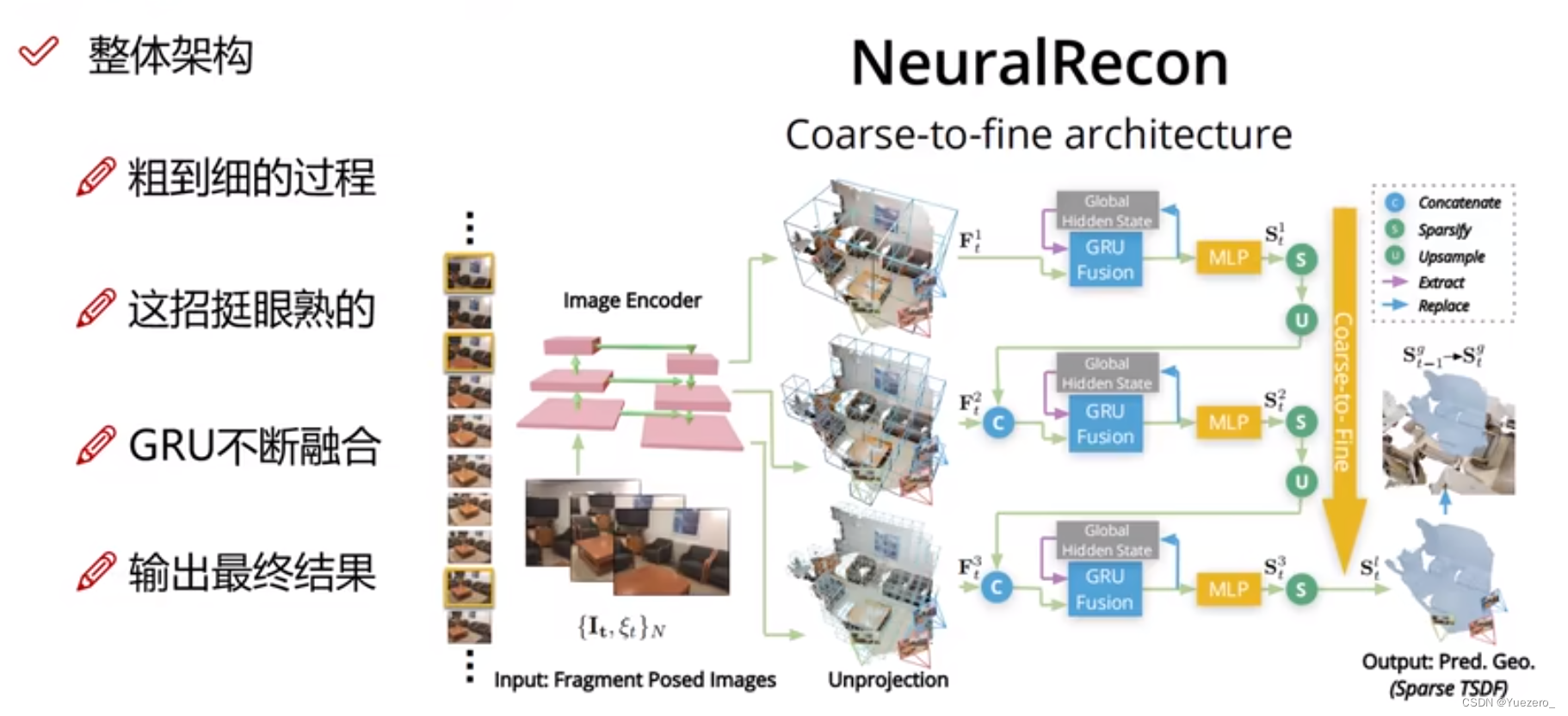
三维重建(单目、双目、多目、点云、SFM、SLAM)
1 相机几何与标定1.1 相机模型中的坐标系1.2 四种坐标系之间的转换1.3 相机内参1.4 相机标定2 单目三维重建2.1 NeuralRecon三维重建定义 在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由于单视频的信息不完全,因此三维重建需要利用经验知识. 而…...

Java中的final和权限修饰符
目录 final 常量 细节: 权限修饰符 Java权限修饰符用于控制类、方法、变量的访问范围。Java中有四种权限修饰符: 权限修饰符的使用场景: final 方法 表明该方法是最终方法,不能被重写。类 表明该类是最终类,不能被继…...
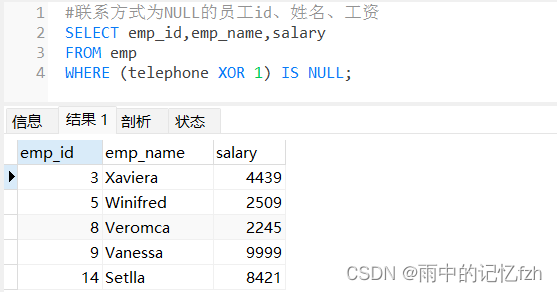
MySQL的基本语句(SELECT型)
基本MySQL语句SELECTSELECT FROM 列的别名去除重复行空值着重号算术运算符加法( )减法( - )乘法( * )除法( / 或DIV)求模( % 或MOD)比较运算符等于( )安全等于( <> )不等于( ! 或 <…...
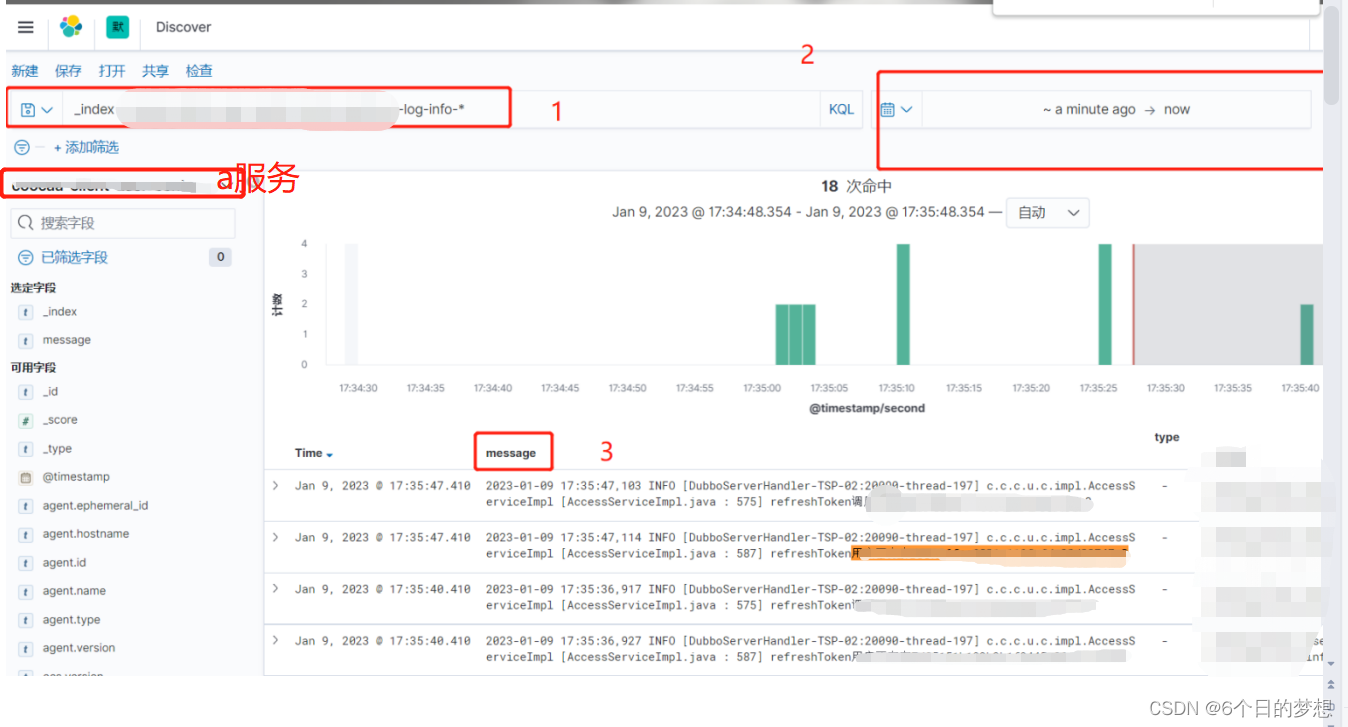
日志服务搭建-ES-FileBeat-Kibana
1次订单量突增问题,导致了有几个数据没有录库,但是确有支付的记录,啥玩意,还能有这个操作,组内安排问题定位,解决,一看打出来的日志,只有支付有,生成订单这边没有&#x…...
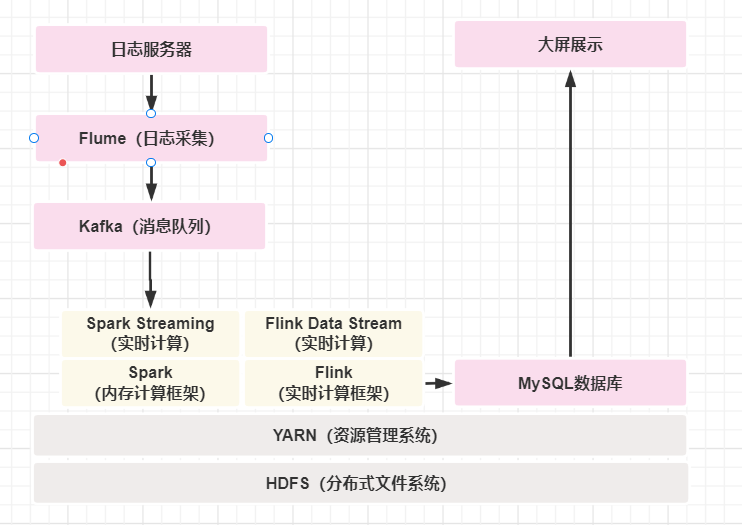
大数据架构设计与数据计算流程
大数据架构设计Hadoop有3个核心组件:分布式文件系统HDFS;分布式运算编程框架MapReduce;分布式资源调度平台YARN。HBase,Hadoop dataBase,基于HDFS的NoSQL数据库,面向列式的内存存储,定期将内存数…...

掌握AI落地三件套:微调、Agent、部署,让你薪资直冲20K+!
文章核心内容是介绍AI行业高薪技能,即掌握大模型落地的“三件套”:微调、Agent、部署。微调是将通用模型变为专属专家的关键,Agent开发让模型能自动解决问题,部署则是基础但重要的能力。文章还强调了传统AI基础的重要性࿰…...

EMQX Dashboard 5.1新手指南:从安装到安全配置的完整流程
EMQX Dashboard 5.1新手指南:从安装到安全配置的完整流程 在物联网和实时消息传递领域,EMQX作为一款高性能的MQTT消息服务器,已经成为众多企业构建可靠物联网平台的首选。而EMQX Dashboard作为其内置的Web管理控制台,在5.1版本中迎…...

噪声系数测试中的Y因子:为什么ENR超噪比是你的关键指标?
噪声系数测试中的Y因子:为什么ENR超噪比是你的关键指标? 在无线通信系统的设计与验证中,噪声系数(Noise Figure)是衡量接收机灵敏度的核心参数之一。而Y因子法作为噪声系数测试的黄金标准,其准确度很大程度…...

Redmine API实战指南:从数据同步到工作流自动化
Redmine API实战指南:从数据同步到工作流自动化 【免费下载链接】redmine Mirror of redmine code source - Official Subversion repository is at https://svn.redmine.org/redmine - contact: vividtone or maeda (at) farend (dot) jp 项目地址: https://gitc…...
)
GitLab实战:如何用rebase -i优雅合并多个commit(附常见错误排查)
Git提交历史优化:交互式rebase高阶操作指南 1. 为什么需要整理Git提交历史 在团队协作开发中,我们经常会遇到提交历史杂乱无章的情况。想象一下这样的场景:你完成了一个新功能的开发,但在这个过程中产生了十几个零散的提交记录&am…...

FireRedASR Pro应用案例:会议录音转文字,提升工作效率实测
FireRedASR Pro应用案例:会议录音转文字,提升工作效率实测 1. 会议记录痛点与解决方案 1.1 传统会议记录的效率瓶颈 在职场工作中,会议记录是一项耗时且容易出错的任务。根据调研数据显示: 普通员工平均每周花费4-6小时在会议…...

STM32F103重映射实战:GPIO_Remap1_CAN1与GPIO_Remap2_CAN1到底选哪个?
STM32F103重映射实战:GPIO_Remap1_CAN1与GPIO_Remap2_CAN1到底选哪个? 第一次在STM32F103上配置CAN总线时,看到GPIO_Remap1_CAN1和GPIO_Remap2_CAN1这两个选项,我完全懵了——它们有什么区别?为什么需要两个重映射选项…...

Captura视频质量优化终极指南:先降噪后锐化的完美工作流
Captura视频质量优化终极指南:先降噪后锐化的完美工作流 【免费下载链接】Captura Capture Screen, Audio, Cursor, Mouse Clicks and Keystrokes 项目地址: https://gitcode.com/gh_mirrors/ca/Captura Captura是一款功能强大的屏幕录制工具,支持…...

BYD Battery Emulator:让电动汽车电池成为家庭储能的智能桥梁
BYD Battery Emulator:让电动汽车电池成为家庭储能的智能桥梁 【免费下载链接】BYD-Battery-Emulator-For-Gen24 This software enables EV battery packs to be used for stationary storage in combination with solar inverters. 项目地址: https://gitcode.co…...

从零学习Kafka:数据存储
下载好之后,进行解压并进入到对应的目录。tar -xzf kafka_2.13-4.1.1.tgz cd kafka_2.13-4.1.1接着我们执行下面两条命令进行一些必要的配置。KAFKA_CLUSTER_ID"$(bin/kafka-storage.sh random-uuid)"bin/kafka-storage.sh format --standalone -t $KAFKA…...