【数据结构】线性表----链表详解
数据结构—-链表详解
目录
文章目录
- 链表的定义
- 链表的构成
- 链表的分类
- 双向和单向
- 带头和不带头
- 循环和不循环
- 链表的命名
- 基本操作的实现
- 初始化
- 打印
- 取值
- 查找
- 插入
- 指定位置插入
- 删除
- 删除
- 销毁
- 部分其他链表的代码实现
- 循环链表
- 双向链表
- 优点/缺点(对比顺序表)
- 优点
- 缺点
链表的定义
前面我们介绍的顺序表,在逻辑结构和物理结构上都是线性、连续的关系,那么我们在篇尾的时候也提到了是否有一种顺序表,无需在物理结构上连续,从而达到更好存取的目的呢?今天它来了。
链表(LinkList)属于线性表的一种,以下是百度百科关于链表的定义:

总结下来,我们可以看出:
在结构上,链表并不是像顺序表那样底层结构是数组,而是包含两个区域:数据域、指针域。我们可以类比成火车,火车每一节车厢实际上是独立的,也就好比数据域,存储着各自的数据;但每一节车厢之间都会由一条链连接在一起,从而形成整个火车,链也就好比指针域,起到连接该车厢和指向下一车厢的作用。而实际上这样的存储结构也就是为什么链表的物理结构可以不连续,而逻辑结构依旧是连续的。
这样的好处就是当我们需要对指定元素进行移动、替换、存取等操作的时候,我们可以一步到位,无需挪动数据,无需扩容,不会造成空间上的浪费——好比你火车更换车厢,总不可能让整个火车都为你而改动吧。

所以,如果要用一句话概括链表是什么,我们可以说:链表是一种线性数据结构,由结点组成,每个结点包含一个数据元素也就是数据域和指向下一个节点的指针也就是指针域。(叫法:结点或者节点都行)
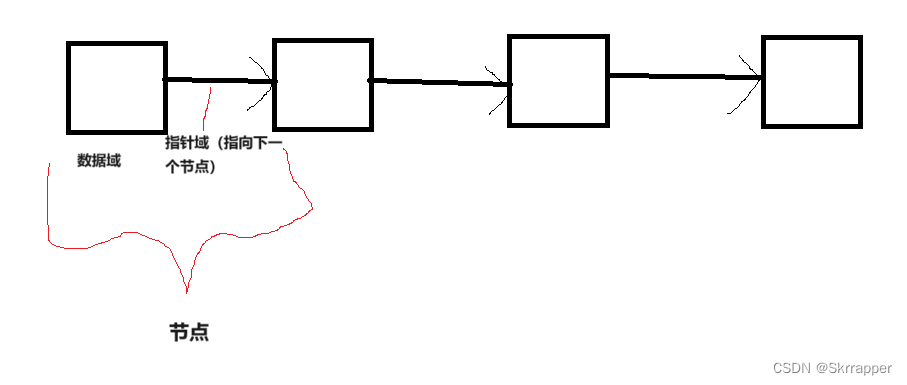
联想:指针域的作用
实际上,在后续的数据结构中,还有很多类型的数据结构会使用到指针域这个概念,或者可以说是结点的概念。结点指地是组成数据元素的存储映像,往往指针就是指向结点的,鉴于它不受物理空间限制的优点,往往都会使用指针和结点来更高效率地实现数据结构。
链表的构成
数据域(data):存放实际数据
指针域(next):存放下一节点的首地址
结点:由数据域和指针域两部分信息组成的数据元素的存储映像
链表的分类
我们平常使用的最多的就是单链表——不带头单向不循环链表
既然有不带头,那么必然就有带头;既然有单向,那么必然就有双向;既然有不循环,那么必然就有循环。
接下来针对这三个方向进行介绍。
双向和单向
单向链表:每个节点包含一个指向下一个节点的指针。单向链表只能从头节点开始遍历,无法从尾节点向前遍历。
双向链表:每个节点包含一个指向下一个节点和一个指向前一个节点的指针。双向链表可以从头节点或尾节点开始遍历,可以方便地在链表中间插入或删除节点。(向的描述与指针域的描述是一致的,单向只有一个指针域,而双向有两个)
可以通俗地理解为,单向为单行道,只能从头走到尾;双向为双行道,既可退又可进。
带头和不带头
带头链表:指第一个结点叫做头结点,不存储有效数据,只作为指引结点
不带头链表:指第一个结点不叫做头结点,就是第一个结点,存储有效数据
注意这里指的带头就是带有头结点的意思,头结点不存储任何数据,它仅仅用于指向第一个结点。优点是操作链表时统一处理,不需要特殊处理第一个节点,代码更加简洁清晰。缺点是需要额外的头节点,占用额外的空间。
循环和不循环
循环链表:最后一个节点的指针指向第一个节点,形成一个环状结构。循环链表可以从任意节点开始遍历,但需要注意避免出现死循环的情况。
不循环链表:最后一个节点的指针直接指向空,仅仅作为线性结构。
虽然链表种类之多,例如还有带有尾结点的链表等等,但在实际应用中只有两种:**单链表(不带头单向不循环链表)和双向链表(带头双向循环链表)**使用得最多,因为它们两个的特性加起来即为所有特性,而其他类型的链表也就不难创建了。
链表的命名
typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode
单链表
SLTDataType、ElemType、LinklistType等等(根据自己的偏好设定),以下都命名为SLTDataType
数据域
SLTDataType data; //保存结点数据
指针域(*
struct SListNode* next;//保存下一结点地址
操作
SLTPushBack//针对操作的命名一般在操作前缀添加SLT等代表其为链表的大写字母缩写
基本操作的实现
有关链表的操作,下方是一些举例
//链表的头插、尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x);//链表的头删、尾删
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos);//销毁链表
void SListDesTroy(SLTNode** pphead);
//打印
void SLTPrint(SLTNode* phead);
接下来针对上述操作进行详细介绍。
初始化
即构造一个空链表
void SlistTest01() {//一般不会这样去创建链表,这里只是为了给大家展示链表的打印SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));node1->data = 1;SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));node2->data = 2;SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));node3->data = 3;SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));node4->data = 4;
//当我们定义好了数据域之后,指针域应该如何定义呢?node1->next = node2;node2->next = node3;node3->next = node4;node4->next = NULL;
//像这样,让指针域指向该节点的下一节点,达到链接的目的
SLTNode* SLTBuyNode(SLTDataType x) {SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL) {//如果开辟失败的情况perror("malloc fail!");exit(1);}newnode->data = x;//开辟数据域newnode->next = NULL;//开辟指针域return newnode;
}
打印
在接下来承担显示的作用,将链表的结构可视化
void SLTPrint(SLTNode* phead) {SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;//使用next指针指向下一节点}printf("NULL\n");
}
取值
与顺序表的取值不一样,因为链表物理结构是不连续的,所以在链表中进行访问的时候不能直接随机访问,只能从首元素出发遍历进行访问。
Status SLTGet(LinkList L, int i, ElemType& e)//获取线性表L中的耨个数据元素的内容,通过变量e返回
{ p = L->next; //初始化,p指向首元结点,j = 1; //初始化,j为计数器while (p&&j < i) //向后扫描,直到p指向的第i个元素或p为空{p = p->next; //p指向下一个结点++j;}if (!p || j > i) //第i个元素不存在,抛出异常return NULL; e = p->data; //取第i个元素return OK;
}查找
查找操作同顺序表类似,都是哦才能够首元结点开始,依次将元素与给定值进行比较。
//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x) {assert(pphead);//遍历链表SLTNode* pcur = *pphead;while (pcur) //等价于pcur != NULL{if (pcur->data == x) {return pcur;}pcur = pcur->next;}//没有找到return NULL;
}
插入
插入分为尾插、头插、指定位置插入,而指定位置插入又分为指定位置之前和之后。
尾插
//尾插
void SLTPushBack(SLTNode** pphead/*为什么是**二级指针?因为*pphead这个指针在传参时实际上还是传值而不是传地址,需要传这个指针的地址也就是使用二级指针*/, SLTDataType x) {assert(pphead);SLTNode* newnode = SLTBuyNode(x);//链表为空,新节点作为pheadif (*pphead == NULL) {*pphead = newnode;return;}//链表不为空,找尾节点SLTNode* ptail = *pphead;while (ptail->next)//并非ptial不能为空,而是ptail->next不能指向空{ptail = ptail->next;}//ptail就是尾节点ptail->next = newnode;
}
头插
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x) {assert(pphead);SLTNode* newnode = SLTBuyNode(x);//newnode *ppheadnewnode->next = *pphead;*pphead = newnode;
}
指定位置插入
之前
//在指定位置之前插入数据
//关键:找到前驱节点
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead);assert(pos);//要加上链表不能为空,如果链表都空了,必然找不到前驱节点assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos刚好是头结点if (pos == *pphead) {//头插SLTPushFront(pphead, x);return;}//pos不是头结点的情况(如果不分情况讨论,那么prev就永远找不到pos)SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev -> newnode -> posprev->next = newnode;newnode->next = pos;
}
之后
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x) {assert(pos);SLTNode* newnode = SLTBuyNode(x);//错误操作:(顺序错误,导致pos->next不再指向下一节点//pos->next=newnode //newnode->next=pos->next//正确操作:newnode->next = pos->next;pos->next = newnode;
}
删除
删除又分为尾删、头删、指定结点删除以及指定位置后续结点删除
尾删
//尾删
void SLTPopBack(SLTNode** pphead) {assert(pphead);//第一个节点不能为空//链表不能为空assert(*pphead);//链表不为空if ((*pphead)->next == NULL)//如果只有一个节点 {free(*pphead);//直接释放*pphead = NULL;//置空return;}//如果有多个节点SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next)//不能指向空{prev = ptail;ptail = ptail->next;}prev->next = NULL;//销毁尾结点free(ptail);ptail = NULL;
}
头删
//头删
void SLTPopFront(SLTNode** pphead) {assert(pphead);//链表不能为空assert(*pphead);//让第二个节点成为新的头//把旧的头结点释放掉SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}
删除
删除又分为删除指定结点、删除指定结点之后的所有结点
删除pos结点
//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pphead);assert(*pphead);assert(pos);//pos刚好是头结点,没有前驱节点,执行头删if (*pphead == pos) {//头删SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//找到了prev以及pos pos->next//先改变指向prev->next = pos->next;//再释放节点free(pos);pos = NULL;
}
删除pos之后的结点
//删除pos之后的节点,也就是pos->next->next
void SLTEraseAfter(SLTNode* pos) {assert(pos);//pos->next不能为空assert(pos->next);//pos pos->next pos->next->nextSLTNode* del = pos->next;//pos->next = pos->next->next;free(del);del = NULL;
}
销毁
//销毁链表
//注意链表的空间是不连续的,所以不能一次性销毁所有元素,只能使用循环一个元素一个元素销毁
void SListDesTroy(SLTNode** pphead) {assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
…
以上操作都基于单链表
部分其他链表的代码实现
循环链表
在介绍链表的分类的时候,已经介绍了循环链表的基本定义,也就是链表的最后一个结点的指针域指向第一个结点,这样就形成了一个循环链表,如果用图像来表示关系的话,如下:
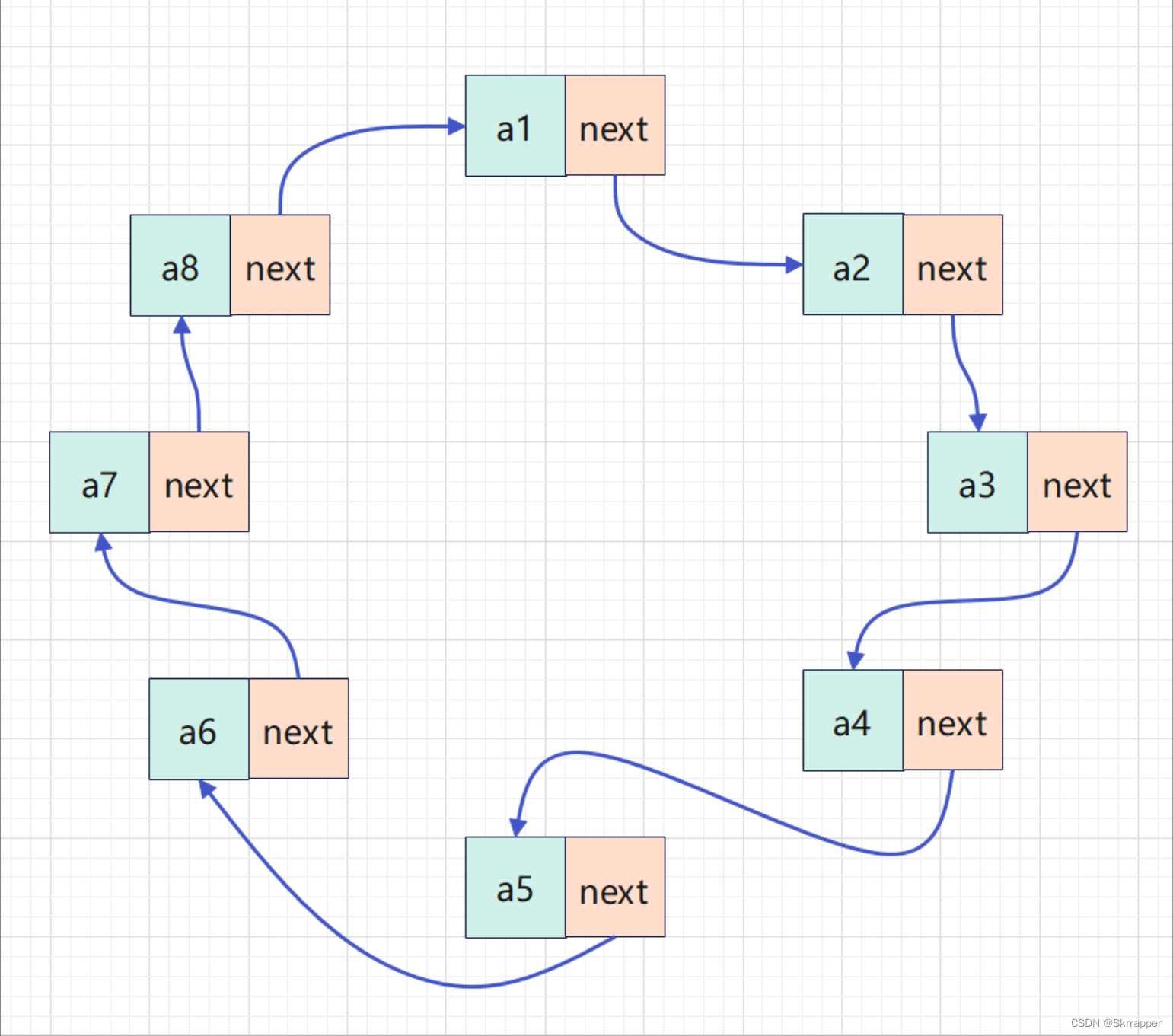
那么针对其代码的实现,实际上只需要让最后一个结点的指针域不指向空,而是指向第一个结点即可。
//关键代码
p=B->next->next;
B->next=A->next;
A->next=p;//指向头结点
循环链表的作用以及使用场景
- 约瑟夫问题:约瑟夫问题是一个经典的问题,即有n个人围成一圈,从第一个人开始报数,报到m的人出列,然后从出列的下一个人开始重新报数,直到所有人都出列。循环链表可以很好地模拟这个问题。
- 环形队列:循环链表可以用来实现环形队列,即队列的尾节点指向头节点,可以很方便地实现循环入队和出队操作。
- 循环播放列表:循环链表可以用来实现循环播放音乐列表或视频列表等功能。实际上循环这个概念,在生活中许多部分都有被使用到,而当它需要使用代码实现的时候,那么循环链表是较为容易实现的方案。
双向链表
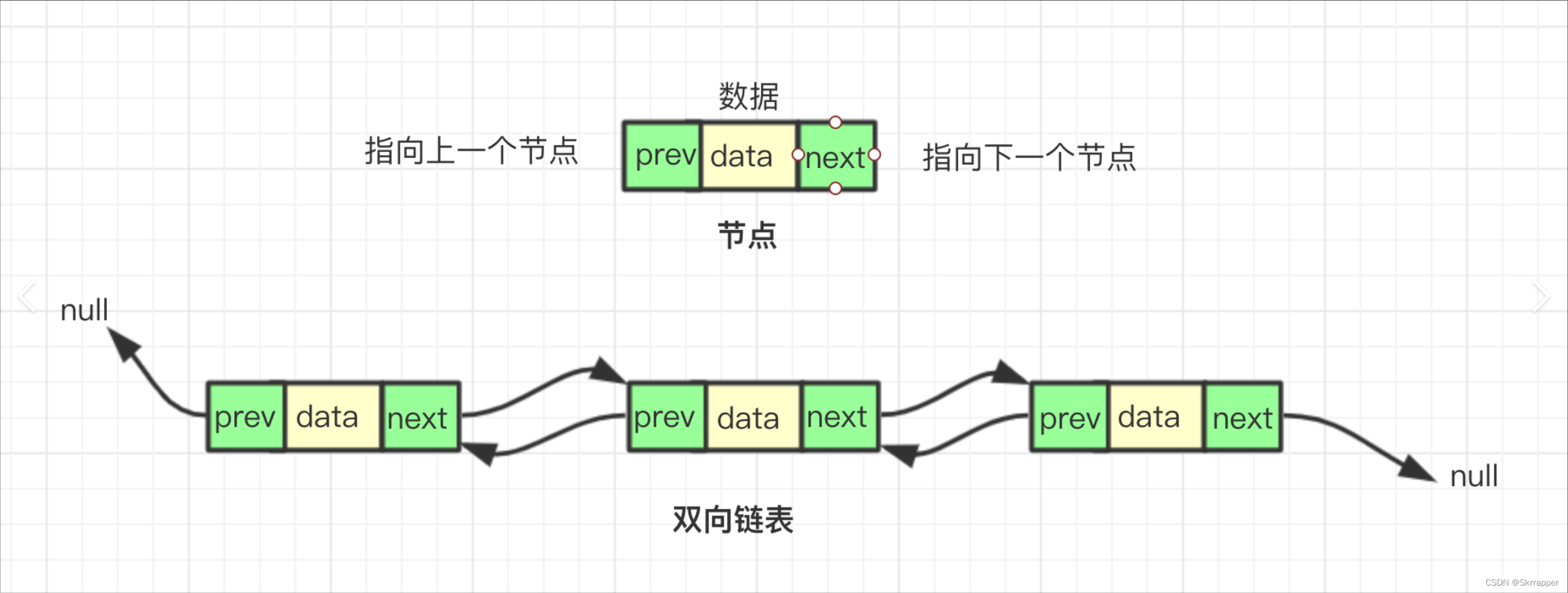
双向链表的每个节点都包含两个指针,一个指向前一个节点,一个指向后一个节点。鉴于这个特点,它与单向链表不同的是,双向链表可以从头到尾或从尾到头遍历链表。
在双向链表中,通常有一个头节点和一个尾节点,它们分别指向链表的第一个节点和最后一个节点,可以方便地在头部或尾部进行插入或删除操作。
双向链表的操作普遍上比单向链表简单,因为它多了一个指针域所以操作的灵活性大大提高。
双向链表的作用以及使用场景
- 需要频繁在链表中间插入或删除节点的情况:双向链表可以在O(1)的时间复杂度内完成插入或删除操作,因此适合在需要频繁插入或删除节点的场景中使用。
- 需要双向遍历链表的情况:双向链表可以方便地从头到尾或从尾到头遍历链表,因此适合在需要双向遍历链表的场景中使用。
- 需要实现栈或队列的情况:双向链表可以方便地在两端进行插入或删除操作,因此适合用来实现栈或队列。
- 需要实现LRU缓存淘汰算法的情况:LRU缓存淘汰算法中经常需要删除最近最少使用的节点,双向链表可以方便地删除尾节点,因此适合用来实现LRU缓存淘汰算法。
优点/缺点(对比顺序表)
优点
1.存储空间充足,对内存利用率高
链表无需像顺序表那样预先分配空间,只要内存空间允许,链表中的元素个数就没有限制,那么这也可以反向说明链表对内存的利用率较高。
2.插入和删除的效率高
不像顺序表那样,在进行插入和删除的时候需要移动整个表,链表可以直接对单个元素进行插入和删除操作。
3.动态性和灵活性
链表的大小可以动态地调整,可以根据需要动态地插入或删除元素,不需要提前指定大小。
4.可以实现高级数据结构
实际上,在后续更高阶的数据结构中,许多结构都是基于链表的。链表可以实现栈、队列、哈希表等高级数据结构,具有很高的灵活性和扩展性。
缺点
1.存储密度小,单个结点有效数据占用空间小
我们发现,链表中的一个结点包含数据域和指针域,但是实际上真正存储了有效元素的只有数据域一部分,那么这就说明了其存储密度小(存储密度=数据元素本身占用的存储量/结点结构占用的存储量)
2.存取元素的效率低
链表不像顺序表那样,是随机存取结构,可以随时存取该位置上的元素;它属于顺序存取结构,只能通过遍历来实现存取元素操作。
3.每存一个数据都要开辟动态空间,增加了内存分配的开销,并可能导致内存碎片化。所以说,动态化既有利也有弊。
相关文章:
【数据结构】线性表----链表详解
数据结构—-链表详解 目录 文章目录 链表的定义链表的构成链表的分类双向和单向带头和不带头循环和不循环 链表的命名基本操作的实现初始化打印取值查找插入指定位置插入删除删除销毁 部分其他链表的代码实现循环链表双向链表 优点/缺点(对比顺序表)优点…...

【小程序】小程序如何适配手机屏幕
小程序如何适配手机屏幕 1. 使用rpx单位2. 百分比布局3. 弹性盒子(Flexbox)和网格布局4. 媒体查询5. 响应式布局6. 测试和调试 1. 使用rpx单位 rpx(responsive pixel)是小程序中的一种长度单位,可以根据屏幕宽度进行自…...

第15节 编写shellcode加载器
我最近在做一个关于shellcode入门和开发的专题课👩🏻💻,主要面向对网络安全技术感兴趣的小伙伴。这是视频版内容对应的文字版材料,内容里面的每一个环境我都亲自测试实操过的记录,有需要的小伙伴可以参考…...

JAVA学习-练习试用Java实现爬楼梯
问题: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼…...
[SWPUCTF 2021 新生赛]PseudoProtocols、[SWPUCTF 2022 新生赛]ez_ez_php
[SWPUCTF 2021 新生赛]PseudoProtocols 打开环境,提示hint.php就在这里,且含有参数wllm 尝试利用PHP伪协议读取该文件 ?wllmphp://filter/convert.base64-encode/resourcehint.php//文件路径php://filter 读取源代码并进行base64编码输出。 有一些敏…...
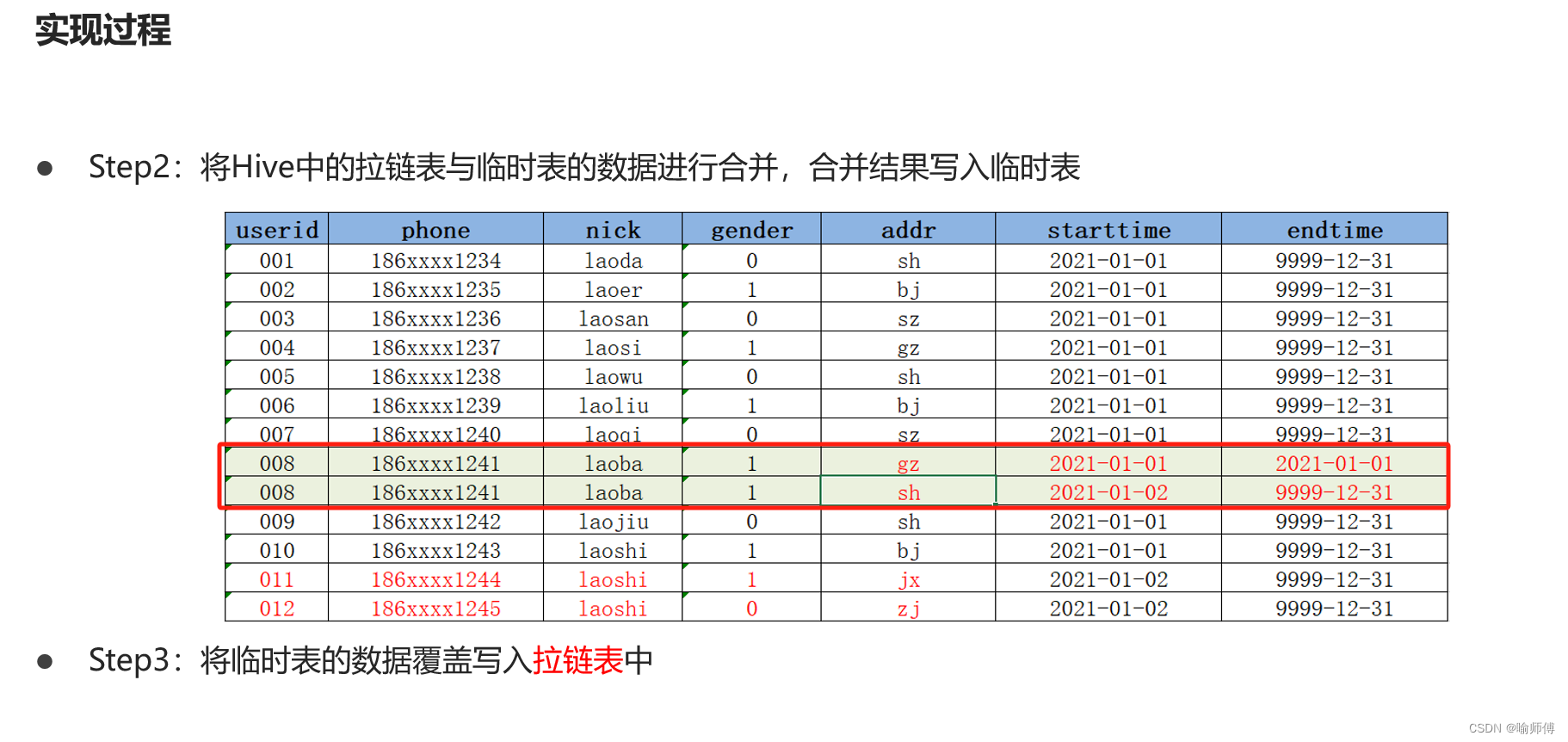
Hive-拉链表的设计与实现
Hive-拉链表的设计与实现 在Hive中,拉链表专门用于解决在数据仓库中数据发生变化如何实现数据存储的问题。 1.数据同步问题 Hive在实际工作中主要用于构建离线数据仓库,定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用…...
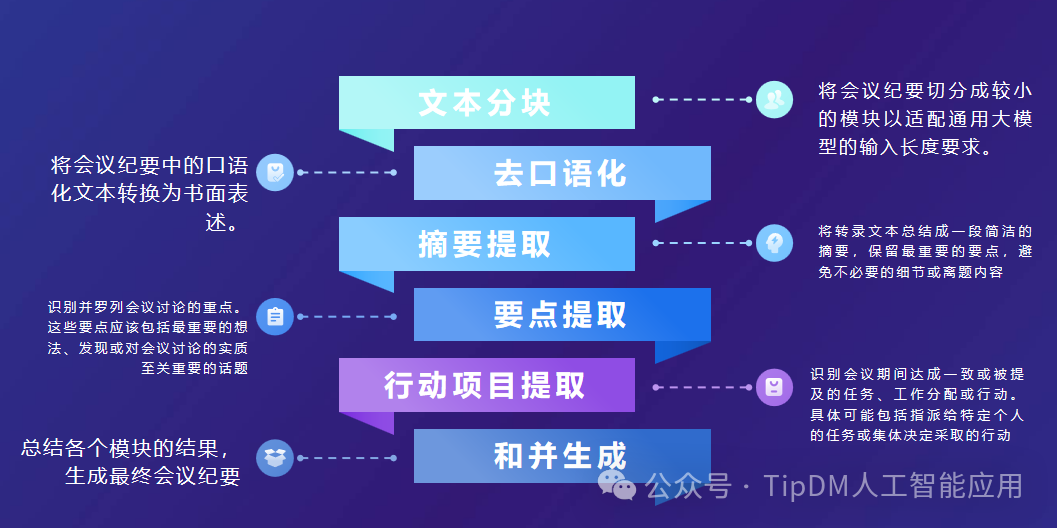
AI应用案例:会议纪要自动生成
以腾讯会议转录生成的会议记录为研究对象,借助大模型强大的语义理解和文本生成等能力,利用指令和文本向量搜索实现摘要总结、要点提取、行动项目提取、会议纪要生成等过程,完成会议纪要的自动总结和生成,降低人工记录和整理时间成…...
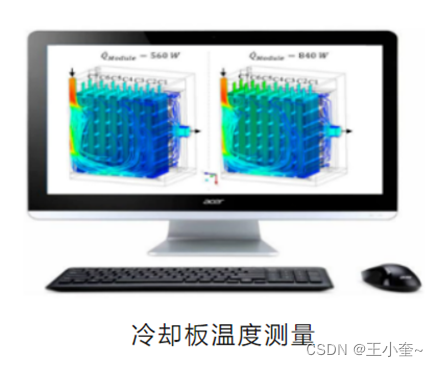
基于光纤技术的新能源汽车电池安全监测--FOM²系统
为什么要进行动力电池包的温度监测? 新能源电动汽车的动力电池包的工作温度,不仅会影响电池包性能,而且直接关系到车辆安全。时有发生的新能源汽车电池包起火事件,对电池包、冷却系统以及电池管理系统(BMS)…...

基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) #Options local_llm llama3 llm ChatOllama(modellocal_llm, format"json", temperature0) #embeddings #embeddings OllamaEmbeddings(model"nomic-embed-text") embed…...
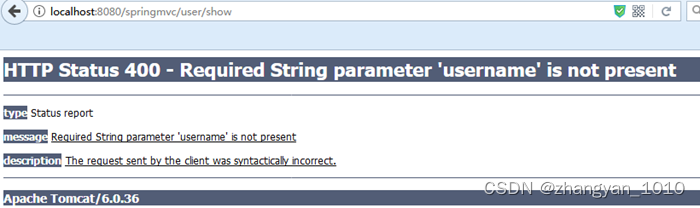
Spring MVC(三) 参数传递
1 Controller到View的参数传递 在Spring MVC中,把值从Controller传递到View共有5中操作方法,分别是。 使用HttpServletRequest或HttpSession。使用ModelAndView。使用Map集合使用Model使用ModelMap 使用HttpServletRequest或HttpSession传值 使用HttpSe…...

常见加解密算法02 - RC4算法分析
RC4是一种广泛使用的流密码,它以其简洁和速度而闻名。区别于块密码,流密码特点在于按位或按字节来进行加密。 RC4由Ron Rivest在1987年设计,尽管它的命名看起来是第四版,实际上它是第一个对外发布的版本。 RC4算法的实施过程简洁…...
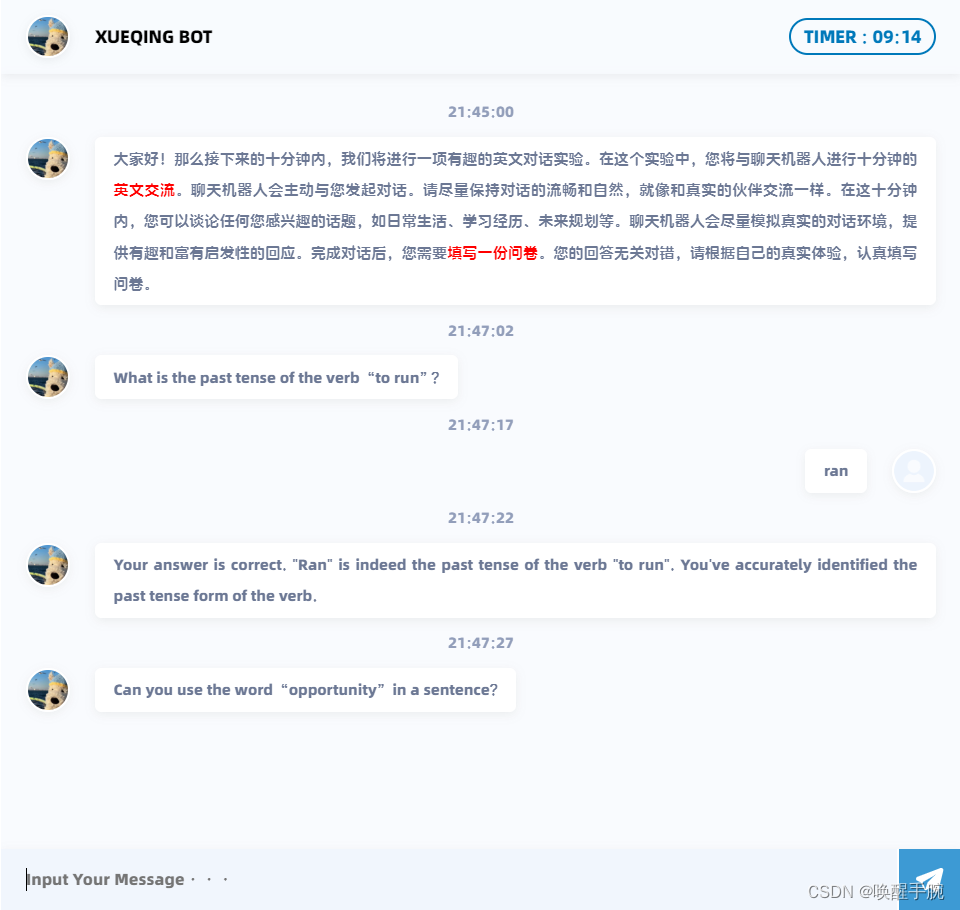
如何使用 ERNIE 千帆大模型基于 Flask 搭建智能英语能力评测对话网页机器人(详细教程)
ERNIE 千帆大模型 ERNIE-3.5是一款基于深度学习技术构建的高效语言模型,其强大的综合能力使其在中文应用方面表现出色。相较于其他模型,如微软的ChatGPT,ERNIE-3.5不仅综合能力更强,而且在训练与推理效率上也更高。这使得ERNIE-3…...
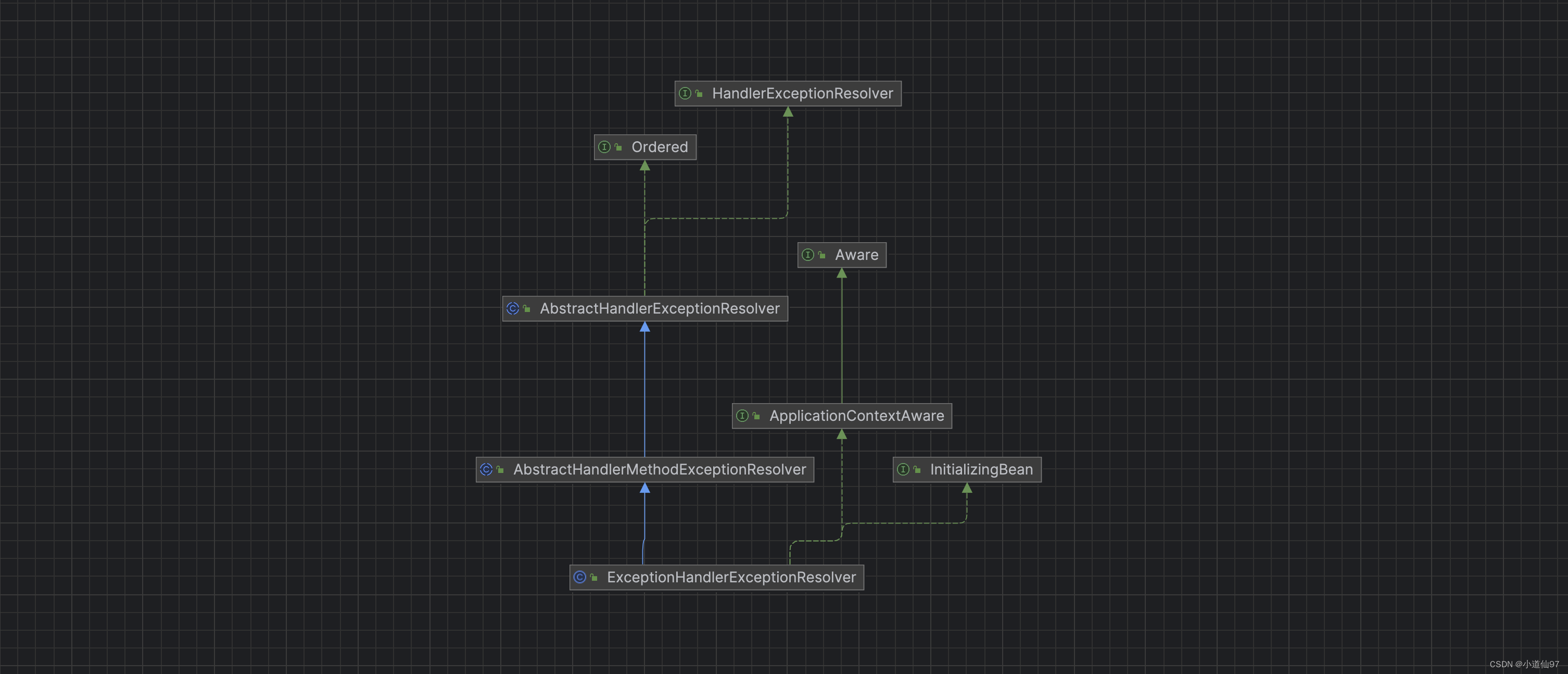
Java全局异常处理,@ControllerAdvice异常拦截原理解析【简单易懂】
https://www.bilibili.com/video/BV1sS411c7Mo 文章目录 一、全局异常处理器的类型1-1、实现方式一1-2、实现方式二 二、全局异常拦截点2-1、入口2-2、全局异常拦截器是如何注入到 DispatcherServlet 的 三、ControllerAdvice 如何解析、执行3-1、解析3-2、执行 四、其它4-1、设…...
)
代码随想录35期Day38-Java(Day37休息)
Day38题目 LeetCode509.斐波那契数列 核心思想:很简单dp[i]dp[i-1]dp[i-2].这里用了数组存储的形式,也可以递归 class Solution {public int fib(int n) {int[] dp new int[n2];dp[0] 0;dp[1] 1;for(int i 2 ; i < n ; i ){dp[i] dp[i-1] dp[i-2];}return dp[n];} …...

力扣HOT100 - 739. 每日温度
解题思路: 单调栈 class Solution {public int[] dailyTemperatures(int[] temperatures) {int length temperatures.length;int[] ans new int[length];Deque<Integer> stack new LinkedList<>();for (int i 0; i < length; i) {int temperatu…...
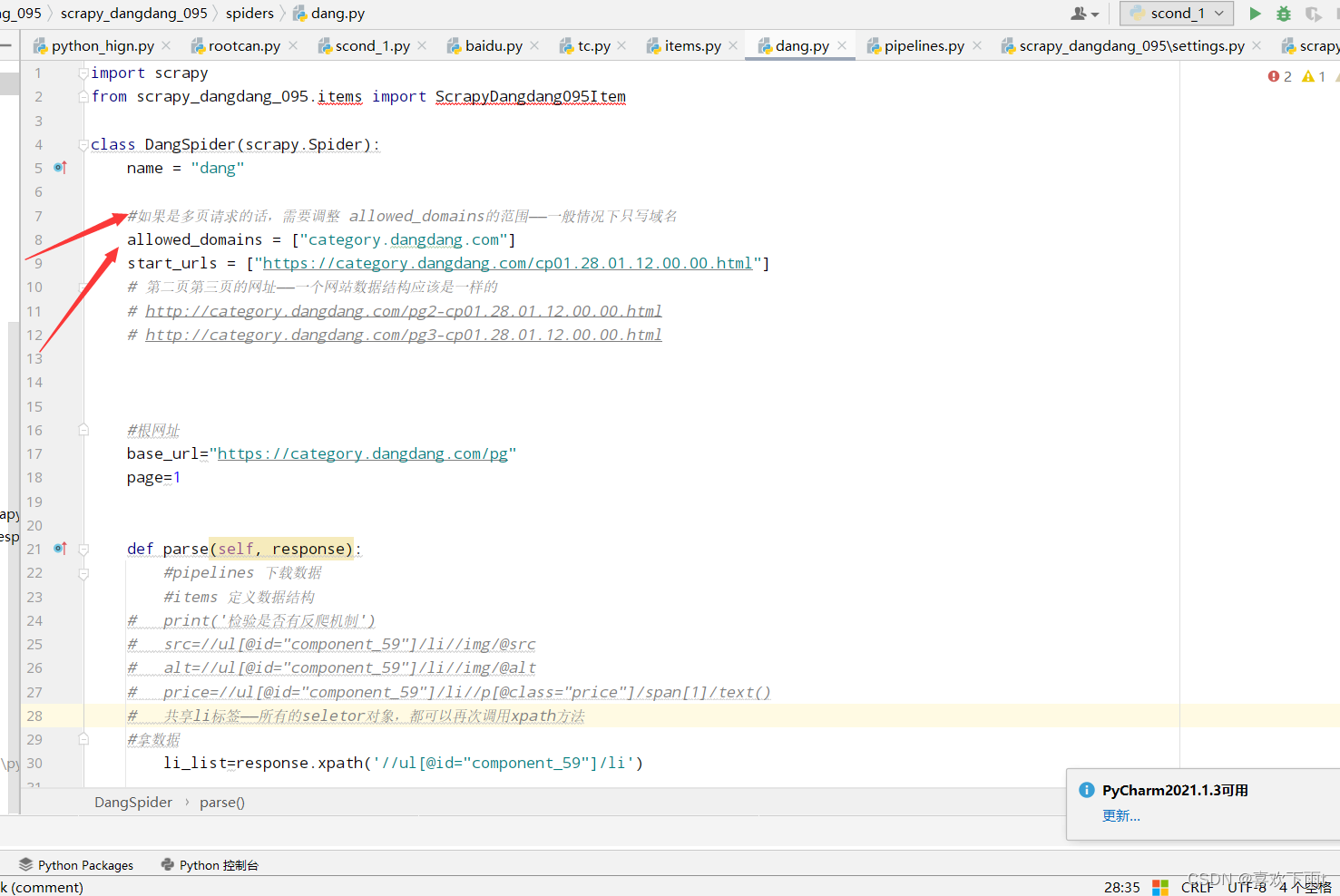
【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】
爬虫之scrapy框架——基本原理和步骤爬取当当网(基本步骤) 下载scrapy框架创建项目(项目文件夹不能使用数字开头,不能包含汉字)创建爬虫文件(1)第一步:先进入到spiders文件中&#x…...

C++ QT设计模式:责任链模式
基本概念 责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,将请求沿着处理链传递,直到有一个对象能够处理为止。 实现的模块有: Handler(处理者):定义一个处理…...
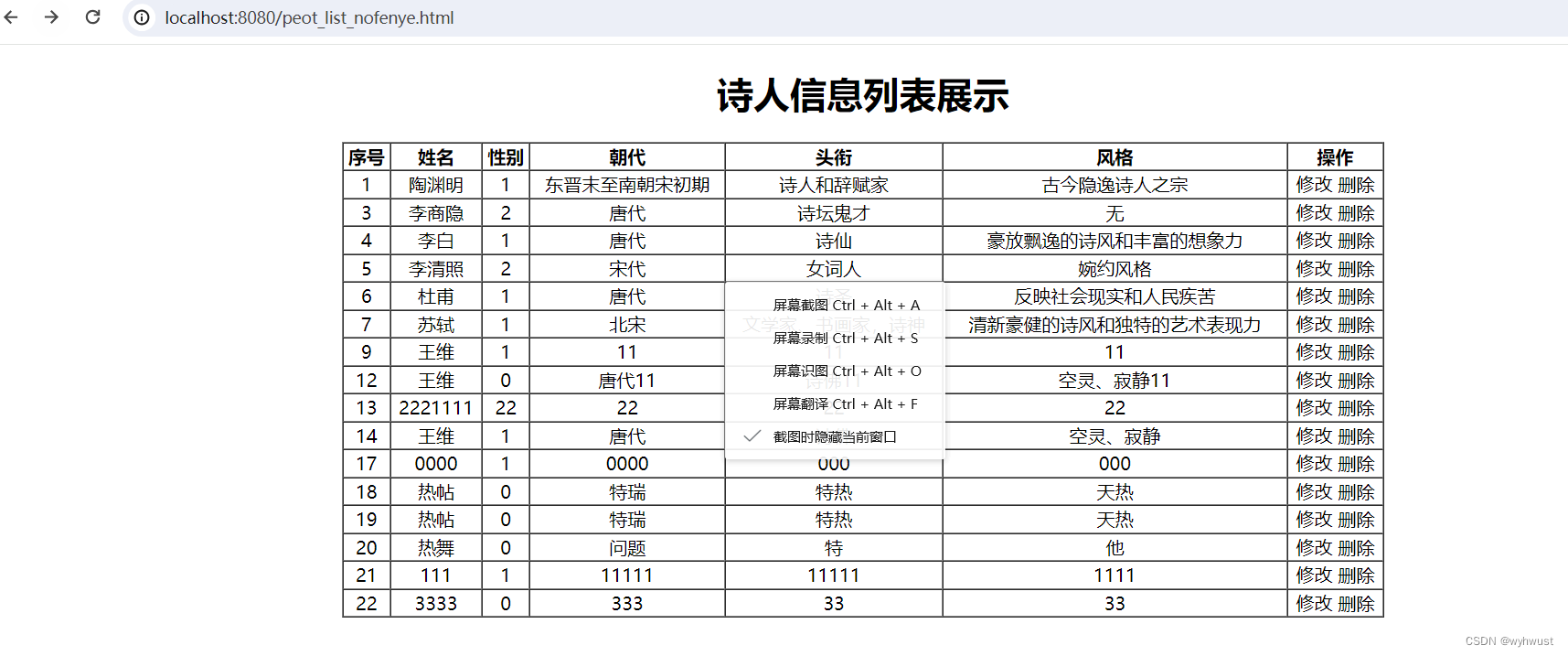
基于springboot+mybatis+vue的项目实战之(后端+前后端联调)
步骤: 1、项目准备:创建数据库(之前已经创建则忽略),以及数据库连接 2、建立项目结构文件夹 3、编写pojo文件 4、编写mapper文件,并测试sql语句是否正确 5、编写service文件 6、编写controller文件 …...
实战篇)
【教程向】从零开始创建浏览器插件(六)实战篇
【教程向】从零开始创建浏览器插件(六)实战篇 在这篇文章中,我们将详细介绍一个名为“摸鱼King”的Chrome扩展程序的开发思路。这个扩展程序的主要功能是在用户浏览网页时提供便捷的方式来摸鱼看小说。 完整的工程我放在了完整工程,可以下载下来自己试一试。 1. 主要功能…...

如何用 OceanBase做业务开发——【DBA从入门到实践】第六期
当应用一款新的数据库时,除了基础的安装部署步骤,掌握其应用开发方法才是实现数据库价值的关键。为此,我们特别安排了5月15日(周三)的《DBA 从入门到实践》第六期课程——本次课程将带大家了解OceanBase数据库的开发流…...

新手入门使用 Python 快速接入 Taotoken 调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门使用 Python 快速接入 Taotoken 调用大模型 对于刚开始接触大模型 API 调用的开发者而言,如何快速、正确地接入…...

盐印相不是滤镜,是光学物理建模!:深度解析Midjourney --sref 与 --style raw 联动实现银盐晶体模拟原理
更多请点击: https://codechina.net 第一章:盐印相不是滤镜,是光学物理建模! 盐印相(Salt Print)作为一种19世纪诞生的早期摄影工艺,其成像本质并非数字图像处理中的风格化滤镜,而是…...

Unity城市建造工作流:模块化建筑与性能优化实践
1. 这不是“贴图堆砌”,而是一套可落地的城市建造工作流你有没有试过在Unity里搭一座像样的城镇?不是那种靠几个Cube拼起来的“示意场景”,而是真正有生活气息、有建筑逻辑、有视觉节奏的城镇——街道有宽窄变化,建筑有主次关系&a…...

UE5场景漫游跳转避坑指南:从UI交互到资源预热
1. 这不是“做个UI跳个关卡”那么简单:UE5场景漫游的起点陷阱 很多人拿到“UE5场景漫游——开始界面及关卡跳转”这个需求,第一反应是:“不就是加个UMG按钮,绑个OpenLevel节点?”我去年带三个实习生做文旅数字孪生项目…...

Unity预加载:减少游戏中首次加载资源时的卡顿
遇到的问题,如标题所示,所以写了如下模块。模块功能就是初始化时候,加载零散/文件夹的物体,代码如下:#region 启动预加载模块/// <summary> 预加载间隔(分帧防卡顿) </summary>priv…...

2026年必看:六款热门AI编程工具横评,Trae与Cursor怎么选
2026年必看:六款热门AI编程工具横评,Trae与Cursor怎么选AI编程工具正从辅助插件进化为全流程开发核心,2026年市场进入智能体协作新阶段。本文精选6款主流AI编程工具,从核心功能、协作模式、适配场景等维度深度解析,帮开…...

十三张扑克APP
能开发十三张扑克APP的请联系我,有客户渠道需要这类APP,要开发很多款十三张...

你的仿真传感器数据准吗?Gazebo中激光雷达与深度相机的噪声模型配置与Rviz可视化调参实战
高保真机器人仿真:Gazebo传感器噪声模型与Rviz可视化调参全指南 在机器人算法开发中,仿真环境的真实性直接决定了算法测试的有效性。许多SLAM和导航算法在仿真环境中表现优异,一旦部署到真实机器人上却出现各种问题,这往往源于仿真…...

专栏导读:为什么需要从 MM 理解 HMM
一个真实的困境 假设你是一个 GPU 计算框架的开发者。用户写了这样一段代码: float *data malloc(1GB); // ... 填充数据 ... gpu_kernel<<<grid, block>>>(data); // 希望 GPU 直接访问 data在传统编程模型下,这不可能工作——GPU …...

终极LDDC歌词工具指南:如何快速获取完美同步的逐字歌词
终极LDDC歌词工具指南:如何快速获取完美同步的逐字歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地…...