【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】
爬虫之scrapy框架——基本原理和步骤+爬取当当网(基本步骤)
- 下载scrapy框架
- 创建项目(项目文件夹不能使用数字开头,不能包含汉字)
- 创建爬虫文件
- (1)第一步:先进入到spiders文件中(进入相应的位置)
- (2)第二步:创建爬虫文件
- (3)第三步:查看创建的项目文件——检查路径是否正确
- 运行爬虫代码
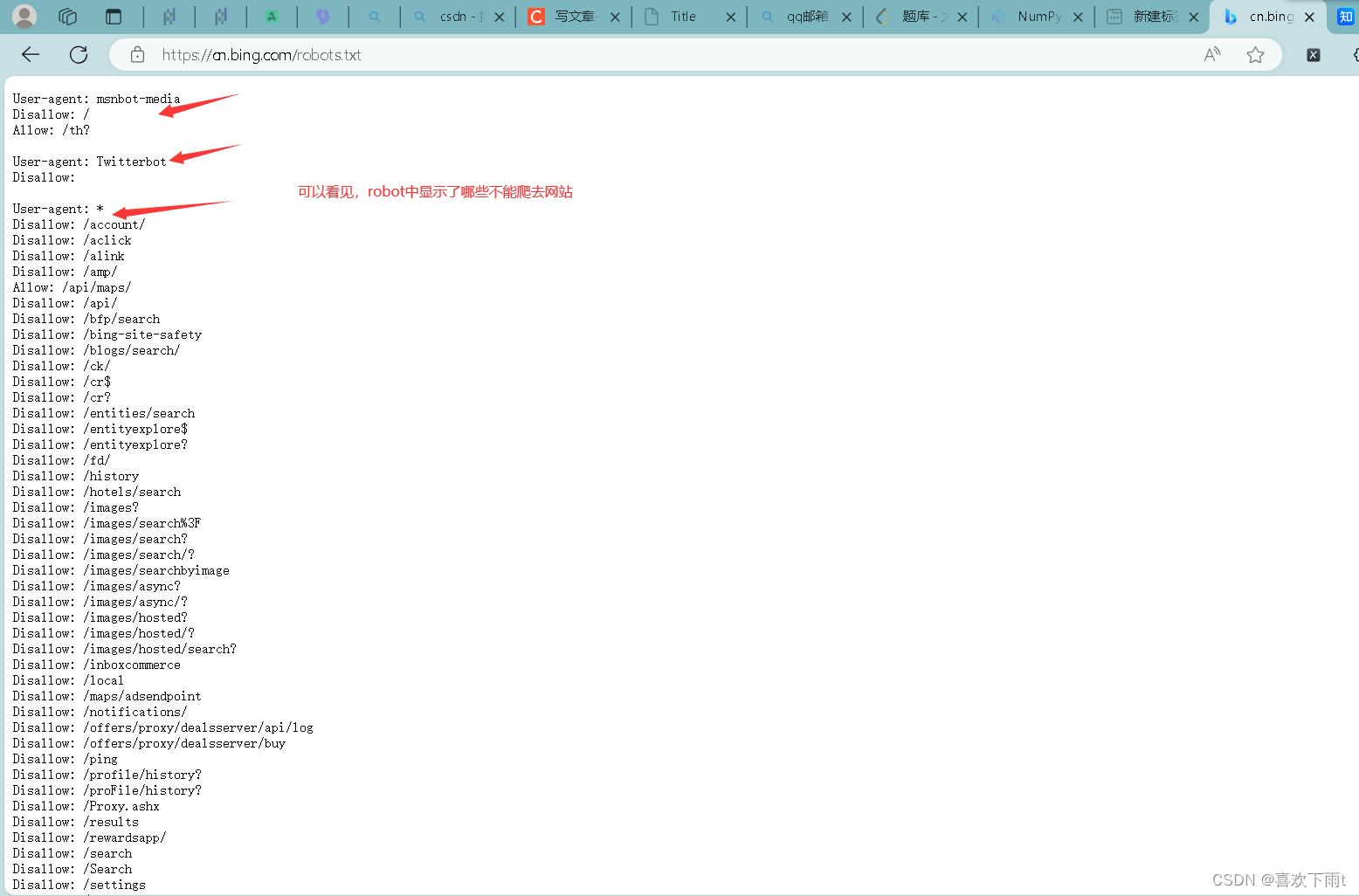
- 查看robots协议——是否有反爬取机制——君子协议(修改君子协议)
- (1)查看某网站的君子协议
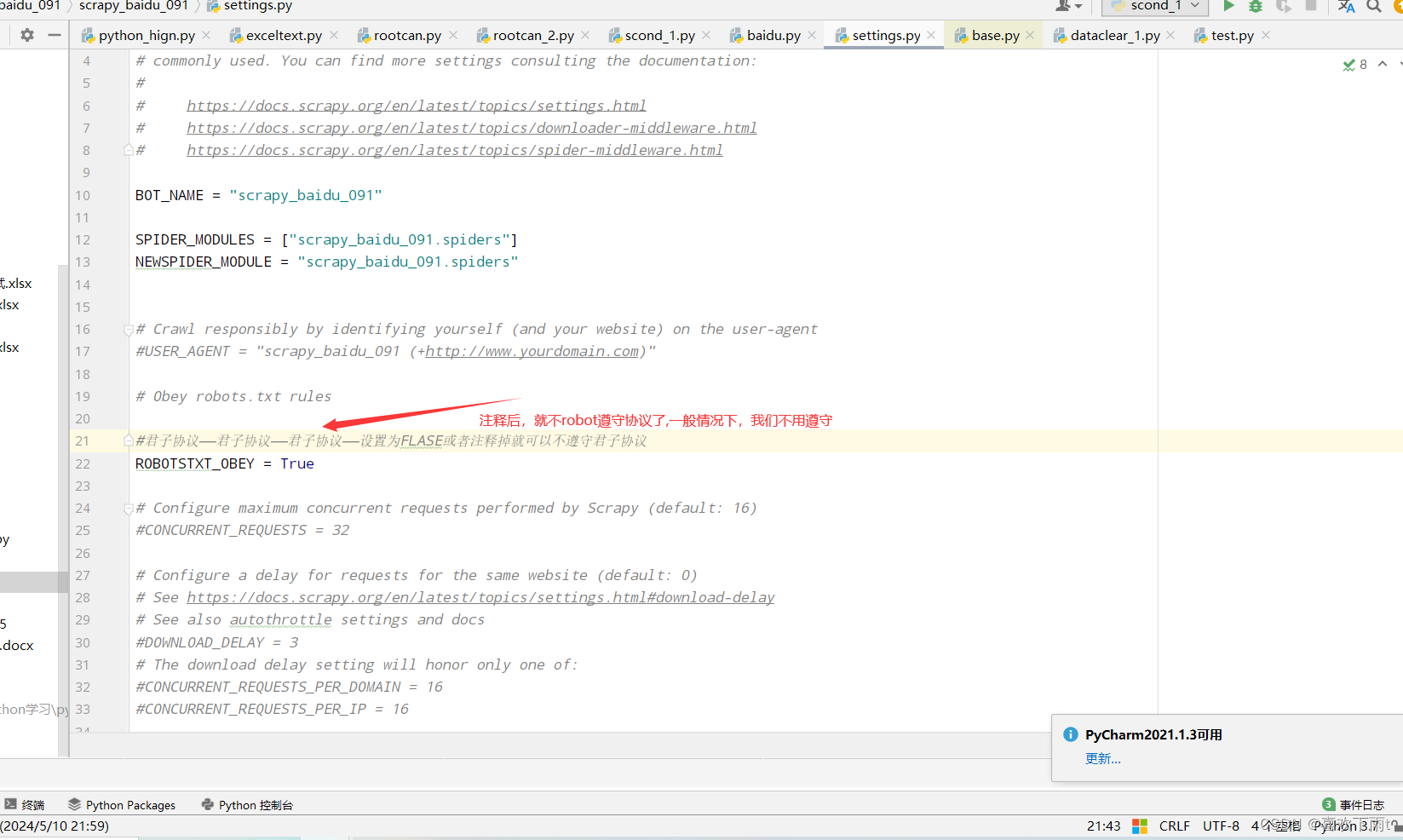
- (2)修改settings文件中君子协议
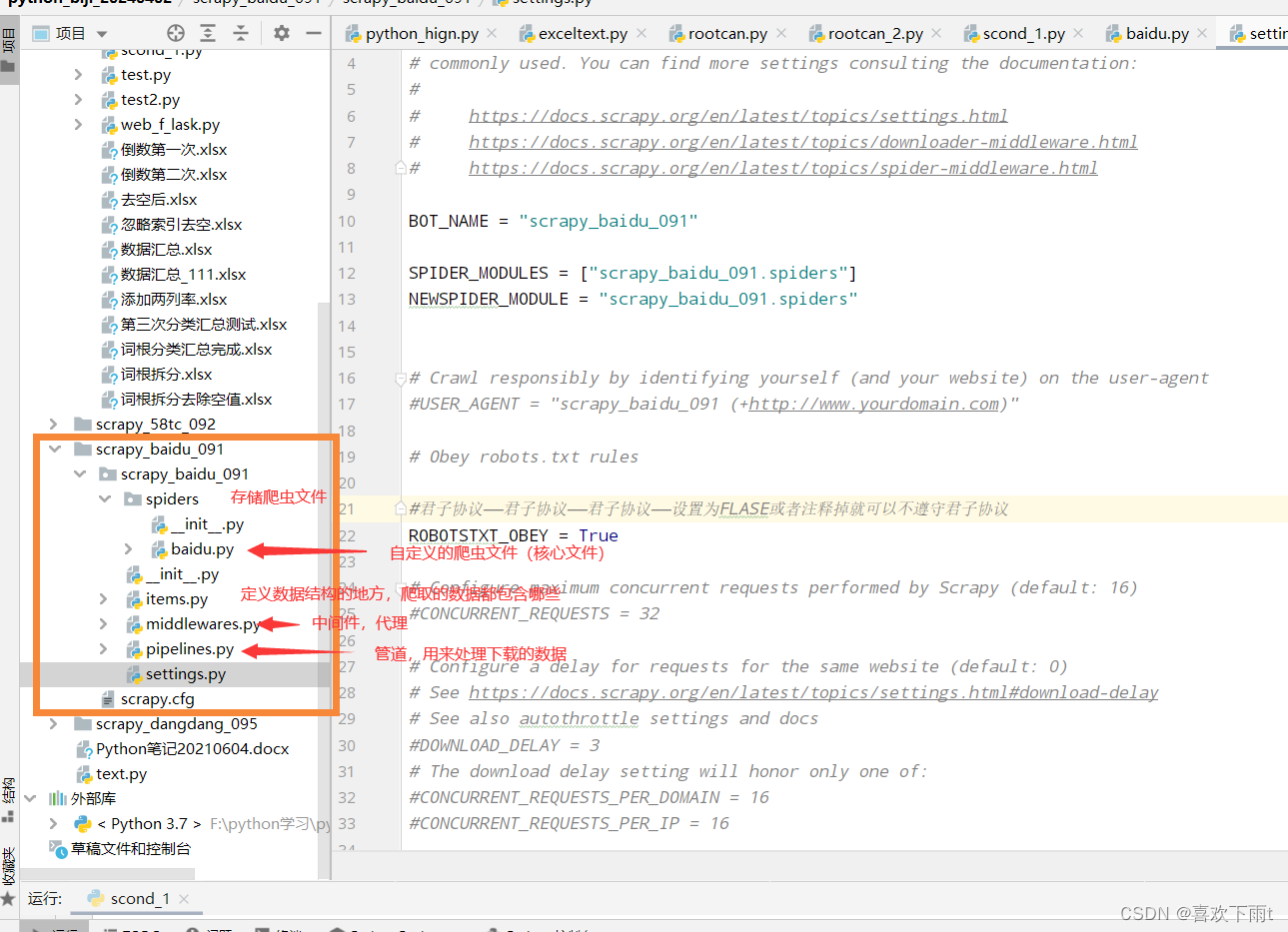
- scrapy项目的结构
- response的常用属性和方法
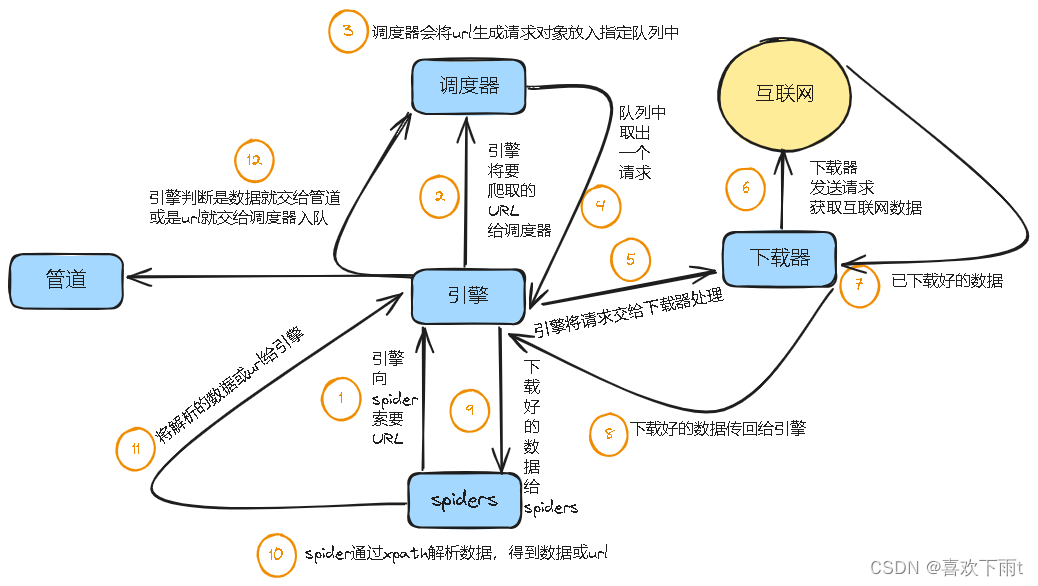
- scrapy框架原理解析
- scrapy sell 工具调试——具体下载不说明
- 当当网爬取案例
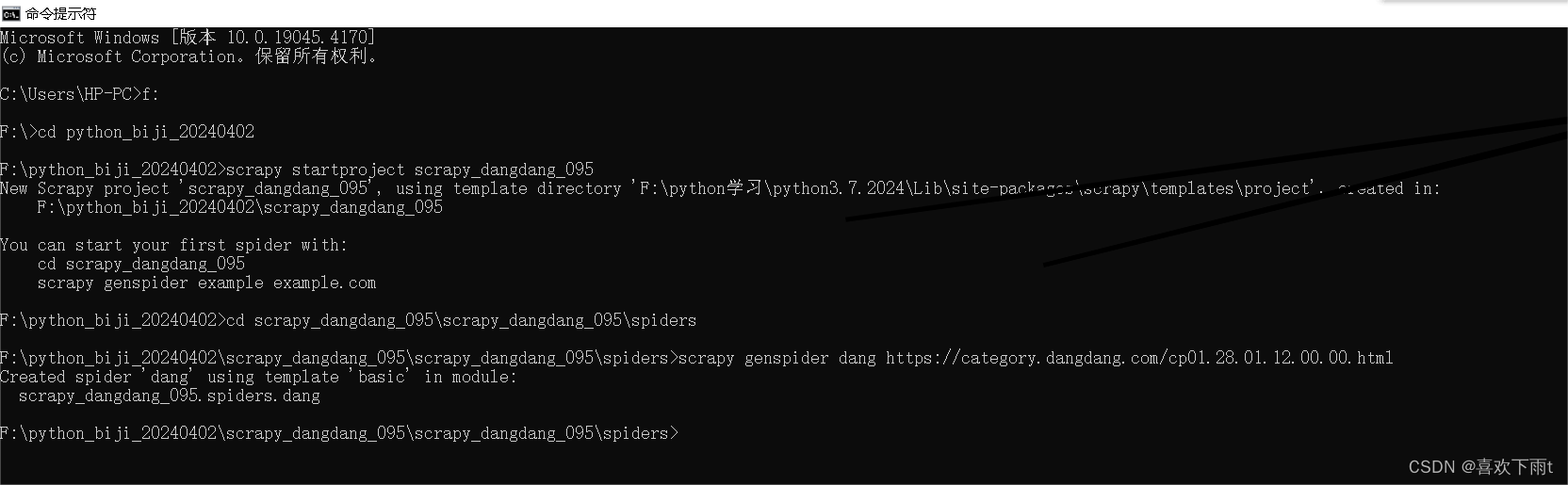
- 1. 创建当当网爬虫项目
- 2. 检查网址
- 3. 在函数中打印一条数据,看是否网站有反爬机制
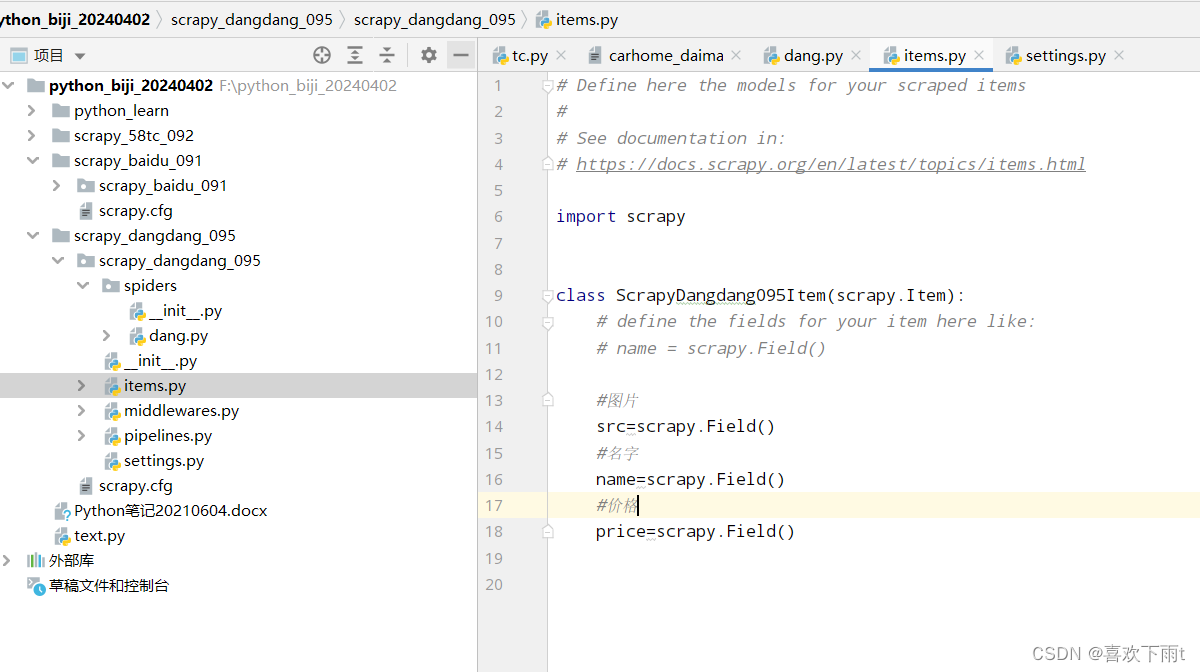
- 4. 定义数据结构——选择要爬取哪些属性
- 5. 去网址分析数据——拿到xpath表达式
- (1)拿到图片
- (2)拿到名字
- (3)拿到价格
- 6. 编写函数
- 7.运行后拿到数据
- 8.保存数据
- (1)封装数据——yield提交给管道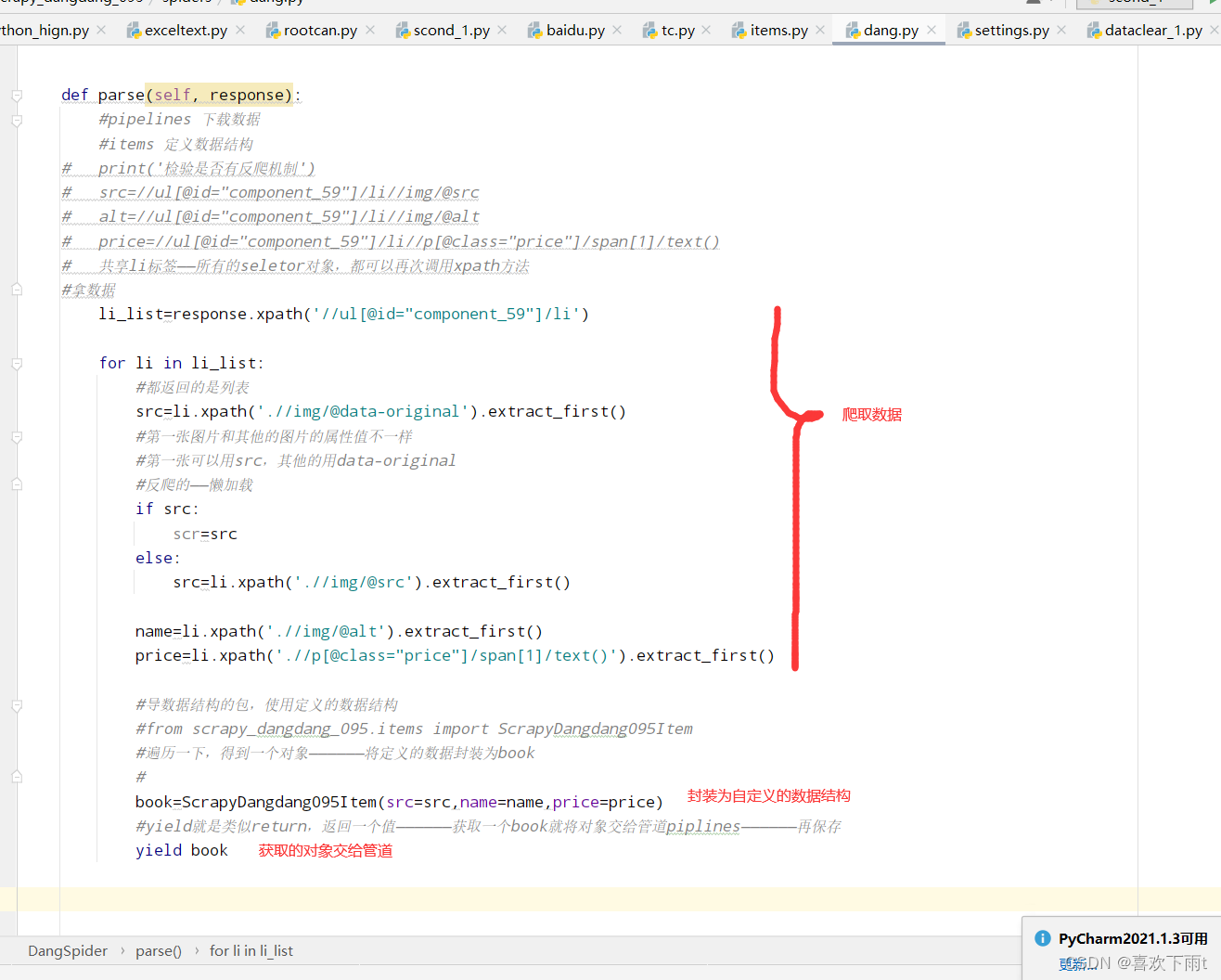
- (2)开启管道——保存内容
- 9.多条管道下载
- (1)定义管道类
- (2)在settings中开启管道
- 10.多页数据的下载
- (1)定义一个基本网址和page
- (2)重新调用def parse(self, response):函数——编写多页请求
- (3)修改allowed_domains的范围——一半多页请求范围编写域名即可
- 11.爬取核心代码
下载scrapy框架
scrapy安装视频链接
创建项目(项目文件夹不能使用数字开头,不能包含汉字)
cmd:
scrapy startproject 项目名称
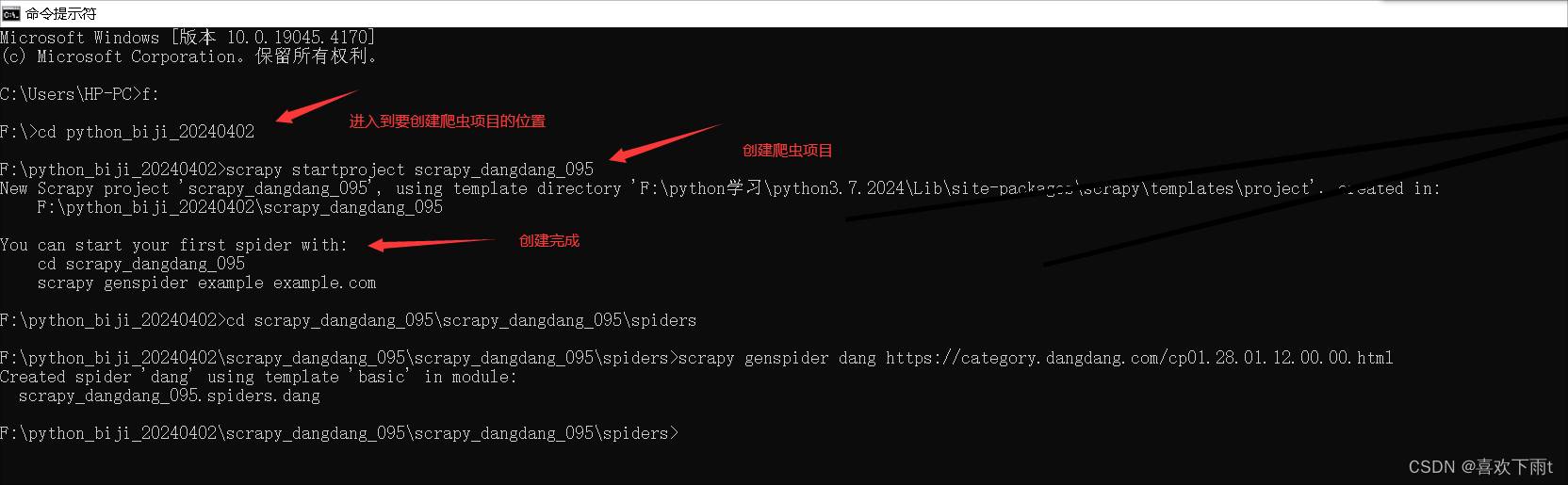
创建爬虫文件
(1)第一步:先进入到spiders文件中(进入相应的位置)
cd 项目的名字\项目的名字\spiders
(2)第二步:创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页网址
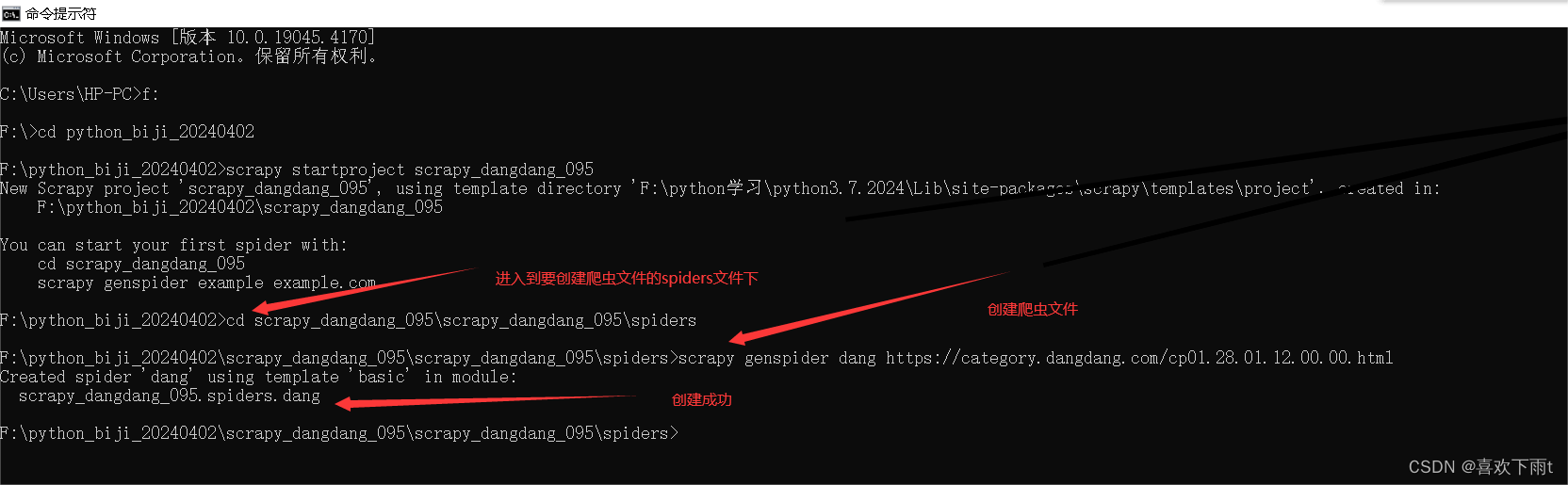
(3)第三步:查看创建的项目文件——检查路径是否正确
注意:不满足时需要手动修改(版本不同,造成的结果不一)
运行爬虫代码
scrapy crawl 爬虫的名字
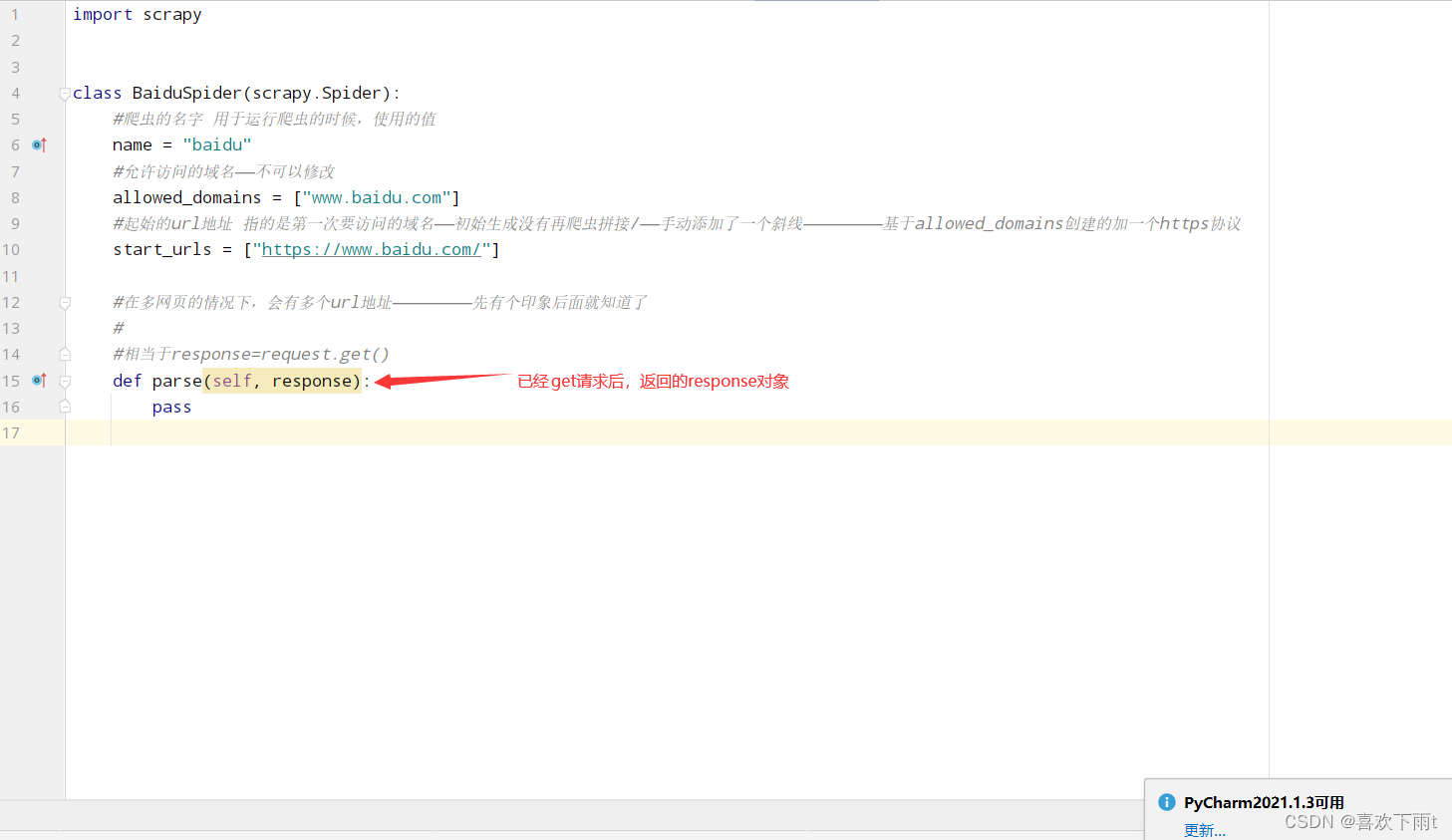
查看robots协议——是否有反爬取机制——君子协议(修改君子协议)
(1)查看某网站的君子协议
(2)修改settings文件中君子协议
scrapy项目的结构
response的常用属性和方法
(1)爬去网站的源码数据
content_1=response.txt
(2)爬去网站的二进制源码数据
response.body
(3)xpath方法可以用来解析response中的内容
response.xpath('')
(4)extract方法用来提取seletor对象的data属性值
response.extract()
(5)extract_first方法用来提取seletor列表的第一个数据
response.extract()
scrapy框架原理解析
scrapy sell 工具调试——具体下载不说明
(1)进入scrapy shell工具
scrapy shell 网址
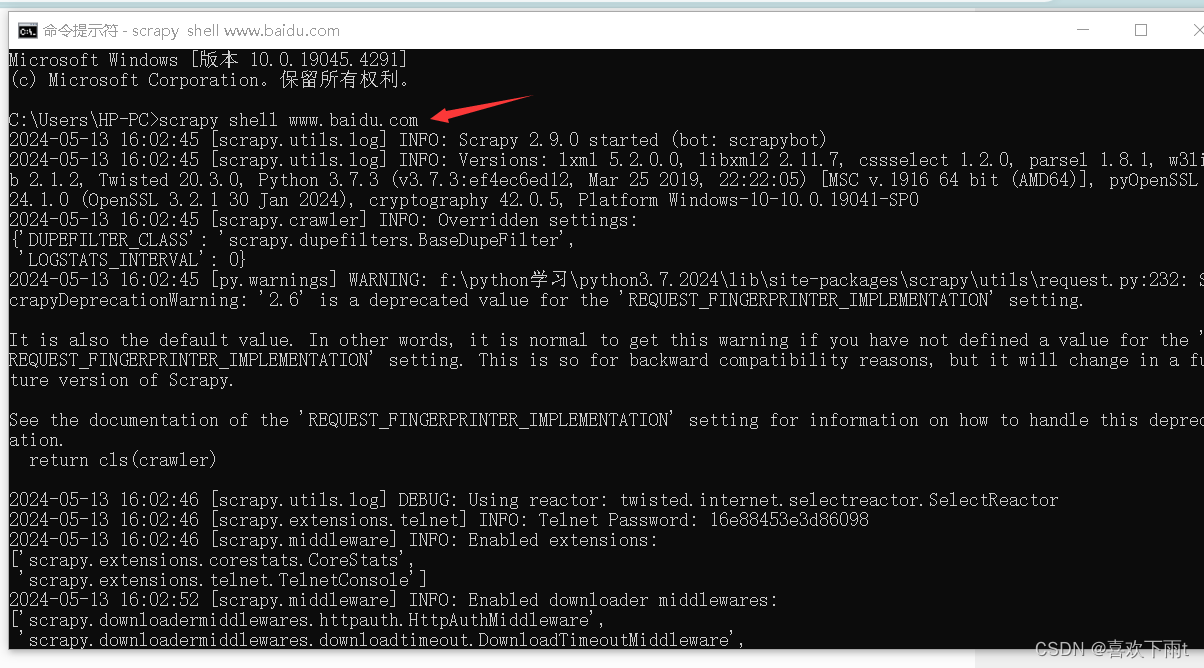
(2)可以看见有一个response对象
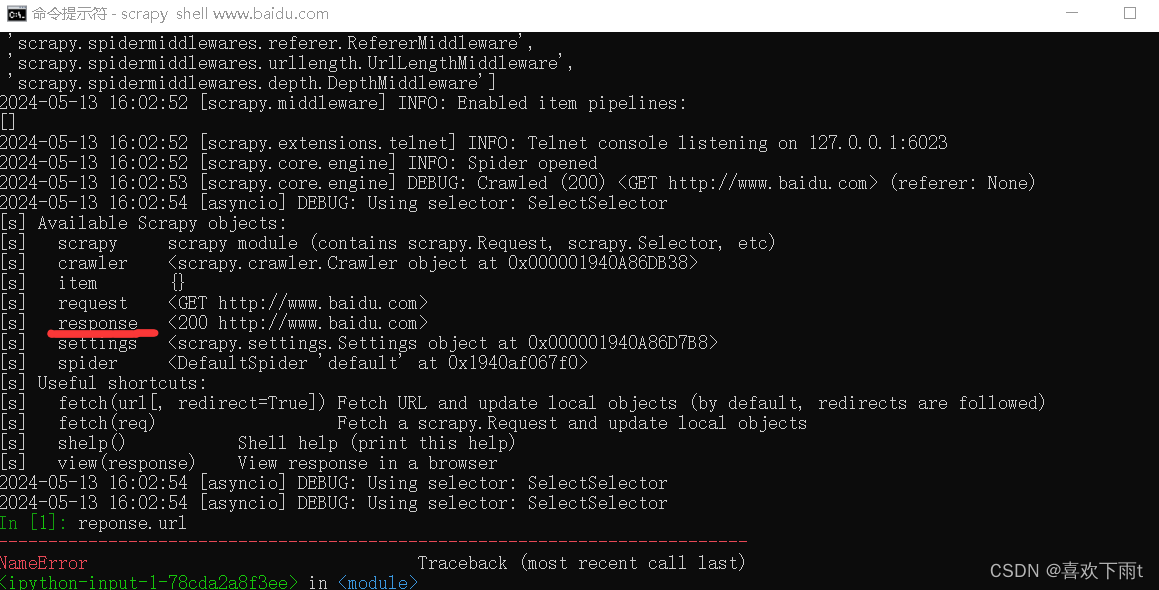
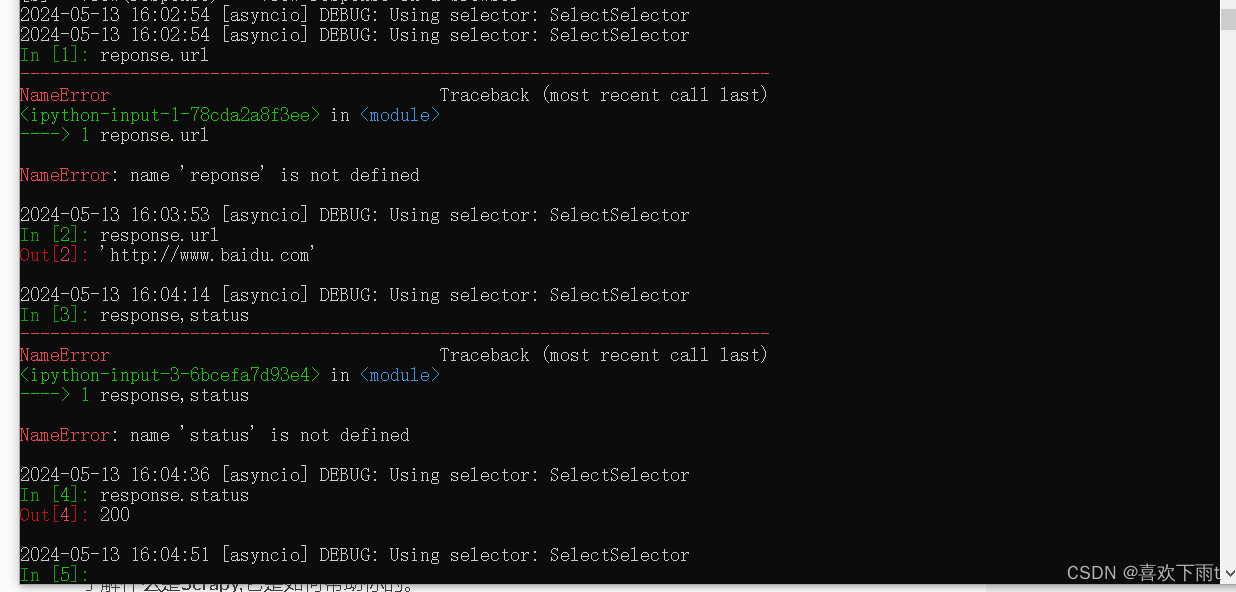
(3)可以对response对象进行操作调试(不用像项目一样每次多要运行项目,减少麻烦)
当当网爬取案例
1. 创建当当网爬虫项目
2. 检查网址
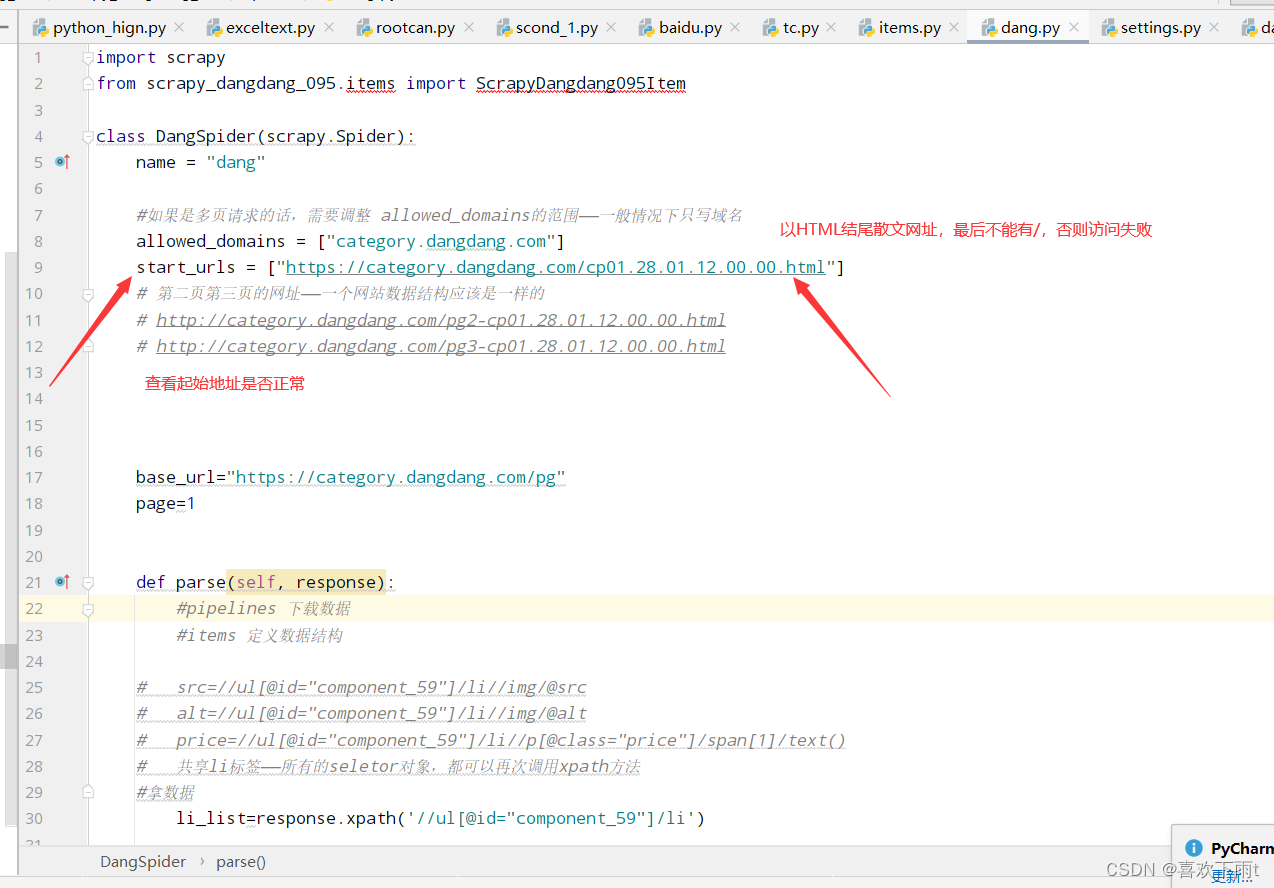
3. 在函数中打印一条数据,看是否网站有反爬机制
图1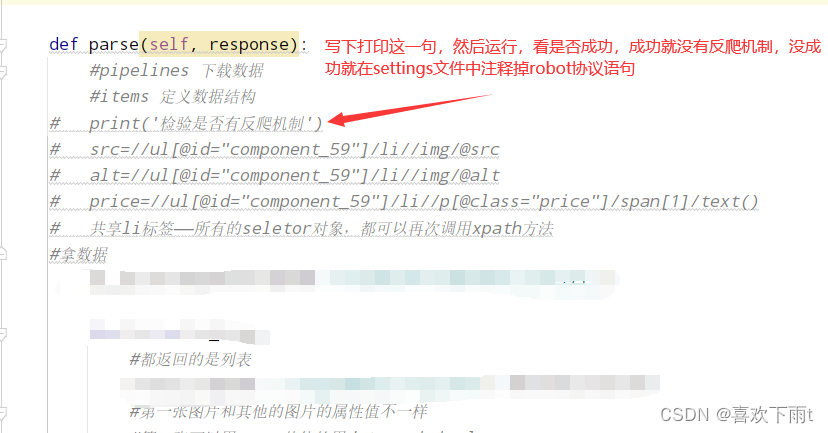
图2
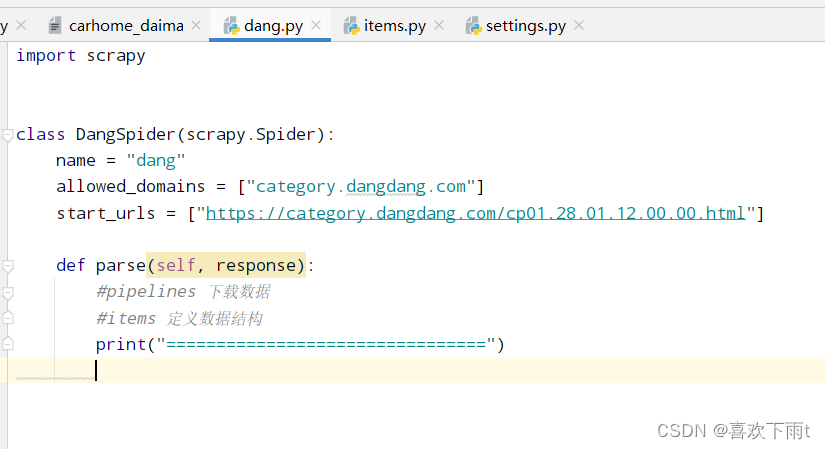
4. 定义数据结构——选择要爬取哪些属性
5. 去网址分析数据——拿到xpath表达式
(1)拿到图片
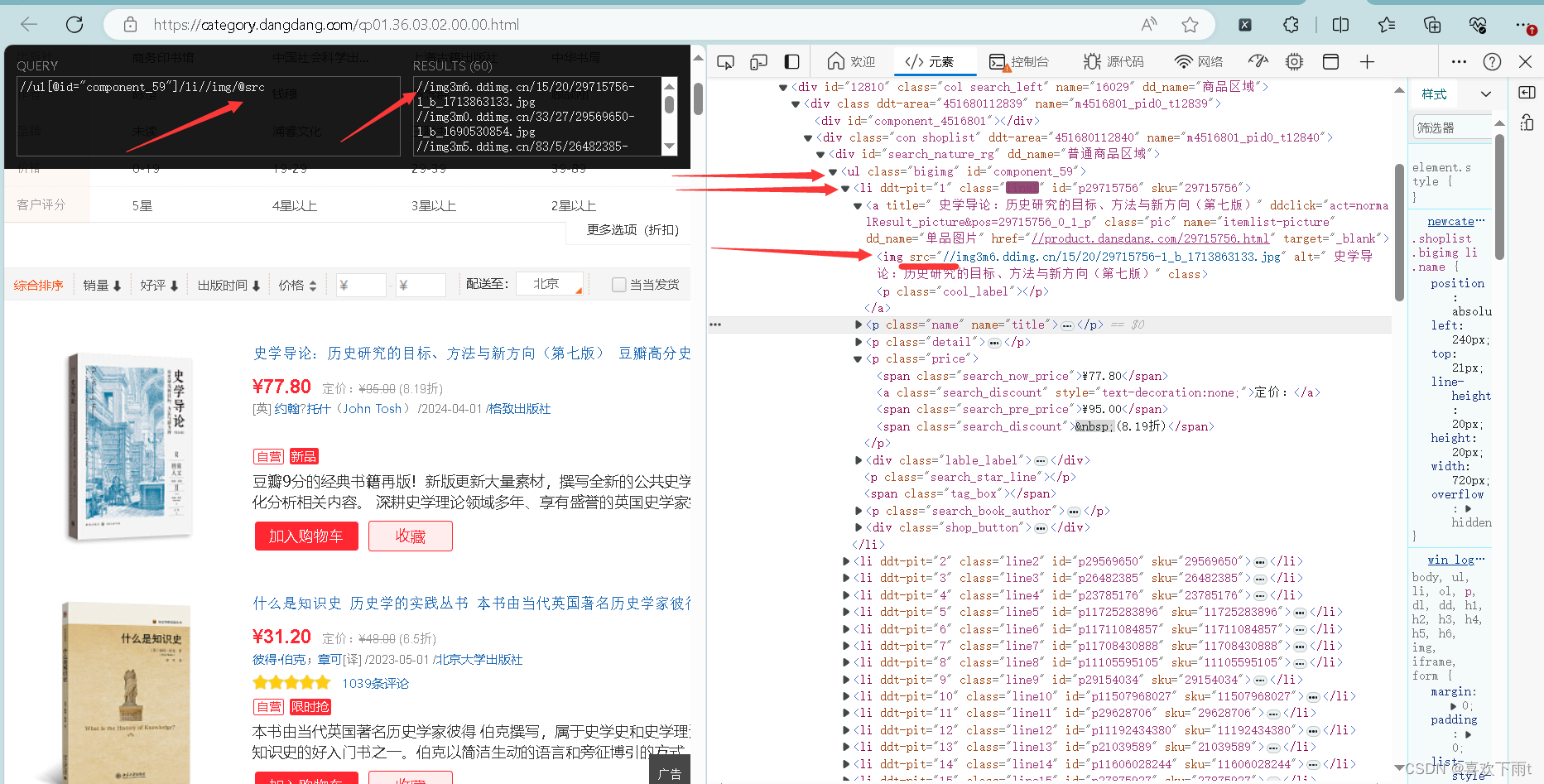
(2)拿到名字
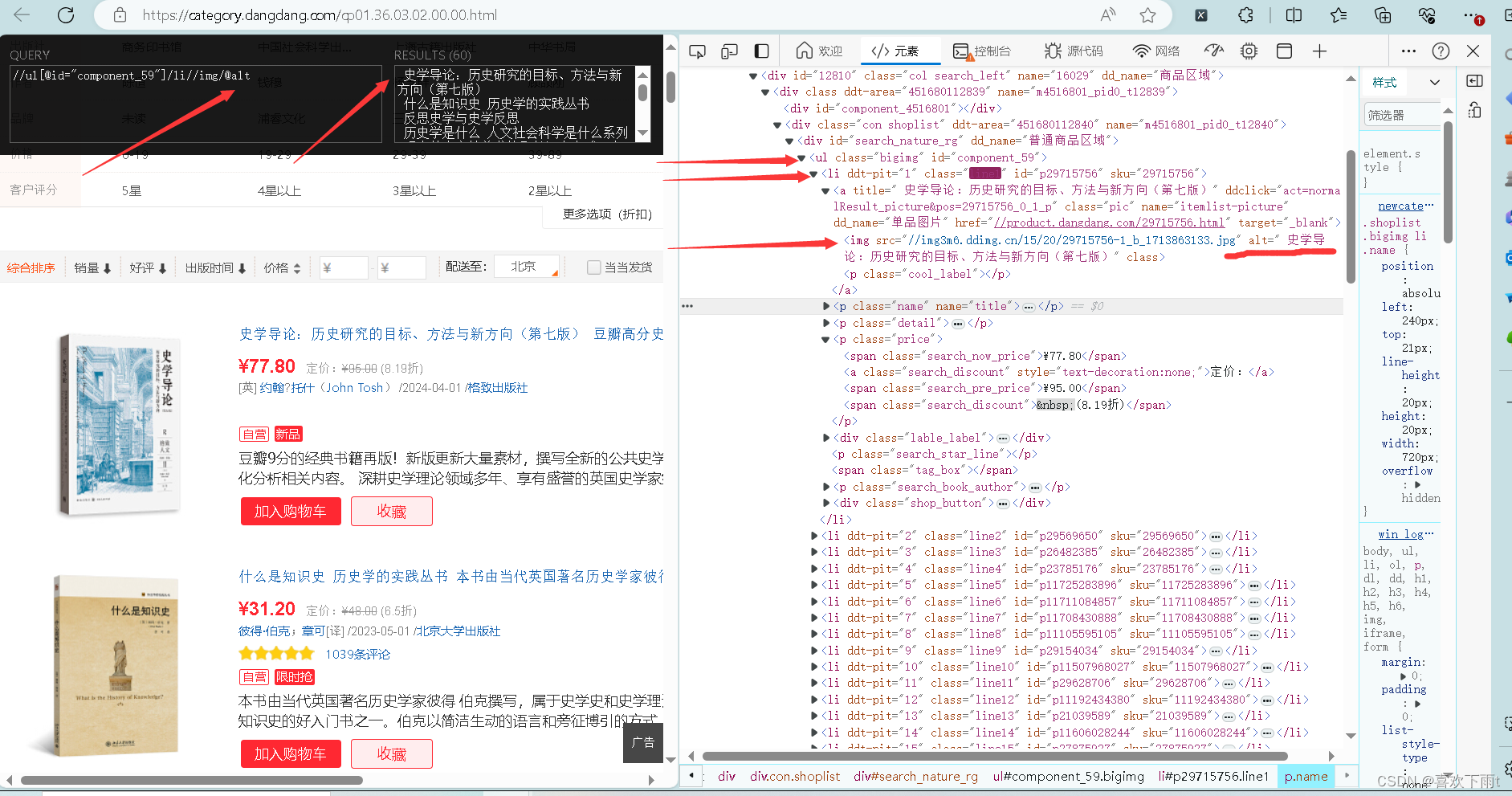
(3)拿到价格
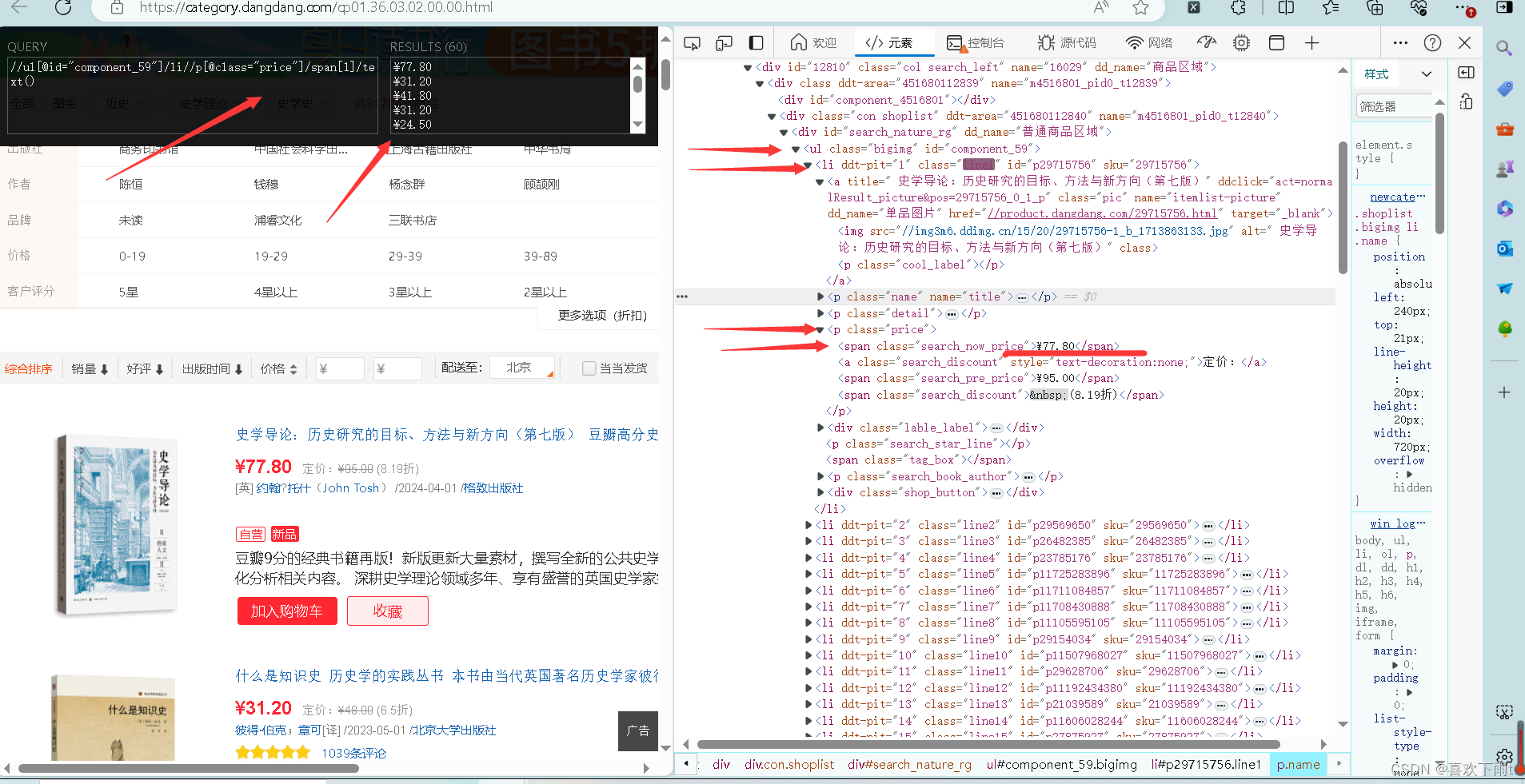
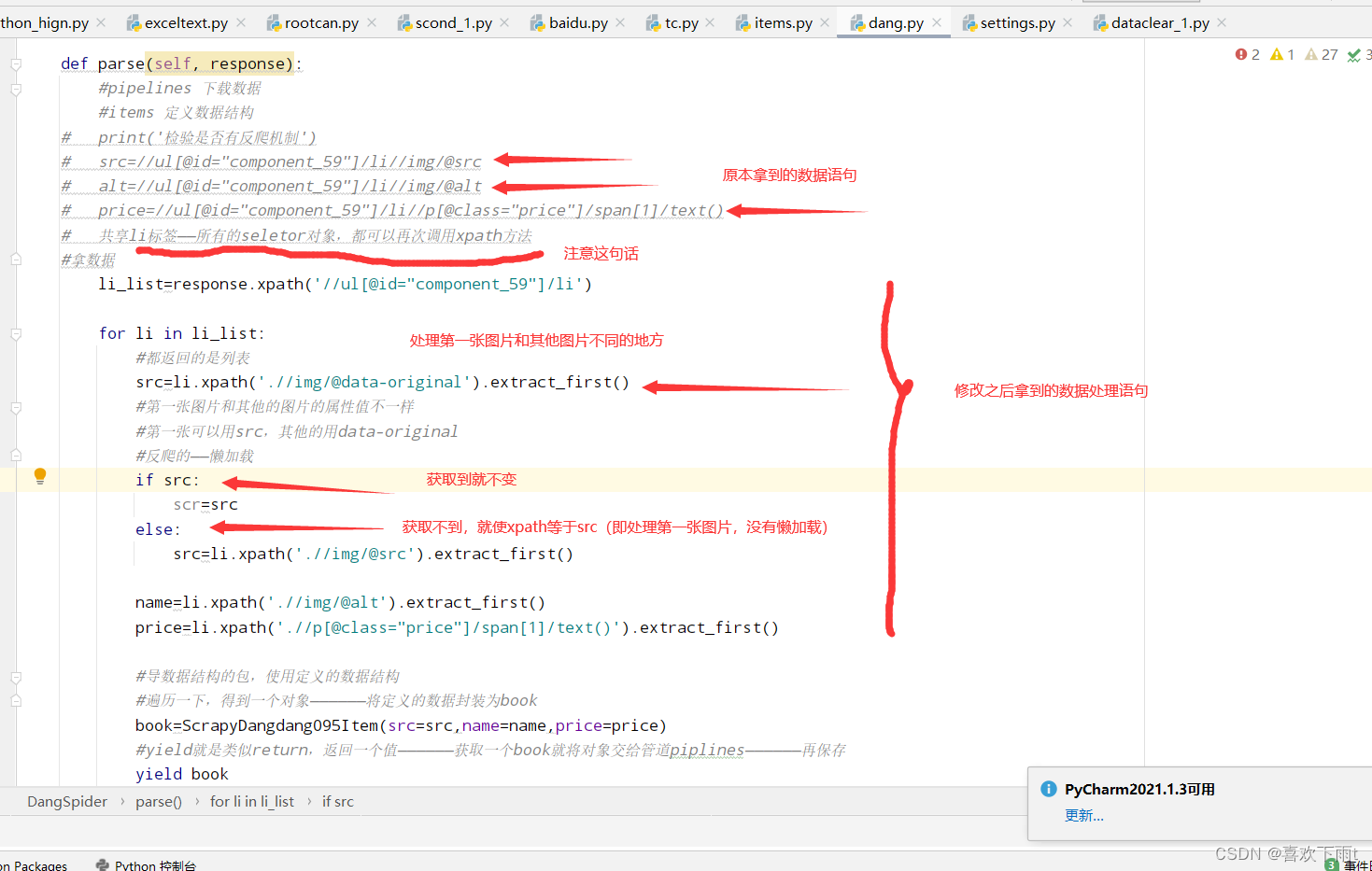
6. 编写函数
(1)懒加载处理
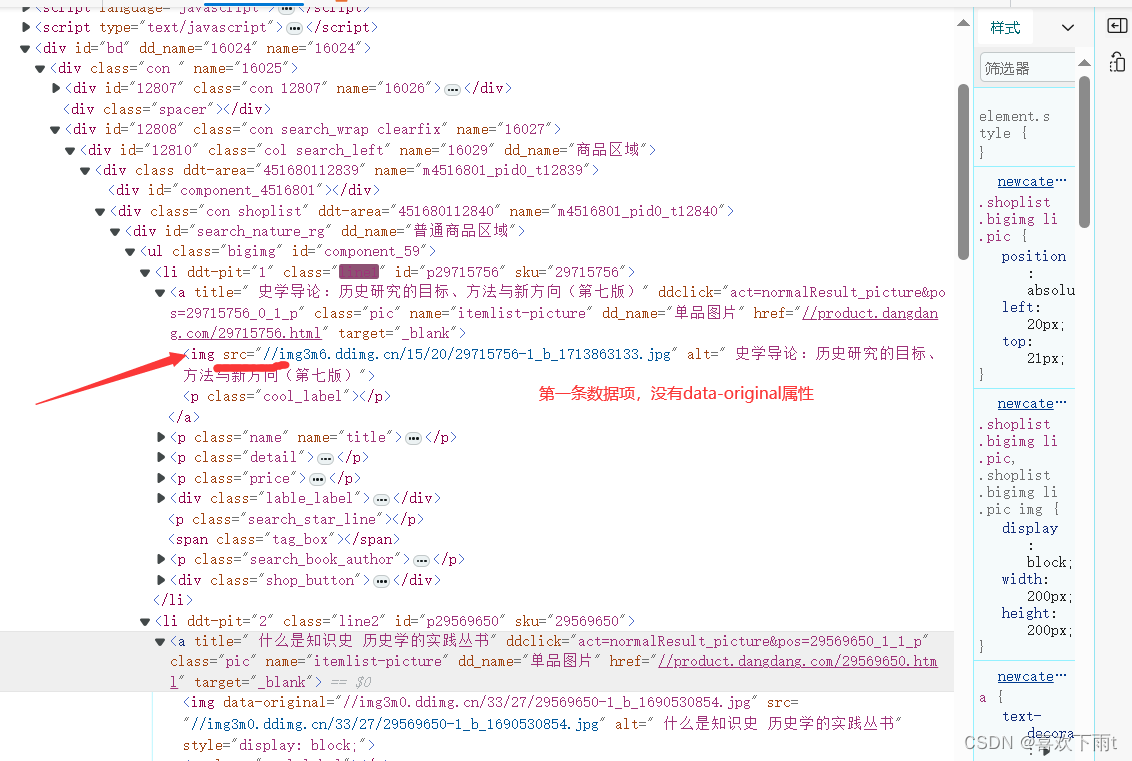
图1——非第一张图片(懒加载——有data-original)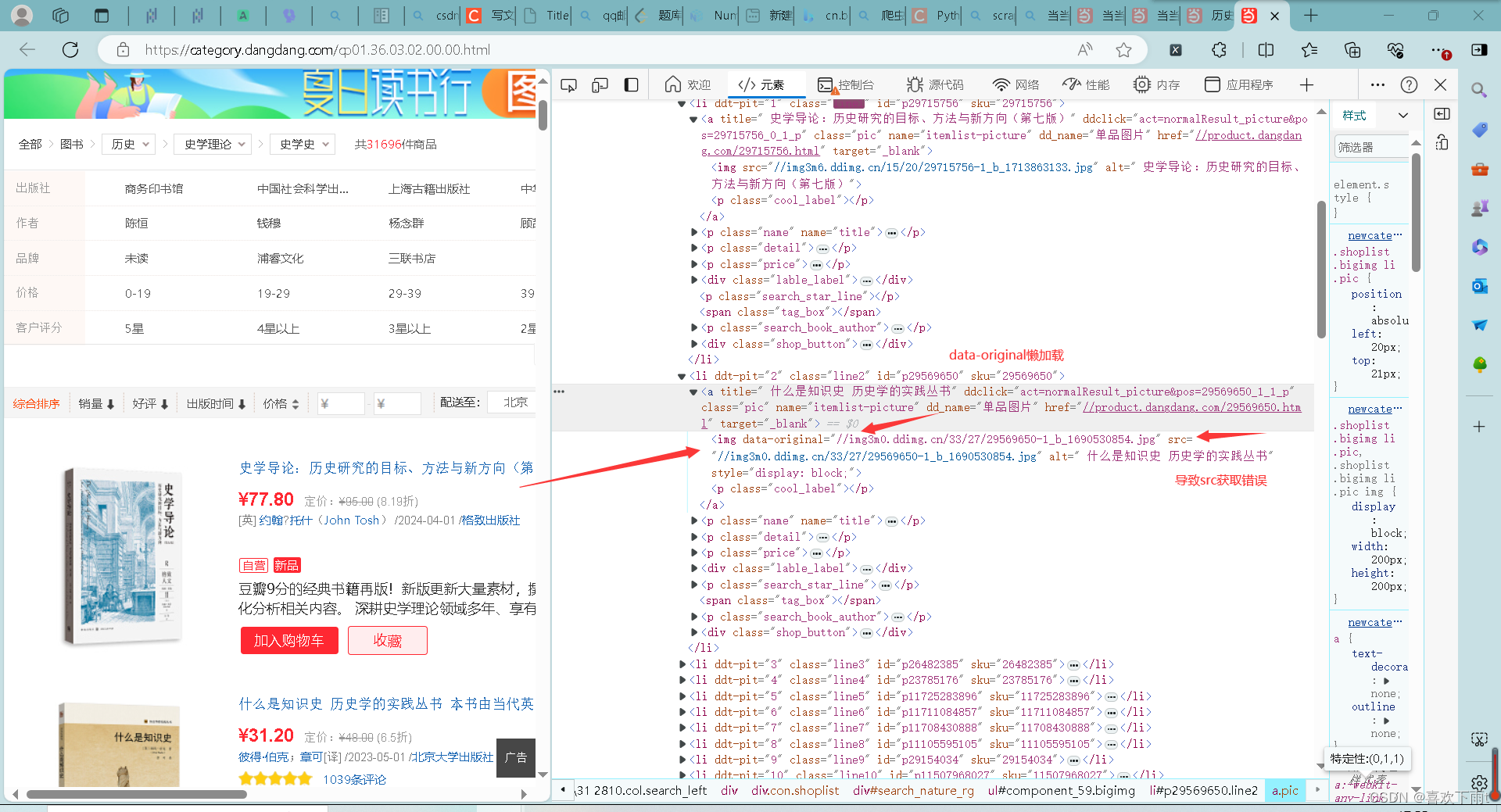 图2——第一张图片和其他的图片的属性值不一样
图2——第一张图片和其他的图片的属性值不一样
注:第一张可以用src,其他的用data-original
(2)代码解释如图:
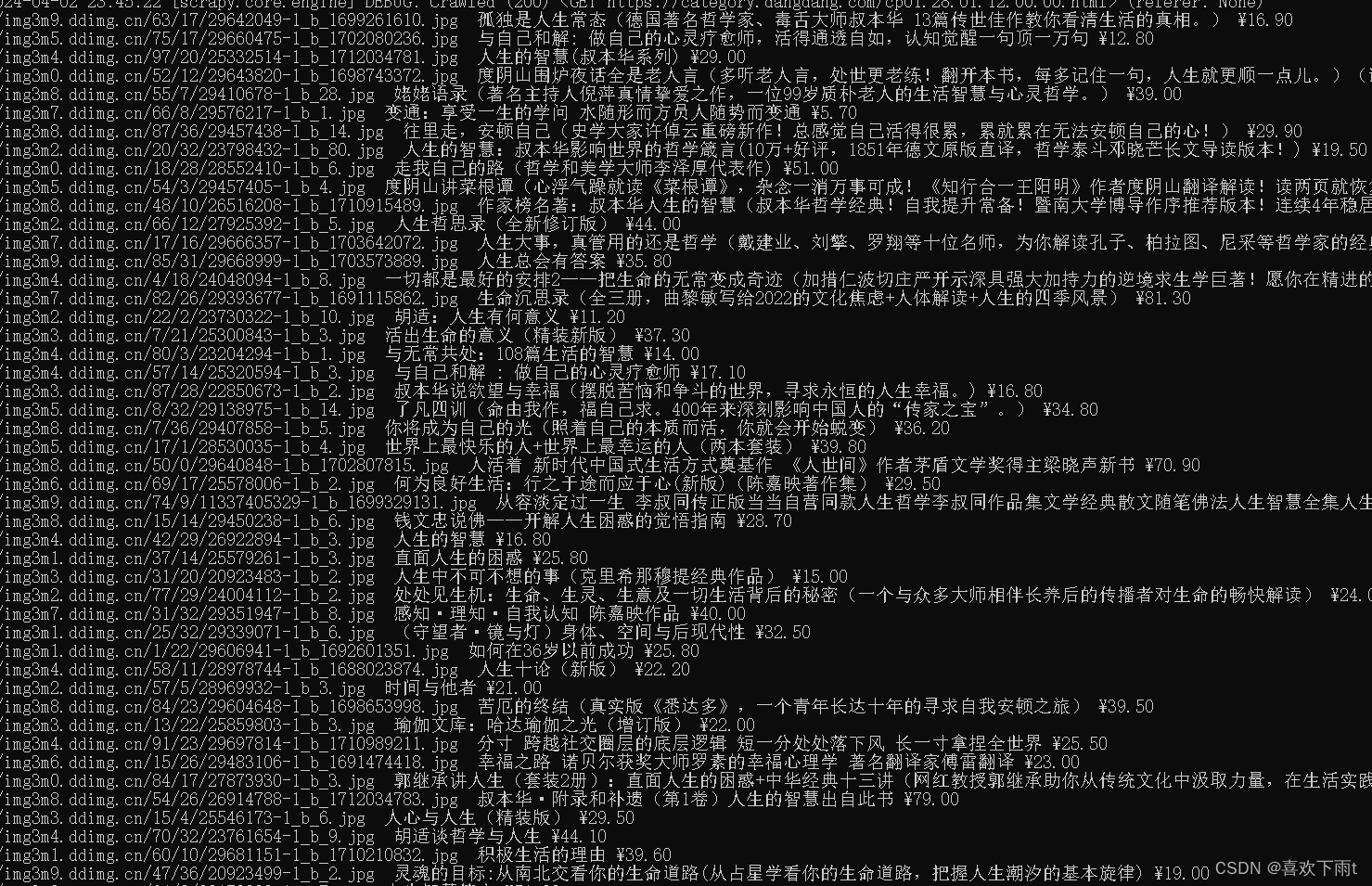
7.运行后拿到数据
scrapy crawl 爬虫的名字
8.保存数据
(1)封装数据——yield提交给管道
(2)开启管道——保存内容
图1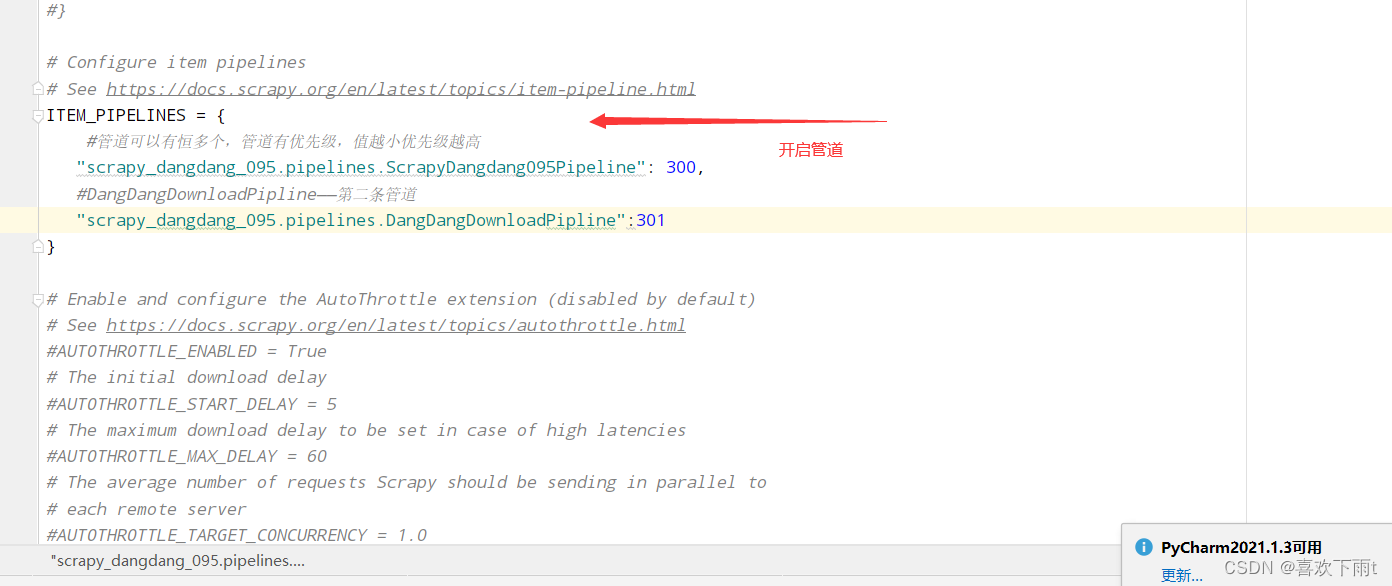
图2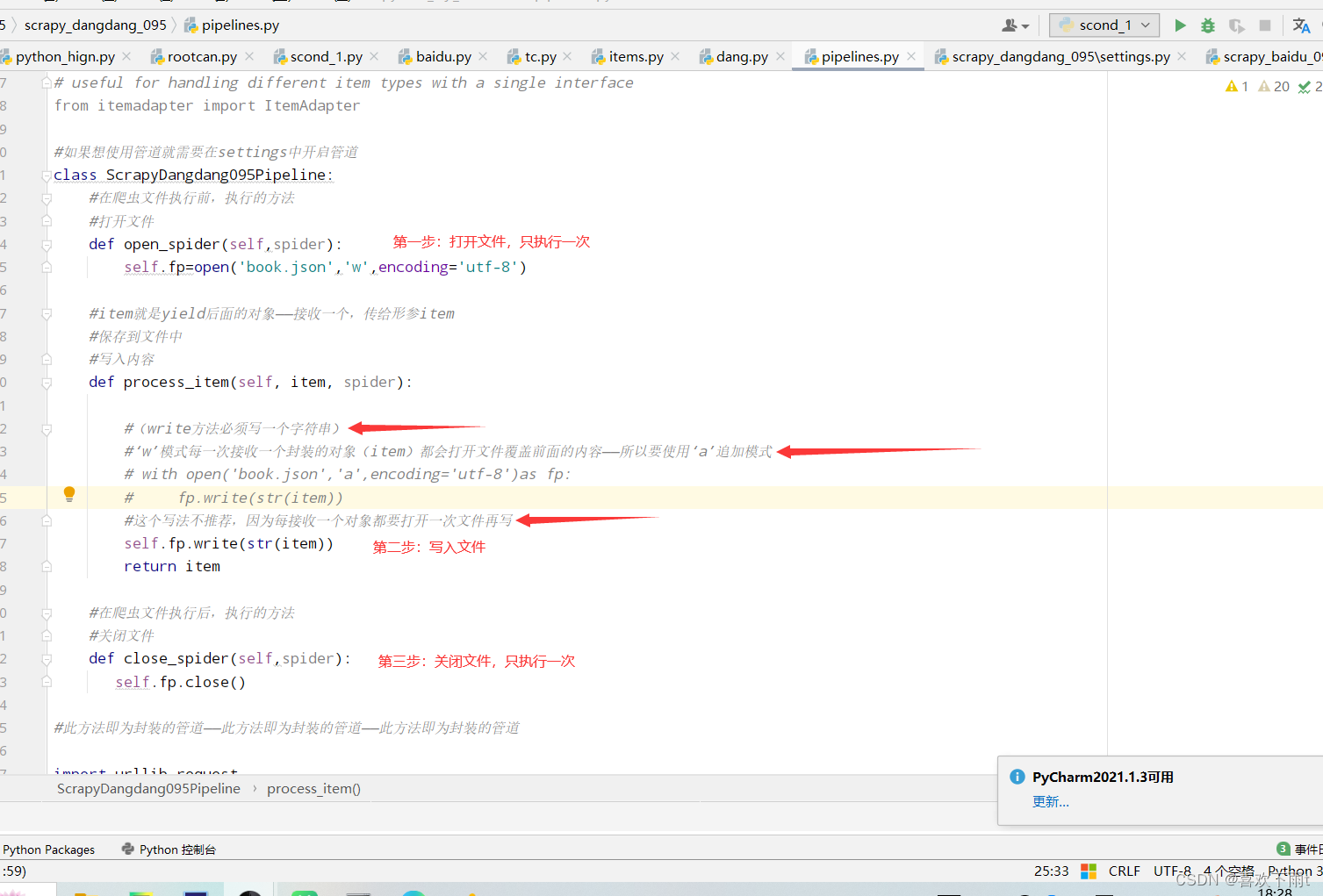
9.多条管道下载
(1)定义管道类
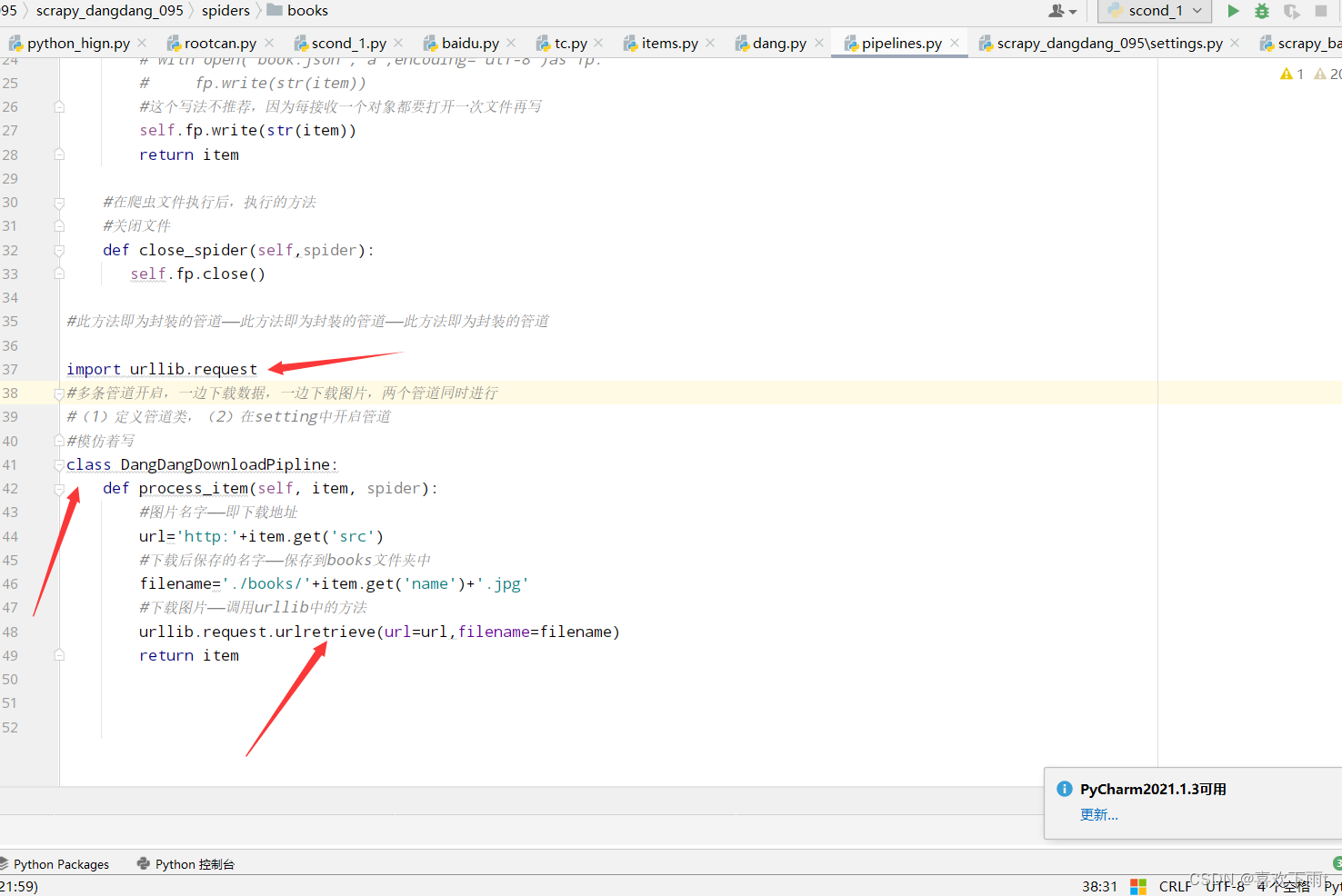
(2)在settings中开启管道
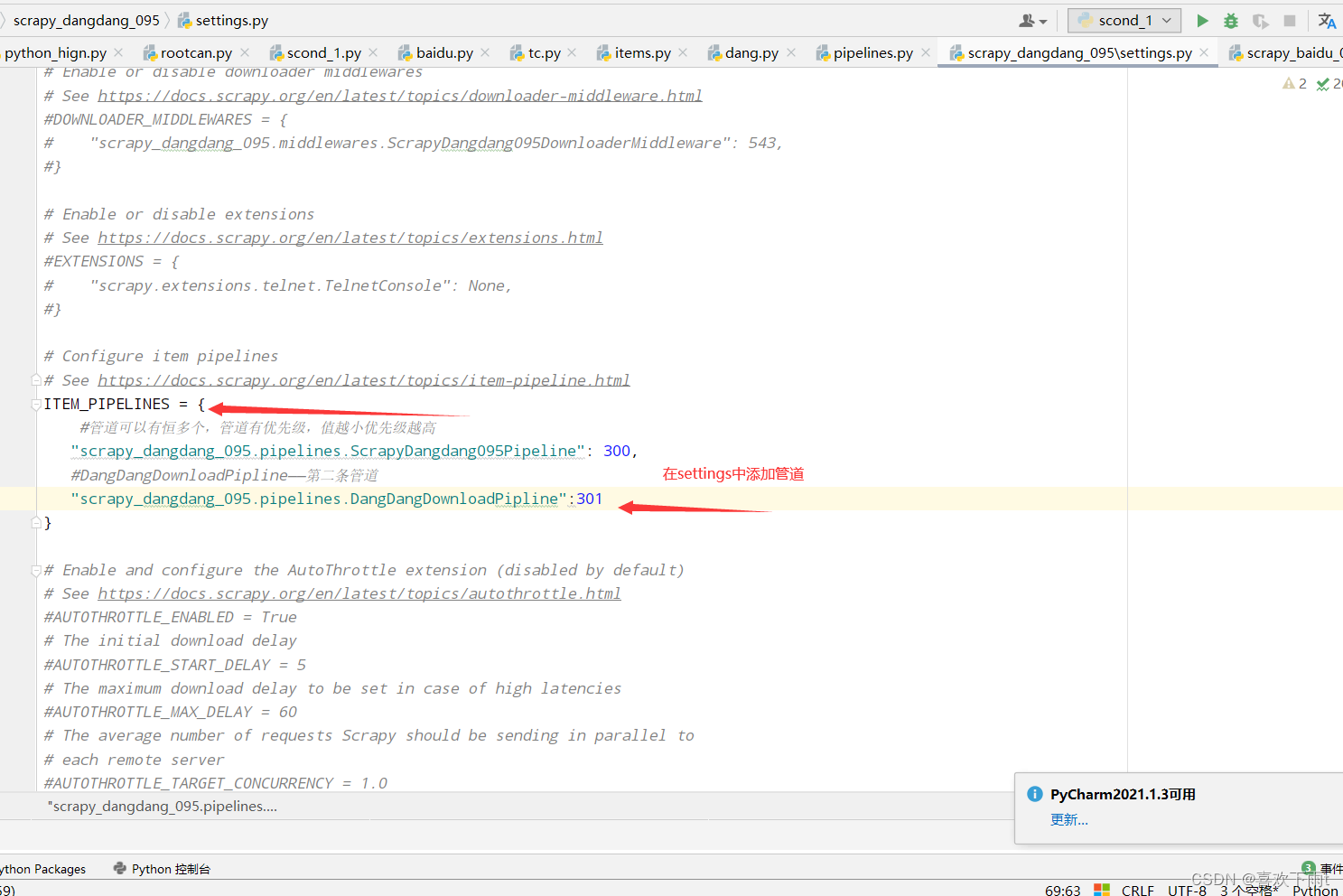
10.多页数据的下载
(1)定义一个基本网址和page
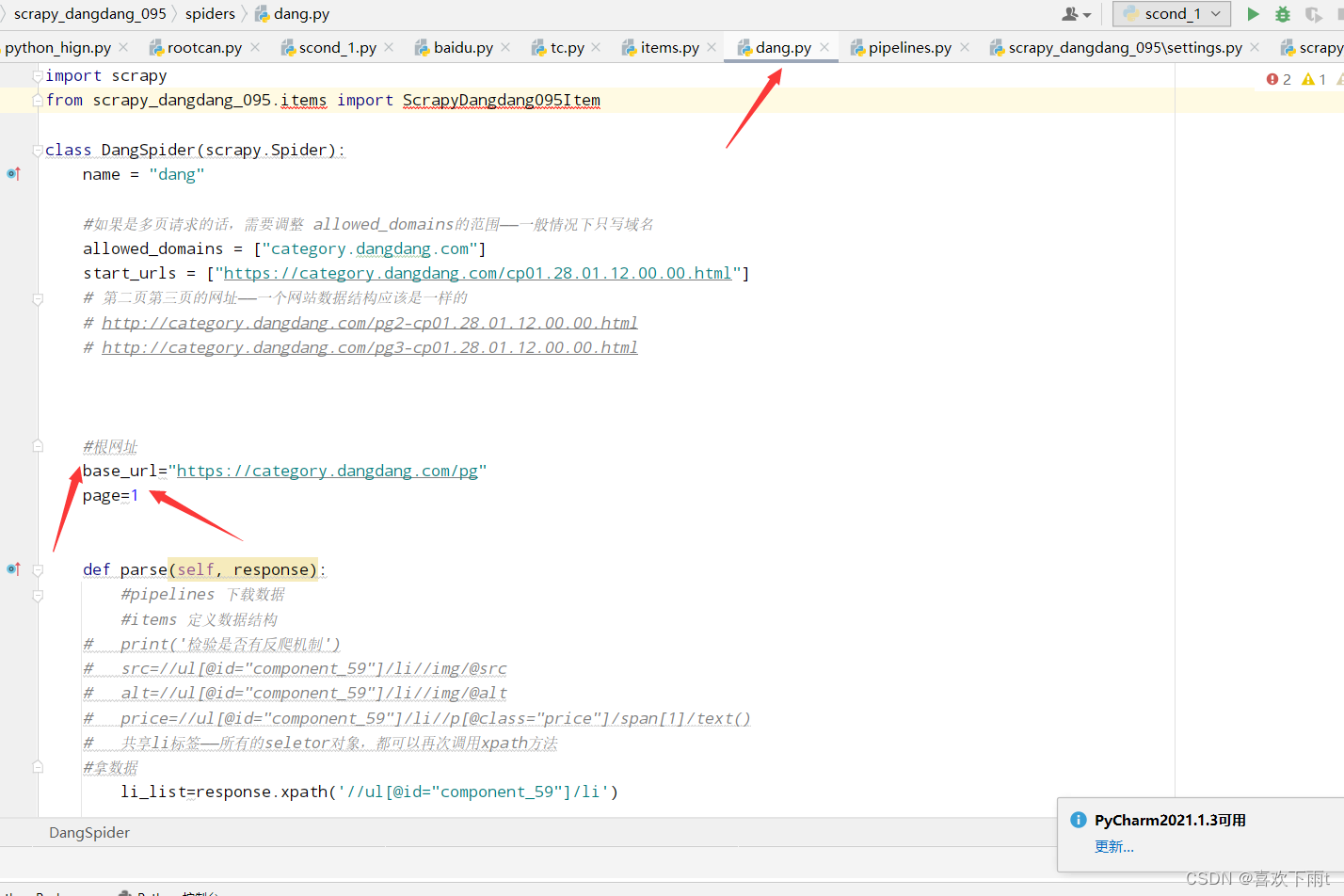
(2)重新调用def parse(self, response):函数——编写多页请求
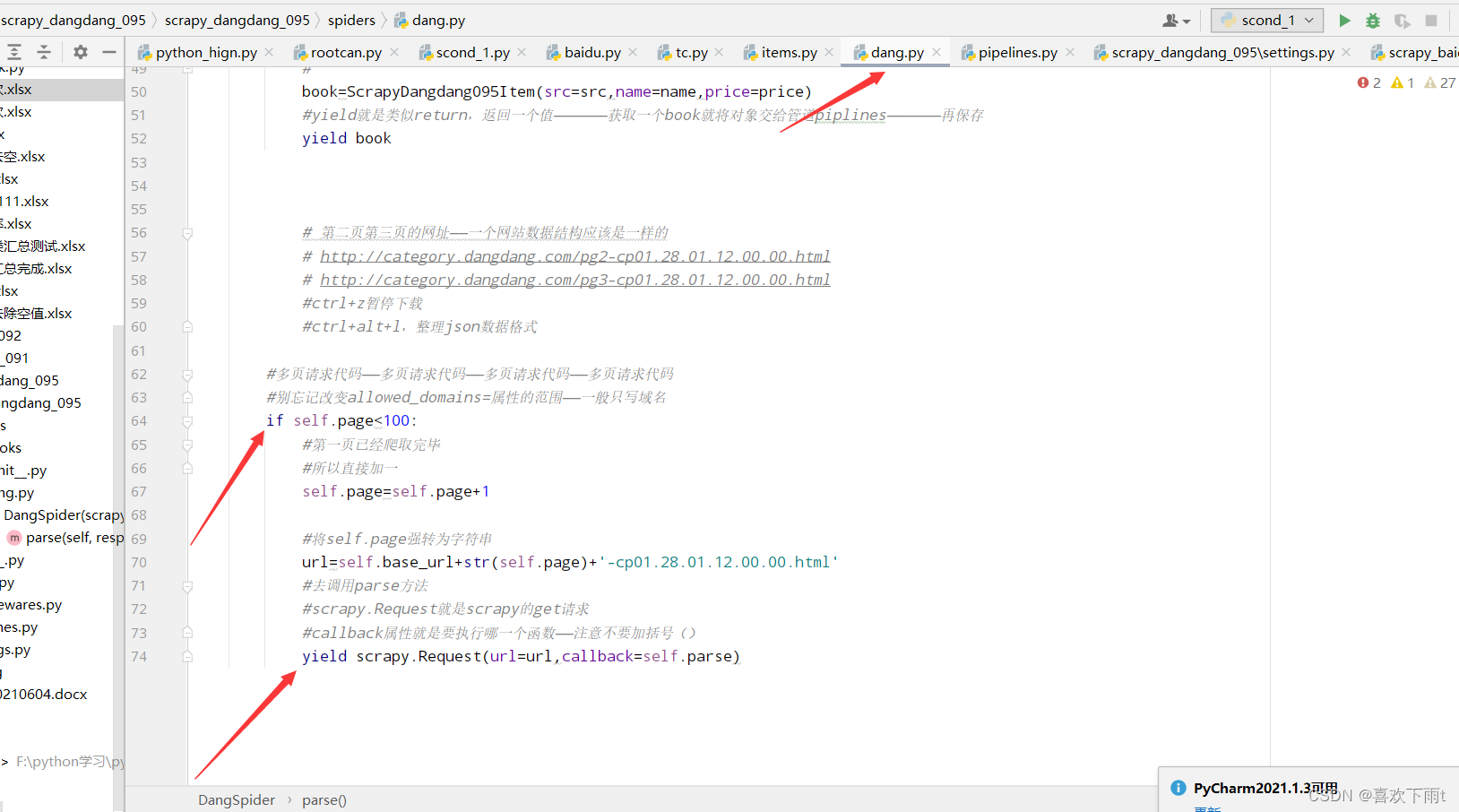
(3)修改allowed_domains的范围——一半多页请求范围编写域名即可
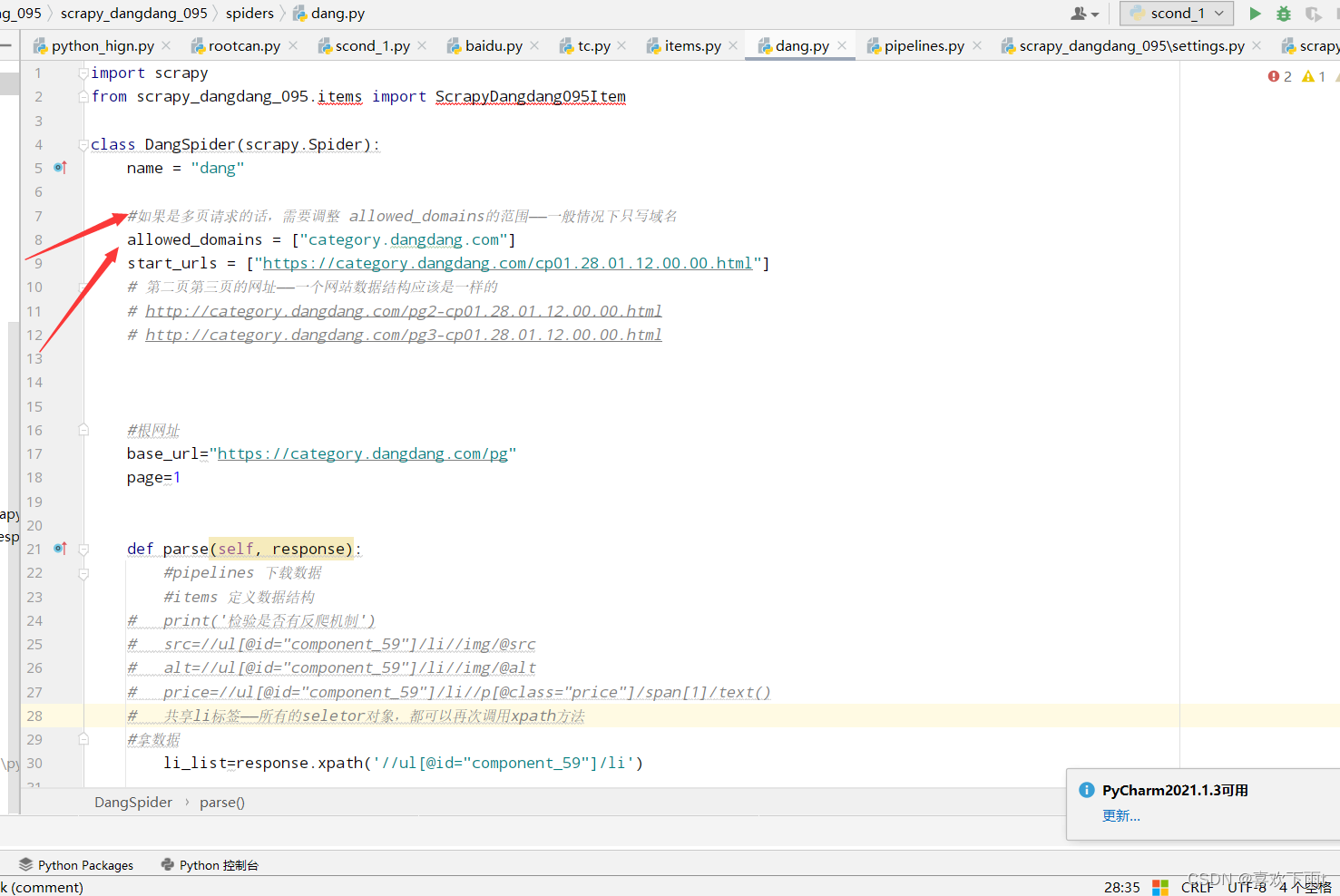
11.爬取核心代码
import scrapy
from scrapy_dangdang_095.items import ScrapyDangdang095Itemclass DangSpider(scrapy.Spider):name = "dang"#如果是多页请求的话,需要调整 allowed_domains的范围——一般情况下只写域名allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.28.01.12.00.00.html"]# 第二页第三页的网址——一个网站数据结构应该是一样的# http://category.dangdang.com/pg2-cp01.28.01.12.00.00.html# http://category.dangdang.com/pg3-cp01.28.01.12.00.00.html#根网址base_url="https://category.dangdang.com/pg"page=1def parse(self, response):#pipelines 下载数据#items 定义数据结构# print('检验是否有反爬机制')# src=//ul[@id="component_59"]/li//img/@src# alt=//ul[@id="component_59"]/li//img/@alt# price=//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()# 共享li标签——所有的seletor对象,都可以再次调用xpath方法#拿数据li_list=response.xpath('//ul[@id="component_59"]/li')for li in li_list:#都返回的是列表src=li.xpath('.//img/@data-original').extract_first()#第一张图片和其他的图片的属性值不一样#第一张可以用src,其他的用data-original#反爬的——懒加载if src:scr=srcelse:src=li.xpath('.//img/@src').extract_first()name=li.xpath('.//img/@alt').extract_first()price=li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()#导数据结构的包,使用定义的数据结构#from scrapy_dangdang_095.items import ScrapyDangdang095Item#遍历一下,得到一个对象——————将定义的数据封装为book#book=ScrapyDangdang095Item(src=src,name=name,price=price)#yield就是类似return,返回一个值——————获取一个book就将对象交给管道piplines——————再保存yield book# 第二页第三页的网址——一个网站数据结构应该是一样的# http://category.dangdang.com/pg2-cp01.28.01.12.00.00.html# http://category.dangdang.com/pg3-cp01.28.01.12.00.00.html#ctrl+z暂停下载#ctrl+alt+l,整理json数据格式#多页请求代码——多页请求代码——多页请求代码——多页请求代码#别忘记改变allowed_domains=属性的范围——一般只写域名if self.page<100:#第一页已经爬取完毕#所以直接加一self.page=self.page+1#将self.page强转为字符串url=self.base_url+str(self.page)+'-cp01.28.01.12.00.00.html'#去调用parse方法#scrapy.Request就是scrapy的get请求#callback属性就是要执行哪一个函数——注意不要加括号()yield scrapy.Request(url=url,callback=self.parse)
相关文章:
【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】
爬虫之scrapy框架——基本原理和步骤爬取当当网(基本步骤) 下载scrapy框架创建项目(项目文件夹不能使用数字开头,不能包含汉字)创建爬虫文件(1)第一步:先进入到spiders文件中&#x…...

C++ QT设计模式:责任链模式
基本概念 责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,将请求沿着处理链传递,直到有一个对象能够处理为止。 实现的模块有: Handler(处理者):定义一个处理…...
基于springboot+mybatis+vue的项目实战之(后端+前后端联调)
步骤: 1、项目准备:创建数据库(之前已经创建则忽略),以及数据库连接 2、建立项目结构文件夹 3、编写pojo文件 4、编写mapper文件,并测试sql语句是否正确 5、编写service文件 6、编写controller文件 …...
实战篇)
【教程向】从零开始创建浏览器插件(六)实战篇
【教程向】从零开始创建浏览器插件(六)实战篇 在这篇文章中,我们将详细介绍一个名为“摸鱼King”的Chrome扩展程序的开发思路。这个扩展程序的主要功能是在用户浏览网页时提供便捷的方式来摸鱼看小说。 完整的工程我放在了完整工程,可以下载下来自己试一试。 1. 主要功能…...

如何用 OceanBase做业务开发——【DBA从入门到实践】第六期
当应用一款新的数据库时,除了基础的安装部署步骤,掌握其应用开发方法才是实现数据库价值的关键。为此,我们特别安排了5月15日(周三)的《DBA 从入门到实践》第六期课程——本次课程将带大家了解OceanBase数据库的开发流…...
Element-UI快速入门
作者介绍:✌️大厂全栈码农|毕设实战开发,专注于大学生项目实战开发、讲解和毕业答疑辅导。 推荐订阅精彩专栏 👇🏻 避免错过下次更新 Springboot项目精选实战案例 更多项目:CSDN主页YAML墨韵 学如逆水行舟,…...
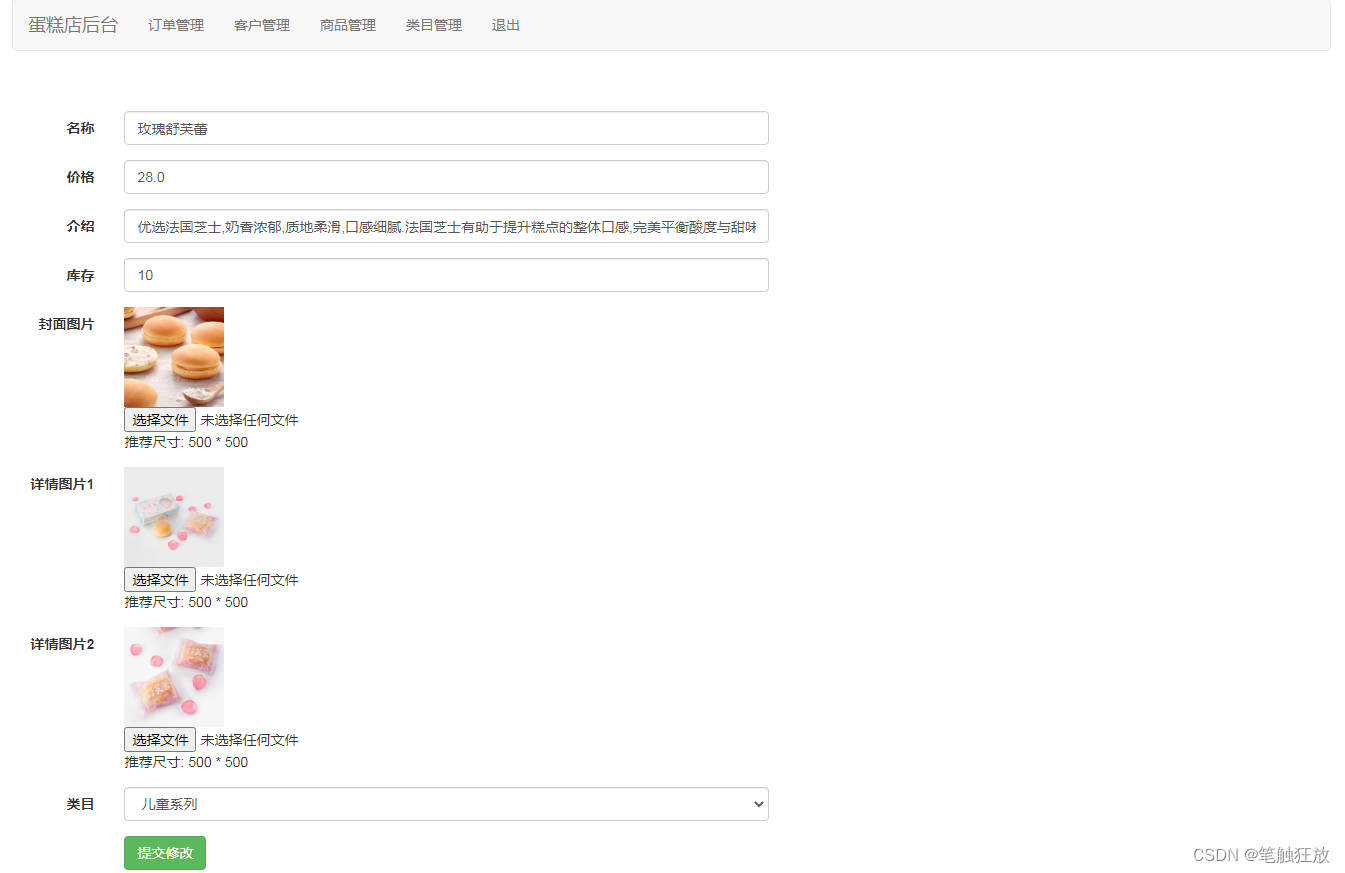
【JavaWeb】网上蛋糕商城后台-商品管理
概念 本文讲解和实现网上蛋糕商城的后台管理系统中的商品管理功能。 商品列表 点击后台管理系统的head.jsp头部的“商品管理”功能选项,向服务器发送请求/admin/goods_list 因此需要在servlet包中创建AdminGoodsListServlet类,用于获取商品信息列表 …...

Django Admin后台管理:高效开发与实践
title: Django Admin后台管理:高效开发与实践 date: 2024/5/8 14:24:15 updated: 2024/5/8 14:24:15 categories: 后端开发 tags: DjangoAdmin模型管理用户认证数据优化自定义扩展实战案例性能安全 第1章:Django Admin基础 1.1 Django Admin简介 Dj…...

Centos7网卡启动失败(Failed to start LSB: Bring up/down)
好雨知时节 当春乃发生 随风潜入夜 润物细无声 报错内容 启动虚拟机时,Ceotos的虚拟网卡没有一起启动,导致服务无法正常使用 查询网络启动状态 systemctl status network.service报Failed to start LSB: Bring up/down 查看网络启动日志 journalctl…...

【NOIP2008普及组复赛】 题4:立体图
题4:立体图 【题目描述】 小渊是个聪明的孩子,他经常会给周围的小朋友讲些自己认为有趣的内容。最近,他准备给小朋友讲解立体图,请你帮他画出立体图。 小渊有一块面积为mn的矩形区域,上面有mn个边长为1的格子&#…...

【Leetcode每日一题】 动态规划 - 简单多状态 dp 问题 - 删除并获得点数(难度⭐⭐)(76)
1. 题目解析 题目链接:LCR 091. 粉刷房子 这个问题的理解其实相当简单,只需看一下示例,基本就能明白其含义了。 2.算法原理 1. 状态定义 在解决这类问题时,我们首先需要根据题目的具体要求来定义状态。针对房屋粉刷问题&#…...

Windows---CMD常用指令大全
CMD是什么? Windows操作系统中的命令行界面程序,全称为命令提示符 CMD可以干什么? 允许用户在文本界面下输入命令来执行各种操作,如文件管理、系统设置、软件安装等 帮助用户更好地控制和管理Windows系统 windows系统CMD指…...
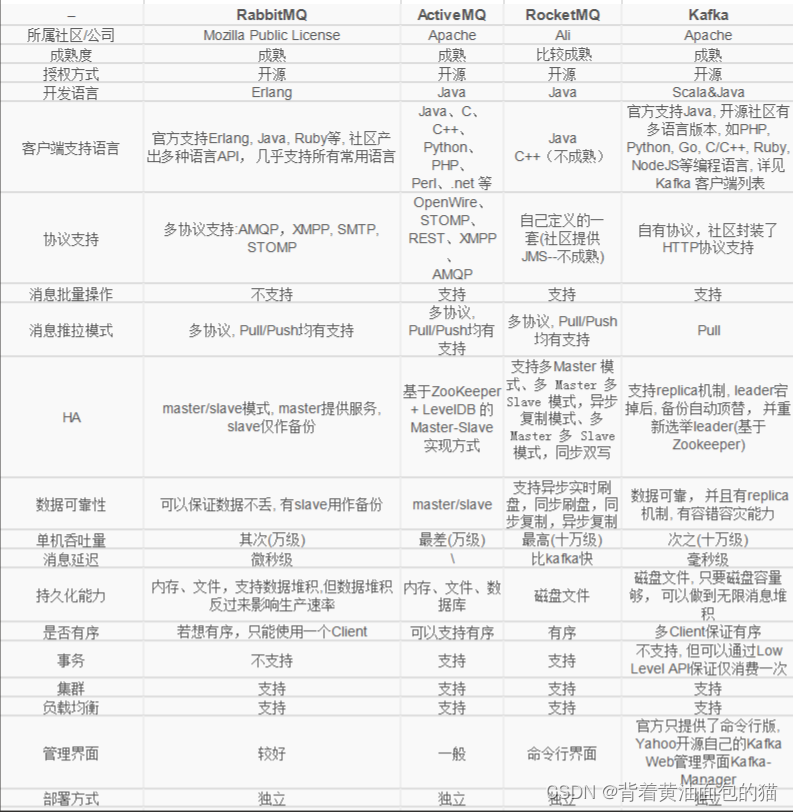
消息中间件是什么?有什么用?常见的消息中间件有哪些?
1.什么是消息中间件? 消息中间件基于队列模型在网络环境中为应用系统提供同步或异步、可靠的消息传输的支撑性软件系统。 2.现实中的痛点: 1.Http请求基于请求与响应的模型,在高并发的情况下,客户端发送大量的请求达到服务器端…...

富锂锰基材料极具发展潜力 我国产业化进程加速
富锂锰基材料极具发展潜力 我国产业化进程加速 富锂锰基材料以锰元素为主,我国锰资源较丰富,相比于铁锂材料、高镍三元材料,富锂锰基材料具有一定的降本潜力。此外富锂锰基材料在能量密度、充放电倍率等方面也具有明显优势。富锂锰基材料是富…...

聚水潭和金蝶云星空单据接口对接
聚水潭和金蝶云星空单据接口对接 对接系统:金蝶云星空 金蝶K/3Cloud(金蝶云星空)是移动互联网时代的新型ERP,是基于WEB2.0与云技术的新时代企业管理服务平台。金蝶K/3Cloud围绕着“生态、人人、体验”,旨在帮助企业打造…...

OpenAI深夜震撼发布最新模型GPT-4o,送上最快速便捷教程
北京时间5月14日凌晨,有人说OpenAI一夜改变了历史。 在我们的深夜、太平洋时间的上午 10 点,OpenAI 召开春季发布会,公布了最新的GPT-4o模型,o代表Omnimodel(全能模型)。20多分钟的演示直播,展…...
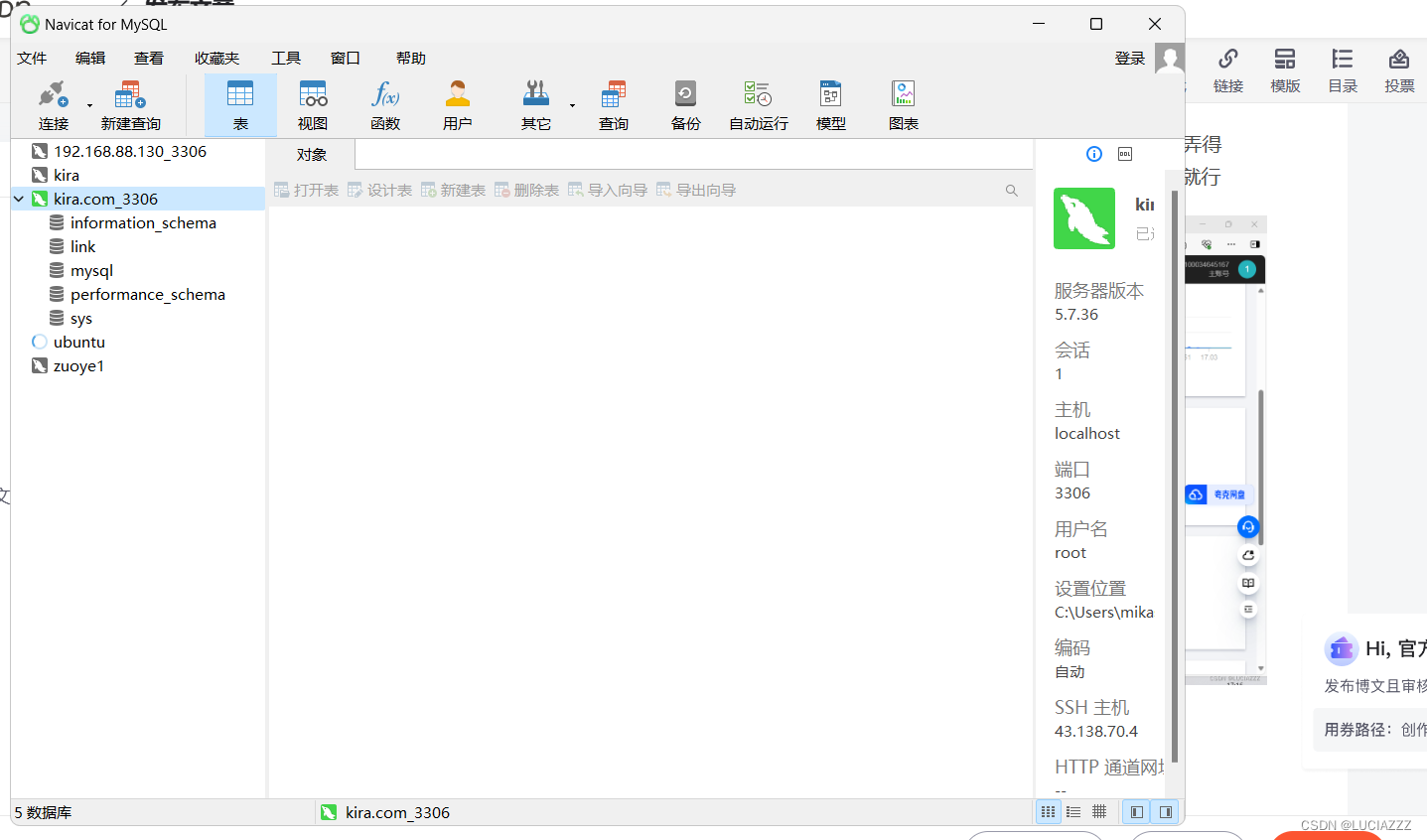
没有申请域名的情况下,用navicat远程连接我们的服务器的Mysql数据库
我们可以根据公网ip用shell来远程连接 首先我们打开自己买的服务器 例如你看这个,就是我们的公网IP 如果服务器里面没有安装mysql数据库的话,那么我们可以用一个轻量级的docker来安装数据库代替一下 我们用docker弄个轻量级的mysql5.7.36,…...

Hive中小文件过多的几种处理方式
1、使用concatenate(只支持RCFile和ORC格式) 2、减少map数量,调整参数:输入合并文件相关的参数 3、减少reduce的数量(例如直接设置reduce为xx个、或者设置reduce的大小,系统自动根据大小确定reduce的个数…...

用户登录认证和权限授权(SpringSecurity、JWT、session)
文章目录 前言一、登录认证1. 问题引入2. Session2.1 实现原理2.2 过滤器Filter2.3 上下文对象 3. JWT3.2 实现步骤3.3 拦截器 HandlerInterceptorAdapter3.4 上下文对象 4. Session VS JWT 二、权限授权1. 权限类型1.1 页面权限(菜单项权限)1.2 ACL模型…...
第十二届蓝桥杯省赛真题 Java A 组【原卷】
文章目录 发现宝藏【考生须知】试题 A: 相乘试题 B: 直线试题 C : \mathrm{C}: C: 货物摆放试题 D: 路径试题 E: 回路计数试题 F : \mathrm{F}: F: 最少砝码试题 G: 左孩子右兄弟试题 H : \mathrm{H}: H: 异或数列试题 I \mathbf{I} I 双向排序试题 J : \mathrm{J}: J: 分…...

零基础学 Web 安全 20256最全系统入门攻略
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

Java基础小知识
一、 计算机基础知识1.计算机硬件的分类:运算器 控制器 存储器 输入设备 输出设备二、cmd命令窗口的基本用法操着: 说明:盘符名称 : 盘符切换。E:回车,表示切换到E盘dir 查看当前路径下的内容cd 目录 进入单级目录。cd…...

终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查
终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue Contin…...

AspectCore-Framework反射扩展:打造极致性能的.NET应用终极指南
AspectCore-Framework反射扩展:打造极致性能的.NET应用终极指南 【免费下载链接】AspectCore-Framework AspectCore is an AOP-based cross platform framework for .NET Standard. 项目地址: https://gitcode.com/gh_mirrors/as/AspectCore-Framework Aspec…...

7.跨品牌手机刷机原理深度解析|BL 解锁机制 + 分区读写 + 故障修复全方案
摘要 本文系统性地阐述主流品牌智能手机(华为、小米、OPPO、vivo、一加、苹果)刷机与维修的核心原理与操作流程。针对不同品牌底层架构差异,提供从Bootloader解锁、Recovery刷写到系统固件注入的完整技术方案。所有操作步骤均基于实际硬件环境验证,包含完整可运行的Python…...

2021年5月AI工程化三大关键突破:Deformable DETR、REALM与WB Model Registry
1. 项目概述:这不是一份榜单,而是一份2021年5月AI领域真实水位的切片报告“The AI Monthly Top 3 — May 2021”这个标题乍看像一份轻量级资讯简报,但在我连续追踪AI领域动态超过十年、亲手部署过从BERT-base到GPT-3早期API调用、从YOLOv3训练…...

谷歌 I/O 开发者大会亮点多:Gemini Spark、YouTube 搜索等新功能来袭!
谷歌 I/O 开发者大会拉开帷幕 谷歌年度 I/O 开发者大会于周二在加利福尼亚州山景城拉开帷幕,会上发布了众多新的 AI 功能、硬件和工具。记者在现场通过 CNET 的实时博客报道了每一项更新。以下是一些亮点回顾。 Gemini Spark 任务自动化 AI 是今年谷歌 I/O 大会的核…...
)
uml学习笔记(1)
UML学习笔记一:面向对象与UML基础入门 一、面向对象开发思想 两种开发范式对比 结构化方法:以功能、流程为核心拆分模块。逻辑简单直观,但复用性差、耦合度高、维护困难,不适合复杂大型项目。面向对象方法:以现实事物的…...
)
从CRUD到AI大神:小白程序员5个月逆袭之路(收藏版)
本文分享了作者从传统CRUD工程师转型为AI应用工程师的心路历程。通过实战先行、深入学习、项目巩固三个阶段,作者逐步掌握了AI模型开发、部署和服务化能力,并成功开发了多个AI应用项目。文章强调实践导向的学习方法,建议程序员利用AI工具提升…...

从文件上传到 RAG 检索:真正看懂了一个 AI 项目的知识库链路
一、前言:今天不是单独学一个知识点,而是串起了一条完整链路 今天继续分析 AI 项目中的 RAG 模块时,我发现自己之前对“文件上传”“文件切片”“向量化”“召回”“大模型回答”这些概念,虽然都单独听过,但真正放到项…...