Flink Stream API实践
目录
Flink程序的基本构成
获得执行环境(environment)
加载/初始化数据(source)
基于文件
基于socket
基于集合
自定义
转换操作(transformation)
基本转换
物理分区
任务链和资源组
名称和描述
指定计算结果放置在何处(sink)
触发程序执行(execution)
Flink程序的基本构成
一个Flink程序的基本构成如下:
1.获得一个执行环境(environment)
2.加载/创建初始数据(source)
3.在此数据上指定转换(transformation)
4.指定将计算结果放置在何处(sink)
5.触发程序执行(execution)
获得执行环境(environment)
获得流处理执行环境的三种方式:
1.根据上下文实际情况的执行环境
StreamExecutionEnvironment.getExecutionEnvironment();
2.本地执行环境
StreamExecutionEnvironment.createLocalEnvironment();
3.远程执行环境
createRemoteEnvironment(String host, int port, String... jarFiles);
例如:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();LocalStreamEnvironment localEnvironment = StreamExecutionEnvironment.createLocalEnvironment();StreamExecutionEnvironment remoteEnvironment = StreamExecutionEnvironment.createRemoteEnvironment("node1", 8081,"path/to/jarfile");
通常情况下,直接使用getExecutionEnvironment()来获取执行环境,因为程序运行时根据上下文条件自动选择相应的环境。如果在IDE中执行程序,将返回本地的执行环境。如果将程序打成jar文件,并通过命令提交jar到flink集群,此时将返回flink集群环境。
加载/初始化数据(source)
基于文件
- readTextFile(path)
- readFile(fileInputFormat, path)
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)
例如:
DataSource<String> lineDs = env.readTextFile("data/words.txt");
基于socket
socketTextStream(hostname, port)
例如:
DataStreamSource<String> lineStream = env.socketTextStream("node2", 7777);
基于集合
- fromCollection(Collection)
- fromCollection(Iterator, Class)
- fromElements(T ...)
- fromParallelCollection(SplittableIterator, Class)
- generateSequence(from, to)
例如:
DataStreamSource<Integer> source = env.fromCollection(Arrays.asList(0, 1, 2));
DataStream<Integer> dataStream = env.fromElements(1, 0, 3, 0, 5);
DataStreamSource<Long> source1 = env.generateSequence(1, 10);
自定义
- 旧的方式:addSource(SourceFunction<OUT> function)
例如:读取kafka的数据
env.addSource(new FlinkKafkaConsumer<>(...))
- 新的方式:fromSource(Source<OUT, ?, ?> source, WatermarkStrategy<OUT> timestampsAndWatermarks, String sourceName)
例如:读取kafka的数据
env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkasource")
转换操作(transformation)
转换操作:运算符将一个或多个数据流转换为新的数据流。
程序可以将多个转换组合成复杂的数据流拓扑结构。
本节描述了基本转换、应用这些转换后的有效物理分区以及对Flink运算符链的深入了解。
基本转换
- Map
- FlatMap
- Filter
- KeyBy
- Reduce
- Window
- WindowAll
- Window Apply
- WindowReduce
- Union
- Window Join
- Interval Join
- Window CoGroup
- Connect
- CoMap, CoFlatMap
- Cache
在Flink WordCount工程 的基础上操作,把以下案例代码放在org.example.transformations包或者其他自定义的包下。
Map
DataStream → DataStream
对流数据里的每个元素进行转换,得到另一个流数据。
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer value) throws Exception {return 2 * value;}
});
将数据流里的每个元素乘以2,得到新的数据流并输出,完整代码如下:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*Takes one element and produces one element.A map function that doubles the values of the input stream:*/
public class OperatorMap {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceDataStream<Integer> dataStream = env.fromElements(1, 2, 3, 4, 5);// transformationsSingleOutputStreamOperator<Integer> data = dataStream.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer value) throws Exception {return 2 * value;}});// sinkdata.print();// executeenv.execute();}
}
运行结果
2> 10
7> 4
6> 2
8> 6
1> 8
FlatMap
DataStream → DataStream
将数据流中的每个元素转换得到0个,1个 或 多个元素
dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out)throws Exception {for(String word: value.split(" ")){out.collect(word);}}
});
把句子中的单词取出来,完整代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*Takes one element and produces zero, one, or more elements.A flatmap function that splits sentences to words:*/
public class OperatorFlatMap {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceDataStream<String> dataStream = env.fromElements("hello world", "hello flink", "hello hadoop");// transformationsSingleOutputStreamOperator<String> data = dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {for (String word : value.split(" ")) {out.collect(word);}}});// sinkdata.print();// executeenv.execute();}
}
运行结果
5> hello
7> hello
6> hello
7> hadoop
5> world
6> flink
Filter
DataStream → DataStream
为每个元素计算一个布尔函数,并保留函数返回true的元素。
dataStream.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) throws Exception {return value != 0;}
});
输出不是0的元素,完整代码如下:
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*Evaluates a boolean function for each element and retains those for which the function returns true.A filter that filters out zero values*/
public class OperatorFilter {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceDataStream<Integer> dataStream = env.fromElements(1, 0, 3, 0, 5);// transformationsSingleOutputStreamOperator<Integer> data = dataStream.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) throws Exception {return value != 0;}});// sinkdata.print();// executeenv.execute();}
}
运行结果
8> 5
6> 3
4> 1
KeyBy
DataStream → KeyedStream
在逻辑上将流划分为不相交的分区。具有相同键的所有记录都被分配到同一个分区。在内部,keyBy()是通过散列分区实现的。
dataStream.keyBy(value -> value.getSomeKey()); dataStream.keyBy(value -> value.f0);
根据key进行分组,并对值进行求和,完整代码如下:
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;
import java.util.List;/*Logically partitions a stream into disjoint partitions.All records with the same key are assigned to the same partition. Internally, keyBy() is implemented with hash partitioning.There are different ways to specify keys.*/
public class OperatorKeyBy {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceList<Tuple2<String, Integer>> dataSource = Arrays.asList(Tuple2.of("hello", 3),Tuple2.of("flink", 2),Tuple2.of("hadoop", 4),Tuple2.of("flink", 5));DataStreamSource<Tuple2<String, Integer>> dataStream = env.fromCollection(dataSource);// transformationsSingleOutputStreamOperator<Tuple2<String, Integer>> data = dataStream.keyBy(value -> value.f0).sum(1);// sinkdata.print();// executeenv.execute();}
}
运行结果
3> (hello,3)
7> (flink,2)
8> (hadoop,4)
7> (flink,7)
Reduce
KeyedStream → DataStream
对键控数据流进行“滚动”缩减。将当前元素与上一个缩减值组合并发出新值。
keyedStream.reduce(new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2)throws Exception {return value1 + value2;}
});
对有相同key的值进行规约运算,这里做求和运算,完整代码如下:
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;
import java.util.List;/*KeyedStream → DataStreamA “rolling” reduce on a keyed data stream.Combines the current element with the last reduced value and emits the new value.A reduce function that creates a stream of partial sums:*/
public class OperatorReduce {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceList<Tuple2<String, Integer>> dataSource = Arrays.asList(Tuple2.of("hello", 3),Tuple2.of("flink", 2),Tuple2.of("hadoop", 3),Tuple2.of("flink", 5),Tuple2.of("hello", 1),Tuple2.of("hadoop", 1));DataStreamSource<Tuple2<String, Integer>> dataStream = env.fromCollection(dataSource);// transformationsKeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(value -> value.f0);SingleOutputStreamOperator<Tuple2<String, Integer>> data = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, (value1.f1 + value2.f1));}});// sinkdata.print();// executeenv.execute();}
}
运行结果
7> (flink,2)
8> (hadoop,3)
3> (hello,3)
7> (flink,7)
8> (hadoop,4)
3> (hello,4)
Window
KeyedStream → WindowedStream
可以在已分区的KeyedStreams上定义窗口(Windows)。窗口根据某些特性(例如,最后10秒内到达的数据)对每个键中的数据进行分组。
dataStream.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(10)));
可以对窗口的数据进行计算,例如:计算10秒滚动窗口中每个单词出现的次数,案例代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;public class WindowWordCount {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// source and transformationsSingleOutputStreamOperator<Tuple2<String, Integer>> dataStream = env.socketTextStream("node1", 7777).flatMap(new Splitter()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(1);// sinkdataStream.print();// executionenv.execute("Window WordCount");}public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : sentence.split(" ")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}
}
启动nc监听
[hadoop@node1 ~]$ nc -lk 7777
运行flink程序
发送测试数据
[hadoop@node1 ~]$ nc -lk 7777 hello world hello flink hello hadoop hello java hello
运行结果
5> (world,1) 8> (hadoop,1) 3> (hello,3) 7> (flink,1) 2> (java,1) 3> (hello,1) 3> (hello,1)
注意:输入数据的速度不一样,会导致数据分配到不同的窗口,计算出的结果也会不一样。
WindowAll
DataStream → AllWindowedStream
可以在常规数据流上定义窗口。 Windows 根据某些特征(例如,最近 10 秒内到达的数据)对所有流事件进行分组.
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(10)));
注意:很多情况下WindowAll是一种非并行转换。所有记录将被收集到同一个任务中进行计算,数据量大可能会出现OOM问题。
把所有窗口中的数据进行规约运算,这里使用逗号来拼接每个单词,完整代码如下:
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;/*Windows can be defined on regular DataStreams.Windows group all the stream events according to some characteristicThis is in many cases a non-parallel transformation. (非并行)All records will be gathered in one task for the windowAll operator.*/
public class OperatorWindowAll {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// source and transformationsSingleOutputStreamOperator<String> result = env.socketTextStream("node1", 7777).windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10))).reduce(new ReduceFunction<String>() {@Overridepublic String reduce(String value1, String value2) throws Exception {return value1 + "," + value2;}});// sinkresult.print();// executeenv.execute();}
}
测试数据
[hadoop@node1 ~]$ nc -lk 7777 hello world hadoop flink hello
运行结果
4> hello,world 5> hadoop,flink,hello
Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
将通用函数应用到整个窗口。
注意:如果使用 windowAll 转换,则需要使用 AllWindowFunction。
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {public void apply (Tuple tuple,Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {public void apply (Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
});
对窗口内元素根据key相同进行求和运算,完整代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class OperatorWindowApply {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// source and transformationsDataStreamSource<String> dataStream = env.socketTextStream("node1", 7777);WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = dataStream.flatMap(new Splitter()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(10)));SingleOutputStreamOperator<Integer> applyStream = windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Integer, String, TimeWindow>() {@Overridepublic void apply(String s, TimeWindow window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception {int sum = 0;for (Tuple2<String, Integer> value : values) {sum += value.f1;}out.collect(new Integer(sum));}});// sinkapplyStream.print();// executeenv.execute();}public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : sentence.split(" ")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}
}
发送测试数据
[hadoop@node1 ~]$ nc -lk 7777 hello world hello hadoop hello flink flink
运行结果
5> 1 3> 1 3> 2 7> 2 8> 1
注意:输入速度不一样,导致数据分配到不同的窗口,运行结果也会不一样。
分析结果
第一行hello world在一个窗口,每个单词都出现1次,所以输出1 、 1
第二行、第三行、第四行 在同一窗口,hello出现2次, flink出现2次, hadoop出现一次,所以输出 2 、 2、 1
WindowReduce
WindowedStream → DataStream
将函数式Reduce函数应用于窗口并返回Reduce后的值。
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);}
});
使用Reduce实现词频统计,完整代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class OperatorWindowReduce {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// source and transformationsDataStreamSource<String> dataStream = env.socketTextStream("node1", 7777);WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = dataStream.flatMap(new Splitter()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(10)));SingleOutputStreamOperator<Tuple2<String, Integer>> result = windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return new Tuple2<String, Integer>(value1.f0, value1.f1 + value2.f1);}});// sinkresult.print();// executeenv.execute();}public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : sentence.split(" ")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}
}
测试数据
[hadoop@node1 ~]$ nc -lk 7777 hello hello world hello flink flink flink hadoop hadoop hello
运行结果
5> (world,1) 3> (hello,2) 7> (flink,3) 3> (hello,1) 8> (hadoop,2) 3> (hello,1)
Union
DataStream* → DataStream
两个或多个相同类型的数据流联合创建一个包含所有流中所有元素的新流。
dataStream.union(otherStream1, otherStream2, ...);
两个相同类型的数据流联结,完整代码如下:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*
Union of two or more data streams creating a new stream containing all the elements from all the streams.
Note: If you union a data stream with itself you will get each element twice in the resulting stream.*/
public class OperatorUnion {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// sourceDataStream<Integer> dataStream1 = env.fromElements(1, 2, 3);DataStream<Integer> dataStream2 = env.fromElements(4, 5, 6);// transformationsDataStream<Integer> res = dataStream1.union(dataStream2);// sinkres.print();// executeenv.execute();}
}
运行结果
1
2
3
4
5
6
Window Join
DataStream,DataStream → DataStream
连接给定键和公共窗口上的两个数据流
dataStream.join(otherStream).where(<key selector>).equalTo(<key selector>).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new JoinFunction () {...});
两个数据流的窗口联结,案例完整代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class OperatorWindowJoin {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4),Tuple2.of("c", 12)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer,Integer>> ds2 = env.fromElements(Tuple3.of("a", 1,1),Tuple3.of("a", 11,1),Tuple3.of("b", 2,1),Tuple3.of("b", 12,1),Tuple3.of("c", 14,1),Tuple3.of("d", 15,1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer,Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));DataStream<String> join = ds1.join(ds2).where(r1 -> r1.f0).equalTo(r2 -> r2.f0).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {@Overridepublic String join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second) throws Exception {return first + "<----->" + second;}});join.print();env.execute();}
}
运行结果
(a,1)<----->(a,1,1) (a,2)<----->(a,1,1) (b,3)<----->(b,2,1) (c,12)<----->(c,14,1)
Interval Join
KeyedStream,KeyedStream → DataStream
在给定时间间隔内使用公共key连接两个KeyedStream的两个元素 e1 和 e2,以便 e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound。
keyedStream.intervalJoin(otherKeyedStream).between(Time.milliseconds(-2), Time.milliseconds(2)) // 时间下限,时间上限.upperBoundExclusive(true) // 可选项.lowerBoundExclusive(true) // 可选项.process(new IntervalJoinFunction() {...});
间隔连接,完整代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;public class OperatorIntervalJoin {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.fromElements(Tuple3.of("a", 1, 1),Tuple3.of("a", 11, 1),Tuple3.of("b", 2, 1),Tuple3.of("b", 12, 1),Tuple3.of("c", 14, 1),Tuple3.of("d", 15, 1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));KeyedStream<Tuple2<String, Integer>, String> ks1 = ds1.keyBy(r1 -> r1.f0);KeyedStream<Tuple3<String, Integer, Integer>, String> ks2 = ds2.keyBy(r2 -> r2.f0);//调用 interval joinks1.intervalJoin(ks2)// 连接时间间隔.between(Time.seconds(-2), Time.seconds(2)).process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {@Overridepublic void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, Context ctx, Collector<String> out) throws Exception {out.collect(left + "<------>" + right);}}).print();env.execute();}
}
运行结果
(a,1)<------>(a,1,1) (a,2)<------>(a,1,1) (b,3)<------>(b,2,1)
Window CoGroup
DataStream,DataStream → DataStream
将给定键和公共窗口上的两个数据流联合分组。
dataStream.coGroup(otherStream).where(0).equalTo(1).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new CoGroupFunction () {...});
两个数据流联合分组,完整代码如下:
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.example.jiaocai.chapter5.CoGroupExample;public class OperatorWindowCoGroup {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> socketSource1 = env.socketTextStream("node1", 7777);DataStream<String> socketSource2 = env.socketTextStream("node1", 8888);DataStream<Tuple2<String, Integer>> input1 = socketSource1.map(line -> {String[] arr = line.split(" ");String id = arr[0];int t = Integer.parseInt(arr[1]);return Tuple2.of(id, t);}).returns(Types.TUPLE(Types.STRING, Types.INT));DataStream<Tuple2<String, Integer>> input2 = socketSource2.map(line -> {String[] arr = line.split(" ");String id = arr[0];int t = Integer.parseInt(arr[1]);return Tuple2.of(id, t);}).returns(Types.TUPLE(Types.STRING, Types.INT));DataStream<String> coGroupResult = input1.coGroup(input2).where(i1 -> i1.f0).equalTo(i2 -> i2.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(10))).apply(new CoGroupExample.MyCoGroupFunction());coGroupResult.print();env.execute("window cogroup function");}public static class MyCoGroupFunction implements CoGroupFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String> {@Overridepublic void coGroup(Iterable<Tuple2<String, Integer>> input1, Iterable<Tuple2<String, Integer>> input2, Collector<String> out) {input1.forEach(element -> System.out.println("input1 :" + element.f1));input2.forEach(element -> System.out.println("input2 :" + element.f1));}}
}
测试数据
[hadoop@node1 ~]$ nc -lk 7777 hello 2 hello 1 [hadoop@node1 ~]$ nc -lk 8888 hello 3 hello 4
运行结果
input1 :2 input1 :1 input2 :3 input2 :4
Connect
DataStream,DataStream → ConnectedStream
“连接”两个保留其类型的数据流,连接允许两个流之间共享状态。两个流的数据类型可以不一样。
DataStream<Integer> someStream = //... DataStream<String> otherStream = //...ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
connect连接后,得到ConnectedStreams流,对于ConnectedStreams流转换时需要实现CoMapFunction或CoFlatMapFunction接口,重写里面的两个方法分别来处理两个流数据,也就是第一个方法处理第一个流的数据,第二个方法处理第二个流的数据。传入的数据类型如下:
// IN1 表示第一个流的数据类型
// IN2 表示第二个流的数据类型
// IN3 表示处理后输出流的数据类型
public interface CoMapFunction<IN1, IN2, OUT> extends Function, Serializable {
两个不同数据类型的数据流的联结,完整代码如下:
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;public class OperatorConnect {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// sourceDataStream<Integer> dataStream1 = env.fromElements(1, 2, 3);DataStream<String> dataStream2 = env.fromElements("hello", "flink", "spark");// transformationsConnectedStreams<Integer, String> connectedStreams = dataStream1.connect(dataStream2);SingleOutputStreamOperator<String> res = connectedStreams.map(new CoMapFunction<Integer, String, String>() {@Overridepublic String map1(Integer input1) throws Exception {return input1.toString();}@Overridepublic String map2(String input2) throws Exception {return input2;}});// sinkres.print();// executeenv.execute();}
}
运行结果
1
hello
2
flink
3
spark
CoMap, CoFlatMap
ConnectedStream → DataStream
将连接流转换为数据流,其中转换与map、flatMap类似
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {@Overridepublic Boolean map1(Integer value) {return true;}@Overridepublic Boolean map2(String value) {return false;}
});connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {@Overridepublic void flatMap1(Integer value, Collector<String> out) {out.collect(value.toString());}@Overridepublic void flatMap2(String value, Collector<String> out) {for (String word: value.split(" ")) {out.collect(word);}}
});
将连接流转换为数据流,完整代码如下:
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.util.Collector;public class OperatorCoFlatMap {public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// sourceDataStream<Integer> dataStream1 = env.fromElements(1, 2, 3);DataStream<String> dataStream2 = env.fromElements("hello world", "hello flink");// transformationsConnectedStreams<Integer, String> connectedStreams = dataStream1.connect(dataStream2);SingleOutputStreamOperator<String> res = connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {@Overridepublic void flatMap1(Integer value, Collector<String> out) throws Exception {out.collect(value.toString());}@Overridepublic void flatMap2(String value, Collector<String> out) throws Exception {for (String word : value.split(" ")) {out.collect(word);}}});// sinkres.print();// executeenv.execute();}
}
运行结果
8> hello
8> flink
4> 1
7> hello
7> world
5> 2
6> 3
Cache
缓存转换的中间结果。 目前仅支持以批量执行模式运行的作业。 缓存中间结果是在第一次计算中间结果时延迟生成的,以便后续作业可以重用该结果。 如果缓存丢失,将使用原始转换重新计算。
DataStream<Integer> dataStream = //... CachedDataStream<Integer> cachedDataStream = dataStream.cache();//缓存数据 cachedDataStream.print();
物理分区
- 自定义分区
- 随机分区
- 重新缩放
- 广播
自定义分区
dataStream.partitionCustom(partitioner, "someKey"); dataStream.partitionCustom(partitioner, 0);
随机分区
dataStream.shuffle();
重新缩放
dataStream.rescale();
广播
dataStream.broadcast();
任务链和资源组
- 启动新链
- 禁用链接
- 设置插槽共享组
启动新链
Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first mapper.
someStream.filter(...).map(...).startNewChain().map(...);
禁用链接
Do not chain the map operator.
someStream.map(...).disableChaining();
设置插槽共享组
someStream.filter(...).slotSharingGroup("name");
名称和描述
someStream.filter(...).setName("filter").setDescription("一些描述内容");
指定计算结果放置在何处(sink)
- writeAsText(path):输出到文件中
- writeAsCsv(...):输出csv文件中
- print():打印到控制台
- writeUsingOutputFormat()
- writeToSocket:输出到Socket中
- addSink:自定义sink,例如输出到kafka中
例如:
DataStreamSource<Integer> dataStream = env.fromElements(1, 2, 3);
dataStream.writeAsText("sinkout");
dataStream.print();
触发程序执行(execution)
- execute:同步执行,会阻塞其他作业
execute() execute(String jobName) execute(StreamGraph streamGraph)
例如:
env.execute();
- executeAsync:异步执行,不会阻塞其他作业
executeAsync() executeAsync(String jobName) executeAsync(StreamGraph streamGraph)
例如:
env.executeAsync();
完成!enjoy it!
相关文章:

Flink Stream API实践
目录 Flink程序的基本构成 获得执行环境(environment) 加载/初始化数据(source) 基于文件 基于socket 基于集合 自定义 转换操作(transformation) 基本转换 物理分区 任务链和资源组 名称和描述…...

AI图像生成-原理
一、图像生成流程总结 【AI绘画】深入理解Stable Diffusion!站内首个深入教程,30分钟从原理到模型训练 买不到的课程_哔哩哔哩_bilibili 二、如果只是用comfy UI生成图片 1、找到下面几个文件,把对应模型移动到对应文件夹即可使用 2、选择对…...

【JavaScript】尺寸和位置
DOM对象相关的尺寸和位置属性 用于获取和修改元素在页面中的尺寸和位置。 只读属性: clientWidth和clientHeight:获取元素可视区域的宽度和高度(padding content),不包括边框和滚动条。 offsetWidth和offsetHeight…...
Express框架下搭建GraphQL API
需要先下载apollo-server-express,apollo-server-express是Express框架下,用于构建GraphQL服务的中间件,属于Apollo Server的一部分: npm install apollo-server-express 随后在index.js添加 apollo-server-express包࿱…...
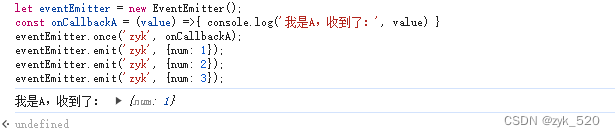
发布订阅模式
一、常见的发布订阅模式 1、Dom的事件 Event addEventListener dispatchEvent //订阅中心 const event new Event(zyk); //订阅 document.addEventListener(zyk, (value)>{console.log(我收到了:, value) }); //发布 document.dispatchEvent(e, 1); docume…...
【Java 演示灵活导出数据】
演示灵活导出数据 🎉🎉🎉🎉🎉🎉【小吴小吴bug全无开通公众号】关注公众号获取第一时间博客动态 背景今天临时起兴打开稀土掘金导航栏看到页面推广gitee项目恰巧最近也在学习python了解到python爬虫很厉害&…...
一对一WebRTC视频通话系列(六)——部署到公网
本系列博客主要记录一对一WebRTC视频通话实现过程中的一些重点,代码全部进行了注释,便于理解WebRTC整体实现。 本专栏知识点是通过<零声教育>的音视频流媒体高级开发课程进行系统学习,梳理总结后写下文章,对音视频相关内容感…...
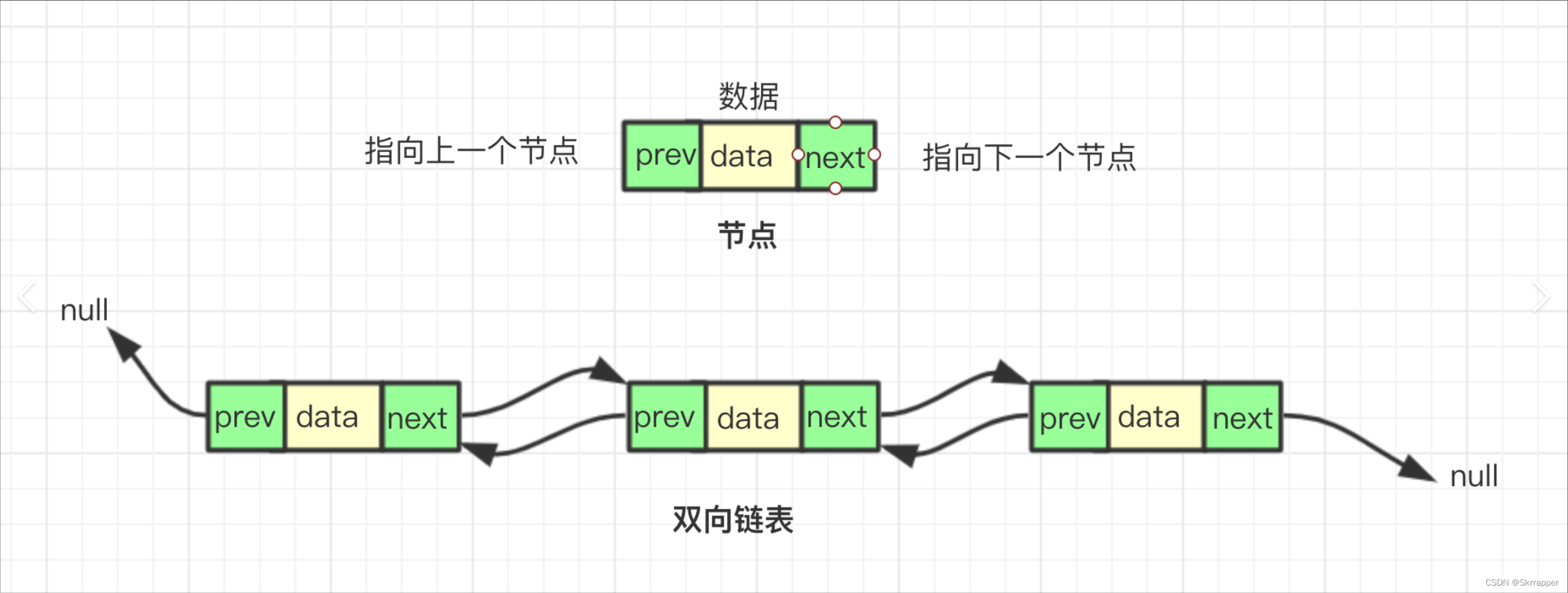
【数据结构】线性表----链表详解
数据结构—-链表详解 目录 文章目录 链表的定义链表的构成链表的分类双向和单向带头和不带头循环和不循环 链表的命名基本操作的实现初始化打印取值查找插入指定位置插入删除删除销毁 部分其他链表的代码实现循环链表双向链表 优点/缺点(对比顺序表)优点…...

【小程序】小程序如何适配手机屏幕
小程序如何适配手机屏幕 1. 使用rpx单位2. 百分比布局3. 弹性盒子(Flexbox)和网格布局4. 媒体查询5. 响应式布局6. 测试和调试 1. 使用rpx单位 rpx(responsive pixel)是小程序中的一种长度单位,可以根据屏幕宽度进行自…...

第15节 编写shellcode加载器
我最近在做一个关于shellcode入门和开发的专题课👩🏻💻,主要面向对网络安全技术感兴趣的小伙伴。这是视频版内容对应的文字版材料,内容里面的每一个环境我都亲自测试实操过的记录,有需要的小伙伴可以参考…...

JAVA学习-练习试用Java实现爬楼梯
问题: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼…...
[SWPUCTF 2021 新生赛]PseudoProtocols、[SWPUCTF 2022 新生赛]ez_ez_php
[SWPUCTF 2021 新生赛]PseudoProtocols 打开环境,提示hint.php就在这里,且含有参数wllm 尝试利用PHP伪协议读取该文件 ?wllmphp://filter/convert.base64-encode/resourcehint.php//文件路径php://filter 读取源代码并进行base64编码输出。 有一些敏…...
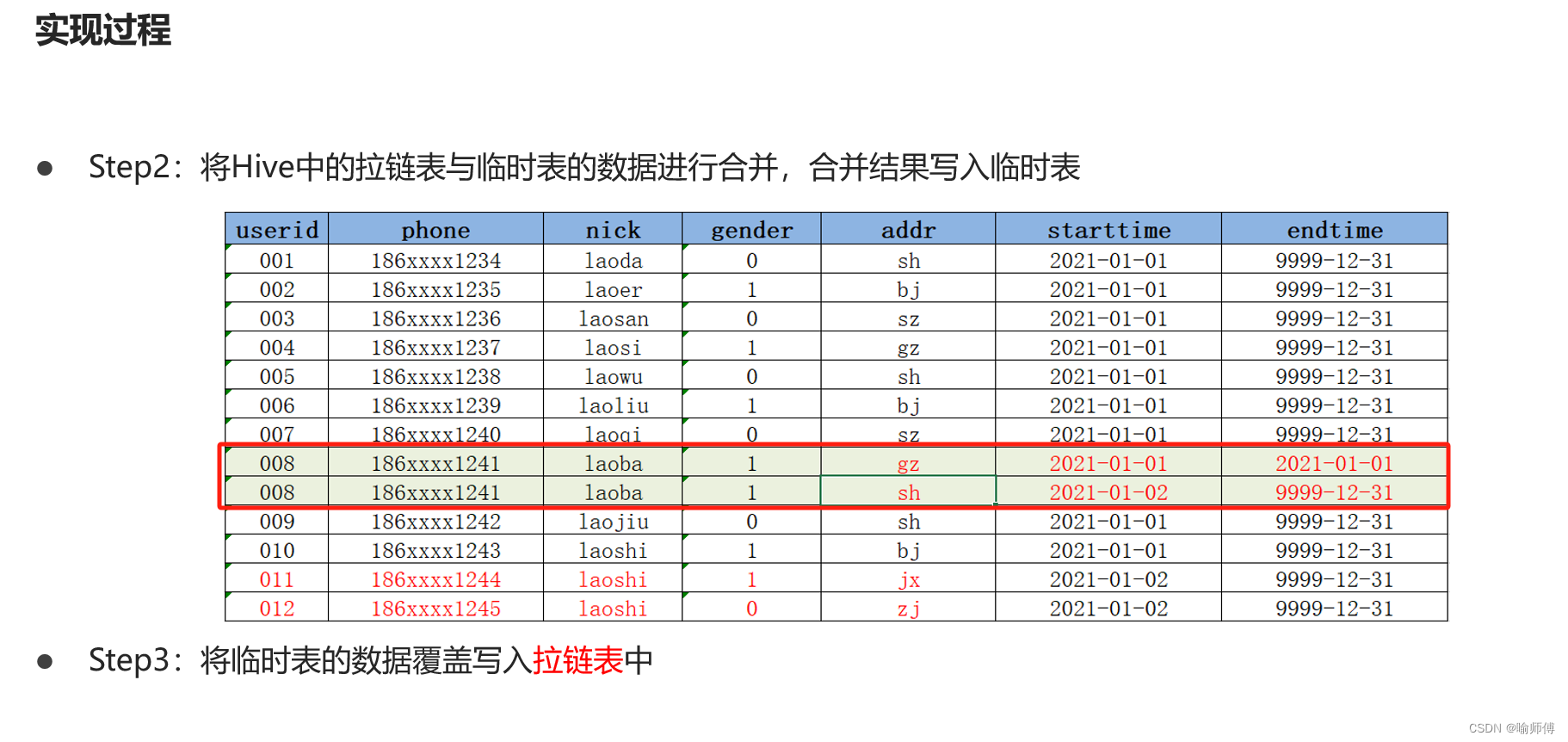
Hive-拉链表的设计与实现
Hive-拉链表的设计与实现 在Hive中,拉链表专门用于解决在数据仓库中数据发生变化如何实现数据存储的问题。 1.数据同步问题 Hive在实际工作中主要用于构建离线数据仓库,定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用…...
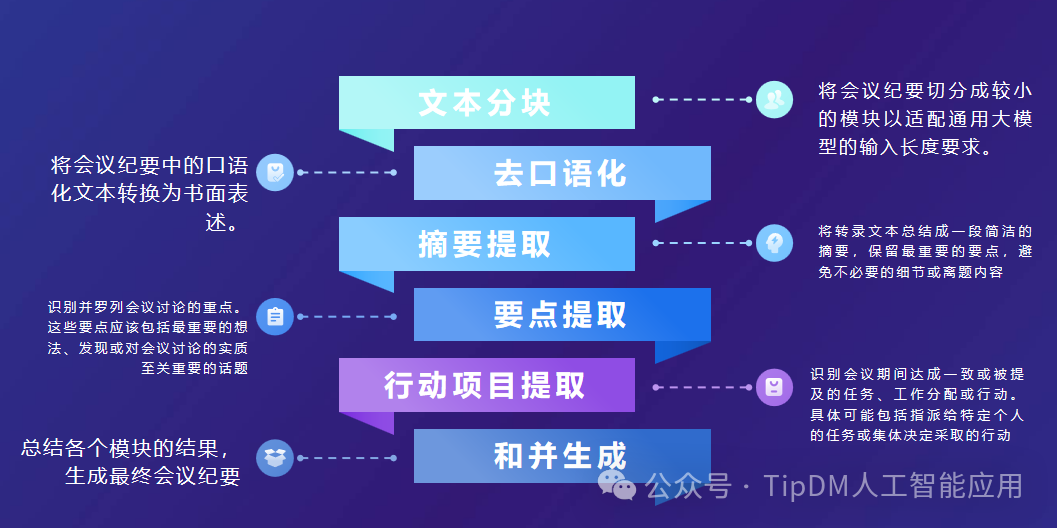
AI应用案例:会议纪要自动生成
以腾讯会议转录生成的会议记录为研究对象,借助大模型强大的语义理解和文本生成等能力,利用指令和文本向量搜索实现摘要总结、要点提取、行动项目提取、会议纪要生成等过程,完成会议纪要的自动总结和生成,降低人工记录和整理时间成…...
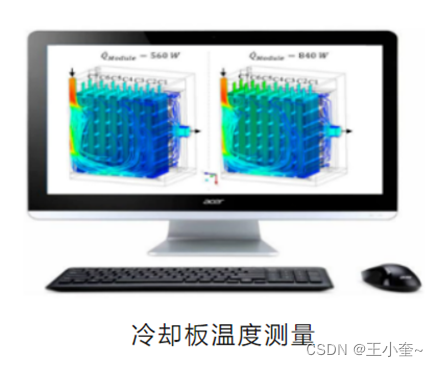
基于光纤技术的新能源汽车电池安全监测--FOM²系统
为什么要进行动力电池包的温度监测? 新能源电动汽车的动力电池包的工作温度,不仅会影响电池包性能,而且直接关系到车辆安全。时有发生的新能源汽车电池包起火事件,对电池包、冷却系统以及电池管理系统(BMS)…...

基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) #Options local_llm llama3 llm ChatOllama(modellocal_llm, format"json", temperature0) #embeddings #embeddings OllamaEmbeddings(model"nomic-embed-text") embed…...
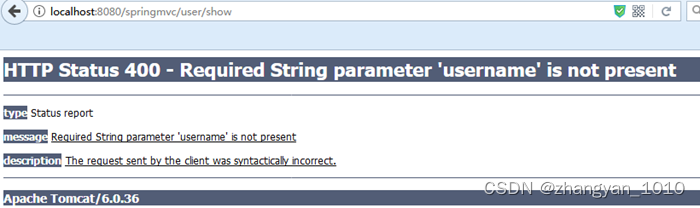
Spring MVC(三) 参数传递
1 Controller到View的参数传递 在Spring MVC中,把值从Controller传递到View共有5中操作方法,分别是。 使用HttpServletRequest或HttpSession。使用ModelAndView。使用Map集合使用Model使用ModelMap 使用HttpServletRequest或HttpSession传值 使用HttpSe…...

常见加解密算法02 - RC4算法分析
RC4是一种广泛使用的流密码,它以其简洁和速度而闻名。区别于块密码,流密码特点在于按位或按字节来进行加密。 RC4由Ron Rivest在1987年设计,尽管它的命名看起来是第四版,实际上它是第一个对外发布的版本。 RC4算法的实施过程简洁…...
如何使用 ERNIE 千帆大模型基于 Flask 搭建智能英语能力评测对话网页机器人(详细教程)
ERNIE 千帆大模型 ERNIE-3.5是一款基于深度学习技术构建的高效语言模型,其强大的综合能力使其在中文应用方面表现出色。相较于其他模型,如微软的ChatGPT,ERNIE-3.5不仅综合能力更强,而且在训练与推理效率上也更高。这使得ERNIE-3…...
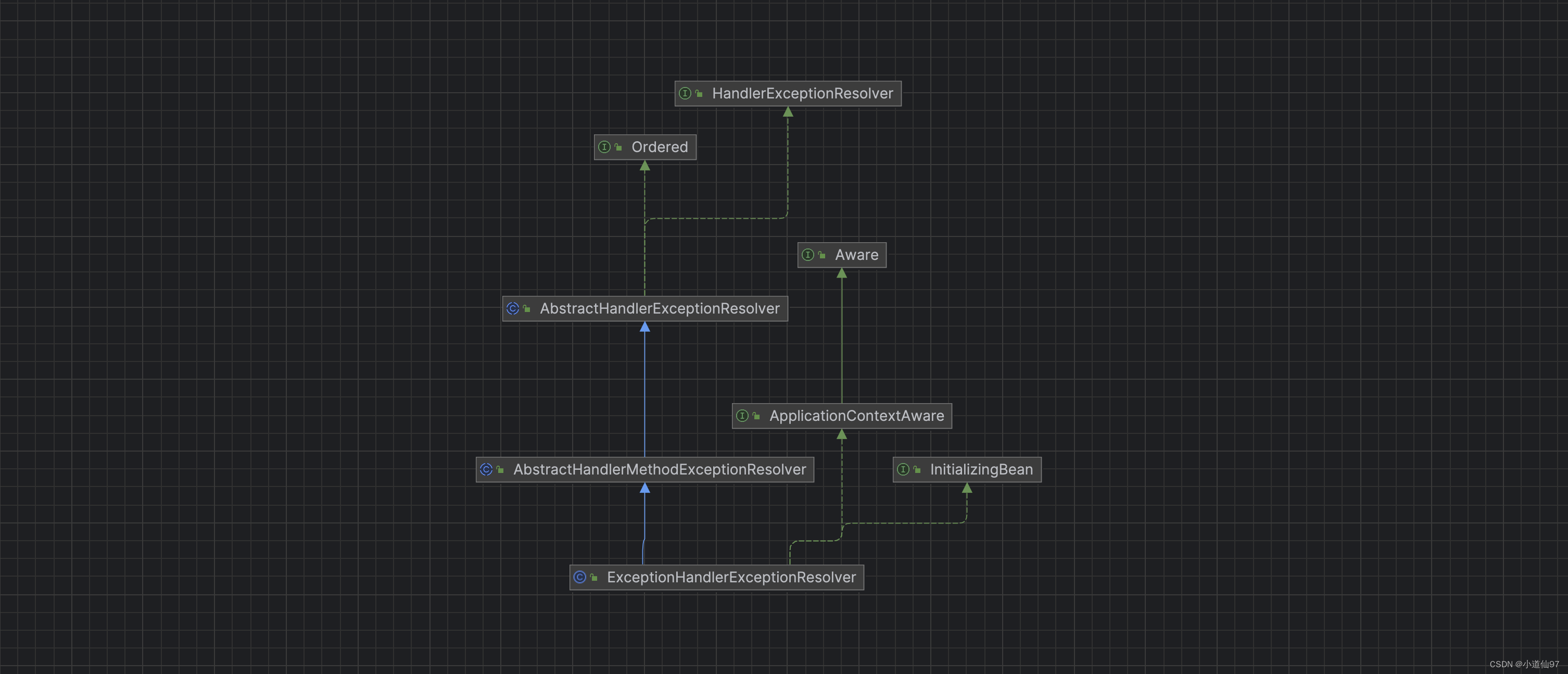
Java全局异常处理,@ControllerAdvice异常拦截原理解析【简单易懂】
https://www.bilibili.com/video/BV1sS411c7Mo 文章目录 一、全局异常处理器的类型1-1、实现方式一1-2、实现方式二 二、全局异常拦截点2-1、入口2-2、全局异常拦截器是如何注入到 DispatcherServlet 的 三、ControllerAdvice 如何解析、执行3-1、解析3-2、执行 四、其它4-1、设…...

Unity UGUI三大Layout Group核心原理与工程实践
1. 为什么这三个Layout Group是Unity UI开发的“地基级”组件,而不是可有可无的装饰品?在Unity里做UI,很多人第一反应是拖控件、调锚点、手动改RectTransform——这就像盖房子不打地基,先砌墙再想承重。我带过十几期新人训练营&am…...

深入理解Android中startActivity的完整流程:聚焦IPC机制与Binder原理
引言 在Android开发中,startActivity() 方法是启动新Activity的核心API,它贯穿了应用的生命周期管理。理解其内部流程,不仅有助于优化性能、避免常见错误,还能提升开发者在面试中的竞争力。本文将以“一次完整的 startActivity 到底经历了什么”为主题,深入探讨整个流程,…...

JMeter分布式压测实战:突破单机瓶颈的原理与落地
1. 为什么单台JMeter跑不动你的压测任务?你是不是也遇到过这样的场景:在本地用JMeter跑一个5000并发的HTTP请求,CPU直接飙到98%,内存告急,响应时间曲线像心电图一样乱跳,结果还没导出,JMeter自己…...

Adams 多体动力学:工业仿真的黄金标准与未来引擎
Adams(Automatic Dynamic Analysis of Mechanical Systems)是全球多体动力学仿真领域的标杆软件,由 MSC Software 公司开发(现隶属于 Hexagon 集团),凭借领先的虚拟样机技术,成为汽车、航空航天…...

从弹簧小车到悬臂梁:用Python和SymPy手把手推导变分法与欧拉方程
从弹簧小车到悬臂梁:用Python和SymPy手把手推导变分法与欧拉方程 在工程力学和数学物理方程的学习中,变分法是一个既令人着迷又让人望而生畏的领域。它像一座桥梁,连接着抽象的数学原理和具体的物理现象。传统教学中,变分法往往以…...

OptScale 安全最佳实践:10个关键步骤保护你的云成本数据和配置
OptScale 安全最佳实践:10个关键步骤保护你的云成本数据和配置 【免费下载链接】optscale FinOps and cloud cost optimization tool. Supports AWS, Azure, GCP, Alibaba Cloud and Kubernetes. 项目地址: https://gitcode.com/gh_mirrors/op/optscale OptS…...

IDM激活脚本完全指南:3种方法实现永久免费使用
IDM激活脚本完全指南:3种方法实现永久免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为Internet Download Manager(IDM&…...

Unity重型战士Mecanim动画包:开箱即用的战斗动画解决方案
1. 这套动画包到底解决了什么实际问题?在Unity项目开发中,我见过太多团队卡在“角色动不起来”这一步——不是程序写不出状态机,而是美术资源交付后,Animator Controller里一堆红色警告:Missing Avatar、Clip not mapp…...

为什么你的双色调总像PPT?揭秘Midjourney v6中未公开的--tint权重衰减算法与Gamma校准阈值
更多请点击: https://kaifayun.com 第一章:双色调视觉失真的本质归因 双色调视觉失真并非单纯由显示设备或图像压缩引发的表层现象,其根本源于人眼视锥细胞响应函数与数字色彩空间映射之间的结构性不匹配。当图像被强制量化为仅含两种色调&a…...

振弦采集模块精度检测实战:从原理到环境测试全解析
1. 项目概述与核心目标在工程监测领域,振弦式传感器因其长期稳定性好、抗干扰能力强、信号传输距离远等优点,被广泛应用于桥梁、大坝、隧道、边坡等结构物的应力、应变、位移和压力监测。而VM系列振弦采集模块,作为连接传感器与数据采集系统的…...