hadoop学习---基于Hive的数据仓库相关函数机制及其优化方案
Hive相关函数(部分):
-
if函数:
-
作用: 用于进行逻辑判断操作
-
语法: if(条件, true返回信息,false返回信息)
-
注意: if函数支持嵌套使用
-
-
select if(a=a,’bbbb’,111) fromlxw_dual; bbbb select if(1<2,100,200) fromlxw_dual; 200 -
nvl函数:
-
作用: null值替换函数
-
格式: nvl(T value, T default_value)
-
-
select nvl(principal,1) from mydb.aaaaa; 1 -
COALESCE函数
-
作用: 非空查找函数:
-
格式: coalesce(值1,值2,值3...)
-
说明: 从第一个值开始判断, 找到第一个不为null的值, 将其返回, 如果都为null,返回null
-
-
select COALESCE(null,’aaa’,50) from lxw_dual; aaa -
CASE WHEN THEN 函数:
-
格式1: case 字段 when 条件 then 值1 when 条件 then 值2 .. else 值3 end
-
格式2: case when 条件 then 值1 when 条件2 then 值2 .. else 值3 end
-
-
select case 100when 50 then 'tom'when 100 then 'mary'else 'tim' end from lxw_dual; mary select case 200 when 50 then 'tom'when 100 then 'mary' else 'tim' end from lxw_dual; tim -
isnull() | isnotnull() 函数
作用:
isnull()判断是否为null,如果为null返回true,否则返回false
isnotnull()判断是否不为null,如果不为null,返回true,如果为null返回falsel
hive的并行优化:
并行编译:
Hive默认同时只能编译一段HiveSQL,并上锁。
将hive.driver.parallel.compilation设置为true,各个会话可以同时编译查询,提高团队工作效率。否则如果在UDF中执行了一段HiveQL,或者多个用户同时使用的话, 就会锁住。
修改hive.driver.parallel.compilation.global.limit的值,0或负值为无限制,可根据团队人员和硬件进行修改,以保证同时编译查询。
说明:
hive在同一时刻只能编译一个会话中SQL, 如果有多个会话一起来执行SQL, 此时出现排队的情况, 只有当这一个会话中SQL全部编译后, 才能编译另一个会话的SQL, 导致执行效率变慢
解决方案:
hive.driver.parallel.compilation 是否开启并行编译 设置为true
hive.driver.parallel.compilation.global.limit 最大允许同时有多少个SQL一起编译 设置为0表示无限制
这两项可以建议直接在CM的hive配置窗口上进行永久配置 (通用配置)
并行执行:
Hive会将一个查询转化为一个或多个阶段,包括:MapReduce阶段、抽样阶段、合并阶段、limit阶段等。默认情况下,一次只执行一个阶段。不过,如果某些阶段不是互相依赖,是可以并行执行的。
set hive.exec.parallel=true,可以开启并发执行,默认为false。
set hive.exec.parallel.thread.number=16; //同一个sql允许的最大并行度,默认为8。
说明:
在运行一个SQL的时候, 这个SQL形成的执行计划中, 可能会被拆分为多个阶段, 当各个阶段之间没有依赖关系的时候, 可以尝试让多个阶段同时运行, 从而提升运行的效率, 这就是并行执行
配置方案:
set hive.exec.parallel=true; 是否开启并行执行
set hive.exec.parallel.thread.number=16; 最大允许并行执行的数量
关于并行优化, 必须要求服务器有资源, 如果没有资源, 及时满足并行的条件, 也不会执行
Hive小文件合并:
HDFS中namenode中存储的元数据是什么?
在Hadoop Distributed File System (HDFS)中,NameNode负责存储元数据,这意味着它管理着文件系统的逻辑视图和文件的物理布局信息。具体来说,元数据包括但不限于以下几个方面:
- 文件系统命名空间:包括文件和目录的名称、目录结构以及这些实体之间的层级关系。
- 文件属性:每个文件或目录的属性,如创建时间、访问权限、修改时间、所有权信息等。
- 文件块信息:文件被切分成多个块(默认大小通常为128MB或更大),NameNode存储了每个文件对应的块列表,以及这些块的版本信息。
- 块位置信息:虽然NameNode不永久保存块的确切物理位置(这些信息由DataNodes动态报告并在系统启动时重建),但它知道每个块应该有多少副本,以及这些副本的大致分布情况。
- 副本放置策略信息:NameNode还跟踪副本放置策略,确保数据块在集群中的分布符合预定规则,比如机架感知策略,以优化数据读取速度和容错性。
元数据的管理对于确保文件系统的高效运作至关重要,它使得NameNode能够快速响应客户端的文件读写请求,指导客户端找到所需数据块的确切位置。值得注意的是,NameNode为了提高效率,会将大部分元数据存储在内存中,而较为静态的部分(如fsimage,即文件系统镜像)和对元数据的更改记录(edits log)则存储在磁盘上,并通过Secondary NameNode(或更现代的Hadoop版本中的Checkpoint Node)定期合并以减少NameNode重启时的恢复时间。
小文件有什么影响呢?
HDFS角度:
每一个小文件, 都会有一份元数据, 当小文件过多后, 会导致出现大量的元数据存储namenonde的内存中, 从而导致内存使用率增大, 一旦namenode内存存满了, 即使datanode依然有空间, 也是无法存储的
MR角度:
在运行MR的时候, 每一个文件至少是一个文件切片, 也就意味至少需要运行一个mapTask. 当小文件过多后, 就会导致产生更多的mapTask, 而每一个mapTask只处理极少的数据, 导致资源被大量占用, 运行的时间都没有申请资源时间长
假设: 150M 10M 8M 300M 12M 6M 请问会运行几个mapTask: 9个
从hive角度如何解决小文件过多的问题呢?
在执行SQL的时候, 输出的文件数量尽量变得少一些
hive.merge.mapfiles : 是否开启map端小文件合并 (适用于MR只有map没有reduce, map输出结果就是最终结果)
hive.merge.mapredfiles : 是否开启reduce端小文件合并操作
hive.merge.size.per.task: 合并后输出文件的最大值 ,默认是128M
hive.merge.smallfiles.avgsize: 判断输出各个文件平均大小, 当这个大小小于设置值, 认为出现了小文件问题,需要进行合并操作示例:
设置合并文件后, 输出最大值128M, 设置平均值为 50M
假设一个MR输出一下几个文件:
1M,10M,5M,3M,150M,80M,2M 平均值:35.xxx
发现输出的多个文件的平均值比设定的平均值要小, 说明出现小文件的问题, 需要进行合并, 此时会合并结果为:
128M,123M
矢量化查询:
hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种hive特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
set hive.vectorized.execution.enabled=true;读取零拷贝:
ORC可以使用新的HDFS缓存API和ZeroCopy读取器来避免在扫描文件时将额外的数据复制到内存中。
set hive.exec.orc.zerocopy=true;说明: 在hive读取数据的时候, 只需要读取跟SQL相关的列的数据即可, 不使用列, 不进行读取, 从而减少读取数据, 提升效率
示例: A表有 a,b,c,d,e 五个字段
select a,b,b from A where b=xxx and c between xx and xxx;
发现SQL中没有使用d和e两个字段, 如果开启读取零拷贝, 在读取数据的时候, 就不会将d和e这两个字段读取到内存中
数据倾斜的优化:
什么是数据倾斜呢?
在运行过程中,有多个reduce, 每一个reduce拿到的数据不是很均匀, 导致其中某一个或者某几个reduce拿到数据量远远大于其他的reduce拿到数据量, 此时认为出现了数据倾斜问题
数据倾斜会导致问题?
1) 执行效率下降(整个执行时间, 就看最后一个reduce结束时间)
2) 由于其中某几个reduce长时间运行, 资源长期被占用, 一旦超时, YARN强制回收资源, 导致运行失败
3) 导致节点出现宕机问题
....
在执行什么SQL的时候, 会出现多个reduce的情况呢?
1) 多表join的时候
2) 执行group by的时候
3) 执行分桶操作(跟数据倾斜没太大关系)
如何解决数据倾斜的问题呢?
group by 数据倾斜
方案一: 采用combiner的方式来解决 (在map端提前聚合)
核心: 在每一个mapTask进行提前聚合操作, 将聚合之后结果, 发送给reduce中, 完成最终的聚合, 从而减少从map到reduce的数据量, 减轻数据倾斜压力
配置:
set hive.map.aggr=true; 开启map端提前聚合操作(combiner)开启map端combiner。此配置可以在group by语句中提高HiveQL聚合的执行性能。这个设置可以将顶层的聚合操作放在Map阶段执行,从而减轻数据传输和Reduce阶段的执行时间,提升总体性能。默认开启,无需显示声明。
方案二: 负载均衡解决方案 (大combiner)
核心: 采用两个MR来解决, 第一个MR负责将数据均匀落在不同reduce上, 进行聚合统计操作, 形成一个局部的结果, 在运行第二个MR读取第一个MR的局部结果, 按照相同key发往同一个reduce的方案, 完成最终聚合统计操作。第一个MR Job中,Map 的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
配置:
set hive.groupby.skewindata=true;注意:
一旦使用方案二, hive不支持多列上的采用多次distinct去重操作, 一旦使用, 就会报错
错误内容: DISTINCT on different columns notsupported with skew in data.
示例:
(1) SELECT count(DISTINCT uid) FROM log
(2) SELECT ip, count(DISTINCT uid) FROM log GROUP BY ip
(3) SELECT ip, count(DISTINCT uid, uname) FROMlog GROUP BY ip
(4) SELECT ip, count(DISTINCT uid), count(DISTINCT uname) FROMlog GROUP BY ip
其中: 1,2,3 是可以正常执行的, 4会报错
join的数据倾斜
解决方案一 :
通过采用 map join,bucket map join, SMB map join
方案: 将reduce端join的操作, 移植到map端进行join即可, 直接将倾斜排除即可, 因为在map端基本不会有倾斜问题但是: 不管是map join, 还是 bucket map join以及SMB map join在使用的时候 都必须满足相关的条件, 但是很多时候, 我们的环境无法满足这些条件, 那么也就意味无法使用这些解决方案
解决方案二:
思路: 将那些容易产生倾斜的key的值, 从这个环境中, 排除掉, 这样自然就没有倾斜问题, 讲这些倾斜的数据单独找一个MR来处理即可
处理方案:
编译期解决方案:
配置:
set hive.optimize.skewjoin.compiletime=true;
建表:
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 倾斜的字段和需要拆分的key值
SKEWED BY (key) ON (1,5,6)
-- 为倾斜值创建子目录单独存放
[STORED AS DIRECTORIES];
说明:
当明确知道表中那些key的值有倾斜问题, 一般采用编译期解决, 在建表的时候, 提前设置好对应值有倾斜即可, 这样在执行的时候, hive会直接将这些倾斜的key的值从这个MR排除掉, 单独找一个MR来处理即可
运行期解决方案:
配置:
set hive.optimize.skewjoin=true; 是否开启运行期倾斜解决join
set hive.skewjoin.key=100000; 当key出现多少个的时候, 认为有倾斜
说明:
在执行的过程中, hive会记录每一个key出现的次数, 当出现次数达到设置的阈值后, 认为这个key有倾斜的问题, 直接将这个key对应数据排除掉, 单独找一个MR来处理即可
建议:
如果提前知道表中有那些key有倾斜, 直接使用编译期即可
如果仅知道一部分, 对于其他key无法保证, 建议编译期和运行期同时开启
union all相关优化点:
配置项:
set hive.optimize.union.remove=true;
作用:
此项配置减少对Union all子查询中间结果的二次读写说明:
此项配置一般和join的数据倾斜组合使用
如何感知有数据倾斜?
方案一: 通过查看 job history历史日志(19888) 适用于MR已经执行完成了。
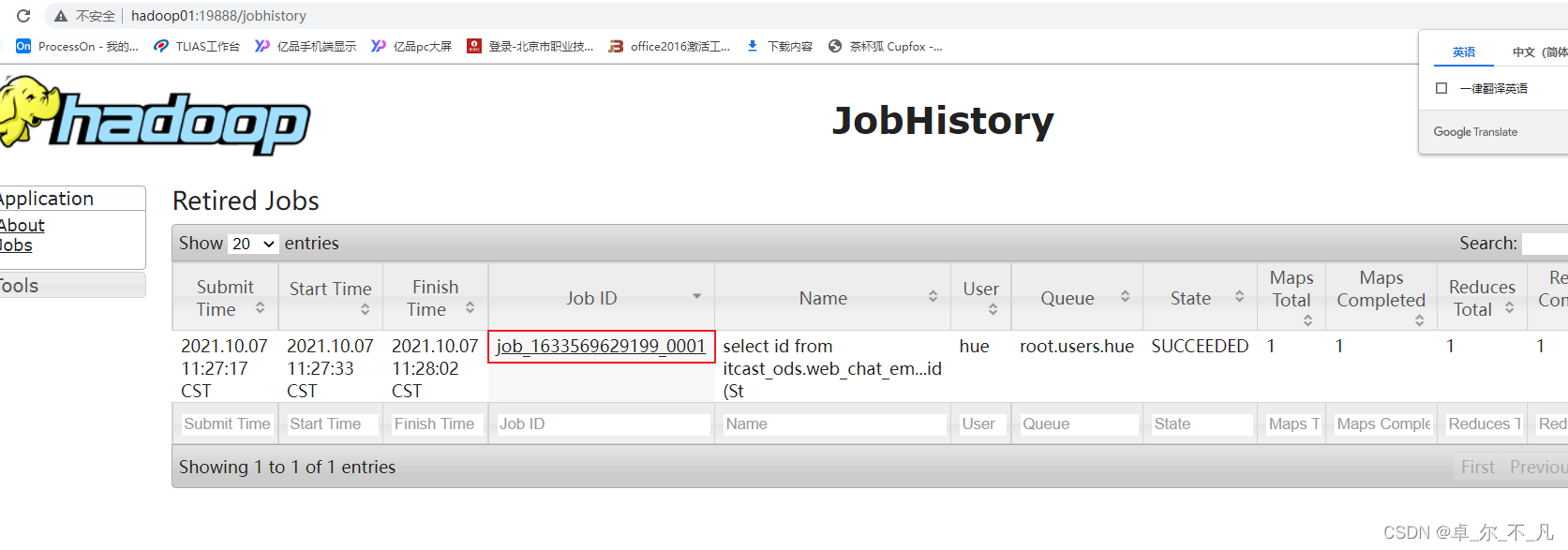


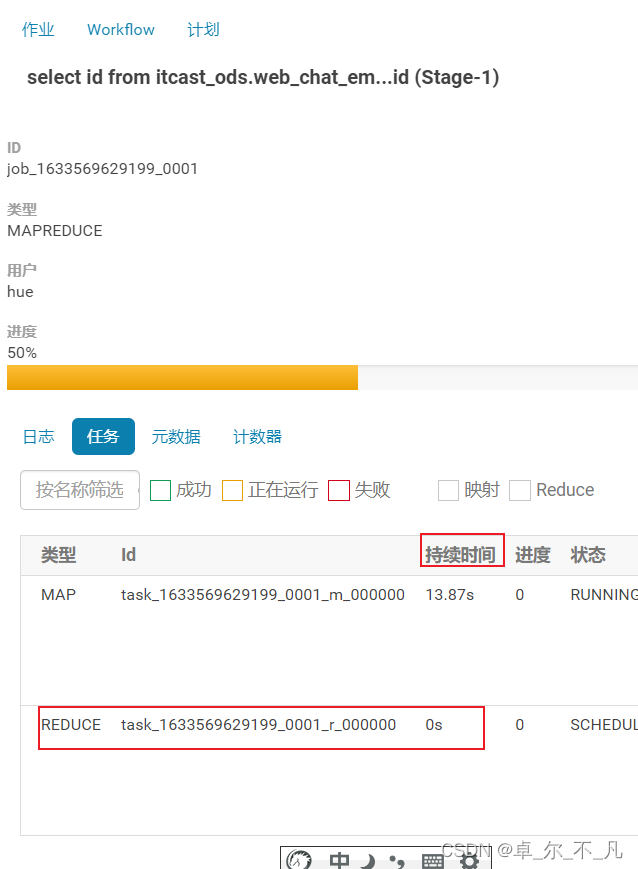
方案二: 在运行过程中借助HUE查看:

关联优化器
在Hive的一些复杂关联查询中,可能同时还包含有group by等能够触发shuffle的操作,有些时候shuffle操作是可以共享的,通过关联优化器选项,可以尽量减少复杂查询中的shuffle,从而提升性能。
配置:
set hive.optimize.correlation=true;说明:
在Hive的一些复杂关联查询中,可能同时还包含有group by等能够触发shuffle的操作,有些时候shuffle操作是可以共享的,通过关联优化器选项,可以尽量减少复杂查询中的shuffle,从而提升性能。
比如:
select id,max(id) from itcast_ods.web_chat_ems group by id;
union all
select id,min(id) from itcast_ods.web_chat_ems group by id;
总结:
常开项:
set hive.exec.parallel=true; 是否开启并行执行
set hive.exec.parallel.thread.number=16; 最大允许并行执行的数量
set hive.vectorized.execution.enabled=true; 矢量化查询
set hive.exec.orc.zerocopy=true; 读取零拷贝
set hive.optimize.correlation=true; 关联优化器
针对性开启:
set hive.map.aggr=true; 开启 group by combiner数据倾斜方案
set hive.groupby.skewindata=true;开启groupby 负载均衡优化
set hive.optimize.skewjoin.compiletime=true; join的编译期优化
set hive.optimize.skewjoin=true; 是否开启运行期倾斜解决join
set hive.skewjoin.key=100000; 当key出现多少个的时候, 认为有倾斜
set hive.optimize.union.remove=true; union all优化
相关文章:
hadoop学习---基于Hive的数据仓库相关函数机制及其优化方案
Hive相关函数(部分): if函数: 作用: 用于进行逻辑判断操作 语法: if(条件, true返回信息,false返回信息) 注意: if函数支持嵌套使用 select if(aa,’bbbb’,111) fromlxw_dual; bbbb select if(1<2,100,200) fromlxw_dual; 200nvl函数:…...

【MySQL数据库】丨高可用之MHA集群部署
一、准备工作 1.1 修改主机名 vim /etc/hosts# 添加对应主机 192.168.28.128 mha1 192.168.28.131 mha2 192.168.28.132 mha31.2 关闭防火墙及修改selinux # 关闭防火墙 systemctl stop firewalld systemctl disable firewalld # 关闭自启动# 修改selinux vim /etc/sy…...
uniapp的底部弹出层实现保姆式教程
实现照片: 此过程先进入uniapp官网,找到扩展组件 打开找到里面的uni-popup和uni-icons 点击进入,下载&安装 点击下载并导入HBuilderX 导入到你使用的目录,如test目录 同样将uni-icons点击下载并导入HBuilderX 点击合并 此时te…...

国外IP代理免费试用技巧
随着互联网的普及,人们越来越依赖于网络来获取信息、进行交流和娱乐。国外IP代理就成了利器之一。在本文中,我们将探讨如何免费使用国外IP代理。 一、了解国外IP代理的原理 国外IP代理,简单来说,就是通过连接到位于国外的代理服务…...

vue-cropper裁剪图片 vue
效果图 1.配置环境 npm install vue-cropper 2.代码 <template><div class"cropper-content"><div class"cropper-box"><div class"cropper"><vue-cropper ref"cropper" :img"option.img" :…...

算法-卡尔曼滤波之基本数学的概念
1.均值 定义:均值是一组数据中所有数值的总和除以数据的数量。均值是数据的中心趋势的一种度量,通常用符号 xˉ 表示。 :对于包含 n 个数据的数据集 {𝑥1,𝑥2,...,𝑥𝑛},均值 xˉ 计…...

NeoVim配置文件基本的
init.lua 文件 require(options) require(keymaps) require(plugins) require(colorscheme) require(lsp)-- 插件 require("config.lualine") require("config.nvim-tree") require("config.treesitter")~\lua\plugins.lua 文件 local lazypa…...
Qt学习笔记1.3.4 QtCore-Qt资源系统
文章目录 资源收集文件(.qrc)外部二进制资源内编译(compiled-in)资源压缩使用应用程序中的资源使用库中的资源 Qt资源系统是一种 独立于平台的机制,用于在应用程序的可执行文件中存储二进制文件。如果您的应用程序总是需要一组特定的文件(图标、翻译文件等)&#x…...
同城组局同城活动找搭子小程序JAVA源码面芽组局的实现方案
功能概述 基于微信小程序开发的一款软件,支持用户动态发布、私信聊天关注、礼物充值打赏、发起活动组局、用户报名参与、支持商家入驻,对接广告功能等。 活动发布:用户可以在平台上发布各种类型的活动,如户外徒步、音乐会观赏、…...

Unable to locate the .NET SDK
问题描述: vs2019 加载项目时,提示如下: Unable to locate the .NET SDK as specified by global.json, please check that the specified version is installed. 项目中没有globan找al.json 文件 先使用: dotnet --list-sdks 命…...

C++STL初阶(1):string的使用及初阶原理
此文作为学习stl的笔记,许多普及、概念性的知识点将不再罗列(如stl的发展、背景等) 便于读者作为复习等方法了解。 0.STL简介(笔记向) STL不是祖师爷本贾尼实现的,是在惠普实验室中实现的。其作为一个数据结…...

Day41-Java基础之反射和动态代理
1. 反射 1.1 反射的概述: 专业的解释(了解一下): 是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法; 对于任意一个对象,都能够调用它的任意属性和方法ÿ…...
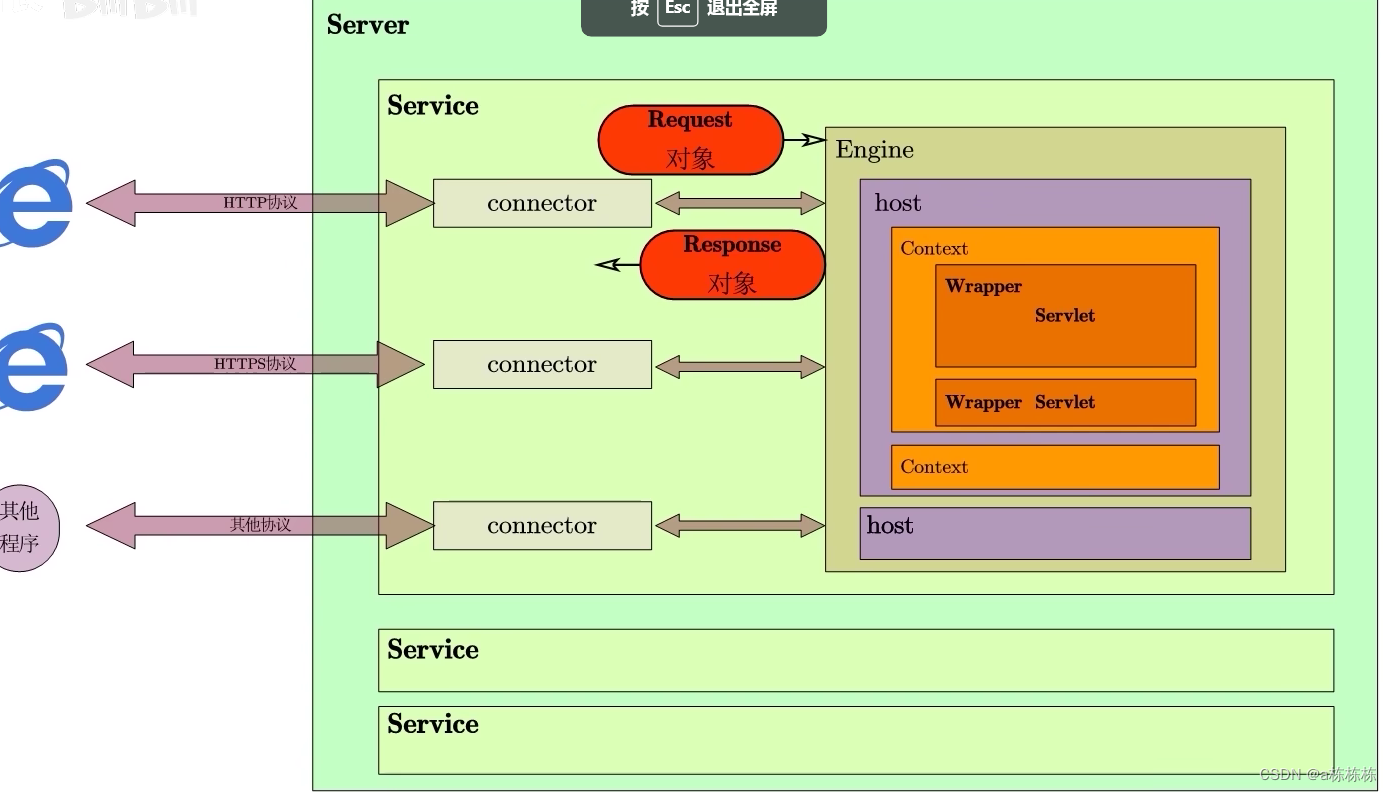
Tomcat的实现
在一台电脑上启动tomcat,tomcat是server,即服务器。服务器只会被实例化一次,tomcat这只猫就是服务器。服务器下包含多个子节点服务,即service,顾名思义就是对外提供服务。服务器通常只有一个服务,默认是卡特…...

RK3576 Camera:资源介绍
RK3576是RK今年上市的中高端旗舰芯片,定位弱于RK3588。这篇文章主要分享一下RK3576这颗主控芯片的camera资源。 (1)RK3576 camera资源 ①RK3576 camera硬件框图 RK3576的camera硬件框图如图所示,拥有一路4lane的DCPHYÿ…...

Symfony DomCrawler库在反爬虫应对中的应用
在当今信息爆炸的时代,互联网上的数据量巨大,但这也带来了一些问题,比如恶意爬虫可能会对网站造成严重的影响,导致资源浪费和服务不稳定。为了解决这个问题,许多网站采取了反爬虫策略。Symfony DomCrawler库是一个强大…...

1Panel应用推荐:Uptime Kuma
1Panel(github.com/1Panel-dev/1Panel)是一款现代化、开源的Linux服务器运维管理面板,它致力于通过开源的方式,帮助用户简化建站与运维管理流程。为了方便广大用户快捷安装部署相关软件应用,1Panel特别开通应用商店&am…...
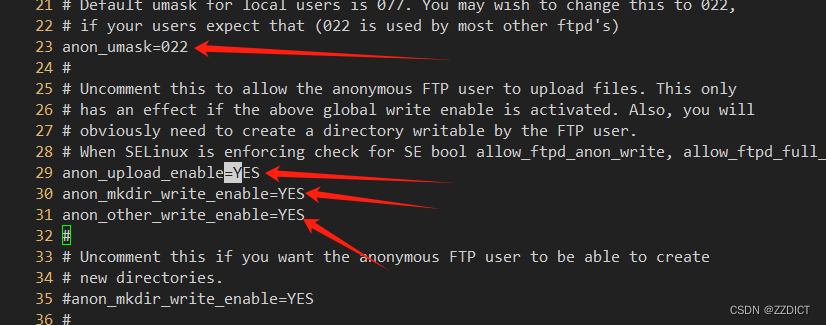
传输文件协议FTP与LFTP
目录 一.简介 二. FTP基础 主动模式(Active Mode): 被动模式(Passive Mode): 三. Vsftp 服务器简介 四. Vsftpd配置 1. 安装vsftpd(ftp服务端) 2.编辑配置文件 (…...

expdp和impdp 实战
1 查询需要导出数据的用户 select username,default_tablespace from dba_users where username like %USERNAME%; 2 查看原来表空间大小 set linesize 9999 pagesize 9999 SELECT total.tablespace_name, Round(total.MB, 2) AS Total_MB, Round(t…...

知了汇智引领未来:全新AIGC系列课程,打造数字时代人才新标杆
在全球AIGC(生成式人工智能)技术加速发展的背景下,一系列权威报道揭示了该领域内市场潜力、行业应用、教育研究、政府监管以及具体应用场景的蓬勃进展。据腾讯网4月19日报道,中国AIGC应用市场规模预计于2024年达到200亿人民币&…...

软件项目验收第三方测试报告如何获取
软件项目验收第三方测试报告是确保软件质量、安全性和稳定性的重要环节。对于企业和开发者来说,获取一份全面、专业的第三方测试报告,对于提升软件产品的竞争力和用户满意度至关重要。本文将介绍如何获取软件项目验收第三方测试报告,以及相关…...

第九届蓝桥杯国赛b组--备战国赛版h
第一题:0换零钞 - 蓝桥云课 模拟 #include <bits/stdc.h> using namespace std; int main() {int a,b,c0;for(a1;a<200;a)//一元钞票{for(b1;b<100;b)//两元钞票{for(c1;c<40;c)//五元钞票{if(ba*10&&(ab*2c*5)200){cout<<abc<&l…...

3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南
3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾为心爱的PlayStation手柄在Windows电脑上无法被游戏识别而烦…...

5分钟学会AnyFlip电子书一键下载:免费PDF转换终极指南
5分钟学会AnyFlip电子书一键下载:免费PDF转换终极指南 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否曾经在AnyFlip上找到一本精彩的电子书,想要永…...

避开DSP28335内存管理的坑:堆、栈、CMD文件配置全解析与最佳实践
DSP28335内存管理深度优化:从堆栈原理到CMD文件实战配置 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。对于基于TI C2000系列DSP28335的开发者而言,合理规划有限的内存资源不仅能提升系统性能,更能避免那些难以…...

2026年5月19日OpenBSD 7.9发布:多架构更新、内核创新,安全与性能双提升!
2026年5月19日,开源操作系统OpenBSD 7.9正式发布,作为第60个版本,它带来内核与用户空间多层面更新,预计在开源社区持续发挥重要作用。平台支持全面扩展arm64架构新增Rockchip RK3588与RK3576芯片支持,amd64平台MAXCPUs…...

多账号流量内容运营的数据归因与ROI优化:从经验驱动到算法决策的技术转型
📌 当一个团队同时运营20个以上的新媒体账号时,最大的问题不是"怎么发",而是"发了之后怎么知道哪条有用"。本文从数据工程角度,拆解多账号流量内容矩阵如何通过数据归因模型实现ROI优化,以星链引擎…...

FantiaDL终极指南:如何快速下载Fantia平台上的所有内容
FantiaDL终极指南:如何快速下载Fantia平台上的所有内容 【免费下载链接】fantiadl Download posts and media from Fantia 项目地址: https://gitcode.com/gh_mirrors/fa/fantiadl FantiaDL是一款专为Fantia用户设计的强大开源下载工具,能够帮助你…...

宇视出入口相机抓拍调试速成方法
宇视出入口相机抓拍调试速成方法一、背景概述智慧园区、停车场等场景已普及宇视出入口抓拍相机,用于车辆出入管控与车牌识别。现场易受光照、车速、车道环境等影响,常出现漏抓、识别率低、画面模糊等问题。传统调试无标准、耗时长、上手门槛高࿰…...

别再让治具压坏你的板子!手把手教你用TSK-64应力测试仪搞定ICT/FCT应力管控
从应力失控到精准管控:TSK-64测试仪在ICT/FCT产线的实战指南 当产线突然出现批量PCBA功能异常时,多数工程师的第一反应是检查焊接质量或元器件性能,却往往忽略了治具施加的机械应力这个"隐形杀手"。某汽车电子制造商曾因FCT治具压力…...

GitHub Desktop中文汉化终极指南:三分钟实现全界面中文化
GitHub Desktop中文汉化终极指南:三分钟实现全界面中文化 【免费下载链接】GitHubDesktop2Chinese GithubDesktop语言本地化(汉化)工具 【GitHub桌面客户端中文汉化】 项目地址: https://gitcode.com/gh_mirrors/gi/GitHubDesktop2Chinese 还在为GitHub Desk…...