【PostgreSQL支持中文的全文检索插件(zhparser)】
PostgreSQL本身是支持全文检索的,提供两个数据类型(tsvector,tsquery),并且通过动态检索自然语言文档的集合,定位到最匹配的查询结果。其内置的默认的分词解析器采用空格进行分词,但是因为中文的词语之间没有空格分割,所以这种方法并不适用于中文。
要支持中文的全文检索需要额外的中文分词插件,zhparser就是其中一种,是基于Simple Chinese Word Segmentation(SCWS)中文分词库实现的一个PG扩展。
zhparser的源码地址为:https://github.com/amutu/zhparser
中文分词库的下载地址为:http://www.xunsearch.com/scws/download.php
一、安装中文分词库SCWS和zhparser分词插件
1.下载scws-1.2.3和zhparser的包
postgres@ubuntu-linux-22-04-desktop:~$ cd zhparser/
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ ls
scws-1.2.3.tar.bz2 zhparser-master.zip

2.安装中文分词库SCWS
root@ubuntu-linux-22-04-desktop:/home/postgres# cd zhparser/
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# ls
scws-1.2.3.tar.bz2 zhparser-master.zip
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# tar -xf scws-1.2.3.tar.bz2
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# ls
scws-1.2.3 scws-1.2.3.tar.bz2 zhparser-master.zip
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# cd scws-1.2.3/
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# ls
API.md ChangeLog Makefile.in aclocal.m4 config.guess configure etc ltmain.sh win32
AUTHORS INSTALL NEWS cli config.h.in configure.ac install-sh missing
COPYING Makefile.am README compile config.sub depcomp libscws phpext
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# ./configure
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking for gcc... gcc
...
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# make install
Making install in .
make[1]: Entering directory '/home/postgres/zhparser/scws-1.2.3'
make[2]: Entering directory '/home/postgres/zhparser/scws-1.2.3'
make[2]: Nothing to be done for 'install-exec-am'.
make[2]: Nothing to be done for 'install-data-am'.
make[2]: Leaving directory '/home/postgres/zhparser/scws-1.2.3'
make[1]: Leaving directory '/home/postgres/zhparser/scws-1.2.3'
Making install in libscws
make[1]: Entering directory '/home/postgres/zhparser/scws-1.2.3/libscws'
/bin/sh ../libtool --preserve-dup-deps --tag=CC --mode=compile gcc -DHAVE_CONFIG_H -I. -I.. -g -O2 -MT charset.lo -MD -MP -MF .deps/charset.Tpo -c -o charset.lo charset.c
libtool: compile: gcc -DHAVE_CONFIG_H -I. -I.. -g -O2 -MT charset.lo -MD -MP -M
3.安装zhparser插件
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# su - postgres
postgres@ubuntu-linux-22-04-desktop:~$ cd zhparser/
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ ls
scws-1.2.3 scws-1.2.3.tar.bz2 zhparser-master.zip
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ unzip zhparser-master.zippostgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ export SCWS_HOME=/usr/local
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ make -j 24
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -Wno-stringop-truncation -g -O2 -fPIC -fvisibility=hidden -I/usr/local/include/scws -I. -I./ -I/home/postgres/soft-16/include/server -I/home/postgres/soft-16/include/internal -D_GNU_SOURCE -c -o zhparser.o zhparser.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -Wno-stringop-truncation -g -O2 -fPIC -fvisibility=hidden -shared -o zhparser.so zhparser.o -L/home/postgres/soft-16/lib -Wl,--as-needed -Wl,-rpath,'/home/postgres/soft-16/lib',--enable-new-dtags -fvisibility=hidden -lscws -L/usr/local/lib -Wl,-rpath -Wl,/usr/local/lib
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ make install -j 24
/usr/bin/mkdir -p '/home/postgres/soft-16/lib'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/extension'
/usr/bin/install -c -m 755 zhparser.so '/home/postgres/soft-16/lib/zhparser.so'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/extension'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/tsearch_data'
/usr/bin/install -c -m 644 .//zhparser.control '/home/postgres/soft-16/share/extension/'
/usr/bin/install -c -m 644 .//zhparser--1.0.sql .//zhparser--unpackaged--1.0.sql .//zhparser--1.0--2.0.sql .//zhparser--2.0.sql .//zhparser--2.0--2.1.sql .//zhparser--2.1.sql .//zhparser--2.1--2.2.sql '/home/postgres/soft-16/share/extension/'
/usr/bin/install -c -m 644 .//dict.utf8.xdb .//rules.utf8.ini '/home/postgres/soft-16/share/tsearch_data/'
进入到数据库里创建插件
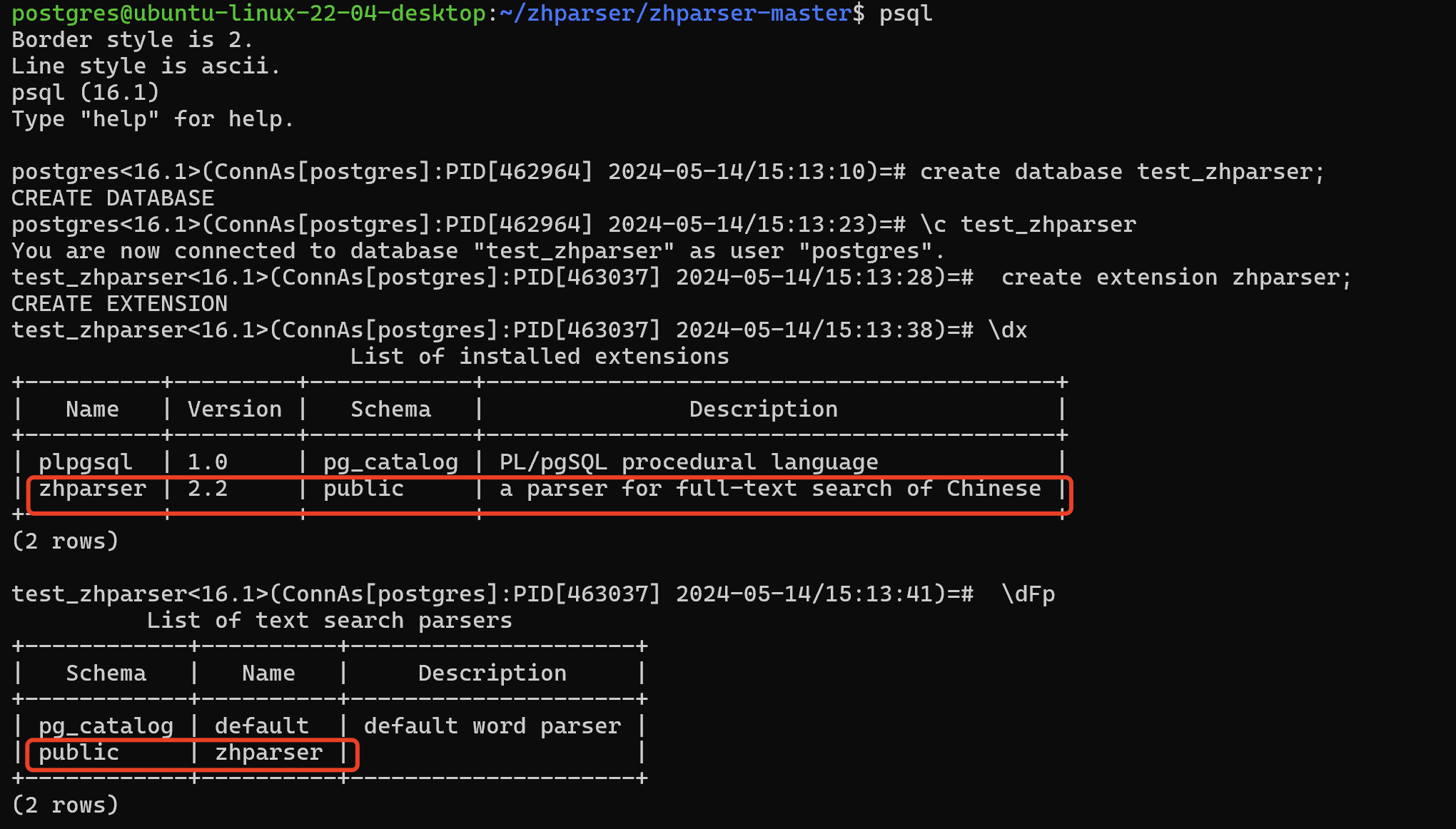
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ psql
Border style is 2.
Line style is ascii.
psql (16.1)
Type "help" for help.postgres<16.1>(ConnAs[postgres]:PID[462964] 2024-05-14/15:13:10)=# create database test_zhparser;
CREATE DATABASE
postgres<16.1>(ConnAs[postgres]:PID[462964] 2024-05-14/15:13:23)=# \c test_zhparser
You are now connected to database "test_zhparser" as user "postgres".
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:28)=# create extension zhparser;
CREATE EXTENSION
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:38)=# \dxList of installed extensions
+----------+---------+------------+------------------------------------------+
| Name | Version | Schema | Description |
+----------+---------+------------+------------------------------------------+
| plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language |
| zhparser | 2.2 | public | a parser for full-text search of Chinese |
+----------+---------+------------+------------------------------------------+
(2 rows)test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:41)=# \dFpList of text search parsers
+------------+----------+---------------------+
| Schema | Name | Description |
+------------+----------+---------------------+
| pg_catalog | default | default word parser |
| public | zhparser | |
+------------+----------+---------------------+
(2 rows)
二、zhparser分词插件的相关配置
zhparser可以将中文切分成下面26种token
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:45)=# select ts_token_type('zhparser');
+---------------------------------+
| ts_token_type |
+---------------------------------+
| (97,a,"adjective,形容词") |
| (98,b,"differentiation,区别词") |
| (99,c,"conjunction,连词") |
| (100,d,"adverb,副词") |
| (101,e,"exclamation,感叹词") |
| (102,f,"position,方位词") |
| (103,g,"root,词根") |
| (104,h,"head,前连接成分") |
| (105,i,"idiom,成语") |
| (106,j,"abbreviation,简称") |
| (107,k,"tail,后连接成分") |
| (108,l,"tmp,习用语") |
| (109,m,"numeral,数词") |
| (110,n,"noun,名词") |
| (111,o,"onomatopoeia,拟声词") |
| (112,p,"prepositional,介词") |
| (113,q,"quantity,量词") |
| (114,r,"pronoun,代词") |
| (115,s,"space,处所词") |
| (116,t,"time,时语素") |
| (117,u,"auxiliary,助词") |
| (118,v,"verb,动词") |
| (119,w,"punctuation,标点符号") |
| (120,x,"unknown,未知词") |
| (121,y,"modal,语气词") |
| (122,z,"status,状态词") |
+---------------------------------+
(26 rows)
创建使用zhparser作为解析器的全文搜索的配置
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:14:36)=# CREATE TEXT SEARCH CONFIGURATION test_zhparserC (PARSER = zhparser);
CREATE TEXT SEARCH CONFIGURATION
往全文搜索配置中增加token映射
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:15:54)=# ALTER TEXT SEARCH CONFIGURATION test_zhparserC A
DD MAPPING FOR n,v,a,i,e,l WITH simple;
ALTER TEXT SEARCH CONFIGURATION
上面的token只映射了名词(n),动词(v),形容词(a),成语(i),叹词(e)和习用语(l)6种。词典使用的是内置的simple词典,即仅做小写转换。可以根据自己的需求自定义,实现屏蔽词和同义词归并等功能。
三、测试zhparser中文分词插件
PostgreSQL本身是支持全文检索的,提供两个数据类型(tsvector,tsquery),自带了to_tsquery函数和plainto_tsquery函数,来处理分析搜索语句。
而一个tsvector的值是唯一分词的分类列表,把一话一句词格式化为不同的词条,在进行分词处理的时候tsvector会自动去掉分词中重复的词条,按照一定的顺序装入。处理加工的文本应该通过使用to_tsvector函数来使之规格化,标注化的应用于搜索。
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:14:15)=# SELECT to_tsquery('english', 'The & Fat & Rats');
+---------------+
| to_tsquery |
+---------------+
| 'fat' & 'rat' |
+---------------+
(1 row)test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:16:51)=# SELECT to_tsvector('english', 'The Fat Rats');
+-----------------+
| to_tsvector |
+-----------------+
| 'fat':2 'rat':3 |
+-----------------+
(1 row)
如下是针对中文全文检索插件的验证:
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:24:01)=# select to_tsvector('test_zhparserC','大连星海湾');
+---------------------+
| to_tsvector |
+---------------------+
| '大连':1 '星海湾':2 |
+---------------------+
(1 row)
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:43:24)=# select to_tsvector('test_zhparserC','大连市星海 广场');
+------------------------------+
| to_tsvector |
+------------------------------+
| '大连市':1 '广场':3 '星海':2 |
+------------------------------+
(1 row)
分词的粒度越粗,效率越高,但遗漏的可能性也会高一点,即召回率受影响。
召回率=提取出的正确信息条数 / 样本中的信息条数
准确率=提取出的正确信息条数 / 提取出的信息条数
可以使用函数后边带 @@ ‘xxx&xxx’;的方式判断是否能从取样的文字里提取出的正确信息,像’大连&广’就无法提取到。效率,召回率和准确率3个指标往往不能兼顾,如果想提高召回率,可以对SCWS的一些选项参数进行调节。
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:23)=# select to_tsvector('test_zhparserC','大连市星海广场');
+------------------------------+
| to_tsvector |
+------------------------------+
| '大连市':1 '广场':3 '星海':2 |
+------------------------------+
(1 row)test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:31)=# select to_tsvector('test_zhparserC','大连市星海广场')@@ '大连市&广场';
+----------+
| ?column? |
+----------+
| t |
+----------+
(1 row)test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:39)=# select to_tsvector('test_zhparserC','大连市星海广场')@@ '大连&广场';
+----------+
| ?column? |
+----------+
| f |
+----------+
(1 row)
也可以使用ts_debug函数,来调试全文检索。这个函数显示的是文档的每个词条通过基本词典的分析和处理的信息。
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:01:34)=# select ts_debug('test_zhparserC','大连市星海广场');
+-------------------------------------------------+
| ts_debug |
+-------------------------------------------------+
| (n,"noun,名词",大连市,{simple},simple,{大连市}) |
| (n,"noun,名词",星海,{simple},simple,{星海}) |
| (n,"noun,名词",广场,{simple},simple,{广场}) |
+-------------------------------------------------+
(3 rows)
这个函数返回的信息为:
1.文本别名-词的类型名称
alias text — short name of the token type
2.描述-描述词的类型
description text — description of the token type
3.词内容-词的文本内容
token text — text of the token
4.词典-词的配置所选择的词典
dictionaries regdictionary[] — the dictionaries selected by the configuration for this token type
5.词典-识别该令牌的字典,如果没有,则为NULL
dictionary regdictionary — the dictionary that recognized the token, or NULL if none did
6.处理后的词条
lexemes text[] — the lexeme(s) produced by the dictionary that recognized the token, or NULL if none did; an empty array ({}) means it was recognized as a stop word
四、结合gin索引的相关使用举例
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:23)=# create table test_zhpc(info text);
CREATE TABLE
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:32)=# insert into test_zhpc select '大连市星海广场' from generate_series(1,10000,1);
INSERT 0 10000
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:45)=# explain analyze select count(*) from test_zhpc where to_tsvector('test_zhparserC', info) @@ '大连市 & 星海广场'::tsquery;
+--------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+--------------------------------------------------------------------------------------------------------------+
| Aggregate (cost=2348.80..2348.81 rows=1 width=8) (actual time=39.306..39.307 rows=1 loops=1) |
| -> Seq Scan on test_zhpc (cost=0.00..2348.80 rows=1 width=0) (actual time=39.258..39.259 rows=0 loops=1) |
| Filter: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| Rows Removed by Filter: 10000 |
| Planning Time: 0.199 ms |
| Execution Time: 39.424 ms |
+--------------------------------------------------------------------------------------------------------------+
(6 rows)test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:49)=# create index idx_gin_1 on test_zhpc using gin (to_tsvector('test_zhparserC'::regconfig,info));
CREATE INDEX
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:36:00)=# explain analyze select count(*) from test_zhpc where to_tsvector('test_zhparserC', info) @@ '大连市 & 星海广场'::tsquery;
+-------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+-------------------------------------------------------------------------------------------------------------------------+
| Aggregate (cost=37.79..37.80 rows=1 width=8) (actual time=0.073..0.074 rows=1 loops=1) |
| -> Bitmap Heap Scan on test_zhpc (cost=33.53..37.79 rows=1 width=0) (actual time=0.069..0.070 rows=0 loops=1) |
| Recheck Cond: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| -> Bitmap Index Scan on idx_gin_1 (cost=0.00..33.53 rows=1 width=0) (actual time=0.067..0.067 rows=0 loops=1) |
| Index Cond: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| Planning Time: 0.112 ms |
| Execution Time: 0.146 ms |
+-------------------------------------------------------------------------------------------------------------------------+
(7 rows)相关文章:
【PostgreSQL支持中文的全文检索插件(zhparser)】
PostgreSQL本身是支持全文检索的,提供两个数据类型(tsvector,tsquery),并且通过动态检索自然语言文档的集合,定位到最匹配的查询结果。其内置的默认的分词解析器采用空格进行分词,但是因为中文的词语之间没…...
SHAP分析交互作用的功能,如果你用的模型是xgboost
SHAP分析交互作用的功能,如果你用的模型是xgboost 如果在SHAP分析中使用的是xgoost模型,就可以使用SHAP分析内置的交互作用分析,为分析变量间的相互提供了另外一个观察的视角。关于SHAP交互作用分析,一个参考资料,还是…...

瑞友科技质量改进服务事业部总经理张力受邀为第十三届中国PMO大会演讲嘉宾
全国PMO专业人士年度盛会 北京瑞友科技股份有限公司质量改进服务事业部总经理张力先生受邀为PMO评论主办的2024第十三届中国PMO大会演讲嘉宾,演讲议题为“PMO如何对接战略成为企业IT投资成功的有效保障”。大会将于6月29-30日在北京举办,敬请关注&#x…...

CVE-2024-4761 Chrome 的 JavaScript 引擎 V8 中的“越界写入”缺陷
分析 CVE-2024-4761 和 POC 代码 CVE-2024-4761 描述 CVE-2024-4761 是一个在 V8 引擎中发现的越界写漏洞,报告日期为 2024-05-09。这个漏洞可能允许攻击者通过特制的代码执行任意代码或者造成内存破坏,进而导致程序崩溃或其他不安全行为。 POC 代码解…...

字符串函数(二):strlen(求长度),strstr(查找子串),strtok(分割),strerror(打印错误信息)
字符串函数 一.strlen(求字符串长度)1.函数使用2.模拟实现(三种方法) 二.strstr(字符串查找子串)1.函数使用2.模拟实现 三.strtok(字符串分割)四.strerror,perror&#x…...

EUCR-30S电机保护器施耐德EOCR
EOCR主要产品有电子式电动机保护继电器,电子式过电流继电器,电子式欠电流继电器,电子式欠电压继电器,其它保护和监视装置,电流互感器。 电器密集型设计 ■ 二个集成组装电流互感器 ■ 欠载保护(空转保护…...
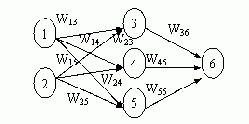
人工神经网络(科普)
人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。在工程…...

宇宙(科普)
宇宙(Universe)在物理意义上被定义为所有的空间和时间(统称为时空)及其内涵,包括各种形式的所有能量,比如电磁辐射、普通物质、暗物质、暗能量等,其中普通物质包括行星、卫星、恒星、星系、星系…...
安防视频/视频汇聚系统EasyCVR视频融合云平台助力智能化酒店安防体系的搭建
一、背景需求 2024年“五一”假期,全国文化和旅游市场总体平稳有序。文化和旅游部6日发布数据显示,据文化和旅游部数据中心测算,全国国内旅游出游合计2.95亿人次。“五一”假期县域市场酒店预订订单同比增长68%,而酒店作为一个高…...
SpringCloudAlibaba:5.1Sentinel的基本使用
概述 简介 Sentinel是阿里开源的项目,提供了流量控制、熔断降级、系统负载保护等多个维度来保障服务之间的稳定性。 官网 https://sentinelguard.io/zh-cn/ Sentinel的历史 2012 年,Sentinel 诞生,主要功能为入口流量控制。 2013-2017 年…...

SHELL-双重循环习题练习
1.99乘法表 #!/bin/bash #99乘法表for ((second1; second<9; second)) dofor ((first1; first<second; first))do echo -n -e "${first}*${second}$[first*second]\t" done echo done ######### 首先定义了一个外循环变量second,初始值为1&am…...

2024年为什么很多电商商家,都想涌入视频号,究竟是什么原因?
大家好,我是电商糖果 对电商有了解的朋友,在今年肯定发现一个现象,那就是很多商家对视频号比较青睐。 视频号究竟有何魔力,让越来越多的商家都想要入驻。 其实很简单,它让商家看到了市场。 视频号背后是谁…...
)
Google Gemma 2B 微调实战(IT科技新闻标题生成)
本文我将使用 Google 的 Gemma-2b 模型来微调一个基于IT科技新闻正文来生成对应标题的模型。并且我将介绍如何使用高度集成的训练框架来进行快速微调。 开始前 为了尽可能简化整个流程,我将使用 linux-cn 数据集[1]作为本次训练任务的训练数据。 模型选择使用 Gemma-2b[2],…...

RabbitMQ:深入理解高性能消息队列
RabbitMQ:深入理解高性能消息队列 文章目录 RabbitMQ:深入理解高性能消息队列前言一、RabbitMQ概述二、RabbitMQ的核心概念三、RabbitMQ的工作原理一、生产者发送消息二、交换机转发消息三、队列存储消息四、消费者接收并处理消息 四、RabbitMQ的使用场景…...
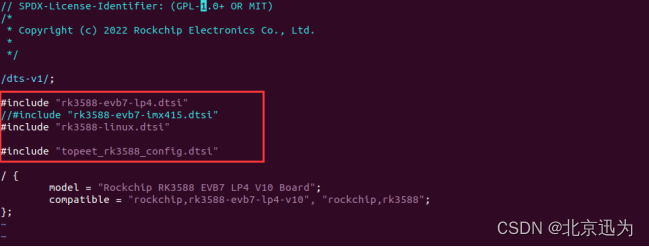
【北京迅为】《iTOP-3588开发板源码编译手册》-第4章 Android12/Linux设备树简介
RK3588是一款低功耗、高性能的处理器,适用于基于arm的PC和Edge计算设备、个人移动互联网设备等数字多媒体应用,RK3588支持8K视频编解码,内置GPU可以完全兼容OpenGLES 1.1、2.0和3.2。RK3588引入了新一代完全基于硬件的最大4800万像素ISP&…...

C++ C# 贝塞尔曲线
二阶贝塞尔曲线公式 三阶贝塞尔曲线公式 C 三维坐标点 二阶到N阶源码 //二阶公式: FVector BezierUtils::CalculateBezierPoint(float t, FVector startPoint, FVector controlPoint, FVector endPoint) {float t1 (1 - t) * (1 - t);float t2 2 * t * (1 - t);…...

勒索软件漏洞?在不支付赎金的情况下解密文件
概述 在上一篇文章中,笔者对BianLian勒索软件进行了研究剖析,并且尝试模拟构建了一款针对BianLian勒索软件的解密工具,研究分析过程中,笔者感觉构建勒索软件的解密工具还挺有成就感,因此,笔者准备再找一款…...
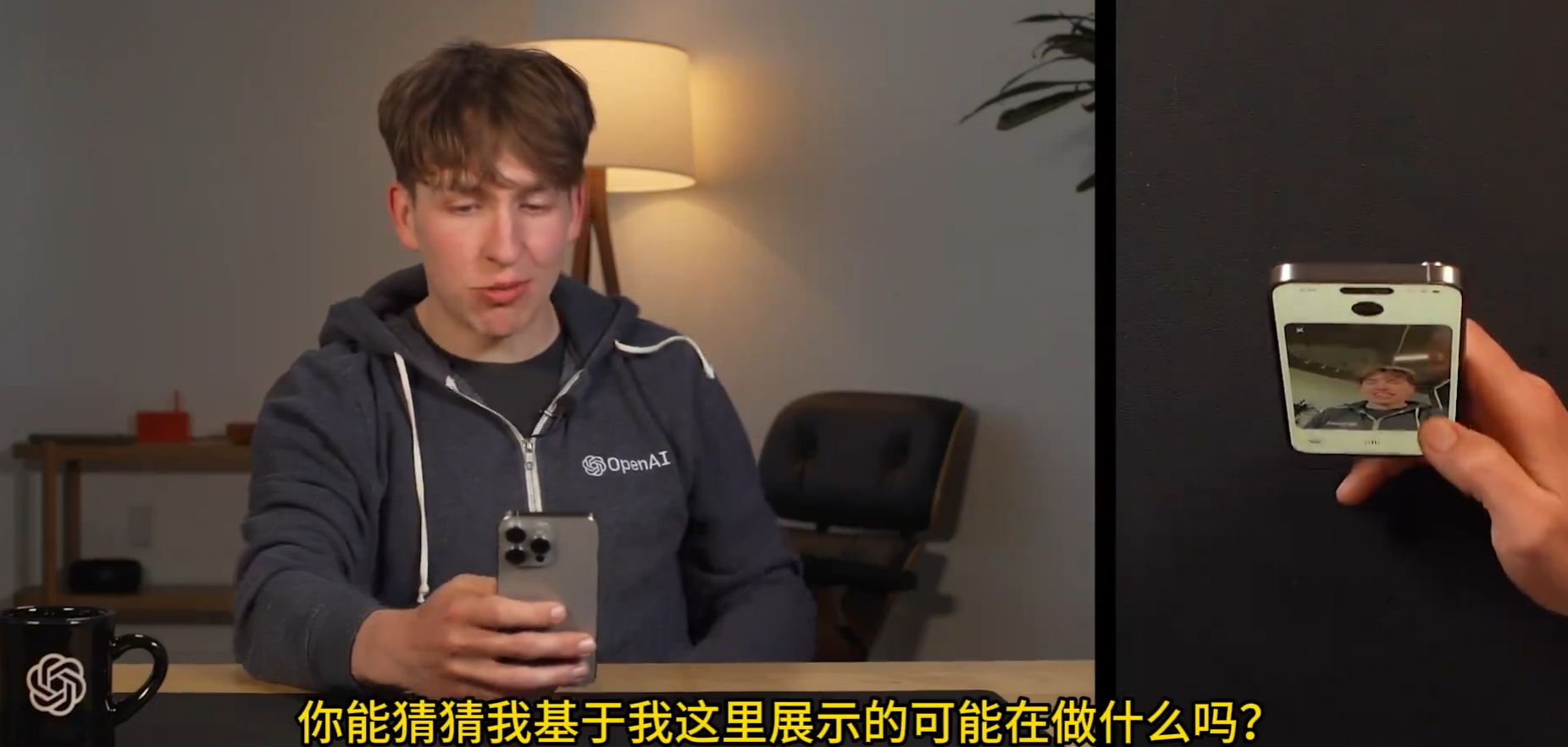
实时“秒回”,像真人一样语音聊天,GPT-4o模型强到恐怖
今天凌晨OpenAl发布了 GPT-4o,这是一种新的人工智能模式,集合了文本、图片、视频、语音的全能模型。 能实时响应用户的需求,并通过语音来实时回答你,你可以随时打断它。还具有视觉能力,能识别物体并根据视觉做出快速的…...
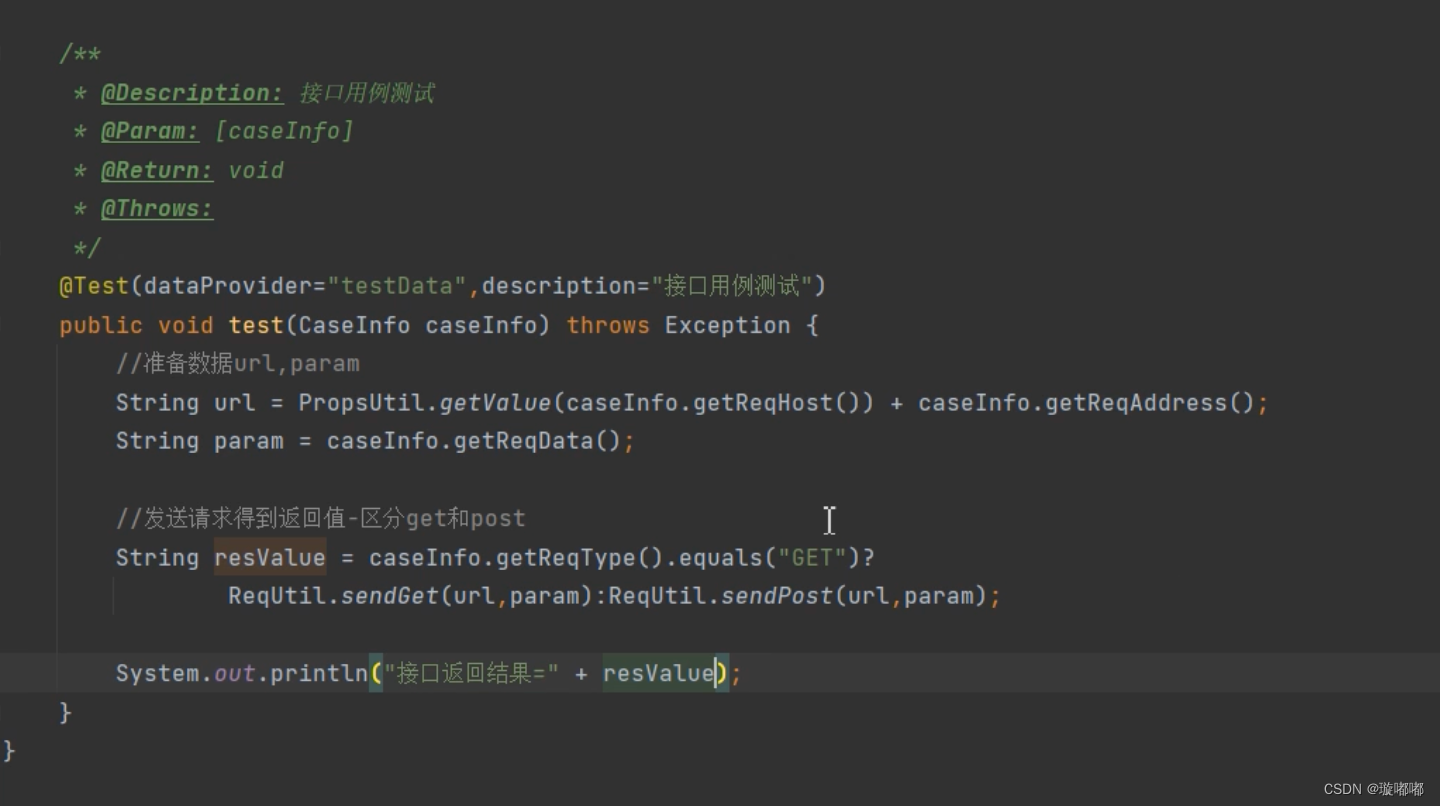
Properties配置文件和源码
先对测试类进行get方法复写得到getReqType 判断caseinfo等于get时,就是get请求,反之就不是 这里的url和param都是xxx代替,如果直接写内容,每次都会请求 三目运算优化 为什么要用配置文件 test里时url,可以将ip和端口写在配置文…...
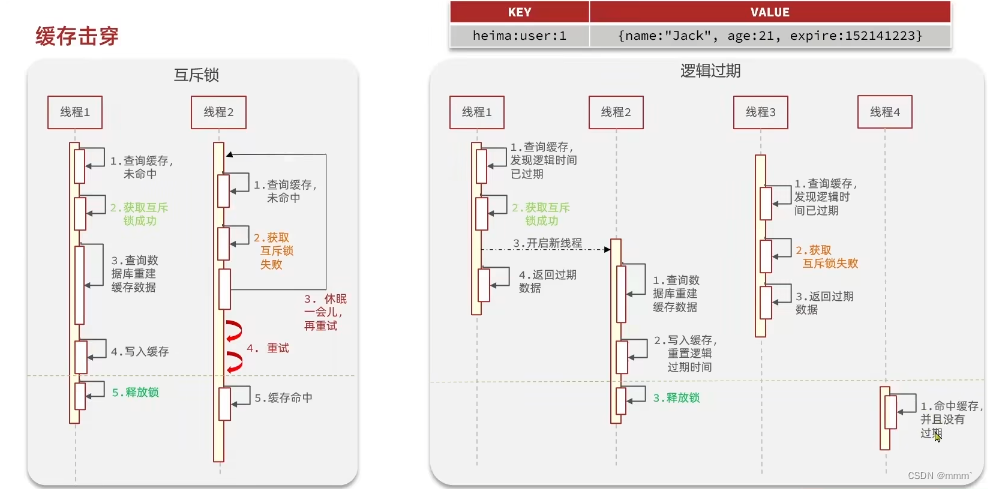
redis原生命令及项目使用
主动更新策略 缓存问题及解决 布隆过滤出现哈希冲突解决方案: 选择合适的哈希函数:布隆过滤器的性能和哈希函数的选择密切相关。选择高效、低碰撞率的哈希函数可以降低误判率。通常使用的哈希函数有 MurmurHash、FNV 等。 合理设置过滤器大小:过滤器的大小(位数组的大小)…...

根据等价类划分法,**有效等价类**是指符合系统规格说明、应被系统正常接受的输入范围
根据等价类划分法,有效等价类是指符合系统规格说明、应被系统正常接受的输入范围。 题目中密码长度要求为 6–12位(含端点),即最小长度为6,最大长度为12,且为整数位数。 因此,关于密码长度的有效…...

启XX辰-头部安全公司面试提问
自我介绍 对称加密有哪些,非对称加密有哪些,两者之间的主要差异 有过JS逆向的经验吗 非对称加密如何获取加密前的内容,已知公钥 如果就给你一个登录框,给出你的测试思路 对于在工作时,给你一个企业名,给出你…...
”)
超自动化运维,您需要的是“可信执行平台(TEP)”
在AI智能体与自动化工具蓬勃发展的今天,各类开源框架与轻量工具层出不穷。它们让“用自然语言驱动电脑做事”的愿景触手可及——文件操作、脚本执行、浏览器控制,一切看似高效便捷。然而,当我们将视线从个人桌面转向企业的数据中心、核心生产…...

python高校学生党员信息管理系统_829h59n3
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能技术实现项目特点应用价值项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背景 高校学生党员信…...

如何将短信从Android传输到 iPhone
每次苹果发布新款 iPhone,都会吸引大量渴望更换手机的用户,其中也包括许多Android用户。对于这些Android用户来说, 将数据从Android迁移到新 iPhone是当务之急,尤其是传输短信,因为短信通常包含个人和职业生活的重要信…...

极域电子教室破解终极指南:如何重获电脑控制权而不被老师发现
极域电子教室破解终极指南:如何重获电脑控制权而不被老师发现 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房上课时,面对老师全屏广播…...

30天学会AI工程师|Day 14:自己实现一个小工具,你才会真正理解 Agent 是怎么“动起来”的
你先知道一件事 昨天你理解了 Tool Calling 的概念,今天最好亲手做一个最小工具。 为什么这一步重要 你完全可以从一个非常简单的例子开始。比如做一个计算器工具,输入两个数字和一个运算符,返回结果。或者做一个时间查询工具,返回…...

如何快速掌握ncmdump:网易云音乐NCM格式解密完整指南
如何快速掌握ncmdump:网易云音乐NCM格式解密完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐的NCM加密格式而烦恼?精心收藏的音乐无法在其他播放器中使用?ncmdump正是…...

无人机带多传感器就死机、数据不同步?做了 17 年工业主机研发,教你解决多设备协同的核心痛点
做了 17 年工业主机研发,我发现一个特别有意思的现象:很多客户的无人机,只带一个普通摄像头的时候,飞得稳稳当当,什么毛病都没有。但一旦加上激光雷达、毫米波雷达、热成像相机、多光谱相机这些传感器,就开…...

如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案
如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到…...