【多模态】30、Monkey | 支持大尺寸图像输入的多任务多模态大模型

文章目录
- 一、背景
- 二、方法
- 2.1 Enhancing Input Resolution
- 2.2 Multi-level Description Generation
- 2.3 Multi-task Training
- 三、效果
- 3.1 Image Caption
- 3.2 General VQA
- 3.3 Scene Text-centric VQA
- 3.4 Document-oriented VQA
- 3.5 消融实验
- 3.6 可视化
论文:Monkey : Image Resolution and Text Label Are Important Things for Large Multi-modal Models
代码:https://github.com/Yuliang-Liu/Monkey
出处:华中科大
时间:2024.02
贡献:
- 模型支持大于 1344x896 分辨率的输入,无需预训练。比在大型语言模型(LMMs)中常用的 448x448 分辨率大了很多,能更好的识别和理解小目标或密集目标或密集文本
- 模型有很好的上下文关联。作者引入了一种多级描述生成的方法,该方法能够提高模型捕捉不同目标之间关系的能力
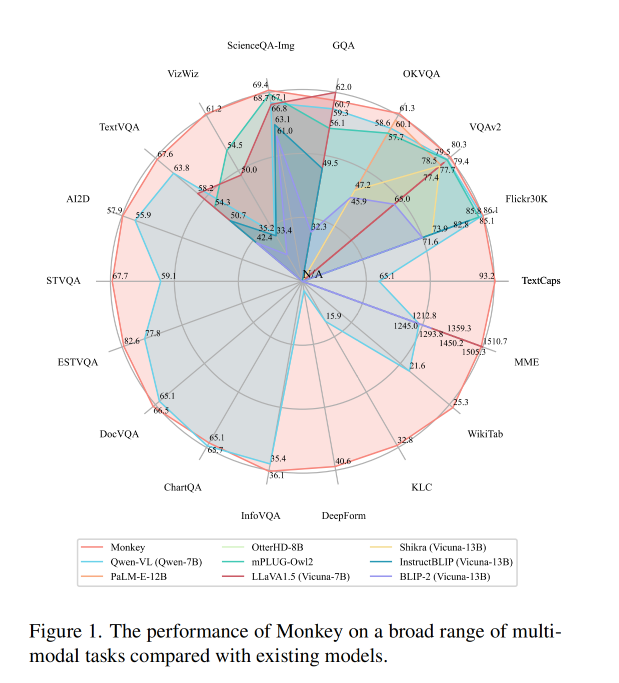
- Monkey 模型在多个测评数据集上都有很好的表现。作者在 18 个数据集上进行了测试,Monkey 模型在图像标题生成、常规视觉问题问答、以场景文本为中心的视觉问答、以文档为导向的视觉问答等任务上的表现都很好
一、背景
LMM 模型能够处理多种不同类型的数据,包括图像、文本、语音等不同模态,对于图像-文本多模态模型,LMM 模型的训练中,图片的分辨率越高,模型能够检测或捕捉到的视觉细节就越丰富,对目标的识别,目标间关系的捕捉,图像中上下文信息的捕捉就更有利,但对于模型来说,很难处理多种不同的分辨率或不同质量的图像,尤其在复杂的场景中更难。
现有的解决方案包括使用具有更大输入分辨率的预训练视觉模块(如LLaVA1.5 [29]),并通过逐渐增加训练过程中的分辨率(如Qwen-VL [3]、PaLI-3 [10]和PaLI-X [9])
但这些方法需要大量的训练资源,并且仍然难以很好的处理更大图像尺寸的图像
为了充分利用大输入分辨率的优势,很重要的一点是图像要有很详细的相关描述,这可以增强模型对图像-文本关系的理解,但是像COYO [6] 和 LAION [45] 通常只有简单的标题,难以满足需求。
Monkey 是什么:一个资源高效的方法,用于提升 LMM 的输入分辨率
- 一般的方法:直接对 ViT 进行插值来增加输入分辨率,但这样做效率不高
- Monkey 使用的方法:将大分辨率的输入图片使用滑动窗口切分成小的 patches,每个 patch 独立的输入静态(不训练)的 visual encoder,编码器经过 LoRA(Low-Rank Adaptation)调整,和一个可训练的视觉重采样器增强,增强了其功能。
- 这种方式利用了现有的大型多模态模型,避免了从头开始进行广泛预训练的需要。通常这些编码器是在较小的分辨率(例如448×448)上训练的,从头开始训练成本很高。通过将每个图像块调整到编码器支持的分辨率,可以维持原有的训练数据分布。
- 为了更好的利用大分辨率输入,作者还提出了一个自动的多级描述生成的方法,这个方法能够无缝结合多个生成器的简介,来为图片生成高质量、丰富的标题数据,利用的模型如下,作者使用这些模型生成了全面且分层的标题,能够捕捉到广泛的视觉细节:
- BLIP2:对图像-文本理解很细腻
- PPOCR:强大的 OCR 识别模型
- GRIT:擅长粒度化的图像-文本对齐
- SAM:用于语义对齐的动态模型
- ChatGPT:有很好的上下文理解和语言生成能力
Vision Transformer (ViT) 使用了 Transformer 架构来处理图像数据。在深度学习中,提升模型处理的图像分辨率通常可以帮助模型捕捉到更细粒度的特征,这在某些任务中可能会提高模型的性能。然而,直接在高分辨率的图像上训练模型会大大增加计算成本和内存需求。
为了解决这个问题,通常会采取以下几种方法之一:
-
渐进式训练:这种方法首先在低分辨率的图像上训练模型,然后逐步增加图像的分辨率。这样可以在早期阶段以较低的计算成本训练模型,并在模型逐渐适应更高分辨率的图像时增加细节。
-
插值:在某些情况下,研究人员可能会选择在预训练的模型基础上,对输入图像进行插值以提高其分辨率。这样做的目的是利用模型在低分辨率图像上学到的知识,并通过插值来适应更高分辨率的图像。插值方法可以是最近邻插值、双线性插值、双三次插值等。
-
多尺度训练:这种方法同时使用不同分辨率的图像来训练模型。模型在从不同分辨率的图像中学习特征时,可以更好地泛化到新的、更高分辨率的图像上。
对于 Vision Transformer (ViT) 而言,由于其结构是将图像分割成多个小块(patch)然后输入到 Transformer 中,因此提升分辨率时需要考虑如何调整这些小块的大小和数量。通过对 ViT 进行插值,可以在不显著改变模型架构的情况下,适应更高分辨率的图像,这是一种相对简单且有效的方法来提升模型处理高分辨率图像的能力。
二、方法
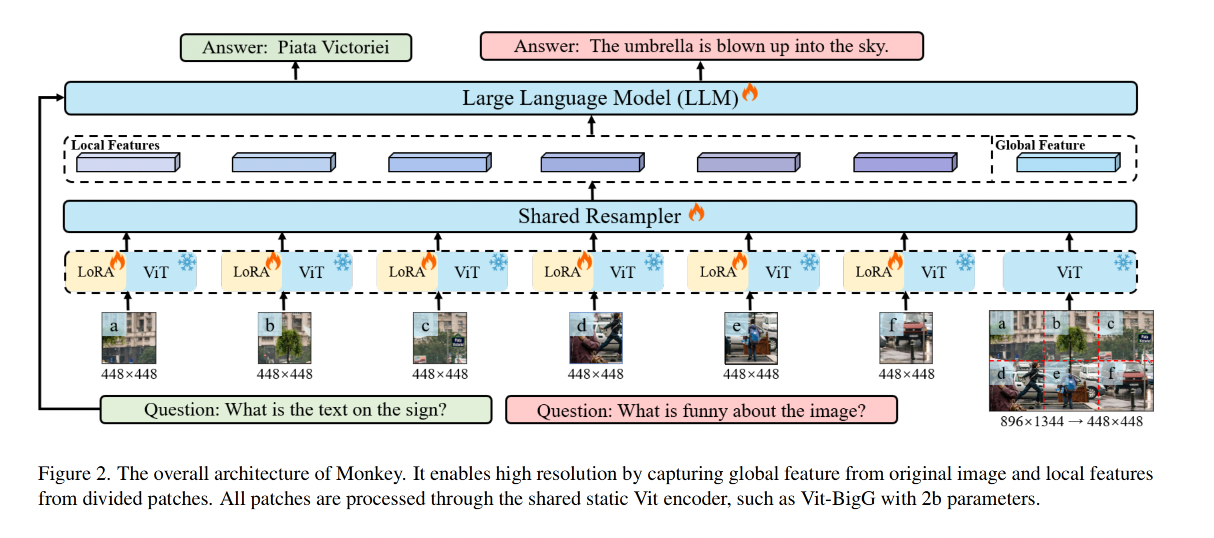
Monkey 模型的结构如图 2 所示,输入的图片被分成了 patches,这些 patches 将被输入 ViT,ViT 是共享参数的,经过 ViT 后得到特征,随后,局部和全局特征通过共享重采样器和大型语言模型(Large Language Model,简称LLM)进行处理,从而生成所需的答案。
2.1 Enhancing Input Resolution
- 首先,输入一个图片,HxWx3
- 接着,使用滑窗来进行切分(滑窗大小为 KaTeX parse error: Undefined control sequence: \time at position 5: H_v \̲t̲i̲m̲e̲ ̲W_v,滑窗大小的宽高也就是 original LMM 所支持的宽高大小),切分成小的图像块儿
- 然后,将切分后的图像块儿输入共享参数的 encoder,每个 encoder 的输入都是不同的图像块儿,此外,会给每个 encoder 搭配一个 LoRA 来适应每个 encoder 对不同位置的图像块儿的学习,有助于模型深入理解空间和上下文的关系,且没有多余引入参数。为了保证整个输入图像的结构信息,作者将原图还会 resize 到 KaTeX parse error: Undefined control sequence: \time at position 5: H_v \̲t̲i̲m̲e̲ ̲W_v 的大小,所以,作者会将独立的图像块儿和 resize 后的 global image 都经过 encoder 编码
- 再后,经过 shared resampler ,这里的 resampler 是源于 Flamingo,主要有两个作用,一个是组合所有的 visual information,另一个是捕捉更高级的语义视觉表达,映射到 language feature space。resampler 是通过 cross-attention module 实现的,其中可训练的 embedding 特征是 query,image features 是 key。
- 最后,将 shared resampler 的输出和文本问题输入一起输入大语言模型 LLM
2.2 Multi-level Description Generation
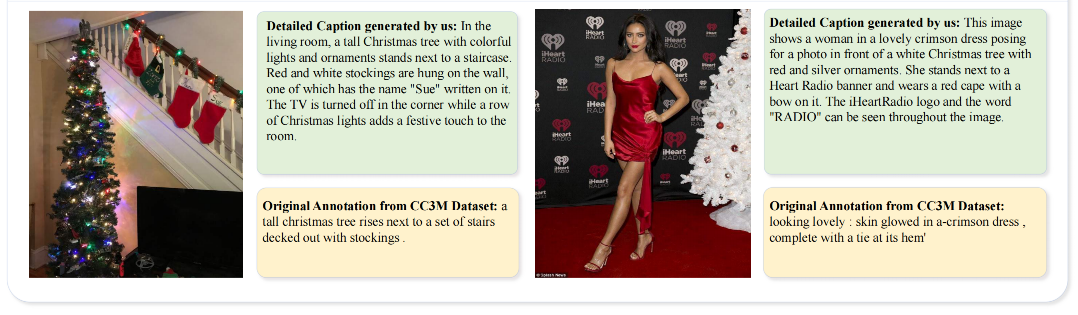
之前的方法如 LLaVa、QWen-VL 都是使用 LAION 和 COYO 或 CC3M 来训练,但这些数据的文本标签非常简单,缺失了对图像的细致的描述,所以,尽管使用了高分辨率的训练数据,确没有挖掘出图像的更细致的信息
基于此,本文提出了一种生成多层描述的方法,能够生成丰富且高质量的描述,作者使用了多个模型来实现:
- BLIP2:能够为 image 和 text 的关系提供一个很深入的理解
- PPOCR:强大的 OCR 识别模型
- GRIT:擅长粒度化的图像-文本对齐
- SAM:用于语义对齐的动态模型
- ChatGPT:有很好的上下文理解和语言生成能力
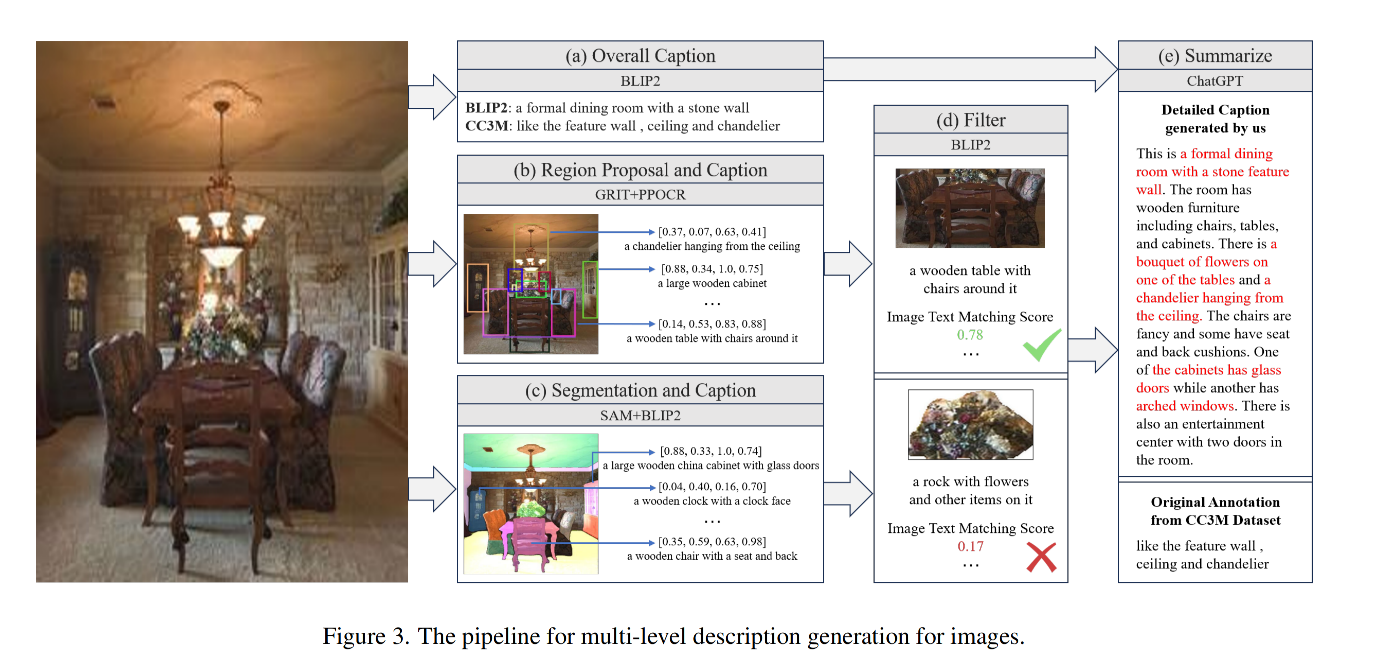
整个流程如图 3 所示:
- 第一步:使用 BLIP2 的 Q-former 来生成 overall caption,同时保留 CC3M 的注释来提供上下文;使用 GRIT 这个 region-to-text 模型,对特定区域、目标生成详细的描述,GRIT 模型能够检测目标同时生成描述, PPOCR 能够从中提取到文本 text 信息;使用 SAM 进行分割,然后使用 BLIP2 来进行描述。
- 第二步:使用 BLIP2 对 region caption 和 segmentation caption 的结果进行过滤,剔除掉分数匹配较低的 caption
- 第三步:将 global captions, localized descriptions, text extracts, object details with spatial coordinates 一起送入 ChatGPT 进行微调,让 ChatGPT 生成准确且上下文丰富的图像描述

2.3 Multi-task Training
本文模型支持多种不同的任务:
- image caption: “Generate the captionin English:” for basic captions, “Generate the detailed caption in English:” for more intricate ones
- 对 image-based 问题的回答: “{question} Answer: {answer}.”
- 同时处理 text 和 image
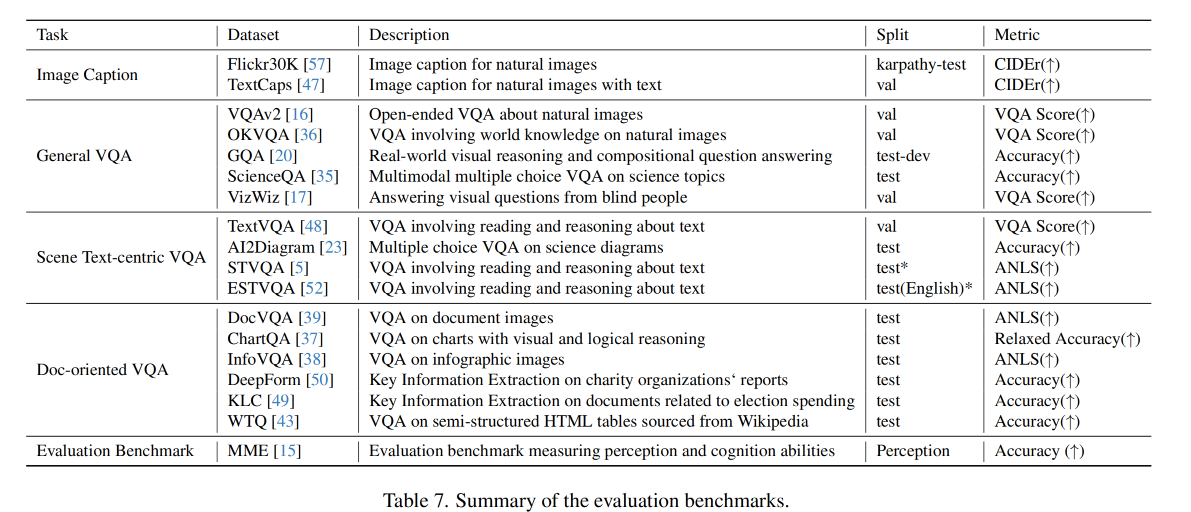
本文使用的数据集:
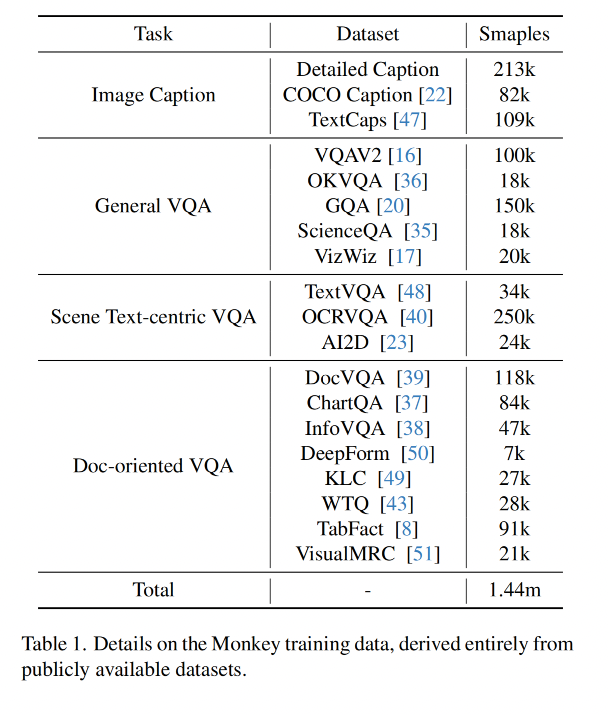
三、效果
模型实现细节:
- 作者使用 Vit-BigG [21] 和 LLM from QwenVL [3] 分别作为预训练好的多模态模型来使用
- 由于 vision encoder 已经训练的很好了,所以作者只做了 instruction-tuning。在 instruction-tuning 时,滑窗的宽高都使用的 448x448 来匹配 Qwen-VL 的 encoder 尺寸
- 对于所有图像块儿,作者使用的是 resampler 是一样的。可学习的查询 query 与图像的局部特征(patches)进行交互,用于提取重要信息。对于每个 patch,都使用相同的 256 维可学习 query。这些 query 是模型中的参数,可以通过训练来优化。
- 由于训练时间有限,主要实验使用的是896×896像素大小的图像
- 对于 LoRA:LoRA 是模型的一部分,用于调整模型的注意力机制和多层感知机(MLP)。在这里,注意力模块的秩设置为16,编码器中MLP的秩设置为32。秩在这里指的是LoRA中用于调整权重的参数数量,它影响模型的复杂度和能力。
- 模型参数:Monkey 总参数量 9.8B(98亿)
- 大型语言模型:包含 7.7B(Billion)参数。
- 重采样模块:包含 0.09B(Million)参数。
- 编码器:包含 1.9B(Billion)参数。
- LoRA:包含 0.117B(Billion)参数。
训练细节:
- 数据:使用 CC3M 数据集中的数据,使用本文方法生成了描述,共 427k image-text pairs
- 优化器:AdamW
- 学习率:1e-5,cosine 学习率下降模式
- batch size:1024
- 训练时长:40 A800 天 / epoch
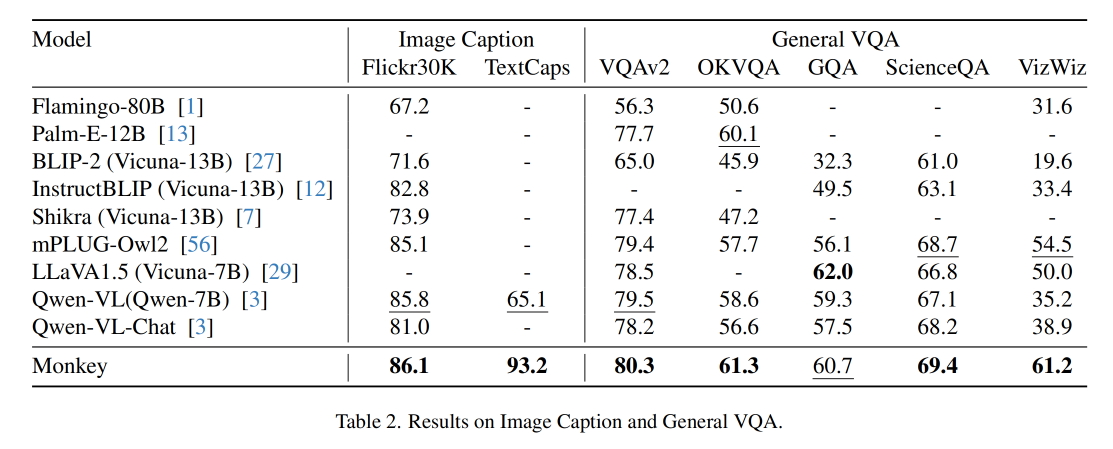
3.1 Image Caption
作者使用 Flickr30K 和 TextCaps 作者 benchmark 来测试这个任务
3.2 General VQA
General visual question answering (VQA)
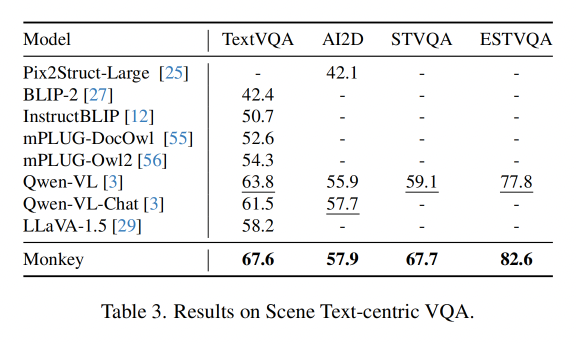
3.3 Scene Text-centric VQA
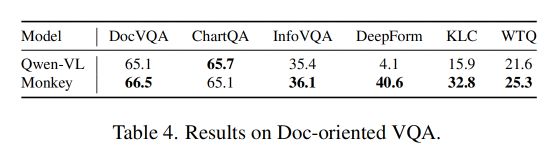
3.4 Document-oriented VQA
3.5 消融实验
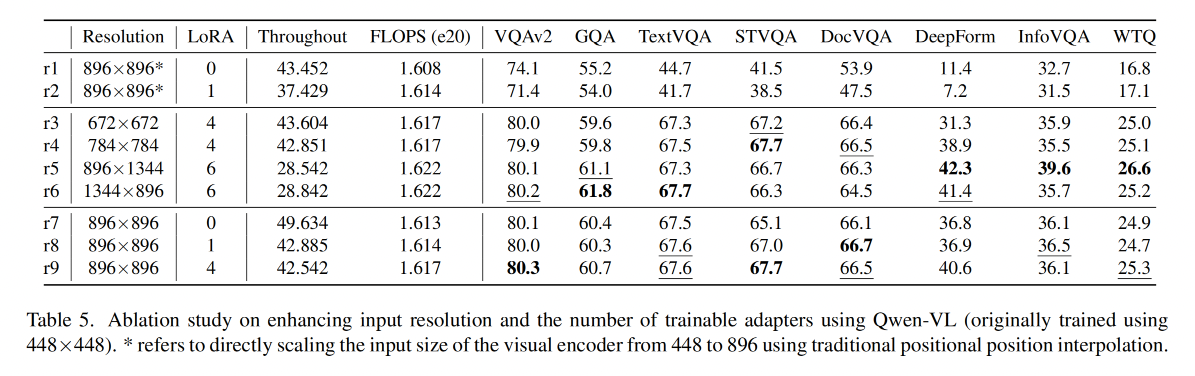
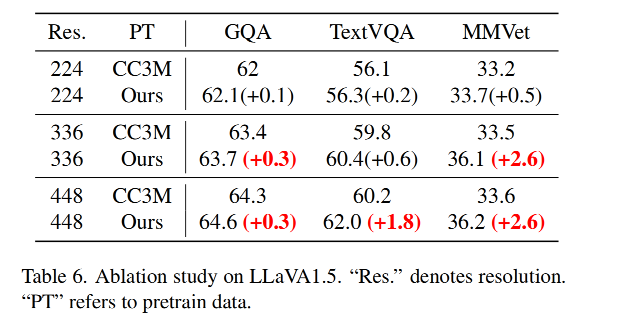
3.6 可视化


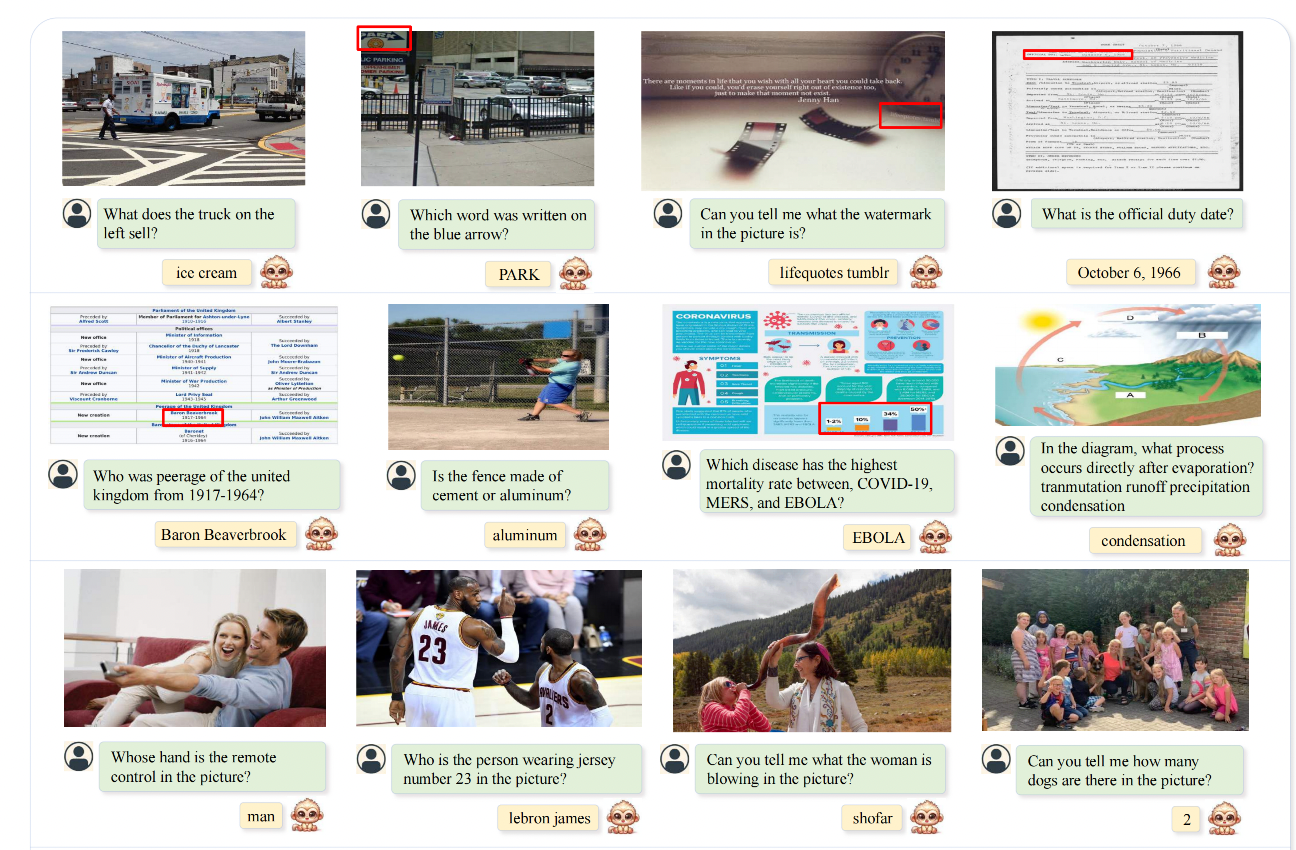

和其他模型的对比:
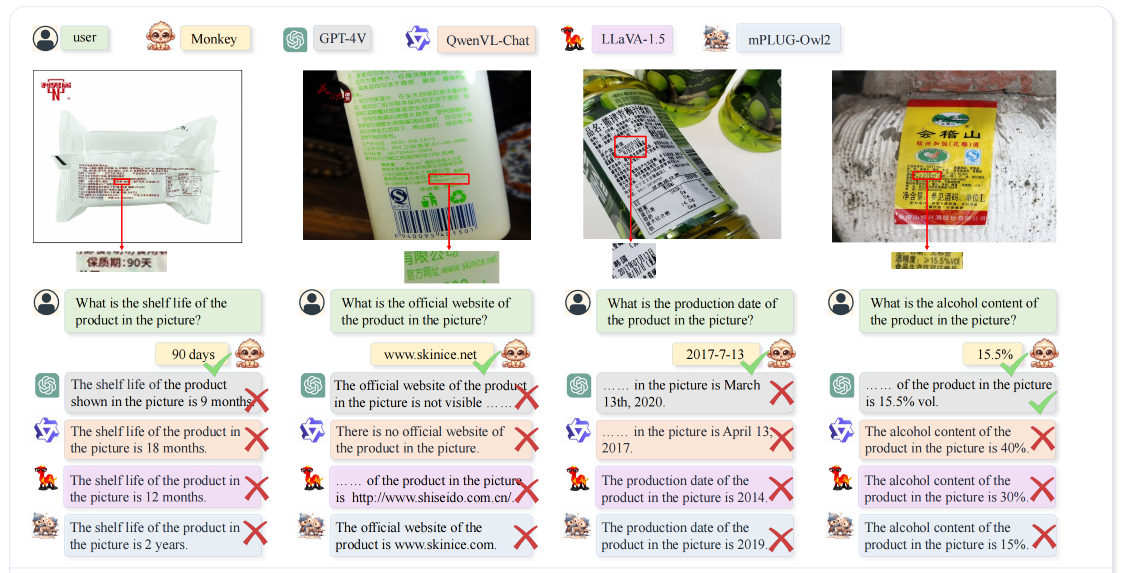
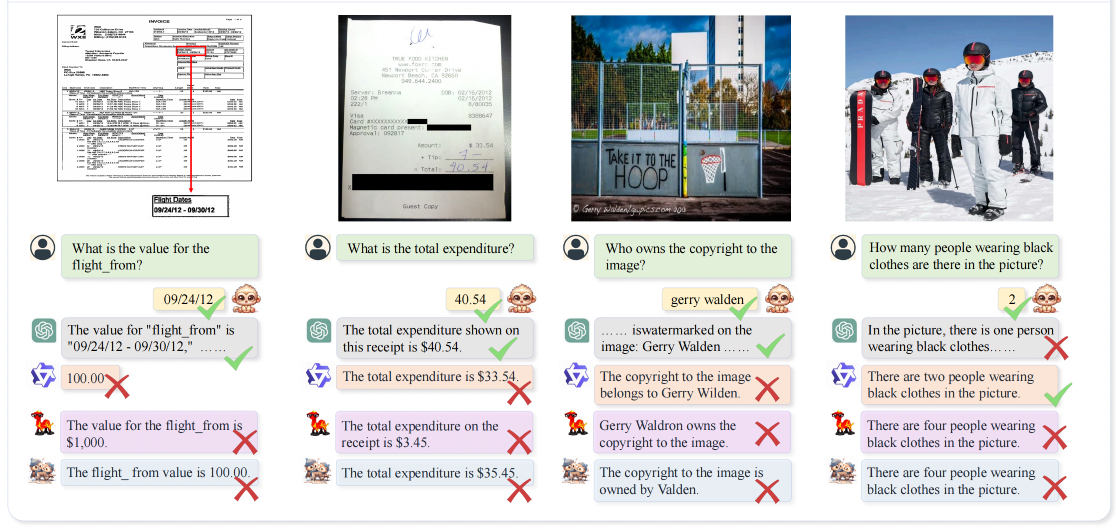
不同分辨率下识别的效果对比:分辨率越小,错误越多

相关文章:
【多模态】30、Monkey | 支持大尺寸图像输入的多任务多模态大模型
文章目录 一、背景二、方法2.1 Enhancing Input Resolution2.2 Multi-level Description Generation2.3 Multi-task Training 三、效果3.1 Image Caption3.2 General VQA3.3 Scene Text-centric VQA3.4 Document-oriented VQA3.5 消融实验3.6 可视化 论文:Monkey : …...

PHP黑魔法之md5绕过
php本身是一种弱语言,这个特性决定了它的两个特点: 输入的参数都是当作字符串处理变量类型不需要声明,大部分时候都是通过函数进行类型转化php中的判断有两种: 松散比较:只需要值相同即可,类型不必相同,不通类型比较会先转化为同类型,比如全数字字符串和数字比较,会比…...
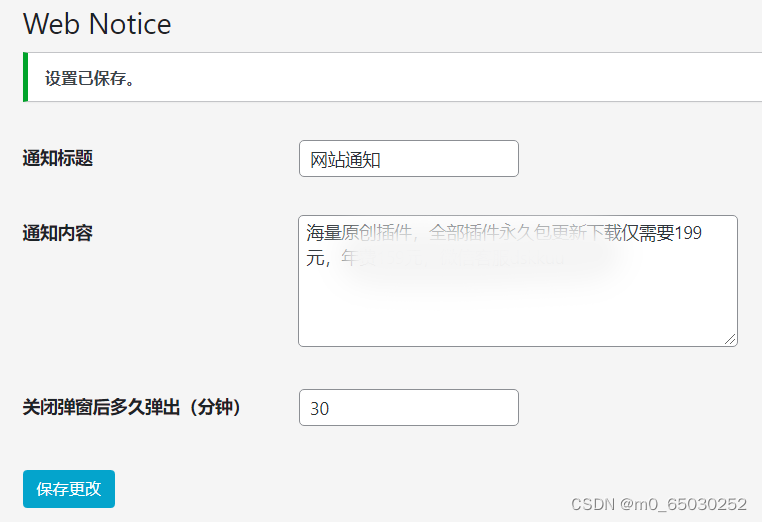
【适用全主题】WordPress原创插件:弹窗通知插件 支持内容自定义
内容目录 一、详细介绍二、效果展示1.部分代码2.效果图展示 三、学习资料下载 一、详细介绍 适用于所有WordPress主题的弹窗插件 一款WordPress原创插件:弹窗通知插件 支持内容自定义 二、效果展示 1.部分代码 代码如下(示例)࿱…...
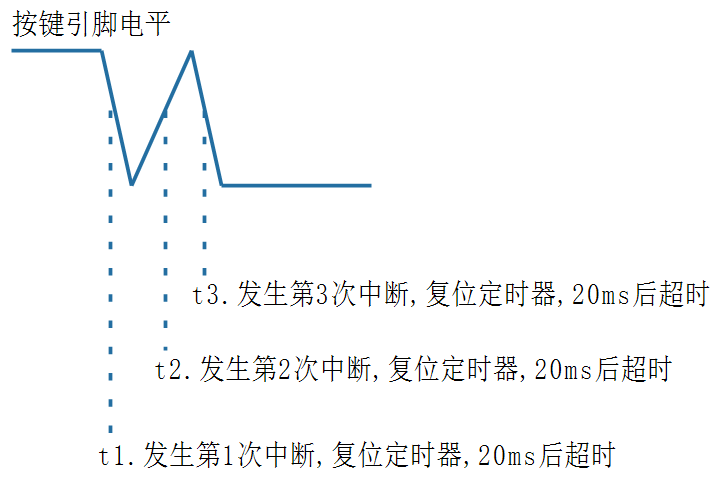
定时器的理论和使用
文章目录 一、定时器理论1.1定时器创建和使用 二、定时器实践2.1周期触发定时器2.2按键消抖 一、定时器理论 定时器是一种允许在特定时间间隔后或在将来的某个时间点调用回调函数的机制。对于需要周期性任务或延迟执行任务的嵌入式应用程序特别有用。 软件定时器: …...
【架构-17】通信系统架构设计理论
通信系统网络架构 1. 局域网网络架构 拓扑结构:星型、总线型、环型、树型。 网络架构:单核心架构(结构简单,地理范围受限)、双核心架构(网络拓扑结构可靠,投资较单核高)、环型架构…...

网络中的基本概念
网络初识 局域网:把若干个电脑组成在一起,通过路由器进行组网。 广域网:把局域网进一步的连接,构成更复杂的网络体系。 IP地址:区分主机。 端口号:区分主机上不同的程序。 协议:是一种约定&…...
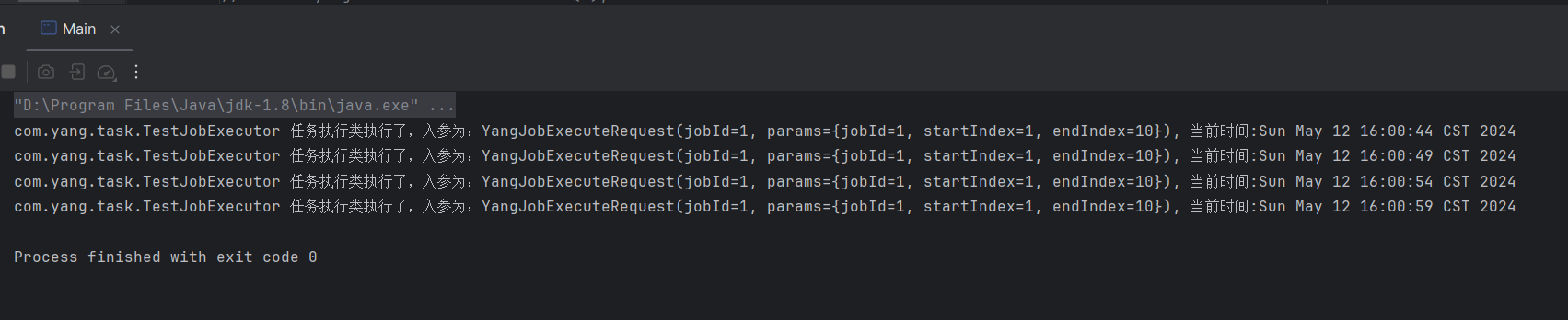
手撸XXL-JOB(二)——定时任务管理
在上一节中,我们介绍了SpringBoot中关于定时任务的执行方式,以及ScheduledExecutorService接口提供的定时任务执行方法。假设我们现在要写类似XXL-JOB这样的任务调度平台,那么,对于任务的管理,是尤为重要的。接下来我们…...
DEV--C++小游戏(吃星星(0.2))
目录 吃星星(0.2) 简介 本次更新 分部代码 头文件(增) 命名空间变量(增) 副函数(新,增) 清屏函数 打印地图函数(增) 移动函数 选择颜色…...

Lua 协程池
协程池 在 使用 Lua 协程模拟 Golang 的 go defer 编程模式 中介绍了 Lua 协程的使用,模仿 golang 封装了下 还可以做进一步的优化 原来的 go 函数是这样实现的: function go(_co_task)local co coroutine.create(function(_co_wrap)_co_task(_co_w…...
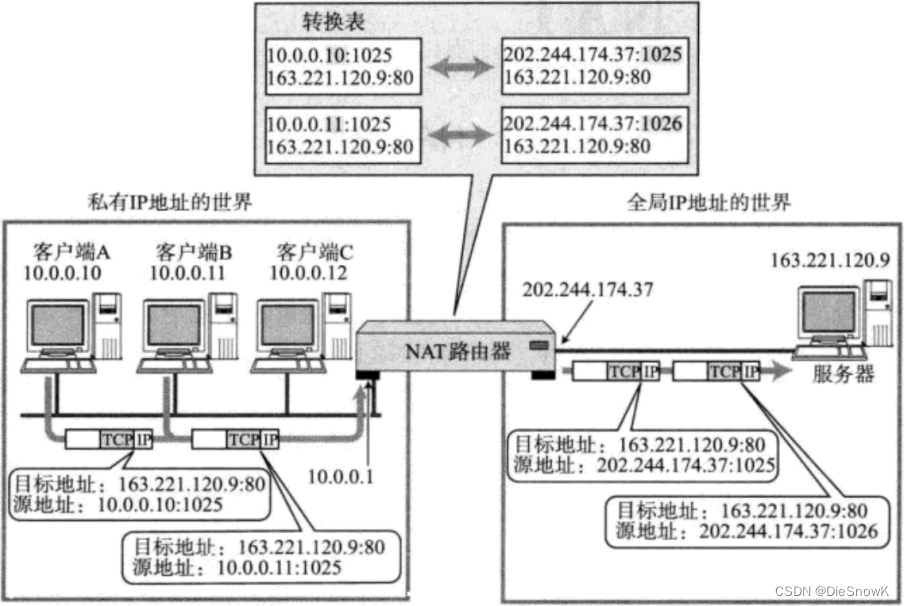
[Linux][网络][协议技术][DNS][ICMP][ping][traceroute][NAT]详细讲解
目录 1.DNS1.DNS背景2.域名简介 2.ICMP协议1.ICMP功能2.ICMP两类报文 3.ping命令4.traceroute5.NAT技术1.NAT技术背景2.NAT IP转换过程3.静态地址NAT && 动态地址NAT4.网络地址端口转换NAPT5.NAT技术的缺陷6.NAT和代理服务器 6.总结1.数据链路层2.网络层3.传输层4.应用…...
Android 集成Bugly完成线上的异常Exception收集及处理
文章目录 (一)添加产品APP(二)集成SDK(三)参数配置权限混淆 (四)初始化 (一)添加产品APP 一)在个人头像 -> 我的头像 -> 新建产品 二&…...

Redis——Redis的数据库结构、删除策略及淘汰策略
Redis是一个高性能的key-value存储系统,它支持多种数据结构,并提供了丰富的删除策略和淘汰策略。以下是关于Redis的数据库结构、删除策略及淘汰策略的详细介绍: Redis的数据库结构 Redis是一个key-value数据库,数据存储是以一个…...

【Vue3笔记03】Vue3项目工程中使用vue-router路由
这篇文章,主要介绍Vue3项目工程中如何使用vue-router路由。 目录 一、vue-router路由 1.1、下载vue-router路由 1.2、创建router.js文件 1.3、main.js配置路由...
并行执行的4种类别——《OceanBase 并行执行》系列 4
OceanBase 支持多种类型语句的并行执行。在本篇博客中,我们将根据并行执行的不同类别,分别详细阐述:并行查询、并行数据操作语言(DML)、并行数据定义语言(DDL)以及并行 LOAD DATA 。 《并行执行…...

函数练习.
1.打印乘法口诀表 口诀表的行数和列数自己指定如:输入9,输出99口诀表,输出12,输出1212的乘法口诀表。 multiplication(int index) { if (index 9) { int i 0; for (i 1; i < 10; i) { int j 0; for (j 1; j &…...

Git 分支命令操作详解
目录 1、分支的特点 2、分支常用操作 3、分支的使用 3.1、查看分支 3.2、创建分支 3.3、修改分支 3.4、切换分支 3.5、合并分支 3.6、产生冲突 3.7、解决冲突 3.8、创建分支和切换分支说明 1、分支的特点 同时并行推进多个功能开发,提高开发效率。各个分…...

十二生肖Midjourney绘画大挑战:释放你的创意火花
随着AI艺术逐渐进入大众视野,使用Midjourney绘制十二生肖不仅能够激发我们的想象力,还能让我们与传统文化进行一场新式的对话。在这里,我们会逐一提供给你创意满满的绘画提示词,让你的作品别具一格。而且,我们还精选了…...
【C++】priority_queues(优先级队列)和反向迭代器适配器的实现
目录 一、 priority_queue1.priority_queue的介绍2.priority_queue的使用2.1、接口使用说明2.2、优先级队列的使用样例 3.priority_queue的底层实现3.1、库里面关于priority_queue的定义3.2、仿函数1.什么是仿函数?2.仿函数样例 3.3、实现优先级队列1. 1.0版本的实现…...

Go语言函数
在Go语言中,函数是一种基本的构建块,用于组织代码并执行特定任务。它们是可重复使用的代码段,可以接收输入参数,执行一系列操作,并可返回结果。以下是Go语言中函数的详细介绍及其使用方法: 基本语法 Go语…...

如何使用EasyExcel导入百万数据
摘要: 本文将详细探讨如何利用EasyExcel库,以及结合Java编程,高效地导入大规模数据至应用程序中。我们将逐步介绍导入流程、代码实现细节,并提供性能优化建议,旨在帮助读者在处理百万级别数据时,提高效率与…...

ElevenLabs希腊文语音合成精度提升87%:基于ISO 639-2标准的音素对齐校准全流程详解
更多请点击: https://kaifayun.com 第一章:ElevenLabs希腊文语音合成精度提升87%的工程意义与语言学背景 ElevenLabs在2024年Q2发布的v3.2语音模型中,针对现代希腊语(el-GR)的语音合成MOS(Mean Opinion S…...

中年以后,真正有效的抗衰老运动,其实就这 4 种
过了 30 岁,肌肉每年流失 1%-2%,基础代谢下降,精力大不如前——这不是错觉,是生理规律。 但运动的选择,决定了你是「老得快」还是「逆生长」。分享 4 种被科学验证的抗衰老运动,中年人越早开始越好。 1️⃣…...

酷安UWP桌面客户端:在Windows电脑上高效刷酷安的完整指南
酷安UWP桌面客户端:在Windows电脑上高效刷酷安的完整指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在为手机小屏幕刷酷安而感到眼睛酸痛吗?想在27寸大屏幕…...

为AI智能体工作流构建高可用的模型调用后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AI智能体工作流构建高可用的模型调用后端 在构建基于OpenClaw或Hermes Agent的自动化工作流时,模型调用的稳定性直接…...

Camunda流程版本管理避坑指南:从Version Tag查询到迁移验证,这些细节决定成败
Camunda流程版本管理实战精要:从精准查询到安全迁移的全链路策略 在企业级流程自动化领域,Camunda作为领先的工作流引擎,其版本管理机制直接影响着业务系统的稳定性和迭代效率。本文将深入剖析版本管理的核心痛点,提供一套覆盖全…...
)
告别明文传输!手把手教你用JS+国密SM2加密登录密码(附C#/Java后端解密代码)
国密SM2算法实战:从JS前端加密到C#/Java后端解密的完整指南 在当今数字化时代,Web应用安全已成为开发者不可忽视的重要课题。每次登录、每次数据传输都可能成为潜在的安全漏洞,特别是当敏感信息如用户密码以明文形式在网络中传输时。作为开发…...

深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透
深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透 引言 在波场(TRON)生态中,TRC-20 代币标准扮演着至关重要的角色,它不仅是承载如USDT等巨量稳定币的基石,更是连接DeFi、GameFi和NFT等…...

2026毕业季降AI工具排行榜,4款知网维普降AI软件横评
2026年毕业季过半,但还有大量同学的论文卡在AIGC检测这一关。知网在年初做了一次算法升级,维普、万方也在跟进,检测变得越来越严。论文一个字没改,去年12月查AI率18%能过,今年再查变成32%,很多同学就是栽在…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

直流接地故障查找:从原理到实践的安全操作指南
1. 项目概述:为什么直流接地查找是个“精细活儿”?在电力系统、轨道交通、数据中心以及各类工业控制场景中,直流系统是名副其实的“神经系统”。它为继电保护、自动装置、通信设备、事故照明以及控制回路提供稳定可靠的电源。你可以把它想象成…...