旅游集市数仓建设
旅游集市数仓建设
小白如何从0到1成为大数据工程师
目录
旅游集市数仓建设
1.上传数据
2.可能用到的UDF函数
3.创建所需数据库及表
1)ODS层
①ods_oidd
②ods_wcdr
③ods_ddr
④ods_dpi
2)DWD层
①dwd_res_regn_mergelocation_msk_d
②dwm_staypoint_msk_d
③dws_province_tourist_msk_d
④dws_city_tourist_msk_d
⑤dws_county_tourist_msk_d
3)DIM层
①dim_usertag_msk_m
4)ADS层
1)需求矩阵
2)根据区县游客表计算如下指标
1.上传数据
cd /usr/local/soft/mkdir ctyun/cd ctyun/pwd
2.可能用到的UDF函数
cd /usr/local/soft/mkdir jars/cd jars/pwd

添加资源并注册函数
add jars /usr/local/soft/jars/jtxy_hdfs-1.0-SNAPSHOT.jar;create temporary function get_points as 'ctyun.udf.getPointsUDF';create temporary function dateBetweenUDF as 'ctyun.udf.dateBetweenUDF';create temporary function calLength as 'ctyun.udf.calLength';create temporary function get_city_or_prov_id as 'ctyun.udf.getCityIdOrProvID';
3.创建所需数据库及表
create database ods;use ods;
1)ODS层
①ods_oidd
OIDD是采集A接口的信令数据,包括手机在发生业务时的位置信息。OIDD信令类型数据分为三大 类,呼叫记录、短信记录和用户位置更新记录。
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_oidd(mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'oidd位置数据表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/data/tour/ods/ods_oidd'; // 添加分区
alter table ods.ods_oidd add partition(day_id=20180503);// 加载数据
load data local inpath '/usr/local/soft/ctyun/ods_oidd/day_id=20180503/*' into table ods_oidd partition(day_id=20180503);//查看数据select * from ods.ods_oidd limit 10;
dfs -mkdir -p /data/tour/ods/ods_oidd;dfs -ls /data/tour/ods/ods_oidd;dfs -ls /data/tour/ods/;dfs -rmr /data/tour/ods/ods_oidd;

②ods_wcdr
WCDR采集网络中ABIS接口的数据,基于业务发生过程中三个扇区的测量信息,通过三角定位法 确定用户的位置信息。
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_wcdr (mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'wcdr位置数据表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/data/tour/ods/ods_wcdr'; // 添加分区
alter table ods.ods_wcdr add partition(day_id=20180503);// 加载数据
load data local inpath '/usr/local/soft/ctyun/ods_wcdr/day_id=20180503/*' into
table ods_wcdr partition(day_id=20180503);//查看数据select * from ods.ods_wcdr limit 10;
③ods_ddr
当前DDR中只有移动数据详单可以提取基站标识,其他语音,短信,增值等业务没有位置信息, 不做为数据融合的基础数据。
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_ddr(mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'ddr位置数据表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/data/tour/ods/ods_ddr'; // 添加分区
alter table ods.ods_ddr add partition(day_id=20180503);// 加载数据
load data local inpath '/usr/local/soft/ctyun/ods_ddr/day_id=20180503/*' into
table ods_ddr partition(day_id=20180503);// 查询数据select * from ods.ods_ddr limit 10;
④ods_dpi
移动DPI数据采集用户移动用户数据上网时移动核心网和PDSN之间接口的数据。
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_dpi(mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'dpi位置数据表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/data/tour/ods/ods_dpi'; // 添加分区
alter table ods.ods_dpi add partition(day_id=20180503);// 加载数据
load data local inpath '/usr/local/soft/ctyun/ods_dpi/day_id=20180503/*' into
table ods_dpi partition(day_id=20180503);// 查询数据select * from ods.ods_dpi limit 10;
2)DWD层
create database dwd;use dwd;
①dwd_res_regn_mergelocation_msk_d
在ODS层中,由于数据来源不同,原始位置数据被分成了好几张表加载到了我们的ODS层。 为了方便大家的使用,我们在DWD层做了一张位置数据融合表,在这里,我们将oidd、wcdr、 ddr、dpi位置数据汇聚到一张表里面,统一字段名,提升数据质量,这样就有了一张可供大家方 便使用的明细表了。
CREATE EXTERNAL TABLE IF NOT EXISTS dwd.dwd_res_regn_mergelocation_msk_d (mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment '位置数据融合表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS ORCFilelocation '/data/tour/dwd/dwd_res_regn_mergelocation_msk_d'; // 添加分区
alter table dwd.dwd_res_regn_mergelocation_msk_d add partition(day_id=20180503);手动下载数据
// hive 直接运行速度太慢,可用手动load/put文件方式
// 手动load
// 注意 上面的建表语句文件存储格式修改为了ORCFile 所以不能直接使用下面的load方法load data local inpath '/usr/local/soft/ctyun/dwd_merge/part-00000*' into
table dwd.dwd_res_regn_mergelocation_msk_d partition(day_id=20180503);// union allinsert into table dwd.dwd_res_regn_mergelocation_msk_d
partition(day_id="20180503")select mdn ,start_time ,county_id ,longi ,lati ,bsid ,grid_id ,biz_type ,event_type ,data_source
from ods.ods_oiddwhere day_id = "20180503"union allselect mdn ,start_time ,county_id ,longi ,lati ,bsid ,grid_id ,biz_type ,event_type ,data_source
from ods.ods_wcdrwhere day_id = "20180503"union allselect mdn ,start_time ,county_id ,longi ,lati ,bsid ,grid_id ,biz_type ,event_type ,data_source
from ods.ods_dpiwhere day_id = "20180503"union allselect mdn ,start_time ,county_id ,longi ,lati ,bsid ,grid_id
,biz_type
,event_type
,data_source
from ods.ods_ddrwhere day_id = "20180503";

②dwm_staypoint_msk_d
计算一个人在一个网格内的停留时间,按手机号,网格id,区县id分组
1、对所有时间进行排序
2、取第一个点的开始时间和最后一个点的结束时间
create database dwm;use dwm;CREATE EXTERNAL TABLE IF NOT EXISTS dwm.dwm_staypoint_msk_d (mdn string comment '用户手机号码'
,longi string comment '网格中心点经度'
,lati string comment '网格中心点纬度'
,grid_id string comment '停留点所在电信内部网格号'
,county_id string comment '停留点区县'
,duration string comment '机主在停留点停留的时间长度(分钟),lTime-eTime'
,grid_first_time string comment '网格第一个记录位置点时间(秒级)'
,grid_last_time string comment '网格最后一个记录位置点时间(秒级)'
)
comment '停留点表'PARTITIONED BY (day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILElocation '/data/tour/dwm/dwm_staypoint_msk_d'; 通过grid_id 网格id 获取 网格中心点经纬度 longi、lati
该SQL执行会出现问题: 执行流程一直处于 0% Map 0% reduce
/**
insert into table dwm.dwm_staypoint_msk_d partition(day_id=20180503)
select t1.mdn,get_points(grid_id)[0] as longi,get_points(grid_id)[1] as lati,t1.grid_id,t1.county_id,dateBetweenUDF(t1.grid_first_time,t1.grid_last_time) as duration,t1.grid_first_time,t1.grid_last_time
from (select mdn,grid_id,county_id,min(split(start_time,',')[0]) as grid_first_time,max(split(start_time,',')[1]) as grid_last_timefrom dwd.dwd_res_regn_mergelocation_msk_dwhere day_id="20180503"group by mdn, grid_id, county_id
)t1;
*/优化后的SQL:WITH split_table as (
SELECT
mdn
,grid_id
,county_id
,split(start_time,',')[1] as grid_first_time
,split(start_time,',')[0] as grid_last_time
FROM dwd.dwd_res_regn_mergelocation_msk_d
where day_id="20180503"
)
, max_min_table as (
SELECT
mdn
,grid_id
,county_id
,Max(grid_first_time) OVER(PARTITION BY mdn,grid_id,county_id) as grid_first_time
,MIN(grid_last_time) OVER(PARTITION BY mdn,grid_id,county_id) as grid_last_time
FROM split_table
)insert into table dwm.dwm_staypoint_msk_d partition(day_id=20180503)
SELECT
t1.mdn
,get_points(t1.grid_id)[0] as longi
,get_points(t1.grid_id)[1] as lati
,t1.grid_id
,t1.county_id
,dateBetweenUDF(t1.grid_first_time,t1.grid_last_time) as duration
,t1.grid_first_time
,t1.grid_last_time
FROM (
SELECT
mdn
,grid_id
,county_id
,grid_first_time
,grid_last_time
FROM max_min_table
group by
mdn
,grid_id
,county_id
,grid_first_time
,grid_last_time
) t1

③dws_province_tourist_msk_d
游客定义 出行距离大于300km 常住地在用户画像表中 在省内停留时间大于3个小时
create database dws;use dws;
CREATE EXTERNAL TABLE IF NOT EXISTS dws.dws_province_tourist_msk_d (mdn string comment '手机号大写MD5加密'
,source_county_id string comment '游客来源区县'
,d_province_id string comment '旅游目的地省代码'
,d_stay_time double comment '游客在该省停留的时间长度(小时)'
,d_max_distance double comment '游客本次出游距离'
)
comment '旅游应用专题数据省级别-天'PARTITIONED BY (day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUETlocation '/data/tour/dws/dws_province_tourist_msk_d';停留点表dwm_staypoint_msk_d与用户画像维表dim_usertag_msk_m 通过mdn关联,使用 get_city_or_prov_id(county_id,"province")方法,传入county_id,返回province_id,然后按 mdn、province_id、resi_county_id分组,使用calLength(grid_id, resi_grid_id) 传入网格id、居 住地网格id,算出出行距离,并计算每个用户到每个省的累计出行时间,然后取出 累计时间最大 值超过3小时(180分钟),出行距离大于300km的用户
④dws_city_tourist_msk_d
出行距离大于100km 在市内停留时间大于3个小时
CREATE EXTERNAL TABLE IF NOT EXISTS dws.dws_city_tourist_msk_d (mdn string comment '手机号大写MD5加密'
,source_county_id string comment '游客来源区县'
,d_city_id string comment '旅游目的地市代码'
,d_stay_time double comment '游客在该省市停留的时间长度(小时)'
,d_max_distance double comment '游客本次出游距离'
)
comment '旅游应用专题数据城市级别-天'PARTITIONED BY (day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUETlocation '/data/tour/dws/dws_city_tourist_msk_d';停留点表dwm_staypoint_msk_d与用户画像维表dim_usertag_msk_m 通过mdn关联,使用 get_city_or_prov_id(county_id,"city")方法,传入county_id,返回city_id,然后按mdn、city_id、 resi_county_id分组,使用calLength(grid_id, resi_grid_id) 传入网格id、居住地网格id,算出出行 距离,并计算每个用户到每个市的累计出行时间,然后取出 累计时间最大值超过3小时(180分 钟),出行距离大于100km的用户
⑤dws_county_tourist_msk_d
出行距离大于10km 在县内停留时间大于3个小时
CREATE EXTERNAL TABLE IF NOT EXISTS dws.dws_county_tourist_msk_d (mdn string comment '手机号大写MD5加密' ,source_county_id string comment '游客来源区县' ,d_county_id string comment '旅游目的地县代码' ,d_stay_time double comment '游客在该县停留的时间长度(小时)' ,d_max_distance double comment '游客本次出游距离'
)
comment '旅游应用专题数据县级别-天'PARTITIONED BY (day_id string comment '日分区'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUETlocation '/data/tour/dws/dws_county_tourist_msk_d';停留点表dwm_staypoint_msk_d与用户画像维表dim_usertag_msk_m 通过mdn关联,按mdn、 county_id、resi_county_id分组,使用calLength(grid_id, resi_grid_id) 传入网格id、居住地id, 算出出行距离,并计算每个用户到每个县的累计出行时间,然后取出 累计时间最大值超过3小时 (180分钟),出行距离大于10km的用户
运行SQL时报错 我们要创建一下UDF函数

add jars /usr/local/soft/jars/jtxy_hdfs-1.0-SNAPSHOT.jar;create temporary function get_points as 'ctyun.udf.getPointsUDF';create temporary function dateBetweenUDF as 'ctyun.udf.dateBetweenUDF';create temporary function calLength as 'ctyun.udf.calLength';create temporary function get_city_or_prov_id as 'ctyun.udf.getCityIdOrProvID';insert into table dws.dws_county_tourist_msk_d partition(day_id="20180503")select ttt1.mdn,ttt1.source_county_id,ttt1.d_county_id,ttt1.d_stay_time,ttt1.d_max_distancefrom(select mdn,resi_county_id as source_county_id,county_id as d_county_id,sum(duration) as d_stay_time,max(calLength(tt1.grid_id,tt1.resi_grid_id)) as d_max_distancefrom(select t1.mdn,t1.grid_id,t1.county_id,t1.duration,t2.resi_county_id,t2.resi_grid_idfrom (select *from dwm.dwm_staypoint_msk_d
where day_id='20180503') t1 join(select *from dim.dim_usertag_msk_mwhere month_id='201805') t2 on t1.mdn = t2.mdn) tt1 group by tt1.mdn,tt1.county_id,tt1.resi_county_id)ttt1 where d_stay_time > 180 and d_max_distance > 10000;3)DIM层
create database dim;use dim;
①dim_usertag_msk_m
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_usertag_msk_m (mdn string comment '手机号大写MD5加密'
,name string comment '姓名'
,gender string comment '性别,1男2女'
,age string comment '年龄'
,id_number string comment '证件号码'
,number_attr string comment '号码归属地'
,trmnl_brand string comment '终端品牌'
,trmnl_price string comment '终端价格',packg string comment '套餐'
,conpot string comment '消费潜力'
,resi_grid_id string comment '常住地网格'
,resi_county_id string comment '常住地区县'
)
comment '用户画像表'PARTITIONED BY (month_id string comment '月分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUETlocation '/data/tour/dim/dim_usertag_msk_m'; // 添加分区
alter table dim.dim_usertag_msk_m add partition(month_id=201805);// 加载数据
load data local inpath
'/usr/local/soft/ctyun/dim_usertag_msk_m/month_id=201805/*' into table
dim.dim_usertag_msk_m partition(month_id=201805);// 查询数据select * from dim_usertag_msk_m limit 10;
4)ADS层
根据需求建设
1)需求矩阵


2)根据区县游客表计算如下指标
客流量按天 [区县id,客流量]
select t1.d_county_id,count(*) as d_county_cnt
from (select d_county_idfrom dws.dws_county_tourist_msk_dwhere t1.day_id="20180503"
) t1 group by t1.d_county_id;性别按天 [区县id,性别,客流量]
select t1.d_county_id,t2.gender,count(*) as d_county_gender_cnt
from(select mdn,d_county_idfrom dws.dws_county_tourist_msk_dwhere day_id="20180503"
) t1 left join (select mdn,genderfrom dim.dim_usertag_msk_mwhere month_id=20180503
) t2 on t1.mdn = t2.mdn
group by t1.d_county_id,t2.gender;年龄按天 [区县id,年龄,客流量]
常住地按天 [区县id,常住地市,客流量]
归属地按天 [区县id,归属地市,客流量]
select t1.d_county_id,t2.number_attr,count(*) as d_county_number_attr_cnt
from(select mdn,d_county_idfrom dws.dws_county_tourist_msk_dwhere day_id="20180503"
) t1 left join (select mdn,number_attrfrom dim.dim_usertag_msk_mwhere month_id=20180503
) t2 on t1.mdn = t2.mdn
group by t1.d_county_id,t2.number_attr;终端型号按天 [区县id,终端型号,客流量]
消费等级按天 [区县id,消费等级,客流量]
停留时长按天 [区县id,停留时长,客流量]
相关文章:
旅游集市数仓建设
旅游集市数仓建设 小白如何从0到1成为大数据工程师 目录 旅游集市数仓建设 1.上传数据 2.可能用到的UDF函数 3.创建所需数据库及表 1)ODS层 ①ods_oidd ②ods_wcdr ③ods_ddr ④ods_dpi 2)DWD层 ①dwd_res_regn_mergelocation_msk_d ②dwm_s…...

vue实现点击高亮效果
<view class"tabs"><textv-for"(item, index) in subTypes":key"item.id"class"text":class"{ active: index activeIndex }"//动态绑定高亮类:判断下标是否等于当前下标tap"activeIndex index&…...
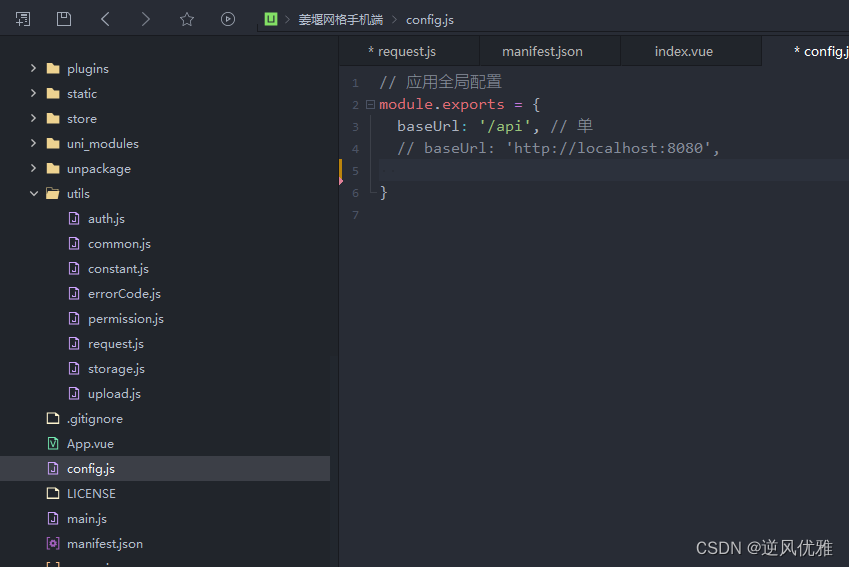
uniapp 配置请求代理+请求封装
uniapp官网提供了三种方式:什么是跨域 | uni-app官网 1. 通过uniapp自带浏览器 打开项目是不存在跨域的 第二种方式: "h5" : {"template" : "static/index.html","devServer": {"proxy": {&quo…...

代码随想录算法训练营第二十八天|216.组合总和III、17.电话号码的字母组合
216.组合总和III 文档讲解:代码随想录 题目链接:. - 力扣(LeetCode) 这一题与昨天的组合差不多,区别就在只有和是目标值的时候才会加入到result数组中,并且在回溯时,会处理sum的值 class Solution:def __i…...
大模型prompt实例:知识库信息质量校验模块
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模…...

正则表达式和lambda表达式
正则表达式(Regular Expressions)和Lambda表达式虽然都包含“表达式”一词,但它们在编程中的作用和用法是完全不同的。让我们详细比较一下它们的定义、用途和应用场景: 正则表达式 定义:正则表达式是一种用于匹配文本…...
pyenv 之 python 多版本管理(win11)
1. 背景 常常会用到Python的多个版本,因此可以使用Pyenv来对Python版本进行管理。 2. win11下载 pyenv 在终端执行下载语句: pip install pyenv-win --target D:\software\pyenv 其中 D:\software\pyenv 为你想要下载到的文件目录,建议在 …...

nodemon运行ts文件
https://juejin.cn/post/7035637086451400734 nodemon经常用来调试js文件,大家都是知道的,但是用nodemon来调试ts文件,大家试过吗? 如果直接运行nodemon index.ts是会报错的。 ts 复制代码 //index.ts console.log(1) 需要全局…...

内网渗透瑞士军刀-impacket工具解析(二)
impacket工具解析之Kerberos认证协议 上一期我们介绍了impacket中ntlm协议的实现,在Windows认证中除了使用ntlm认证,还支持Kerberos认证协议,Kerberos认证也是Windows 活动目录中占比最高的认证方式。 什么是Kerberos协议? Kerb…...

huggingface 笔记:pipeline
1 介绍 pipeline() 是使用预训练模型进行推理的最简单和最快速的方式。可以针对不同模态的许多任务直接使用 pipeline() 2 举例:情感分析 2.1 创建pipeline实例 from transformers import pipelineclassifier pipeline("sentiment-analysis") #首先创…...
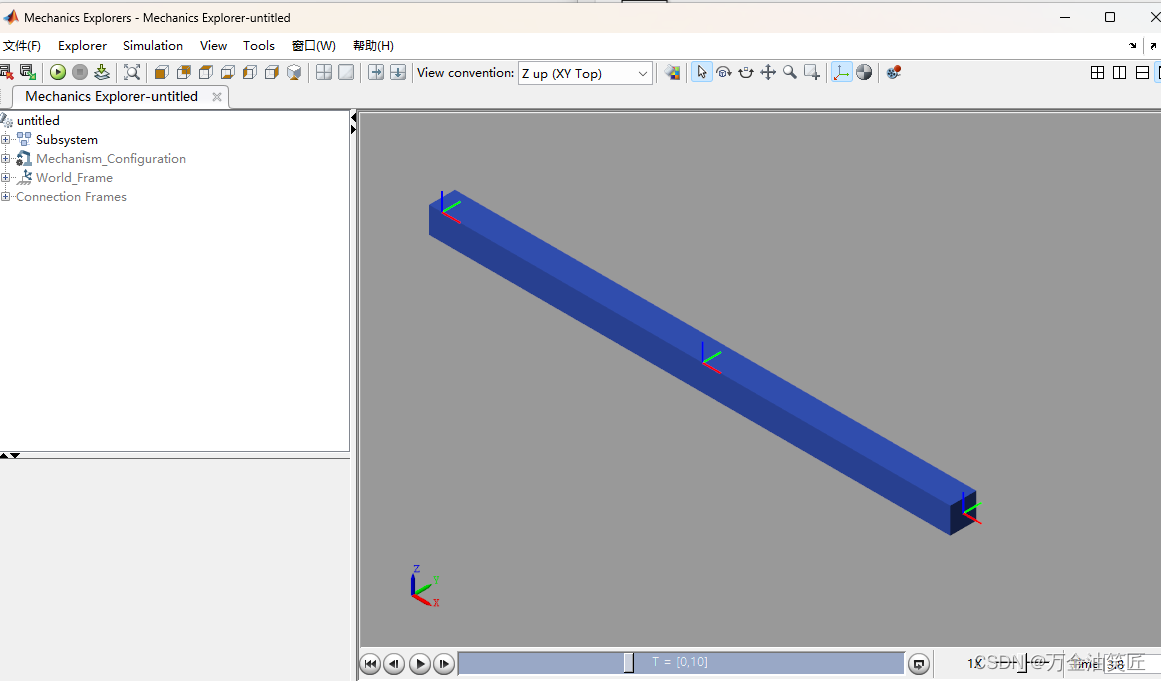
玩转Matlab-Simscape(初级)-01-从一个简单模型开始学习之旅
** 玩转Matlab-Simscape(初级)- 01 - 从一个简单模型开始学习之旅 ** 目录 玩转Matlab-Simscape(初级)- 01 - 从一个简单模型开始学习之旅 前言一、从模板开始建模二、建模一个简单的连杆2.1 建模2.2 生成子系统 总结 前言 在产…...
电脑录屏软件有哪些?这3款神器必须要知道
在当今现代社会,电脑录屏软件已经成为人们日常生活中不可或缺的一部分。无论是录制游戏精彩瞬间、制作教程、还是在线会议记录,一款好用的电脑录屏软件都能帮助我们更高效地完成任务。可是电脑录屏软件有哪些呢?接下来,我们将介绍…...
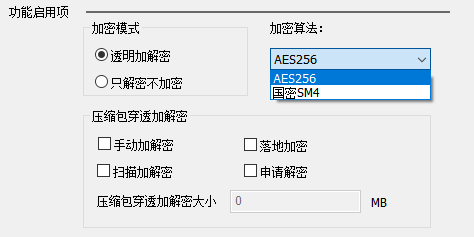
如何在华企盾DSC防泄密系统中设置文件自动加密?
在华企盾DSC系统中设置文件自动加密的过程,简单且用户友好,确保了企业数据的安全,同时不干扰日常工作流程。以下是设置文件自动加密的步骤: 系统安装与配置:确保华企盾DSC数据防泄密系统已经在企业的网络中正确安装和配…...

【DevOps】Dockerfile详解,做自己的docker镜像
学会使用DockerHub找自己想要的镜像以后,我们会很方便的使用一些公用镜像仓库的Docker镜像。但是开发和部署的过程中,能找到的镜像可能并不能满足我们需要,这样我们就需要自己制作Docker镜像。我们通过需要编写一个 Dockerfile,然…...
CSRF 攻击实验:Token 不存在绕过验证
前言 CSRF(Cross-Site Request Forgery),也称为XSRF,是一种安全漏洞,攻击者通过欺骗用户在受信任网站上执行非自愿的操作,以实现未经授权的请求。 CSRF攻击利用了网站对用户提交的请求缺乏充分验证和防范…...

c#教程——索引器
前言: 索引器(Indexer)可以像操作数组一样来访问对象的元素。它允许你使用索引来访问对象中的元素,就像使用数组索引一样。在C#中,索引器的定义方式类似于属性,但具有类似数组的访问方式。 索引器&#x…...
)
麒麟服务器上执行可执行脚本报错:bash: ./xx: Permission denied(完整版)
前情提要 本来都好好的,我重启了服务器以后就开始报这个错了,而我的麒麟服务器目前是这个情况: 已经在服务器上配置好了 ssh 免密登录,在命令行里执行 ssh -o StrictHostKeyCheckingno -p 22 usernamexxx.xxx.xxx.xxx 可以正常登…...

前端起dev从110秒减少到7秒, 开发体验大幅提升
[webpack由浅入深]系列的内容 第一层: 了解一个小功能的完整流程. 看完可以满足好奇心和应付原理级别面试.第二层: 源码陪读, webpack源码比较灵活, 自己看容易陷入迷惑. 文章里会贴出关键流程的代码来辅助阅读源码. 如果你正在自己调试, 在这些方法上下断点会节约你宝贵的时间…...

Flink CDC 原理
简介 Flink CDC(Change Data Capture)是 Apache Flink 提供的一个变更数据捕获工具集。它可以监控数据库的变更,并将这些变更实时地以流的形式提供给下游系统,这些变更包括插入、更新和删除操作。 Flink CDC 适用于需要实时数据…...

AI建站工具怎么选?5大维度对比与选型指南
AI建站工具怎么选?5大维度对比与选型指南面对市面上层出不穷的建站工具,很多自媒体人和创业者都犯了难:“都说自己简单、好用,到底哪个更适合我?”“不会代码的我,应该用哪种工具才能少走弯路?”…...

OpenClaw部署工具包:一键自动化安装与ROS集成指南
1. 项目概述:一个为“OpenClaw”项目量身定制的部署工具包如果你在开源社区里混迹过一段时间,特别是对机器人、机械臂或者自动化控制项目感兴趣,那么你很可能听说过“OpenClaw”这个名字。它通常指代一个开源的、模块化的机械爪或夹持器项目&…...

PZEM-004T v3.0电力监测库:构建工业级能源数据基础设施的战略选择
PZEM-004T v3.0电力监测库:构建工业级能源数据基础设施的战略选择 【免费下载链接】PZEM-004T-v30 Arduino library for the Updated PZEM-004T v3.0 Power and Energy meter 项目地址: https://gitcode.com/gh_mirrors/pz/PZEM-004T-v30 在数字化转型浪潮中…...

TIDAL无损音乐下载神器:tidal-dl-ng让你的音乐收藏永久化
TIDAL无损音乐下载神器:tidal-dl-ng让你的音乐收藏永久化 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 你是否曾为流媒体音乐…...

MAA明日方舟助手:10分钟解放双手,开启全自动游戏体验
MAA明日方舟助手:10分钟解放双手,开启全自动游戏体验 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...
)
用STM32F103C8T6的GPIO模拟I2C,驱动AD5593R DAC模块输出多路电压(附完整代码)
基于STM32F103C8T6的GPIO模拟I2C驱动AD5593R实现精密电压输出 在嵌入式开发中,I2C总线因其简洁的两线制设计而广受欢迎,但硬件I2C外设资源有限的情况时有发生。当手头只有STM32F103C8T6这类基础型号的最小系统板时,GPIO模拟I2C协议成为突破硬…...

老漏洞新谈:CVE-2010-0738的HEAD请求绕过与JBoss JMX Console的权限之殇
CVE-2010-0738:HEAD请求的艺术与JMX Console的防御盲区 十年前那个春寒料峭的三月,当安全研究员在JBoss JMX控制台前反复切换HTTP请求方法时,一个看似平常的HEAD请求意外触发了系统响应。这个后来被编号为CVE-2010-0738的漏洞,不…...

为OpenClaw构建现代化Web控制台:从架构设计到移动端访问
1. 项目概述:为OpenClaw打造一个现代化的本地Web控制台如果你和我一样,是个喜欢折腾本地AI和自动化工具的人,那你肯定对OpenClaw不陌生。它是一个功能强大的个人助理框架,能帮你处理文件、连接各种服务、甚至通过浏览器自动化来完…...

ASMR资源管理新范式:asmroner如何重新定义音频内容获取体验
ASMR资源管理新范式:asmroner如何重新定义音频内容获取体验 【免费下载链接】asmr-downloader A tool for download asmr media from asmr.one(Thanks for the asmr.one) 项目地址: https://gitcode.com/gh_mirrors/as/asmr-downloader 你是否曾为寻找高质量…...

Silk v3解码器:3步搞定微信QQ音频格式转换的终极指南 [特殊字符]
Silk v3解码器:3步搞定微信QQ音频格式转换的终极指南 🎵 【免费下载链接】silk-v3-decoder [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to other format (like mp3). Batch conversion …...