前端起dev从110秒减少到7秒, 开发体验大幅提升
[webpack由浅入深]系列的内容
- 第一层: 了解一个小功能的完整流程. 看完可以满足好奇心和应付原理级别面试.
- 第二层: 源码陪读, webpack源码比较灵活, 自己看容易陷入迷惑. 文章里会贴出关键流程的代码来辅助阅读源码. 如果你正在自己调试, 在这些方法上下断点会节约你宝贵的时间.
webpack cache 发布3年多了, 在历史包袱中的项目中其实非常好用.
本文会介绍 cache 在一个项目中的实践经验, 和实现流程, 以及了解流程后的一些推论.
webpack cache 实践经验
我的实践经验是基于公司的一个 monorepo 老项目.
效果是单个子项目的dev速度从110秒减少到了7秒, 单个文件改动10秒.
下面说的经验也都是基于这个例子.
合适的使用场景
webpack cache 的效果是用磁盘空间换 compile 速度.
所以在我看来, webpack cache 更合适在本地 dev 的场景使用, 因为本地 dev 触发 compile 比 ci 服务器频繁得多, 并且改动更小, 可以命中更多缓存, 也能大幅提升开发体验.
实践
在实践中, 缓存的命中率没什么可操作性. 优化空间都在减少占用磁盘空间上. 在我的项目中, 我做了以下配置:
- 如果配置 cache 的文件是读取配置文件的, 要将
buildDependencies配置为你的文件, 而不是__filename. 在我们公司打包脚本中是一个 webpack-chain 文件. - monorepo 子包会有一些公共依赖, 在 module resolve 的时候也会指到主包的 node_modules, 在这种情况下 cache 配置的
cacheDirectory可以让多个子包指到同一个文件夹, 来节省cache空间. (在 dev 的时候 react-refresh 会产生大几百m的缓存, 是起码可以节省的) - 合理设置
maxAge, 超过maxAge的未被使用的缓存会被清除.
我的看法是生产设置小, dev看自己电脑空间, 如果足够的话可以不设置. (默认一个月)
webpack cache 实现流程
下面会深入一下 cache 的实现流程, 了解流程除了满足好奇心, 还可以:
-
根据特殊场景优化配置.
-
了解什么边缘情况会造成缓存占用磁盘大.
-
根据自己需求二开 cache.
webpack cache 的实现流程职能分层非常清晰, 并且只有一个分层比较复杂, 其他都很简单.
我们从 compile 时调用 cache 说起.
在 compile 流程中读取与保存 cache
webpack流程相关的前置知识如果不清楚, 需要先看以往的文章来补一下, 再继续回这里.
在compilation里有三个变量: _modulesCache, _assetsCache, _codeGenerationCache. 分别在对应的时间点读取和写入 cache:
-
_modulesCache 读取: 在 addModule 的时候读取. module 的 build 在读取之后, 如果命中 cache, 那么
needBuild就会是false, 跳过这个 module 的 build, 来节省时间. (build 做的事是运行 loader 和 parse 并分析 ast ) -
_modulesCache 写入: 在 module 的 build 完成之后, 把 build 后的 module 结果按照 module 的 id 存储起来.
-
_codeGenerationCache: 读取和写入分别在
module.codeGeneration()的前后. -
_assetsCache: 在最终生成 assets 的阶段, 在获取 manifest 以后读取 cache, 如果命中, 则不逐个调用
fileManifest.render()来产生 assets 了. 如果不命中, 则调用 render 后写入 cache.
(这里调用的时候加了层包装是因为这里的 cache 都要匹配 hash )
这些 cache 的来源和相关的调用时机
在代码中可以看到, 这些 cache 都是调用 compiler.getCache() 获得的, 也就是 compiler.cache()封装了一层 facade.
而this.cache就是new Cache(). 所以上面章节的 cache, 都是 new Cache()实例的调用.
另外可以看到, this.cache在 compiler 中, 还在对应的流程中调用了 beginIdle, endIdle, shutdown, 和storeBuildDependencies.
buildDependency 不影响功能先不看, 其他的调用之后展开.
通过 option 指向不同的 cache 实现
进入到Cache类里, 发现所有方法的时间都是调用了 tapable.
cache 的具体实现, 是在 apply option 的时候注入的. (文件是 WebpackOptionsApply, 方法是 process )
在这里可以看到, case 很少, 只有2个.
第一个是使用内存, 第二个是使用文件系统写入硬盘.
内存使用里的MemoryCachePlugin非常简单:
在内存里建立一个
map, 分别在外部调用get(), 和store()方法的时候调用对应的map的方法.
另外在
shutdown的时候把map清了.
对, 就是这么简单. 其实文件系统也这么简单, 复杂的点是读取和写入硬盘.
写入文件的 cache 实现: IdleFileCachePlugin
现在我们来看写入硬盘的实现: IdleFileCachePlugin.
先看get和store方法, 其实就是调用了strategy.store和strategy.restore. 只是多写几行代码来保证所有的写操作都做完再读.
除此之外, 还在 beginIdle 和 shutdown 的时候调用了strategy.afterAllStored来持久化 cache.
PackFileCacheStrategy 主要功能
进入到strategy, 我们关注store, restore, 和afterAllStored方法.
先看store, 和restore方法, 通过_getPack()获取到从硬盘读取的结构化数据pack, 分别调用pack的get()方法和set()方法.
afterAllStored的作用是把数据持久化到硬盘. 第一步也是获取内存里的pack数据, 再经过一定处理来写到硬盘中.
经过观察可以看到, _openPack()的读取硬盘, 和afterAllStored()的写入文件, 都是通过fileSerializer()来进行的.
cache 在内存, 与文件系统的最大区别, 其实就在于持久化的过程, 对于 cache 的读取和写入都是差不多的.
而下面要说的fileSerializer做的事, 就把内存中的格式化数据向硬盘读写, 并且尽量优化减少写入的体积.
整理数据与写入和读取文件的 Serializer
这一节是最复杂的, 主要研究对象是fileSerializer的2个方法serialize()和deserialize().
并且优化逻辑是和上面提到的pack和相关实体的数据结构紧密相关的.
首先看fileSerializer以 middleware 的形式来分代码职责, 执行fileSerializer的serialize()或deserialize()的时候, 会轮流执行各个 middleware 的对应的serialize()或deserialize()方法.
构造时候的 middleware 有:
- SingleItemMiddleware: 转化数组/单个元素的, 我感觉就没啥用, 没体会到意义.
- ObjectMiddleware: 在序列化的时候, 调用目标数据自己的函数, 进行数据整理.
- binaryMiddleware: 序列化/反序列化成二进制.
- fileMiddleware: 读取/写入硬盘.
下面展开讲一下我关注的ObjectMiddleware.
ObjectMiddleware与pack的读取/写入优化
先来看ObjectMiddleware的serialize()和deserialize()方法.
他们的模式其实是一样的: 构造一个上下文ctx来给序列化/反序列化的数据对应的方法调用.
其实 s/ds 的直接目标都是PackContainer对象, 所以会在 s/ds 的过程中调用PackContainer的 s/ds 方法.
ctx中提供的write, read方法可以操作正在被ObjectMiddleware处理的数据, 从而影响ObjectMiddleware的处理结果.
另外可以看到PackContainer的writeLazy的目标是this.data, 也就是pack对象, 并且write()会触发pack对象的 s/ds 方法.
经过debug, PackContainer里的内容其实是差不多的, 所以核心内容就是pack的 s/ds 方法了.
pack 的数据结构与优化
这是最后一部分, 但比较复杂, 我只有能力简单的说一下.
首先说几个 pack 的关键属性:
- content: 他是真正存放内容的地方. 但奇怪的他不是一个 map, 而是一个数组.
用意是数组的每个元素最后会被写成单独的文件, 通过一些优化, 每次改动可以只写有改动的 cache 所对应的文件
- itemInfo: 这个是保存数据关系的地方.
他的键是 id, pack 的 get(), set() 的第一步都是先从itemInfo中通过 id 找到对应的信息.
他的值是对应的信息, 信息内容有: etag 对比 hash; location 存储信息在 content 数组的哪个位置; lastAccess 每次 get 会更新值, 在垃圾回收的时候配合 maxAge 决定是否清理; freshValue 如果不存储在 content 中, 他是一个刚被建立的内容, 值就存在这里, 相对的, location 有值的时候这里是没值的.
- invalid: 如果
pack完全没动, 这个变量可以快速判断. 第一次set()操作就会把他置为 true.
如果熟悉了这些属性, 那么pack的set()和get()方法就非常好理解了.
最后, pack在serialize()的方法中进行了垃圾回收的操作,
就结果而言, 就是合理地对pack的数据结构进行一些更新. (主要就是 content 和 itemInfo, lazy, outdated 判断和变更)
但其过程在我能力范围之外, 以后能力有提升的话再回来分析.
相关文章:

前端起dev从110秒减少到7秒, 开发体验大幅提升
[webpack由浅入深]系列的内容 第一层: 了解一个小功能的完整流程. 看完可以满足好奇心和应付原理级别面试.第二层: 源码陪读, webpack源码比较灵活, 自己看容易陷入迷惑. 文章里会贴出关键流程的代码来辅助阅读源码. 如果你正在自己调试, 在这些方法上下断点会节约你宝贵的时间…...

Flink CDC 原理
简介 Flink CDC(Change Data Capture)是 Apache Flink 提供的一个变更数据捕获工具集。它可以监控数据库的变更,并将这些变更实时地以流的形式提供给下游系统,这些变更包括插入、更新和删除操作。 Flink CDC 适用于需要实时数据…...

Axure网上超市用户端APP原型 (O2O生鲜电商/买菜到家/数字零售/京东到家/抖音超市领域)
作品概况 页面数量:共 100 页 源文件格式:rp格式,兼容 Axure RP 9/10,非程序软件无源代码 适用领域:O2O生鲜电商、网上超市、买菜到家、数字零售 作品特色 本作品为网上超市用户消费端Axure交互原型,属于…...

外包公司中能学到技术的都是那些人?
在外包公司能够有效学习并提升技术的人,通常具备以下特点和行为模式: 自我驱动力强:这类人有强烈的学习欲望和提升自我的动机,不依赖公司安排的培训,而是主动寻找学习资源,如在线课程、技术书籍、开源项目等…...
JavaEE初阶-多线程进阶2
文章目录 前言一、CAS1.1 CAS的概念1.2 原子类1.3 CAS的ABA问题 二、JUC中常用类2.1 Callable接口2.2 ReentrantLock(可重入)2.3 Semaphore信号量2.4 CountDownLatch类2.5 CopyOnWriteArrayList类2.6 ConcurrentHashMap 前言 对于多线程进阶的部分&…...

B/S和C/S框架
一、B/S框架 B/S框架是指Browser/Server框架,即基于浏览器和服务器的应用程序开发框架。在B/S架构中,用户通过浏览器(Browser)访问服务器(Server)上的应用程序或网站,而无需在用户端安装额外的客…...
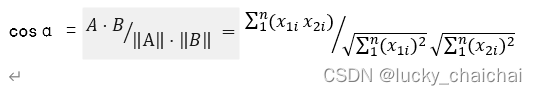
机器学习中常用的几种距离——欧式、余弦等
目录 一、欧式距离(L2距离)二、曼哈顿距离(L1距离)三、汉明距离四、余弦相似度 一、欧式距离(L2距离) (1)二维空间的距离公式(三维空间的在这个基础上类推)&…...

2024 Google I/O Android 相关内容汇总
2024 Google I/O Android 相关内容汇总 本次 Google I/O 的核心虽然是 AI ,但是 Android 也是作为主要议题出现, Android 部分可以简单分为产品和开发相关内容,接下来主要介绍这两部分的相关更新。 重点开始开发相关,内容不少 产…...
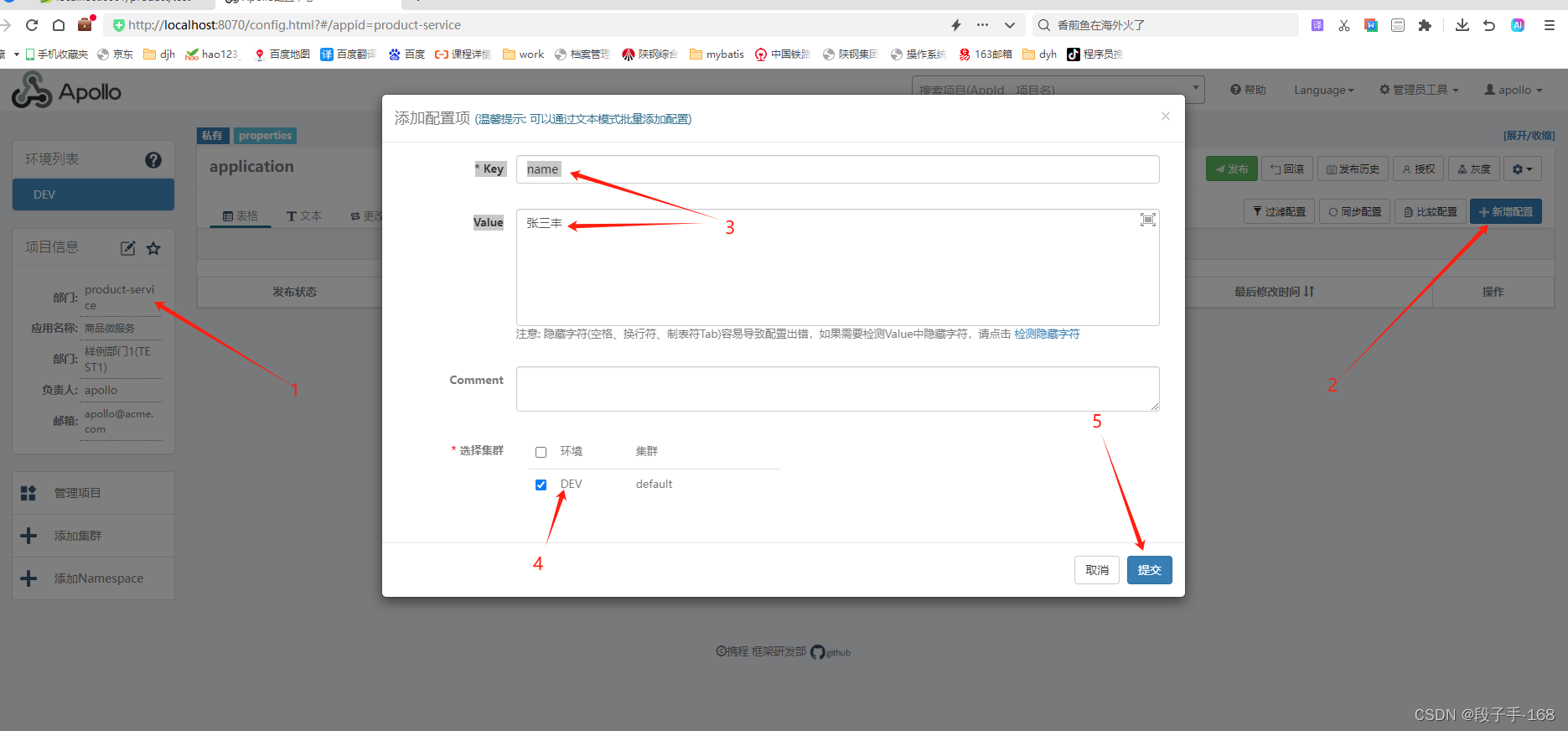
# 从浅入深 学习 SpringCloud 微服务架构(十八)
从浅入深 学习 SpringCloud 微服务架构(十八) 一、开源配置中心 Apollo:概述 1、开源配置中心 Apollo Apollo -A reliable configuration management system Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理…...

在SQL Server中使用临时表与普通表的性能差异分析
在SQL Server中,临时表和普通表的性能确实存在差异,具体表现和影响因素如下: 临时表和普通表的区别 存储位置: 临时表:存储在tempdb数据库中,生命周期仅限于当前会话或批处理。当会话结束或批处理完成时&a…...
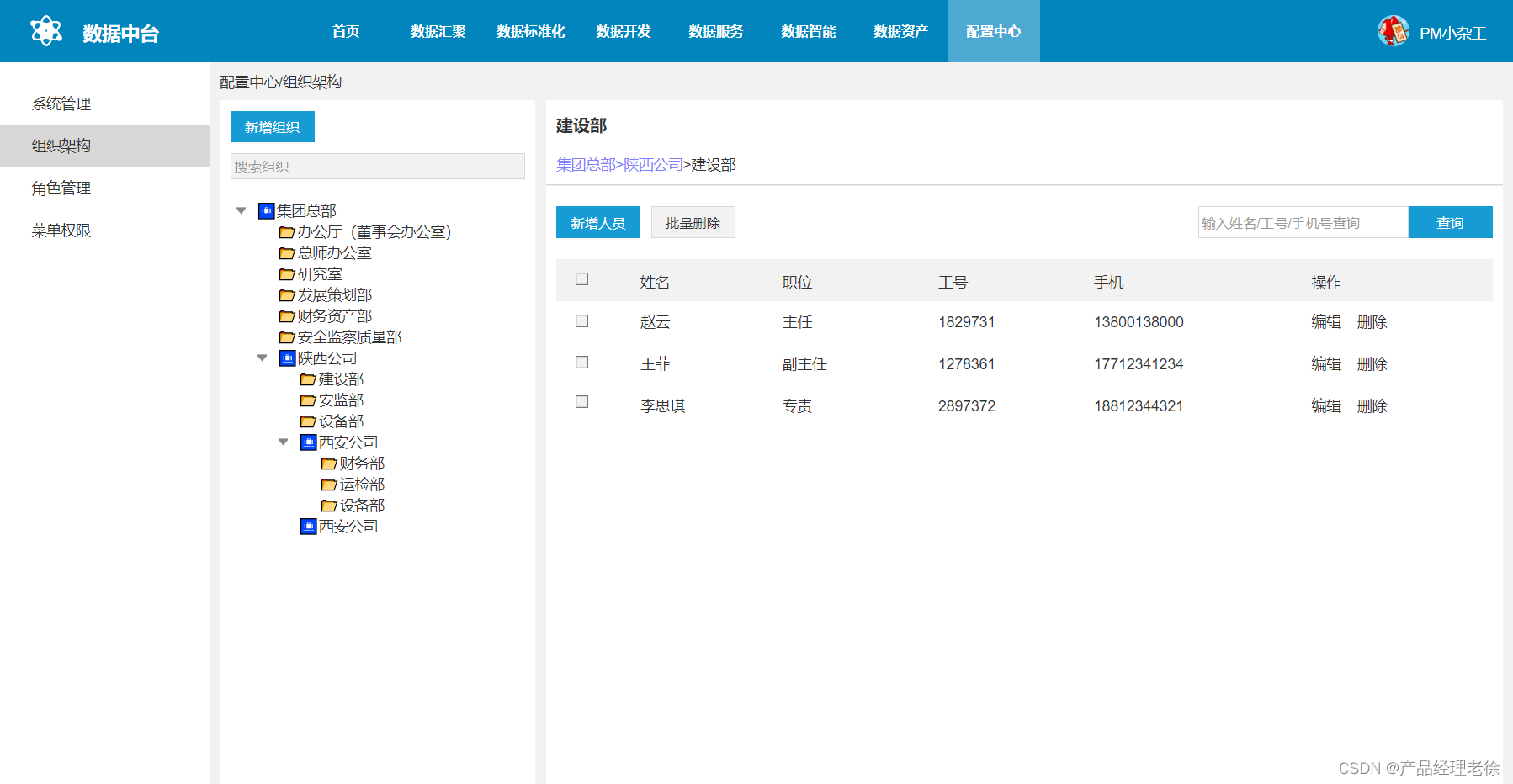
数据中台管理系统原型
数据中台是一个通用性的基础平台,适用于各类行业场景,数据中台包含多元数据汇聚、数据标准化、数据开发、数据共享、数据智能、数据资产管理等功能,助力企业数字化转型。 数据汇聚 数据汇聚是将不同系统、不同类型的多元源数据汇聚至目标数据…...

数据库练习
在数据库中创建一个表student,用于存储学生信息 CREATE TABLE student( id INT PRIMARY KEY, name VARCHAR(20) NOT NULL, grade FLOAT ); 1、向student表中添加一条新记录(记录中id字段的值为1,name字段的值为"monkey",…...
Rust学习笔记(上)
前言 笔记的内容主要参考与《Rust 程序设计语言》,一些也参考了《通过例子学 Rust》和《Rust语言圣经》。 Rust学习笔记分为上中下,其它两个地址在Rust学习笔记(中)和Rust学习笔记(下)。 编译与运行 Ru…...

【SRC实战】文件名回显导致反射型XSS,URL重定向
挖个洞先 https://mp.weixin.qq.com/s/hnrm-snkETuR-gqPOSnQXQ “ 以下漏洞均为实验靶场,如有雷同,纯属巧合 ” 01 — 漏洞证明 一、反射型XSS “ 文件名回显,能否触发XSS?” 1、灯塔扫到敏感文件,发现1.txt会在…...

mysql高版本导入低版本Unknown collation: utf8mb4_0900_ai_ci
MySQL数据库导入SQL报错 Unknown collation: ‘utf8mb4_0900_ai_ci‘ 错误原因:我本地的MySQL数据包版本为8.0的,而服务器上的MySQL版本为5.7,双方的版本不兼容,这样就导致我在本地写好的SQL无法在服务器上的MySQL上运行。 解决办…...

运筹说 第114期 | 其他排队模型简介
前面我们已经学习了一些排队模型,对排队系统有了基本认知,本期小编带大家继续来学习其他排队模型的内容。 一、有限源排队模型 顾客源为有限的这类排队问题的主要特征是顾客总数是有限的,如只有m个顾客。每个顾客来到系统中接受服务后仍回到…...

易基因: WGBS等揭示梨驯化和改良过程中DNA甲基化对果实成熟的作用机制 | 作物育种
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 梨(Pyrus ssp.,蔷薇科杏仁核亚科)是世界上最重要的温带水果作物之一。与野生梨相比,栽培梨的果实在许多形态特征上表现出显著变化…...

数据分析(二)——导入外部数据,导入Excel数据,CSV文件,txt文件,HTML网页,数据抽取,DataFrame对象的loc属性与iloc属性
一.导入外部数据 1.导入.xIs或.xIsx文件 pd.read_ excel(io,sheet_ name,header) 1.1常用参数说明 ●io:表示.xIs或.xIsx文件路径或类文件对象 ●sheet name:表示工作表,取值如下表所示 ●header:默认值为0,取第一行的值为列名,数据为除列…...

如何让Linux系统崩溃?
如何使 Linux 系统崩溃 警告 下面的代码行是 Bash shell 的一个简短而甜蜜的 fork 炸弹。分叉炸弹之所以有效,是因为它能够产生无限数量的进程。最终,Linux无法处理所有这些,并且会崩溃。 fork 炸弹的一大优点是你不需要 root 权限即可执行它…...

C# 实现邮件推送功能
🏆作者:科技、互联网行业优质创作者 🏆专注领域:.Net技术、软件架构、人工智能、数字化转型、DeveloperSharp、微服务、工业互联网、智能制造 🏆欢迎关注我(Net数字智慧化基地),里面…...

GC9A01驱动踩坑记:从供应商代码到自研优化,软件SPI这些细节别忽略
GC9A01驱动深度优化:软件SPI性能压榨实战手册 当240x240的LCD屏幕刷新一张图片需要整整1秒时,那种卡顿感会让任何开发者抓狂。上周调试GC9A01驱动时,我就遇到了这个噩梦——供应商提供的软件SPI驱动在40MHz主频下刷新率不足1FPS。经过72小时的…...

WechatRealFriends:微信好友关系检测终极方案深度解析
WechatRealFriends:微信好友关系检测终极方案深度解析 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...
)
OpenClaw 接入 DeepSeek 模型完整配置教程(2026 最新版)
OpenClaw 接入 DeepSeek 模型完整配置教程 一、前置准备 已安装并正常运行 OpenClaw Windows 客户端;OpenClaw 顶部 Gateway 状态保持在线;电脑网络正常,可稳定访问 DeepSeek 开放平台;准备可接收验证码的手机号或微信账号&…...

计算机视觉:YOLOv12安装环境
YOLOv12安装环境 一、工具软件准备 1、yolov12 1)下载yolov12主体部分 推荐官方地址:https://github.com/sunsmarterjie/yolov12 2)下载训练模型 地址: https://github.com/sunsmarterjie/yolov12 3)安装命令和p…...

北京理工大学:数据中心节能降碳之算电协同——背景、技术、实践和展望 2026
这份由北京理工大学 2026 年初发布的《数据中心节能降碳之算电协同:背景、技术、实践和展望》报告,围绕算电协同,从背景、技术、实践、展望四方面系统分析,核心是推动算力与电力、热力深度融合,助力数据中心节能降碳、…...

全面配置指南:Excel MCP Server高效部署与专业运维实战
全面配置指南:Excel MCP Server高效部署与专业运维实战 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server Excel MCP Server是一个强大的模型…...
)
X.509证书格式(SPDM协议)
字段名称含义用途示例待签名内容(tbsCertificate)Version (版本)含义: 证书版本号。取值: v1(0), v2(1), v3(2)。互联网 PKI 必须使用 v3 (值为 2)。告诉解析程序该按照哪个标准来读取后续的字段(目前绝大多数为 v3)。Version: 3 (0x2)Serial Number (序…...

终极指南:8步搭建你的私人游戏串流服务器Sunshine
终极指南:8步搭建你的私人游戏串流服务器Sunshine 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上流畅玩PC游戏吗?Sunshine是一款免费开源…...

R型变压器与稳压电源:解决电压不稳跳闸,保障电器安全
1. 项目概述:从频繁跳闸到电压稳定的核心诉求如果你住在农村、城乡结合部,或者一些老旧小区,家里电器一多,或者一到用电高峰,空气开关就“啪”一声跳闸,这种烦恼我太懂了。以前我老家也这样,夏天…...

5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界
5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾经因为物理显示器限制而无法获得完…...