从离线到实时:无锡锡商银行基于 Apache Doris 的数据仓库演进实践
作者:武基鹏,无锡锡商银行 大数据技术经理
编辑整理:SelectDB 技术团队
导读:为实现数据资产的价值转化以及全面数字化、智能化的风险管理,无锡锡商银行大数据平台经历从 Hive 离线数据仓库到 Apache Doris 实时数据仓库的演进,目前已接入数百张实时表、上百数据服务接口 ,接口 QPS 达到数百万级别,解决了离线数据仓库时效性不足、成本高昂、效率低下等问题,查询提速超 10 倍,为用户提供及时、有效、安全的数据服务及使用体验。
面对大数据、物联网、人工智能等新兴技术给金融行业带来的变革,无锡锡商银行将科技能力和大数据能力的发展放在重要位置。为实现数据资产的价值转化以及全面数字化、智能化的风险管理,基于“业务线上化、风控数据化、架构平台化”三翼一体的科技布局,无锡锡商银行建立了大数据平台,以管理每日流入的海量交易记录与信贷申请数据,借助用户画像、实时报表、实时风控等应用,为用户提供更加及时、有效、安全的数据服务及使用体验。
无锡锡商银行大数据平台经历了基于 Hive 离线数据仓库到基于 Apache Doris 的实时数据仓库演进。通过架构的升级,解决了离线数据仓库时效性不足、成本高昂、效率低下等问题,实现查询速度 10 倍提升,使得银行能够更快感知客户行为,及时洞察异常交易行为、识别和预防潜在的风险。本文将详细介绍无锡锡商银行大数据平台演进历程以及 Apache Doris 在实时查询、营销服务、风控服务等场景的落地实践。
基于 Hive 的大数据离线数据仓库
01 需求场景
无锡锡商银行早期建设了大数据离线数据仓库,主要服务于数据报送、数据风控、数据运营、即席查询及日常取数等场景,需求场景包括且不限于:
- 数据报送:客户风险、EAST 报送、1104、大集中、征信报送、利率报备、反洗钱、金融基础数据报送等。
- 数据风控:包含对贷款类风控指标、用户行为指标、反欺诈、贷后预警、贷后管理等风险控制。
- 数据运营:对 BI 业务报表、管理驾驶舱、行外渠道和行内各系统进行定时批量供数。
- 即席查询及日常取数:根据业务需求进行数据分析、数据开发及数据提取。
02 架构及痛点
在早期离线数据仓库中,数据主要来源于 Oracle、MySQL、MongoDB、Elasticsearch 以及文件。通过使用 Sqoop、Spark、外部数据源和 Shell 等工具,将数据离线抽取到 Hive 离线数据仓库中,并在 Hive 中通过 ODS、DWD、DWS 和 ADS 分层处理,最终输出结果为应用服务层提供支持。
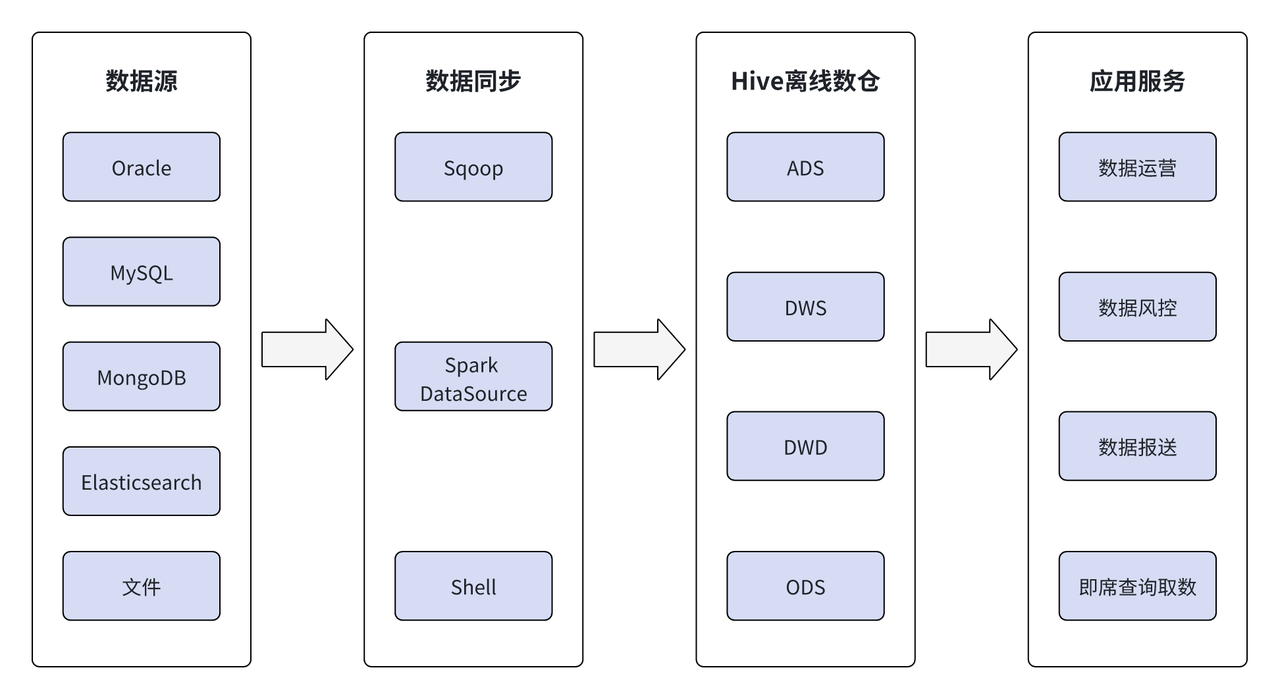
近些年,随着无锡锡商银行业务的发展与扩张,相关业务部门对数据处理的要求也越来越高,离线数据仓库已无法满足新的需求,主要体现在:
- 数据时效性不足:离线数据仓库使用离线抽取的方案,数据时效性为 T+1,而报表、数据大盘、营销指标、风控变量要求数据实时更新,当前架构无法满足。
- 数据查询效率低:需满足秒级别、毫秒级的查询响应。离线数据仓库执行引擎主要是 Hive 及 Spark,Hive 执行时会将查询分解为多个 MapReduce 任务,并需读取和写入 HDFS 中的数据,执行时长一般为分钟级别,严重影响查询效率。
- 维护成本高:离线数据仓库底层涉及技术栈繁多 ,包括 LDAP、Ranger、ZooKeeper、HDFS、YARN、Hive、Spark 等多个系统,这将导致较高的系统维护成本。虽然线上也有 HBase + Phoenix 的实时存储与服务,但由于其组件比较“重”、社区不活跃,且某些特性无法满足实时场景需求,仍然不能完全解决当前的问题。
技术选型
面对离线数据仓库时效性不足、查询效率不高,多个技术栈带来的维护成本高等痛点,实时数据仓库的构建势在必行。在对多个 MPP 数据库进行深入的调研后,无锡锡商银行决定以 Apache Doris 为核心构建实时数据仓库平台。这一技术选型旨在确保平台在数据写入、查询及服务层面均能满足实时业务分析的高要求。选择 Apache Doris 的理由如下:
- 高效数据更新: Apache Doris Unique Key 支持大批量数据更新、小批量数据实时写入以及轻量化表结构的修改。尤其在处理大量数据和分区时,能够有效避免庞大的修改量和修改不准确的问题,从而提供更加便捷实时的数据更新。
- 低延时实时写入: 支持秒级别的数据实时写入、更新和删除;支持主键表模型写时合并,可实现微批高频实时写入;并且支持主键模型 Sequence 列设置,可保证数据导入过程中的有序性。
- 查询性能优异: Apache Doris 多表 Join 能力强大,依托向量化执行引擎、CBO 查询优化器、MPP 架构、智能物化视图等功能,能够实现海量数据的毫秒级查询响应,满足即查即走的数据查询要求。同时 Apache Doris 2.0 版本支持行列混存,在点查询场景可以实现数万并发的毫秒级响应。
- 平台极简易用: 兼容 MySQL 协议,并提供丰富的 API 接口,能够降低上层应用的使用难度。同时,Apache Doris 架构精简,只有 FE 和 BE 两进程,节点扩缩容简单、集群管理和数据副本管理均支持自动化,具备部署简单、使用成本及运维成本低的特点。
引入 Apache Doris 搭建大数据实时数据仓库
2022 年 4 月,无锡锡商银行引入 Apache Doris 构建实时数据仓库平台。考虑到银行数据规模非常庞大,接入实时数据的同时,再从业务库同步全量历史数据难度较大,因此,初期实时数据搭建主要依托于离线数据。
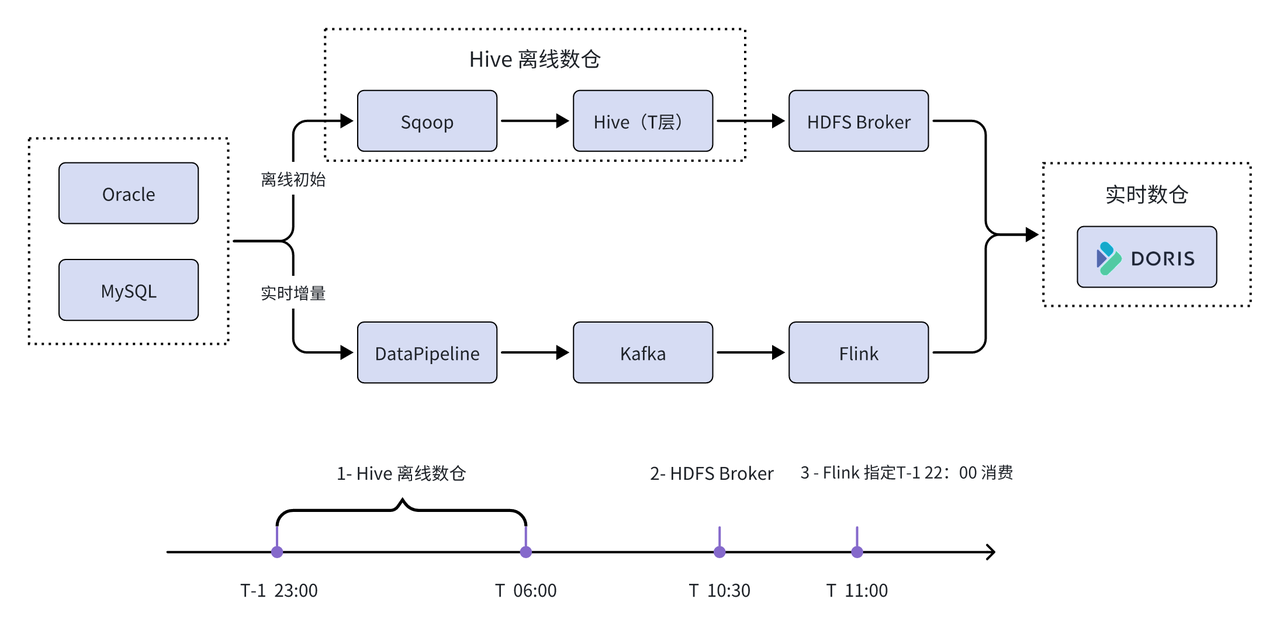
首先,采用 HDFS Broker 方式高效初始化历史实时数据;同时,借助采集工具 DataPipeline 将数据实时采集至 Kafka 集群中,再由 Flink 写硬编码模式将数据实时写入 Apache Doris 中。最后,借助飞流平台的接口服务能力,将 Apache Doris 作为统一存储与查询引擎,为各业务线提供服务。
飞流平台是无锡锡商银行为应对未来实时业务场景而构建的统一综合平台,主要包含实时采集、实时同步工具、实时数据仓库、实时计算以及数据服务。
01 完善数据流转链路
从银行数据特性出发,结合 Apache Doris 功能优势,无锡锡商银行重新思考并完善了数据流转链路:
- 从离线数据仓库同步历史数据,风险最小化: 文提到,由于银行数据的庞大规模,如果直接从 Oracle 与 MySQL 同步全量历史数据,会导致大量数据流经过防火墙和交换机,引发其他业务请求阻塞和服务超时等问题。为了避免这些潜在的风险和问题,首先基于 Oracle 与 MySQL 批量构建 Doris 表结构,然后使用 HDFS Broker 从离线数仓 Hive ODS 层同步 T-1 全量数据到 Doris 中,从而实现风险最小化。
- 实时增量抽取,更安全抽取模式: 实时抽取会产生极少量的磁盘 IO、内存、CPU 消耗,为了避免对业务主库有影响,默认认情况下,一般会选择从业务从库或同城灾备库实时抽取。而针对时效性要求较高的业务需求,需要充分评估才能从业务主库抽取数据。
- 构建 Kafka 层,保证数据一致性: 建立 Kafka 层作为数据中间传输层,以确保数据的有序性和一致性。通过将 Datapipeline 发送的数据的 Key 配置为 Database-Table-PK,并按照同一个维度有序地发送到 Kafka Topic 的某个分区(Partition)。由于 Kafka Topic 各自分区内部是有序存储的,因此下游的消费者可以按照顺序处理数据,避免乱序情况对实时数据仓库数据准确性的影响。此外,Kafka 层可作为数据公共层可开放给营销类、风控类业务等场景使用。
- 数据实时写入,保证数据不丢不重: 在实际应用场景中,离线链路在 T-1 日的晚上 11 点至早上 6 点进行数据离线跑批,在 T 日 10 点借助 HDFS Broker 方式进行表历史数据初始化。实时链路使用 Flink 直接指向 T-1 的晚上 10 点消费 Kafka Topic ,进行实时数据同步,而在实时消费过程中会出现部分重叠数据。为应对该问题,选用 Apache Doris 的 Unique Key 模型(该模型支持数据幂等性),该模型可快速覆盖重叠数据;并使用 Flink-Doris-Connector 完善实时数据仓库链路,以保证实时数据同步不丢不重。
02 灵活的数据服务
为了提供精准、高效的查询响应,无锡锡商银行采取了以下三种方式来实现数据服务:
- 离线数据查询:针对离线需求,需要对数据进行快速查询。无锡锡商银行将数据定期从离线数据仓库导入到实时数据仓库 Doris 表中。这样可以在实时数据仓库中快速查询,满足离线数据分析和决策的需求。
- 简单实时需求:对于不复杂的实时需求,无锡锡商银行利用 Apache Doris 的高效查询能力,在"飞流"平台上提供了直接配置数据服务接口的能力,用户可基于实时数据仓库 ODS 层的 SQL 进行手动配置。通过这种方式,可以快速满足简单实时数据查询的需求。
- 复杂实时需求:对于复杂的实时需求,无锡锡商银行采用实时 Kafka 数据流和 Flink 轻度计算的方式,将数据流写入实时数据仓库的 DWD 层表中,在"飞流"平台上基于明细表的 SQL 进行再次聚合,并手动配置数据服务接口,以满足复杂实时数据查询的需求。
面向更多样化的服务场景
01 BI 报表秒级查询响应
无锡锡商银行基于 Apache Doris 满足了当日数据分析、日常取数以及 BI 实时报表等多种场景需求,查询响应时间大大缩短,能够在 1 秒内返回查询结果,极大降低了数据分析师的等待成本和服务器资源的消耗。
比如,在 BI 实时报表方面,无锡锡商银行建立实时贷款数据表、实时存款数据表、账户时点余额表等多种报表。**这些报表平均 SQL 代码行数为 253 行,平均响应时间为 1.5 秒。**另外,通过优化查询性能和数据模型设计,无锡锡商银行能够在较短的时间内生成准确的实时报表,为业务决策提供及时的数据支持。
02 支持个性化营销方案
在营销类数据服务方面,无锡锡商银行基于 Apache Doris 丰富客户标签、完善客户精准画像,开展了资产净增活动、艺术家盲盒活动等多种营销活动。通过实时数据的分析,银行能够及时观察活动用户的转化情况,并及时调整运营圈选策略,实现从“千人一面”到“千人千面”的个性化营销。
比如,在资产净增活动和艺术家盲盒活动等营销活动中,无锡锡商银行利用 Apache Doris 实时数据仓库的能力,不断收集、分析和反馈活动数据。通过实时观察用户的转化情况,及时调整运营圈选策略,确保人员和活动之间的匹配度。这种个性化的营销策略使得银行能够更好地满足客户的需求,提升参与度、响应率以及用户粘性。
03 高效的风险识别与控制
Apache Doris 的引入,使得无锡锡商银行能够更快计算出风控特征变量、异常交易行为。以新用户注册为例,当用户填写资料时,系统可以基于实时的风控特征变量,快速判断审批策略结果,及时优化策略模型,保证审批的质量和准确性。
无锡锡商银行还能够及时识别和预防潜在的风险。例如,对于短时间内大量交易、异常交易金额等交易数据,银行可以实时收集并进行监测,以及时发现异常交易行为和欺诈行为。通过实时数据分析,银行可以快速识别潜在的风险,并采取相应的措施进行预防和应对。
另外,无锡锡商银行还利用 Apache Doris 实时数据仓库对客户的信用历史和信贷申请信息进行实时分析。通过快速判断客户申请金额是否符合其还款能力,银行可以及时作出风险评估和决策,从而有效控制信贷风险。
04 七日交易流水表的数据自动更新
在实际应用场景中,交易流水表的数据量非常庞大,涉及交易序号、交易日期、交易类型、交易金额等数据。为确保数据的及时更新,无锡锡商银行选择采用 Apache Doris 动态分区表的特性。该特性可以自动创建分区,并自动删除超过七天的交易流水数据,以实现七日交易流水表的数据自动更新。具体的操作包括以下步骤:
- 以业务日期构建伪列作为联合主键;
- 当 ID 数据进行
tran_date跨天更新时,代码进行回表操作; - 找到数据在 Insert 与分区表中对应的 Date 值,并拼接成 Update Json 更新入库。

借助 Apache Doris 动态分区分表特性,不仅能够保证底层主键和服务器稳定运行,还能够自动更新并只保留七天流水交易数据以供分析师查询,并满足百万 QPS 下 1.5 秒查询响应需求。
05 高并发点查询
早期营销类与风控类应用场景主要依赖两套 HBase 集群以支持点查服务,然而在实际应用中,会遇到诸如 Master / Regionserver 异常退出、RIT 等问题。为避免该问题,可利用 Apache Doris 高并发点查能力,并在创建 Unique Key 表时,启用 Merge-on-Write 策略,使得主键点查能够经由简化的 SQL 执行路径完成,仅需一次 RPC 即可完成快速的查询响应。
最终通过在三台节点上进行压力测试,在为每台节点配置了 8C、10GB 的情况下,获得了以下显著收益:
- 在单表包含 5000 万数据的查询场景中,QPS 高达 2.5 万;
- 在涉及 5000 万数据的多表读写场景中,QPS 同样达到 2 万;
- 复杂 SQL 查询的稳定性也保持在 QPS 2.5 万的高水平;
- 在多表实时读写场景中,QPS 亦能稳定在 2.5 万。
结束语
目前 Apache Doris 在无锡锡商银行已经接入数百张实时表、上百数据服务接口 、接口 QPS 达到数百万级别。此外,Apache Doris 作为统一查询网关,显著提升了历史数据分析的效率,与原来分钟级响应时间相比,查询提速超 10 倍。
未来,无锡锡商银行将持续发掘 Apache Doris 优势,并推进其在实时场景中更深度的应用。
- 在性能表现上:进一步优化高并发点查询、自动分区分桶、执行引擎等能力,以提升数据的查询响应效率;
- 在负载均衡上:构建双集群,实现架构负载均衡;同时,将完善架构预警与熔断机制,保障业务运行不间断;
- 在集群稳定性上:实现 Apache Doris 集群的“分工协作”,使其各自承担实时数据仓库的计算与存储、数据服务加速查询等任务,进一步提高系统的稳定性及可靠性。
相关文章:
从离线到实时:无锡锡商银行基于 Apache Doris 的数据仓库演进实践
作者:武基鹏,无锡锡商银行 大数据技术经理 编辑整理:SelectDB 技术团队 导读:为实现数据资产的价值转化以及全面数字化、智能化的风险管理,无锡锡商银行大数据平台经历从 Hive 离线数据仓库到 Apache Doris 实时数据仓…...

网易云如何改ip地址到另外城市
在数字化时代,网络音乐平台已经成为我们日常生活中不可或缺的一部分。然而,有时候我们可能会因为某些原因想要改变自己的IP地址,网易云音乐作为国内领先的音乐平台,其强大的功能和丰富的音乐资源吸引了大量用户。那么,…...

Golang 开发实战day13 - Reciver Functions
🏆个人专栏 🤺 leetcode 🧗 Leetcode Prime 🏇 Golang20天教程 🚴♂️ Java问题收集园地 🌴 成长感悟 欢迎大家观看,不执着于追求顶峰,只享受探索过程 Golang 开发实战day13 - 接收…...
ZL-016D多通道小鼠主动跑轮系统主要研究动物生活节律
简单介绍: 多通道小鼠主动跑轮系统是由动物本身自发运动来推动跑轮转动。在这种构型中,笼内动物长期活动的信息,如跑轮转动方向、转数、累计总行程等,能够使用编码器进行长度计记录。此装置由转轮组件、笼体、以及转动方向速度传…...
)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA…...

计算机类的英语
Algorithm(算法)Binary code(二进制代码)Byte(字节)Cache(缓存)Database(数据库)Encryption(加密)Firewall(防火墙&#x…...

深⼊理解指针(5)
目录 1. 回调函数是什么?1.1 使用回调函数修改 2. qsort使⽤举例2.1 使⽤qsort函数排序整型数2.2 使⽤qsort排序结构数据按年龄排序2.3 使⽤qsort排序结构数据按名字排序2.4整体代码 3. qsort函数的模拟实现3.1 整型数组的实现3.2 结构体按名字排序实现3.3 结构体按…...

baomidou dynamic-datasource 强制查询sql走主库
场景 因为引用了baomidou主从数据源,因为业务场景特殊,需要查询语句强制走主库,把解决方案分享出来,帮助大家少走弯路 pom依赖 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-data…...
FPGA ov5640视频以太网传输
1 实验任务 使用DFZU4EV MPSoC 开发板及双目OV5640摄像头其中一个摄像头实现图像采集,并通过开发板上的以太网接口发送给上位机实时显示。 2 Verilog代码 2.1 顶层模块 timescale 1ns / 1ps //以太网传输视频顶层模块module ov5640_udp_pc (input sys_cl…...

论Java和C++方向选择
目录 1.难度2.就业压力3.岗位选择4.薪资待遇5.选择建议小结 1.难度 Java ,C, 测开,整体来说三个方向难度相当。 1.仅从语法角度来看,c 是掌控一切,知识都要懂一点,而java的特点在于省心,都封装…...
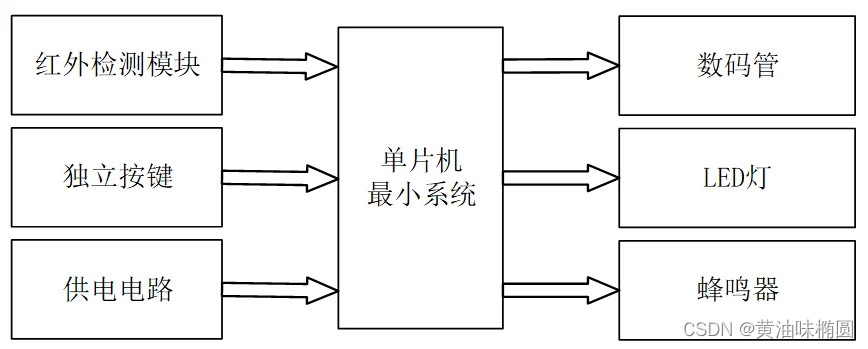
交通灯-设计说明书
设计摘要: 本设计基于单片机技术,旨在实现智能化交通信号控制,并具备夜间模式、禁止通行模式、同行模式切换以及车流量监测功能。通过按键S1和S2实现夜间模式和禁止通行模式的切换,确保夜间交通安全和禁止通行的需要。按键S3和S4…...
)
[前端] vue2的/deep/转化为vue3语法(笔记)
vue2语法示例 <style scoped lang"less">::v-deep .el-carousel__button {width: 8px;height: 3px;border-radius: 3px;}::v-deep .el-carousel__indicator.is-active button {width: 16px;} } </style>在 Vue 3 中,/deep/ 或 >>> …...

JavaScript基础(七)
isNaN //用来判断一个变量是不是一个非数字 不是来判断是不是number类型,而是判断当前值能不能转为number类型,OK?懂了。 还有同学不明白,来看实例: <script> //isNaN(非数字)→true (数字)→fal…...

【DevOps】Linux 内核网络子系统全面指南与性能调优
目录 一、Linux 内核网络子系统 1. Netfilter 主要特性 工作流程 2. Traffic Control (TC) 主要特性 工作流程 3. Socket 主要特性 工作流程 二、内核参数优化 1. net.ipv4.tcp_window_scaling 2. net.core.netdev_max_backlog 3. net.ipv4.tcp_rmem 和 net.ipv4…...
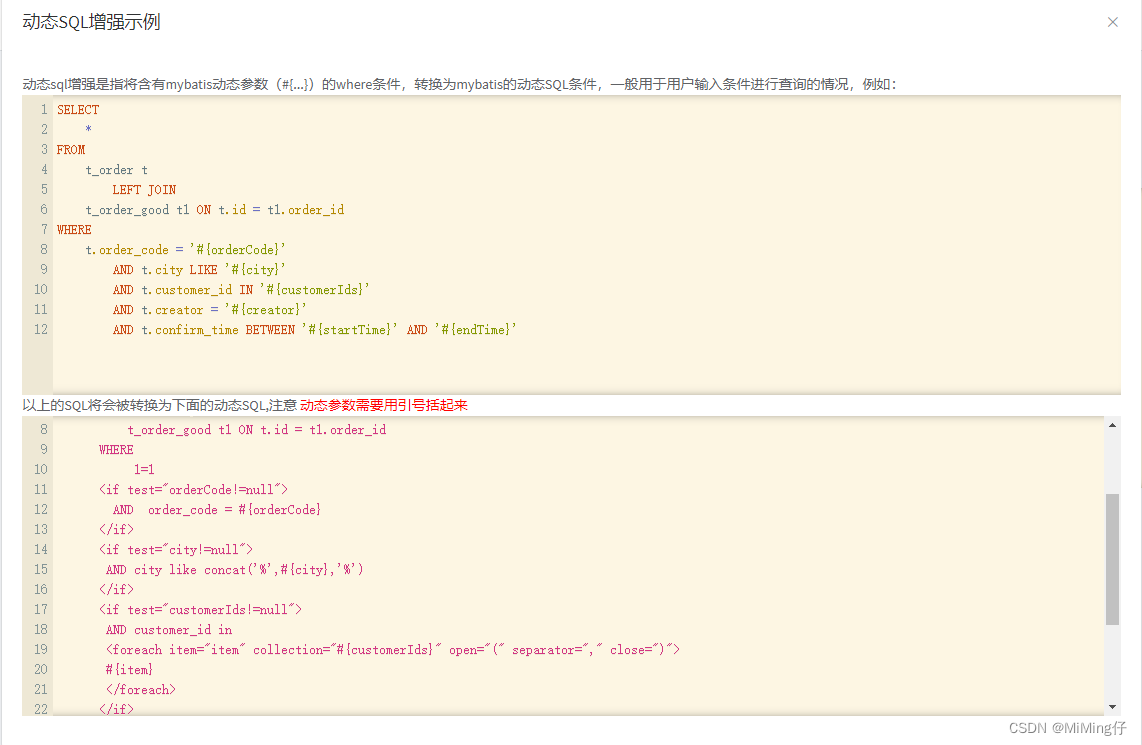
mybatis-plus-ui代码生成器
mybatis-plus-generator-ui 提供交互式的Web UI用于生成兼容mybatis-plus框架的相关功能代码,包括Entity,Mapper,Mapper.xml,Service,Controller等 ,可以自定义模板以及各类输出参数,也可通过SQL查询语句直接生成代码。 使用方法 引入mave…...

项目进度总结
完成了签到,老师发布签到并设置持续的时间,学生在规定的时间内可用签到码进行签到,超过时间将不在允许签到...
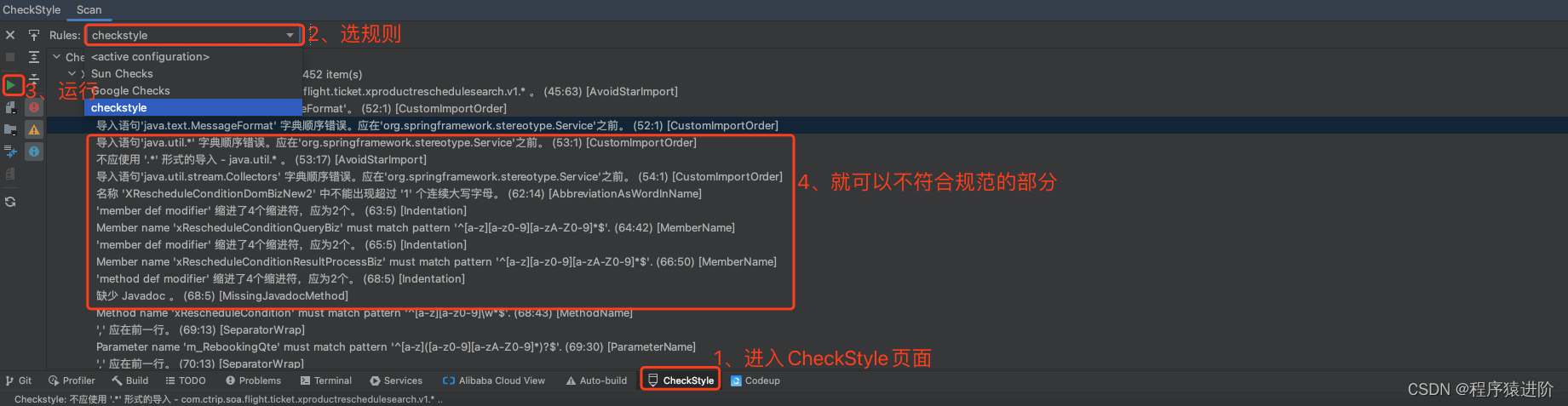
CheckStyle静态样式之道
优质博文:IT-BLOG-CN 在标准化的统一样式检查规范里,最为常用的统一样式工具是checkstyle插件,而不是国内阿里的代码规约插件。 【1】下载插件 【2】配置生效 配置生效及告警设置 【3】配置checkstyle.xml 官网地址 官网最新Releases 下面…...

2024中国振威化工装备展
2024上海国际化工设备展览会 第十六届上海国际化工装备博览会将于2024年11月19-21日在国家会展中心(上海)举办,预计参展企业1000多家,展览面积7万平方米,观众突破10万人次。展会设置石化装备、化工单元设备、化工环保…...

Docker操作之启动多个相同容器实例并nginx负载均衡
文章目录 前言 一、一些概念 1.Docker 2.nginx 二、操作步骤 1.构建compose.yaml 2.nginx配置 3.Docker compose命令 4.问题与解决 总结 前言 Docker对于开发、运维人员来说都很熟悉,但是对于开发人员来说,多数时候只需一个容器实例运行即可。…...
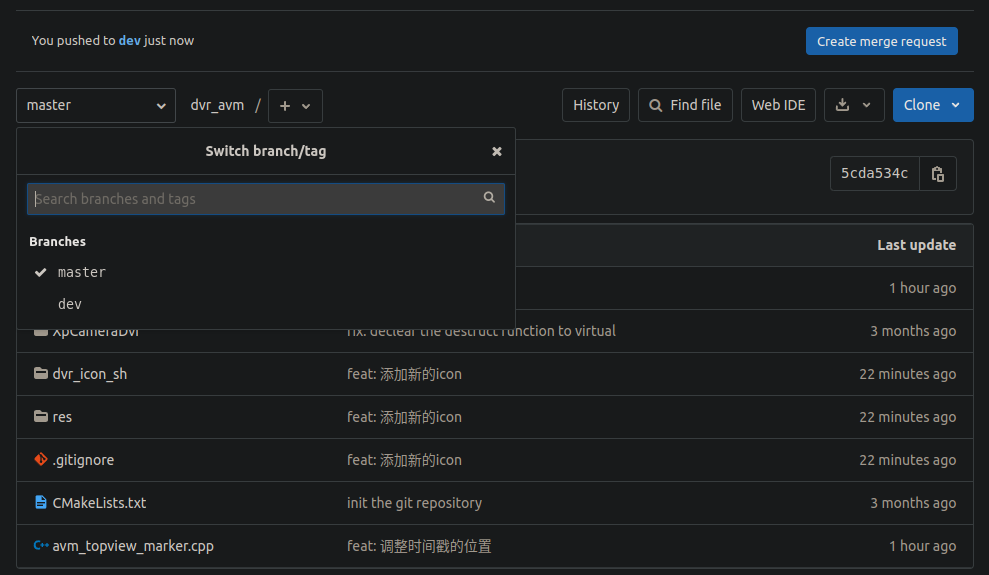
本地的git仓库和远程仓库
文章目录 1. 远程创建仓库2. 关联远程和本地代码3. 推送本地分支到远程4. 删除远程分支5. 分支重命名6. git pull rebase7. git merge master把本地文件删除了 1. 远程创建仓库 2. 关联远程和本地代码 上面创建完后会得到一个git仓库的链接,有SSH或者http的 http:…...
实战:从配置到调试,手把手教你防止程序‘饿死’)
ESP32任务看门狗(TWDT)实战:从配置到调试,手把手教你防止程序‘饿死’
ESP32任务看门狗深度实战:构建高可靠多任务系统的关键技巧 在物联网设备开发中,系统稳定性往往决定着产品的成败。想象一下这样的场景:你的智能家居网关在凌晨3点突然停止响应,或者工业传感器节点在关键时刻丢失数据——这些问题的…...

告别手动排版:用docx2tex将Word文档智能转换为LaTeX
告别手动排版:用docx2tex将Word文档智能转换为LaTeX 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 还在为论文排版而烦恼吗?每次从Word转换到LaTeX都要重新调整公式、…...

GEE数据流转实战:如何用Google Drive和Assets搭建你的遥感数据处理流水线
GEE数据流转实战:构建云端遥感数据处理流水线 当遥感数据处理遇上云计算平台,一场关于效率的革命正在悄然发生。Google Earth Engine(GEE)作为全球领先的地理空间分析平台,与Google Drive和Assets的深度整合࿰…...
)
不只是模拟器:用Android-x86把你的旧笔记本变成安卓平板(附VirtWifi联网指南)
旧笔记本重生计划:用Android-x86打造高性能安卓工作站 你是否有一台闲置多年的旧笔记本,性能早已跟不上现代操作系统的需求,却又舍不得丢弃?别急着让它沦为电子垃圾,通过Android-x86项目,这些老设备完全可以…...

手把手教你用Python3运行seeyon_exp工具,一键检测致远OA常见漏洞
手把手教你用Python3运行seeyon_exp工具进行致远OA漏洞检测 在当今企业数字化办公环境中,协同办公系统承载着大量核心业务数据,其安全性至关重要。致远OA作为国内广泛使用的办公自动化平台,近年来曝光的多个高危漏洞引起了安全从业者的高度关…...

一文搞懂工业机器人通讯协议:TCP/IP、Modbus与专用协议对比
在我十年的工控开发生涯中,通讯问题永远是项目延期的第一大原因。我见过太多团队花了几个月时间做运动控制和视觉算法,最后却卡在了机器人通讯上:要么是数据传输不稳定,要么是速度跟不上产线节拍,要么是换个品牌机器人就要全部重写代码。 很多新手工程师觉得通讯就是&quo…...

软件设计师下午题训练2-3题+2020下上午题错题解析 练习真题训练15
一、训练题2 1、2021上 (1) (2) a:团购点编号 b:客户电话 供货 主键 :(供货商编号,团购点编号) 外键:供货商编号、团购点编号 订单 主键:订单编号…...

Ubuntu 下 P106-100 矿卡 `nvidia-smi No devices were found` 问题解决全过程
Ubuntu 下 P106-100 矿卡 nvidia-smi No devices were found 问题解决全过程 最近折腾一张老矿卡 P106-100,在 Ubuntu 下遇到一个非常经典的问题: nvidia-smi No devices were found但是: lspci | grep -i nvidia却能看到显卡: 01:00.0 3D controller: NVIDIA Corporat…...

为什么你的离心风扇仿真总不准?建模方法与调速策略深度拆解
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 211、985硕士,从业16年 从事结构设计、热设计、售前、产品设计、项目管理等工作,涉足消费电子、新能源、医疗设备、制药信息化、核工业等…...

A-59F所有应用模式说明
A-59F 是一款高集成语音处理模组,一体化实现 AI ENC 降噪、AEC 回音消除、扩音防啸叫、BF 波束拾音 四大核心能力。支持模拟 / 数字麦克风、模拟 / I2S 数字音频接口,邮票孔 SMT 封装,体积小巧、易嵌入,可大幅简化音频电路&#x…...