python爬取数据并将数据写入execl表中
文章目录
- 概要
概要
提示:python爬取数据并将数据写入execl表中,仅供学习使用,代码是很久前的,可能执行不通,自行参考学习。
# -*- coding: utf-8 -*-
import datetime # 日期库
import requests # 进行网络请求
import xlwt # 与excel相关的操作
from lxml import etree # 引入xpath库,方便定位元素
import time # 进行访问频率控制
import random # 随机数生成
import math # 数学库# main
def main(word, filename):word = wordfilename = filenameSavepath = "./test/" + filename + ".xls" # 存储路径datalist = getdata(word) # 获取爬取的关键词数据savedata(datalist, Savepath) # 保存的数据和路径参数# 获取html源码
def ask_url(url):html = ""# 进行伪装头信息,防止416错误,模拟浏览器头部信息,向豆瓣服务器发送消息(最好加上cookie)headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/83.0.4103.116 Safari/537.36 "}try:response = requests.get(url, headers=headers,timeout=10) # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)time.sleep(random.randint(1, 3)) # 每隔1-3s执行一次请求html = response.content # 获取网页的html源代码print("请求访问成功")except requests.exceptions.RequestException as e:print("超时") # 10秒请求无响应则显示超时print(e)return html# 获取站长工具网站关键词总数
def num(word):word = word # 关键词url = 'http://rank.chinaz.com/' + word # 站长工具查询关键词URLnum = ask_url(url) # 获取网页源码num1 = etree.HTML(num) # 解析网页try:global num2 # 全局变量 num2num2 = num1.xpath('/html/body/div[3]/div[7]/div[1]/div[1]/span/i[1]/text()')[0] # 通过xpath获取网页关键词总数的值print(num2) # 输出获取的值num2 = int(num2) # 将值类型转化为intnum2 = str(num2) # 将值类型转化为strprint('关键词数:' + num2) # 打印关键词数num2 = int(num2)if num2 <= 200: # if num2<=200,原值返回num2 = int(num2)elif num2 >= 1000: # if num2>=1000,赋值为1num2 = 1else:num2 = 200 # else num2=200except:print("该网站没有关键词") # if没有获取到值则显示无关键词pass # 用pass防止报错return num2 # 返回最终关键词总数num2# 获取爬取的关键词
def getdata(word):word = word # URLnum2 = num(word) # 获取关键词总数num2 = num2 / 20 # 获取页数num3 = math.ceil(num2) # 去除小数取整num3 = str(num3) # 转化为strprint('页面数:' + num3) # 输出总页数num3 = int(num3)Datalist = [] # 用来存储已经经过处理的信息print("{:^20}\t{:^12}\t{:^12}\t".format('关键词', '指数', '排名')) # 打印表头for i in range(0, num3): # 在1-num3页内爬取关键词的信息i = i + 1 # i + 1 用于翻页操作i = str(i)url = 'http://rank.chinaz.com/' + word + '-0---0-' + i # 这个根据网页的翻页特点 站长工具网址翻页后参数变化是每页的数字+1data = ask_url(url) # 获取到源代码data = data.decode('utf-8') # 将数据进行utf-8编码# 从源代码中提取信息if data != "":html_data = etree.HTML(data) # 解析网页# 使用xpath定位到全部要获取的内容 然后在这个里面循环提取div_list = html_data.xpath('//ul[@class="_chinaz-rank-new5b"]')for item in div_list:data_item = [] # 在循环里面建立一个空的列表存储关键词一页的全部数据# 关键词movie_rank = item.xpath('li[1]//a[1]//text()')[0]data_item.append(movie_rank)# PC指数movie_name = item.xpath('li[4]//text()')[0]data_item.append(movie_name)# 排名paiming = item.xpath('li[2]//a//text()')[0]data_item.append(paiming)print("{:^20}\t{:^8}\t{:^8}\t".format(movie_rank, movie_name, paiming))# 先将一行的数据存储在data_item中,再将data_item存入DatalistDatalist.append(data_item)return Datalist# 将html获取的信息存入Excel表格中
def savedata(Datalist, Savapath):col = ("关键词", "PC指数", "排名") # Excel的表头 也就是列数house_list = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象worksheet = house_list.add_sheet("同行网站关键词", cell_overwrite_ok=True) # 新建工作区,设为可覆盖for i in range(0, 3): # 写入表头 一共3列worksheet.write(0, i, col[i]) # 写入表头 一共3列try:for i in range(0, num2): # 写入数据 也就是行数 num2为总行数print("正在写入第%d条数据" % (i + 1))item = Datalist[i] # 获取的数据的索引for j in range(0, 3): # 列数worksheet.write(i + 1, j, item[j]) # i + 1是从第1行开始写 第0行被表头占用了 item[j]将数据按照数据的索引进行写入house_list.save(Savapath) # 存储except:print('存入Execl失败')pass# 读取文本中关键词
def lead_keywords():print('>> 正在导入关键词列表..')try:with open('./url_list.txt', 'r', encoding='gbk') as f: # 打开文本keywords = f.readlines() # 按行读取关键词except:with open('./url_list.txt', 'r', encoding='utf-8') as f:keywords = f.readlines()print(keywords)print('>> 正在导入关键词列表成功!')return keywords# 主函数
def seomain():words = lead_keywords() # 从文本中导入批量URLfor word in words: # 循环URLword.strip() # 对URL去除空格word = word.replace("\n", "") # 对URL去除换行符star_time = time.time() # 开始时间print(word) # 输出当前执行的URLfilename = str(word + datetime.datetime.now().strftime('%Y%m%d-%H-%M-%S')) # 形成文件名(URL+系统时间)try:main(word, filename) # 执行main()函数,将(URL,文件名)传入main()函数end_time = time.time() # 结束时间print("爬取完毕! 一共耗时: %.2f秒" % (end_time - star_time)) # 打印耗时except:passprint('已写入Execl到程序当前目录下,文件名为系统时间.xls')time.sleep(10) # 停止10秒# 程序入口
if __name__ == '__main__':seomain() # 执行主函数相关文章:

python爬取数据并将数据写入execl表中
文章目录 概要 概要 提示:python爬取数据并将数据写入execl表中,仅供学习使用,代码是很久前的,可能执行不通,自行参考学习。 # -*- coding: utf-8 -*- import datetime # 日期库 import requests # 进行网络请求 im…...

Linux动静态库
Linux动静态库 1.动静态库介绍 在程序翻译的链接阶段,其实就是把一堆.o文件链接在一起形成.exe文件。如果一个程序中需要链接很多个.o文件,那么这些.o文件就需要被打包才方便管理,**库文件本质就是把.o文件打包。**库文件是一种提高开发效率…...
)
线程与进程___(一)
1、线程 Thread 类创建得线程为前台线程,线程池中的为后台线程,,,Main方法结束后,前台线程仍然运行,直到完成,而后台线程立刻结束。 调用线程时候不会立刻进入 Running 状态, 而是…...

Google IO 2024有哪些看点呢?
有了 24 小时前 OpenAI 用 GPT-4o 带来的炸场之后,今年的 Google I/O 还未开始,似乎就被架在了一个相当尴尬的地位,即使每个人都知道 Google 将发布足够多的新 AI 内容,但有了 GPT-4o 的珠玉在前,即使是 Google 也不得…...

纯血鸿蒙APP实战开发——Navigation页面跳转对象传递案例
介绍 本示例主要介绍在使用Navigation实现页面跳转时,如何在跳转页面得到转入页面传的类对象的方法。实现过程中使用了第三方插件class-transformer,传递对象经过该插件的plainToClass方法转换后可以直接调用对象的方法, 效果图预览 使用说…...

Windows C++ 读取、修改配置文件.ini
目录 一、INI文件基础介绍 二、GetPrivateProfileString和WritePrivateProfileString 解释: 一、INI文件基础介绍 INI文件(初始化文件)是一种简单的文本文件,用于存储程序的配置设置。它们通常用于Windows操作系统环境中&#x…...
物联网D3——按键控制LED、光敏传感蜂鸣器
按键控制LED 按键抖动,电平发生变化,可用延时函数抵消按键抖动对系统的影响 传感器电路图 按键电路图 c语言对应类型 “_t”后缀表示使用typedef重命名的数据类型 枚举类型 #include<iostream> using namespace std; //定义枚举类型 typedef enu…...
Spring初学入门(跟学笔记)
一、Spring概述 Spring是一款主流的Java EE轻量级开源框架。 Spring的核心模块:IoC(控制反转,指把创建对象过程交给Spring管理 )、AOP(面向切面编程,在不修改源代码的基础上增强代码功能) 二、…...
二进制部署k8s---下篇
一 master02 节点部署 1 先在master01 添加映射master02 对master02进行环境初始化 3 从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点 scp -r /opt/etcd/ root192.168.11.12:/opt/ scp -r /opt/kubernetes/ root192.168.11.12:/opt…...

基于Sentinel-1遥感数据的水体提取
本文利用SAR遥感图像进行水体信息的提取,相比光学影像,SAR图像不受天气影响,在应急情况下应用最多,针对水体,在发生洪涝时一般天气都是阴雨天,云较多,光学影像质量较差,基本上都是利…...

C++自定义头文件使用(函数和类)
简单案例需求: 1,计算正方形和三角形的周长——函数 2,模拟不同类型的动物叫声——类 一、创建项目 C空项目 Class_Study 二、创建主函数 在源文件下添加新建项,main.cpp 三、自定义头文件——函数 需求:1&a…...
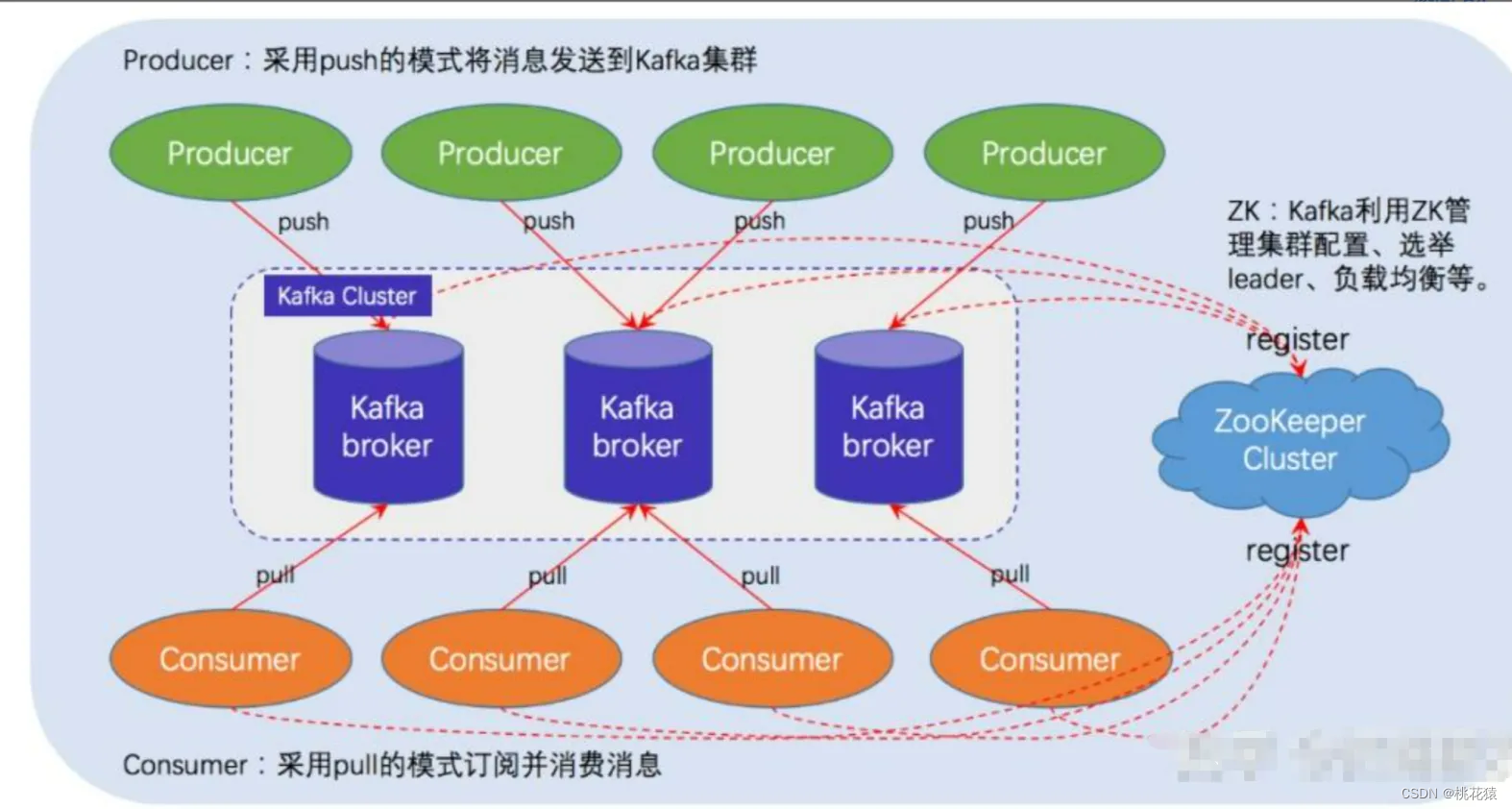
消息队列选型
一、要解决的问题 1.1 异步 分析: 需要根据场景来判断。若整体链路的逻辑中,某些逻辑是不需要强实时的,滞后一段时间是允许的,同时又不会对用户带来不好的体验,那么可以使用MQ完成异步操作。 例如:秒杀场…...
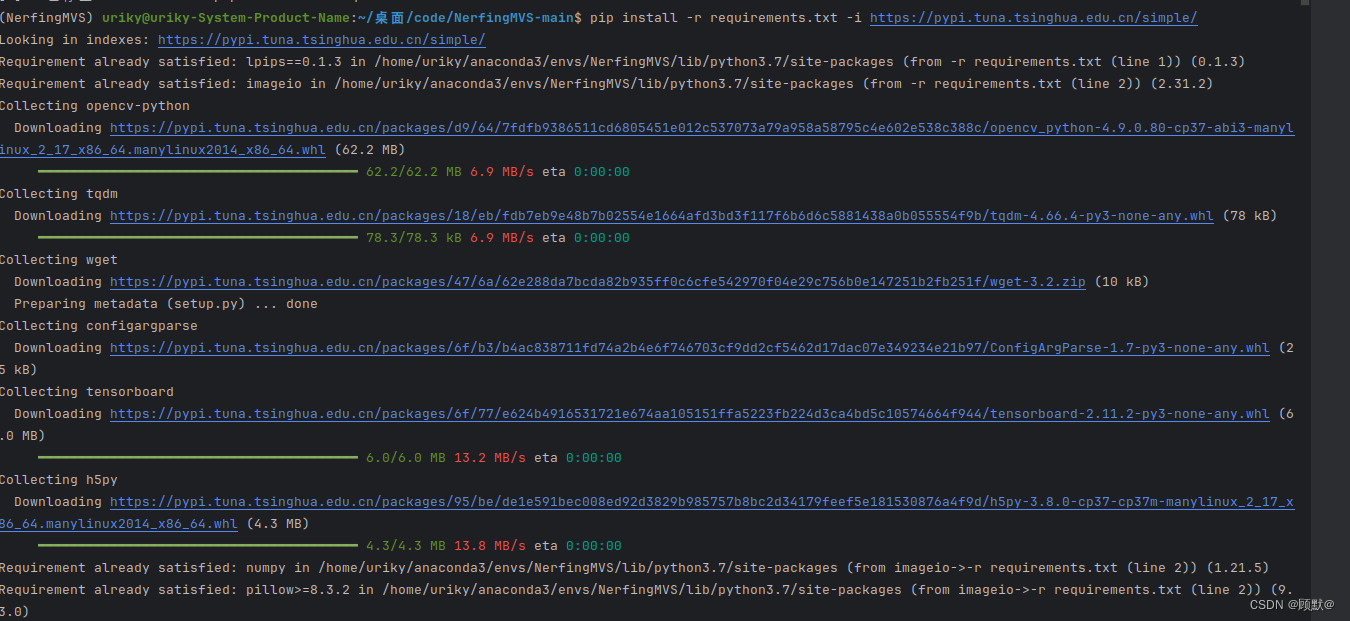
ubuntu在conda环境中使用 pip install -r requirements.txt但是没有安装在虚拟环境中
whereis pip pip listubuntu在conda环境中使用pip install lpips0.1.3 但是安装在了这里 Requirement already satisfied: lpips0.1.3 in /home/uriky/anaconda3/lib/python3.11/site-packages (0.1.3) 就会出现黄色波浪,未在虚拟环境中安装包 解决办法1࿱…...

力扣127.单词接龙讲解
距离上一次刷题已经过去了.........嗯............我数一一下............整整十天,今天再来解一道算法题 由于这段时间准备简历,没咋写博客。。今天回来了!!!!!!!&…...

latex笔记
双列排版,右端margin不对齐怎么解决 如下图这种情况, 解决方法: 在文档开头引入ragged2e包 \usepackage{ragged2e}然后在子章节的开头添加 \justifying\subsection{camouflaged object detection based on coarse-to-fine strategy} \just…...
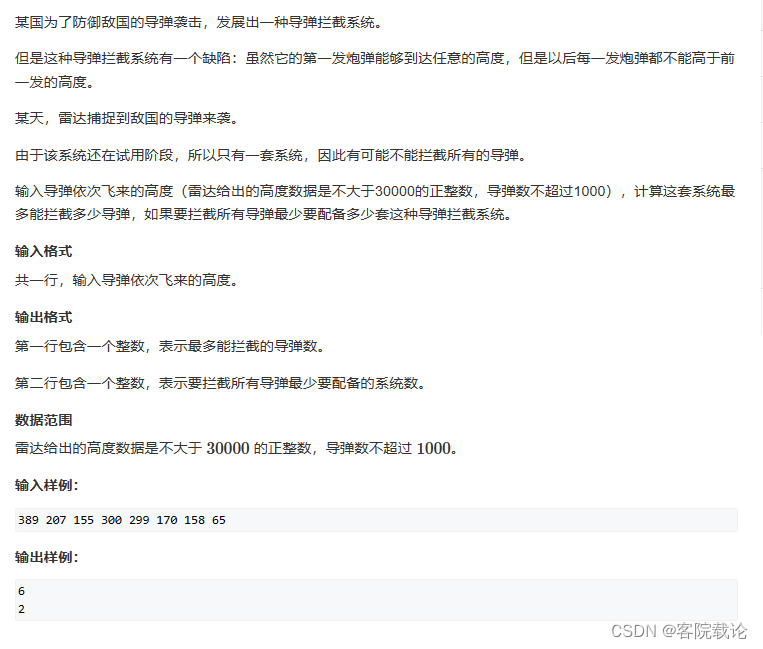
秋招算法——AcWing101——拦截导弹
文章目录 题目描述思路分析实现源码分析总结 题目描述 思路分析 目前是有一个笨办法,就是创建链表记录每一个最长下降子序列所对应的节点的链接,然后逐个记录所有结点的访问情况,直接所有节点都被访问过。这个方法不是很好,因为需…...

IDEA不能创建新项目和新模块
问题: IDEA不管是创建新项目还是新模块都创建不成功,会报如下图错误 解决方案: 在电脑设置里搜索 “防火墙和网络保护” ,打开如下图所示 找到你所安装的IDEA,更改设置,选中IDEA 最后,确定&am…...

WebRTC 的核心:RTCPeerConnection
WebRTC 的核心:RTCPeerConnection WebRTC 的核心:RTCPeerConnection创建 RTCPeerConnection 对象RTCPeerConnection 与本地音视频数据绑定媒体协商ICE什么是 Candidate?收集 Candidate交换 Candidate尝试连接 SDP 与 Candidate 消息的互换远端…...

LeetCode hot100-39-N
101. 对称二叉树给你一个二叉树的根节点 root , 检查它是否轴对称。做不出来哇,递归一生之敌 普通的对一棵树的递归遍历根本没办法只接比较左子树的左和右子树的右这样来比较,所以这题比较巧妙的是把这棵树当做两棵树一样去遍历比较。 官方…...

NumPy常用操作
目录 一:简介 二:NumPy 常用操作 三:总结 一:简介 是一个开源的Python库,它为Python提供了强大的多维数组对象和用于处理这些数组的函数。NumPy的核心是ndarray,它是一个高效的多维数组容器,用于存储和处理大规模的数据。NumPy还提供了许多数学函数,用于数组之间的操…...

高频电路中的隐形卫士:深度解析开关二极管BAV99的选型与应用
1. 高频电路中的隐形挑战:为什么需要BAV99? 当你设计一个高速数字接口或者射频模块时,最头疼的问题往往不是功能实现,而是那些看不见的高频干扰。我曾经在一个USB3.0接口保护电路的设计中,就因为选错了二极管ÿ…...

免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战
免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南
英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于…...

高光谱图像处理入门避坑指南:数据冗余、小样本和‘维数灾难’怎么破?
高光谱图像处理实战:破解数据冗余与小样本困境的技术路线 当第一次接触高光谱图像时,大多数研究者都会被其数据立方体的三维结构所震撼——数百个连续光谱波段构成的"超视觉"信息库,理论上能捕捉到人眼无法感知的物质指纹特征。但随…...

从‘拍脑袋’到‘有框架’:我是如何用MECE给团队Bug根因分析会‘降噪’的
从‘拍脑袋’到‘有框架’:我是如何用MECE给团队Bug根因分析会‘降噪’的 作为技术团队的负责人,你是否经历过这样的场景:Bug复盘会上,大家七嘴八舌地讨论着"测试没覆盖到"、"代码写得有问题"、"需求理解…...

并发编程小记---5.17
final类型的特点:final 变量:赋值后不能改(引用地址不可变)final 方法:不能被子类重写final 类:不能被继承引用类型:Java 数据类型就两种:基本数据类型:byte short int l…...

从FM收音机到5G基站:拆解DDS技术如何悄悄改变我们的通信设备
从FM收音机到5G基站:拆解DDS技术如何悄悄改变我们的通信设备 上世纪90年代,当人们第一次在车载收音机上按下"自动搜台"按钮时,很少有人意识到这个流畅体验背后隐藏着一项革命性技术——直接数字频率合成(DDS)…...
的四种“平替”方案全解析(含代码对比))
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比)
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比) 在实时渲染领域,次表面散射(Subsurface Scattering,简称SSS)一直是提升材质真实感的关键技…...
)
从零到一:用Air724UG 4G模块和Python,手把手搭建一个物联网数据上报系统(含完整代码)
从零构建基于Air724UG的物联网数据中台:Python全栈开发实战 当你拿起一块Air724UG 4G模块时,握在手中的不仅是通讯硬件,更是连接物理世界与数字世界的桥梁。这个火柴盒大小的模块能够将田间地头的土壤数据、工厂车间的设备状态、城市角落的环…...
)
为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单)
更多请点击: https://codechina.net 第一章:为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单) 我们对127条在Perplexity平台中返回空结果、过时答案或完全偏离编程意图的用户Qu…...