【传知代码】VRT: 关于视频修复的模型(论文复现)
前言:随着数字媒体技术的普及,制作和传播视频内容变得日益普遍。但是,视频中由于多种因素,例如传输、存储和录制设备等,经常出现质量上的问题,如图像模糊、噪声干扰和低清晰度等。这类问题对用户的体验和观看体验产生了直接的负面影响,因此,视频修复技术显得尤为关键。 其重要性不容忽视。
本文所涉及所有资源均在传知代码平台可获取
概述
视频修复技术(Video Restoration Techniques,VRT)是一种利用计算机视觉和图像处理技术来改善、修复和恢复视频内容的方法。其主要目的是消除视频中存在的噪声、模糊、失真、抖动等问题,使视频内容更清晰、更稳定,并且提高其视觉质量和观感。其实现的作用是:
1)噪声去除:使用去噪算法来消除视频中的各种类型的噪声,例如高斯噪声、椒盐噪声等,以提高图像质量和清晰度。
2)运动补偿:通过分析视频中的运动信息,利用运动估计和补偿技术来减少视频中的运动模糊,使图像更加清晰和稳定。
3)图像恢复:使用插值、补洞和修复算法来修复视频中存在的缺失、损坏或者破坏的图像部分,以恢复视频的完整性和连贯性。
4)超分辨率重建:利用超分辨率重建技术来增加视频的空间分辨率,从而提高图像的清晰度和细节展现能力。
视频修复与单一图像修复的区别在于:前者主要关注从单一图像中恢复丢失或损坏的信息,而后者则涉及对整个视频序列的处理。在进行视频修复时,需要充分考虑帧与帧之间的时间序列关系,这样可以更有效地利用时间信息来进行修复工作。这样的时序关联可能包括相邻帧间的动态运动、变动等相关信息。
关于时间信息的价值:视频里的这些时间数据在理解和修复过程中起到了不可或缺的作用。视频修复过程中,相邻帧的相互联系、动态的变动以及视频序列的动态变化等因素都为其提供了丰富的背景信息。传统的单一图像修复技术不能充分利用这些时间序列信息,而视频修复则专注于通过综合多帧信息来提升修复的效果。
在处理多帧视频时,我们面临了一系列新的挑战,包括多帧之间的对齐、在动态环境中信息的变动以及长时间序列的依赖性等问题。
为了实现更为精确和稳健的视频修复,我们需要构建一个能够最大化利用这些信息的机制。
VRT模型的详细说明
VRT 模型是指视频修复技术(Video Restoration Techniques)的模型,它是一种利用深度学习和计算机视觉技术来改善、修复和恢复视频内容的模型。这些模型通常基于深度神经网络,能够学习视频中的复杂模式和结构,并自动进行修复和增强。其整体框架如下:
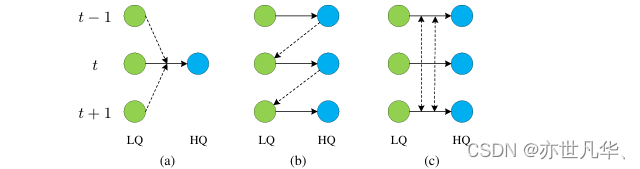
Figure 1.绿色圆圈:低质量(LQ)的输入帧;蓝色圆圈:高质量(HQ)的输出帧。t-1,t及t+1为帧序号;虚线是用来描述不同帧融合的。
VRT的总体结构:Video Restoration Transformer(VRT)是一个致力于视频修复任务的深度学习模型。其整体框架由多个尺度组成,每个尺度包含两个关键模块:Temporal Mutual Self Attention(TMSA)和Parallel Warping。VRT的目的是通过并行帧预测与长时序依赖建模的方法来充分利用多帧视频信息实现高效修复。
VRT具有多尺度结构,各尺度内含有TMSA与Parallel Warping两模块。该设计使模型能够运行于不同分辨率特征,从而较好地拟合视频序列的细节及动态变化情况。

TMSA模块:Temporal Mutual Self Attention负责把视频序列划分成细小的片段,并将相互注意力应用到这些片段中,进行联合运动估计,特征对齐以及特征融合等。同时利用自注意力机制对特征进行提取。该设计使模型可以联合处理多帧信息,较好地解决了长时序依赖建模问题。
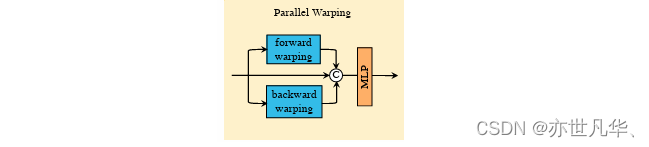
Parallel Warping模块:Parallel Warping模块用于通过并行特征变形从相邻帧中进一步融合信息。它利用平行特征变形有效地将相邻帧信息融合到当前帧中。该步骤与特征的引导变形相似,进一步提升了该模型多帧时序信息使用效率。
下图展示了提出的Video Restoration Transformer(VRT)的框架。给定T个低质量输入帧,VRT并行地重建T个高质量帧。它通过多尺度共同提取特征、处理对齐问题,并在不同尺度上融合时间信息。在每个尺度上,VRT具有两种模块:时间互相自注意力和平行变形。为了清晰起见,图中省略了不同尺度之间的下采样和上采样操作。

实验结果表现
VRT在不同视频修复任务上的表现,如下图所示:

不同任务表现: VRT在视频超分辨率、视频去模糊、视频去噪、视频帧插值和时空视频超分辨率等五个任务上都进行了实验。通过对比实验结果,VRT展现了在各项任务中的优越性能,提供了高质量的修复效果。

性能对比: VRT与其他当前主流的视频修复模型进行了性能对比,涵盖了14个基准数据集。实验结果显示,VRT在各个数据集上都明显优于其他模型,表现出色。尤其在某些数据集上,VRT的性能提升高达2.16dB,凸显了其在视频修复领域的卓越性能。
视频修复技术(VRT)的优势和创新点主要体现在以下几个方面:
1. 深度学习驱动的修复模型:VRT采用深度学习技术,如卷积神经网络(CNN)和生成对抗网络(GAN),能够自动学习视频中的复杂模式和结构。相较于传统的基于规则的方法,深度学习模型在处理视频修复任务上表现出更高的灵活性和效果。
2. 端到端的修复过程:VRT模型通常采用端到端的修复过程,即直接从损坏或低质量的视频帧到修复后的视频帧,无需手动干预或多个步骤的流程。这种端到端的方式简化了修复流程,提高了效率。
3. 多种修复技术的综合应用:VRT模型综合运用了多种修复技术,如噪声去除、运动补偿、图像恢复等,能够在多个方面改善视频质量。通过这种综合应用,VRT能够更全面地处理视频中的问题,提供更优质的修复结果。
4. 大规模训练数据的利用:VRT模型通常使用大规模的真实视频数据进行训练,这些数据涵盖了各种不同来源和类型的视频,包括电影、电视节目、监控视频等。通过利用这些数据,VRT模型能够学习到更广泛、更真实的修复模式,提升了修复效果的准确性和鲁棒性。
5. 实时性能和效果的提升:随着硬件和算法的不断进步,现代VRT模型在实时性能和修复效果方面都取得了显著的提升。一些优化的算法和硬件加速技术使得VRT能够在更短的时间内完成修复任务,并且在视觉上提供更加真实和清晰的修复结果。
总的来说,视频修复技术(VRT)利用深度学习等先进技术,结合多种修复技术,综合应用大规模训练数据,实现了对视频内容的高效、自动、全面修复,为视频产业和相关领域带来了巨大的优势和创新点。 VRT在不同任务上的性能提升如下图所示:

核心代码实现
这里给出视频恢复(Video Restoration)模型的测试脚本,用于在测试集上评估模型的性能:
导入依赖库和模块:
import argparse
import cv2
import glob
import os
import torch
import requests
import numpy as np
from os import path as osp
from collections import OrderedDict
from torch.utils.data import DataLoaderfrom models.network_vrt import VRT as net
from utils import utils_image as util
from data.dataset_video_test import VideoRecurrentTestDataset, VideoTestVimeo90KDataset, \SingleVideoRecurrentTestDataset, VFI_DAVIS, VFI_UCF101, VFI_Vid4定义主函数 main():
def main():parser = argparse.ArgumentParser()# ...(解析命令行参数的设置)args = parser.parse_args()# 定义设备(使用GPU或CPU)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 准备模型model = prepare_model_dataset(args)model.eval()model = model.to(device)# ...(根据数据集类型准备测试集)# 定义保存结果的目录save_dir = f'results/{args.task}'if args.save_result:os.makedirs(save_dir, exist_ok=True)test_results = OrderedDict()# ...(初始化用于保存评估结果的数据结构)# 遍历测试集进行测试for idx, batch in enumerate(test_loader):# ...(加载测试数据)with torch.no_grad():output = test_video(lq, model, args)# ...(处理模型输出,保存结果,计算评估指标)# 输出最终评估结果# ...准备模型和数据集的函数 prepare_model_dataset(args):
def prepare_model_dataset(args):# ...(根据任务类型选择合适的模型和数据集)return model测试视频的函数和视频片段的函数:
def test_video(lq, model, args):# ...(根据需求测试整个视频或分割成多个片段进行测试)return output
def test_clip(lq, model, args):# ...(根据需求测试整个片段或分割成多个子区域进行测试)return output写在最后
VRT通过深度学习驱动的修复模型、端到端的修复过程、多种修复技术的综合应用、大规模训练数据的利用以及实时性能和效果的提升,实现了对视频内容的高效、自动、全面修复,为视频产业和相关领域带来了重大的优势和创新点。
通过对VRT的全面介绍和深入解析,我们不难发现它在视频修复领域的卓越贡献。VRT通过并行帧预测、长时序依赖建模和多尺度设计等关键创新点,显著提升了视频修复的性能。其在多个任务上的卓越表现以及在实际应用中的广泛潜力,使得VRT成为视频修复领域的前沿技术。
鼓励更多研究者深入挖掘视频修复领域的技术挑战,并通过VRT的经验为该领域的未来发展做出更多贡献。不仅如此,VRT的创新性和通用性也为深度学习在其他领域的研究提供了有益的参考,推动了整个人工智能领域的发展。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号

相关文章:
【传知代码】VRT: 关于视频修复的模型(论文复现)
前言:随着数字媒体技术的普及,制作和传播视频内容变得日益普遍。但是,视频中由于多种因素,例如传输、存储和录制设备等,经常出现质量上的问题,如图像模糊、噪声干扰和低清晰度等。这类问题对用户的体验和观…...

不用投稿邮箱,怎样向各大新闻媒体投稿?
身为单位的信息宣传员,我深知肩上责任重大。每个月,完成单位在媒体上投稿发表文章的考核任务,就如同一场无声的赛跑,既要保证速度,更要注重质量。起初,我遵循“前辈们”的老路,一头扎进了邮箱投稿的海洋。但很快,现实给了我一记重拳——邮箱投稿的竞争犹如千军万马过独木桥,稿件…...
NAT技术总结与双向NAT配置案例
NAT的转换方式: 1.静态转换:固定的一对一IP地址映射。 interface GigabitEthernet0/0/1 ip address 122.1.2.24 nat static global 122.1.2.1 inside 192.168.1.1 #在路由器出接口 公网地址 私网地址。 2.动态转换:Basic NAT nat address-gr…...

mysql的explain
explain可以用于select,delete,insert,update的statement。 当explain用于statement时,mysql将会给出其优化器(optimizer)的执行计划。 通过explain字段生成执行计划表。下面来解析这个执行计划表的每一列…...
SpringBoot+Vue实现图片滑块和文字点击验证码
一、背景 1.1 概述 传统字符型验证码展示-填写字符-比对答案的流程,目前已可被机器暴力破解,应用程序容易被自动化脚本和机器人攻击。 摒弃传统字符型验证码,采用行为验证码采用嵌入式集成方式,接入方便,安全&#…...
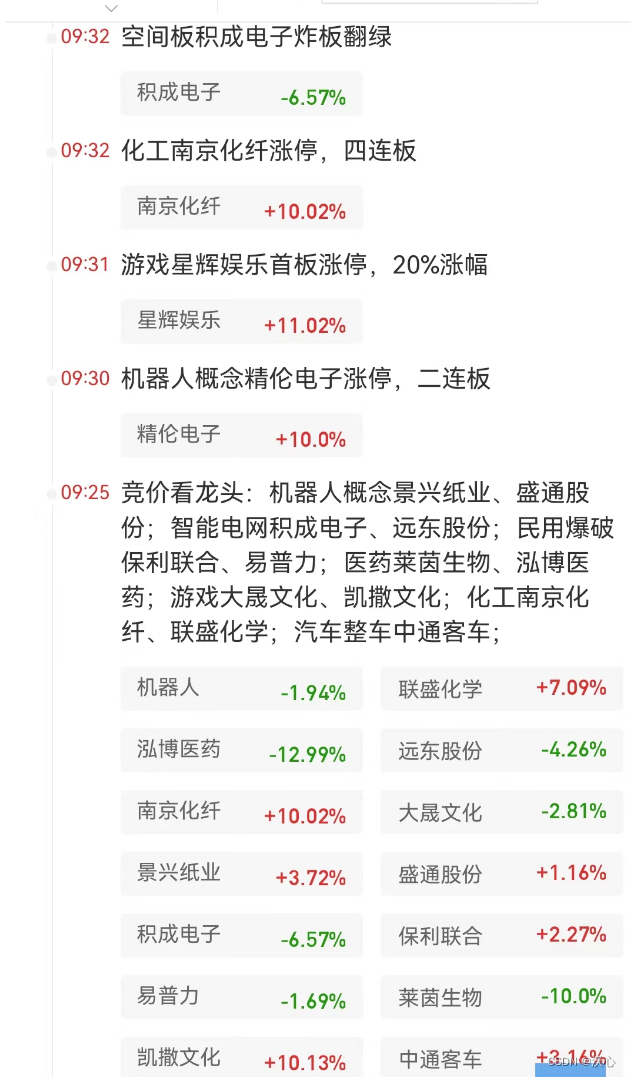
每日复盘-20240515
仅用于记录当天的市场情况,用于统计交易策略的适用情况,以便程序回测 短线核心:不参与任何级别的调整,采用龙空龙模式 一支股票 10%的时候可以操作, 90%的时间适合空仓等待 国联证券 (1)|[9:25]|[133765万]|31.12 一…...
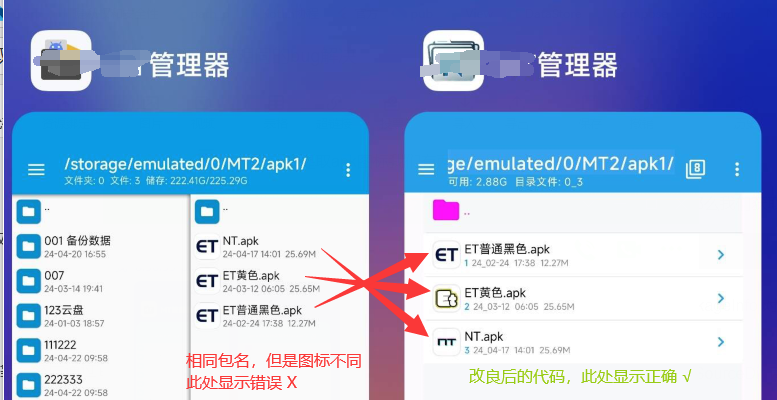
【Android】Apk图标的提取、相同目录下相同包名提取的不同图标apk但是提取结果相同的bug解决
一般安卓提取apk图标我们有两种常用方法: 1、如果已经获取到 ApplicationInfo 对象(假设名为 appInfo),那么我们获取方法为: appInfo.loadIcon(packageManager)// 返回一个 Drawable 对象2、 如果还没获取到 Applica…...

高校普法|基于SSM+vue的高校普法系统的设计与实现(源码+数据库+文档)
高校普法系统 目录 基于SSM+vue的高校普法系统的设计与实现 一、前言 二、系统设计 三、系统功能设计 1系统功能模块 2管理员功能模块 3律师功能模块 4学生功能模块 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获…...

pytest教程-47-钩子函数-pytest_sessionfinish
领取资料,咨询答疑,请➕wei: June__Go 上一小节我们学习了pytest_sessionstart钩子函数的使用方法,本小节我们讲解一下pytest_sessionfinish钩子函数的使用方法。 pytest_sessionfinish 钩子函数在 Pytest 测试会话结束时调用,…...
如何使用Python下载哔哩哔哩(Bilibili)视频字幕
在本文中,我将向大家展示如何使用Python下载哔哩哔哩(Bilibili)视频的字幕。通过这个方法,你可以轻松地获取你喜欢的视频的字幕文件,方便学习和交流。 准备工作 在开始之前,我们需要安装一些必要的库&…...

IP代理网络协议介绍
在IP代理页面上,存在HTTP/HTTPS/Socks5三种协议。它们都是客户端与服务器之间交互的协议。 HTTP HTTP又称之为超文本传输协议,在因特网使用范围广泛。它是一种请求/响应模型,客户端向服务器发送请求,服务器解析请求后对客户端作出…...

渗透相关面试+流量分析
文章目录 简单自我介绍上一个工作的主要内容Hvv的分组和流程你在hvv/攻防演练中取得了哪些成绩? 二、渗透相关面试题基础端口号以及入侵方式OSI七层协议响应状态码都有哪些?**WAF和IPS的区别**盲注是什么?java内存马类型**内存马有几种类型**…...
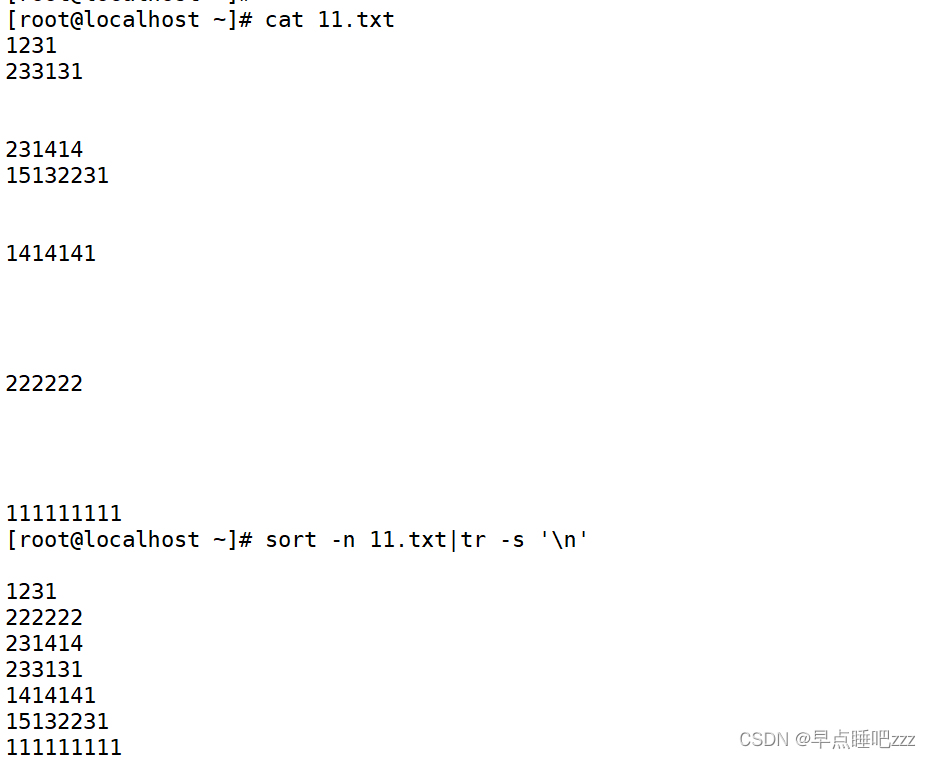
Shell之高效文本处理命令
目录 一、排序命令—sort 基本语法 常用选项 二、去重命令—uniq 基本语法 常用选项 三、替换命令—tr 基本语法: 常用选项 四、裁剪命令—cut 基本语法: 常用选项 字符串分片 五、拆分命令—split 基本语法: 六、 文件…...

u3d的ab文件注意事项
//----------------LoadAllAB.cs--------------------- using System.Collections;using UnityEngine;namespace System.IO{public class LoadAllAB : MonoBehaviour{ //读取本地string path "Assets/Actors/lznh/ab/animation/t_bl/";// Use this for initiali…...
Go微服务开源框架kratos的依赖注入关系总结
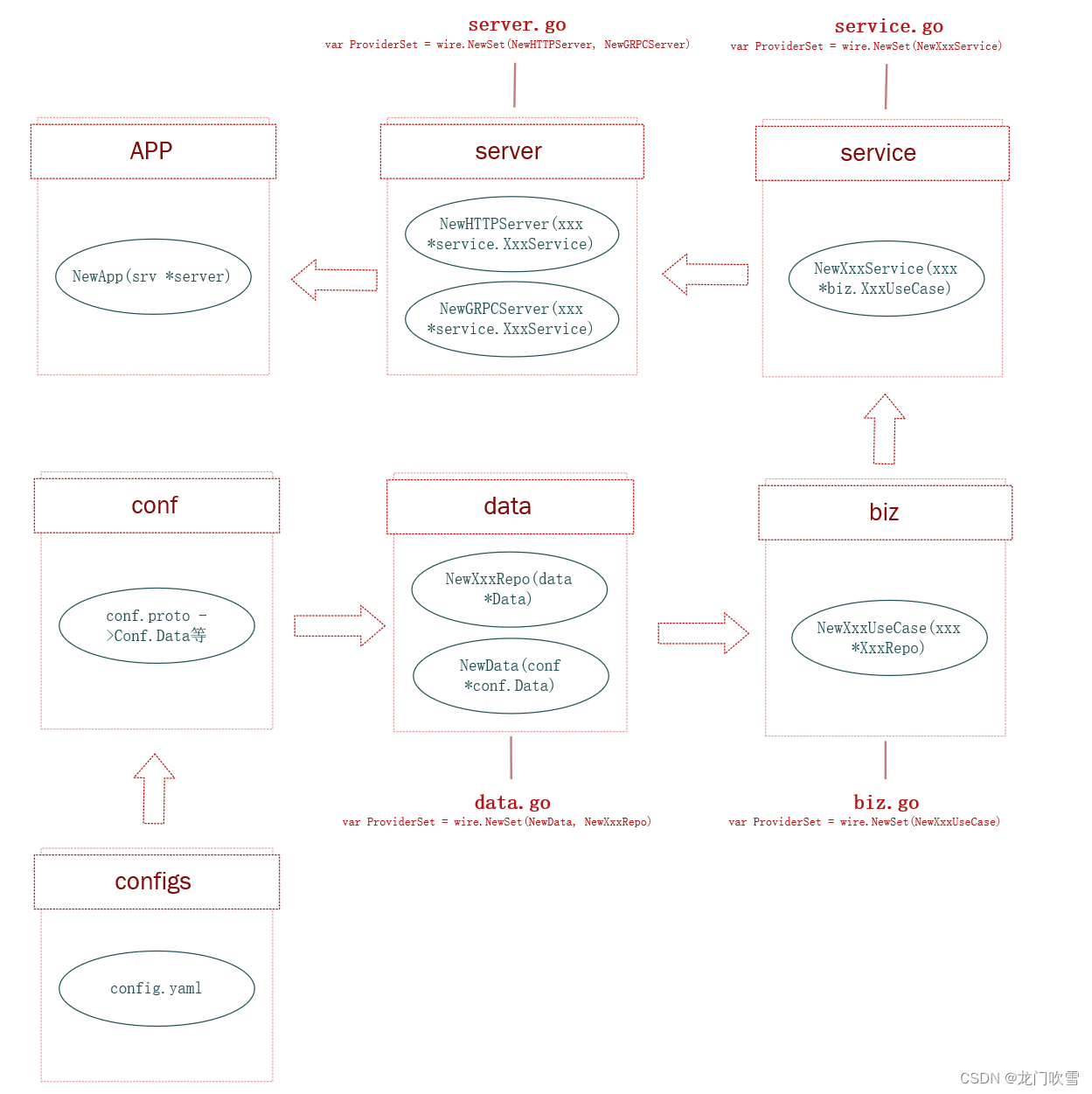
该文章为学习开源微服务框架kratos的学习笔记!官方文档见:简介 | Kratos Kratos 一套轻量级 Go 微服务框架,包含大量微服务相关框架及工具。 一、Kratos 项目结构简介 通过 Kratos 工具生成的 Go工程化项目模板如下: applicati…...

Linux 第三十二章
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C,linux 🔥座右铭:“不要等到什么都没有了…...

手机号码的正则表达式
手机号码的正则表达式会根据不同的国家/地区有所不同,因为每个国家/地区都有自己特定的手机号码格式。但是,我可以为你提供一个通用的正则表达式模板,并给出一些具体国家/地区的例子。 通用模板 一个基本的手机号码正则表达式模板可能如下所…...

机器学习入门介绍
各位大佬好 ,这里是阿川的博客 , 祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 目录 三大方向机器学习产生的原因机器如何学习…...

一文说通用户故事点数是什么?
一文说通用户故事点数是什么? 第26期:一文说通用户故事点数是什么? 用户故事点数是一种采用相对估算法进行估算的一种工具,一般采用斐波那契数列表征用户故事里说的大小,采用0 1 2 3 5 8 13这样的一些数字来表征用户…...

GAME101-Lecture07学习
前言 今天主要讲shading(着色)。在讲着色前,要先讲图形中三角形出现遮挡问题的方法(深度缓存或缓冲)。 先采样再模糊错误:对信号的频谱进行翻译(在这期间会有频谱的混叠)ÿ…...
)
保姆级教程:在Ubuntu上配置Lotus基准测试环境(含参数下载与自定义GPU支持)
在Ubuntu上配置Lotus基准测试环境的完整指南 对于Filecoin生态系统的参与者来说,理解网络性能并优化硬件配置至关重要。本文将带您完成在Ubuntu系统上搭建Lotus基准测试环境的全过程,从基础环境准备到高级GPU自定义支持,为您提供一份详尽的实…...

别再为前后端AES加解密头疼了!手把手教你用CryptoJS和Java 8实现无缝对接
跨平台AES加解密实战:打通CryptoJS与Java的密钥对齐与编码陷阱 前后端分离架构下,数据安全传输始终是开发者的核心关切。当看到控制台抛出javax.crypto.BadPaddingException: Given final block not properly padded这类错误时,多数开发者都会…...

思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析
思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版烦恼吗?字体选择困…...

从原理到实战:晶体管开关电路设计与常见问题解析
1. 项目概述:为什么我们需要晶体管开关?如果你玩过Arduino或者树莓派,肯定遇到过这样的尴尬:想用单片机的一个GPIO引脚直接点亮一个12V的汽车大灯,或者驱动一个小马达,结果要么灯不亮,要么马达纹…...

国产巴伦替代 Mini-Circuits TCM1‑63AX+,H3‑TCM1‑63AX+ 现货可原位替代
最近很多做射频 / 通信 / 无线项目的朋友都在找Mini TCM1‑63AX 的国产替代,既要性能对标、又要现货快交、还要价格友好。给大家分享一款恒利泰 H3‑TCM1‑63AX,完全原位替代 TCM1‑63AX,参数一致、脚位兼容,直接替换不用改板。 ✅…...

ChatGPT实时支付功能“不可见”的真相:不是没上线,而是被GDPR/SCA双重拦截——3分钟自查你的地区、浏览器、MFA配置是否全达标?
更多请点击: https://codechina.net 第一章:ChatGPT实时支付功能在哪里 ChatGPT 本身并不原生支持实时支付功能。OpenAI 官方发布的 ChatGPT(包括免费版、Plus 订阅版及 Team/Enterprise 版)定位为人工智能对话助手,其…...

Cesium 体积云进阶:从Perlin-Worley噪声到动态云区渲染
1. 从一团云到动态云区的技术跃迁 第一次在Cesium里用Perlin噪声做出那团棉花糖般的云时,我兴奋地截了十几张图发朋友圈。但很快发现一个问题——这团云放在城市上空像块棉花,放在山脉间又像团雾气,怎么看都不像自然界的云层。真正的云应该有…...

避坑指南:LVGL Bar控件在RTOS和低内存MCU上的5个常见问题与解决方案
避坑指南:LVGL Bar控件在RTOS和低内存MCU上的5个常见问题与解决方案 在嵌入式开发中,LVGL作为轻量级图形库被广泛应用,但其Bar控件(进度条)在资源受限环境(如FreeRTOS、内存<64KB的MCU)下常出…...

告别龟速传输:在AutoDL上利用AutoPanel高效迁移大容量数据集的实战技巧
1. 为什么大容量数据集传输总是慢如蜗牛? 每次在AutoDL上处理大容量数据集时,最让人抓狂的就是漫长的传输等待。我清楚地记得第一次尝试上传15GB图像数据集时的绝望——整整6个小时的等待,期间还因为网络波动失败了两次。后来才发现ÿ…...

轻松管理AD域:一款基于.NET的Web工具推荐
轻松管理AD域:一款基于.NET的Web工具推荐 【下载地址】AD域管理Web版工具 本资源提供了一个基于微软官方文档,使用.NET技术开发的Web AD域管理工具。该工具采用简单的HTML和一般处理程序(Generic Handler)来实现,旨在为…...