云原生时代顶流消息中间件Apache Pulsar部署实操之Pulsar IO与Pulsar SQL
文章目录
- Pulsar IO (Connector连接器)
- 基础定义
- 安装Pulsar和内置连接器
- 连接Pulsar到Cassandra
- 安装cassandra集群
- 配置Cassandra接收器
- 创建Cassandra Sink
- 验证Cassandra Sink结果
- 删除Cassandra Sink
- 连接Pulsar到PostgreSQL
- 安装PostgreSQL集群
- 配置JDBC接收器
- 创建JDBC Sink
- 验证JDBC Sink结果
- Pulsar SQL
- 定义
- 简单使用
Pulsar IO (Connector连接器)
基础定义
Pulsar IO连接器能够轻松地创建、部署和管理与外部系统(如Apache Cassandra、Aerospike等)交互的连接器。IO连接器有两种类型:源连接器和接收器连接器。

可以通过Connector Admin CLI使用源和接收器子命令管理Pulsar连接器(例如,在连接器上创建、更新、启动、停止、重新启动、重新加载、删除和执行其他操作)。有关最新和完整的信息,请参阅Pulsar管理文档。
安装Pulsar和内置连接器
在将Pulsar连接到数据库之前,需要先安装Pulsar和所需的内置连接器。要启用Pulsar连接器,您需要在下载页面上下载连接器的tarball版本。
# 下载最新版本2.11.0的pulsar-io-cassandra和pulsar-io-jdbc-postgres,需要什么连接器可以从官方查看是否支持并下载,这里举例就下载两个
https://www.apache.org/dyn/mirrors/mirrors.cgi?action=download&filename=pulsar/pulsar-2.11.0/connectors/pulsar-io-cassandra-2.11.0.nar
https://www.apache.org/dyn/mirrors/mirrors.cgi?action=download&filename=pulsar/pulsar-2.11.0/connectors/pulsar-io-jdbc-postgres-2.11.0.nar
# 在pulsar根目录下创建目录
mkdir connectors
# 将压缩文件移动connectors目录
mv pulsar-io-jdbc-postgres-2.11.0.nar pulsar-io-jdbc-postgres-2.11.0.nar connectors
# 重启pulsar
# 查看可用连接器列表
curl -w '\n' -s http://localhost:8080/admin/v2/functions/connectors

连接Pulsar到Cassandra
安装cassandra集群
# 下载镜像并启动cassandra测试容器
docker run -d --rm --name=cassandra -p 9042:9042 cassandra
# 查看进程
docker ps
# 查看运行日志
docker logs cassandra
# 等待一小段时间后查看Cassandra集群状态
docker exec cassandra nodetool status
# 使用cqlsh连接到Cassandra集群

# 使用cqlsh连接到Cassandra集群
docker exec -ti cassandra cqlsh localhost
# 创建一个密钥空间pulsar_itxs_keyspace
CREATE KEYSPACE pulsar_itxs_keyspace WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
# 创建一个表pulsar_itxs_table
USE pulsar_itxs_keyspace;
CREATE TABLE pulsar_itxs_table (key text PRIMARY KEY, col text);

配置Cassandra接收器
现在已经有一个Cassandra集群在本地运行;要运行Cassandra接收器连接器,需要准备一个配置文件,其中包括Pulsar连接器运行时需要知道的信息,例如Pulsar连接器如何找到Cassandra集群,Pulsar连接器用于写入Pulsar消息的键空间和表是什么等等;可以使用Json或者Yaml这两种格式创建配置文件。
vim examples/cassandra-sink.json
{"roots": "192.168.3.100:9042","keyspace": "pulsar_itxs_keyspace","columnFamily": "pulsar_itxs_table","keyname": "key","columnName": "col"
}
vim examples/cassandra-sink.yml
configs:roots: "192.168.3.100:9042"keyspace: "pulsar_itxs_keyspace"columnFamily: "pulsar_itxs_table"keyname: "key"columnName: "col"
创建Cassandra Sink
可以使用Connector Admin CLI创建sink连接器和操作。运行下面命令来创建一个Cassandra接收器连接器,接收器类型为Cassandra,配置文件为上一步创建的examples/cassandra-sink.yml。
bin/pulsar-admin sinks create \--tenant my-test \--namespace my-namespace \--name cassandra-itxs-sink \--sink-type cassandra \--sink-config-file examples/cassandra-sink.yml \--inputs persistent://my-test/my-namespace/itxs_cassandra
命令执行后,Pulsar创建接收器连接器cassandra-itxs-sink。这个接收器连接器作为Pulsar函数运行,并将主题itxs_cassandra中产生的消息写入Cassandra表pulsar_itxs_table;

可以使用Connector Admin CLI对连接器进行监控和其他操作。
- 获取连接器的信息
bin/pulsar-admin sinks get \--tenant my-test \--namespace my-namespace \--name cassandra-itxs-sink
- 检查连接器的状态
bin/pulsar-admin sinks status \--tenant my-test \--namespace my-namespace \--name cassandra-itxs-sink
验证Cassandra Sink结果
生成一些消息到Cassandra接收器itxs_cassandra的输入主题
for i in {0..9}; do bin/pulsar-client produce -m "itxskey-$i" -n 1 persistent://my-test/my-namespace/itxs_cassandra; done
再次查看连接器的状态,可以有10条记录处理统计信息
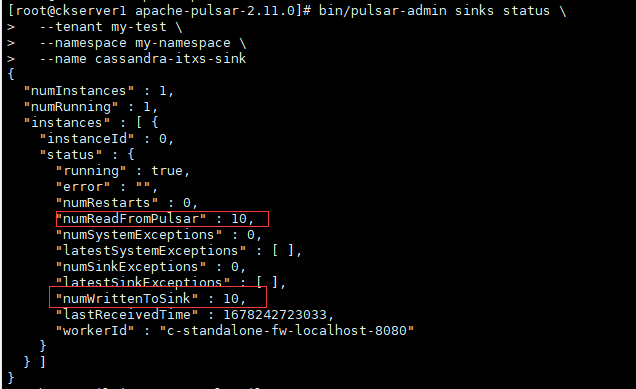
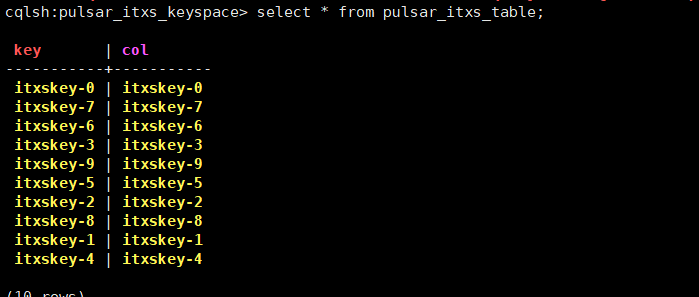
查看Cassandra的pulsar_itxs_table
USE pulsar_itxs_keyspace;
select * from pulsar_itxs_table;
删除Cassandra Sink
bin/pulsar-admin sinks delete \--tenant my-test \--namespace my-namespace \--name cassandra-itxs-sink
连接Pulsar到PostgreSQL
安装PostgreSQL集群
这里使用PostgreSQL 12 docker镜像在docker中启动一个单节点PostgreSQL集群。
# 从Docker中拉取PostgreSQL 12映像
docker pull postgres:12
# 启动postgres容器
docker run -d -it --rm \--name pulsar-postgres \-p 5432:5432 \-e POSTGRES_PASSWORD=password \-e POSTGRES_USER=postgres \postgres:12
# 查看运行日志
docker logs -f pulsar-postgres
# 进入容器
docker exec -it pulsar-postgres /bin/bash
# 使用默认用户名和密码登录PostgreSQL
psql -U postgres postgres
# 使用以下命令创建pulsar_postgres_jdbc_sink表:
create table if not exists pulsar_postgres_jdbc_sink
(
id serial PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
配置JDBC接收器
现在有一个本地运行的PostgreSQ,接下来需要配置JDBC接收器连接器。
- 创建配置文件vim connectors/pulsar-postgres-jdbc-sink.yaml
configs:userName: "postgres"password: "password"jdbcUrl: "jdbc:postgresql://192.169.3.100:5432/postgres"tableName: "pulsar_postgres_jdbc_sink"
创建JDBC Sink
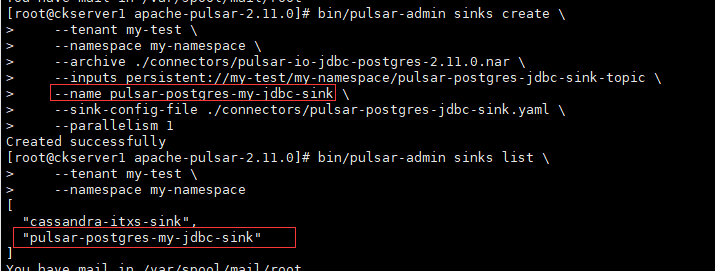
执行下面命令后,Pulsar将创建接收器连接器pulse -postgres-jdbc-sink。这个sink连接器作为Pulsar函数运行,并将Topic为pulsar-postgres-jdbc-sink-topic中产生的消息写入PostgreSQL表pulsar_postgres_jdbc_sink。
bin/pulsar-admin sinks create \--tenant my-test \--namespace my-namespace \--archive ./connectors/pulsar-io-jdbc-postgres-2.11.0.nar \--inputs persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic \--name pulsar-postgres-my-jdbc-sink \--sink-config-file ./connectors/pulsar-postgres-jdbc-sink.yaml \--parallelism 1
列出所有的sink
bin/pulsar-admin sinks list \--tenant my-test \--namespace my-namespace
验证JDBC Sink结果
通过JavaAPI生成一些消息到Cassandra接收器pulsar-postgres-jdbc-sink-topic这个主题,在Java项目添加maven依赖
<properties><pulsar.version>2.11.0</pulsar.version></properties> <dependency><groupId>org.apache.pulsar</groupId><artifactId>pulsar-client</artifactId><version>${pulsar.version}</version></dependency>
这里演示实体类成员变量简单就直接使用public声明了
package sn.itxs.pulsar.io;public class User{public int id;public String name;
}
新增ClientDemo.java
package sn.itxs.pulsar.io;import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.impl.schema.AvroSchema;public class ClientDemo {public static void main(String[] args) throws Exception {PulsarClient client = null;Producer<User> producer = null;try {client = PulsarClient.builder().serviceUrl("pulsar://192.168.5.52:6650").build();producer = client.newProducer(AvroSchema.of(User.class)).topic("persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic").create();User user = new User();int index = 10;while (index++ < 20) {try {user.id = index;user.name = "this is a test " + index;producer.newMessage().value(user).send();} catch (Exception e) {e.printStackTrace();}}System.out.println("send finish");} catch (Exception e) {e.printStackTrace();}finally {if (producer!=null){producer.close();}if (client!=null){client.close();}}}
}
运行程序后查看PostgreSQL表pulsar_postgres_jdbc_sink,已经有刚才
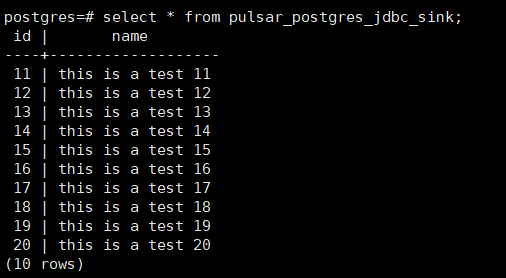
上面由于在Java中创建了Schema,因此不需要手工创建,可以查看当前persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic主体已生成Schema信息如下:
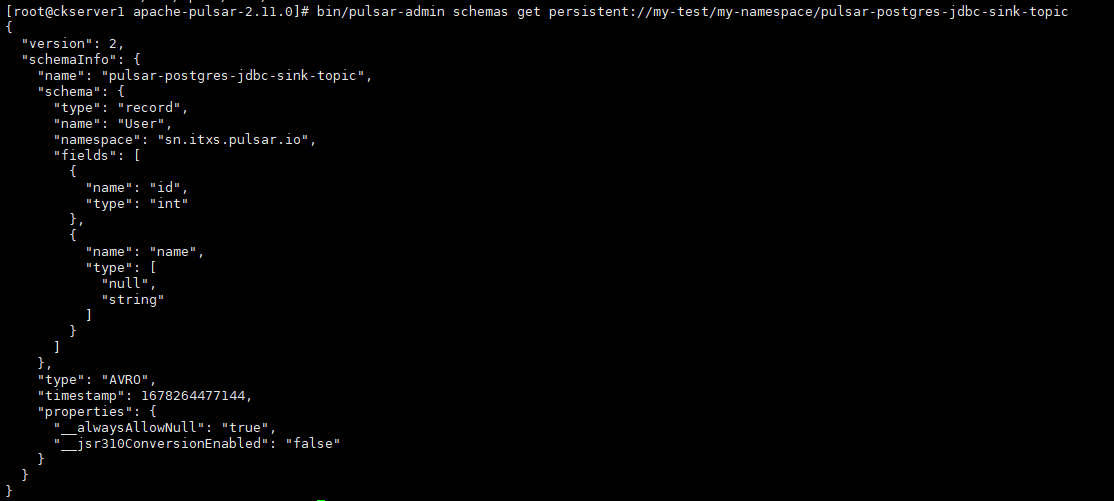
如果要从pulsar-admin命令行创建schema可以这样操作
- 创建schema,创建一个avro-schema文件,将以下内容复制到该文件中,并将该文件放在pulsar/connectors文件夹中。vim connectors/avro-schema
{"type": "AVRO","schema": "{\"type\":\"record\",\"name\":\"Test\",\"fields\":[{\"name\":\"id\",\"type\":[\"null\",\"int\"]},{\"name\":\"name\",\"type\":[\"null\",\"string\"]}]}","properties": {}
}
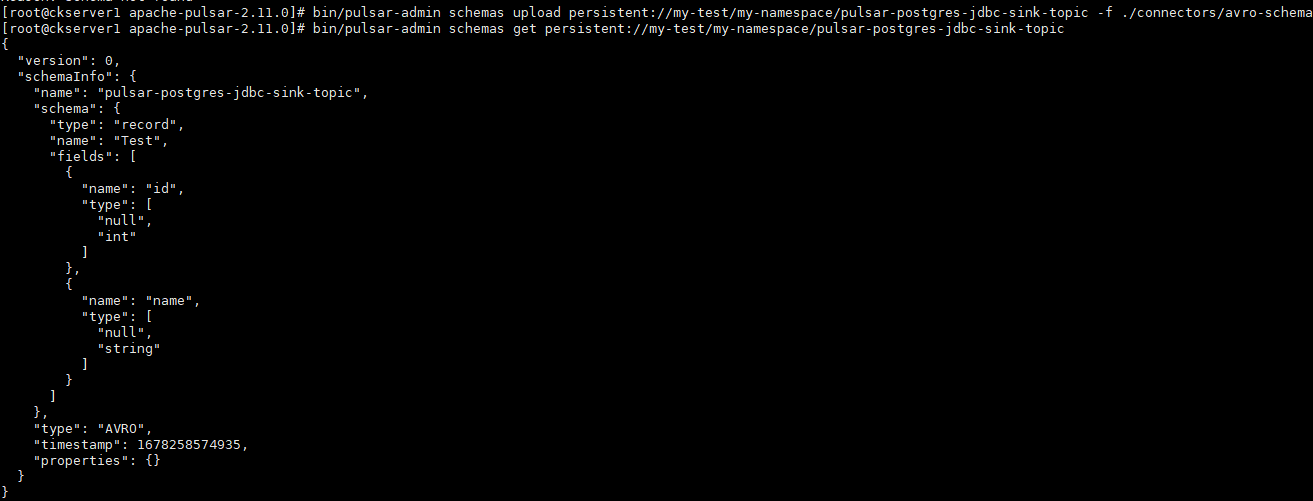
- 上传schema到topic,将avro-schema模式上传到pulsar-postgres-jdbc-sink-topic主题
bin/pulsar-admin schemas upload persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic -f ./connectors/avro-schema
- 检查模式是否上传成功。
bin/pulsar-admin schemas get persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic1
如需stop停止、restart重启指定的sinks可以如下操作,当然也可以更新指定sinks,详细命令可以查阅官网
bin/pulsar-admin sinks stop \--tenant my-test \--namespace my-namespace \--name pulsar-postgres-my-jdbc-sink \
Pulsar SQL
定义
Apache Pulsar用于存储事件数据流,事件数据由预定义的字段构成。通过模式注册表的实现,可以在Pulsar中存储结构化数据,并使用Trino(以前是Presto SQL)查询数据。作为Pulsar SQL的核心,Pulsar Trino插件使Trino集群中的Trino worker能够查询来自Pulsar的数据.
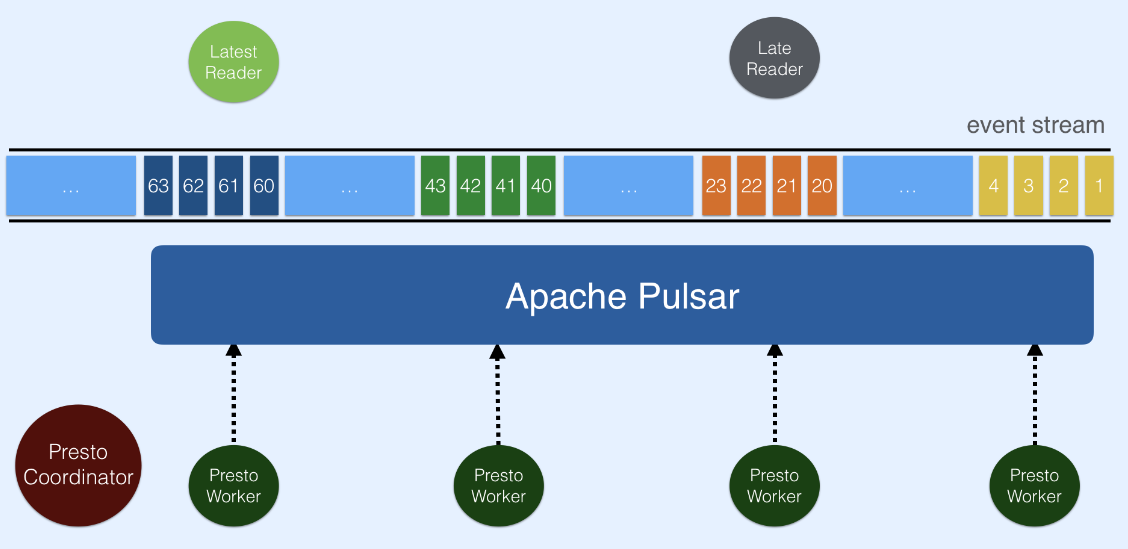
由于Pulsar采用了基于两级段的架构,因此查询性能高效且可扩展性强。Pulsar中的主题在Apache BookKeeper中存储为段。每个主题段被复制到一些BookKeeper节点上,从而支持并发读和高读吞吐量。在Pulsar Trino连接器中,数据直接从BookKeeper中读取,因此Trino worker可以同时从水平可扩展数量的BookKeeper节点中读取
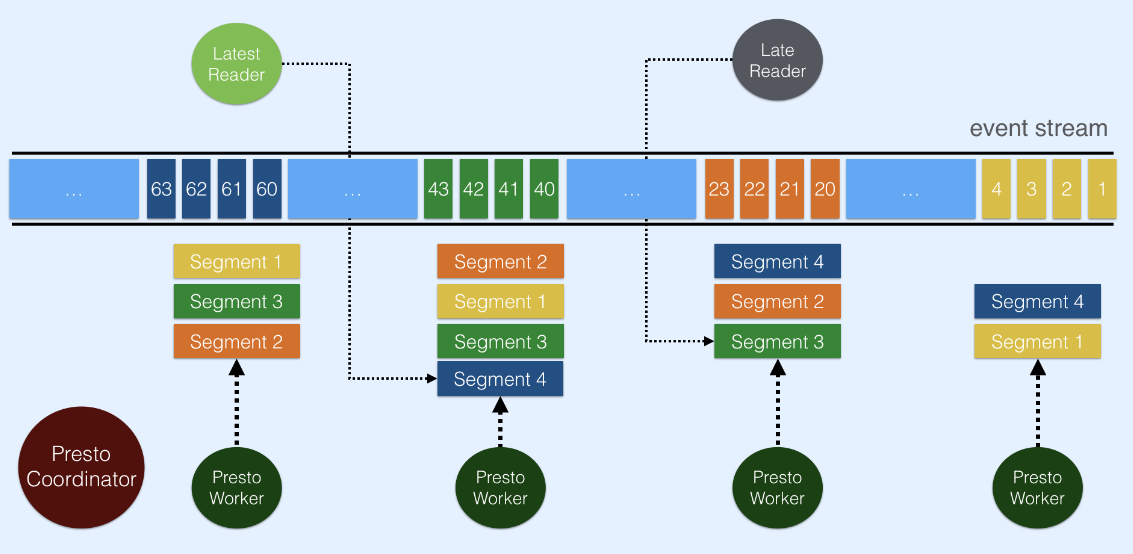
简单使用
在Pulsar中查询数据前,需要安装Pulsar和内置连接器。
# 这里演示就直接启动独立集群
PULSAR_STANDALONE_USE_ZOOKEEPER=1 ./bin/pulsar standalone
# 启动一个Pulsar SQL worker
./bin/pulsar sql-worker run
# 初始化Pulsar独立集群和SQL worker后,执行SQL CLI:
./bin/pulsar sql
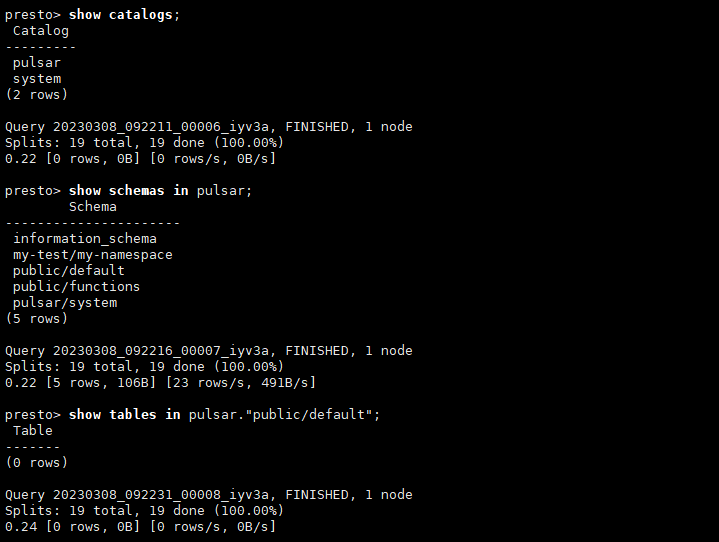
show catalogs;
show schemas in pulsar;
show tables in pulsar."public/default";
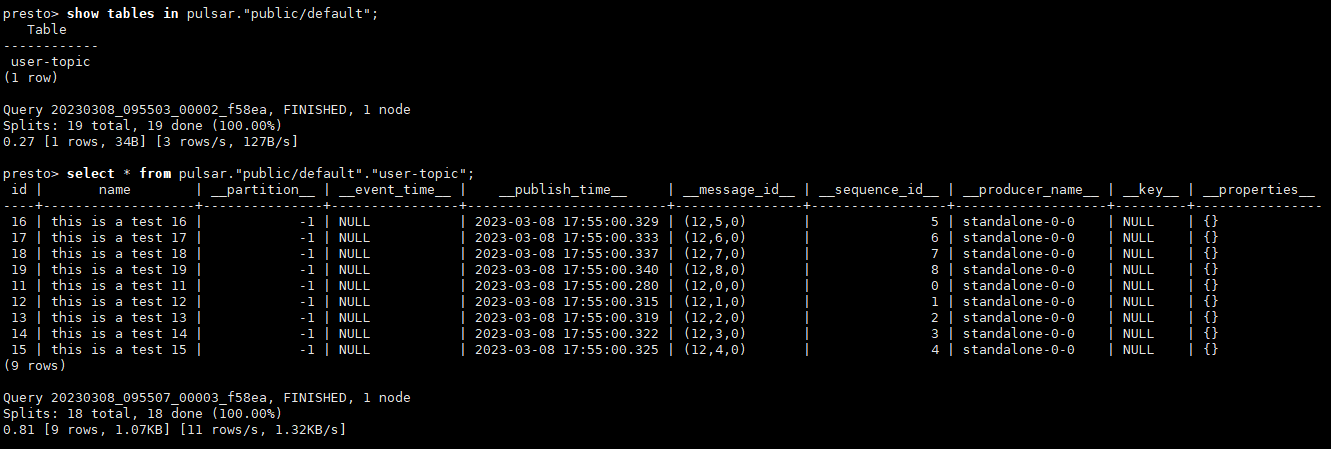
通过前面的Java示例,我们改为Json格式写入Pulsar的user-topic
package sn.itxs.pulsar.io;import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Schema;public class ClientSqlDemo {public static void main(String[] args) throws Exception {PulsarClient client = null;Producer<User> producer = null;try {client = PulsarClient.builder().serviceUrl("pulsar://192.168.5.52:6650").build();producer = client.newProducer(Schema.JSON(User.class)).topic("user-topic").create();User user = new User();int index = 10;while (index++ < 20) {try {user.id = index;user.name = "this is a test " + index;producer.newMessage().value(user).send();} catch (Exception e) {e.printStackTrace();}}System.out.println("send finish");} catch (Exception e) {e.printStackTrace();}finally {if (producer!=null){producer.close();}if (client!=null){client.close();}}}
}
运行程序后再来查询就有刚才发送的消息数据,_开头的字段为Pulsar 自带的。
select * from pulsar."public/default"."user-topic";
- 本人博客网站IT小神 www.itxiaoshen.com
相关文章:
云原生时代顶流消息中间件Apache Pulsar部署实操之Pulsar IO与Pulsar SQL
文章目录Pulsar IO (Connector连接器)基础定义安装Pulsar和内置连接器连接Pulsar到Cassandra安装cassandra集群配置Cassandra接收器创建Cassandra Sink验证Cassandra Sink结果删除Cassandra Sink连接Pulsar到PostgreSQL安装PostgreSQL集群配置JDBC接收器创建JDBC Sink验证JDBC …...
Input子系统(一)启动篇
代码路径 基于AndroidS(12.0)代码 system/core/libutils/Threads.cppframeworks/base/services- java/com/android/server/SystemServer.java- core- java/com/android/server/input/InputManagerService.java- jni/com_android_server_input_InputMan…...

WuThreat身份安全云-TVD每日漏洞情报-2023-03-08
漏洞名称:Agilebio Lab Collector 远程命令执行 漏洞级别:高危 漏洞编号:CVE-2023-24217,CNNVD-202303-375 相关涉及:Agilebio Lab Collector 4.234 漏洞状态:EXP 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-05536 漏洞名称:PrestaShop “Xen Forum”模…...

ABP IStringLocalizer部分场景不生效的问题
问题描述: 本地项目依赖注入本地化服务时候生效,第三方项目调用本地接口时候出现本地化失效的问题。 解决方案: 第三方服务封装的 GetHttp 请求的请求头中添加 语言相关信息 request.Headers.Add("accept-language", "zh-C…...

数组(四)-- LC[167] 两数之和-有序数组
1 两数之和 1.1 题目描述 题目链接:https://leetcode.cn/problems/two-sum/description/ 1.2 求解思路 1. 暴力枚举 最容易想到的方法是枚举数组中的每一个数 x,寻找数组中是否存在 target - x 参考代码 class Solution(object):def twoSum(self, n…...
Mac电脑,python+appium+安卓模拟器使用步骤
1、第一步,环境搭建,参考这位博主的文章,很齐全 https://blog.csdn.net/qq_44757414/article/details/128142859 我在最后一步安装appium-doctor的时候,提示权限不足,换成sudo appium-doctor即可 2、第二步࿰…...

Linux命令·find进阶
find是我们很常用的一个Linux命令,但是我们一般查找出来的并不仅仅是看看而已,还会有进一步的操作,这个时候exec的作用就显现出来了。 exec解释:-exec 参数后面跟的是command命令,它的终止是以;为结束标志的࿰…...

R语言ggplot2 | 用百分比格式表示数值
📋文章目录Percent() 函数介绍例子1,在向量中格式化百分比:例子2,格式化数据框列中的百分比:例子3,格式化多个数据框列中的百分比:如何使用percent()函数在绘图过程展示通常在绘图时,…...

【代码训练营】day53 | 1143.最长公共子序列 1035.不相交的线 53. 最大子序和
所用代码 java 最长公告子序列 LeetCode 1143 题目链接:最长公告子序列 LeetCode 1143 - 中等 思路 这个相等于上一题的不连续状态 dp[i] [j]:以[0, i-1]text1和以[0, j-1]text2 的最长公共子序列的长度为dp[i] [j]递推公式: 相同&#x…...
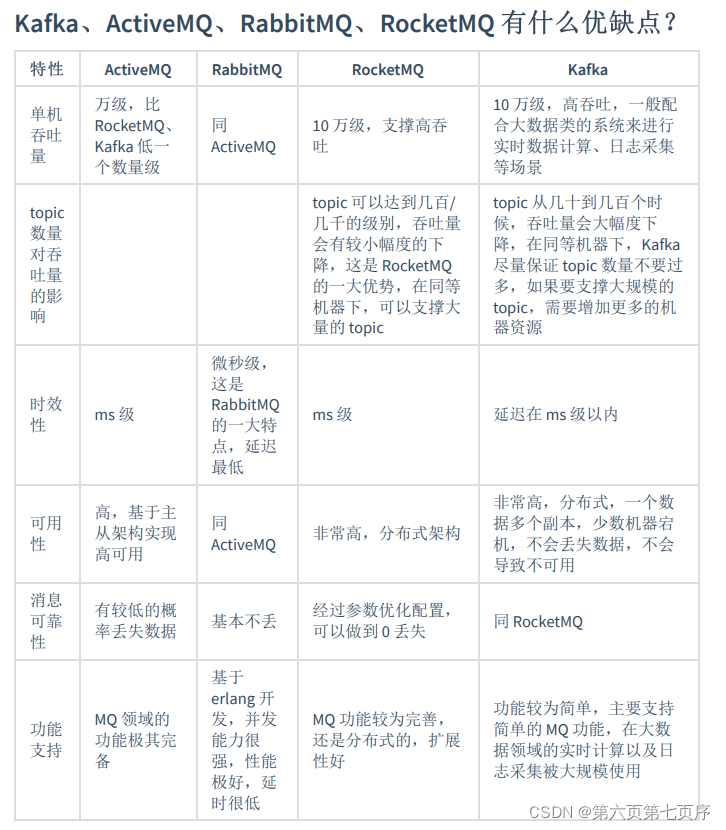
消息队列理解
为什么使用消息队列 使⽤消息队列主要是为了: 减少响应所需时间和削峰。降低系统耦合性(解耦/提升系统可扩展性)。 当我们不使⽤消息队列的时候,所有的⽤户的请求会直接落到服务器,然后通过数据库或者 缓存响应。假…...
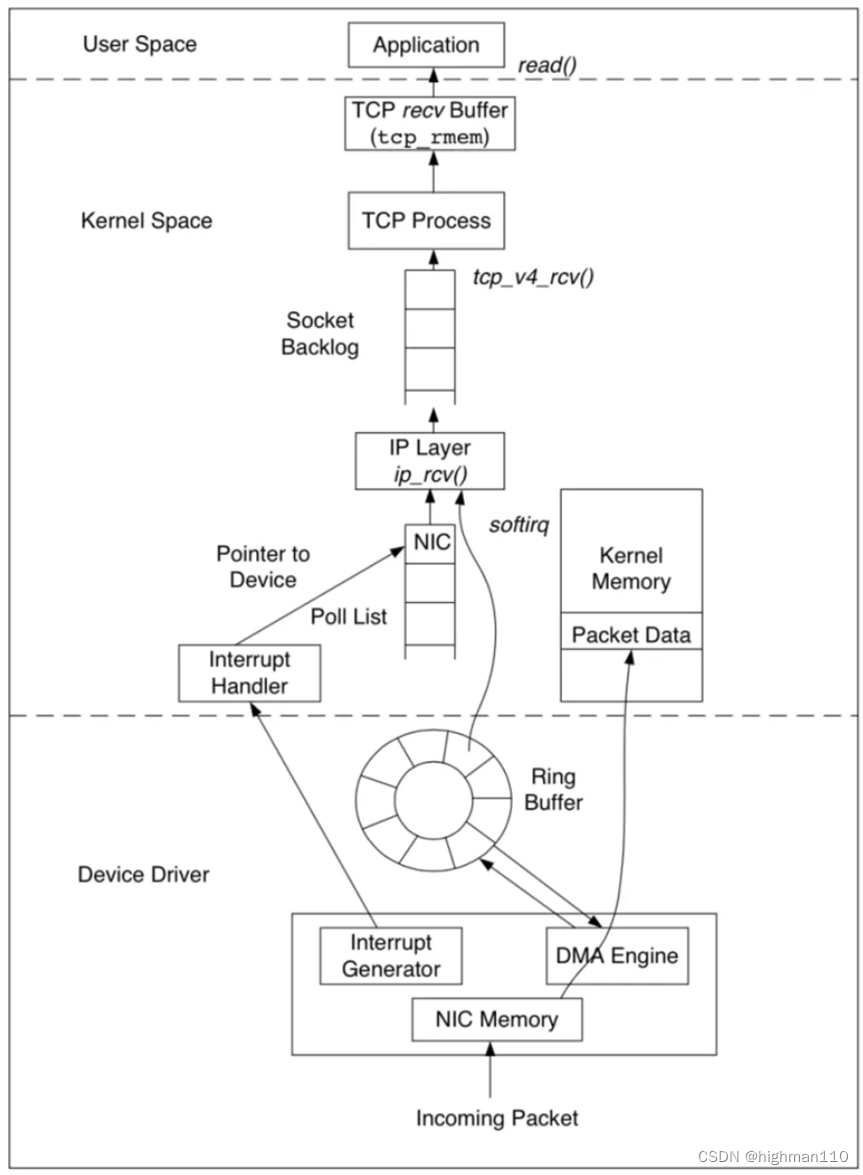
【Linux内核一】在Linux系统下网口数据收发包的具体流向是什么?
在TCP/IP网络分层模型里,整个协议栈被分成了物理层、链路层、网络层,传输层和应用层。物理层对应的是网卡和网线,应用层对应的是我们常见的Nginx,FTP等等各种应用。Linux实现的是链路层、网络层和传输层这三层。 在Linux内核实现中…...
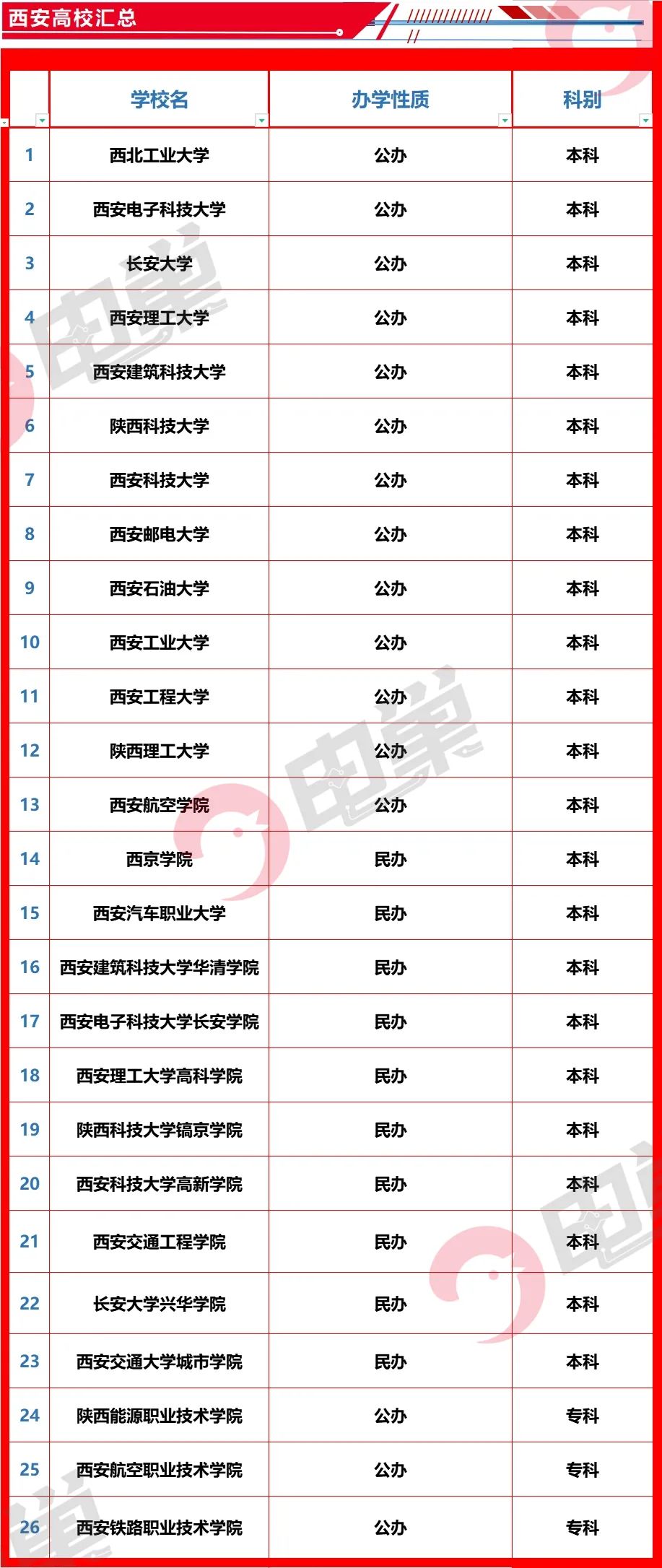
南京、西安集成电路企业和高校分布一览(附产业链主要厂商及高校名录)
前言 3月2日,国务院副总理刘鹤在北京调研集成电路企业发展,并主持召开座谈会。刘鹤指出,集成电路是现代化产业体系的核心枢纽,关系国家安全和中国式现代化进程。他表示,我国已形成较完整的集成电路产业链,也…...
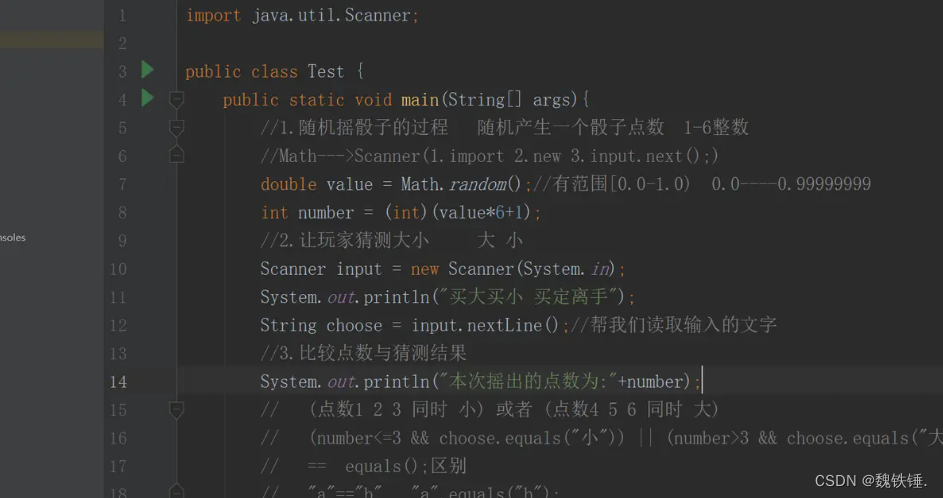
后端Java随机比大小游戏实战讲解
## - 利用print打印输出提示用户 ## - 利用Scanner函数抓取数据 ## - 利用Math方法实现随机数 #### 1.首先用到的是print函数,对用户进行提醒进一步的操作 通过System.out.print();提示用户进行选择买大买小。 #### 2.然后利用Scanner函数,对用户输出…...

dolphinschedule使用shell任务结束状态研究
背景:配置的dolphin任务,使用的是shell,shell里包含了spark-submit 如下截图。 dolphin shell 介绍完毕,开始说明现象。 有天有人调整了集群的cdp配置,executor-cores max1 我之前这里写的是2,所以spark任…...
如何用postman实现接口自动化测试
postman使用 开发中经常用postman来测试接口,一个简单的注册接口用postman测试: 接口正常工作只是最基本的要求,经常要评估接口性能,进行压力测试。 postman进行简单压力测试 下面是压测数据源,支持json和csv两个格…...
IMU(惯性测量单元)和INS的分析对比研究-2023-3-8)
AHRS(航姿参考系统)IMU(惯性测量单元)和INS的分析对比研究-2023-3-8
名称 AHRS俗称航姿参考系统 IMU 惯性测量单元 INS 惯性导航系统 英文 全称 (Attitude and Heading Reference System) (Inertial Measurement Unit) Inertial Navigation System) 组成 加速度计,磁…...

企业管理经典书籍推荐
几乎每一位成功的商业人士都有着良好的阅读习惯。并且他们阅读涉猎的范围也大多与企业管理和领导力有关。而关于企业管理经典书籍,我推荐你看以下这两本。一本是《经理人参阅:企业管理实务》,另一本是《经理人参阅:领导力提升》。…...

JVM系列——破坏双亲委派模型的场景和应用
上文提到过双亲委派模型并不是强制性的,而是Java设计者推荐的类加载器实现方式。 在Java的世界中大部分的类加载器都遵循这个模型,但也有例外的情况,直到Java 模块化出现为止,双亲委派模型出现过几次(3次?&…...
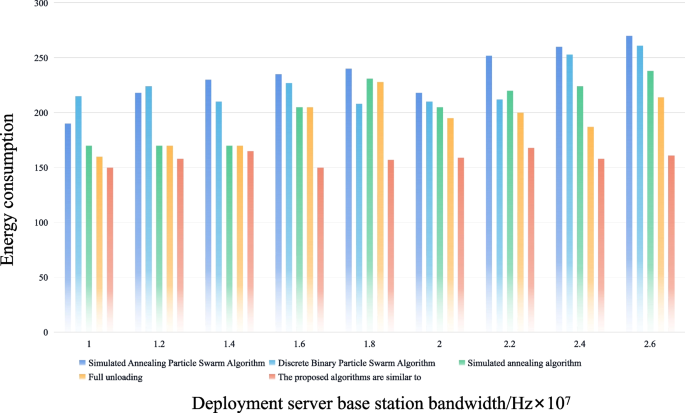
基于智能边缘和云计算的数字经济服务细粒度任务调度机制
数字经济被各国视为推动经济增长的必然选择,为经济高质量发展提供了新机遇、新路径。对于中国市场而言,云计算背后的强大基础是数字经济不可阻挡的发展趋势。在数字经济中,云作为基础设施成为构建数字经济金字塔的基础。为缓解数字经济服务器…...
ccc-pytorch-卷积神经网络实战(6)
文章目录一、CIFAR10 与 lenet5二、CIFAR10 与 ResNet一、CIFAR10 与 lenet5 第一步:准备数据集 lenet5.py import torch from torch.utils.data import DataLoader from torchvision import datasets from torchvision import transformsdef main():batchsz 128C…...

Fluent | 动网格技术解析与应用场景
1. 动网格技术到底是什么? 第一次接触动网格这个概念时,我也是一头雾水。简单来说,动网格就是让计算流体力学(CFD)模拟中的网格能够"动起来"的技术。想象一下你在用Fluent模拟一个活塞在气缸里的运动&#x…...

终极GitHub加速解决方案:让你的代码下载速度提升100倍
终极GitHub加速解决方案:让你的代码下载速度提升100倍 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾经因为G…...

拯救你的机械键盘:3步告别按键连击烦恼
拯救你的机械键盘:3步告别按键连击烦恼 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 你是否曾经在打字时突然发现屏幕上出…...

GLM-4v-9b开源镜像实操手册:transformers/vLLM/llama.cpp三端调用
GLM-4v-9b开源镜像实操手册:transformers/vLLM/llama.cpp三端调用 1. 开篇:认识这个强大的多模态模型 今天给大家介绍一个特别实用的AI模型——GLM-4v-9b,这是一个能同时看懂图片和文字的多模态模型。想象一下,你给它一张图片&a…...
)
告别纯手工标注!用微调后的SAM2+ISAT,实现裂缝标注效率翻倍(保姆级避坑指南)
基于SAM2与ISAT的裂缝智能标注实战:从零构建高效半自动化工作流 想象一下这样的场景:你面前堆叠着数千张道路裂缝检测图像,每张都需要精确标注裂缝区域。传统手工标注不仅耗时费力,还容易因疲劳导致标注质量下降。这正是计算机视觉…...

全栈实战应用:基于快马AI快速构建带投稿审稿系统的《构石》期刊官网
全栈实战应用:基于快马AI快速构建带投稿审稿系统的《构石》期刊官网 最近接手了一个学术期刊官网的开发需求,需要实现完整的在线投稿和审稿流程。这个项目涉及前后端联调和数据库设计,正好可以试试用InsCode(快马)平台来快速搭建原型。下面分…...

UniApp静态资源分包实战:除了图片500错误,你的分包策略真的优化到位了吗?
UniApp静态资源分包深度优化:从500报错到全平台兼容方案 在UniApp开发中,随着项目规模扩大,静态资源管理逐渐成为性能优化的关键瓶颈。许多开发者初次接触分包策略时,往往只关注基础配置而忽略资源加载的深层逻辑,直到…...

突破4大硬件限制:老旧Windows设备升级Windows 11的3维优化方案
突破4大硬件限制:老旧Windows设备升级Windows 11的3维优化方案 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 老旧设备升级Windows 11的价值解析 在数字化快…...
)
别再只会用Ettercap了!手把手教你用Python+Scapy从零写一个ARP欺骗脚本(附完整代码)
从零构建ARP欺骗工具:用PythonScapy深入理解网络协议安全 在网络安全领域,ARP欺骗一直是最基础却又最危险的攻击手段之一。大多数初学者会直接使用现成的工具如Ettercap进行实验,但这往往停留在"知其然"的层面。本文将带你从协议层…...
)
避开这些坑!Anthropic Computer Use在Mac上的安全使用指南(含Streamlit界面优化技巧)
避开这些坑!Anthropic Computer Use在Mac上的安全使用指南(含Streamlit界面优化技巧) 在Mac上探索AI工具的边界时,Anthropic Computer Use无疑是一把双刃剑。它既能让你通过自然语言指令操控整个系统,也可能因权限过高…...