记一次Kafka warning排查过程
1、前因
在配合测试某个需求的时候,正好看到控制台打印了个报错,如下:
2023-03-06 17:05:58,565[325651ms][pool-28-thread-1][org.apache.kafka.common.utils.AppInfoParser][WARN] - Error registering AppInfo mbean
javax.management.InstanceAlreadyExistsException: kafka.producer:type=app-info,id=producer-1at com.sun.jmx.mbeanserver.Repository.addMBean(Repository.java:437)at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.registerWithRepository(DefaultMBeanServerInterceptor.java:1898)at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.registerDynamicMBean(DefaultMBeanServerInterceptor.java:966)at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.registerObject(DefaultMBeanServerInterceptor.java:900)at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.registerMBean(DefaultMBeanServerInterceptor.java:324)at com.sun.jmx.mbeanserver.JmxMBeanServer.registerMBean(JmxMBeanServer.java:522)at org.apache.kafka.common.utils.AppInfoParser.registerAppInfo(AppInfoParser.java:64)at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:426)at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:287)at org.springframework.kafka.core.DefaultKafkaProducerFactory.createKafkaProducer(DefaultKafkaProducerFactory.java:406)at org.springframework.kafka.core.DefaultKafkaProducerFactory.createProducer(DefaultKafkaProducerFactory.java:392)at org.springframework.kafka.core.KafkaTemplate.getTheProducer(KafkaTemplate.java:463)at org.springframework.kafka.core.KafkaTemplate.doSend(KafkaTemplate.java:401)at org.springframework.kafka.core.KafkaTemplate.send(KafkaTemplate.java:216)
很明显是Kafka在创建Producer实例的时候重复了,正好趁着有空排查排查,不然谁知道后面会因为这个导致什么问题。
2、BUG定位
根据堆栈信息,找到与Kafka有关的报错代码,进到类 AppInfoParser 的 registerAppInfo方法中,代码如下:
public static synchronized void registerAppInfo(String prefix, String id, Metrics metrics, long nowMs) {try {ObjectName name = new ObjectName(prefix + ":type=app-info,id=" + Sanitizer.jmxSanitize(id));AppInfo mBean = new AppInfo(nowMs);ManagementFactory.getPlatformMBeanServer().registerMBean(mBean, name);registerMetrics(metrics, mBean); // prefix will be added later by JmxReporter} catch (JMException e) {log.warn("Error registering AppInfo mbean", e);}
}
从方法名可以推测,应当是 Kafka 在创建 Producer 实例时,会按 Producer 的 id 构造一个 AppInfo,并注册到一个公共的类似Map的东西中,而我们的代码创建了多个实例,并且 id 重复了,基于这个猜测来看Kafka的配置文件(已脱敏):
<!-- 定义producer1的参数 -->
<bean id="producerProperties1" class="java.util.HashMap"><constructor-arg><map><entry key="bootstrap.servers" value="localhost:9092"/><entry key="retries" value="3"/><entry key="batch.size" value="4096"/><entry key="linger.ms" value="10"/><entry key="buffer.memory" value="40960"/><entry key="acks" value="all"/><entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/><entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/></map></constructor-arg>
</bean><!-- 定义producer2的参数 -->
<bean id="producerProperties2" class="java.util.HashMap"><constructor-arg><map><entry key="bootstrap.servers" value="localhost:9092"/><entry key="retries" value="3"/><entry key="batch.size" value="4096"/><entry key="linger.ms" value="10"/><entry key="buffer.memory" value="40960"/><entry key="acks" value="all"/><entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/><entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/></map></constructor-arg>
</bean>
可以看到项目中配置了两个 Kafka 的 Producer,并且都未指定 Producer 的 id,符合我们的猜测,那么我们要怎么修复,如果我们指定了 id,Producer 在多线程的情况下,每个线程的 id 是否又会重复。
基于几个问题,进到类 KafkaProducer 的构造方法中,来看 AppInfoParser.registerAppInfo() 方法调用语句:
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
可以看到前面说的 Producer 的 id 实际上是 clientId,往前找到 clientId 的赋值语句:
this.clientId = buildClientId(config.getString(ProducerConfig.CLIENT_ID_CONFIG), transactionalId);
进到 buildClientId 里面:
private static String buildClientId(String configuredClientId, String transactionalId) {if (!configuredClientId.isEmpty())return configuredClientId;if (transactionalId != null)return "producer-" + transactionalId;return "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement();
}
可知如果 configuredClientId 和 transactionalId 都为空,那么clientId就会自动生成,继续往上追溯,来看 transactionalId 的赋值语句:
String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG) ?(String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG) : null;
其中 ProducerConfig.TRANSACTIONAL_ID_CONFIG 值为 transactional.id,可见 transactionalId 的值取得是用户配置(userProvidedConfigs)中的 transactional.id 的值,而 configuredClientId 值并不是直接获取的用户配置(userProvidedConfigs)的 client.id,而是拿的构造方法中传入的config中的 client.id 对应的值,说明 config 很有可能是在用户配置(userProvidedConfigs)的基础上进行了些许处理。
继续往上追溯,进到 DefaultKafkaProducerFactory.createKafkaProducer 方法中:
protected Producer<K, V> createKafkaProducer() {if (this.clientIdPrefix == null) {return new KafkaProducer<>(this.configs, this.keySerializerSupplier.get(),this.valueSerializerSupplier.get());}else {Map<String, Object> newConfigs = new HashMap<>(this.configs);newConfigs.put(ProducerConfig.CLIENT_ID_CONFIG,this.clientIdPrefix + "-" + this.clientIdCounter.incrementAndGet());return new KafkaProducer<>(newConfigs, this.keySerializerSupplier.get(),this.valueSerializerSupplier.get());}
}
可以看到如果 clientIdPrefix 不为空的情况下,会在 config 中放入 client.id 的键值对,很明显这种情况下不会有我们所说的 clientId 重复的情况发生,因此我们只需要保证 clientIdPrefix 不为空即可。在 DefaultKafkaProducerFactory 构造方法中找到 clientIdPrefix 的赋值语句:
if (this.clientIdPrefix == null && configs.get(ProducerConfig.CLIENT_ID_CONFIG) instanceof String) {this.clientIdPrefix = (String) configs.get(ProducerConfig.CLIENT_ID_CONFIG);
}
其中 ProducerConfig.CLIENT_ID_CONFIG 值为 client.id,所以只需要在用户配置中添加 client.id 的值,那么 KafkaProducer 在创建时,就会在自动生成的 clientId 中添加前缀字符串,从而避免不同的 KafkaProducer 的 id 冲突。
3、BUG修复
将上述Kafka配置文件修改如下:
<!-- 定义producer1的参数 -->
<bean id="producerProperties1" class="java.util.HashMap"><constructor-arg><map><entry key="bootstrap.servers" value="localhost:9092"/><entry key="client.id" value="a"/><entry key="retries" value="3"/><entry key="batch.size" value="4096"/><entry key="linger.ms" value="10"/><entry key="buffer.memory" value="40960"/><entry key="acks" value="all"/><entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/><entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/></map></constructor-arg>
</bean><!-- 定义producer2的参数 -->
<bean id="producerProperties2" class="java.util.HashMap"><constructor-arg><map><entry key="bootstrap.servers" value="localhost:9092"/><entry key="client.id" value="b"/><entry key="retries" value="3"/><entry key="batch.size" value="4096"/><entry key="linger.ms" value="10"/><entry key="buffer.memory" value="40960"/><entry key="acks" value="all"/><entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/><entry key="value.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/></map></constructor-arg>
</bean>
相关文章:

记一次Kafka warning排查过程
1、前因 在配合测试某个需求的时候,正好看到控制台打印了个报错,如下: 2023-03-06 17:05:58,565[325651ms][pool-28-thread-1][org.apache.kafka.common.utils.AppInfoParser][WARN] - Error registering AppInfo mbean javax.management.I…...
)
MySQL学习笔记(6.视图)
1. 视图作用 (1). 简化业务,将多个复杂条件,改为视图 (2). mysql对用户授权,只能控制表权限,通过视图可以控制用户字段权限。 (3). 可以避免基本表变更,影响业务。只需更改视图即可。 2. 视图(创建&…...

java多线程与线程池-01多线程知识复习
多线程知识复习 文章目录 多线程知识复习第1章 多线程基础1.1.2 线程与进程的关系1.2 多线程启动1.2.1 线程标识1.2.2 Thread与Runnable1.2.3 run()与start()1.2.4 Thread源码分析1.3 线程状态1.3.1 NEW状态1.3.2 RUNNABLE状态1.3.3 BLOCKED状态1.3.4 WAITING状态1…...

Typescript - 将命名空间A导入另一个命名空间B作为B的子命名空间,并全局暴露命名空间B
前言 最近相统一管理 ts 中的类型声明,这就需要将各模块下的命名空间整合到全局的命名空间下,牵涉到从别的文件中引入命名空间并作为子命名空间在全局命名空间中统一暴露。 将命名空间A导入另一个命名空间B作为B的子命名空间 文件说明 assets.ts 文件中…...
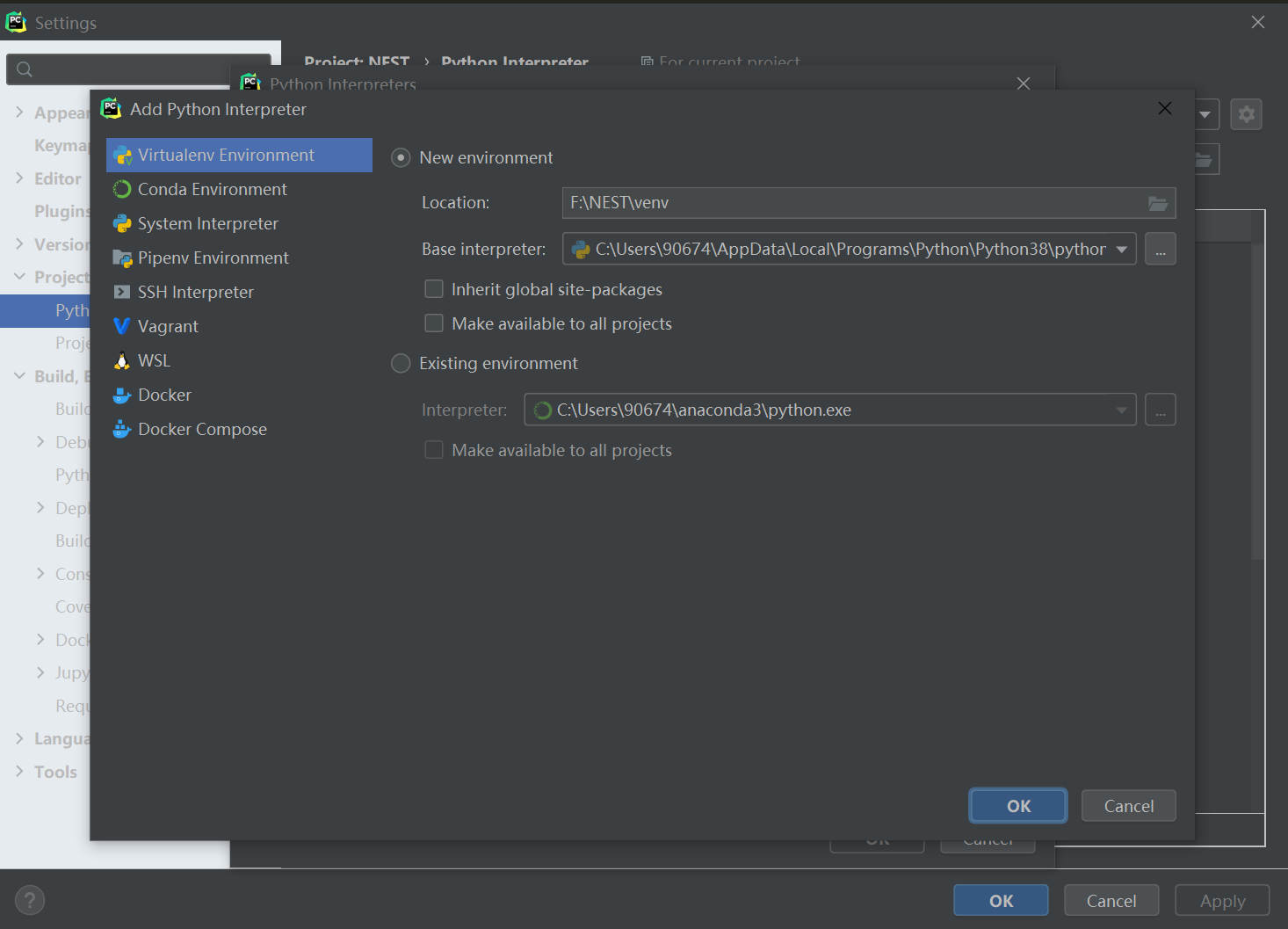
Windows下实现Linux内核的Python开发(WSL2+Conda+Pycharm)
许多软件可以通过Python交互,但没有开发Windows版本,这个时候装双系统或虚拟机都很不方便,可以采取WSL2CondaPycharm的策略来进行基于Linux内核的Python开发。启动WSL2,安装Linux内核教程:旧版 WSL 的手动安装步骤 | M…...

新闻发布网站分析及适用场景
在当今数字时代,发布新闻的渠道已经不再局限于传统媒体,越来越多的企业、组织和个人开始使用互联网平台发布新闻稿,以提升品牌知名度和影响力。本文将介绍一些可以发布新闻的网站,并分析其特点和适用场景。一、新闻稿发布平台1.新…...
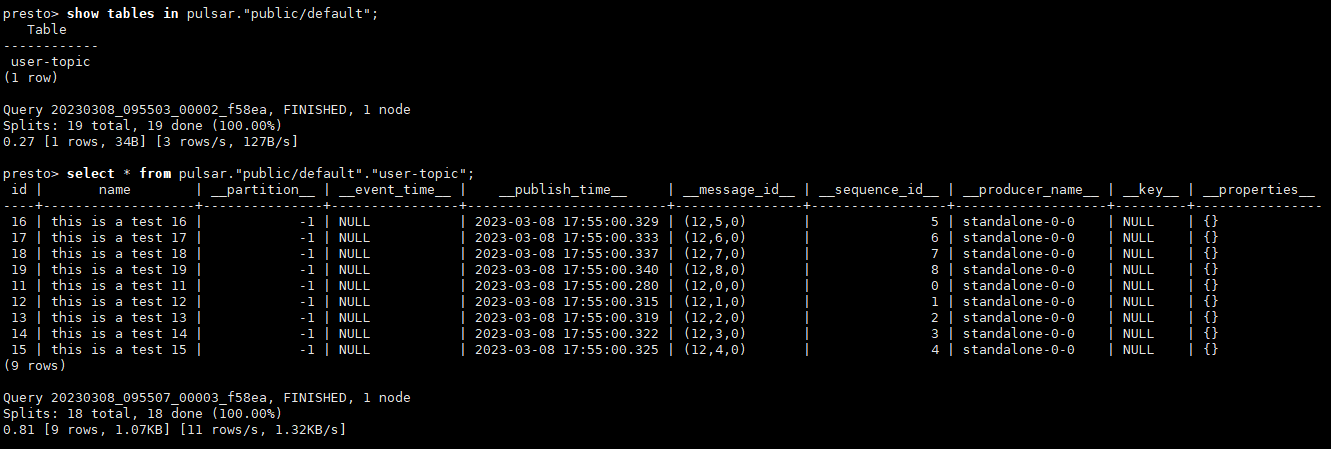
云原生时代顶流消息中间件Apache Pulsar部署实操之Pulsar IO与Pulsar SQL
文章目录Pulsar IO (Connector连接器)基础定义安装Pulsar和内置连接器连接Pulsar到Cassandra安装cassandra集群配置Cassandra接收器创建Cassandra Sink验证Cassandra Sink结果删除Cassandra Sink连接Pulsar到PostgreSQL安装PostgreSQL集群配置JDBC接收器创建JDBC Sink验证JDBC …...
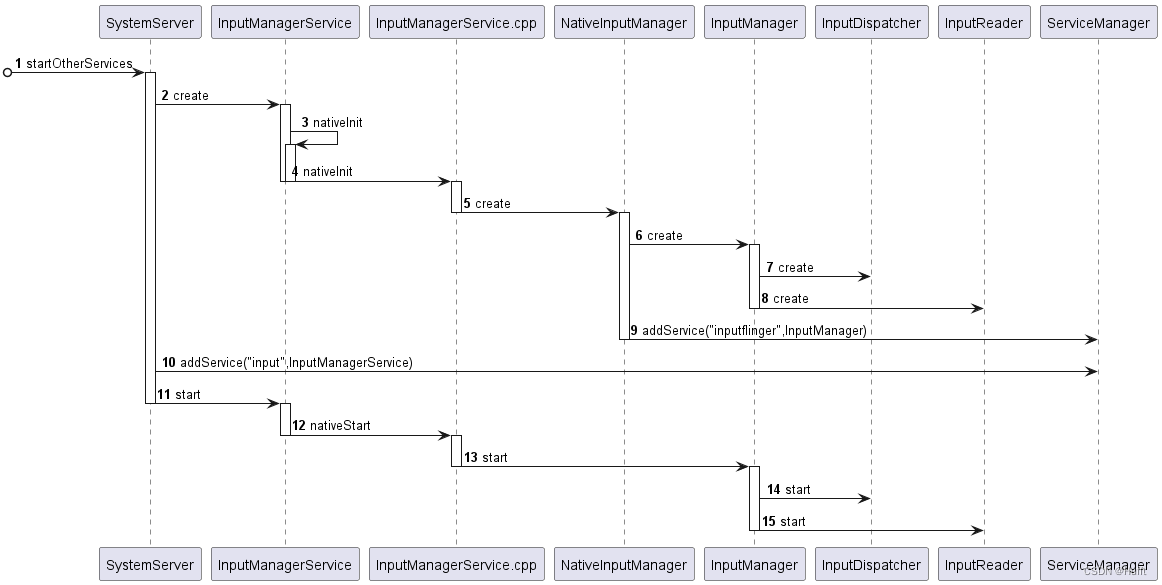
Input子系统(一)启动篇
代码路径 基于AndroidS(12.0)代码 system/core/libutils/Threads.cppframeworks/base/services- java/com/android/server/SystemServer.java- core- java/com/android/server/input/InputManagerService.java- jni/com_android_server_input_InputMan…...

WuThreat身份安全云-TVD每日漏洞情报-2023-03-08
漏洞名称:Agilebio Lab Collector 远程命令执行 漏洞级别:高危 漏洞编号:CVE-2023-24217,CNNVD-202303-375 相关涉及:Agilebio Lab Collector 4.234 漏洞状态:EXP 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-05536 漏洞名称:PrestaShop “Xen Forum”模…...

ABP IStringLocalizer部分场景不生效的问题
问题描述: 本地项目依赖注入本地化服务时候生效,第三方项目调用本地接口时候出现本地化失效的问题。 解决方案: 第三方服务封装的 GetHttp 请求的请求头中添加 语言相关信息 request.Headers.Add("accept-language", "zh-C…...

数组(四)-- LC[167] 两数之和-有序数组
1 两数之和 1.1 题目描述 题目链接:https://leetcode.cn/problems/two-sum/description/ 1.2 求解思路 1. 暴力枚举 最容易想到的方法是枚举数组中的每一个数 x,寻找数组中是否存在 target - x 参考代码 class Solution(object):def twoSum(self, n…...
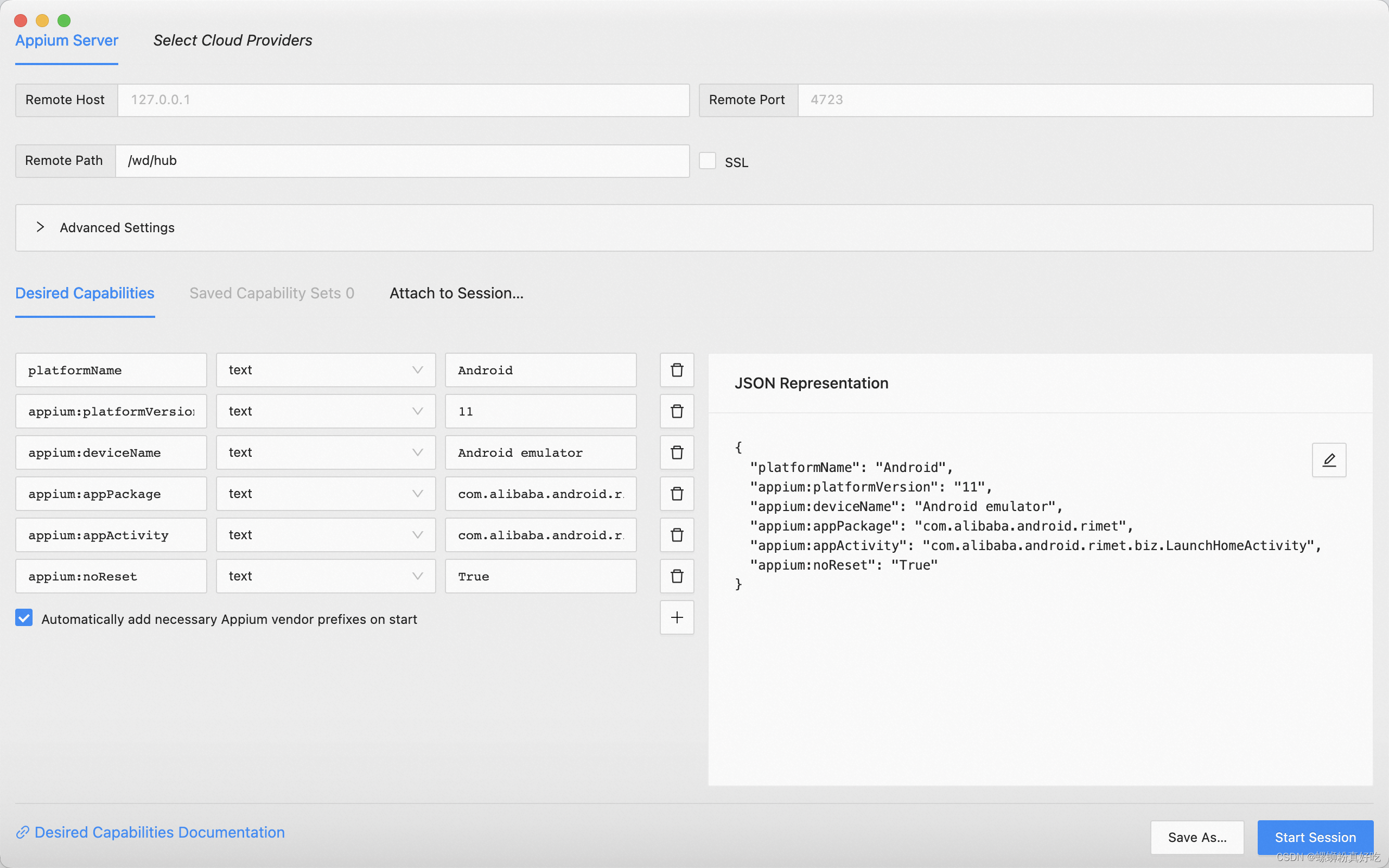
Mac电脑,python+appium+安卓模拟器使用步骤
1、第一步,环境搭建,参考这位博主的文章,很齐全 https://blog.csdn.net/qq_44757414/article/details/128142859 我在最后一步安装appium-doctor的时候,提示权限不足,换成sudo appium-doctor即可 2、第二步࿰…...

Linux命令·find进阶
find是我们很常用的一个Linux命令,但是我们一般查找出来的并不仅仅是看看而已,还会有进一步的操作,这个时候exec的作用就显现出来了。 exec解释:-exec 参数后面跟的是command命令,它的终止是以;为结束标志的࿰…...

R语言ggplot2 | 用百分比格式表示数值
📋文章目录Percent() 函数介绍例子1,在向量中格式化百分比:例子2,格式化数据框列中的百分比:例子3,格式化多个数据框列中的百分比:如何使用percent()函数在绘图过程展示通常在绘图时,…...

【代码训练营】day53 | 1143.最长公共子序列 1035.不相交的线 53. 最大子序和
所用代码 java 最长公告子序列 LeetCode 1143 题目链接:最长公告子序列 LeetCode 1143 - 中等 思路 这个相等于上一题的不连续状态 dp[i] [j]:以[0, i-1]text1和以[0, j-1]text2 的最长公共子序列的长度为dp[i] [j]递推公式: 相同&#x…...
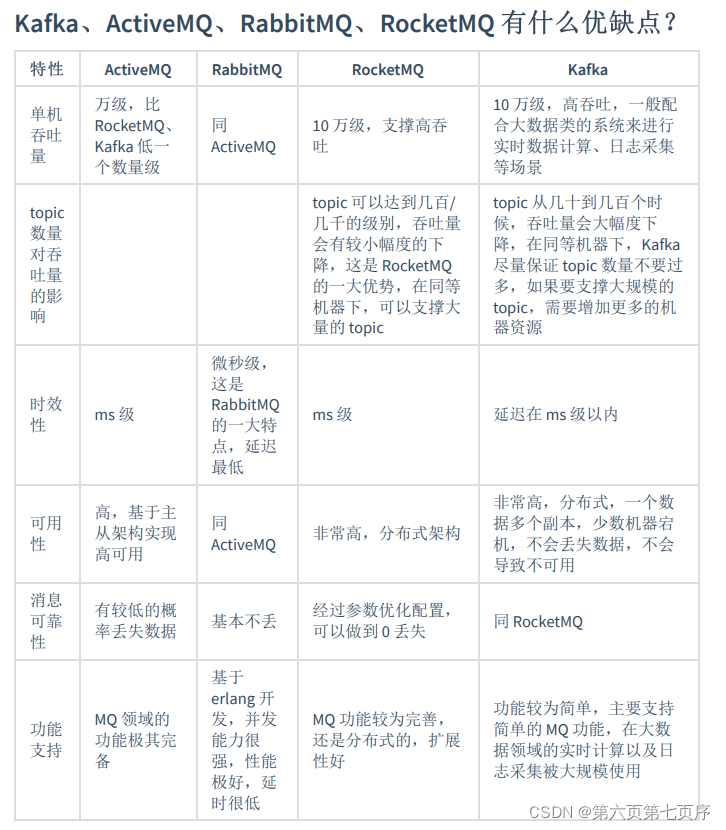
消息队列理解
为什么使用消息队列 使⽤消息队列主要是为了: 减少响应所需时间和削峰。降低系统耦合性(解耦/提升系统可扩展性)。 当我们不使⽤消息队列的时候,所有的⽤户的请求会直接落到服务器,然后通过数据库或者 缓存响应。假…...
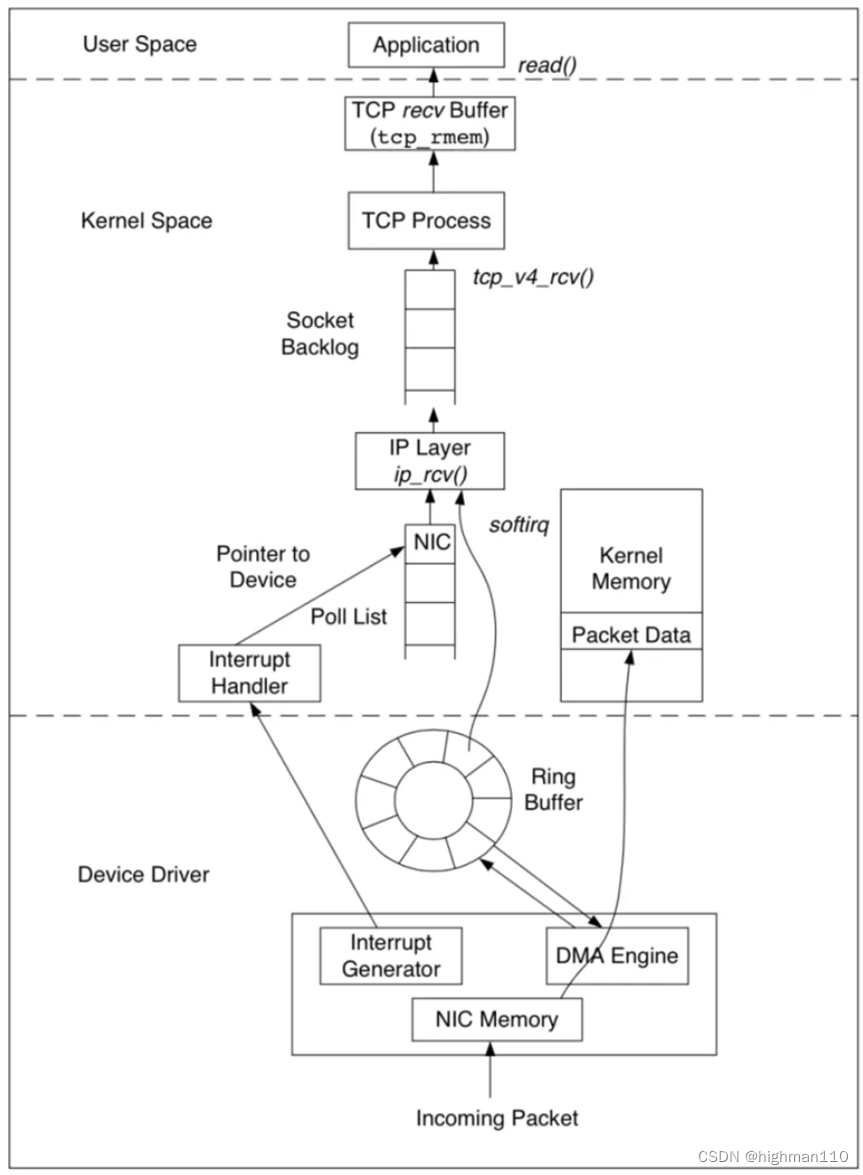
【Linux内核一】在Linux系统下网口数据收发包的具体流向是什么?
在TCP/IP网络分层模型里,整个协议栈被分成了物理层、链路层、网络层,传输层和应用层。物理层对应的是网卡和网线,应用层对应的是我们常见的Nginx,FTP等等各种应用。Linux实现的是链路层、网络层和传输层这三层。 在Linux内核实现中…...
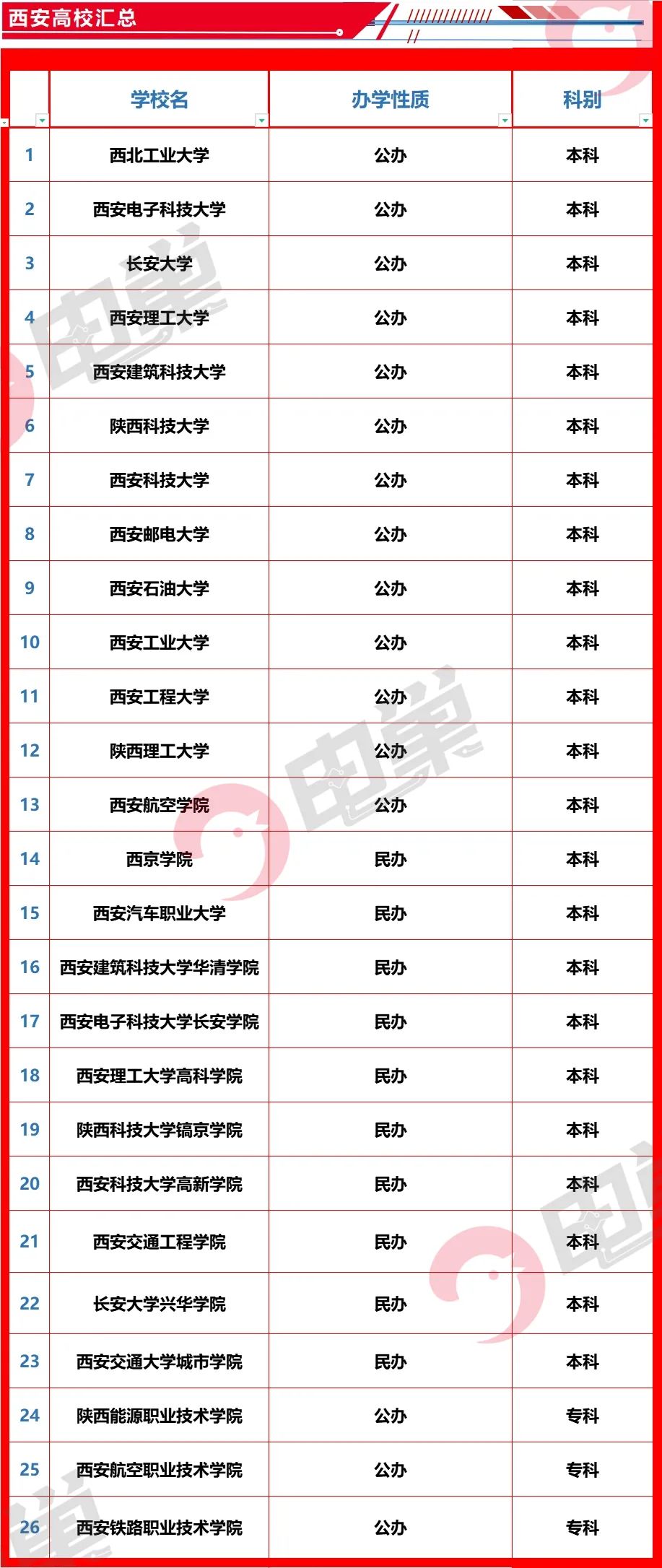
南京、西安集成电路企业和高校分布一览(附产业链主要厂商及高校名录)
前言 3月2日,国务院副总理刘鹤在北京调研集成电路企业发展,并主持召开座谈会。刘鹤指出,集成电路是现代化产业体系的核心枢纽,关系国家安全和中国式现代化进程。他表示,我国已形成较完整的集成电路产业链,也…...
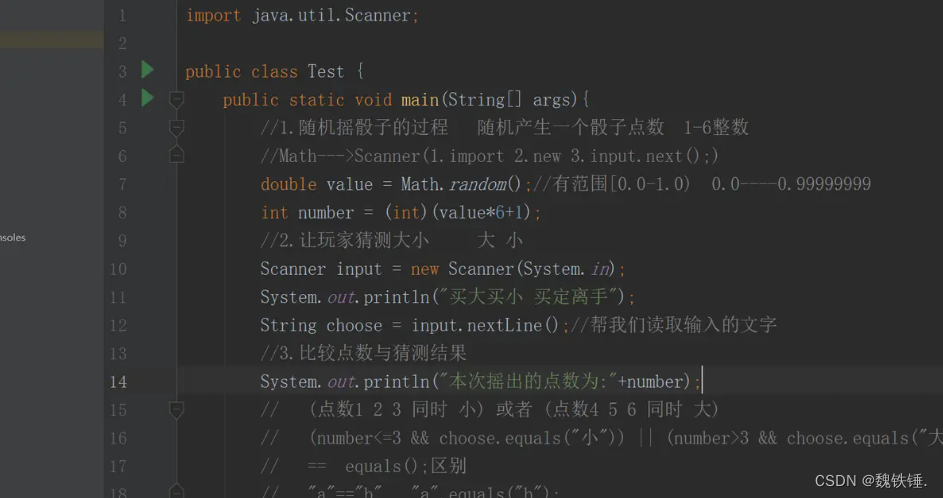
后端Java随机比大小游戏实战讲解
## - 利用print打印输出提示用户 ## - 利用Scanner函数抓取数据 ## - 利用Math方法实现随机数 #### 1.首先用到的是print函数,对用户进行提醒进一步的操作 通过System.out.print();提示用户进行选择买大买小。 #### 2.然后利用Scanner函数,对用户输出…...

dolphinschedule使用shell任务结束状态研究
背景:配置的dolphin任务,使用的是shell,shell里包含了spark-submit 如下截图。 dolphin shell 介绍完毕,开始说明现象。 有天有人调整了集群的cdp配置,executor-cores max1 我之前这里写的是2,所以spark任…...

告别转换限制:实测可免费批量处理Geojson、Shapefile与KML的在线工具指南
1. 为什么你需要这个免费批量转换工具? 作为一个经常处理地理信息数据的老手,我太懂你们遇到的痛点了。上周帮学弟改毕业论文,他用的那个知名在线转换工具,刚传了第4个文件就弹出"本月免费额度已用完"——这哪够用啊&am…...

微信毕业设计基于微信小程序的易物小店交换系统
前言 Spring Boot 易物小店交换系统是一个基于 Web 的应用程序,利用 Spring Boot 框架构建,主要用于帮助用户实现物品交换的功能。该系统为用户提供了一个便捷、安全、高效的平台,让他们能够轻松地发布自己想要交换的物品信息,寻找…...

抖音弹幕抓取终极指南:如何利用系统代理技术实现免费数据监听
抖音弹幕抓取终极指南:如何利用系统代理技术实现免费数据监听 【免费下载链接】DouyinBarrageGrab 基于系统代理的抖音弹幕wss抓取程序,能够获取所有数据来源,包括chrome,抖音直播伴侣等,可进行进程过滤 项目地址: h…...

OptiScaler:打破显卡技术壁垒——跨平台玩家的AI超分辨率解决方案
OptiScaler:打破显卡技术壁垒——跨平台玩家的AI超分辨率解决方案 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler 当你…...
)
从二极管到MOS管:工程师实测对比三种防反接电路的效率与成本(含数据)
从二极管到MOS管:三种防反接电路的全维度工程评估手册 当你的电路板因为电源反接冒出一缕青烟时,那种混合着焦味和绝望的体验,相信每个硬件工程师都记忆犹新。防反接电路看似简单,却直接影响着产品的可靠性、成本和能效表现。本文…...

告别模拟音频线!用MAX98357A数字功放芯片,5分钟搞定I2S直连ESP32播放MP3
5分钟实现ESP32数字音频播放:MAX98357A功放芯片极简开发指南 在智能硬件开发中,音频输出功能常被视为"必要但麻烦"的组件——传统方案需要DAC转换、运放电路、滤波网络等一系列复杂设计。而MAX98357A这颗仅指甲盖大小的芯片,用纯数…...

2026指纹浏览器风控对抗技术实践:从特征伪装到行为合规的全流程落地
一、引言:多账号运营场景下的风控挑战与技术诉求随着 2026 年全球互联网平台风控技术的持续迭代,AI 驱动的多维度交叉验证已成为主流风控模式,平台不仅对设备硬件指纹、网络环境进行深度检测,更将操作行为、业务数据、行为轨迹纳入…...

团队知识协作平台:构建高效智能的文档管理系统
团队知识协作平台:构建高效智能的文档管理系统 【免费下载链接】outline Outline 是一个基于 React 和 Node.js 打造的快速、协作式团队知识库。它可以让团队方便地存储和管理知识信息。你可以直接使用其托管版本,也可以自己运行或参与开发。源项目地址&…...

Realistic Vision V5.1 性能调优:针对STM32嵌入式设备图像生成的优化思路探讨
Realistic Vision V5.1 性能调优:针对STM32嵌入式设备图像生成的优化思路探讨 最近在捣鼓一个挺有意思的项目,想把一些前沿的AI图像生成能力,塞进像STM32F103C8T6这种资源极其有限的嵌入式设备里。你可能要问了,这怎么可能&#…...

从学习到实战:用快马ai生成企业级java博客项目,打通知识应用最后一公里
今天想和大家分享一个特别实用的Java学习实战经验——如何用InsCode(快马)平台快速搭建一个企业级Java博客系统。这个项目完美覆盖了Java学习路线中的核心知识点,从基础框架到生产级功能一应俱全,特别适合想要通过实战巩固技能的朋友。 项目整体设计思路…...