colab使用本地数据集微调llama3-8b模型
在Google的Colab上面采用unsloth,trl等库,训练数据集来自Google的云端硬盘,微调llama3-8b模型,进行推理验证模型的微调效果。
保存模型到Google的云端硬盘可以下载到本地供其它使用。
准备工作:将训练数据集上传到google的云端硬盘根目录下,文件名就叫做train.json
train.json里面的数据格式如下:
[
{
"instruction": "你好",
"output": "你好,我是智能助手胖胖"
},
{
"instruction": "hello",
"output": "Hello! I am 智能助手胖胖, an AI assistant developed by 丹宇码农. How can I assist you ?"
}
......
]
采用unsloth库、trl库、transformers等库。
直接上代码:
%%capture
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers<0.0.26" trl peft accelerate bitsandbytesfrom unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = ["unsloth/mistral-7b-bnb-4bit","unsloth/mistral-7b-instruct-v0.2-bnb-4bit","unsloth/llama-2-7b-bnb-4bit","unsloth/gemma-7b-bnb-4bit","unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b"unsloth/gemma-2b-bnb-4bit","unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b"unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3
] # More models at https://huggingface.co/unslothmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/llama-3-8b-bnb-4bit",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)model = FastLanguageModel.get_peft_model(model,r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = 16,lora_dropout = 0, # Supports any, but = 0 is optimizedbias = "none", # Supports any, but = "none" is optimized# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long contextrandom_state = 3407,use_rslora = False, # We support rank stabilized LoRAloftq_config = None, # And LoftQ
)alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.### Instruction:
{}### Input:
{}### Response:
{}"""EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):instructions = examples["instruction"]outputs = examples["output"]texts = []for instruction, output in zip(instructions, outputs):input = ""# Must add EOS_TOKEN, otherwise your generation will go on forever!text = alpaca_prompt.format(instruction, input, output) + EOS_TOKENtexts.append(text)return { "text" : texts, }
passfrom datasets import load_dataset
#dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
#dataset = dataset.map(formatting_prompts_func, batched = True,)
from google.colab import drive
# 挂载云端硬盘,加载成功后,在左边的文件树中将会多一个 /content/drive/MyDrive/ 目录
drive.mount('/content/drive')# 加载本地数据集:
# 有instruction和output,input为空字符串
from datasets import load_datasetdata_home = r"/content/drive/MyDrive/"
data_dict = {"train": os.path.join(data_home, "train.json"),#"validation": os.path.join(data_home, "dev.json"),
}
dataset = load_dataset("json", data_files=data_dict, split = "train")
print(dataset[0])
dataset = dataset.map(formatting_prompts_func, batched = True,)from trl import SFTTrainer
from transformers import TrainingArgumentstrainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,dataset_text_field = "text",max_seq_length = max_seq_length,dataset_num_proc = 2,packing = False, # Can make training 5x faster for short sequences.args = TrainingArguments(per_device_train_batch_size = 2,gradient_accumulation_steps = 4,warmup_steps = 5,max_steps = 60,learning_rate = 2e-4,fp16 = not torch.cuda.is_bf16_supported(),bf16 = torch.cuda.is_bf16_supported(),logging_steps = 1,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,output_dir = "outputs",),
)# 开始微调训练
trainer_stats = trainer.train()#推理
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[alpaca_prompt.format("你是谁?", # instruction"", # input"", # output - leave this blank for generation!)
], return_tensors = "pt").to("cuda")outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)#此处输出的答案,能明显看到就是自己训练的数据,而不是原来模型的输出。说明微调起作用了# 保存模型,改成挂接的云硬盘目录也可以保存到google的个人云存储空间,然后打开个人云存储空间下载到本地
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")# Merge to 16bit
if True: model.save_pretrained_merged("model", tokenizer, save_method = "merged_16bit",)其实可以将.ipynb文件上传到个人云存储空间,双击这个文件就会打开colab,然后依次执行代码即可,随时可以增加、删除、修改,特别方便,还能免费使用GPU、CPU等资源,真的是广大AI爱好者的不错选择。
相关文章:

colab使用本地数据集微调llama3-8b模型
在Google的Colab上面采用unsloth,trl等库,训练数据集来自Google的云端硬盘,微调llama3-8b模型,进行推理验证模型的微调效果。 保存模型到Google的云端硬盘可以下载到本地供其它使用。 准备工作:将训练数据集上传到google的云端硬盘…...
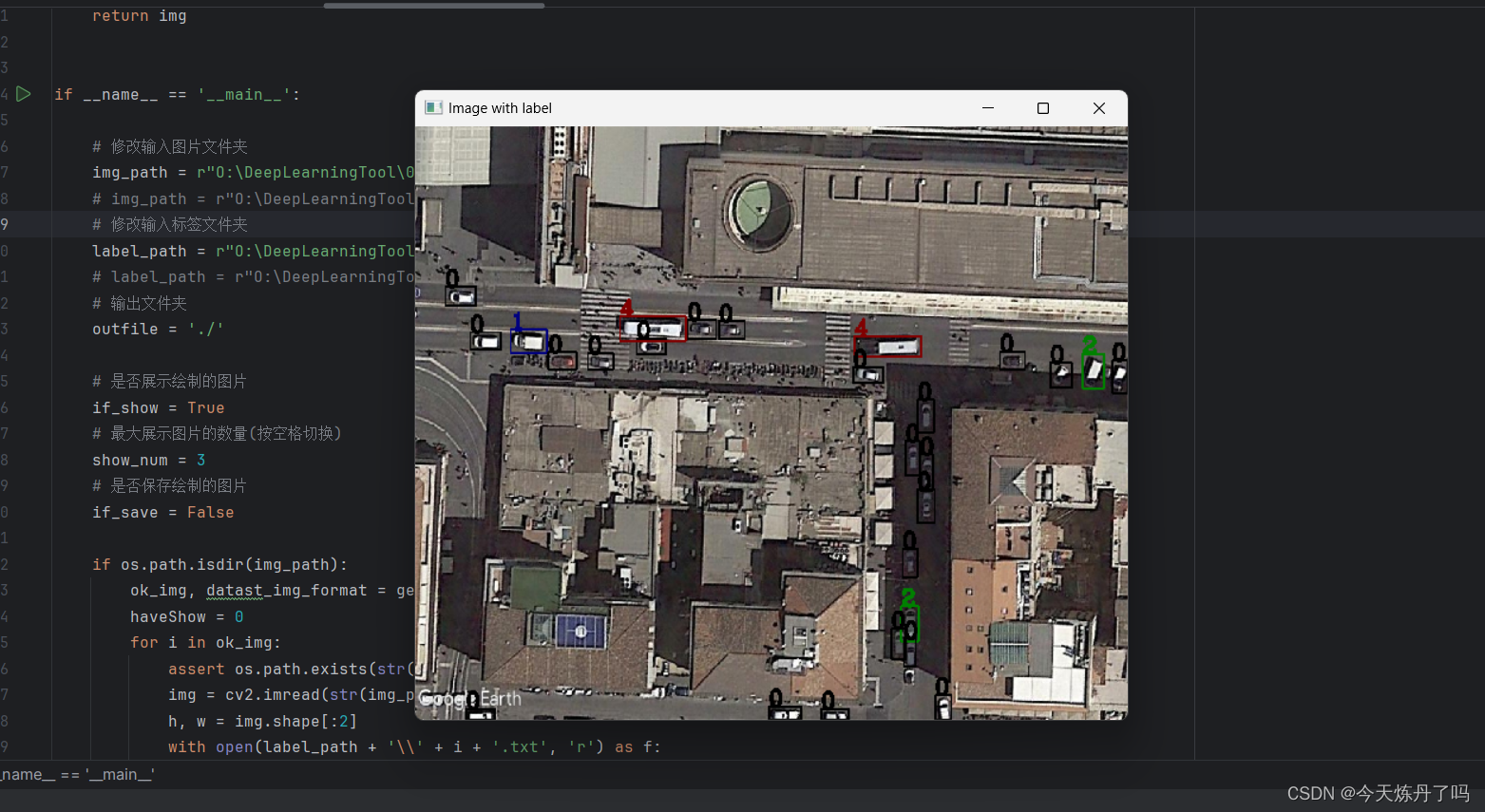
YOLO数据集制作(二)|json文件转txt验证
以下教程用于验证转成YOLO使用的txt格式,适用场景:矩形框,配合json格式文件转成YOLO使用的txt格式脚本使用。 https://blog.csdn.net/StopAndGoyyy/article/details/138681454 使用方式:将img_path和label_path分别填入对应的图…...
)
linux常用命令(持续更新)
1.sudo -i 切换root权限 2. ll 和 ls 查看文件夹下面的文件 3. cat 查看文件内容 cat xxx.txt |grep 好 筛选出有好的内容 4. vi 编辑文件 点击insert进入编辑模式 编辑完之后点击Esc退出编辑模式 数据:wq!回车保存文件 5. ssh 连接到可以访问的系统 6. telnet 看端口是否可以…...

Excel表格导入/导出数据工具类
Excel表格导入/导出数据工具 这里以java语言为类,实现一个简单且较通用的Excel表格数据导入工具类。 自定义注解 ExcelColumn写导入工具类 ExcelImportUtil 自定义注解 ExcelColumn Retention(RetentionPolicy.RUNTIME) Target({java.lang.annotation.ElementTy…...
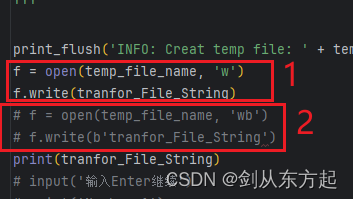
Python自学之路--004:Python使用注意点(原始字符串‘r’\字符转换\‘wb’与‘w区别’\‘\‘与‘\\’区别)
目录 1、原始字符串‘r’ 2、字符转换问题 3、open与write函数’wb’与’w’区分 4、Python里面\与\\的区别 1、原始字符串‘r’ 以前的脚本通过Python2.7写的,通过Python3.12去编译发现不通用了,其实也是从一个初学者的角度去看待这些问题。 其中的\…...
javaEE进阶——SpringBoot与SpringMVC第一讲
文章目录 什么是springMVCSpringMVC什么是模型、视图、控制器MVC和SpringMVC的关系SpringMVC的使用第一个SpringMVC程序RestController什么是注解 那么RestController到底是干嘛的呢?RequestMapping 如何接收来自请求中的querystryingRequestParamRequestMapping(&q…...

LabVIEW和usrp连接实现ofdm通信系统 如何实现
1. 硬件准备 USRP设备:选择合适的USRP硬件(如USRP B210或N210),并确保其与计算机连接(通常通过USB或以太网)。天线:根据频段需求选择合适的天线。 2. 软件安装 LabVIEW:安装LabVI…...
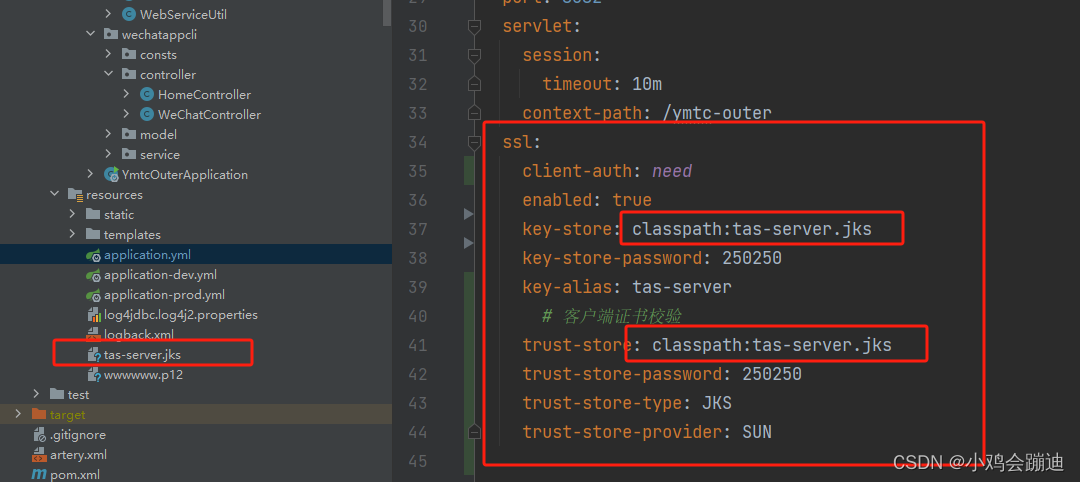
NGINX SPRING HTTPS证书
服务器:xxx.xxx.xxx.56 客户端器:xxx.xxx.xxx.94##生成服务器证书和密钥容器 keytool -genkey -alias tas-server -keypass 250250 -keyalg RSA -keysize 2048 -validity 3650 -keystore D:\https证书\tas-server.jks -storepass 250250 -dname "C…...
WordPress插件Plus WebP,可将jpg、png、bmp、gif图片转为WebP
现在很多浏览器和CDN都支持WebP格式的图片了,不过我们以前的WordPress网站使用的图片都是jpg、png、bmp、gif,那么应该如何将它们转换为WebP格式的图片呢?推荐安装这款Plus WebP插件,可以将上传到媒体库的图片转为WebP格式图片&am…...
)
GitLab CI/CD的原理及应用详解(五)
本系列文章简介: 在当今快速变化的软件开发环境中,持续集成(Continuous Integration, CI)和持续交付(Continuous Delivery, CD)已经成为提高软件开发效率、确保代码质量以及快速响应市场需求的重要手段。Gi…...

连锁收银系统如何助力实体门店私域运营
作为实体门店,私域运营是提升客户黏性和增加复购率的重要策略之一。而连锁收银系统在私域运营中扮演了关键的角色,它不仅可以帮助门店管理客户信息和消费记录,还能够通过数据分析和营销功能提供个性化的服务和推广活动。下面看看连锁收银系统…...

JETBRAINS IDES 分享一个2099通用试用码!PhpStorm 2024 版 ,支持一键升级
文章目录 废话不多说上教程:(动画教程 图文教程)一、动画教程激活 与 升级(至最新版本) 二、图文教程 (推荐)Stage 1.下载安装 toolbox-app(全家桶管理工具)Stage 2 : 下…...

超级好用的C++实用库之MD5信息摘要算法
💡 需要该C实用库源码的大佬们,可搜索微信公众号“希望睿智”。添加关注后,输入消息“超级好用的C实用库”,即可获得源码的下载链接。 概述 MD5信息摘要算法是一种广泛使用的密码散列函数,由Ronald L. Rivest在1991年设…...

ssm132医院住院综合服务管理系统设计与开发+vue
医院住院综合服务管理系统的设计与实现 摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对医院住院信息管理混乱&…...

在Linux上安装并启动Redis
目录 安装gcc环境 上传redis文件 启动redis-server 后台启动redis-server 查看redis启动状态 参考文章:Linux 安装 Redis 及踩坑 - 敲代码的阿磊 - 博客园 (cnblogs.com) 准备:打开VMware Workstation,创建一个虚拟机,进入管…...
vue3.0+antdv的admin管理系统vue-admin-beautiful推荐
前言 几年前,笔者自学了vue这一优秀的前端框架,但苦于没项目练手,无意间发现了vue-admin-beautiful这一优秀的前端集成框架。当时就使用它做了一很有意思的小项目---终端监控云平台,实现了前端和后台的整体功能。整体方案介绍参见…...

C# WinForm —— 20 RichTextBox 介绍
1. 简介 富文本框,拥有TextBox的所有功能,,但还有更多高级的文本输入和编辑功能,比如设置字体颜色、样式、段落、图片、超链接等 2. 常用属性 属性解释(Name)控件ID,在代码里引用的时候会用到,一般以 rtxt 开头Acce…...

springmvc数据绑定
数据绑定 数据绑定流程 springmvc框架将ServletRequest对象及目标方法的入参实例传递给WebDataBinderFactory实例,以创建DataBinder实例对象 DataBinder调用装配在springmvc上下文中的ConversionService组件进行数据类型转换、数据格式化工作。将Servlet中的请求信息…...
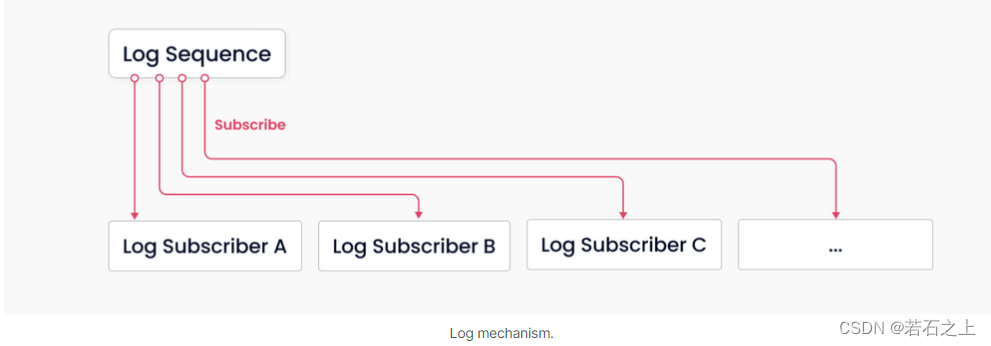
Milvus的存储/计算分离
前言 根据数据面与控制面相隔离的原则,从可扩展性和灾难恢复来看,Milvus由4个相互独立的层组成 访问层 由一系列无状态的代理组成,访问层是系统和用户之间的第一层,它主要是验证客户端请求和规整返回的结果 代理是无状态的&am…...

SHAP值是个什么值?
SHAP 值是个什么值? 起初,我们知道SHAP值代表了变量对于结局变量的贡献程度,然而,在做了一些SHAP分析之后,感觉有一些SHAP值还是有一些难以理解的地方,比如,为什么有负值?SHAP值为0…...

用 Mass Change Wizard 批量治理 SAP S/4HANA Business Role
在 SAP S/4HANA Cloud 的权限治理里,最怕的不是创建一个 Business Role,而是系统上线一段时间后,几十个甚至上百个 Business Role 需要一起调整。业务团队说,财务共享中心要启用新的 SAP Fiori Launchpad Space。Basis 团队说,旧的自定义 Space 要逐步退出。审计团队又补了…...

RV1126 NPU部署ResNet50全流程:从PyTorch训练到嵌入式板端推理
1. 项目概述:从零到一,在RV1126上跑通ResNet50最近在折腾一块EASY-EAI-Nano开发板,核心是瑞芯微的RV1126芯片,这玩意儿带了个NPU,不拿来跑跑AI模型实在说不过去。手头正好有个车辆分类的需求,就想试试经典的…...

LLMRank:基于大模型排序学习的自动化评估方案与实践指南
1. 项目概述:当大模型学会“自我评价”,我们该如何用好它? 最近在折腾大语言模型(LLM)应用落地的朋友,估计都绕不开一个核心问题: 怎么判断模型生成的内容到底好不好? 是通顺就行…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

基于MCP协议构建Reddit社区趋势分析工具:架构、部署与应用
1. 项目概述:一个实时洞察社区脉搏的利器最近在做一个社区运营相关的项目,需要实时追踪几个特定话题在Reddit上的讨论热度变化。手动刷帖、统计关键词频率这种笨办法效率太低,而且很难量化趋势。就在我琢磨着是不是要自己写个爬虫加分析脚本的…...

AI智能体分类学:从原理到实践,构建高效Agent系统的设计指南
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家聊起Agent,要么是“它能帮我写代码”,要么是“它能自动处理客服”,但很少有人能系统地说清楚ÿ…...

RP2350微控制器模拟Macintosh 128K:嵌入式复古计算实践
1. 项目概述:在RP2350上复活Macintosh 128K拿到一块Adafruit Fruit Jam开发板,看着上面那颗RP2350双核微控制器,我就在想,除了跑跑MicroPython、控制几个LED,这玩意儿还能干点啥更“出格”的事?答案是把一台…...

终极虚拟显示器解决方案:ParsecVDisplay完全指南
终极虚拟显示器解决方案:ParsecVDisplay完全指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动(VDD&#x…...

基于树莓派与电子墨水屏的慢速电影播放器制作全攻略
1. 项目概述:当电影遇见电子墨水如果你和我一样,对电子墨水(eInk)屏幕那种独特的、像印刷品一样的显示效果着迷,同时又是个喜欢折腾树莓派(Raspberry Pi)的玩家,那么这个项目绝对能让…...