深度学习中常见的九种交叉验证方法汇总
目录
1. K折交叉验证(K-fold cross-validation)
2. 分层K折交叉验证(Stratified K-fold cross-validation)
3. 时间序列交叉验证(Time Series Split)
4. 留一交叉验证(Leave-One-Out Cross-Validation,LOOCV)
5. 留P交叉验证(Leave-P-Out Cross-Validation,LPOCV)
6. 重复K折交叉验证(Repeated K-Fold Cross-Validation)
7. 留出交叉验证(Holdout Cross-Validation)
8. 自助采样交叉验证(Bootstrap Cross-Validation)
9. 蒙特卡洛交叉验证(Monte Carlo Cross-Validation)
10. 重复随机子采样交叉验证(Repeated Random Subsampling Cross-Validation)
| 方法 | 任务类型 | 划分方式 | 计算量 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|
| K折交叉验证 | 通用 | 将数据集分为 K 个子集,每次选取一个子集作为验证集 | 中等 | 充分利用数据,可以更准确地评估模型性能 | 计算量较大 | 通用 |
| 分层K折交叉验证 | 通用 | 类似于 K 折交叉验证,但保持每个折中类别比例 | 中等 | 对于不平衡数据集,保证了每个折中的类别比例 | 计算量较大 | 数据不平衡时 |
| 时间序列交叉验证 | 时间序列数据 | 根据时间顺序划分数据,保证训练集在测试集之前 | 低 | 考虑了时间序列数据的顺序性,适合于时间序列预测任务 | 不适用于非时间序列数据 | 时间序列预测任务 |
| 留一交叉验证 | 通用 | 每次将一个样本作为验证集 | 高 | 最大程度利用数据,评估结果准确 | 计算量巨大,效率低下 | 数据集较小时 |
| 留P交叉验证 | 通用 | 每次留下 P 个样本作为验证集 | 高 | 可以自定义留下的样本数量 P,适用于不同情况 | 计算量较大,效率低下 | 数据集较小时 |
| 重复K折交叉验证 | 通用 | 对 K 折交叉验证进行多次重复 | 高 | 提供更稳健的评估结果,减少因随机性引起的评估误差 | 计算量更大 | 需要更加稳健的评估结果 |
| 留出交叉验证 | 通用 | 将数据集划分为训练集和测试集,通常使用固定比例 | 低 | 计算量低,简单易用 | 不充分利用数据 | 数据集较大时 |
| 自助采样交叉验证 | 通用 | 通过自助采样的方式随机采样训练集 | 高 | 充分利用数据,对于小样本数据集效果好 | 计算量较大,可能会产生相似的训练样本,引入估计偏差 | 数据集较小,或者需要处理小样本数据时 |
| 蒙特卡洛交叉验证 | 通用 | 随机重复采样和验证 | 高 | 可以得到对数据的全面评估 | 计算量非常大 | 需要对模型进行全面评估时 |
| 重复随机子采样交叉验证 | 通用 | 通过随机子采样的方式重复采样训练集 | 高 | 充分利用数据,减少因样本选择的随机性引起的评估误差 | 计算量较大,可能会产生相似的训练样本,引入估计偏差 | 数据集较小,或者需要处理小样本数据时 |
1. K折交叉验证(K-fold cross-validation)
- 介绍: 将数据集分成K个大小相似的互斥子集,称为“折叠”(fold)。然后,对模型进行K次训练和测试,在每次训练中,使用K-1个折叠作为训练集,剩下的一个折叠作为测试集。
- 优点: 充分利用数据,减少因数据划分不同而引起的方差;可以评估模型性能的稳定性。
- 缺点: 计算量较大,因为需要训练和测试K次模型。
- 使用场景: 适用于数据量较小,但希望充分利用数据进行模型评估和选择的情况。
- 适用任务: 适用于分类和回归任务。
import numpy as np
from sklearn.model_selection import KFold# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建K折交叉验证对象
kf = KFold(n_splits=2, shuffle=True)# 遍历每一次交叉验证
for train_index, test_index in kf.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
2. 分层K折交叉验证(Stratified K-fold cross-validation)
- 介绍: 与K折交叉验证类似,但是在每个折叠中,类别比例与整个数据集中的类别比例相同。
- 优点: 在处理不平衡数据集时效果更好,确保每个折叠中类别的分布是相似的。
- 缺点: 对于较大的数据集,可能会导致计算开销增加。
- 使用场景: 适用于处理类别不平衡的分类任务。
- 适用任务: 主要用于分类任务。
import numpy as np
from sklearn.model_selection import StratifiedKFold# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 创建分层K折交叉验证对象
skf = StratifiedKFold(n_splits=2, shuffle=True)# 遍历每一次交叉验证
for train_index, test_index in skf.split(X, y):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
3. 时间序列交叉验证(Time Series Split)
- 介绍: 主要用于时间序列数据,保持数据的时间顺序,将数据集分割成连续的时间段,然后在每个时间段上进行交叉验证。
- 优点: 考虑到了时间顺序的影响,避免了时间序列数据的信息泄露。
- 缺点: 可能无法完全适用于非时间序列数据。
- 使用场景: 适用于时间序列数据的预测任务,如股票价格预测、天气预测等。
- 适用任务: 主要用于时间序列数据的预测任务。
import numpy as np
from sklearn.model_selection import TimeSeriesSplit# 创建时间序列数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([1, 2, 3, 4, 5])# 创建时间序列交叉验证对象
tscv = TimeSeriesSplit(n_splits=3)# 遍历每一次交叉验证
for train_index, test_index in tscv.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
4. 留一交叉验证(Leave-One-Out Cross-Validation,LOOCV)
- 介绍: 将数据集中的每个样本单独作为测试集,其他样本作为训练集,重复进行N次(N为样本数量),最终取平均。
- 优点: 对数据进行了最大程度的利用,可以有效减小因为样本数量较少而引起的方差。
- 缺点: 计算开销较大,因为需要训练和评估N次模型。
- 使用场景: 适用于数据量较小且计算资源充足的情况。
- 适用任务: 适用于分类和回归任务。
import numpy as np
from sklearn.model_selection import LeaveOneOut# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建Leave-One-Out交叉验证对象
loo = LeaveOneOut()# 遍历每一次交叉验证
for train_index, test_index in loo.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
5. 留P交叉验证(Leave-P-Out Cross-Validation,LPOCV)
- 介绍: 类似于Leave-One-Out交叉验证,但是每次将P个样本作为测试集,其余样本作为训练集,重复进行多次。
- 优点: 在一定程度上减小了计算开销,同时保持了较高的样本利用率。
- 缺点: 计算开销仍然较大,特别是对于大样本量的数据集。
- 使用场景: 适用于数据量较大,但仍希望充分利用数据进行模型评估的情况。
- 适用任务: 适用于分类和回归任务。
import numpy as np
from sklearn.model_selection import LeavePOut# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建Leave-P-Out交叉验证对象
lpocv = LeavePOut(p=2)# 遍历每一次交叉验证
for train_index, test_index in lpocv.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
6. 重复K折交叉验证(Repeated K-Fold Cross-Validation)
- 介绍: 重复K折交叉验证多次,每次随机重新划分数据集。
- 优点: 能够更好地评估模型的稳定性和泛化性能。
- 缺点: 计算开销较大,因为需要重复多次K折交叉验证。
- 使用场景: 适用于需要更准确评估模型性能和泛化能力的情况。
- 适用任务: 适用于分类和回归任务。
import numpy as np
from sklearn.model_selection import RepeatedKFold# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建Repeated K-fold交叉验证对象
rkf = RepeatedKFold(n_splits=2, n_repeats=2)# 遍历每一次交叉验证
for train_index, test_index in rkf.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
7. 留出交叉验证(Holdout Cross-Validation)
- 介绍: 将数据集划分为训练集和测试集,通常使用较大比例的数据作为训练集,而剩余部分作为测试集。
- 优点: 简单易用,计算开销小。
- 缺点: 对划分方式较为敏感,可能因为随机性而导致评估结果不稳定。
- 使用场景: 适用于数据量较大的情况,但不适用于数据量较小的情况,因为可能会导致训练集和测试集的样本偏差。
- 适用任务: 主要用于分类和回归任务。
import numpy as np
from sklearn.model_selection import train_test_split# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)8. 自助采样交叉验证(Bootstrap Cross-Validation)
- 介绍: 通过有放回地随机抽样生成多个大小相同的训练集和测试集,然后对每个训练集和测试集进行模型训练和评估。
- 优点: 可以对模型的稳定性和泛化性能进行更准确的评估,特别适用于小样本数据集。
- 缺点: 计算开销较大,因为需要进行多次重采样。
- 使用场景: 适用于小样本数据集和需要对模型稳定性进行更准确评估的情况。
- 适用任务: 主要用于分类和回归任务。
import numpy as np
from sklearn.utils import resample# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建Bootstrap交叉验证对象
n_iterations = 5
n_samples = len(X)
for i in range(n_iterations):X_train, X_test, y_train, y_test = resample(X, y, n_samples=n_samples, replace=True)
9. 蒙特卡洛交叉验证(Monte Carlo Cross-Validation)
- 介绍: 通过随机地多次将数据集划分为训练集和测试集,并对每次划分进行模型训练和评估。
- 优点: 可以提供更准确的评估结果,对数据集的划分更加灵活。
- 缺点: 计算开销较大,因为需要进行多次随机划分。
- 使用场景: 适用于对模型性能进行更准确评估,并希望对数据集划分进行更灵活控制的情况。
- 适用任务: 主要用于分类和回归任务。
import numpy as np
from sklearn.model_selection import ShuffleSplit# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 创建Monte Carlo交叉验证对象
n_iterations = 5
ss = ShuffleSplit(n_splits=n_iterations, test_size=0.2, random_state=42)# 遍历每一次交叉验证
for train_index, test_index in ss.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 在此处训练和评估模型
10. 重复随机子采样交叉验证(Repeated Random Subsampling Cross-Validation)
- 介绍: 通过多次随机子采样来构建训练集和测试集,每次采样得到不同的训练集和测试集,并重复此过程多次以获得更稳健的评估结果。
- 优点: 能够在不同的训练集和测试集上进行多次评估,提供对模型性能的更加稳健的估计。
- 缺点: 计算成本较高,需要多次重复采样和训练模型。
- 使用场景: 用于需要更稳健的性能评估的情况,或者对模型性能进行一致性验证。
- 适用任务: 通用的机器学习任务,特别是需要对模型性能进行稳健性评估的情况。
import numpy as np
from sklearn.model_selection import ShuffleSplit, cross_val_score# 创建数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])# 定义重复次数
n_repeats = 5# 定义随机子采样交叉验证
rss_cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=42)# 使用交叉验证评估模型
scores = cross_val_score(model, X, y, cv=rss_cv, n_jobs=-1)# 输出结果
for i, score in enumerate(scores):print(f"Cross-validation run {i+1}: {score}")
相关文章:

深度学习中常见的九种交叉验证方法汇总
目录 1. K折交叉验证(K-fold cross-validation) 2. 分层K折交叉验证(Stratified K-fold cross-validation) 3. 时间序列交叉验证(Time Series Split) 4. 留一交叉验证(Leave-One-Out Cross-…...

企业建网站流程
企业建网站是一个复杂而繁琐的过程,需要根据企业的需求和目标进行规划、设计、开发和运营。以下是企业建网站的一般流程,主要包括以下几个步骤: 第一步:需求分析 企业建网站的第一步是进行需求分析。这个过程需要与企业负责人和相…...

Laravel通过phpSpreadsheet合并excel
背景 最近有一个需求,需要将所有excel文件的sheet合并到一个文件。 目前我们处理表格使用的是xlswriter这个插件,对于数据量比较大的话非常好用。...
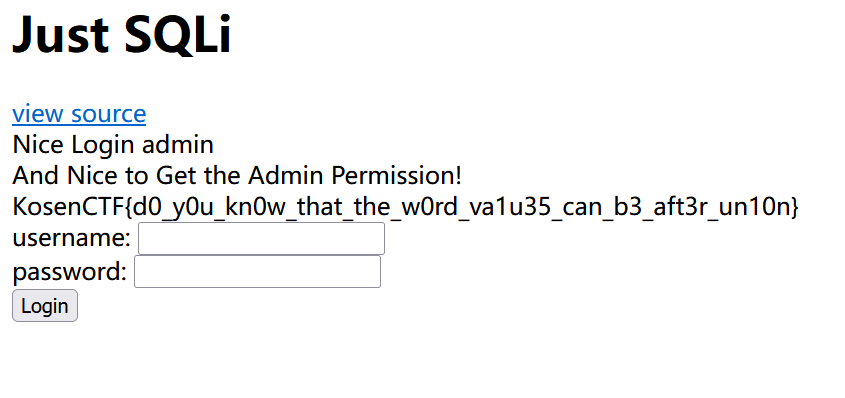
CTF网络安全大赛web题目:just_sqli
这道题目是bugku的web题目 题目的 描 述: KosenCTF{} 原文链接: CTF网络安全大赛web题目:just_sqli - 红客网-网络安全与渗透技术 题目Web源代码: <?php$user NULL; $is_admin 0;if (isset($_GET["source"])) {highlig…...

Java入门基础学习笔记27——生成随机数
Random的使用:生成随机数。 随机数应用: 随机点名: 年会抽奖: 猜数字游戏: 密码学。 查看API文档: package cn.ensource.random;import java.util.Random;public class RandomDemo1 {public static voi…...
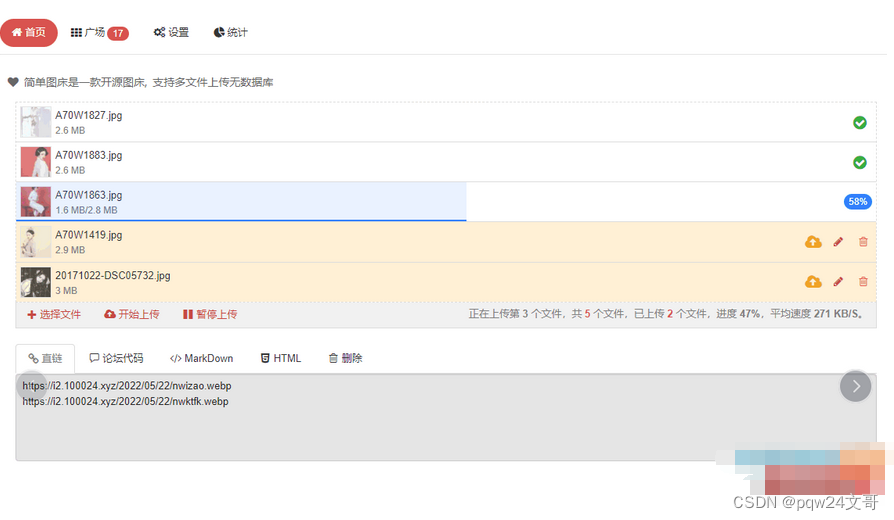
EasyImage2.0 图床源码
EasyImage2.0 是一个简单图床的源码,它支持以下功能: 1. API接口 2. 登录后才能上传图片 3. 设置图片质量 4. 压缩图片大小 5. 添加文字或图片水印 6. 设定图片的宽度和高度 7. 将上传的图片转换为指定的格式 8. 限制上传图片的最小宽度和高度 …...

人工智能创新领衔,Android系统如虎添翼:2024 Google I/O 大会深度解析
人工智能创新领衔,Android系统如虎添翼:2024 Google I/O 大会深度解析 2024年5月14日举行的Google I/O大会,犹如一场精彩的科技盛宴,吸引了全球的目光。大会上,谷歌发布了一系列重磅产品和技术更新,展现了…...

下单制造fpc的工艺参数
FPC工艺简介 - 百度文库 (baidu.com) FPC工艺参数 - 豆丁网 (docin.com) FPC柔性线路板的主要参数.ppt (book118.com) 捷多邦: 华秋: 背胶: FPC板背胶是可以粘接在光滑表面的一种薄型胶带,可以在狭小以及光滑的表面上用来提供高…...
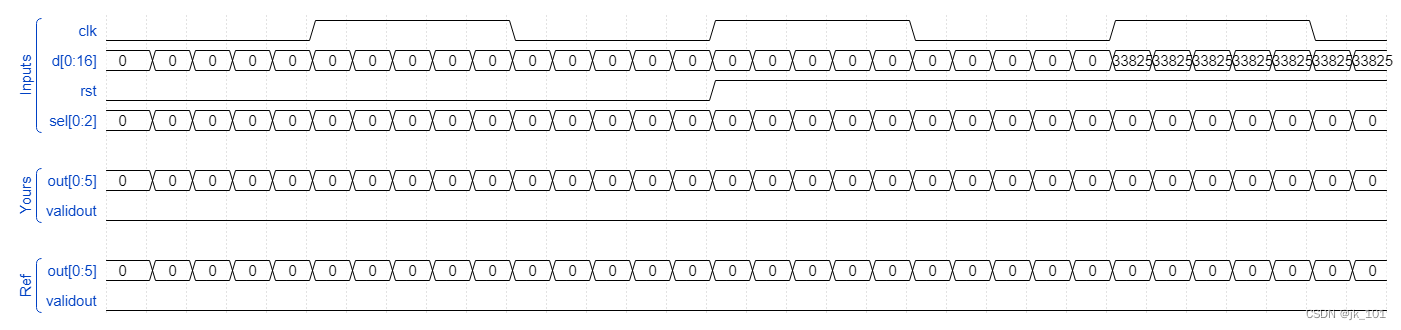
位拆分与运算
描述 题目描述: 现在输入了一个压缩的16位数据,其实际上包含了四个数据[3:0][7:4][11:8][15:12], 现在请按照sel选择输出四个数据的相加结果,并输出valid_out信号(在不输出时候拉低) 0: 不输出且只有此时的输入有…...

windows11目标文件夹访问被拒绝-将安全信息应用到以下对象时发生错误
将安全性信息应用到以下对象时发生错误”解决办法 要夺取所有权时,点“安全”添加用户并允许所有权限后点击“应用”, 一直“无法保存对。。。(文件夹名)权限所在的更改。拒绝访问”啊 必须先点击“高级”,把“允许父项…...

C#thread线程传参数更新UI的文本框
C#线程的用法有几个不同的地方: 1、怎么启动线程? 2、是不是需要传入参数? 3、是不是要调用到UI中的控件,并对其进行更新? 关于启动线程,这里一个示例是在form中启动: 定义一个private:sta…...
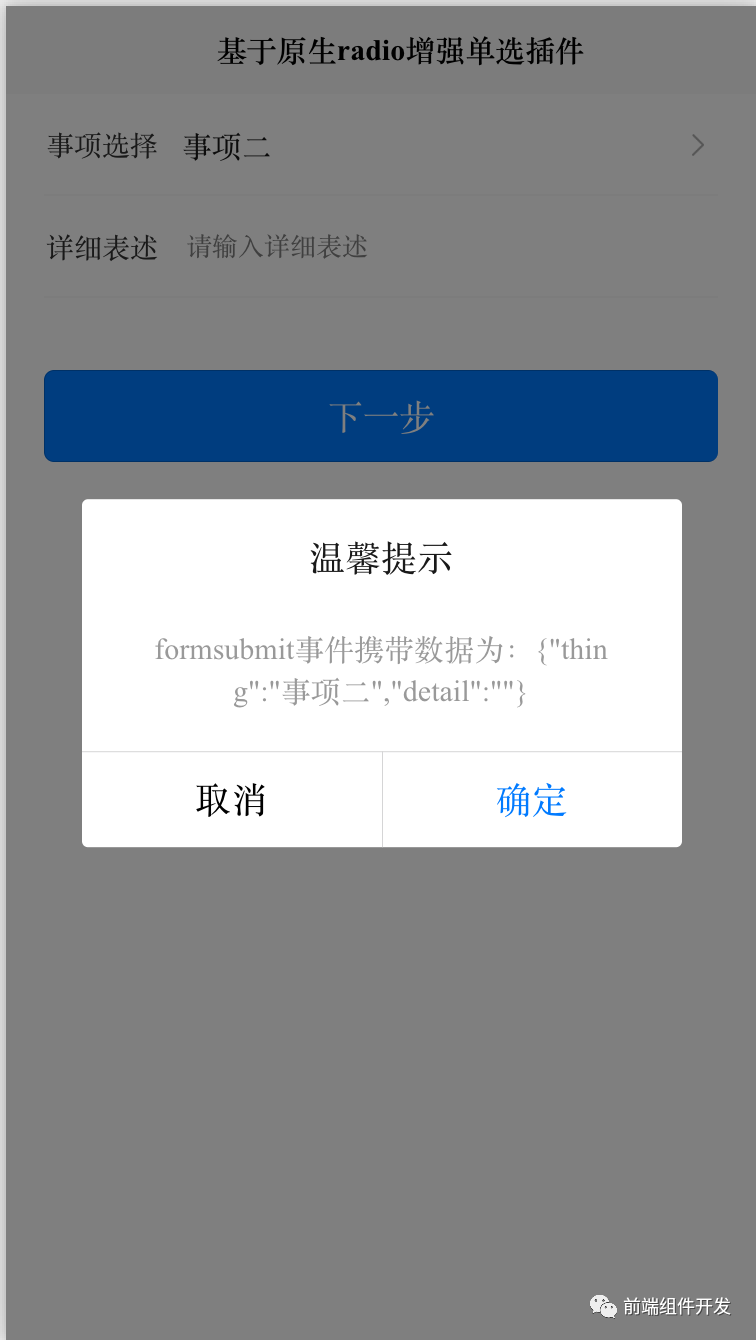
基于Vue和uni-app的增强型单选ccRadioView组件开发
标题:基于Vue和uni-app的增强单选组件ccRadioView的设计与实现 摘要:本文将详细介绍如何使用Vue和uni-app构建一个简单、好用且通用的单选框组件ccRadioView。该组件提供了单选列表的功能,并支持反向传值,方便开发者快速实现单选…...

信息系统项目管理师0602:项目立项管理 — 历年考题(详细分析与讲解)
点击查看专栏目录 1、2017年11月第31题 题干: 项目经理小李依据当前技术发展趋势和所掌握的技术能否支撑该项目的开发,进行可行性研究。小李进行的可行性研究属于( )。 选项: A. 经济可行性分析 B. 技术可行性分析 C. 运行环境可行性分析 D. 其他方面的可行性分析 答案…...

vue2 中使用audio播放音频
<audio controls ref"audioPlayer" style"width:800px;"><source :src"obj.audioUrl" /></audio> data() {return {obj: {audioUrl: require(../../../../public/audio/video.wav)}}}, 有个地方一定要注意一下. 如果不写req…...
一键追爆款,GPT一键改文 ,绘唐3,绘唐工具
ai画影满足你的制作要求 一键追爆款,GPT一键改文 入口工具 AI推文小说&漫画解说&解压混剪 人物定义,角色定义,lora转换,模型转换,可视化参考满足 一键追爆款 一键挂机生成,效果更精彩ÿ…...

在C#中编写递归函数时,为了避免无限递归
在C#中编写递归函数时,为了避免无限递归(也称为栈溢出),你需要确保递归调用有一个明确的终止条件。这个终止条件通常基于一个或多个参数,当这些参数满足某个特定条件时,递归就会停止并返回结果。 以下是一…...

css层叠样式表——基础css面试题
1、css样式来源有哪些? 內联样式-<a style"color:red"></a>内部样式-<style></style>外部样式-写在独立.css文件中的浏览器用户自定义样式浏览器默认样式 2、样式优先级问题 不同级别下: !important作为style属性…...
数据库-索引结构(B-Tree,B+Tree,Hash,二叉树)
文章目录 索引结构有哪些?二叉树详解?B-Tree详解?BTree详解?Hash详解?本篇小结 更多相关内容可查看 索引结构有哪些? MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包…...

Microsoft Azure AI语音服务
一:文字转语音SDK安装 安装语音 SDK - Azure AI services | Microsoft Learn 二:基于文本转语音Rest API 文本转语音 API 参考 (REST) - 语音服务 - Azure AI services | Microsoft Learn 三:基于文本合成语音 如何基于文本合成语音 - 语…...
【Linux】常用指令、热键与权限管理
一、常用指令 (1)ls 功能:列出指定目录下的所有子目录与文件 用法:ls (选项) (目录或文件名) 常用选项: -a:列出目录下的所有文件,包括隐藏…...

金融数据分析实战:从Python工具链到量化策略回测全流程解析
1. 项目概述:为什么我们需要一个“金融技能”仓库?在金融行业摸爬滚打了十几年,我见过太多聪明人因为工具和方法的缺失,在数据分析和决策上走了弯路。无论是刚入行的分析师,还是希望提升个人理财能力的职场人ÿ…...

构建企业级金融数据采集系统:AKShare进阶实战指南
构建企业级金融数据采集系统:AKShare进阶实战指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/akshar…...

【香橙派5】基于RKNN-Lite在RK3588上部署Yolov5的实战指南
1. 香橙派5与RK3588平台简介 香橙派5作为一款高性能的单板计算机,搭载了瑞芯微RK3588芯片,这颗芯片内置了强大的NPU(神经网络处理单元),算力高达6TOPS。这意味着它能够高效处理复杂的AI推理任务,比如实时目…...

Windows本地部署Claude代码助手:架构解析与实战指南
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“Claude-code-ChatInWindows”,作者是LKbaba。光看名字,你大概能猜到它想干什么:在Windows系统里,让Claude这个AI来帮你写代码。这听起来是不是挺酷的…...

观察 Taotoken 用量看板如何帮助团队清晰掌握 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 用量看板如何帮助团队清晰掌握 API 调用成本 对于依赖大模型 API 进行开发的项目团队而言,成本控制与预…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

Nix构建确定性AI编程环境:解决Cursor编辑器依赖冲突难题
1. 项目概述:当代码编辑器遇上Nix的确定性魔法 最近在折腾开发环境时,我遇到了一个老生常谈但又无比头疼的问题:团队里新来的同事怎么也跑不起来我本地运行得好好的一个代码辅助工具链。依赖版本冲突、系统库路径不对、甚至是因为他用的macO…...