大数据学习之 Hadoop部署
Hadoop部署
-
Linux桌面模式关闭
# 设置 systemctl set-default multi-user.target # 重启 reboot -
防火墙关闭
systemctl status firewalld systemctl stop firewalld # 关闭开机自启 systemctl disable firewalld -
配置Java环境
echo $JAVA_HOME java -version # Java配置 # 上传jar包并解压 tar -zxvf ...jdk.jar # 配置环境变量 vim /etc/profile JAVA_HOME=/usr/local/soft/jdk1.8.0_171 export PATH=$JAVA_HOME/bin:$PATH -
网络环境
# 查看IP ifconfig # 修改网络IP vim /etc/sysconfig/network-scripts/ifcfg-ens331 TYPE=Ethernet2 PROXY_METHOD=none3 BROWSER_ONLY=no4 BOOTPROTO=static5 DEFROUTE=yes6 IPV4_FAILURE_FATAL=no7 IPV6INIT=yes8 IPV6_AUTOCONF=yes9 IPV6_DEFROUTE=yes10 IPV6_FAILURE_FATAL=no11 IPV6_ADDR_GEN_MODE=stable-privacy12 NAME=ens3213 UUID=9d8db489-1d03-49dd-9a72-c106b667af6a14 DEVICE=ens3215 ONBOOT=yes16 IPADDR=192.168.44.10017 netmask=255.255.255.018 GATEWAY=192.168.44.2# 关闭网络管理器 systemctl status NetworkManager systemctl stop NetworkManager systemctl disable NetworkManager -
修改主机名称
vim /etc/hostname 在当前虚拟机中设置Master 之后克隆的三个节点需要设置node1 node2 -
克隆另外两台从节点 node1 node2
选中当前节点 关机 -> 右键 ->管理 -> 克隆 -> 当前状态 -> 创建完整克隆 -> 选择路径修改名称 -> 完成
注意:选中的路径最好是 SSD 固态 同时磁盘空间三个节点最少保证大于70G
-
修改克隆主机 一定要修改
先启动node1节点,配置好之后再启动node2
1.修改网络
2.修改主机名
-
修改IP映射
当node1 node2 配置完成后,再启动Master 修改IP映射
vim /etc/hosts # 安装自己的IP修改映射关系 192.168.44.100 master 192.168.44.110 node1 192.168.44.120 node2 -
配置主节点和其他节点之间的免密登录
免密登录
当在Master节点中需要控制node1 和 node2 节点启动相关的一些命令任务
需要使用 ssh root@ip/hostname ctrl+D:退出
后续Hadoop启动会切换到从节点启动任务,需要密码非常麻烦,所以需要配置免密登录
# 在Masetr节点中执行如下命令: # > 需要三次回车 ssh-keygen -t rsa # 将密码复制到 master node1 node2 > 需要输入密码 ssh-copy-id master ssh-copy-id node1 ssh-copy-id node2 # 验证:ssh node1 ctrl + d 退出登录 -
校验时间是否同步
使用xshell对当前所有会话同时发送命令 date 查看系统时间 如果时间不同步 ,那么需要配置
yum install ntp ntpdate time.windows.com -
正式开始配置Hadoop
上传Hadoop并解压
tar -zxvf hadoop-3.1.3.tar.gz -
配置环境变量
vim /etc/profile HADOOP_HOME=/usr/local/soft/hadoop-3.1.3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile -
修改配置文件
core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://master:9000</value> </property> <!-- 指定hadoop数据的存储目录 --> <property><name>hadoop.tmp.dir</name><value>/usr/local/soft/hadoop-3.1.3/data</value> </property>hdfs-site.xml
dfs.namenode.http-address master:50070
该配置项设置网页的访问端口 对于3.x版本的Hadoop其端口为9870
<!-- 2nn web端访问地址--> <property><name>dfs.namenode.secondary.http-address</name><value>master:9868</value> </property> <property><name>dfs.replication</name><value>1</value> </property><property><name>dfs.permissions</name><value>false</value> </property>yarn-site.xml
<!-- 指定MR走shuffle --> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property><name>yarn.resourcemanager.hostname</name><value>master</value> </property> <!-- 环境变量的继承 --> <property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- yarn容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>workers
在该文件中主要是对从节点的名称进行配置
node1
node2hadoop-env.sh
Hadoop的执行环境
# 在最后加入以下配置 export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
分发Hadoop到node1、node2
scp表示远程复制
-r 表示复制的为目录
root@node1 表示用户及IP 由于配置了免密登录所以不需要密码
:
pwdpwd 表示当前所在的目录路径 :需要指定目标位置的路径scp -r hadoop-3.1.3 root@node1:`pwd` scp -r hadoop-3.1.3 root@node2:`pwd` -
初始化Hadoop
# 初始化 hdfs namenode -format只能在Master中执行一次
# 启动集群 start-all.sh # 停止 stop-all.sh -
检查
-
页面
HDFS的访问页面 http://IP:9870/
Yarn的访问页面http://master:8088/
-
查看进程
jps(查看所有Java启动的进程) # Master节点 3273 NameNode 3548 SecondaryNameNode 3807 ResourceManager# node1节点 2977 NodeManager 2862 DataNode# node2节点 2977 NodeManager 2862 DataNode
-
-
Hadoop安装或运行过程出现问题
-
1.查看日志
在当前安装目录中找到logs 并分析哪个进程宕机,可以查看进程对应的日志文件
-
2.重新安装
1.删除所有节点中的data目录
2.寻找正确的配置文件,进行替换,并将所有节点进行同步
3.重新格式化
-
Hadoop存储
在Hadoop中数据存储是由HDFS组件决定的,可以通过9870端口进行访问,在Hadoop2.x版本中端口为50070
相关文章:

大数据学习之 Hadoop部署
Hadoop部署 Linux桌面模式关闭 # 设置 systemctl set-default multi-user.target # 重启 reboot防火墙关闭 systemctl status firewalld systemctl stop firewalld # 关闭开机自启 systemctl disable firewalld配置Java环境 echo $JAVA_HOME java -version # Java配置 # 上传ja…...

xxe漏洞--xml外部实体注入漏洞
1.xxe漏洞介绍 XXE(XML External Entity Injection)是一种攻击技术,它允许攻击者注入恶意的外部实体到XML文档中。如果应用程序处理XML输入时未正确配置,攻击者可以利用这个漏洞访问受影响系统上的敏感文件、执行远程代码、探测内…...

Nginx反向代理与负载均衡:让网站像海豚一样灵活
引言:"当网站遇上海豚:Nginx让数据流动更流畅!"想象一下,你的网站是一片繁忙的海域,而Nginx就像一群聪明的海豚,它们不仅能够迅速地找到最佳的捕食路线(反向代理)…...

企业应考虑的优秀云安全措施
作为云客户,企业有责任确保正确使用他们提供的工具来保证数据和应用程序的安全。让德迅云安全来跟大家一起研究一些典型企业应该考虑的优秀云安全措施。 在数据安全和隐私方面,企业是否在努力跟上疫情的发展?企业不是一个人。就像多年以前,C…...

如何将老板的游戏机接入阿里云自建K8S跑大模型(下)- 安装nvidia/gpu-operator支持GPU在容器中共享
文章目录 安装nvidia/gpu-operator支持GPU在容器中共享 安装nvidia/gpu-operator支持GPU在容器中共享 安装 nvidia/gpu-operator遇到两个问题: 由于我们都懂的某个原因,导致某些镜像一直现在不成功。 解决办法,准备一个🪜&#…...

代码随想录-Day16
104. 二叉树的最大深度 方法一:深度优先搜索 class Solution {public int maxDepth(TreeNode root) {if (root null) {return 0;} else {int leftHeight maxDepth(root.left);int rightHeight maxDepth(root.right);return Math.max(leftHeight, rightHeight) …...

31.@Anonymous
1►@Anonymous原理 大家应该已经习惯我的教学套路,很多时候都是先使用,然后讲述原理。 上节课我们使用了注解@Anonymous,然后接口就可以直接被访问到了,不用token!不用token!不用token!。 我们一般知道,注解是给程序看的,给机器看的,当然也是给程序员看的。注解如果…...

oracle 表同一列只取最新一条数据写法
select * from (select t.*,row_number() over(partition by 去重列名 order by 排序列名 desc) as rnfrom 表名)where rn1 1.row_number() over(....): 为每条数据分配一个行号,1.2.3....这样的 2.partition by : 以某列作为分组,每个分组行号从1开始…...
C语言游戏实战(12):植物大战僵尸(坤版)
植物大战僵尸 前言: 本游戏使用C语言和easyx图形库编写,通过这个项目我们可以深度的掌握C语言的各种语言特性和高级开发技巧,以及锻炼我们独立的项目开发能力, 在开始编写代码之前,我们需要先了解一下游戏的基本规则…...
提权方式及原理汇总
一、Linux提权 1、SUID提权 SUID(设置用户ID)是赋予文件的一种权限,它会出现在文件拥有者权限的执行位上,具有这种权限的文件会在其执行时,使调用者暂时获得该文件拥有者的权限。 为可执行文件添加suid权限的目的是简…...

【leetcode----二叉树中的最大路径和】
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。 路径和 是路径中各节点值的总和。 给你一个二叉树的根节点 root ,…...

Rust: 编译过程中链接器 `cc` 没有找到
这个错误信息表明在编译过程中链接器 cc 没有找到。cc 通常是 C 编译器的符号链接,它指向系统上的实际 C 编译器,如 gcc 或 clang。这个错误通常意味着你的系统缺少必要的编译工具链。 要解决这个问题,你需要确保你的系统上安装了 C 编译器。…...

【vue-3】动态属性绑定v-bind
1、文本动态绑定: <input type"text" v-bind:value"web.url"> 简写: <input type"text" :value"web.url"> 2、文字样式动态绑定 <b :class"{textColor:web.fontStatus}">vue学…...

Rust:多线程环境下使用 Mutex<T> 还是 Arc<Mutex<T>> ?
在 Rust 中,Mutex 本身不是线程不安全的;它提供了内部的线程同步机制。然而,如果你想在多线程环境中共享同一个 Mutex,你需要确保这个 Mutex 可以被多个线程访问。为此,你通常需要使用 Arc<Mutex<T>>。Arc…...

关于如何创建一个可配置的 SpringBoot Web 项目的全局异常处理
前情概要 这个问题其实困扰了我一周时间,一周都在 Google 上旅游,我要如何动态的设置 RestControllerAdvice 里面的 basePackages 以及 baseClasses 的值呢?经过一周的时间寻求无果之后打算决定放弃的我终于找到了一些关键的线索。 当然在此…...

docker三种自定义网络(虚拟网络) overlay实现原理
docker提供了三种自定义网络驱动:bridge、overlay、macvlan。 bridge驱动类似默认的bridge网络模式。 overlay和macvlan是用于创建跨主机网络。 支持自定义网段、网关,docker network create --subnet 172.77.0.0/24 --gateway 172.77.0.1 my_n…...
C#上位机1ms级高精度定时任务
precisiontimer 安装扩展包 添加引用 完整代码 using PrecisionTiming;using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; us…...

盘点28个免费域名申请大全
盘点28个免费域名申请大全 免费域名推荐学习使用,免费就意味着没任何保障。 名称稳定时间支持解析模式后缀格式说明地址EU.org28 年NS.eu.org/. 国家简写.eu.org需要审核,稳定性高,限制少,国内访问有问题,可 CFeu.orgp…...
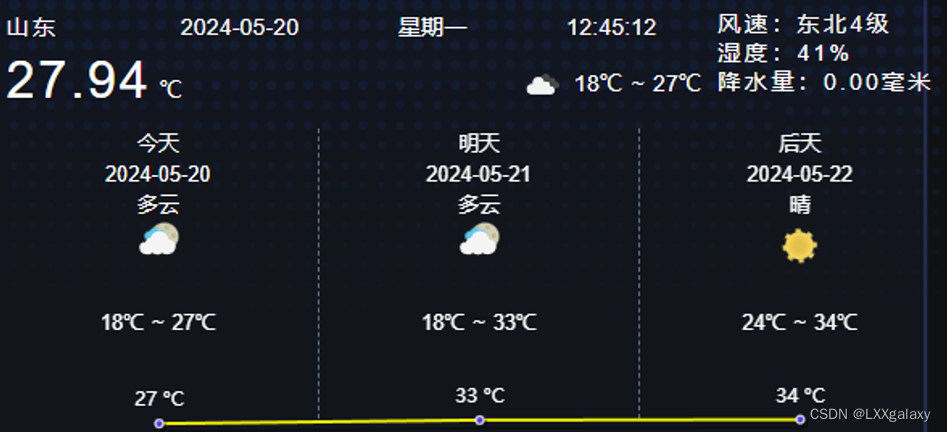
【vue】封装的天气展示卡片,在线获取天气信息
源码 <template><div class"sen_weather_wrapper"><div class"sen_top_box"><div class"sen_left_box"><div class"sen_top"><div class"sen_city">山东</div><qctc-time cl…...

【MySQL】库的操作和表的操作
库的操作和表的操作 一、库的操作1、创建数据库(create)2、字符集和校验规则(1)查看系统默认字符集以及校验规则(2)查看数据库支持的字符集(3)查看数据库支持的字符集校验规则(4)校验…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

终极指南:如何用WarcraftHelper让魔兽争霸3在现代电脑上完美运行 [特殊字符]
终极指南:如何用WarcraftHelper让魔兽争霸3在现代电脑上完美运行 🎮 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔…...

CN2628 可用太阳能供电 5 伏特低压差电压调制集成电路
概述: CN2628是一款可用太阳能供电的低噪声线性电压调制集成电路,采用固定5.0V输出电压,最大 输出电流可达1安培,在5.5V到7V的输入电压范围内输出电压精度可达1%。CN2628工作电流只有520微安,而且同输入和输出的压差没有关系。 CN…...

跨平台鼠标控制库ez-cursor-free:原理、实现与自动化实战
1. 项目概述与核心价值如果你是一名开发者,尤其是经常需要处理跨平台UI自动化、游戏脚本或者桌面应用交互的开发者,那么你一定对“鼠标控制”这个基础但又充满细节的环节感到过头疼。不同的操作系统(Windows, macOS, Linux)提供了…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

DeepMind Lab:强化学习研究的3D视觉仿真平台搭建与实战指南
1. 项目概述:一个被低估的强化学习研究“健身房”如果你在深度强化学习(Deep Reinforcement Learning, DRL)这个圈子里待过一段时间,或者正试图入门,那么你大概率听说过OpenAI的Gym、Unity的ML-Agents,甚至…...

【仿真学习框架】MultiModalWBC 完全指南:从入门到精通的多模态全身控制框架
版本: v1.0 | 日期: 2026-05-15 目标读者: 具身智能研究者、机器人学习工程师、人形机器人开发者 前置知识: 基础强化学习(PPO)、PyTorch、刚体动力学概念 📑 目录 1. 初见 MultiModalWBC:我们到底在解决什么问题? 1.1 人形机器人控制的"碎片化"困境 1.2 多模态…...