面试字节大模型算法实习岗,感觉有点崩溃。。。
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
重磅消息!《大模型面试宝典》(2024版) 正式发布!
喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们。
- 应聘岗位:字节大模型算法实习生
- 面试轮数:第一轮
- 整体面试感觉:偏难
1. 自我介绍
2. 技术问题回答
2.1 介绍一下 transformer?
传统的seq2seq模型使用循环神经网络(RNN)来处理序列数据,但RNN存在一些限制,如难以并行计算和难以捕捉长期依赖关系。Transformer则通过使用自注意力机制(self-attention)来解决这些问题。
Transformer模型由编码器和解码器组成。编码器将输入序列转换为一系列高维特征表示,而解码器则将这些特征表示转换为输出序列。编码器和解码器都由多个相同的层组成。每个层都包含一个自注意力子层和一个前馈神经网络子层。
自注意力机制允许模型在编码和解码过程中对输入序列的不同部分进行加权。它通过计算每个输入位置与其他位置之间的相关性得分,来决定每个位置的重要性。这样,模型可以更好地关注关键的上下文信息。
除了自注意力机制,Transformer还引入了残差连接和层归一化,来帮助模型更好地训练和优化。残差连接允许模型在不同层之间直接传递信息,层归一化则有助于减轻训练过程中的梯度问题。
Transformer模型的训练通常使用无监督的方式,如自编码器或语言模型。一旦训练完成,它可以用于各种序列到序列任务,如机器翻译、文本摘要、对话生成等。
2.2 transformer的输入和输出分别是什么?
Transformer 的输入是经过词嵌入(Word Embedding)和位置嵌入(Positional Embedding)处理后的序列,输出也是经过词嵌入和位置嵌入处理后的序列。
具体来说,Transformer 的输入是一个由单词或符号组成的序列,如句子或文本。首先,将这些单词或符号转换为它们的嵌入向量,通常是通过词嵌入技术实现的。然后,为每个单词或符号分配一个位置嵌入向量,以表示它们在序列中的位置。这些嵌入向量和位置嵌入向量被组合在一起,形成一个三维的张量,作为 Transformer 的输入。
Transformer 的输出也是一个由单词或符号组成的序列,与输入序列具有相同的形状。在 Transformer 中,输入序列和输出序列之间通过自注意力机制(Self-Attention)进行交互。在每个时间步,Transformer 都会计算输入序列中每个单词或符号与输出序列中每个单词或符号的注意力权重,并基于这些权重生成输出序列中的每个单词或符号的嵌入向量。最终,这些嵌入向量被转换回单词或符号,形成输出序列。
2.3 说一下 Bert模型?
BERT 模型的核心思想是通过大规模的无监督预训练来学习通用的语言表示,然后在特定任务上进行微调。相比传统的基于词的语言模型,BERT 引入了双向 Transformer 编码器,使得模型能够同时利用上下文信息,从而更好地理解词语在不同上下文中的含义。
BERT 模型的预训练阶段包含两个任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。在 MLM 任务中,模型会随机遮盖输入序列的一部分单词,然后预测这些被遮盖的单词。这样的训练方式使得模型能够学习到单词之间的上下文关系。在 NSP 任务中,模型会输入两个句子,并预测这两个句子是否是连续的。这个任务有助于模型理解句子之间的关联性。
在预训练完成后,BERT 模型可以通过微调在各种下游任务上进行应用,如文本分类、命名实体识别、问答系统等。通过微调,BERT 模型能够根据具体任务的数据进行特定领域的学习,从而提高模型在特定任务上的性能。
BERT 模型的优势在于它能够捕捉词语之间的上下文信息,从而更好地理解自然语言。它在多项自然语言处理任务中取得了领先的性能,并推动了该领域的发展。
2.4 说一下 transformer的输出和 bert 有什么区别?
-
Transformer输出: 在标准的Transformer模型中,输出是由解码器的最终层产生的,通常是一个表示整个序列的向量。这个向量可以用于各种任务,如文本分类、生成等。
-
BERT输出: BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer的预训练模型,主要用于学习丰富的上下文语境。BERT的输出不仅包含了整个序列的向量,还包括了每个输入词的上下文相关表示。BERT的预训练阶段包括两个任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
总的来说,BERT的输出更注重于每个词的上下文相关表示,而标准的Transformer输出更倾向于整个序列的表示。
2.5 注意力机制都有哪些?能不能简单介绍一下?
-
自注意力机制(Self-Attention): 给定一个输入序列,自注意力机制通过对序列中每个元素计算权重,然后将这些权重加权求和得到输出。这个权重表示了模型对输入中不同位置的关注程度。具体来说,对于每个位置,通过计算与其他位置的相似度得到一个权重,最后将这些权重应用于输入序列上。这使得模型能够同时关注序列中的多个位置。
-
多头注意力机制(Multi-Head Attention):
-
思路:为了提高模型的表达能力,Transformer引入了多头注意力机制,允许模型学习多组不同的注意力权重。每个注意力头都产生一个输出,最后通过线性变换和拼接得到最终的多头注意力输出。
-
缺点:MQA(multi query attention)会导致quality degradation,我们不希望仅仅是推理快,而且还希望quality可以对标MHA;
-
Group Query Attention(GQA)
-
动机:改进多查询注意力(MQA)的性能,以加速解码器的推理速度。现有的MQA方法可能导致质量下降,并且为了更快的推理速度需要训练单独的模型,并不理想。
-
方法:通过预训练模型进行上训练(uptraining),将现有的多头注意力(MHA)模型转换为使用MQA的模型,并引入分组查询注意力(GQA),多查询注意力和多头注意力的一种泛化方法。GQA使用中间数量的键值头(大于一个,小于查询头的数量),实现了性能和速度的平衡。
-
优势:论文的主要优势是通过上训练(uptraining)现有模型,以较小的计算成本将多头注意力模型转换为多查询模型,从而实现快速的多查询和高质量的推理。同时,引入的分组查询注意力方法在接近多头注意力的质量的同时,速度几乎与多查询注意力相当。
2.6 树模型是如何计算每个特征的重要性的?
树模型计算特征重要性主要是根据不用的指标来计算的。
-
基尼重要性(Gini Importance): 基尼重要性衡量了一个特征在决策树中的节点分裂中对纯度改善的贡献程度。通过计算每个特征在不同节点上的基尼指数减小量,然后加权求和,得到特征的重要性。
-
信息增益(Information Gain): 信息增益用于衡量一个特征在决策树节点分裂中对不确定性的减小程度。通过计算每个特征对目标变量的信息增益,可以评估其重要性。
2.7 如何构建多模态模型?
多模态模型结合了来自不同数据源或模态的信息,通常包括视觉、语言、音频等。构建多模态模型的一般步骤包括:
-
数据预处理: 将不同模态的数据统一格式,确保能够输入到模型中。
-
模型设计: 使用适当的深度学习架构,如融合型(Fusion-based)或并行型(Parallel-based),将不同模态的信息整合在一起。
-
训练和微调: 利用多模态数据进行模型训练,并通过微调来适应具体任务。
2.8 在多模态任务中,如果视觉模型的输出张量比语言模型的输出张量短很多,该进行什么操作?
可以尝试使用以下方法:
-
填充(Padding): 在视觉模型的输出中添加适当数量的填充,使其长度与语言模型的输出一致。
-
剪裁(Trimming): 在语言模型的输出中剪裁一部分,使其长度与视觉模型的输出一致。
-
使用注意力机制: 在模型设计中,可以使用注意力机制来动态地对不同模态的信息进行权重分配,从而处理不同长度的输出。
3. Leetcode 题
-
无重复字符的最长子串
-
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
-
提示:
-
0 <= s.length <= 5 * 104
-
s 由英文字母、数字、符号和空格组成
-
题目解答
class Solution:def lengthOfLongestSubstring(self, s: str) -> int:'''方法:左右指针+哈希表解析:无重复字串哈希表:存储当前遍历到的元素,并由于判断是否重复左右指针:r 用于 添加 不重复的字符l 用于 删除元素,直到 字串中无 重复字符位置思路:1.定义 左右指针 l和r,和 无重复字串哈希表2.当 遇到不重复的字符,将其加入 dic,r 并往右移动;3. 当 遇到重复的字符, l 边往右移动,边移除左边元素,直到遇到 s[l]!=s[r]4. 计算 当前不含有重复字符的 最长子串 的长度复杂度:时间:O(n)空间:O(n)'''l = 0r = 0s_len = len(s)s_set = set()res = 0while r<s_len and r>=l:if s[r] not in s_set:s_set.add(s[r])r = r+1else:while s[l]!=s[r]:s_set.remove(s[l])l = l+1s_set.remove(s[l])l = l+1res = max(res,r-l)return res
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
相关文章:

面试字节大模型算法实习岗,感觉有点崩溃。。。
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。 针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。 总结链接…...
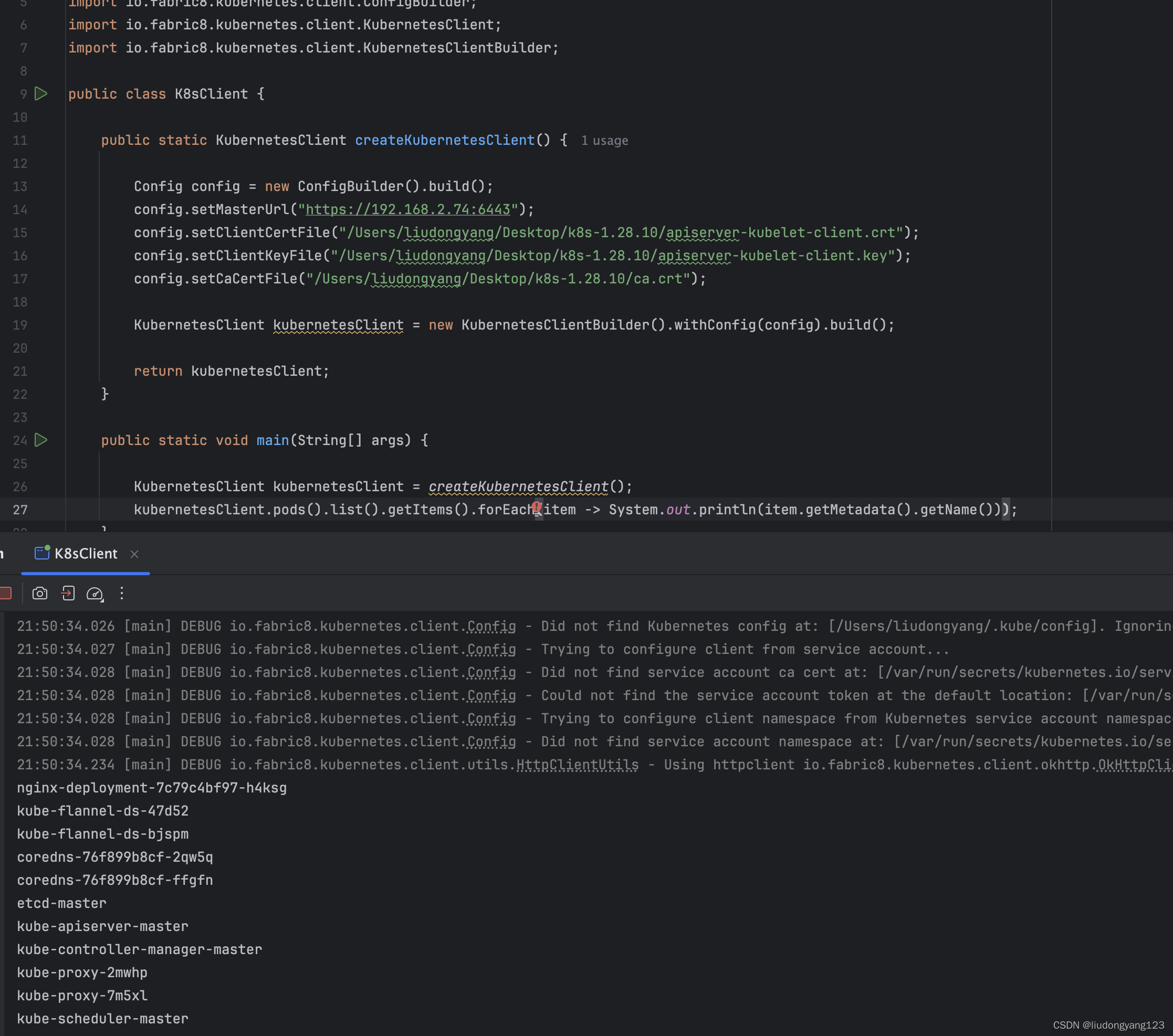
k8s 1.24.x之后如果rest 访问apiserver
1.由于 在 1.24 (还是 1.20 不清楚了)之后,下面这两个apiserver的配置已经被弃用 了,简单的说就是想不安全的访问k8s是不可能了,所以只能走安全的访问方式也就是 https://xx:6443了,所以需要证书。 - --ins…...

深度解析:用 Python 爬虫逆向破解 solscan 的请求头加密参数 Sol-Aut
大家好!我是爱摸鱼的小鸿,关注我,收看每期的编程干货。 逆向是爬虫工程师进阶必备技能,当我们遇到一个问题时可能会有多种解决途径,而如何做出最高效的抉择又需要经验的积累。本期文章将以实战的方式,带你详细地逆向分析 solscan 网站请求头加密字段 Sol-Aut 的构造逻辑,…...

Flutter 中的 InputDecorator 小部件:全面指南
Flutter 中的 InputDecorator 小部件:全面指南 在Flutter中,InputDecorator是一个用于装饰输入字段的组件,它为TextField和TextFormField提供了一个统一的外观和布局。InputDecorator可以让您自定义输入框的标签、填充、边框、图标、光标、错…...

useTransition:开启React并发模式
写在前面:并发 并发模式(Concurrent Mode)1的一个关键特性是渲染可中断。 React 18 之前,更新内容渲染的方式是通过一个单一的且不可中断的同步事务进行处理。同步渲染意味着,一旦开始渲染就无法中断,直到…...

Android 12系统源码_多窗口模式(二)系统实现分屏的功能原理
前言 上一篇我们具体分析了系统处于多窗口模式下,Android应用和多窗口模式相关方法的调用顺序,对于应用如何适配多窗口模式有了一个初步的认识,本篇文章我们将会结合Android12系统源码,具体来梳理一下系统是如何触发多窗口分屏模…...

字符函数:分类函数与转换函数
字符函数 一.字符分类函数二.字符转换函数 在编程的过程中,我们经常要处理字符和字符串,为了方便操作字符和字符串,C语⾔标准库中提供了一系列库函数,接下来我们就学习⼀下这些函数。 一.字符分类函数 C语言中有⼀系列的函数是专门…...

SpringBoot 集成Mybatis
SpringBoot集成第三方技术,一般都分为导坐标,改配置,写代码三个步骤。 集成Mybatis也类似,新建一个SpringBoot项目。修改:pom.xml文件。 一、导入坐标 <!--druid--> <dependency><groupId>com.al…...

C语言-atoi()库函数的模拟实现
文章目录 前言一、atoi()库函数的介绍及使用1.1 atoi()库函数介绍1.2 atoi()库函数使用 二、atoi()库函数的模拟实现2.1 函数设计2.2 函数实现思路2.3 具体实现2.4 测试 总结 前言 本篇文章介绍c语言中库函数atoi()的使用,以及模拟实现库函数。 一、atoi()库函数的…...

定时监测服务器磁盘是否超过阈值,超过就删除docker 镜像
达到指定百分比 删除镜像脚本 df -h 查找到 内存占用信息 ,得到的 文件系统名称是 overlay的,Use% 达到70就进行删除docker 镜像 #!/bin/bash# 设置磁盘使用阈值 THRESHOLD70# 获取 overlay 文件系统的磁盘使用百分比 DISK_USAGES$(df -h | grep overl…...

UDP聊天室
服务器端 #include <myhead.h>#define SER_IP "192.168.124.38" #define SER_PORT 8888 #define RBUFSIZE 128 #define WBUFSIZE 128typedef struct node{char usrName[20];struct sockaddr_in cli_sockaddr;struct node* next; }node, *node_p;node_p create…...
LLM多模态——GPT-4o改变人机交互的多模式 AI 模型应用
1. 概述 OpenAI 发布了迄今为止最新、最先进的语言模型 – GPT-4o也称为“全“ 模型。这一革命性的人工智能系统代表了一次巨大的飞跃,其能力模糊了人类和人工智能之间的界限。 GPT-4o 的核心在于其原生的多模式特性,使其能够无缝处理和生成文本、音频…...

安卓手机APP开发__蓝牙功能概述
安卓手机APP开发__蓝牙功能概述 目录 概述 基本内容 关键的类和接口 概述 安卓平台支持了蓝牙网络栈,它允许一个设备和其它的蓝牙设备进行无线的交换数据。 APP的框架…...

get和post的区别,二者是幂等的吗?
一、什么是幂等 所谓幂等性通俗的将就是一次请求和多次请求同一个资源产生相同的副作用。 维基百科定义:幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。 在编程中一个幂等操作的特点是其任意多次执…...

农场--Kruskal应用--c++
【题目要求】 农场里有一些奶牛,作为食物的草料不够了。农场主需要去别的农场借草料。该地区有N (2 < N < 2,000) 个农场,农场名称用数字N标识,农场之间的道路是双向的,一共有M (1 < M < 10,000)条道路,单…...
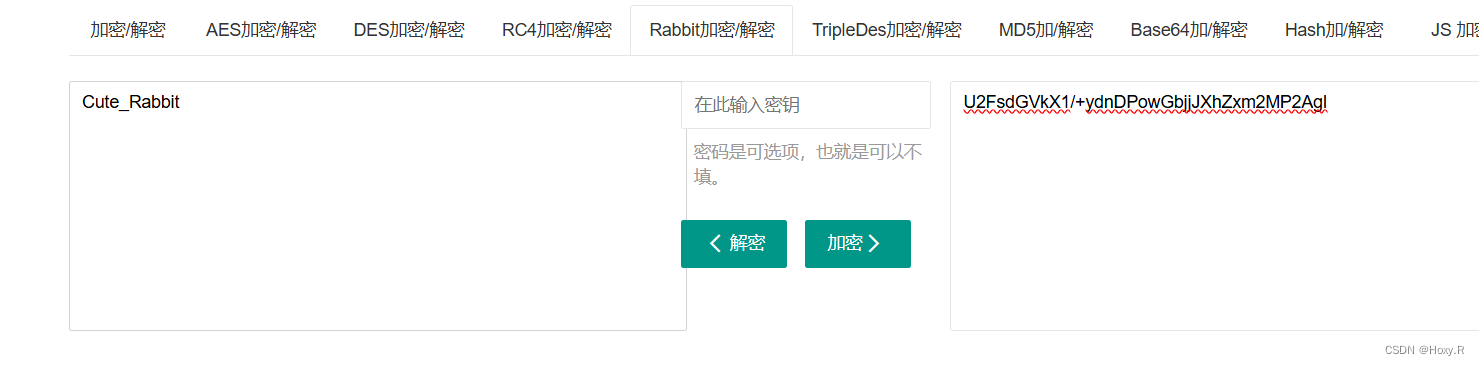
【Crypto】Rabbit
文章目录 一、Rabbit解题感悟 一、Rabbit 题目提示很明显是Rabbit加密,直接解 小小flag,拿下! 解题感悟 提示的太明显了...

IRFB3207PBF TO-220 N沟道75V/180A 直插MOSFET场效应管
英飞凌(Infineon)的 IRFB3207PBF 是一款高性能的 N 沟道 MOSFET,适用于多种电子设备和系统中的高侧开关应用。以下是 IRFB3207PBF 的一些典型应用场景: 1. 电源管理:在电源管理系统中,IRFB3207PBF 可以作为…...
的工作流演示)
基于单张图片快速生成Metahuman数字人(模型贴图绑定)的工作流演示
基于单张图片快速生成Metahuman数字人(模型贴图绑定)的工作流演示 MetahumanModeler, 是我基于facebuilder以及metahuman的理解开发而成,插件可以基于单张图片生成metahuman拓扑结构的面部3d模型,同时生成对应的面部的贴图&#…...

MySQL数据库下的Explain命令深度解析
Explain是一个非常有的命令,可以用来获取关于查询执行计划的信息,以及如何解释输出。Explain命令是查看查询优化器如何决定执行查询的主要方法。这个功能有一定的局限性,并不总是会说出真相,但是它的输出是可以获取的最好信息&…...
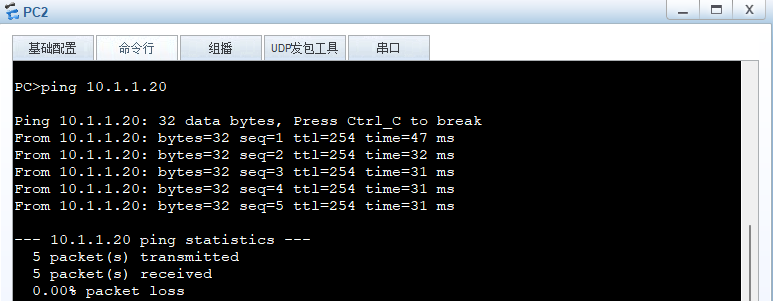
防火墙技术基础篇:基于IP地址的转发策略
防火墙技术基础篇:基于IP地址的转发策略的应用场景及实现 什么是基于IP地址的转发策略? 基于IP地址的转发策略是一种网络管理方法,它允许根据目标IP地址来选择数据包的转发路径。这种策略比传统的基于目的地地址的路由更灵活,因…...

WeChatFerry:微信机器人自动化框架的终极技术指南
WeChatFerry:微信机器人自动化框架的终极技术指南 【免费下载链接】WeChatFerry 微信机器人,可接入DeepSeek、Gemini、ChatGPT、ChatGLM、讯飞星火、Tigerbot等大模型。微信 hook WeChat Robot Hook. 项目地址: https://gitcode.com/GitHub_Trending/w…...

小白程序员必看:收藏这份分词知识框架,轻松入门大模型!
分词是NLP和大型语言模型处理文本的第一步。本文系统介绍了分词的基本概念,详细解析了英文和中文的分词方法,包括词级、字符级和子词级分词的原理与区别。特别强调了子词级分词(如BPE、WordPiece)在解决OOV问题和保留语义结构方面…...

OBS Source Record:解锁视频源独立录制的技术乐高
OBS Source Record:解锁视频源独立录制的技术乐高 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record 想象一下,你在OBS Studio中精心布置了一个包含摄像头、游戏画面和PPT演示的复杂场景&…...

终极AMD Ryzen性能调优指南:5分钟掌握SMUDebugTool免费调试神器
终极AMD Ryzen性能调优指南:5分钟掌握SMUDebugTool免费调试神器 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: h…...

QQ音乐加密音频一键解密:3步让Mac用户重获音乐自由
QQ音乐加密音频一键解密:3步让Mac用户重获音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换…...

大二学完 MyBatis 再学 MyBatis-Plus,我踩过的 10 个坑
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 本节目属于专栏《后端新手谈》:https://blog.csdn.net/2401_87662859/category_13141790.html 大家吼 ! 我是 逆境不可逃 今天给…...

【考研】2026/5/21
政治2026/5/21唯物辩证法本质上是批判的和革命的:在唯物辩证法看来,一切事物都处在发生、发展和灭亡的过程中,“不存在任何最终的东西、绝对的东西、神圣的东西”。唯物辩证法是客观辩证法与主观辩证法的统一:①客观辩证法&#x…...
)
STM32 USB开发避坑指南:手把手教你读懂并配置端点描述符(附完整代码)
STM32 USB开发避坑指南:手把手教你读懂并配置端点描述符(附完整代码) 在嵌入式开发领域,USB通信一直是让工程师又爱又恨的技术。爱它的通用性和高速传输能力,恨它那晦涩难懂的协议栈和层出不穷的配置问题。特别是当项目…...

KaTrain围棋AI:5步开启专业级围棋训练新时代 [特殊字符]
KaTrain围棋AI:5步开启专业级围棋训练新时代 🎯 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否渴望提升围棋水平,却苦于缺乏专业指导&am…...

【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架》. Lea…...