Go源码--sync库(1)sync.Once和
简介
这篇主要介绍 sync.Once、sync.WaitGroup和sync.Mutex
sync.Once
once 顾名思义 只执行一次 废话不说 我们看源码 英文介绍直接略过了 感兴趣的建议读一读 获益匪浅
其结构体如下
Once 是一个严格只执行一次的object
type Once struct {// 建议看下源码的注解,done 放在结构体第一个 所以其 地址就是 结构体的地址 不用加偏移量 则生成的汇编代码很紧凑,// 且cpu减少一次偏移量计算,执行效率高。所以对其频繁的访问(形成 hot path)速度更快。done uint32 m Mutex // 互斥锁
}
其当然只有一个函数 Do 我们来看下源码
// Do 严格执行一次 f
func (o *Once) Do(f func()) {// Note: Here is an incorrect implementation of Do://// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {// f()// }//// Do guarantees that when it returns, f has finished.// This implementation would not implement that guarantee:// given two simultaneous calls, the winner of the cas would// call f, and the second would return immediately, without// waiting for the first's call to f to complete.// This is why the slow path falls back to a mutex, and why// the atomic.StoreUint32 must be delayed until after f returns.// 上面英文翻译过来大意如下:// 注意 上述 代码里利用 CompareAndSwapUint32 来实现 是一个错误的示例。// 因为 Do 函数要确保 协程 返回时 f已经执行完毕了(因为如果f没执行完毕,// 某协程就返回,这时f当中配置项 可能还没初始化, 那么该协程 要调用 f 里// 定义的 配置项 可能 会报空指针异常),但是这种实现不能保证:例如 有两个// 同时对Do的调用,操作cas成功的调用会执行f(其实cas 中 比较 赋值 返回 这三种操作是// 直接调用操作系统 lock 命令实现的原子操作),另一个操作cas失败不会等第一个调用// 操作f 就直接返回。这就是为什么慢路径操作(doShow)会使用互斥锁,以及为什么 StoreUint32// 必须等 f 执行完毕后才能调用的原因。// 其实啰嗦了一大堆 就是要保证 所有调用 返回时 保证 f中初始化的配置文件 结构体 可用 不能报空指针异常等。// 这里是 第一波同时调用后(f已经执行完毕) ,后续调用可以直接对o.done来判断// 后续o.doSlow还要不要走,以便不执行加锁等影响效率的操作.// 另外done如果调用过多就是热路径, 会直接内联到调用处,我的理解是 直接将&o.done 替换成一个 变量 这个变量就是1if atomic.LoadUint32(&o.done) == 0 {// Outlined slow-path to allow inlining of the fast-path.o.doSlow(f)}
}其中 doSlow 函数如下
func (o *Once) doSlow(f func()) {o.m.Lock() // 加锁defer o.m.Unlock() // defer 压栈 最后执行if o.done == 0 { // 第一波同时调用 都在 锁这边 阻塞,则保证就一个执行 其余的直接返回就行 这就是为什么 必须要判断两次 o.done==0(第一次判断 见atomic.LoadUint32处 )defer atomic.StoreUint32(&o.done, 1) // defer 压栈 函数 f 执行完毕后 再修改 done的值f() // 执行函数}
}
sync.WaitGroup
WaitGroup结构体如下
type WaitGroup struct {noCopy noCopy// 原子类的 数据存储 为 64位,其中高32位存 待完成的任务(协程)数,低32位存储 在信号sema处阻塞的协程数(一般情况下是主协程,所以 waiter 一般为1)state atomic.Uint64 // high 32 bits are counter, low 32 bits are waiter count.sema uint32 // 信号量 阻塞了多少协程(一般是主协程) 阻塞逻辑根据这个参数控制 一般情况最大也就是1
}
其中关于 32 位和 64位等平台 运行差异可以自行搜索查看,不在赘述
其中最重要的函数是 Add(delta int), Done(), Wait().
下面举一个小例子
func demo(wg *sync.WaitGroup) {fmt.Println("this is demo")wg.Done() // 执行完任务后 任务数减1}func TestWaitGroup(t *testing.T) {var wg sync.WaitGroupwg.Add(5) // Add 函数 用来 添加需要 执行多少任务for i := 0; i < 5; i++ {go func() {demo(&wg)}()}wg.Wait() // 主协程阻塞 等待 任务完成
}其中 Add(delta int)函数 讲解 如下:
// Add 添加一个 delta 数量的未完成任务;delta可以为负数
func (wg *WaitGroup) Add(delta int) {if race.Enabled { // 一般为false ,测试情况下为trueif delta < 0 {// Synchronize decrements with Wait.race.ReleaseMerge(unsafe.Pointer(wg))}race.Disable()defer race.Enable()}state := wg.state.Add(uint64(delta) << 32) // state 高32为 加 deltav := int32(state >> 32) // 高32位为 待完成协程数w := uint32(state) // 阻塞等待协程数;一般为主协程阻塞 w一般为 0和1 ,有大神知道例外情况不,欢迎补充if race.Enabled && delta > 0 && v == int32(delta) {// The first increment must be synchronized with Wait.// Need to model this as a read, because there can be// several concurrent wg.counter transitions from 0.race.Read(unsafe.Pointer(&wg.sema))}if v < 0 { // 待完成任务数 <0 例如: Add(2) 但是 Done()了 3次panic("sync: negative WaitGroup counter")}if w != 0 && delta > 0 && v == int32(delta) { // Add和Wait在并发条件下被调用,不合理panic("sync: WaitGroup misuse: Add called concurrently with Wait")}if v > 0 || w == 0 { // 当待完成的任务大于0 或者 等待任务是0 (没走到主协程调用wait),则返回return}// This goroutine has set counter to 0 when waiters > 0.// Now there can't be concurrent mutations of state:// - Adds must not happen concurrently with Wait,// - Wait does not increment waiters if it sees counter == 0.// Still do a cheap sanity check to detect WaitGroup misuse.if wg.state.Load() != state { // 误用panic("sync: WaitGroup misuse: Add called concurrently with Wait")}// Reset waiters count to 0.wg.state.Store(0) // 先将 state 置为 0,走到这一步时,肯定是 v==0&&w>0,这时开始唤醒 沉睡的协程(主程序),所以为了复用wg需要初始化其参数for ; w != 0; w-- { // 根据 waiter数量 唤醒 每个在sema处阻塞的协程,下面函数执行完毕后 sema为1runtime_Semrelease(&wg.sema, false, 0) // 释放 信号量 唤醒 沉睡的协程,这里 wg.sema采用cas自增1}
}
Done()函数源码 如下
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() { // Done 就是 协程完毕后 非完成协程数减1wg.Add(-1)
}
Wait()函数 源码 如下:
func (wg *WaitGroup) Wait() {if race.Enabled {race.Disable()}for { // 请注意 for循环 目前只会执行一次循环 Wait的阻塞机制不在 for 循环处(至少 通常情况下是)state := wg.state.Load()v := int32(state >> 32)w := uint32(state)if v == 0 { // 如果 非完成的协程数为0,则Wait直接返回。例如: 主程序还没走到 Wait()代码处,前面调用了sleep函数,// 则到Wait时可能所有协程都执行完毕了,这时 v==0// Counter is 0, no need to wait.if race.Enabled {race.Enable()race.Acquire(unsafe.Pointer(wg))}return}// Increment waiters count.if wg.state.CompareAndSwap(state, state+1) { // 这里是 cas对state进行自增;主程序来增state的低32位也就是 waiter数,// 这里大家应该就明白了 Wait只有主程序调用所以 state低32位最大是1(其他情况请大神告诉下)if race.Enabled && w == 0 {// Wait must be synchronized with the first Add.// Need to model this is as a write to race with the read in Add.// As a consequence, can do the write only for the first waiter,// otherwise concurrent Waits will race with each other.race.Write(unsafe.Pointer(&wg.sema))}runtime_Semacquire(&wg.sema) // 在这边阻塞(看其源码是调用这个函数的协程阻塞,也就是主协程阻塞),这时 未完成协程大于0;其会一直阻塞直到 sema大于0(Add函数最后代码部分),然后就对 sema进行递减 唤醒协程(主协程);// 目前sema就两个值 跟 state一样 0 ,1 所以逻辑相对简单。其源码 见 runtime/sema.go 感兴趣的可以看看if wg.state.Load() != 0 { // 查看state是否被重置了(见 Add wg.state.Store(0) ) 如果没有 panicpanic("sync: WaitGroup is reused before previous Wait has returned")}if race.Enabled {race.Enable()race.Acquire(unsafe.Pointer(wg))}return // 唤醒主协程后 退出 Wait()函数}}
}sync.Mutex
锁 就是我锁上 你不能用 我打开你才能用 sync.Mutex 主要采用了 自旋(runtime_doSpin(): 操作系统命令 pause)和睡眠(runtime_SemacquireMutex: 类似 linux futex阻塞) )方式来 使得 协程进行阻塞也就是上锁。采用释放信号量 (runtime_Semrelease)来唤醒阻塞协程(可以唤醒任意一个或者队列第一个)或者自旋直接获取锁(无需信号量参与)
看似挺简单 但其源码 我利用业余时间大概看了一周左右吧 虽然也就二百多行 但是是我看过有限源码里比较难理解的了,所以再向大神对齐的路上是愈来愈拉胯了看来,下面我们开始分析下源码
我们看下Mutex锁结构体
type Mutex struct {state int32 // 锁的状态 sema uint32 // 信号量
}
其实现了如下锁接口:
type Locker interface {Lock()Unlock()
}
首先需要先认识几个参数 如下:
const (mutexLocked = 1 << iota // 锁上锁标志mutexWoken // 有协程被唤醒标志mutexStarving // 当前锁饥饿标志mutexWaiterShift = iota // state左移右移 位数 用来计算 waiters数量// Mutex fairness. //// Mutex can be in 2 modes of operations: normal and starvation.// In normal mode waiters are queued in FIFO order, but a woken up waiter// does not own the mutex and competes with new arriving goroutines over// the ownership. New arriving goroutines have an advantage -- they are// already running on CPU and there can be lots of them, so a woken up// waiter has good chances of losing. In such case it is queued at front// of the wait queue. If a waiter fails to acquire the mutex for more than 1ms,// it switches mutex to the starvation mode.//// In starvation mode ownership of the mutex is directly handed off from// the unlocking goroutine to the waiter at the front of the queue.// New arriving goroutines don't try to acquire the mutex even if it appears// to be unlocked, and don't try to spin. Instead they queue themselves at// the tail of the wait queue.//// If a waiter receives ownership of the mutex and sees that either// (1) it is the last waiter in the queue, or (2) it waited for less than 1 ms,// it switches mutex back to normal operation mode.//// Normal mode has considerably better performance as a goroutine can acquire// a mutex several times in a row even if there are blocked waiters.// Starvation mode is important to prevent pathological cases of tail latency.// 以上翻译如下:// Mutex 公平锁// Mutex 有两种模式 :正常模式和饥饿模式// 正常模式下获取锁的顺序是先进先出,但是一个唤醒的等待者需要和一个新到达的协程竞争锁。// 新到达的协程有一个优势,它们已经在cpu上运行了而且数量很多,所以刚被唤醒的协程就失去// 了抢占锁的机会,这时它就会排在队列的头部。如果一个协程超过1ms没获取锁,那么锁状态就会// 切换为饥饿模式。// 饥饿模式下 直接将锁从正在执行 unlock操作 的协程交给 队列头部排队的协程,即使锁未锁// 定状态新到达的协程也不能获得锁,也不进行自旋。相反他们会直接查到队列尾部// 这是从 正常模式到饥饿模式 还得从饥饿模式切换回去呢 要满足两个条件// (1) 协程是队列最后一个 (2) 它等待时间少于1ms// 正常模式性能要好很多,因为即使有阻塞的等待协程,一个协程也可以连续多次获取锁 ?? 这是为啥// 1msstarvationThresholdNs = 1e6
)
那说完了这些 以上这些参数跟 mutex啥关系呢 我们来看一张图

看到了吧 直接用 位图 前三位来表示mutex的各种状态 后29位来表示 waiters的数量
接下来 我们来看下 mutex 实现的 Locker的两个函数
Lock()函数
我们先来梳理下其粗粒度的流程图:
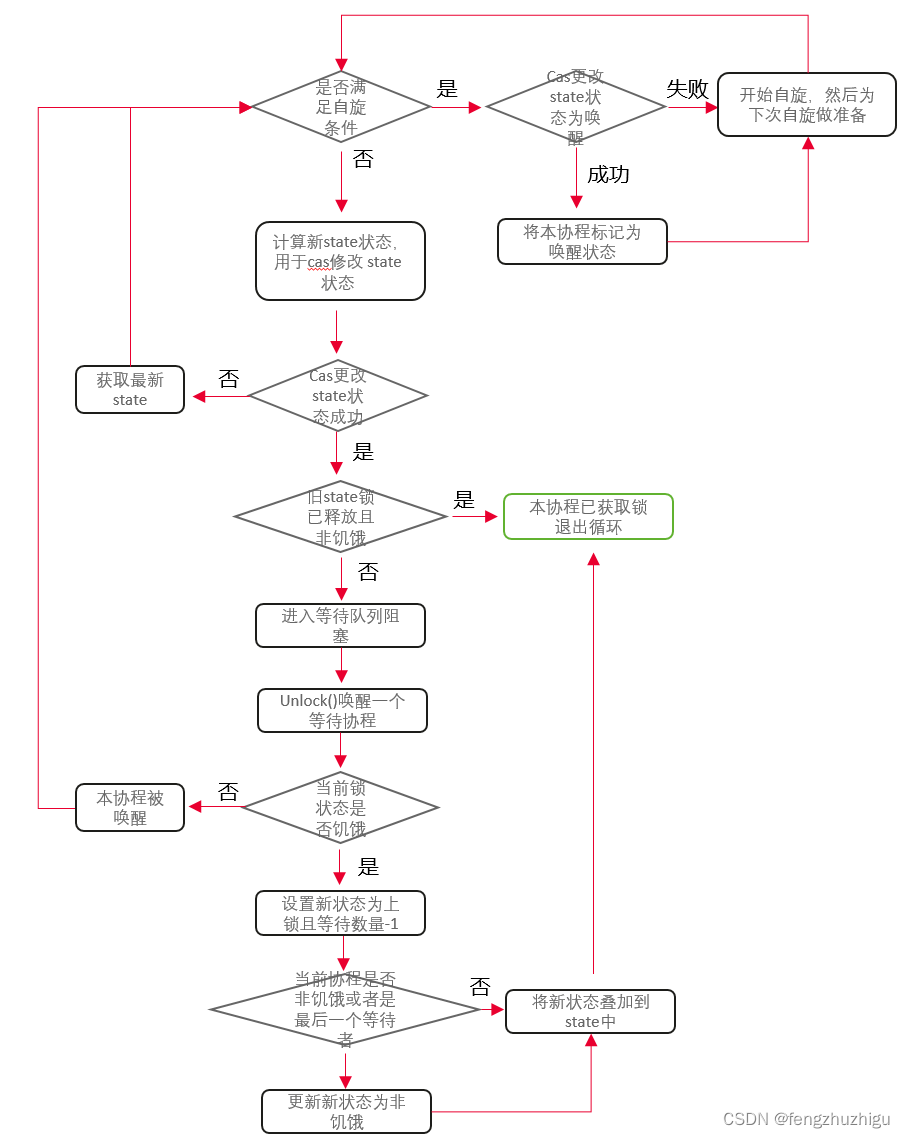
下面代码可以按照上图进行梳理
// Lock() 先采用cas快速获取锁 如果获取失败 就 阻塞等待锁释放 ps: 阻塞其实有三种情况 1 自旋 2. 进入 等待队列 3. 前两种都失败 继续 for重试1,2两种情况 这也会造成阻塞的效果
func (m *Mutex) Lock() {// Fast path: grab unlocked mutex.if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {if race.Enabled {race.Acquire(unsafe.Pointer(m))}return}// Slow path (outlined so that the fast path can be inlined)m.lockSlow()
}
其中最重要的 是 lockSlow()函数 是重点 也是难点
其代码如下:
// 其实说白了 就是根据锁当前的状态和当前协程的状态 来 更新 锁状态 更新 当前协程状态 然后在一定条件下阻塞协程(pause 或者加入队列)
func (m *Mutex) lockSlow() {var waitStartTime int64 // 当前协程等待的时间starving := false // 当前协程状态awoke := false // 当前协程是否被唤醒iter := 0 // 当前协程自旋次数old := m.state // 当前锁状态for {// Don't spin in starvation mode, ownership is handed off to waiters// so we won't be able to acquire the mutex anyway.// 自旋条件:非饥饿模式、锁锁着、没达到最大自旋次数 自旋就是 浪费cpu的时钟周期 所以要 限制自旋的次数if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {// Active spinning makes sense.// Try to set mutexWoken flag to inform Unlock// to not wake other blocked goroutines.// 协程唤醒条件: 当前协程非唤醒、锁非唤醒、等待的协程数不为0 则更新锁为唤醒状态 更新成功后 协程变为唤醒状态// 将锁 置为唤醒模式 是防止 mutex解锁时再唤醒其他协程if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {awoke = true}// 协程开始睡眠 底层调用的 操作系统 pauseruntime_doSpin()// 自旋数加1iter++// 重新获取 state值 用于比较计算old = m.statecontinue}// 不能自旋时,要么cas更新 state某个标志位和waiters数量 要么 继续 for循环 执行如下逻辑。// 其实不能自旋就两种情况:// 1. 本协程原因 自旋达到了 阈值// 2. 别的协程原因 修改了 state 使得 old&(mutexLocked|mutexStarving) == mutexLocked 为false 咦 这不废话吗// 以下代码主要开始准备计算 new 用cas来更新 statenew := old// Don't try to acquire starving mutex, new arriving goroutines must queue.// 如果是非饥饿模式 new 状态 变为 上锁(新来的协程 锁状态不是饥饿 就不用去queue里等待 可以直接尝试获取锁 所以要更新 new)if old&mutexStarving == 0 {new |= mutexLocked}// 等待协程数加1条件: 当前锁锁着或者为饥饿状态(于此相反的 是 非锁定且非饥饿状态 可以直接尝试获取锁 无需增加等待记数)if old&(mutexLocked|mutexStarving) != 0 {new += 1 << mutexWaiterShift}// The current goroutine switches mutex to starvation mode.// But if the mutex is currently unlocked, don't do the switch.// Unlock expects that starving mutex has waiters, which will not// be true in this case.// new更新为饥饿状态:当前协程 饥饿状态(等待超过1ms) 并且 锁锁着if starving && old&mutexLocked != 0 {new |= mutexStarving}// 看了几篇帖子 还是没整明白这里 先 todo吧if awoke {// The goroutine has been woken from sleep,// so we need to reset the flag in either case.if new&mutexWoken == 0 {throw("sync: inconsistent mutex state")}// 清除 唤醒标记new &^= mutexWoken}// 开始采用cas 根据 new 修改 state cas 成功后 (有可能就只更新了 协程等待数) 进行 计算等待时间 入等待队列 等 操作if atomic.CompareAndSwapInt32(&m.state, old, new) {// 如果原先的 状态是 锁已释放 且 是非饥饿状态,则这个协程可直接获取锁 且可直接 执行 Lock()后的代码,没必要执行下面 入队列 等逻辑了if old&(mutexLocked|mutexStarving) == 0 {break // locked the mutex with CAS}// 走到这里 证明 原先锁 未释放 或者 是饥饿状态 则 需要将 协程加入队列(头或者尾部)注意这里 我们不管 new是啥状态 只管原先old的状态// If we were already waiting before, queue at the front of the queue.// 如果原先等待过 则 cas成功后 直接 加入等待队列头 设置计算本协程等待时间queueLifo := waitStartTime != 0// 等待时间初始化 作为基准时间if waitStartTime == 0 {waitStartTime = runtime_nanotime()}// 将当前协程 加入等待队列(已等待过直接加入等待头部)使用sleep源语进行阻塞runtime_SemacquireMutex(&m.sema, queueLifo, 1)// 下面代码是本协程出队列被唤醒后 执行的// 加入等待队列后 计算等待时间 超过阈值 修改本协程状态为 饥饿starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs// 获取当前锁状态old = m.state// 当前锁为饥饿 则直接获取锁 (防止协程被饿死),否则就去自旋if old&mutexStarving != 0 {// If this goroutine was woken and mutex is in starvation mode,// ownership was handed off to us but mutex is in somewhat// inconsistent state: mutexLocked is not set and we are still// accounted as waiter. Fix that.// 协程是被唤醒的 且锁是饥饿模式下 锁一定是未锁定,且是未被唤醒状态(如果是唤醒状态 todo)或者 队列位空 则抛出异常if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {throw("sync: inconsistent mutex state")}// 等待队列数量减1 同时 设定锁为锁定状态 delta 最终是要 加在 atomic.AddInt32 上 下面式子 可以分解为// 1. 设定锁为锁定状态 atomic.AddInt32(&m.state, mutexLocked)// 2. 等待队列数量减1 atomic.AddInt32(&m.state, - 1<<mutexWaiterShift)// 由于 其在 state 中的 二进制表示 互不影响 所以可以 合并成 int32(mutexLocked - 1<<mutexWaiterShift)delta := int32(mutexLocked - 1<<mutexWaiterShift)// 如果当前协程处于非饥饿状态 或者本协程是最后一个 等待者 则 将锁状态置为正常状态(改为正常状态 是因为饥饿模式下 所有协程都会入队列sleep 不会自旋等待 性能消耗大)if !starving || old>>mutexWaiterShift == 1 {// Exit starvation mode.// Critical to do it here and consider wait time.// Starvation mode is so inefficient, that two goroutines// can go lock-step infinitely once they switch mutex// to starvation mode.delta -= mutexStarving}// 因为是被唤醒的 则直接更新状态 就行 不用cas 更新完成后直接退出 Lock() 执行 其后代码atomic.AddInt32(&m.state, delta)break}// 本协程被唤醒 自旋次数清零 且从for循环重新开始awoke = true// 自旋次数清零iter = 0} else {// 自旋或者 cas修改锁状态失败 继续获取 state 从 for循环开始 这时 本协程 既没有 修改本身任何状态 也没有修改state任何状态old = m.state}}if race.Enabled {race.Acquire(unsafe.Pointer(m))}
}
Unlock()
unlock就比较简单了 我们直接看它
func (m *Mutex) Unlock() {if race.Enabled {_ = m.staterace.Release(unsafe.Pointer(m))}// Fast path: drop lock bit.// 因为 Unlock 只能一个协程执行 所以 可以直接修改 锁状态 锁解锁new := atomic.AddInt32(&m.state, -mutexLocked)// 如果 等待协程数量不为0 或者 锁饥饿 或者 锁为唤醒状态 执行慢解锁流程 否则 解锁完毕if new != 0 {// Outlined slow path to allow inlining the fast path.// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.m.unlockSlow(new)}
}其中 unlockSlow()函数 代码如下
func (m *Mutex) unlockSlow(new int32) {if (new+mutexLocked)&mutexLocked == 0 {fatal("sync: unlock of unlocked mutex")}// 如果锁 非 饥饿if new&mutexStarving == 0 {old := newfor {// If there are no waiters or a goroutine has already// been woken or grabbed the lock, no need to wake anyone.// In starvation mode ownership is directly handed off from unlocking// goroutine to the next waiter. We are not part of this chain,// since we did not observe mutexStarving when we unlocked the mutex above.// So get off the way.// 如果 等待的协程为0 没必要再去更新 state 状态了 直接返回// 如果锁上锁了 表示已经有协程获取到了锁 不用再唤醒 且 等待协程减1了 直接返回// 如果锁是唤醒状态 说明已经有协程被唤醒了 (自旋的没入队列的协程被唤醒 这就是为什么 自旋的协程比 入队列协程更容易获取锁的原因)// 如果锁是 饥饿状态 todo 不用更新 等待协程数量?? 为啥不执行 runtime_Semrelease(&m.sema, true, 1) ??if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {return}// Grab the right to wake someone.// 等待协程数-1 锁状态 置为以唤醒new = (old - 1<<mutexWaiterShift) | mutexWokenif atomic.CompareAndSwapInt32(&m.state, old, new) {// 唤醒一个协程runtime_Semrelease(&m.sema, false, 1)return}old = m.state}} else {// Starving mode: handoff mutex ownership to the next waiter, and yield// our time slice so that the next waiter can start to run immediately.// Note: mutexLocked is not set, the waiter will set it after wakeup.// But mutex is still considered locked if mutexStarving is set,// so new coming goroutines won't acquire it.// 饥饿模式下 直接唤醒队列头协程,注意此时state还没加锁状态 唤醒的 协程会设置,也会 执行 等待队列数减1等// 注意 在饥饿模式下 锁仍然被认为是 锁定的状态 (我个人认为只是效果一样,因为饥饿状态 别的协程过来 会直接插到 队列尾部 不会去获取锁 因为不会自旋)runtime_Semrelease(&m.sema, true, 1)}
}还是有一些小疑问 没解决 先放着吧 有大神知道的可以解答下 疑问点都标注在注解中了
sync/atomic 包
sync.Pool
sync.Map
总结
相关文章:
Go源码--sync库(1)sync.Once和
简介 这篇主要介绍 sync.Once、sync.WaitGroup和sync.Mutex sync.Once once 顾名思义 只执行一次 废话不说 我们看源码 英文介绍直接略过了 感兴趣的建议读一读 获益匪浅 其结构体如下 Once 是一个严格只执行一次的object type Once struct {// 建议看下源码的注解…...

头歌OpenGauss数据库-I.复杂查询第3关:统计总成绩
本关任务:计算每个班的语文总成绩和数学总成绩,要求科目中低于60分的成绩不记录总成绩。 tb_score结构数据: namechinesemathsA8998B9989C5566D8866E5566F8899tb_class表结构数据: stunameclassnameAC1BC2CC3DC2EC1FC3--#请在此添加实现代码 --# # # # # # # # # # Begin #…...

LeetCode hot100-47-N
105. 从前序与中序遍历序列构造二叉树给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。这题放选择题里还能选出来,前序中序一起确定了一颗什…...

中北大学软件学院计算机网络实验一
目录 1.实验名称2.实验目的3.实验内容4.实验过程(1)安装Packer Tracer并熟悉软件操作(2)利用一台型号为2960的交换机将2台pc机互连组建一个小型局域网(3)分别设置pc机的ip地址(4)验证…...
扩散模型学习1
DDPM 总体训练原理 https://www.bilibili.com/video/BV1nB4y1h7CN/?spm_id_from333.337.search-card.all.click&vd_sourcef745c116402814185ab0e8636c993d8f 讲得很好:每次都是输入t和noise-x的图像,预测noise之后得到和加入的noise比较;…...

【HTML】制作一个跟随鼠标的流畅线条引导页界面(可直接复制源码)
目录 前言 HTML部分 CSS部分 JS部分 效果图 总结 前言 无需多言,本文将详细介绍一段HTML代码,图中线条可跟随鼠标移动,具体内容如下: 开始 首先新建一个HTML的文本,文本名改为[index.html],创建好后右…...

vue3父子组件、跨级组件之间的通信之provide, inject -- 通俗易懂
当组件之间的跨度比较大时,用父子孙之间的通信需要层层传递,不优雅,也不方便传值和更新。 此方法适用于父子组件之间、爷孙组件之间的通信且高效。 父组件: 孙组件: 此处本组件触发点击事件后,count的数据…...

input输入多行文本,保存为.dot文件和对应的.txt文件
需求 不管是上面的dot还是这个dot 变成 input输入文本按“# ꧂ ꧁”结束保存在dot文本文件夹下,用txt保存每个文件文件名: 编号. 第二行有字文字 时间戳 代码 首先,我会创建一个Python脚本,它将接受用户的输入,直到…...
如何让社区版IDEA变得好用
如何让社区版IDEA变得好用 背景 收费版的idea功能非常强大,但是费用高。社区版的免费,但是功能被阉割了。如何才能让社区版Idea变得好用,就需要各种插件支持了。经过全局配置编码,maven,jdk版本,在加上各…...
Hsql每日一题 | day02
前言 就一直向前走吧,沿途的花终将绽放~ 题目:主播同时在线人数问题 如下为某直播平台主播开播及关播时间,根据该数据计算出平台最高峰同时在线的主播人数。 id stt edt 1001,2021-06-14 12:12:12,2021-06-14 18:1…...

RepOptimizer原理与代码解析(ICLR 2023)
paper:Re-parameterizing Your Optimizers rather than Architectures offcial implementation:https://github.com/dingxiaoh/repoptimizers 背景 神经网络的结构设计是将先验知识融入模型中。例如将特征转换建模成残差相加的形式(\(yf(x…...
)
持续总结中!2024年面试必问 20 道 Redis面试题(六)
上一篇地址:持续总结中!2024年面试必问 20 道 Redis面试题(五)-CSDN博客 十一、Redis集群的原理是什么? 集群是一种分布式系统架构,它由多个节点组成,这些节点共同工作以提供高可用性、扩展性…...
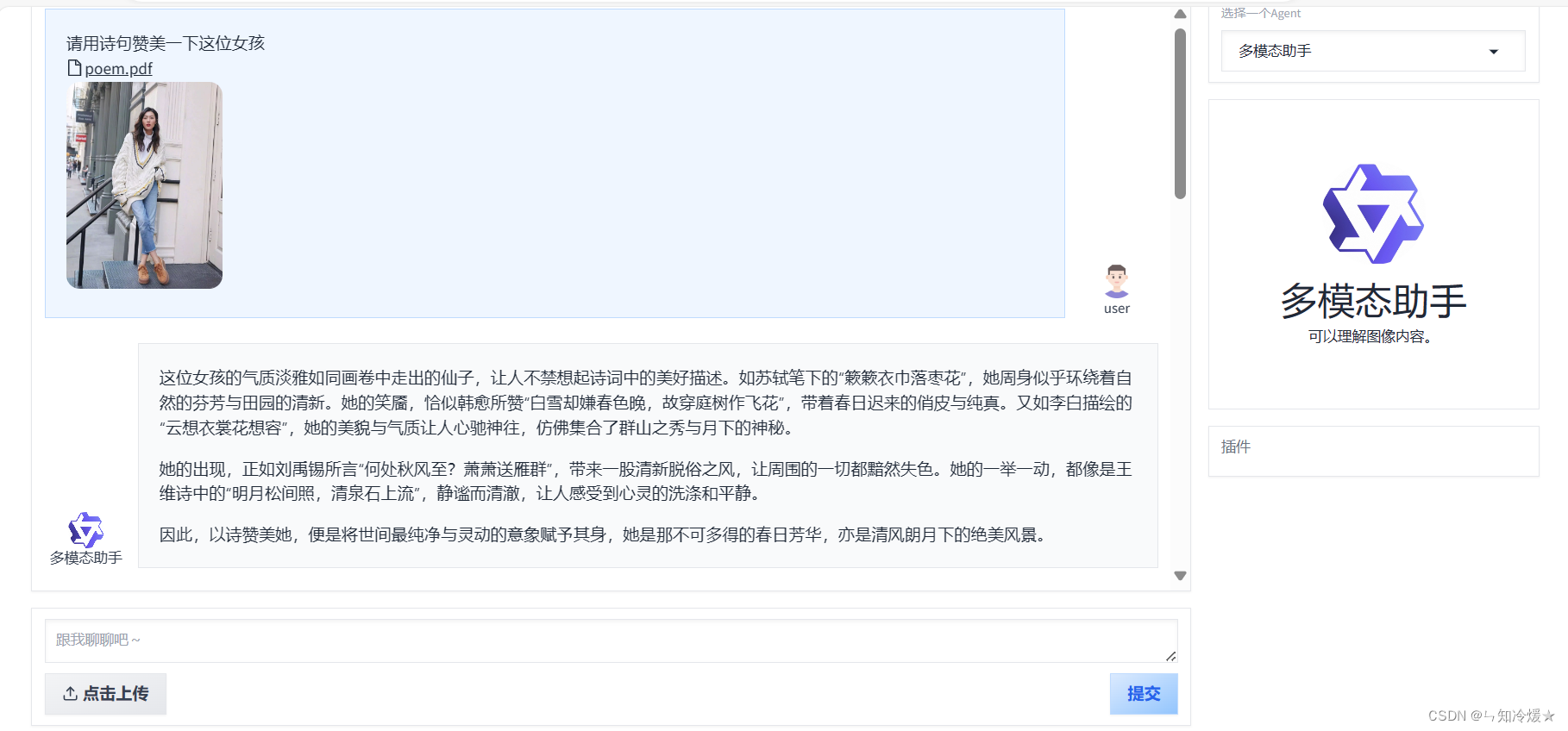
【通义千问—Qwen-Agent系列2】案例分析(图像理解图文生成Agent||多模态助手|| 基于ReAct范式的数据分析Agent)
目录 前言一、快速开始1-1、介绍1-2、安装1-3、开发你自己的Agent 二、基于Qwen-Agent的案例分析2-0、环境安装2-1、图像理解&文本生成Agent2-2、 基于ReAct范式的数据分析Agent2-3、 多模态助手 附录1、agent源码2、router源码 总结 前言 Qwen-Agent是一个开发框架。开发…...
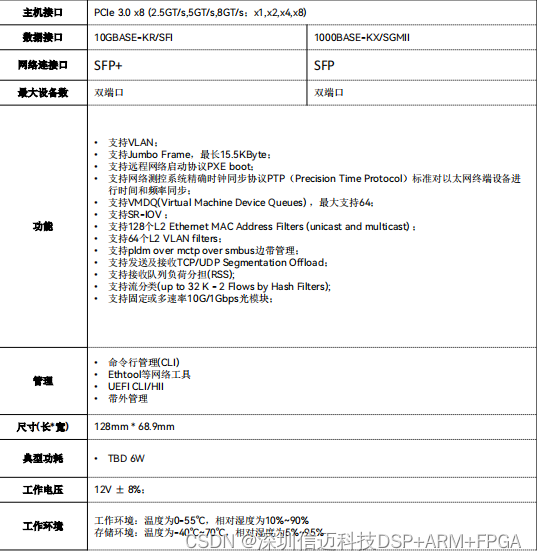
10G SFP双口万兆以太网控制器,高速光口网络接口卡
2-Port 10G SFP NIC 是一款高速网 络接口卡,采用了 PCI Express 3.0 x8 接口,支持双 端口万兆以太网,具有高性能、高可靠性、低功耗等 优点,是数据中心、云计算、虚拟化等领域的理想选 择。 支持多种网络协议,如 …...
)
[前端|vue] 验证器validator使用笔记 (笔记)
文档 validator.js文档地址 规则编写示例 element-plus 使用示例 const captchaLoginRules {phoneNumber: [{ required: true, message: 手机号不能为空, trigger: blur },{validator: (_rule: any, value: string, _callback: any): boolean > {return isMobilePhone(…...
欢乐钓鱼大师攻略大全,游戏自动辅助,钓鱼大全!
欢迎来到《欢乐钓鱼大师》的攻略大全!本文将为你详细介绍游戏中的各类玩法、技巧和注意事项,帮助你快速掌握游戏精髓,成为一名真正的钓鱼大师。攻略内容包括新手鱼竿选择、锦标赛攻略、实用技巧、藏宝图玩法、箱子开法等多个方面。让我们一起…...

Prompt - 流行的10个框架
转载自:https://juejin.cn/post/7287412759050289212 文章目录 1、ICIO框架2、CRISPE框架3、BROKE框架4、CREATE框架5、TAG框架6、RTF框架7、ROSES框架8、APE框架9、RACE框架10、TRACE框架 测试用例 为了看到不同的Prompt框架效果,本文定义一个统一的测…...

PYQT5点击Button执行多次问题解决方案(亲测)
PYQT5点击Button却执行多次问题 使用pyqt5时遇到问题,UI上按钮点击一次,对应的槽函数却执行了3遍 首先,确认函数名无冲突,UI button名无命名冲突,下图是简单的示例程序: 运行后,点击按钮&#…...

华为编程题目(实时更新)
1.大小端整数 计算机中对整型数据的表示有两种方式:大端序和小端序,大端序的高位字节在低地址,小端序的高位字节在高地址。例如:对数字 65538,其4字节表示的大端序内容为00 01 00 02,小端序内容为02 00 01…...

AI巨头争相与Reddit合作:为何一个古老的论坛成为AI训练的“宝藏”?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

保姆级教程:在RK3588开发板上用Python部署NanoTrack,实测120FPS真香
保姆级教程:在RK3588开发板上用Python部署NanoTrack,实测120FPS真香 RK3588作为当前嵌入式AI领域的旗舰级芯片,其强大的NPU算力让边缘设备也能流畅运行复杂的视觉算法。本文将手把手带你完成NanoTrack模型从转换到部署的全流程,实…...
稀疏记忆微调:在Transformer权重中编码任务专属结构化记忆
1. 这不是又一篇“加个正则就叫持续学习”的水文——我们来拆解这篇真正动了底层参数结构的稀疏记忆微调如果你最近刷过arxiv或者NeurIPS、ICLR的预印本列表,大概率见过标题里带“Continual Learning”“Sparse”“Memory”这几个词组合出现的论文。但说实话&#x…...
)
别再死记硬背了!用Unity可视化工具一步步拆解A*寻路算法(附完整C#源码)
用Unity可视化工具玩转A*寻路算法:从理论到实战的沉浸式学习 在游戏开发的世界里,路径规划算法就像是一位隐形的向导,决定着NPC如何绕过障碍物找到玩家,或是战略游戏中单位如何选择最优行军路线。A*算法作为其中最耀眼的明星&…...

Unity节点化效率工具:ComfyUI范式赋能中大型项目开发
1. 这不是又一个“UI美化插件”,而是Unity开发者每天要敲十次的底层效率杠杆Efficiency Nodes ComfyUI——光看名字,很多人第一反应是“ComfyUI?那不是Stable Diffusion的可视化工作流工具吗?怎么跑Unity里来了?”这恰…...

【论文阅读】GEN-1: Scaling Embodied Foundation Models to Mastery
快速了解部分 基础信息(英文): 1.题目: GEN-1: Scaling Embodied Foundation Models to Mastery 2.时间: 2026.04 3.机构: Generalist AI 4.3个英文关键词: GEN-1, Embodied Intelligence, VLA 1句话通俗总结本文干了什么事情 本文发布了新一…...

淘金币自动化脚本:每天节省20分钟,解放双手的终极指南
淘金币自动化脚本:每天节省20分钟,解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinb…...

UVa 255 Correct Move
题目分析 这是一道关于国际象棋棋盘上王和后移动规则的模拟问题。题目描述了一个 888 \times 888 的棋盘,格子编号从 000 到 636363,编号方式为逐行排列(第 000 行:0∼70 \sim 70∼7,第 111 行:8∼158 \sim…...

Java 程序员第 24 阶段:多 Agent 高阶实战,复杂业务场景完整落地实现
在多 Agent 基础篇中,我们探讨了角色协同、任务拆分的基本模式。本文进一步深入,聚焦高阶架构设计、跨服务协作与复杂场景完整落地,帮助读者构建生产级别的多 Agent 系统。一、高阶架构:从简单协同到生产级系统1.1 三层架构模型成…...

别再用 STVP 了!用 IAR 3.11.1 调试 STM8S003 点灯程序,效率翻倍
告别STVP:用IAR 3.11.1高效调试STM8S003点灯程序全指南 在嵌入式开发领域,工具链的选择往往决定了开发效率的上限。对于STM8系列开发,许多工程师仍在使用STVP这种基础的烧录工具,却不知已经错过了IAR Embedded Workbench带来的效…...

告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单
告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 还在为PPT演示超时而烦恼吗?每次演讲都像和时间赛跑,担心讲得太快或太…...