kafka配置消费者重要参数
文章目录
- fetch.min.bytes
- fetch.max.wait.ms
- fetch.max.bytes
- max.poll.records
- max.partition.fetch.bytes
- session.timeout.ms和heartbeat.interval.ms
- max.poll.interval.ms
- request.timeout.ms
- auto.offset.reset
- enable.auto.commit
- partition.assignment.strategy
- 区间(range)
- 轮询(roundRobin)
- 黏性(sticky)
- 协作黏性(cooperative sticky)
fetch.min.bytes
这个属性指定了消费者从服务器获取记录的最小字节数,默认是1字节。broker在收到消费者的获取数据请求时,如果可用数据量小于fetch.min.bytes指定的大小,那么它就会等到有足够可用数据时才将数据返回。这样可以降低消费者和broker的负载,因为它们在主题流量不是很大的时候(或者一天里的低流量时段)不需要来来回回地传输消息。如果消费者在没有太多可用数据时CPU使用率很高,或者在有很多消费者时为了降低broker的负载,那么可以把这个属性的值设置得比默认值大。但需要注意的是,在低吞吐量的情况下,加大这个值会增加延迟。
fetch.max.wait.ms
通过设置fetch.min.bytes,可以让Kafka等到有足够多的数据时才将它们返回给消费者,feth.max.wait.ms则用于指定broker等待的时间,默认是500毫秒。如果没有足够多的数据流入Kafka,那么消费者获取数据的请求就得不到满足,最多会导致500毫秒的延迟。如果要降低潜在的延迟(为了满足SLA),那么可以把这个属性的值设置得小一些。如果fetch.max.wait.ms被设置为100毫秒,fetch.min.bytes被设置为1 MB,那么Kafka在收到消费者的请求后,如果有1 MB数据,就将其返回,如果没有,就在100毫秒后返回,就看哪个条件先得到满足。
fetch.max.bytes
这个属性指定了Kafka返回的数据的最大字节数(默认为50 MB)。消费者会将服务器返回的数据放在内存中,所以这个属性被用于限制消费者用来存放数据的内存大小。需要注意的是,记录是分批发送给客户端的,如果broker要发送的批次超过了这个属性指定的大小,那么这个限制将被忽略。这样可以保证消费者能够继续处理消息。值得注意的是,broker端也有一个与之对应的配置属性,Kafka管理员可以用它来限制最大获取数量。broker端的这个配置属性可能很有用,因为请求的数据量越大,需要从磁盘读取的数据量就越大,通过网络发送数据的时间就越长,这可能会导致资源争用并增加broker的负载。
max.poll.records
这个属性用于控制单次调用poll()方法返回的记录条数。可以用它来控制应用程序在进行每一次轮询循环时需要处理的记录条数(不是记录的大小)。
max.partition.fetch.bytes
这个属性指定了服务器从每个分区里返回给消费者的最大字节数(默认值是1 MB)。当KafkaConsumer.poll()方法返回ConsumerRecords时,从每个分区里返回的记录最多不超过max.partition.fetch.bytes指定的字节。需要注意的是,使用这个属性来控制消费者的内存使用量会让事情变得复杂,因为你无法控制broker返回的响应里包含多少个分区的数据。因此,对于这种情况,建议用fetch.max.bytes替代,除非有特殊的需求,比如要求从每个分区读取差不多的数据量。
session.timeout.ms和heartbeat.interval.ms
session.timeout.ms指定了消费者可以在多长时间内不与服务器发生交互而仍然被认为还“活着”,默认是10秒。如果消费者没有在session.timeout.ms指定的时间内发送心跳给群组协调器,则会被认为已“死亡”,协调器就会触发再均衡,把分区分配给群组里的其他消费者。session.timeout.ms与heartbeat.interval.ms紧密相关。heartbeat.interval.ms指定了消费者向协调器发送心跳的频率,session.timeout.ms指定了消费者可以多久不发送心跳。因此,我们一般会同时设置这两个属性,heartbeat.interval.ms必须比session.timeout.ms小,通常前者是后者的1/3。如果session.timeout.ms是3秒,那么heartbeat.interval.ms就应该是1秒。把session.timeout.ms设置得比默认值小,可以更快地检测到崩溃,并从崩溃中恢复,但也会导致不必要的再均衡。把session.timeout.ms设置得比默认值大,可以减少意外的再均衡,但需要更长的时间才能检测到崩溃。
max.poll.interval.ms
这个属性指定了消费者在被认为已经“死亡”之前可以在多长时间内不发起轮询。前面提到过,心跳和会话超时是Kafka检测已“死亡”的消费者并撤销其分区的主要机制。我们也提到了心跳是通过后台线程发送的,而后台线程有可能在消费者主线程发生死锁的情况下继续发送心跳,但这个消费者并没有在读取分区里的数据。要想知道消费者是否还在处理消息,最简单的方法是检查它是否还在请求数据。但是,请求之间的时间间隔是很难预测的,它不仅取决于可用的数据量、消费者处理数据的方式,有时还取决于其他服务的延迟。在需要耗费时间来处理每个记录的应用程序中,可以通过max.poll.records来限制返回的数据量,从而限制应用程序在再次调用poll()之前的等待时长。但是,即使设置了max.poll.records,调用poll()的时间间隔仍然很难预测。于是,设置max.poll.interval.ms就成了一种保险措施。它必须被设置得足够大,让正常的消费者尽量不触及这个阈值,但又要足够小,避免有问题的消费者给应用程序造成严重影响。这个属性的默认值为5分钟。当这个阈值被触及时,后台线程将向broker发送一个“离开群组”的请求,让broker知道这个消费者已经“死亡”,必须进行群组再均衡,然后停止发送心跳。
request.timeout.ms
这个属性指定了消费者在收到broker响应之前可以等待的最长时间。如果broker在指定时间内没有做出响应,那么客户端就会关闭连接并尝试重连。它的默认值是30秒。不建议把它设置得比默认值小。在放弃请求之前要给broker留有足够长的时间来处理其他请求,因为向已经过载的broker发送请求几乎没有什么好处,况且断开并重连只会造成更大的开销。
auto.offset.reset
这个属性指定了消费者在读取一个没有偏移量或偏移量无效(因消费者长时间不在线,偏移量对应的记录已经过期并被删除)的分区时该做何处理。它的默认值是latest,意思是说,如果没有有效的偏移量,那么消费者将从最新的记录(在消费者启动之后写入Kafka的记录)开始读取。另一个值是earliest,意思是说,如果没有有效的偏移量,那么消费者将从起始位置开始读取记录。如果将auto.offset.reset设置为none,并试图用一个无效的偏移量来读取记录,则消费者将抛出异常。
enable.auto.commit
**这个属性指定了消费者是否自动提交偏移量,默认值是true。**你可以把它设置为false,选择自己控制何时提交偏移量,以尽量避免出现数据重复和丢失。如果它被设置为true,那么还有另外一个属性auto.commit.interval.ms可以用来控制偏移量的提交频率。本章后续部分将深入介绍与提交偏移量相关的其他内容。
partition.assignment.strategy
我们知道,分区会被分配给群组里的消费者。PartitionAssignor根据给定的消费者和它们订阅的主题来决定哪些分区应该被分配给哪个消费者。Kafka提供了几种默认的分配策略。
区间(range)
这个策略会把每一个主题的若干个连续分区分配给消费者。假设消费者C1和消费者C2同时订阅了主题T1和主题T2,并且每个主题有3个分区。那么消费者C1有可能会被分配到这两个主题的分区0和分区1,消费者C2则会被分配到这两个主题的分区2。因为每个主题拥有奇数个分区,并且都遵循一样的分配策略,所以第一个消费者会分配到比第二个消费者更多的分区。只要使用了这个策略,并且分区数量无法被消费者数量整除,就会出现这种情况。
轮询(roundRobin)
这个策略会把所有被订阅的主题的所有分区按顺序逐个分配给消费者。如果使用轮询策略为消费者C1和消费者C2分配分区,那么消费者C1将分配到主题T1的分区0和分区2以及主题T2的分区1,消费者C2将分配到主题T1的分区1以及主题T2的分区0和分区2。一般来说,如果所有消费者都订阅了相同的主题(这种情况很常见),那么轮询策略会给所有消费者都分配相同数量(或最多就差一个)的分区。
黏性(sticky)
设计黏性分区分配器的目的有两个:一是尽可能均衡地分配分区,二是在进行再均衡时尽可能多地保留原先的分区所有权关系,减少将分区从一个消费者转移给另一个消费者所带来的开销。如果所有消费者都订阅了相同的主题,那么黏性分配器初始的分配比例将与轮询分配器一样均衡。后续的重新分配将同样保持均衡,但减少了需要移动的分区的数量。如果同一个群组里的消费者订阅了不同的主题,那么黏性分配器的分配比例将比轮询分配器更加均衡。
协作黏性(cooperative sticky)
这个分配策略与黏性分配器一样,只是它支持协作(增量式)再均衡,在进行再均衡时消费者可以继续从没有被重新分配的分区读取消息。可以参考4.1.2节了解更多有关协作再均衡的内容。需要注意的是,如果你从Kafka 2.3之前的版本开始升级,并希望使用协作黏性分配策略,则需要遵循特定的升级路径,具体请参看相关升级指南。
可以通过partition.assignment.strategy来配置分区策略,默认值是org.apache.kafka.clients.consumer.RangeAssignor,它实现了区间策略。你也可以把它改成org.apache.kafka.clients.consumer.RoundRobinAssignor、org.apache.kafka.clients.consumer.StickyAssignor或org.apache.kafka.clients.consumer.CooperativeStickyAssignor。还可以使用自定义分配策略,如果是这样,则需要把partition.assignment.strategy设置成自定义类的名字。
相关文章:

kafka配置消费者重要参数
文章目录 fetch.min.bytesfetch.max.wait.msfetch.max.bytesmax.poll.recordsmax.partition.fetch.bytessession.timeout.ms和heartbeat.interval.msmax.poll.interval.msrequest.timeout.msauto.offset.resetenable.auto.commitpartition.assignment.strategy区间(range)轮询(…...

shell笔记脚本3
执行脚本文件demo2.sh, 观察打印VAR4效果 执行脚本文件后, 在交互式Shell环境打印VAR4, 观察打印VAR4效果 结论 全局变量在当前Shell环境与子Shell环境中可用, 父Shell环境中不可用 小结 自定义变量的分类 自定义局部变量: 就是在一个脚本文件内部使用 var_namevalue 自…...

Kafka消息丢失处理方式,消息丢失与消费失败区别和分别的处理
Kafka 消息丢失的处理方式可以从生产者、Broker 和消费者三个角度来考虑,以确保消息的可靠传递。以下是一些关键的处理措施: Kafka消息丢失处理方式 1. 生产者端的处理方式: 使用生产者确认(acks配置):通…...
AI爆文写作:标题需要什么?情绪炸裂,态度要激烈,行为要夸张!
现在这个传播环境下,在公域中,轻声细语,慢慢的说,无法吸引到注意,没有人搭理。 标题要需要情绪张扬,态度激烈,行为夸张,大声喧闹。 唐韧的用户群是互联网产品经理,阅读量…...
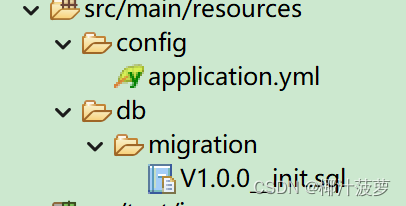
Flyway SpringBoot中使用
Flyway 一、 介绍 通过版本化数据库,提高数据库迁移的可靠性。即启动项目时就按版本执行sql脚本,实现数据库自动迁移。 Flyway是一款开源的数据库版本管理工具,它能够实现数据库迁移和版本控制。Flyway通过SQL脚本或Java代码进行数据库变更…...

全志A133 Android10 lcd配置显示硬件参数说明
一,概述 全志平台,通过board.dts来配置一些通用的 LCD 配置参数。 内核板级配置: longan/device/config/chips/a133/configs/b6/board.dts二,硬件参数说明 1. lcd接口参数说明 lcd_driver_name Lcd 屏驱动的名字(字…...

景源畅信:小白做抖音运营难吗?
在数字化时代,社交媒体已成为人们生活的一部分,而抖音作为其中的翘楚,吸引了众多希望通过平台实现自我价值和商业目标的用户。对于刚入门的小白来说,运营抖音账号可能会遇到不少挑战。接下来,我们将详细探讨这一话题&a…...

初探 Spring Boot Starter Security:构建更安全的Spring Boot应用
引言 Spring Boot 作为 Java 生态系统下的热门框架,以其简洁和易上手著称。而在构建 Web 应用程序时,安全性始终是开发者必须重视的一个方面。Spring Boot Starter Security 为开发者提供了一个简单但功能强大的安全框架,使得实现身份验证和…...

【无标题】思科交换路由中路由引入实验指南
路由引入是网络设计中的一个重要概念,它允许不同路由协议之间的路由信息交换。在思科网络设备中,路由引入可以增强网络的连通性和效率。本文将介绍路由引入的基本概念,并通过一个实验来演示如何在思科路由器中实现路由引入。 ## 路由引入的基…...

基于yolov2深度学习网络的昆虫检测算法matlab仿真,并输出昆虫数量和大小判决
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022A 3.部分核心程序 .......................................................... for i 1:12 % 遍历结…...

Java进阶学习笔记2——static
static: 叫静态,可以修饰成员变量、成员方法。 成员变量按照有无static修饰,分为两种: 类变量:有static修饰,属于类,在计算机中只有一份,会被类的全部对象共享。静态成员变量。 实…...

spring boot集成Knife4j
文章目录 一、Knife4j是什么?二、使用步骤1.引入依赖2.新增相关的配置类3.添加配置信息4.新建测试类5. 启动项目 三、其他版本集成时常见异常1. Failed to start bean ‘documentationPluginsBootstrapper2.访问地址后报404 一、Knife4j是什么? 前言&…...
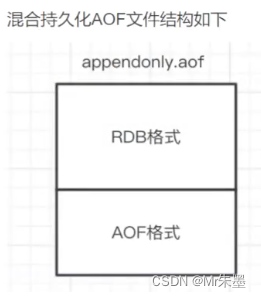
redis核心面试题一(架构原理+RDB+AOF)
文章目录 0. redis与mysql区别1. redis是单线程架构还是多线程架构2. redis单线程为什么这么快3. redis过期key删除策略4. redis主从复制架构原理5. redis哨兵模式架构原理6. redis高可用集群架构原理7. redis持久化之RDB8. redis持久化之AOF9. redis持久化之混合持久化 0. red…...

STM32F1之SPI通信·软件SPI代码编写
目录 1. 简介 2. 硬件电路 移位示意图 3. SPI时序基本单元 3.1 起始条件 3.2 终止条件 3.3 交换一个字节(模式0) 3.4 交换一个字节(模式1) 3.5 交换一个字节(模式2) 3.6 交换一个字节&a…...
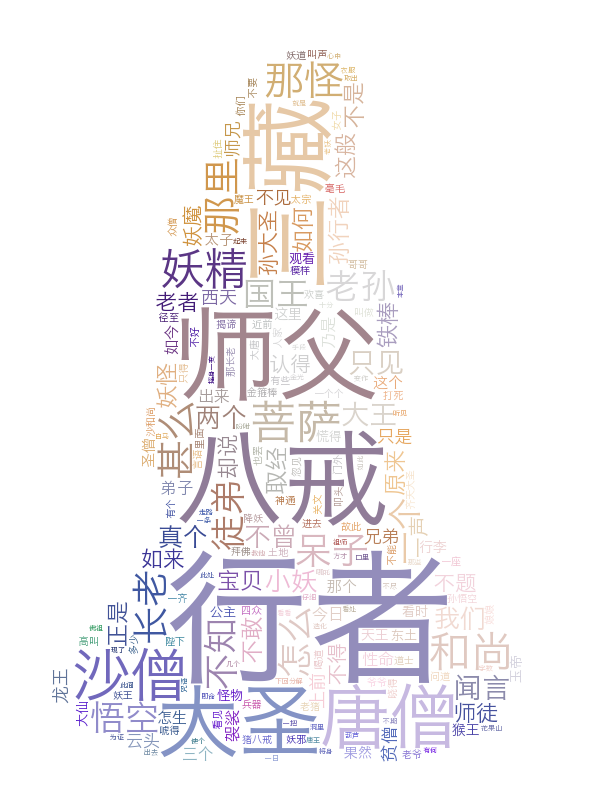
实战:生成个性化词云的Python实践【7个案例】
文本挖掘与可视化:生成个性化词云的Python实践【7个案例】 词云(Word Cloud),又称为文字云或标签云,是一种用于文本数据可视化的技术,通过不同大小、颜色和字体展示文本中单词的出现频率或重要性。在词云中…...

云存储与云计算详解
1. 云存储与云计算概述 1.1 云存储 云存储(Cloud Storage)是指通过互联网将数据存储在远程服务器上,用户可以随时随地访问和管理这些数据。云存储的优点包括高可扩展性、灵活性和成本效益。 1.2 云计算 云计算(Cloud Computin…...

【飞舞的花瓣】飞舞的花瓣代码||樱花代码||表白代码(完整代码)
关注微信公众号「ClassmateJie」有完整代码以及更多惊喜等待你的发现。 简介/效果展示 这段代码是一个HTML页面,其中包含一个canvas元素和相关的JavaScript代码。这个页面创建了一个飘落花瓣的动画效果。 代码【获取完整代码关注微信公众号「ClassmateJie」回复“…...

网络安全的重要组成部分:数据库审计
数据库审计(简称DBAudit)以安全事件为中心,以全面审计和精确审计为基础,实时记录网络上的数据库活动,对数据库操作进行细粒度审计的合规性管理,对数据库遭受到的风险行为进行实时告警。它通过对用户访问数据…...

gc和gccgo编译器
Go 语言有两个主要的编译器,分别是 Go 编译器(通常简称为 gc)和 GCCGO。它们之间有一些重要的异同点: gc 编译器: gc 是 Go 语言的官方编译器,由 Go 语言的开发团队维护。它是 Go 语言最常用的编译器&#…...

开放重定向漏洞
开放重定向漏洞 1.开放重定向漏洞概述2.攻击场景:开放重定向上传 svg 文件3.常见的注入参数 1.开放重定向漏洞概述 开放重定向漏洞(Open Redirect)是指Web应用程序接受用户提供的输入(通常是URL参数),并将…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

告别RaiDrive广告!用开源rclone+Alist,免费把阿里云盘/百度网盘变成电脑本地硬盘
开源方案实战:用rcloneAlist打造无广告的云盘本地化体验 每次打开RaiDrive时弹出的广告窗口是否让您感到困扰?商业软件的收费模式是否让您犹豫不决?今天,我们将彻底解决这些问题。通过开源工具Alist和rclone的组合,您不…...
)
内存申请和使用的场景分析(以AP->kernal->ISP为例)
在 ISP(Image Signal Processor)系统中,AP 与 ISP 之间的内存交互本质上是一个**“AP 申请可 DMA 访问的共享内存 → 内核建立映射 → 硬件寻址读写 → 同步与回收”**的过程。下面按数据流分层详细拆解。一、ISP 内存需求的特殊性 与普通应用…...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...