python爬虫[简易版]
python爬数据[简易版]
对于每个网站的爬的原理基本是一样的,但是具体的代码写法的区别就在于爬的数据中解析出想要的数据格式:
以爬取有道词典中的图片为例:
第一步:打开网站,分析图片的数据源来自哪里,
https://dict-subsidiary.youdao.com/home/content?invalid=&previewEnvTest=
发现我们要的数据原来自这里,
{"data": {.....略....."secondList": [{"name": "网易有道词典APP","picture": "https://ydlunacommon-cdn.nosdn.127.net/4e7ca43db1a83f11c467105181e9badb.png","desc": "智能学习更高效","buttonList": [{"text": "下载","type": 0,"url": "https://cidian.youdao.com/download-app/"}]},{"name": "有道词典笔","picture": "https://ydlunacommon-cdn.nosdn.127.net/c30638638a393dc38464600caf4888fb.jpg","desc": "更专业的词典笔","buttonList": [{"text": "查看详情","type": 0,"url": "https://smart.youdao.com/dictPenX6Pro"}]},......略....
}
接下来就是分析返回的数据,解析数据~拿出图片的url
response = requests.get(url, headers)
# response = request.urlopen(url).read()
# 处理数据json_load = json.loads(response.text)
# json_load = json.loads(response)
dt = json_load['data']
dumps = json.dumps(dt)
loads = json.loads(dumps)
listS = loads["secondList"]
arr = []
for i in listS:json_dumps = json.dumps(i)json_loads = json.loads(json_dumps)arr.append(json_loads["picture"])
爬取数据:
i = 0
for item in arr:requests_get=request.urlopen(item).read()png = "d:/PythonData/pic/" + str(i) + ".png"with open(png, "wb") as f:f.write(requests_get)i = i + 1
完整的代码:
from urllib import request
import re
import requests
import json
"""爬取有道词典的图片
"""
url = "https://dict-subsidiary.youdao.com/home/content?invalid=&previewEnvTest="
headers = {# User-Agent 用户代理 浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 ''Safari/537.36'
}
response = requests.get(url, headers)
# response = request.urlopen(url).read()
# 处理数据
json_load = json.loads(response.text)
# json_load = json.loads(response)
dt = json_load['data']
dumps = json.dumps(dt)
loads = json.loads(dumps)
listS = loads["secondList"]
arr = []
for i in listS:json_dumps = json.dumps(i)json_loads = json.loads(json_dumps)arr.append(json_loads["picture"])
i = 0
for item in arr:requests_get=request.urlopen(item).read()png = "d:/PythonData/pic/" + str(i) + ".png"with open(png, "wb") as f:f.write(requests_get)i = i + 1example:
"""
# 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests
# 导入正则模块 --> 内置模块, 不需要安装
"""
import requests
import re"""
1.
发送请求, 模拟浏览器对于url地址发送请求
- 模拟浏览器 < 反爬处理 > 请求头 < 字典数据类型 >
如果你不伪装, 可能会被识别出来是爬虫程序, 从而得到数据内容
可以直接复制粘贴 --> 开发者工具里面就可以复制- < Response[200] > 响应对象
Response: 中文意思 -->响应
<>: 表示对象
200: 状态码
表示请求成功
发送请求, 请求成功了分析请求url地址变化规律:
第一页: http: // www.netbian.com / dongman /
第二页: http: // www.netbian.com / dongman / index_2.htm
第三页: http: // www.netbian.com / dongman / index_3.htm
第四页: http: // www.netbian.com / dongman / index_4.htm"""
for page in range(2, 11):print(f'=================正在采集第{page}页的数据内容=================')# 请求图片目录页面urlurl = f'http://www.netbian.com/dongman/index_{page}.htm'# 伪装模拟成浏览器headers = {# User-Agent 用户代理 浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}# 发送请求# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名response接受返回的数据response = requests.get(url=url, headers=headers)"""
2.
获取数据, 获取服务器返回响应数据
response
网页源代码
response.text
获取响应文本数据 < 网页源代码 >
3.
解析数据, 提取我们想要的数据内容
- 图片ID
正则表达式Re
会1
不会0
调用re模块里面findall方法 --> 找到所有我们想要的数据
re.findall('找什么数据', '从哪里找') --> 从什么地方, 去匹配找什么样的数据内容
从
response.text < 网页源代码 > 里面
去找 < a
href = "/desk/(\d+).htm"
其中(\d +) 就是我们要的内容
\d + 表示任意数字
"""
# 提取图片ID --> 列表 <盒子/箱子> '29381' 是列表<箱子>里面元素<苹果>
img_id_list = re.findall('<a href="/desk/(\d+).htm"', response.text)
# for循环遍历, 把列表里面元素 一个一个提取出来
for img_id in img_id_list:# img_id变量<袋子> 给 img_id_list 列表<盒子> 里面 元素<苹果> 给装起来print(img_id)"""
4.
发送请求, 模拟浏览器对于url地址发送请求
- 请求
图片详情页页面url
http: // www.netbian.com / desk / {图片ID}.htm
5.
获取数据, 获取服务器返回响应数据
response
网页源代码
"""# 请求详情页链接 --> f'{img_id}' 字符串格式化方法link = f'http://www.netbian.com/desk/{img_id}.htm'# 发送请求response_1 = requests.get(url=link, headers=headers)# 获取数据内容 网页源代码 ---> 乱码了, 进行转码response_1.encoding = 'gbk'# 6. 解析数据, 提取我们想要的数据内容<图片链接/图片标题>img_url, img_title = re.findall('<img src="(.*?)" alt="(.*?)"', response_1.text)[0]# 7. 保存数据 --> 先获取图片数据内容img_content = requests.get(url=img_url, headers=headers).contentwith open('img\\' + img_title + '.jpg', mode='wb') as f:f.write(img_content)print(img_url, img_title)python中的拷贝
import copy
from typing import override"""对于简单的 object,用 shallow copy 和 deep copy 没区别"""
"""构造一个类,然后构造一个实例,然后拷贝这个实例,就会发现,浅拷贝和深拷贝效果一样"""
"""如果是拷贝的list,深拷贝会拷贝list里面的内容,浅拷贝不会拷贝list里面的内容,而是拷贝list的地址""""""浅拷贝"""class Dog(object):def __init__(self, name):self.name = name"""如果要求名一样就是一个,那么需要重写下面的方法## def __eq__(self, other):# return self.name == other.name## def __gt__(self, other):# return self.name > other.name"""a = Dog("a")copy_obj_dog = copy.copy(a)deep_copy_obj_dog = copy.deepcopy(a)print(copy_obj_dog) # <__main__.Dog object at 0x000002A0BFA56210>
print(deep_copy_obj_dog) # <__main__.Dog object at 0x000002A0BFA56ED0>
print(copy_obj_dog == deep_copy_obj_dog) # FALSE# 修改其中的一个,修改深拷贝的对象不影响源对象
deep_copy_obj_dog.name = "b"
print(copy_obj_dog.name) # a
print(deep_copy_obj_dog.name) # b
print(a.name) # a
"""深拷贝"""class Cat:def __init__(self, name):self.name = namec = Cat("c")
copy_obj_cat = copy.copy(c)
deep_copy_obj_cat = copy.deepcopy(c)copy_obj_cat.name = "d"
print(copy_obj_cat.name) # d
print(deep_copy_obj_cat.name) # c
print(c.name) # c# 可以看到浅拷贝跟深拷贝对于简单的obj对象,效果是一样的,都是拷贝到一个新对象中cat = Cat("list")
arr = [cat]
# 浅拷贝list~复杂对象 此时浅拷贝考的是地址
copy_arr = copy.copy(arr)
print(copy_arr == arr) # Trueprint(arr[0])
print(copy_arr[0])# 修改list中的一个,修改浅拷贝的对象会影响源对象
copy_arr[0].name = "修改了"
print(arr[0].name)# 深拷贝~list 修改不会影响源对象
cat2 = Cat("list2")
arr2 = [cat2]deepcopy_arr2 = copy.deepcopy(arr2)
print(deepcopy_arr2 == arr2)print(arr2[0])
print(deepcopy_arr2[0])deepcopy_arr2[0].name = "change"
print(arr2[0].name)"""浅拷贝list中填充的是地址"""
"""深拷贝list中填充的是原始对象的副本"""class CustomCopy():"""自定义复制行为"""def __init__(self, name):self.name = namedef __copy__(self):print("copy")return CustomCopy(self.name)def __deepcopy__(self, memo):print("deepcopy")return CustomCopy(copy.deepcopy(self.name, memo))a = copy.copy(CustomCopy("a"))
ab = copy.deepcopy(CustomCopy("a"))
print(a == ab)相关文章:

python爬虫[简易版]
python爬数据[简易版] 对于每个网站的爬的原理基本是一样的,但是具体的代码写法的区别就在于爬的数据中解析出想要的数据格式: 以爬取有道词典中的图片为例: 第一步:打开网站,分析图片的数据源来自哪里, https://dict-subsidiary.youdao.com/home/content?invalid&pre…...

128天的创意之旅:从初心到成就,我的博客创作纪念日回顾
文章目录 🚀机缘:初心的种子——回望创作之旅的启航🌈收获:成长的果实——128天创作之旅的宝贵馈赠❤️日常:创作与生活的交织👊成就:代码的艺术🚲憧憬:未来的蓝图 &…...
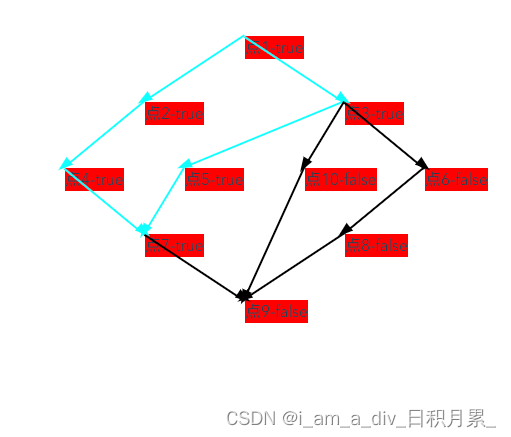
前端绘制流程节点数据
根据数据结构和节点的层级、子节点id,前端自己绘制节点位置和关联关系、指向、已完成节点等 <template><div><div>通过后端节点和层级,绘制出节点以及关联关系等</div><div class"container" ref"container&…...

2024年顶级算法-黑翅鸢优化算法(BKA)-详细原理(附matlab代码)
黑翅鸢是一种上半身蓝灰色,下半身白色的小型鸟类。它们的显著特征包括迁徙和捕食行为。它们以小型哺乳动物、爬行动物、鸟类和昆虫为食,具有很强的悬停能力,能够取得非凡的狩猎成功。受其狩猎技能和迁徙习惯的启发,该算法作者建立…...

Linux 内核开发 28 内核模块文件ko文件介绍
Linux 内核开发 28 内核模块文件ko文件介绍 1. ELF格式简介 内核模块文件ko文件,格式为elf格式, ELF(Executable and Linkable Format)可执行链接格式,是一种用于存储可执行程序、目标代码、共享库和内核模块的标准文件…...
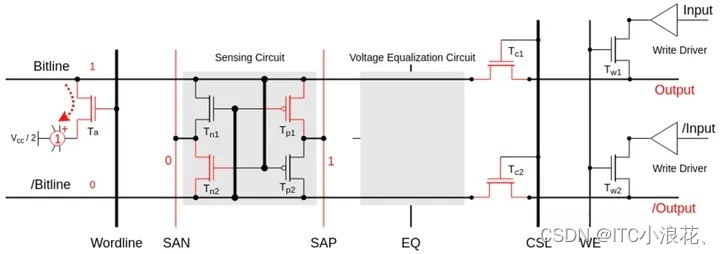
DDR5—新手入门学习(一)【1-5】
目录 1、DDR背景 (1)SDR SDRAM时代 : (2)DDR SDRAM的创新 : (3)DDR技术的演进 : (4)需求推动: 2、了解内存 (1&…...
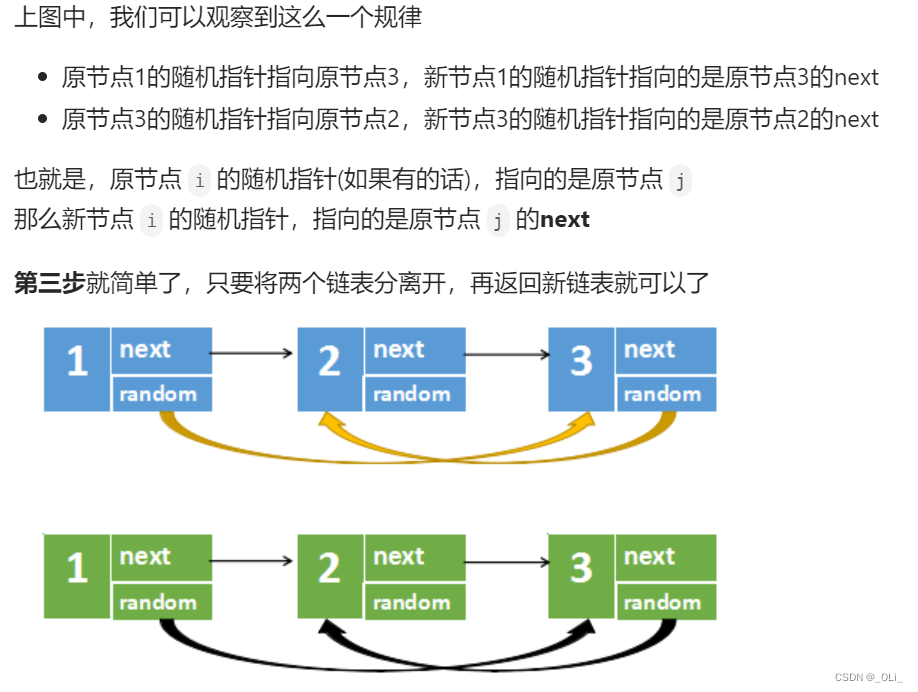
力扣HOT100 - 138. 随机链表的复制
解题思路: class Solution {public Node copyRandomList(Node head) {if(headnull) return null;Node p head;//第一步,在每个原节点后面创建一个新节点//1->1->2->2->3->3while(p!null) {Node newNode new Node(p.val);newNode.next …...
)
深入分析 Android Activity (五)
深入分析 Android Activity (五) 1. Activity 的进程和线程模型 在 Android 中,Activity 默认在主线程(也称为 UI 线程)中运行。理解进程和线程模型对于开发响应迅速且无阻塞的应用程序至关重要。 1.1 主线程与 UI 操作 所有 UI 操作必须…...
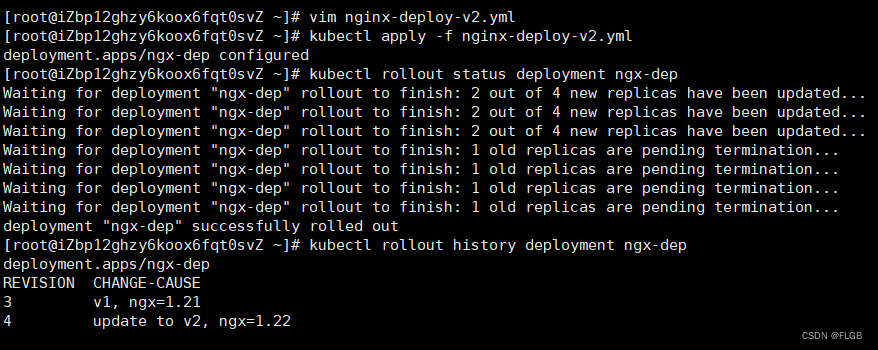
Kubernetes 应用滚动更新
Kubernetes 应用版本号 在 Kubernetes 里,版本更新使用的不是 API 对象,而是两个命令:kubectl apply 和 kubectl rollout,当然它们也要搭配部署应用所需要的 Deployment、DaemonSet 等 YAML 文件。 在 Kubernetes 里应用都是以 …...
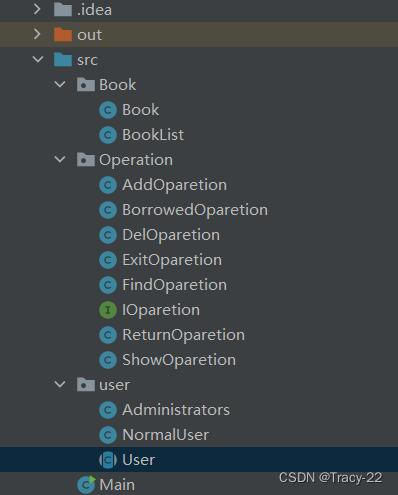
五分钟”手撕“图书管理系统
前言: 图书馆管理系统需要结合JavaSE的绝大部分知识,是一个很好的训练项目。 为了让大家更加方便的查阅与学习,我把代码放开头,供大家查询。 还有对代码的分析,我将以类为单位分开讲解。 目录 全部代码 Main类 Us…...
8个实用网站和软件,收藏起来一定不后悔~
整理了8个日常生活中经常能用得到的网站和软件,收藏起来一定不会后悔~ 1.ZLibrary zh.zlibrary-be.se/这个网站收录了超千万的书籍和文章资源,国内外的各种电子书资源都可以在这里搜索,98%以上都可以在网站内找到,并且支持免费下…...
电商内卷时代,视频号小店凭借一己之力“脱颖而出”
大家好,我是电商笨笨熊 今年618各大电商平台花样百出; 某宝更是直接取消了“预售”,从5月就开始进入618预热期; 不少玩家既开心又难过,市场如此内卷,618确实是个爆发期,但更多的需要不断压低…...
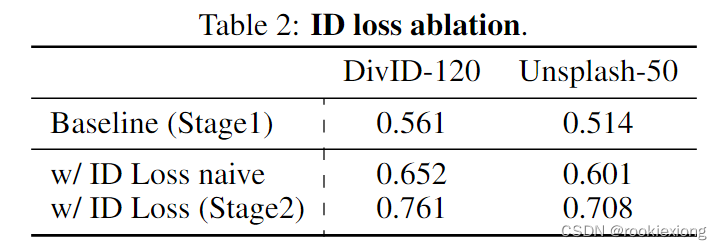
【论文笔记】| 定制化生成PuLID
PuLID: Pure and Lightning ID Customization via Contrastive Alignment ByteDance, arXiv:2404.16022v1 Theme: Customized generation 原文链接:https://arxiv.org/pdf/2404.16022 Main Work 提出了 Pure 和 Lightning ID 定制 (PuLID),这是一种用于…...

P1638 逛画展
题目描述 博览馆正在展出由世上最佳的 𝑚 位画家所画的图画。 游客在购买门票时必须说明两个数字,𝑎 和 𝑏,代表他要看展览中的第 𝑎 幅至第 𝑏 幅画(包含 𝑎,…...
常用命令)
Linux(centos)常用命令
Linux(Centos)常用命令使用说明文档 切换到/home目录下 使用cd命令切换目录,例如: cd /home列出/home目录下的所有文件 使用ls命令列出目录下的文件和子目录,例如: ls /home新建目录dir1 使用mkdir命…...

从入门到精通:掌握Scrapy框架的关键技巧
在当今信息爆炸的时代,获取并利用网络数据成为了许多行业的核心竞争力之一。而作为一名数据分析师、网络研究者或者是信息工作者,要想获取网络上的大量数据,离不开网络爬虫工具的帮助。而Scrapy框架作为Python语言中最为强大的网络爬虫框架之…...

Vue3按顺序调用新增和查询接口
Vue3按顺序调用新增和查询接口 一、前言1、代码 一、前言 如果你想将两个调用接口的操作封装在不同的方法中,你可以考虑将这两个方法分别定义为异步函数,并在需要时依次调用它们。以下是一个示例代码: 1、代码 <template><div>…...

sizeof的了解
32位编译器 qDebug() << "int:" << sizeof(int);qDebug() << "char:" << sizeof(char);qDebug() << "char*:" << sizeof(char*); 字节数: int: 4 char: 1 char*: 4 64位编译器 字节数&#…...

PostgreSQL 教程
## PostgreSQL 教程 ### 1. PostgreSQL 概述 PostgreSQL 是一个开源的对象关系型数据库管理系统(ORDBMS),以其高扩展性和合规性闻名,支持 SQL 和 JSON 查询。 ### 2. 安装与配置 - **下载与安装**:从 PostgreSQL 官方…...

《基于Jmeter的性能测试框架搭建》改进一
《基于Jmeter的性能测试框架搭建》文末笔者提到了不少待改进之处,如下所示。 Grafana性能图表实时展现,测试过程中需实时截图形成测试报告,不够人性化。解决方案:自动生成测试报告并邮件通知。 Grafana性能图表需测试人员实时监控…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...