Hadoop+Spark大数据技术 实验8 Spark SQL结构化
9.2 创建DataFrame对象的方式
val dfUsers = spark.read.load("/usr/local/spark/examples/src/main/resources/users.parquet")
dfUsers: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
dfUsers.show()
+------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| NULL| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+
9.2.2 json文件创建DataFrame对象
val dfGrade = spark.read.format("json").load("file:/media/sf_download/grade.json")
dfGrade: org.apache.spark.sql.DataFrame = [Class: string, ID: string ... 3 more fields]
dfGrade.show(3)
+-----+---+----+-----+-----+ |Class| ID|Name|Scala|Spark| +-----+---+----+-----+-----+ | 1|106|Ding| 92| 91| | 2|242| Yan| 96| 90| | 1|107|Feng| 84| 91| +-----+---+----+-----+-----+ only showing top 3 rows
9.2.3 RDD创建DataFrame对象
val list = List(
("zhangsan" , "19") , ("B" , "29") , ("C" , "9")
)
val df = sc.parallelize(list).toDF("name","age")
list: List[(String, String)] = List((zhangsan,19), (B,29), (C,9)) df: org.apache.spark.sql.DataFrame = [name: string, age: string]
df.printSchema()
root|-- name: string (nullable = true)|-- age: string (nullable = true)
df.show()
+--------+---+ | name|age| +--------+---+ |zhangsan| 19| | B| 29| | C| 9| +--------+---+
9.2.4 SparkSession创建DataFrame对象
// 1.json创建Datarame对象
val dfGrade = spark.read.format("json").load("file:/media/sf_download/grade.json")
dfGrade.show(3)
+-----+---+----+-----+-----+ |Class| ID|Name|Scala|Spark| +-----+---+----+-----+-----+ | 1|106|Ding| 92| 91| | 2|242| Yan| 96| 90| | 1|107|Feng| 84| 91| +-----+---+----+-----+-----+ only showing top 3 rows
dfGrade: org.apache.spark.sql.DataFrame = [Class: string, ID: string ... 3 more fields]
Selection deleted
// 2.csv创建Datarame对象
val dfGrade2 = spark.read.option("header",true).csv("file:/media/sf_download/grade.json")
dfGrade2: org.apache.spark.sql.DataFrame = [{"ID":"106": string, "Name":"Ding": string ... 3 more fields]
dfGrade2.show(3)
+-----------+-------------+-----------+----------+-----------+
|{"ID":"106"|"Name":"Ding"|"Class":"1"|"Scala":92|"Spark":91}|
+-----------+-------------+-----------+----------+-----------+
|{"ID":"242"| "Name":"Yan"|"Class":"2"|"Scala":96|"Spark":90}|
|{"ID":"107"|"Name":"Feng"|"Class":"1"|"Scala":84|"Spark":91}|
|{"ID":"230"|"Name":"Wang"|"Class":"2"|"Scala":87|"Spark":91}|
+-----------+-------------+-----------+----------+-----------+
only showing top 3 rows
Selection deleted
// 3.Parquet创建Datarame对象
val dfGrade3 = spark.read.parquet("file:/usr/local/spark/examples/src/main/resources/users.parquet")
dfGrade3: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
dfGrade3.show(3)
+------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| NULL| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+
9.2.5 Seq创建DataFrame对象
val dfGrade4 = spark.createDataFrame(
Seq(
("A" , 20 ,98),
("B" , 19 ,93),
("C" , 21 ,92),
)
)toDF("Name" , "Age" , "Score")
dfGrade4: org.apache.spark.sql.DataFrame = [Name: string, Age: int ... 1 more field]
dfGrade4.show()
+----+---+-----+ |Name|Age|Score| +----+---+-----+ | A| 20| 98| | B| 19| 93| | C| 21| 92| +----+---+-----+
9.3 DataFrame对象保存为不同格式
9.3.1 write.()保存DataFrame对象
DataFrame.write() 提供了一种方便的方式将 DataFrame 保存为各种格式。以下是几种常见格式的保存方法:
1. 保存为JSON格式
df.write.json("path/to/file.json")
2. 保存为Parquet文件
df.write.parquet("path/to/file.parquet")
3. 保存为CSV文件
df.write.csv("path/to/file.csv")
9.3.2 write.format()保存DataFrame对象
DataFrame.write.format() 提供了一种更灵活的方式来保存 DataFrame,可以通过指定格式名称来选择输出格式。以下是几种常见格式的保存方法:
1. 保存为JSON格式
df.write.format("json").save("path/to/file.json")
2. 保存为Parquet文件
df.write.format("parquet").save("path/to/file.parquet")
3. 保存为CSV文件
df.write.format("csv").save("path/to/file.csv")
9.3.3 先将DataFrame对象转化为RDD再保存文件
虽然可以直接使用 DataFrame 的 write 方法保存文件,但有时需要先将 DataFrame 转换为 RDD 再进行保存。这可能是因为需要对数据进行一些 RDD 特定的操作,或者需要使用 RDD 的保存方法。
rdd = df.rdd.map(lambda row: ",".join(str(x) for x in row))
rdd.saveAsTextFile("path/to/file.txt")
注意:
- 上述代码将 DataFrame 的每一行转换为逗号分隔的字符串,并将结果保存为文本文件。
- 可以根据需要修改代码以使用不同的分隔符或保存为其他格式。
9.4 DataFrame对象常用操作
9.4.1 展示数据
1. show()
// 显示前20行数据
gradedf.show()
// 显示前10行数据
gradedf.show(10)
// 不截断列宽显示数据
gradedf.show(truncate=False)
2. collect()
// 将 DataFrame 转换成 Dataset 或 RDD,返回 Array 对象
gradedf.collect()
3. collectAsList()
// 将 DataFrame 转换成 Dataset 或 RDD,返回 Java List 对象
gradedf.collectAsList()
4. printSchema()
// 打印 DataFrame 的模式(schema)
gradedf.printSchema()
5. count()
// 统计 DataFrame 中的行数
gradedf.count()
6. first()、head()、take()、takeAsList()
// 返回第一行数据
gradedf.first()
// 返回前3行数据
gradedf.head(3)
// 返回前5行数据
gradedf.take(5)
// 返回前5行数据,以 Java List 形式
gradedf.takeAsList(5)
7. distinct()
// 返回 DataFrame 中唯一的行数据
gradedf.distinct.show()
8. dropDuplicates()
// 删除 DataFrame 中重复的行数据
gradedf.dropDuplicates(Seq("Spark")).show()
9.4.2 筛选
1. where()
- 根据条件过滤 DataFrame 中的行数据。
- 示例: gradedf.where("Class = '1' and Spark = '91'").show()
2. filter()
- 与 where() 功能相同,根据条件过滤 DataFrame 中的行数据。
- 示例: gradedf.filter("Class = '1'").show()
3. select()
- 选择 DataFrame 中的指定列。
- 示例: gradedf.select("Name", "Class","Scala").show(3,false)
修改名称:gradedf.select(gradedf("Name").as("name")).show()
4. selectExpr()
- 允许使用 SQL 表达式选择列。
- 示例: gradedf.selectExpr("name", "name as names" ,"upper(Name)","Scala * 10").show(3)
5. col()
- 获取 DataFrame 中指定列的引用。
- 示例: gradedf.col("name")
6. apply()
- 对 DataFrame 中的每一行应用函数。
- 示例: def get_grade_level(grade): return "A" if grade > 90 else "B"
gradedf.select("name", "grade", "grade_level").apply(get_grade_level, "grade_level")
7. drop()
- 从 DataFrame 中删除指定的列。
- 示例: gradedf.drop("grade")
8. limit()
- 限制返回的行数。
- 示例: gradedf.limit(10)
9.4.3 排序
按ID排序
1. orderBy()、sort()
orderBy() 和 sort() 方法都可以用于对 DataFrame 进行排序,它们的功能相同。
// 按id升序排序
gradedf.orderBy("id").show()
gradedf.sort(gradedf("Class").desc,gradedf("Scala").asc).show(3)
// 按id降序排序
gradedf.orderBy(desc("id")).show()
gradedf.sort(desc("id")).show()
2. sortWithinPartitions()
示例:gradedf.sortWithinPartitions("id").show(5)
引申:sortWithinPartitions() 方法用于对 DataFrame 的每个分区内进行排序。
// 首先对 DataFrame 进行重新分区,使其包含两个分区
val partitionedDF = gradedf.repartition(2)
// 对每个分区内的 id 进行升序排序
partitionedDF.sortWithinPartitions("id").show()
需要注意的是,sortWithinPartitions() 方法不会改变 DataFrame 的分区数量,它只是对每个分区内部进行排序。
9.4.4 汇总与聚合
1. groupBy()
groupBy() 方法用于根据指定的列对 DataFrame 进行分组。
(1) 结合 count()
// 统计每个名字的学生人数
gradedf.groupBy("name").count().show()
(2) 结合 max()
// 找出每个课程学生的最高成绩
gradedf.groupBy("Class").max("Scala","Spark").show()(3) 结合 min()
// 找出每个名字学生的最低成绩
gradedf.groupBy("name").min("grade").show()
(4) 结合 sum()
// 计算每个名字学生的总成绩
gradedf.groupBy("name").sum("grade").show()gradedf.groupBy("Class").sum("Scala","Spark").show()
(5) 结合 mean()
// 计算课程的平均成绩gradedf.groupBy("Class").sum("Scala","Spark").show()2. agg()
agg() 方法允许对 DataFrame 应用多个聚合函数。
(1) 结合 countDistinct()
// 统计不重复的名字数量
gradedf.agg(countDistinct("name")).show()
(2) 结合 avg()
gradedf.agg(max("Spark"), avg("Scala")).show()
// 计算所有学生的平均成绩
gradedf.agg(avg("grade")).show()
(3) 结合 count()
// 统计学生总数
gradedf.agg(count("*")).show()
(4) 结合 first()
// 获取第一个学生的姓名
gradedf.agg(first("name")).show()
(5) 结合 last()
// 获取最后一个学生的姓名
gradedf.agg(last("name")).show()
(6) 结合 max()、min()
// 获取最高和最低成绩
gradedf.agg(max("grade"), min("grade")).show()
(7) 结合 mean()
// 计算所有学生的平均成绩
gradedf.agg(mean("grade")).show()
(8) 结合 sum()
// 计算所有学生的总成绩
gradedf.agg(sum("grade")).show()
(9) 结合 var_pop()、variance()
// 计算成绩的总体方差
gradedf.agg(var_pop("grade"), variance("grade")).show()
(10) 结合 covar_pop()
// 计算 id 和 grade 之间的总体协方差
gradedf.agg(covar_pop("id", "grade")).show()
(11) 结合 corr()
gradedf.agg(corr("Spark","Scala")).show()9.4.5 统计
相关文章:
Hadoop+Spark大数据技术 实验8 Spark SQL结构化
9.2 创建DataFrame对象的方式 val dfUsers spark.read.load("/usr/local/spark/examples/src/main/resources/users.parquet") dfUsers: org.apache.spark.sql.DataFrame [name: string, favorite_color: string ... 1 more field] dfUsers.show() -----------…...

认知V2X的技术列一个学习大纲
为了深入学习和理解V2X(Vehicle to Everything)技术,以下是一个学习大纲的概述,结合了参考文章中的相关数字和信息: 一、V2X技术基础 V2X概述 定义:V2X是车用无线通信技术,将车辆与一切事物相连…...

揭秘齿轮加工工艺的选用原则:精准打造高效传动的秘密武器
在机械制造领域,齿轮作为传动系统中的重要组成部分,其加工工艺的选择至关重要。不同的齿轮加工工艺会影响齿轮的精度、耐用性和效率。本文将通过递进式结构,深入探讨齿轮加工工艺的选用原则,带您了解如何精准打造高效传动的秘密武…...
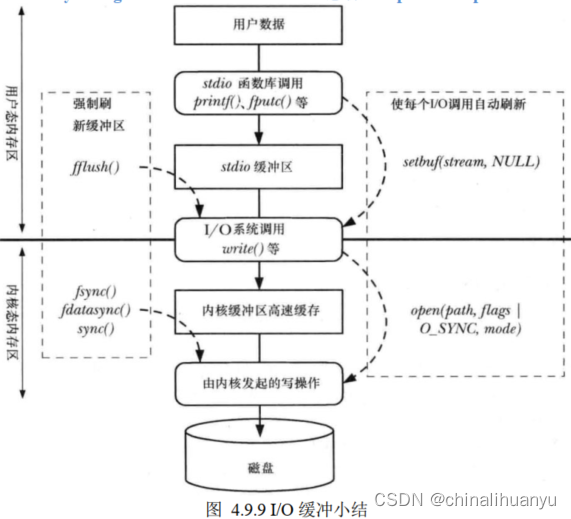
Linux-应用编程学习笔记(二、文件I/O、标准I/O)
一、文件I/O基础 文件 I/O 指的是对文件的输入/输出操作,就是对文件的读写操作。Linux 下一切皆文件。 1.1 文件描述符 在 open函数执行成功的情况下, 会返回一个非负整数, 该返回值就是一个文件描述符(file descriptor&#x…...

AI爆文写作:根据别人的爆款标题,如何通过名词替换改成自己的爆款标题?
在日常刷到爆文的时候,就可以培养自己的网感,为啥这篇文章会爆? 这篇爆文的标题有啥诀窍呢? 比如下面这一篇:《极简生活:变富就是每天循环5个动作》 我们可以发现,每天循环5个动作 这几个词语…...

Mybatis源码剖析---第二讲
Mybatis源码剖析—第二讲 那我们在讲完了mappedstatement这个类,它的一个核心作用之后呢?那下面我有一个问题想问问各位。作为mappedstatement来讲,它封装的是一个select标签或者insert标签。但是呢,我们需要大家注意的是什么&am…...

SpringMvc-restful设计风格
Restful 1、入门1.1 简介1.2 实例 1、入门 1.1 简介 RESTFul是什么 RESTFul是WEB服务接口的一种设计风格。 RESTFul定义了一组约束条件和规范,可以让WEB服务接口更加简洁、易于理解、易于扩展、安全可靠。 1.2 实例 web.xml <?xml version"1.0"…...

在未来你将何去何从?
在数字化的浪潮中,信息技术行业无疑是推动全球经济和社会发展的重要动力。随着科技的不断迭代与进步,云计算、大数据、人工智能(AI)、物联网(IoT)、5G通信和区块链等技术已经深入到我们生活的每一个角落&am…...

Vue.js组件设计模式:构建可复用组件库
在Vue.js中,构建可复用的组件库是提高代码复用性和维护性的关键。下面是一些设计模式,说明如何创建可复用的Vue组件: 1. 单文件组件(Single File Component, SFC) Vue.js组件通常是单文件组件,包含HTML、…...
【C语言】指针运算
前言 前面在“走进指针世界”中我已经讲解过指针相关的很多前置知识,其实还有一个很重要的部分就是指针的运算。这篇博客,就让我们一起了解一下指针的运算吧! 指针作为变量,是可以进行算术运算的,只不过情况会和整型…...
 函数)
Python学习(3) 函数
定义 定义一个函数的格式: def 函数名(参数):执行代码如果没有参数,则称为无参函数。 定义时小括号中写的是形参(形式参数),调用时写的是实参(实际参数)。 调用 调用格式: def…...

计算机网络安全控制技术
1.防火墙技术 防火墙技术是近年来维护网络安全最重要的手段,但是防火墙不是万能的,需要配合其他安全措施来协同 2.加密技术 目前加密技术主要有两大类:对称加密和非对称加密 3.用户识别技术 核心是识别网络者是否是属于系统的合法用户 …...
WordPress插件Disable WP REST API,可根据是否登录来禁用REST API
前面跟大家分享了代码版禁用WordPress REST API的方法(详见『WordPress4.7以上版本如何禁用JSON REST API?』),不过有些站长不太敢折腾自己的网站代码,那么建议试试这款Disable WP REST API,它可以…...

腾讯云COS上传文件出现的问题
1、没有配置 ObjectMetadata 的文件长度 腾讯云COS上传文件出现数据损坏问题_no content length specified for stream data. strea-CSDN博客 2、 使用 FileInputStream使用完没有及时关闭导致报错 ClientAbortException: java.nio.channels.ClosedChannelException 添加…...
【C++】<知识点> 标准和文件的输入输出
目录 一、输入输出操作 1. 相关的类 2. 标准流对象 3. istream类的成员函数 二、流操纵算子 1. 整数流的基数 2. 浮点数精度的流操纵算子 3. 域宽的流操纵算子 4. 其他的流操纵算子 5. 用户自定义流操纵算子 三、文件读写 1. 文本文件的读写 2. 二进制文件的读写 3. 文件读写…...

在阿里Anolis OS 8.9龙蜥操作系统安装docker
在Anolis OS 8系统安装docker 1.更新系统 sudo dnf update -y2.安装依赖包 sudo dnf install -y yum-utils device-mapper-persistent-data lvm23.添加Docker的官方仓库 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo4.安装…...

短剧APP开发,短剧行业发展下的财富密码
今年以来,短剧市场展现出了繁荣发展的态势,成为了一个风口赛道。 短剧具有不拖沓、时长短、剧情紧凑等优势,顺应了当代人的生活,是当代人的“电子榨菜”。 短剧的快速发展同时也带动了新业态新模式的发展,短剧APP就是…...

简述分代垃圾回收器是怎么工作的?
分代垃圾回收器是一种用于管理和回收内存中垃圾对象的技术。它根据对象的存活时间将内存分为不同的代,并针对每个代应用不同的垃圾回收策略。 分代垃圾回收器的工作过程如下: 内存分代:首先,将内存分为不同的代,通常是…...

Qt 自定义代理类
一.使用步骤 继承QStyledItemDelegate类:首先创建一个新的类并继承自QStyledItemDelegate类,作为您的自定义代理类。 实现代理类的构造函数:在代理类中实现构造函数,并在构造函数中调用基类的构造函数,可以选择传入一…...

android GridLayout 布局详解,并举例
GridLayout 是 Android 中的一个布局容器,它允许你在一个二维网格中排列子视图。你可以指定网格的行数和列数,或者让 GridLayout 自动计算它们。每个子视图都可以占据一个或多个网格单元格。GridLayout 非常适合在需要创建规则网格的应用中使用ÿ…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...

智能体任务分配算法:从启发式到深度强化学习的演进与实践
1. 项目概述:从“谁来做”到“如何做得更好”的智能进化在机器人集群、无人机编队或是自动化仓储系统中,我们常常面临一个看似简单实则复杂的问题:眼前有一堆任务,手头有一群可用的智能体(机器人、无人机、服务器等&am…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...